2.1. Study Sites
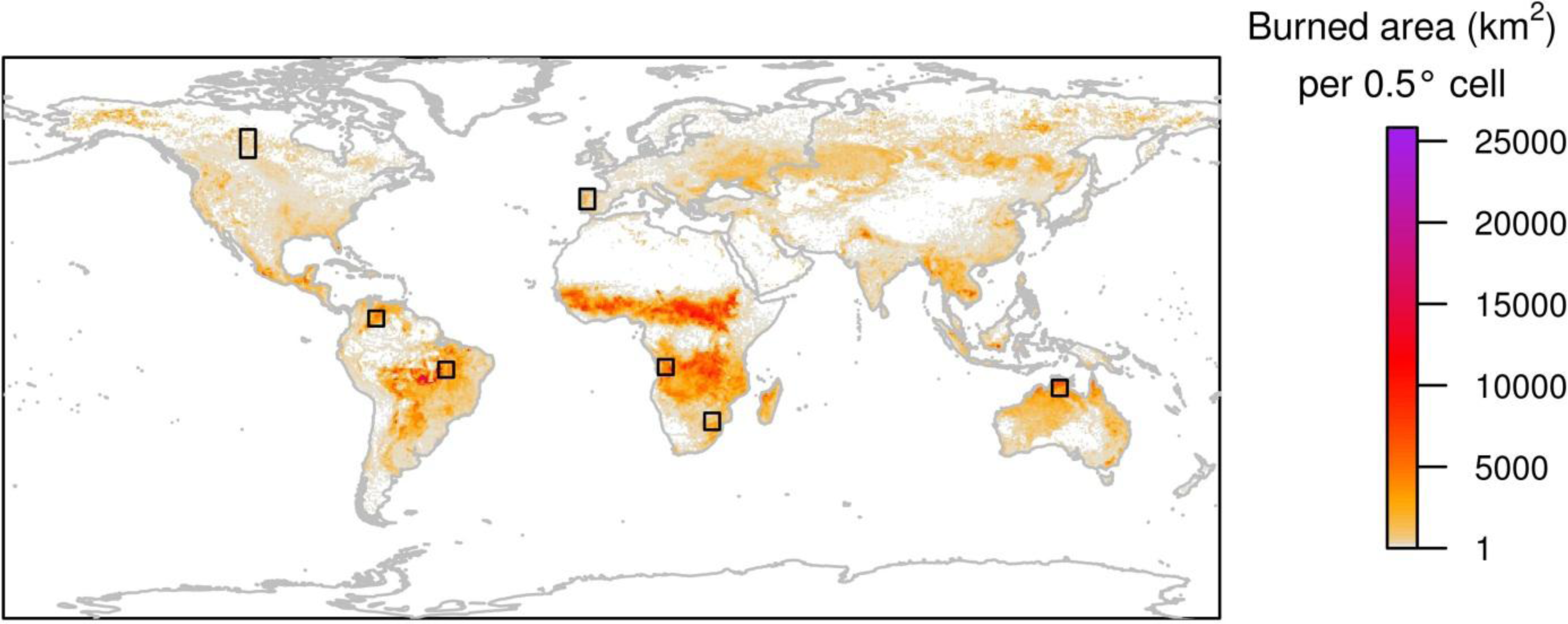
Temporal stability was derived from a set of study sites selected to represent the main ecosystems affected by fire. The reference fire perimeters for each site were derived from multi-temporal analysis of Landsat images, covering seven years (from 2001 to 2007). The seven study sites, each covering an area of 500 km × 500 km were located in Angola, Australia, Brazil, Canada, Colombia, Portugal, and South Africa (
Figure 1). Study sites were purposely selected to cover the most problematic areas for burned area discrimination and to represent the major biomes affected by fires (Tropical savannas, Boreal forest, Tropical forest, and Temperate forest). The fire_cci project collected reference data for three other study sites; however these three sites were not included in the analysis as reference data for some years were unavailable. Accuracy is likely to be dependent on the study site (because the sites belong to very different ecosystems). Therefore, we wanted to make sure that data for all study sites were available for each year to ensure a common temporal basis for evaluating all sites. A reference dataset was generated for each study site and year, from 2001 to 2007.
Although these seven sites provide data to illustrate the techniques proposed for assessing temporal stability, it is critical to recognize the limitations of these data when interpreting the results presented in Section 3. To effectively assess temporal stability of fire products, a long time series of reference data would be needed for a large number of sample sites. The time and cost to obtain such reference data are substantial. In this article, we can take advantage of an existing dataset, albeit one with a small sample size, to provide examples of what the analysis of temporal stability entails. A small sample size will likely yield low statistical power to detect departures from temporal stability, so for our illustrative example analysis, it should not be surprising if the statistical tests result in insufficient evidence to reject a null hypothesis that temporal stability is present. Moreover, the seven sample sites were selected specifically to span a broad geographic range, so the accuracy measures estimated from such a small sample will likely have high variance further reducing the power of the tests. A preferred scenario envisioned for an effective assessment of temporal stability would be to have an equal probability sample of 25–30 sites selected from each of six to eight geographic regions (e.g., biomes), and to obtain an annual time series of reference data for each site from which the accuracy measures would be derived. The temporal stability analyses we describe could then be applied to the sample data from each biome. We emphasize that the results and conclusions based on the seven sample sites should be considered as an illustrative, not definitive assessment of temporal stability of the three real fire products.
2.2. Reference Data
Fire reference perimeters for each site and year were produced for the period 2001 to 2007. For each year, two multi-temporal pairs of Landsat TM/ETM+ images (covering around 34,000 km
2) were downloaded from the Earth Resources Observation Systems (EROS) Data Center (EDC) of the USGS (
http://glovis.usgs.gov). We selected images that were cloud-free and without the Scan Line Corrector (SLC) failure whenever possible. The dates of image pairs were chosen to be close enough to be sure that the BA signal of fires occurring in between the two dates was still clear in the second date. We tried to select images fewer than 32 days apart for Tropical regions, where the burned signal lasts for only a short time, as fires tend to have low severity and vegetation regenerates quickly. For ecosystems where the burned signal persists longer, such as Temperate and Boreal forest, images could be separated by up to 96 days in some years. A total of 98 Landsat scenes were processed to generate the validation dataset. Burned area perimeters were derived from a semi-automatic algorithm developed by Bastarrika
et al. [
19]. Outputs of this algorithm were verified visually by one interpreter and reviewed by another. GOFC-GOLD regional experts were contacted to clarify problematic regions where ecological processes producing spectral responses similar to burned area could occur (e.g., vegetation phenology, harvesting or cutting trees). These reference fires were delineated following a standard protocol defined for the fire_cci project [
20] (available online at
http://www.esa-fire-cci.org/webfm_send/241) and based on the CEOS-LPV guidelines [
21]. Unobserved areas due to clouds or sensor problems in the Landsat images were masked out and removed from further analysis. Similarly, only the central parts of the images were considered for ETM images affected by the SLC failure.
BA products included in this study consisted of monthly files with pixel values referring to the burning date (Julian day, 1–365). Burned pixels between the reference image acquisition dates were coded as “burned”. The rest of the area was coded as “unburned” or “no data”, the latter applied to pixels obscured by clouds, with corrupted data, or missing values.
2.3. Accuracy Measurements
The error matrix summarizes two categorical classifications of a common set of sample locations (
Table 1). As Landsat-TM/ETM+ images have a much higher spatial resolution (30 m) than the global BA products (500–1000 m), the comparison between the global product and reference data was based on the proportion of each BA product pixel classified as burned in the reference (Landsat) pixels. Therefore, we compiled the error matrix, based on the partial agreement between the product and reference pixels. The error matrix for each Landsat scene and year was obtained by summing the agreement and disagreement proportions of each pixel. For example, a pixel classified as burned for the BA product that had 80% of reference burned pixels would have a proportion of 0.8 as true burned (
i.e.,
p11,u = 0.8 for pixel
u) and 0.2 as commission error (
p12,u =0.2), but this pixel would have neither omission errors (
p21,u = 0) nor true unburned area (
p22,u =0). Conversely, a pixel classified as unburned that had 10% of reference pixels detected as burned would have a proportion of 0.9 as true unburned (
p22,u =0.9),
p21,u =0.1 as omission error, and neither commission error (
p12,u =0) nor true burned area (
p11,u =0). The error matrix for each study site and year was computed from the sum of the single pixel error matrices:
where the summation is over all
Nss BA product pixels
u with available reference data at study site
ss. Detailed methods of this process can be found in Binaghi
et al. [
22], and for stratified samples in Stehman
et al. [
23].
Numerous accuracy measures may be derived from the error matrix. Three measures broadly used and generally accepted in the BA validation literature [
5–
7] are overall accuracy:
the commission error ratio:
and omission error ratio:
the two latter referring to the “burned” category. For most users, the accuracy of the “burned” category is much more relevant than the accuracy of unburned areas, as it is more closely related to the impacts of biomass burning on vegetation and atmospheric chemistry. For this reason, measures that focus on the “burned” category are recommended in BA product validation.
OA depends on category-map prevalence [
24] so in areas with low fire occurrence,
OA may be very stable through time because most of the area will be correctly classified as unburned. For this reason,
OA is not expected to be sufficiently sensitive to evaluate temporal stability of a product, as it has a strong dependence on the proportion of burned area (
p+1).
Ce and
Oe are anticipated to be more sensitive measures to changes in accuracy over time.
We also included a measure that combines information related to user’s and producer’s accuracy of BA. Such an aggregate measure of accuracy may be useful in applications in which the user does not have a preference for minimizing either
Oe or
Ce. The aggregate measure used is the Dice coefficient [
25–
27] defined as:
Given that one classifier (product or reference data in our case) identifies a burned pixel,
DC is the conditional probability that the other classifier will also identify it as burned [
26].
Bias has rarely been considered in BA validation even though it is relevant for climate modelers (e.g., of atmospheric emissions) who are interested in BA products with small over- or under-estimation of the proportion of BA [
3]. Bias expressed in terms of proportion of BA is defined as:
The bias can also be scaled relative to the reference BA:
B and
relB values above zero indicate that the product overestimates the extent of BA and values below zero indicate underestimation. An ideal product would have
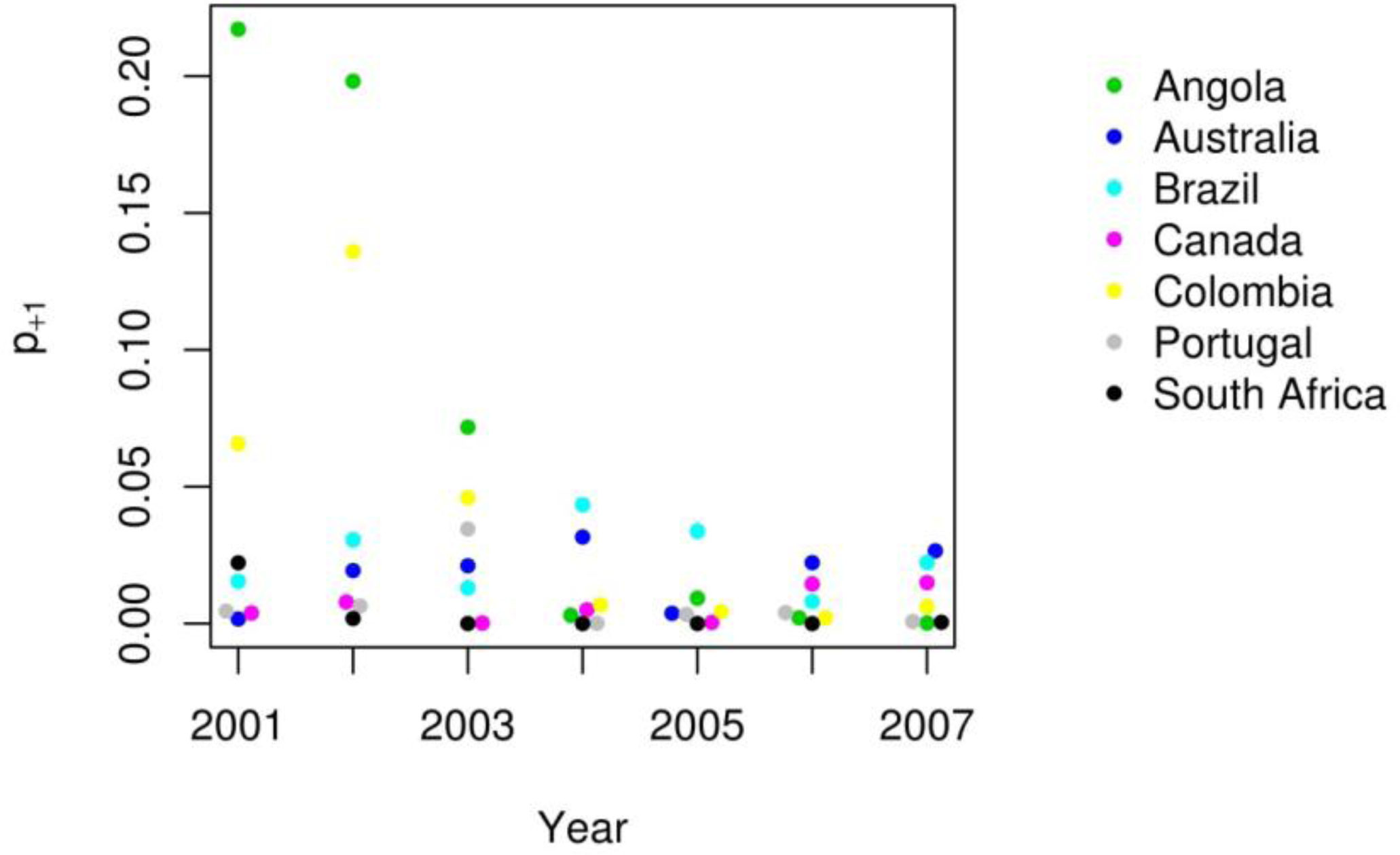
B and
relB close to zero over time, even with variation in the proportion of true BA (
p+1) over time.
B and
relB represent different features if BA varies over time. For example, a BA product exhibiting temporal stability where
B = −0.005 for each year would consistently underestimate the proportion of BA by 0.005 whether
p+1 = 0.001 or
p+1 = 0.05. AB of −0.005 might be acceptable to users when the proportion of BA is high (
p+1 = 0.05) but a
B of −0.005 would likely be considered problematic if the proportion of BA is much lower (e.g., when
p+1 is 0.001). In general, if the proportion of BA is variable over time, we anticipate that users would prefer a product with temporal stability of
relB rather than temporal stability of B. In fact, Giglio
et al. [
18] assumed that absolute bias (referred to as
B in the current manuscript) is proportional to BA in the uncertainty quantification of the Global Fire Emissions Database version 3 (GFED3). Giglio
et al. [
18] found a relation between the size of fire patches and the residual (or bias) for the MCD64 product. This relation was modeled and used in the uncertainty estimates at the GFED3 0.5° cells.
2.4. Temporal Stability Assessment
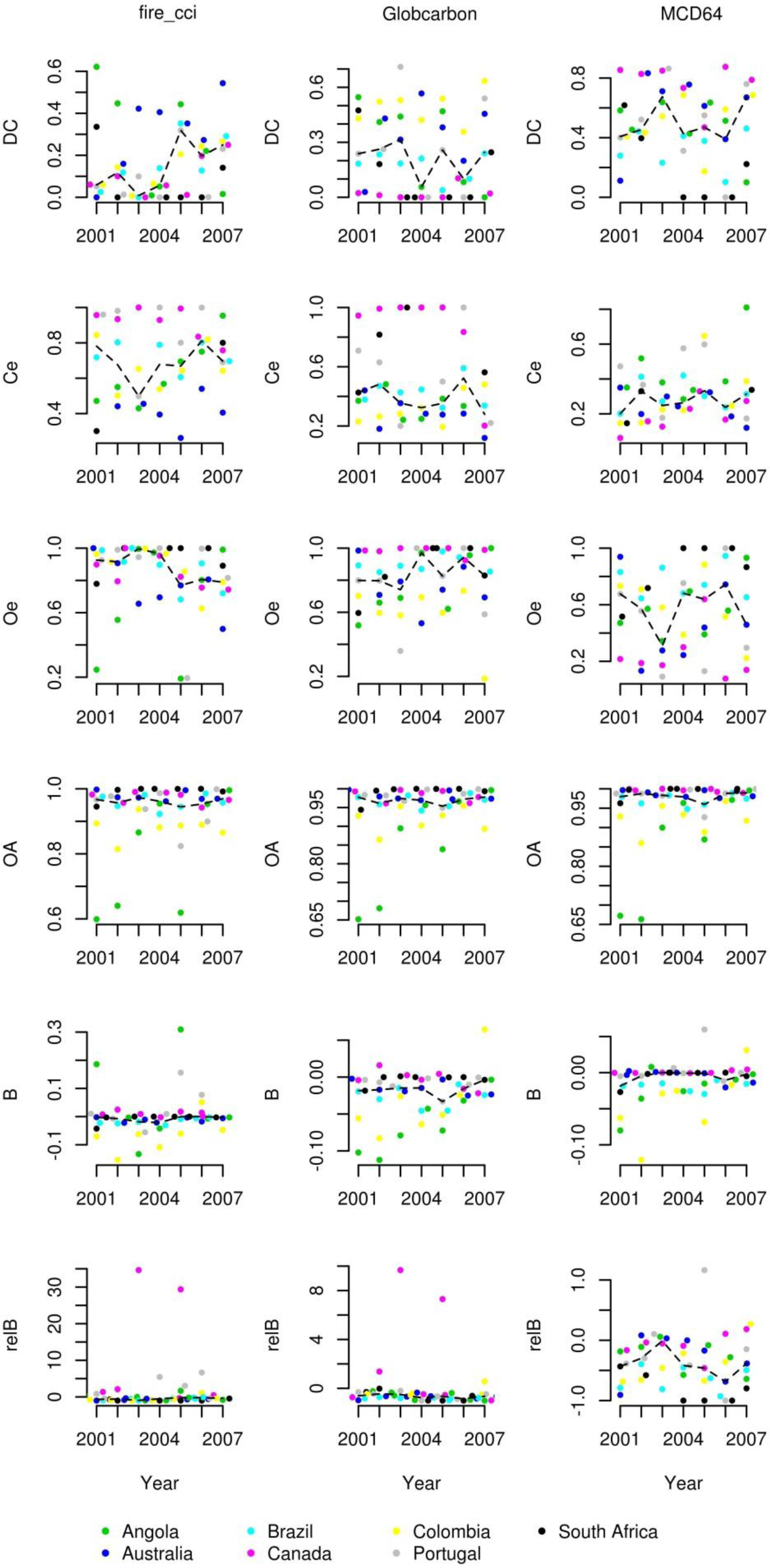
Accuracy measures were obtained for each study site and year. The goal of the temporal stability assessment is to evaluate the variability of accuracy of each product over time. Three assessments were used, two of which were designed to evaluate temporal stability of a single product (for each accuracy measure) and the third designed to compare temporal variability between products. The goal of these analyses is to infer characteristics of a population of sites from the sample of sites; thus, the analyses seek to address aggregate features (parameters) of the population. These analyses do not preclude detailed inspection of individual site results, and such inspection is an important routine component of any exploratory data analysis.
Following the definition of GCOS [
13], the first assessment of temporal stability evaluates whether a monotonic trend exists based on the slope (
b) of the relationship between an accuracy measure (
m) and time (
t). For a given accuracy measure
m, the ordinary least squares estimate of the slope at study site
ss is:
where
t is the year,
n is the number of years and
t̄ and
m̄ are the sample means computed as
and
, respectively. As the test for trend in accuracy over time is based on
b, the test is limited to assessing the linear component of the relationship of accuracy with time (year). The test for trend is a repeated measures analysis [
28] implemented as a parametric test using a one-sample
t-test applied to the sample
bm,ss observations (the sample size is
nss=number of study sites). Alternatively, a non-parametric version of the test for trend could be implemented using the one-sample non-parametric Wilcoxon test applied to the sample
bm,ss observations. The trend tests evaluate the alternative hypothesis that the mean or median slope is different from zero. We chose the nonparametric approach in our analyses. A statistically significant test result would indicate that accuracy metric
m presents temporal instability, as it would have a significant increase or decrease of that metric over time.
For the second assessment, the Friedman test [
29] provides a non-parametric analysis to test the null hypothesis that all years have the same median accuracy against the alternative hypothesis that some years tend to present greater accuracy values than other years. Rejection of the null hypothesis leads to the conclusion that the product does not possess temporal stability. The Friedman test evaluates a broader variety of deviations from temporal stability than is evaluated by the test for trend. Whereas the trend test focuses on a specific pattern of temporal instability (
i.e., an increase or decrease in accuracy over time), the Friedman test can detect more discontinuous departures from temporal stability. The Friedman test is a nonparametric analog to the analysis of a randomized complete block design where a block is one of the seven sites and the treatment factor is “year” with each year 2001 to 2007 considered a level of the “year” treatment factor. By using the blocked analysis, variation among sites is accounted for in the analysis. For example, one study site may have consistently better accuracy than another due to having a different fire distribution size. This source of variation (among site) is removed from the error term used to test for year effects in the Friedman test.
The proposed non-parametric procedures that evaluate the median are motivated for these analyses because of the likely non-normal distribution of the accuracy measures caused by the positive spatial autocorrelation of classification errors. It is well-known that fire events are positively spatial autocorrelated [
30] and this inevitably affects the spatial distribution of errors. This, in turn, may affect accuracy distributions, the variable being measured [
31]. Statistical inferences implemented in the temporal stability analyses are justifiably based on the median rather than the mean to summarize the central tendency of the per-year and per-site accuracy values because the median is less sensitive to outliers. Yearly median accuracies are displayed in the figures (Section 3) to aid visualization and ease interpretation of temporal trends.
The third assessment is based on the proportion of year-pairs with different accuracy for a given BA product. That is, for a given product, yearly accuracies are evaluated in pairs based on the non-parametric Wilcoxon signed-rank test, for matched-pairs observations [
32] with the significance level set at 0.05. These Wilcoxon tests of pairwise differences between years are the nonparametric analog of multiple comparisons procedures such as Fisher’s Protected Least Significant Difference or Tukey’s method for comparing means following a parametric analysis of variance. Temporal variability (
TempVar) of each product is then defined as the proportion of year-pairs with statistically significant differences (
Nsig) in the accuracy measure chosen. That is, if the total number of year-pairs is denoted as
Npair:
Npair is common for all products as it depends only on the number of available years, so for example if
Nyear is the number of years available and
Nyear = 7:
A significant difference in accuracy between two particular years was identified when a significant difference was detected for either DC or
relB, where
relB was used to asses bias, assuming users are more interested on stability in
relB, rather than in
B. Other accuracy measure combinations can be used to identify differences between year-pairs depending on specific end-user preferences.
TempVar provides an easily interpretable assessment of temporal variability as it can be understood as the probability that two randomly selected years have different accuracies.
For any given study site we have complete reference fire perimeters for all of the area within that site for which useable Landsat data were available. Consequently, we do not conduct statistical tests to evaluate temporal stability for each individual study site because we have not sampled within a site but instead worked with what is effectively a census of the available reference data. The accuracy measures obtained for a given study site may be regarded as parameters for that site and statistical inference is not necessary at the individual site level. The seven study sites may be regarded as a representative sample from a population of sites where this population includes much of the global variation in burned area. The statistical tests conducted in our temporal stability analyses should be viewed as inferences pertaining to this global population.
2.5. Hypothetical BA Products
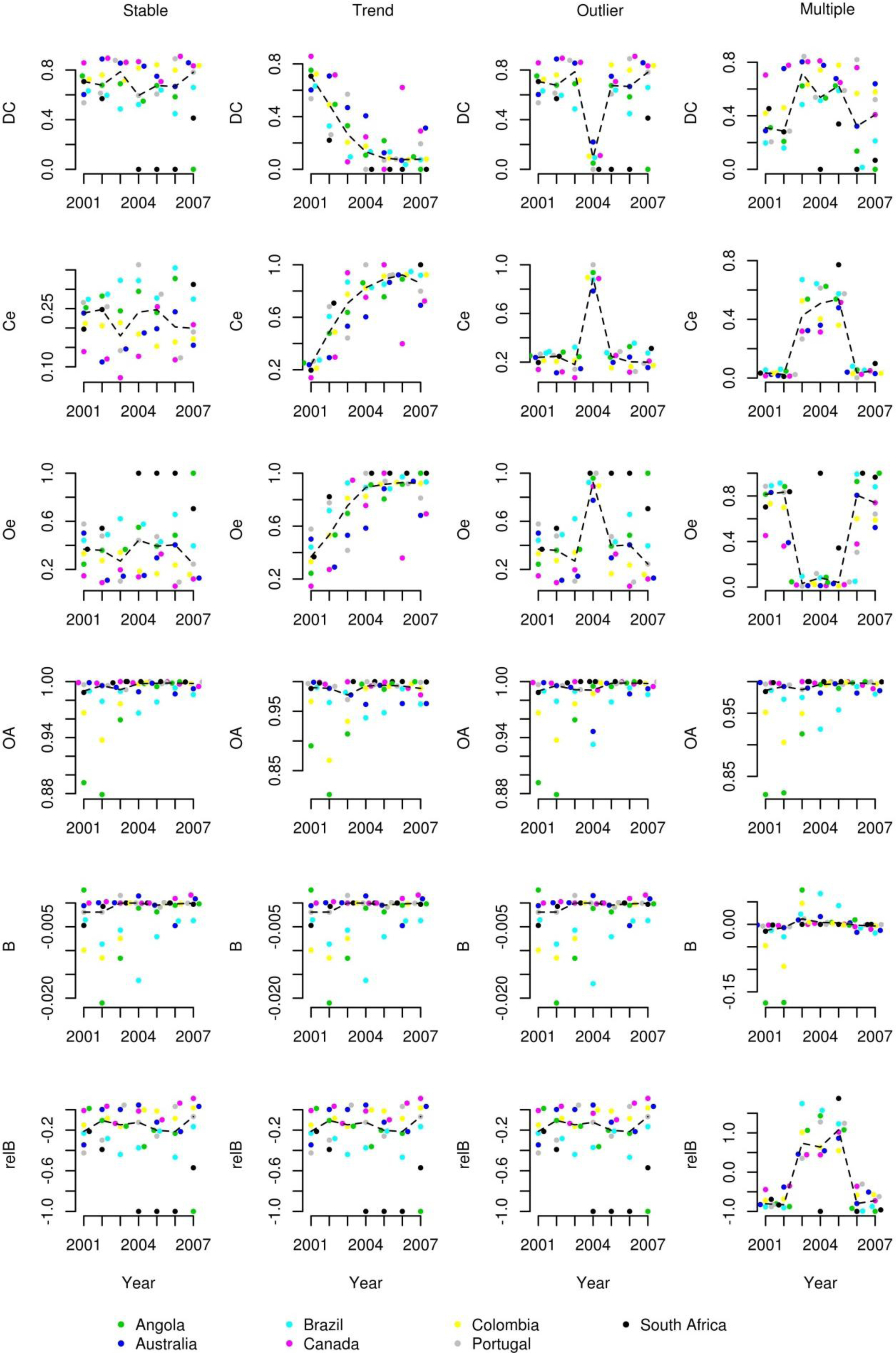
To examine the performance of the proposed temporal stability analyses, we created four hypothetical BA products, where one hypothetical product was constructed to have temporal stability, while the other three products were constructed to have different departures from temporal stability, namely: (a) a decreasing trend in accuracy over time, (b) a single “outlier” year of different accuracy, and (c) multiple consecutive years of different accuracy. The starting point for each hypothetical BA product was the actual reference data for the seven study sites.
The first hypothetical product was named Stable and represented a product that possessed temporal stability. To construct this product, a map pixel was labeled as burned if more than half of the reference pixels within the map pixel were burned (the map pixel is labeled as unburned otherwise). Creating the map pixels in this fashion ensures a common misclassification structure for each year (although prevalence of BA can change year to year) because we retained the actual reference proportion (p+1) of each study site. This first hypothetical BA product should exhibit temporal stability.
The second hypothetical product was named Trend and represents a product that decreases in accuracy over time. Similarly to construction of Stable, a map pixel was labeled as burned if more than half of the reference pixels within the map pixel were burned. To create the decrease in accuracy, the map was offset one pixel east and one pixel south per year. This process would emulate a product with a very consistent classification algorithm but with a failure in the sensor data that is propagated over time as in the first year (2001) the drift is zero (i.e., all pixels are accurately spatially co-registered) and in the last year (2007) where there is a drift of six pixels east and six pixels south. The shift of pixels was implemented such that the proportion of burned pixels for the map (p1+) and reference (p+1) were unchanged. That is, the “column” of map pixels resulting from a one pixel shift of the map to the east would be re-inserted on the western edge of the boundary so that the map proportions p1+ and p2+ were not changed from prior to the shift. The reference map is not shifted at all so there was no change in p+1 and p+2. As B and relB were determined by the difference between p1+ and p+1, these measures take on the same values for the Trend BA product as they do for the Stable hypothetical product.
The third hypothetical product was named Outlier because it was constructed to represent a temporally stable product for all years except one. The initial map labels were created as described for the hypothetical BA product Stable, but for the year 2004 data, the map was offset by six pixels (thus, the outlier year, 2004, was equivalent to what was the year 2007 data in the Trend hypothetical product). The Outlier product emulates a product with a consistent classification algorithm but with a temporary (single year) failure in the sensor data.
The fourth hypothetical product was named Multiple and was designed to emulate a product with a temporally contiguous multi-year shift in accuracy. This product was constructed so that a different classification criterion was used for the central years (2003, 2004, and 2005). For 2003–2005, a map pixel was labeled as burned if more than 20% of the reference pixels within the map pixel were labeled as burned. For the other years (2001, 2002, 2006, and 2007), a map pixel was labeled as burned only if more than 80% of the reference pixels within the map pixel were labeled as burned. Multiple emulates a product with a temporary (three years) change of classification algorithm or sensor data that produces a change of sensitivity on detecting BA.








{kind=link}
{kind=link}
{kind=link}
{kind=link}