
Active Collection of Land Cover Sample Data from Geo-Tagged Web Texts





Abstract
:
1. Introduction
2. Related Works
2.1. Geo-Tagged Web Resources and Their Applications
2.2. Geo-Tagged Web Resources Collection
2.3. Web-Based Sample Data Collection for Land Cover Map Validation
3. Methodology
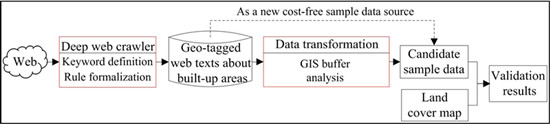
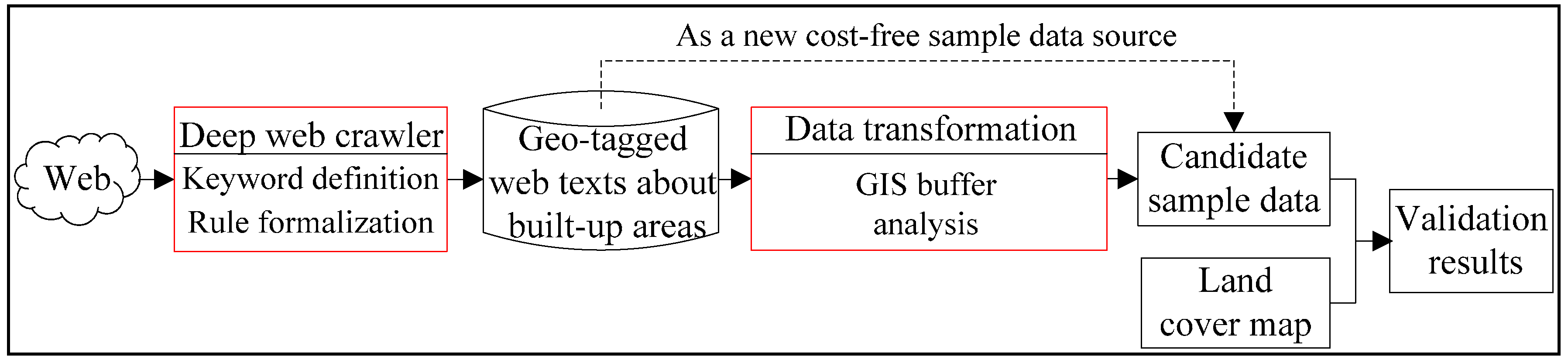
3.1. Conceptual Framework of Active Collection from Geo-Tagged Web Texts


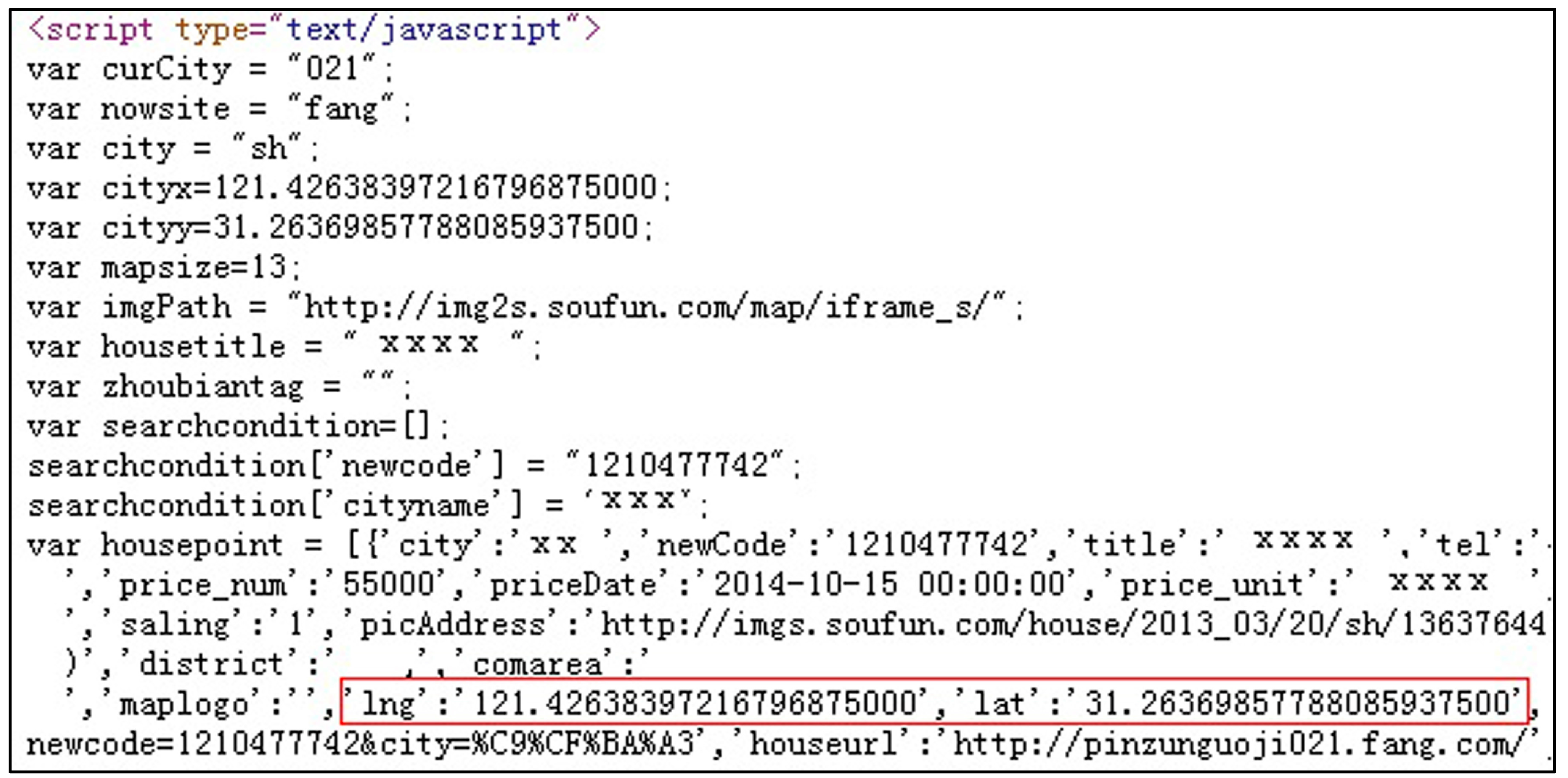
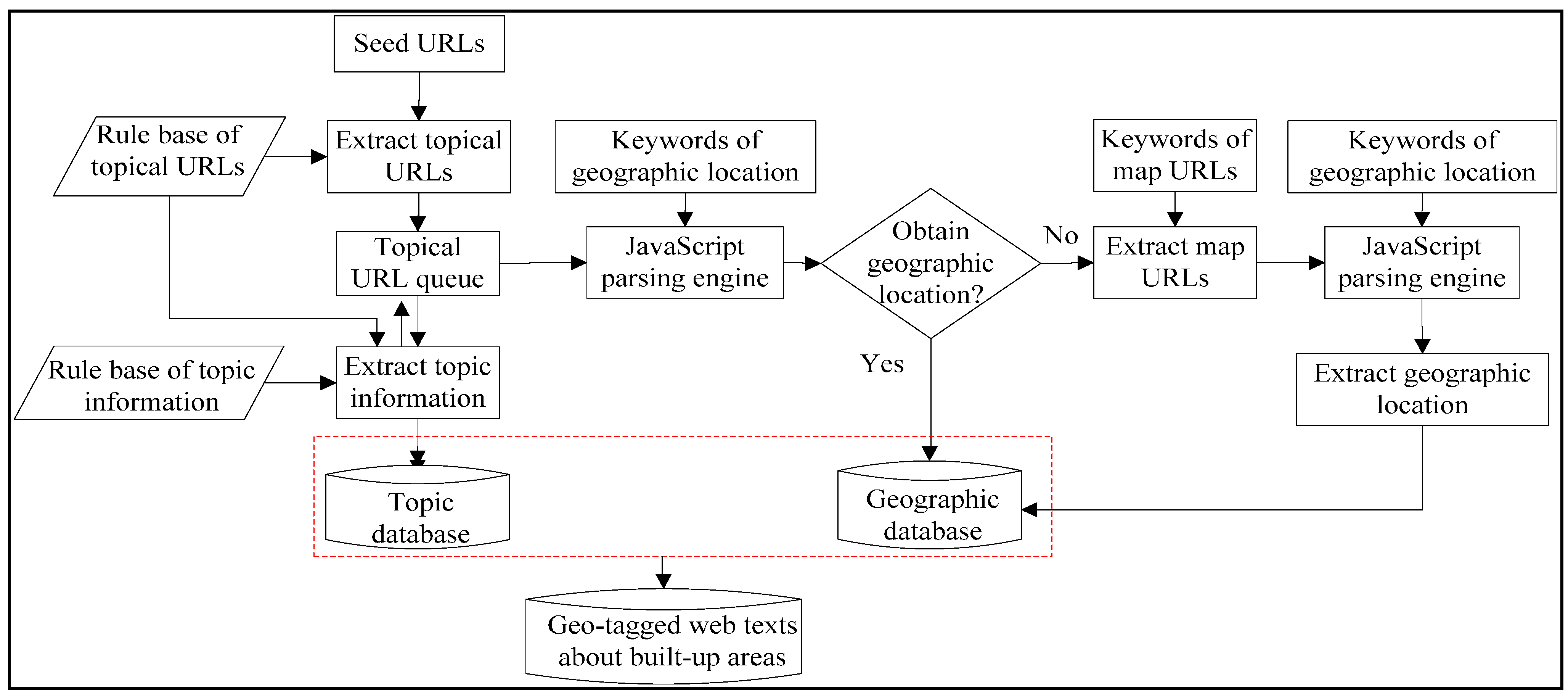
3.2. Deep Web Crawler for Geo-Tagged Web Texts

3.3. Data Transformation Process Using GIS Buffer Analysis
- (1)
- Geo-tagged web texts about built-up areas are collected by the proposed deep web crawler described in Section 3.1.
- (2)
- The collected geo-tagged web texts are filtered to remove undesired texts according to some spatial and temporal restrictions of LC maps. For example, if geo-tagged web texts are not uniform with minimum spatial coverage and temporal coverage of LC maps, they should be discarded.
- (3)
- GIS buffer analysis is exploited to obtain reference zones, which in turn transform the rest of geo-tagged web texts to candidate sample data, as discussed in Section 3.1.
- (4)
- The pixel comparison is conducted to validate the accuracy of the LC maps. Details of pixel comparison are introduced in the following sections.


4. Experiments and Analysis
4.1. Experimental Data and Study Area
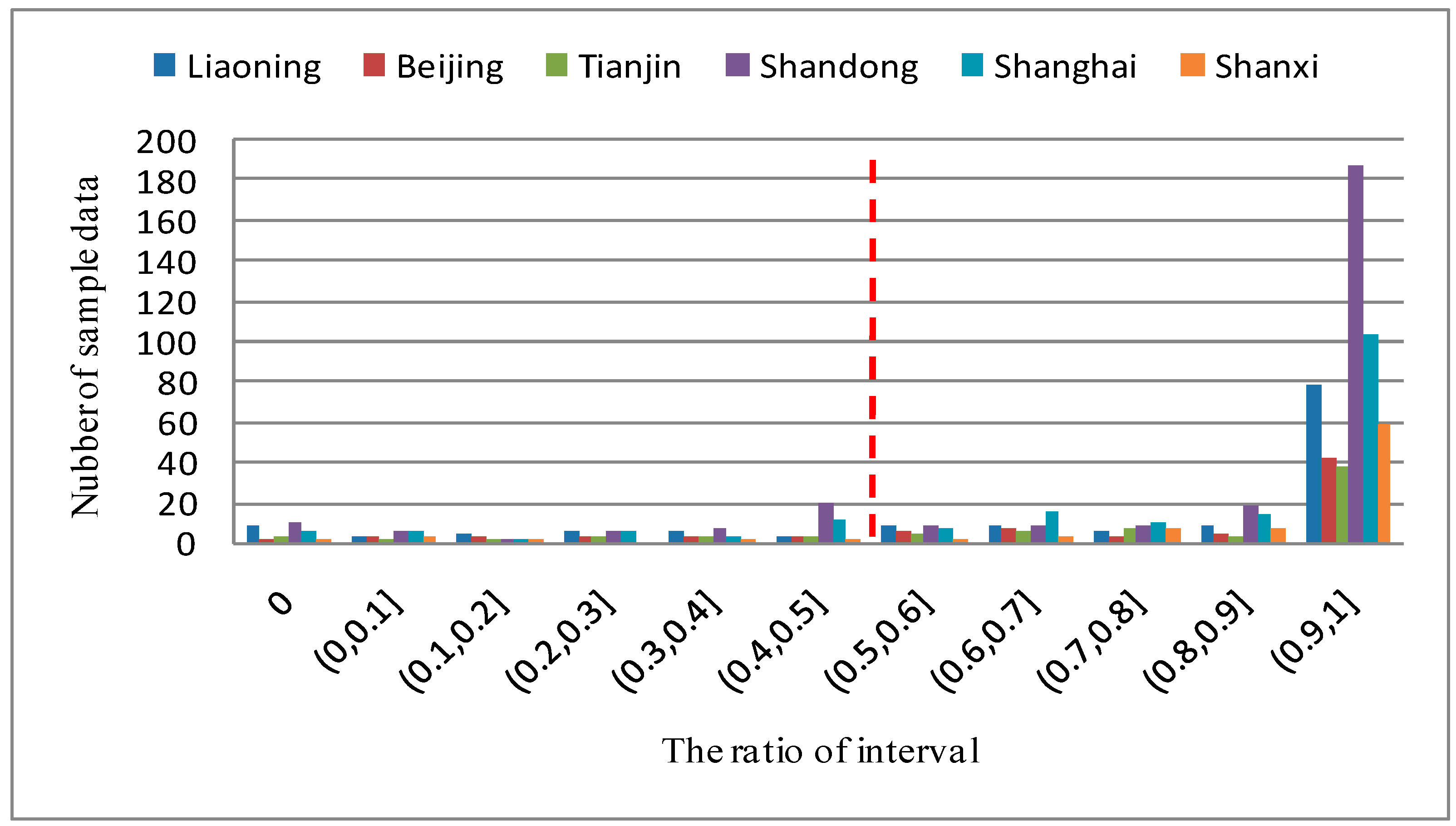
4.2. Results of Deep Web Crawler

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Liaoning | Beijing | Tianjin | Shandong | Shanghai | Shanxi | Total Number | |
|---|---|---|---|---|---|---|---|
| Collected Number | 1264 | 485 | 478 | 2573 | 673 | 810 | 6283 |
| Collecting Time(s) | 2022 | 630 | 717 | 4640 | 1346 | 1528 | 10,883 |
| Speed | 0.63 | 0.77 | 0.67 | 0.55 | 0.5 | 0.53 | 0.58 |
| Liaoning | Beijing | Tianjin | Shandong | Shanghai | Shanxi | Total Number | |
|---|---|---|---|---|---|---|---|
| Collected Number | 1577 | 4034 | 1202 | 2514 | 2024 | 1711 | 10,362 |
| Collecting Time(s) | 7002 | ||||||
| Speed | |||||||
4.3. Assisting Validation and Results
| Building Time | Liaoning | Beijing | Tianjin | Shandong | Shanghai | Shanxi |
|---|---|---|---|---|---|---|
| 2010 | 139 | 74 | 67 | 282 | 184 | 80 |
| 2011 | 168 | 48 | 71 | 402 | 91 | 76 |
| 2012 | 90 | 36 | 51 | 178 | 48 | 85 |
| 2013 | 58 | 25 | 51 | 204 | 46 | 54 |
| 2014 | 11 | 10 | 9 | 25 | 13 | 17 |
| 2015 | 0 | 0 | 0 | 0 | 1 | 1 |



| Liaoning | Beijing | Tianjin | Shandong | Shanghai | Shanxi | Total Number | |
|---|---|---|---|---|---|---|---|
| CR | 108 | 60 | 55 | 232 | 151 | 73 | 679 |
| TC | 139 | 74 | 67 | 282 | 184 | 80 | 826 |
| User’s accuracy | 77.70% | 81.08% | 82.09% | 82.27% | 82.07% | 91.25% | 82.20% |
5. Discussions
- (1)
- Usually, land cover map validation should be done through a rigorous sampling scheme. However, this study just aims to demonstrate that geo-tagged web texts have the potential to become another new cost-free sample data source, rather than to perform rigorous validation. Therefore, sampling schemes are ignored to keep the study focused and simple. After the sample data about other land cover types is collected from geo-tagged web texts, a rigorous sampling scheme suitable for online validation will be integrated into the proposed approach in the future.
- (2)
- Only geo-tagged web texts of built-up areas were collected using the proposed approach to validate artificial surfaces. However, an extensive verification with other land cover types would provide more valuable insights into the proposed approach. Web texts about cultivated land, shrubland, and tundra are difficult to find for the time being, and their occupied areas are seldom offered by websites. Fortunately, a lot of texts about wetland, water bodies, permanent snow/ice, forest, grassland, and bareland are geo-tagged on the web (i.e., Wikipedia and Baidu Encyclopedia [56,57]) and their occupied areas are also offered in detail. For instance, geographic location, occupied area and other descriptions about the wetland area of the Pantanal can be collected from the Wikipedia website [58]. However, the content and structural characteristics of other land cover types are different from artificial surfaces class and their shapes are irregular, which makes the data transformation more difficult. A unified description model for representing the land cover types of wetland, water bodies, permanent snow/ice, forest, grassland, and bareland is under development now. Further, some new rules for extracting the required factors from multiple different web sources are to be summarized. In addition, a new data transformation process will need to be designed for irregular shapes based on minimum bounding box or convex hull in the future. As part of the long-term research objectives of the team [59], when this work is completed, the proposed approach can be used to collect other land cover types from different websites by simply replacing the modules of keywords definition, extraction rules and data transformation.
- (3)
- The quality of geo-tagged web texts directly affects land cover map validation results. Currently, geo-tagged web texts about built-up areas used in this study are from commercial companies, which may be credible to some extent. Except for this data source, there are also a large number of geo-tagged web texts contributed by individual volunteers with no quality assurance. It is difficult to assess the quality of these voluntarily contributed contents quantitatively, but the increasing emotional comments on the content that somehow indicate “approval” or “disapproval” may help at least measure the quality to certain extent. Future work will include sentiment analysis of comments to assess their quality for more accurate validation.
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Stehman, S.V. Sampling designs for accuracy assessment of land cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Estima, J.; Painho, M. Flickr geotagged and publicly available photos: Preliminary study of its adequacy for helping quality control of corine land cover. In Computational Science and Its Applications—ICCSA 2013; Murgante, B., Misra, S., Carlini, M., Torre, C., Nguyen, H.-Q., Taniar, D., Apduhan, B., Gervasi, O., Eds.; Springer: Heidelberg, Germany, 2013; Volume 7974, pp. 205–220. [Google Scholar]
- Foody, G.M.; Boyd, D.S. Using volunteered data in land cover map validation: Mapping west African forests. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1305–1312. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Iwao, K.; Nishida, K.; Kinoshita, T.; Yamagata, Y. Validating land cover maps with Degree Confluence Project information. Geophy. Res. Lett. 2006, 33, L23404. [Google Scholar] [CrossRef]
- Tsendbazar, N.E.; de Bruin, S.; Herold, M. Assessing global land cover reference datasets for different user communities. ISPRS J. Photogramm. Remote Sens. 2015, 103, 93–114. [Google Scholar] [CrossRef]
- Comber, A.; See, L.; Fritz, S.; van der Velde, M.; Perger, C.; Foody, G. Using control data to determine the reliability of volunteered geographic information about land cover. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 37–48. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, P.; Yu, L.; Hu, L.; Li, X.; Li, C.; Zhang, H.; Zheng, Y.; Wang, J.; Zhao, Y.; et al. Towards a common validation sample set for global land-cover mapping. Int. J. Remote Sens. 2014, 35, 4795–4814. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Manakos, I.; Chatzopoulos-Vouzoglanis, K.; Petrou, Z.I.; Filchev, L.; Apostolakis, A. Globalland30 mapping capacity of land surface water in Thessaly, Greece. Land 2014, 4, 1–18. [Google Scholar] [CrossRef]
- Tong, X.; Zhang, X.; Shan, J.; Xie, H.; Liu, M. Attraction-repulsion model-based subpixel mapping of multi-/hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2799–2814. [Google Scholar] [CrossRef]
- Stehman, S.V.; Olofsson, P.; Woodcock, C.E.; Herold, M.; Friedl, M.A. A global land-cover validation data set, II: Augmenting a stratified sampling design to estimate accuracy by region and land-cover class. Int. J. Remote Sens. 2012, 33, 6975–6993. [Google Scholar] [CrossRef]
- Bastin, L.; Buchanan, G.; Beresford, A.; Pekel, J.F.; Dubois, G. Open-source mapping and services for web-based land-cover validation. Ecol. Inform. 2013, 14, 9–16. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Magnussen, S.; McDonald, S. Validation of a large area land cover product using purpose-acquired airborne video. Remote Sens. Environ. 2007, 106, 480–491. [Google Scholar] [CrossRef]
- Clark, M.L.; Aide, T.M. Virtual Interpretation of Earth Web-Interface Tool (VIEW-IT) for collecting land-use/land-cover reference data. Remote Sens. 2011, 3, 601–620. [Google Scholar] [CrossRef]
- Fritz, S.; McCallum, I.; Schill, C.; Perger, C.; Grillmayer, R.; Achard, F.; Kraxner, F.; Obersteiner, M. Geo-Wiki.Org: The use of crowdsourcing to improve global land cover. Remote Sens. 2009, 1, 345–354. [Google Scholar] [CrossRef]
- Fritz, S.; McCallum, I.; Schill, C.; Perger, C.; See, L.; Schepaschenko, D.; van der Velde, M.; Kraxner, F.; Obersteiner, M. Geo-Wiki: An online platform for improving global land cover. Environ. Model. Softw. 2012, 31, 110–123. [Google Scholar] [CrossRef]
- Han, G.; Chen, J.; He, C.; Li, S.; Wu, H.; Liao, A.; Peng, S. A web-based system for supporting global land cover data production. ISPRS J. Photogramm. Remote Sens. 2015, 103, 66–80. [Google Scholar] [CrossRef]
- Zheng, Y.-T.; Zha, Z.-J.; Chua, T.-S. Research and applications on georeferenced multimedia: A survey. Multimed. Tools Appl. 2011, 51, 77–98. [Google Scholar] [CrossRef]
- Li, L.; Goodchild, M.F.; Xu, B. Spatial, temporal, and socioeconomic patterns in the use of Twitter and Flickr. Cartogr. Geogr. Inf. Sci. 2013, 40, 61–77. [Google Scholar] [CrossRef]
- Majid, A.; Chen, L.; Chen, G.; Mirza, H.T.; Hussain, I.; Woodward, J. A context-aware personalized travel recommendation system based on geotagged social media data mining. Int. J. Geogr. Inf. Sci. 2013, 27, 662–684. [Google Scholar] [CrossRef]
- Leung, D.; Newsam, S. Exploring geotagged images for land-use classification. In Proceedings of the ACM Multimedia 2012 Workshop on Geotagging and Its Applications in Multimedia, Nara, Japan, 29 October–2 November 2012.
- Lu, G.; Liu, S.; Lü, K. MBCrawler: A software architecture for micro-blog crawler. In Proceedings of the 2012 International Conference on Information Technology and Software Engineering, Beijing, China, 8–10 December 2012.
- Gao, K.; Zhou, E.-L.; Grover, S. Applied methods and techniques for modeling and control on micro-blog data crawler. In Applied Methods and Techniques for Mechatronic Systems; Springer: Berlin, Germany, 2014; Volume 452, pp. 171–188. [Google Scholar]
- Schmidt, V.; Binner, J. A semi-automated display for geotagged text. In City Evacuations: An Interdisciplinary Approach; Preston, J., Binner, J.M., Branicki, L., Galla, T., Jones, N., King, J., Kolokitha, M., Smyrnakis, M., Eds.; Springer: Heidelberg, Germany, 2015; pp. 107–116. [Google Scholar]
- Wikipedia. Geotagged Photograph. Available online: http://en.wikipedia.org/wiki/Geotagged_photograph (accessed on 27 October 2014).
- Manvi, M.; Dixit, A.; Bhatia, K.K. Design of an ontology based adaptive crawler for hidden web. In Proceedings of the 2013 International Conference on Communication Systems and Network Technologies (CSNT), Gwalior, India, 6–8 April 2013.
- Piccinini, H.; Casanova, M.; Leme, L.P.; Furtado, A. Publishing deep web geographic data. Geoinformatica 2014, 18, 769–792. [Google Scholar] [CrossRef]
- Luo, J.; Joshi, D.; Yu, J.; Gallagher, A. Geotagging in multimedia and computer vision—A survey. Multimed. Tools Appl. 2011, 51, 187–211. [Google Scholar] [CrossRef]
- Cao, L.; Friedland, G.; Larson, M. GeoMM’12: ACM international workshop on geotagging and its applications in multimedia. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012.
- Senaratne, H.; Bröring, A.; Schreck, T. Using reverse viewshed analysis to assess the location correctness of visually generated VGI. Trans. GIS 2013, 17, 369–386. [Google Scholar] [CrossRef]
- Ahern, S.; Naaman, M.; Nair, R.; Yang, J.H.-I. World explorer: Visualizing aggregate data from unstructured text in geo-referenced collections. In Proceedings of the 7th ACM/IEEE-CS Joint Conference on Digital Libraries, Vancouver, BC, Canada, 18–23 June 2007.
- Fujisaka, T.; Lee, R.; Sumiya, K. Discovery of user behavior patterns from geo-tagged micro-blogs. In Proceedings of the 4th International Conference on Uniquitous Information Management and Communication, Suwon, Korea, 14–15 January 2010.
- Crampton, J.W.; Graham, M.; Poorthuis, A.; Shelton, T.; Stephens, M.; Wilson, M.W.; Zook, M. Beyond the geotag: Situating “big data”and leveraging the potential of the geoweb. Cartogr. Geogr. Inf. Sci. 2013, 40, 130–139. [Google Scholar] [CrossRef]
- Gao, S.; Li, L.; Li, W.; Janowicz, K.; Zhang, Y. Constructing gazetteers from volunteered big geo-data based on Hadoop. Environ. Urban Sys. 2014. [Google Scholar] [CrossRef]
- Popescu, A.; Grefenstette, G. Deducing trip related information from flickr. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; pp. 1183–1184.
- Goodchild, M.F.; Glennon, J.A. Crowdsourcing geographic information for disaster response: A research frontier. Int. J. Digit. Earth 2010, 3, 231–241. [Google Scholar] [CrossRef]
- Chae, J.; Thom, D.; Jang, Y.; Kim, S.; Ertl, T.; Ebert, D.S. Public behavior response analysis in disaster events utilizing visual analytics of microblog data. Comput. Graph. 2014, 38, 51–60. [Google Scholar] [CrossRef]
- Eisenstein, J.; Smith, N.A.; Xing, E.P. Discovering sociolinguistic associations with structured sparsity. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011.
- Vu, H.Q.; Li, G.; Law, R.; Ye, B.H. Exploring the travel behaviors of inbound tourists to Hong Kong using geotagged photos. Tour. Manag. 2015, 46, 222–232. [Google Scholar] [CrossRef]
- Frias-Martinez, V.; Frias-Martinez, E. Spectral clustering for sensing urban land use using Twitter activity. Eng. Appli. Artif. Intell. 2014, 35, 237–245. [Google Scholar] [CrossRef]
- Boanjak, M.; Oliveira, E.; Martins, J.; Mendes Rodrigues, E.; Sarmento, L. TwitterEcho: A distributed focused crawler to support open research with twitter data. In Proceedings of the 21st International Conference Companion on World Wide Web, Lyon, France, 16–20 April 2012; pp. 1233–1240.
- Tsou, M.-H.; Yang, J.-A.; Lusher, D.; Han, S.; Spitzberg, B.; Gawron, J.M.; Gupta, D.; An, L. Mapping social activities and concepts with social media (Twitter) and web search engines (Yahoo and Bing): A case study in 2012 US Presidential Election. Cartogr. Geogr. Inf. Sci. 2013, 40, 337–348. [Google Scholar] [CrossRef]
- Lee, R.; Wakamiya, S.; Sumiya, K. Discovery of unusual regional social activities using geo-tagged microblogs. World Wide Web 2011, 14, 321–349. [Google Scholar] [CrossRef]
- Batsakis, S.; Petrakis, E.G.; Milios, E. Improving the performance of focused web crawlers. Data Knowl. Eng. 2009, 68, 1001–1013. [Google Scholar] [CrossRef]
- Hou, D.; Wu, H.; Chen, J.; Li, R. A focused crawler for borderlands situation information with geographical properties of place names. Sustainability 2014, 6, 6529–6552. [Google Scholar] [CrossRef]
- Raghavan, S.; Garcia-Molina, H. Crawling the hidden web. In Proceeding of the 27th International Conference on Very Large Data Bases (VLDB 2001), Rome, Italy, 11–14 September 2001.
- Zeng, W.; Li, M. Survey on the research of deep web crawler. Comput. Syst. Appl. 2008, 17, 122–126. [Google Scholar]
- Foster, A.; Dunham, I.M. Volunteered geographic information, urban forests, & environmental justice. Comput. Environ. Urban Syst. 2014. [Google Scholar] [CrossRef]
- Weiss, M.; Baret, F.; Block, T.; Koetz, B.; Burini, A.; Scholze, B.; Lecharpentier, P.; Brockmann, C.; Fernandes, R.; Plummer, S.; et al. On Line Validation Exercise (OLIVE): A web based service for the validation of medium resolution land products. Application to FAPAR products. Remote Sens. 2014, 6, 4190–4216. [Google Scholar] [CrossRef]
- Yan, Z.; Li, Q.; Dong, Y.; Ding, Y. An ontology-based integration of Web query interfaces for house search. In Proceedings of the International Conference on Information and Automation, Changsha, China, 20–23 June 2008.
- Li, X.; Zhang, L.; Liang, C. A GIS-based buffer gradient analysis on spatiotemporal dynamics of urban expansion in Shanghai and its major satellite cities. Procedia Environ. Sci. 2010, 2, 1139–1156. [Google Scholar] [CrossRef]
- Oliveira, D. Ionosphere-magnetosphere coupling and field-aligned currents. Revi. Bras. Ensino Físi. 2014, 36, 1–5. [Google Scholar]
- Arcavi, A. The role of visual representations in the learning of mathematics. Educ. Stud. Math. 2003, 52, 215–241. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X. Concepts and key techniques for 30 m global land cover mapping. Acta Geo. Et Carto. Sin. 2014, 43, 551–557. [Google Scholar]
- Wikipedia Encyclopedia. Available online: http://www.wikipedia.org/ (accessed on 30 January 2015).
- Baidu Encyclopedia. Available online: http://baike.baidu.com/ (accessed on 30 January 2015).
- Pantanal-Wikipedia, the Free Encyclopedia. Available online: http://en.wikipedia.org/wiki/Pantanal (accessed on 30 January 2015).
- Chen, J.; Wu, H.; Li, S.; Chen, F.; Han, G. Services oriented dynamic computing for land cover big data. J. Geo. Sci. Tec. 2013, 30, 551–557. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, D.; Chen, J.; Wu, H.; Li, S.; Chen, F.; Zhang, W. Active Collection of Land Cover Sample Data from Geo-Tagged Web Texts. Remote Sens. 2015, 7, 5805-5827. https://doi.org/10.3390/rs70505805
Hou D, Chen J, Wu H, Li S, Chen F, Zhang W. Active Collection of Land Cover Sample Data from Geo-Tagged Web Texts. Remote Sensing. 2015; 7(5):5805-5827. https://doi.org/10.3390/rs70505805
Chicago/Turabian StyleHou, Dongyang, Jun Chen, Hao Wu, Songnian Li, Fei Chen, and Weiwei Zhang. 2015. "Active Collection of Land Cover Sample Data from Geo-Tagged Web Texts" Remote Sensing 7, no. 5: 5805-5827. https://doi.org/10.3390/rs70505805
APA StyleHou, D., Chen, J., Wu, H., Li, S., Chen, F., & Zhang, W. (2015). Active Collection of Land Cover Sample Data from Geo-Tagged Web Texts. Remote Sensing, 7(5), 5805-5827. https://doi.org/10.3390/rs70505805