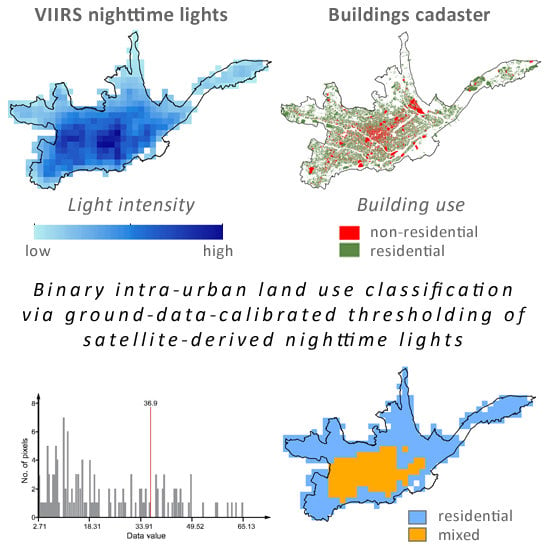
The application of ISA and alternatively VIIRS data to identify intra-urban occupancy type distribution patterns that we outline in this paper and the corresponding findings include several interesting aspects for further discussion. In the following we highlight three relevant points at different stages in the model setup. First, we provide some background information on selection criteria of VIIRS data. Then, we discuss the actual differences in the outcome of the proposed binary land use classification approach when implemented using ISA vs. VIIRS data. Finally, we highlight the impact that proper urban spatial delineation has on the model outcome by applying a spatially shrunk urban mask for the Cuenca City test case.
5.1. VIIRS Data Selection
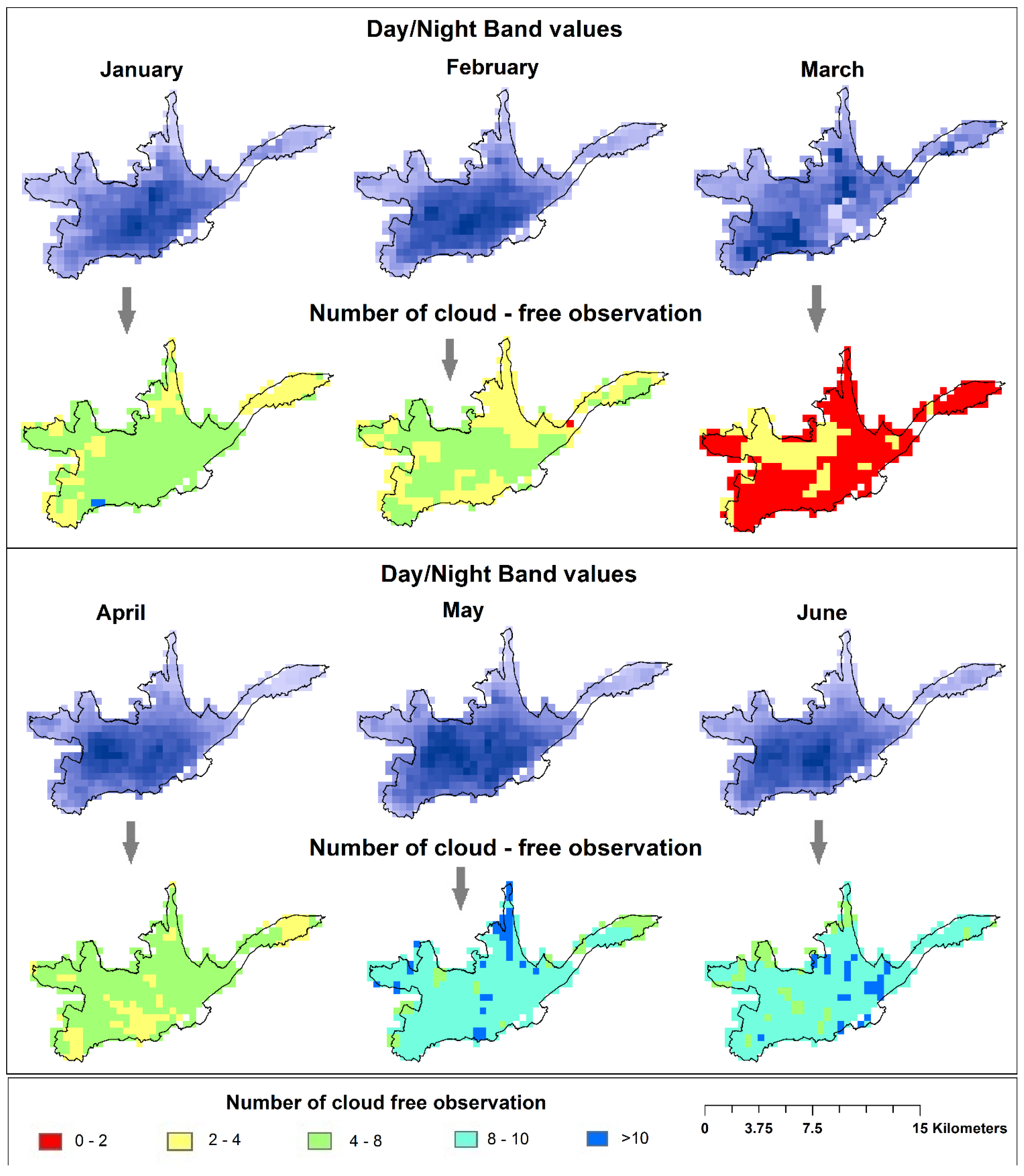
Initial nightlights data selection has a big influence on the model outcome and is particularly important in a sense that VIIRS data is provided by NOAA-NGDC as basic monthly average light intensity composites whereas ISA data comes as a fully-processed product derived from annual DMSP-OLS composites and calibrated with ancillary built-up reference information. The number of cloud-free observations is a crucial factor for producing average composites as excessive cloud cover can obscure light-emitting sources on the ground. In monthly products fewer observations are potentially available to compute composite grids as compared to yearly products and average values can therefore more easily turn out to be skewed and non-representative in case of extended cloud cover in the respective month. There are obviously other influencing parameters that can impair light identification such as obscuring factors like smoke or fog and misleading reflections from snow cover, lightning or the aurora. However, cloud cover is clearly considered the most relevant parameter in the context of the compositing process, particularly in equatorial regions such as the study area of Ecuador. For our study we evaluated the 6 most recent available readily-processed monthly composites (at the time of writing) covering January–June 2015 (other monthly composites were only available as preliminary beta versions having lower quality). For the Cuenca City study area the monthly VIIRS composites of May and June 2015 feature the highest average number of cloud-free observations (see
Table 4), thus providing best data reliability.
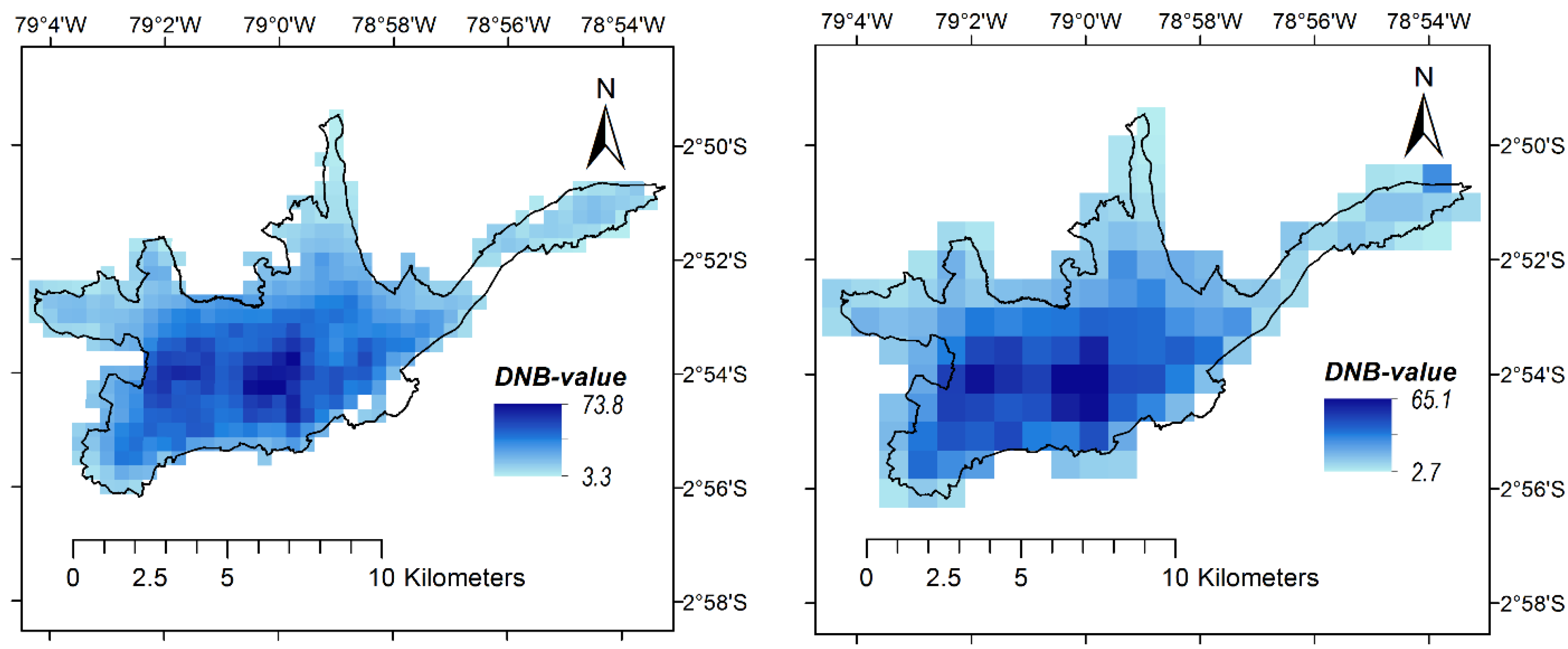
Figure 9 illustrates the light intensity values for the 6 analyzed monthly composites as well as the corresponding number of cloud-free observations at a pixel-by-pixel basis. For the light intensity grids, darker blue tones indicate higher intensity. For the cloud-free observation grids, dark blue would represent the best situation (no cloud cover at any day during the month) whereas green, yellow and red colors indicate decreasing data reliability (due to fewer cloud-free observations).
Table 4.
Average number of cloud-free observations in VIIRS 2015 monthly composites for the Cuenca City study area (grey indicating eventually selected monthly composite).
Table 4.
Average number of cloud-free observations in VIIRS 2015 monthly composites for the Cuenca City study area (grey indicating eventually selected monthly composite).
| Month | Number of Cloud-Free Observation | Day/Night Band (DNB) Value |
|---|
| Min | Max | Average | Min | Max |
|---|
| January | 2 | 9 | 5.47 | 3.8 | 86.9 |
| February | 2 | 6 | 4.52 | 3.52 | 129.1 |
| March | 0 | 4 | 1.98 | 0.0 | 92.3 |
| April | 3 | 8 | 5.37 | 3.9 | 55.8 |
| May | 6 | 11 | 8.97 | 3.5 | 55.7 |
| June | 6 | 11 | 8.81 | 3.3 | 73.8 |
Theoretically, just a couple of high-quality observations can be sufficient to produce an appropriate composite product. While the monthly composites of May and June have the highest number of cloud-free observations, other months’ composites can thus feature very similar light intensity value distributions (as it is the case for example for the April composite). We therefore explicitly refer to data reliability as an indicator as opposed to general data quality.
Figure 9.
VIIRS data of the first six months of 2015 for the Cuenca City study area. Grids of average light intensity (top). Grids showing the number of cloud-free observations at the cell level used to produce the average light intensity composites (bottom).
Figure 9.
VIIRS data of the first six months of 2015 for the Cuenca City study area. Grids of average light intensity (top). Grids showing the number of cloud-free observations at the cell level used to produce the average light intensity composites (bottom).
Although the May composite has the highest number of cloud-free observations on average, that value is almost identical to the June composite (see
Table 4). In that case, an additional parameter should be identified to justify selection. On the one hand visual inspection of the cell-level distribution of cloud-free observations could give an extra indication on potential data quality. If, for example, more cloud-free observations are found in the city center (where non-residential activity is expected), that could be beneficial given the context of the presented study. Another parameter could be the detected light intensity range, with detection of higher intensities (
i.e., likely non-obscured) being potentially favorable. Following the latter criterion, higher intensity levels are identified in the June composite as compared to the May data set (see
Table 4). Other secondary selection criteria could take into account influencing parameters that impair light identification (as mentioned above). Data on those parameters is usually not publicly available though. As intra-urban cloud-free observations at cell-level are similarly distributed for the May and June composites, the higher detected light intensity range was eventually the determining factor in selecting the June data set for the test study.
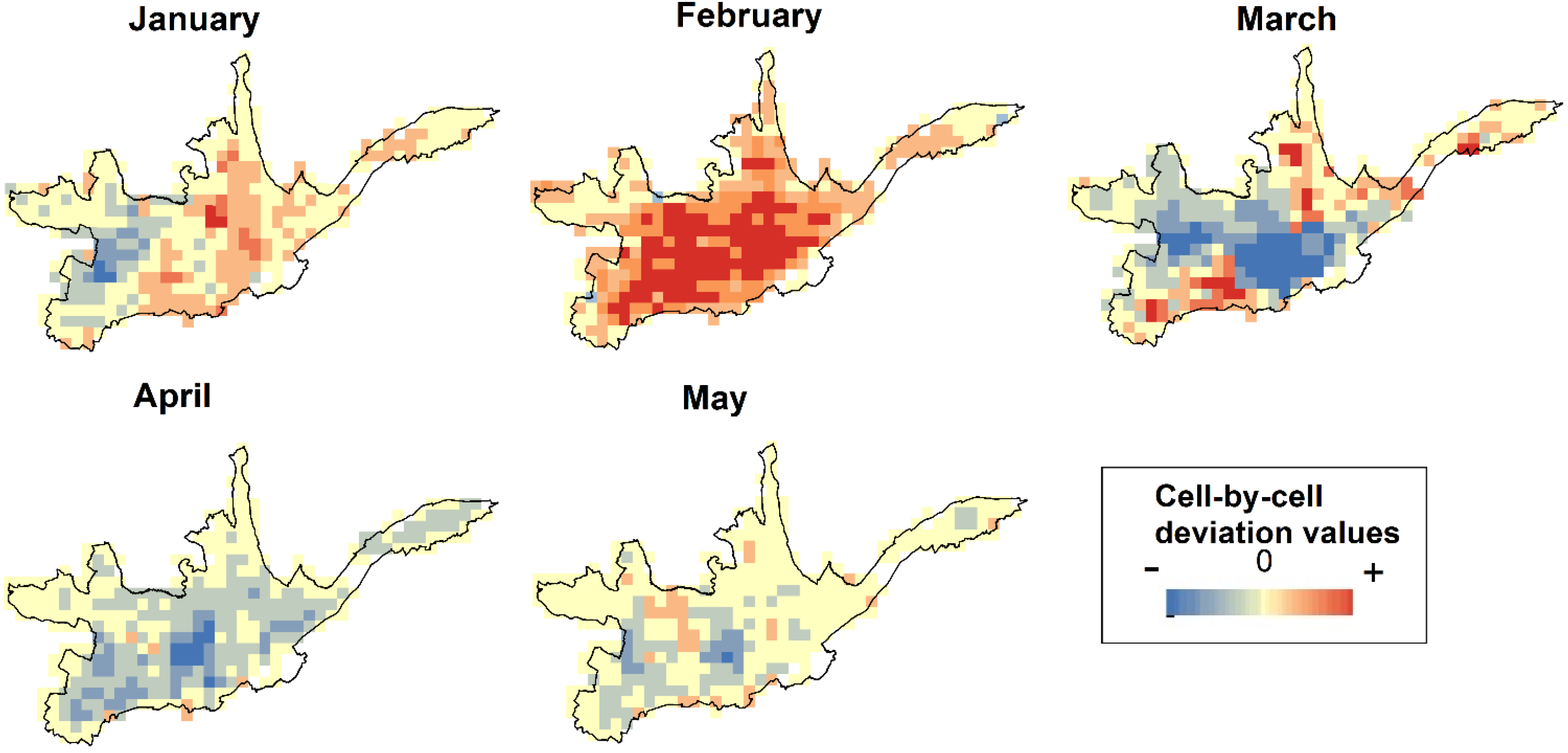
To further highlight the differences in spatial patterns between the 6 available monthly composites, cell-by-cell light intensity deviations of every grid to the eventually selected June composite are computed as illustrated in
Figure 10. In line with the observations described above, the May composite matches the June dataset most closely also in that regard. Besides, the overall patterns of those cell-by-cell deviations align adequately with the corresponding grids showing the number of cloud-free observations (see
Figure 9). The February and March composites, for example, show the largest deviations to the June grid on a cell-by-cell basis, thus assumingly confirming the poorer reliability of those grids when referring to the low number of cloud-free observations. Specifically the March grid can be considered unusable, while there may be additional reasons for the extreme light intensities observed during the month of February (e.g., night parades and other associated carnival celebration activities in the middle of the month).
Figure 10.
Cell-by-cell deviations to the selected June grid.
Figure 10.
Cell-by-cell deviations to the selected June grid.
Table 5 illustrates a set of tested VIIRS threshold values using the May data as alternative in order to demonstrate potential model output variation in case a different monthly composite was selected. When applying the 53rd percentile threshold (highlighted in green in
Table 5) that delivered the best match to the cadastral data in the June composite, a 65:35 building use distribution split was obtained for the May composite, thus significantly overestimating the non-residential share. In the May data the 64th percentile is identified as fitting threshold (highlighted in grey in
Table 5) best approximating the aggregated cadastral grid.
Table 5.
VIIRS distribution thresholds (original 15 arc-sec grid) and corresponding building use distribution ratios using the monthly composite for May ratios (grey indicating selected best-matching threshold, green indicating previously identified June threshold for comparison).
Table 5.
VIIRS distribution thresholds (original 15 arc-sec grid) and corresponding building use distribution ratios using the monthly composite for May ratios (grey indicating selected best-matching threshold, green indicating previously identified June threshold for comparison).
| ID | VIIRS Distribution | Built-up Area Distribution |
|---|
| Min | Threshold | Max | Percentile | Residential Use | Mixed Use |
|---|
| 1 | 3.5 | 16.0 | 55.6 | 24% | 32.00% | 68.00% |
| 2 | 3.5 | 29.5 | 55.6 | 50% | 62.00% | 37.00% |
| 3 | 3.5 | 31.1 | 55.6 | 53% | 65.00% | 35.00% |
| 6 | 3.5 | 37.0 | 55.6 | 64% | 75.00% | 25.00% |
| 9 | 3.5 | 50.6 | 55.6 | 90% | 96.00% | 4.00% |
5.2. Comparative Analysis of ISA- and VIIRS-Based Results of the Binary Land Use Classification
The second aspect to be discussed is a comparison of the model output when using ISA and VIIRS-DNB data respectively. This is relevant in several aspects, most specifically (1) in terms of evaluating feasibility of continued applicability of the presented approach with the DMSP program fading out as well as (2) to assess the impact and examine expected multisided improvements due to VIIRS’ improved spatial and radiometric resolution as compared to OLS.
To factor out potential influences caused by the higher spatial resolution we first compare the findings of the ISA-based analysis to those using a correspondingly aggregated 30 arc-sec VIIRS grid. Results prove to be similar in fact, with a 55th percentile threshold identified as best fit to distinguish residential and mixed occupancy areas in the VIIRS data as compared to the 50% threshold in the ISA data. In case of applying the same 50% threshold to the aggregated VIIRS composite, the obtained occupancy distribution in the correspondingly aggregated cadastral data would show a 70:30 residential-mixed split as compared to the targeted 75:25 ratio. When evaluating the degree of spatial overlap as a measure of model output accuracy, applying the respectively identified best-fitting thresholds to both data sets results in a slightly better capturing of non-residential built-up area in the binary mixed use mask that is derived from the ISA data (83%) as compared to the aggregated VIIRS data based mask (79%). If again the 50% threshold was applied to the VIIRS composite instead of the identified 55th percentile threshold, approximately 84% of the non-residential built-up area would be captured. While thereby a marginally better result is achieved in terms of capturing non-residential built-up area, the residential-mixed distribution ratio would be skewed and mixed use areas would actually be overrepresented spatially.
Applying the VIIRS data in its original spatial resolution (15 arc-sec), the best-fitting threshold value to approximate the targeted 75:25 residential-mixed distribution pattern is identified at the 53rd percentile. This is slightly below the threshold value identified for the aggregated VIIRS composite (55th percentile). 76% of the total non-residential building stock of Cuenca City (3.27 of 4.3 km2) is captured within the derived mixed use mask. That value is below both the 79% value when using the aggregated VIIRS data and the 83% value when using the ISA data. In case of applying the initial 50% threshold for the binary classification, 79% of the non-residential building stock would be captured at a 71:29 occupancy type ratio distribution.
Checking those numbers it therefore appears that using ISA data renders a better model performance than using VIIRS data both in original and aggregated form, inasmuch as more non-residential built-up area is detected in the binary masks that were derived using optimized thresholding to match residential-mixed occupancy distribution ratios. However, while a higher percentage of the non-residential built-up area is captured, ISA-derived mixed use areas are slightly more scattered. Taking VIIRS as input data source clusters the detection more in a sense that the average cell-level non-residential built-up density is higher in those binary occupancy type mask derivatives. Using the original-resolution composite, 76% of the total non-residential building stock (3.27 km2) is captured within 25.75 km2, thus featuring an average non-residential built-up density of 12.7% per km2. When using ISA data, 83% of the total non-residential building stock (3.57 km2) is captured within 32 km2, thus an average density of 11.1% per km2.
With the threshold values and associated parameters are obviously rather similar for the VIIRS- and ISA-based approaches, another interesting evaluative perspective is to derive a corresponding binary mask from the aggregated cadastral data and then check spatial pattern concurrence to the nightlights products.
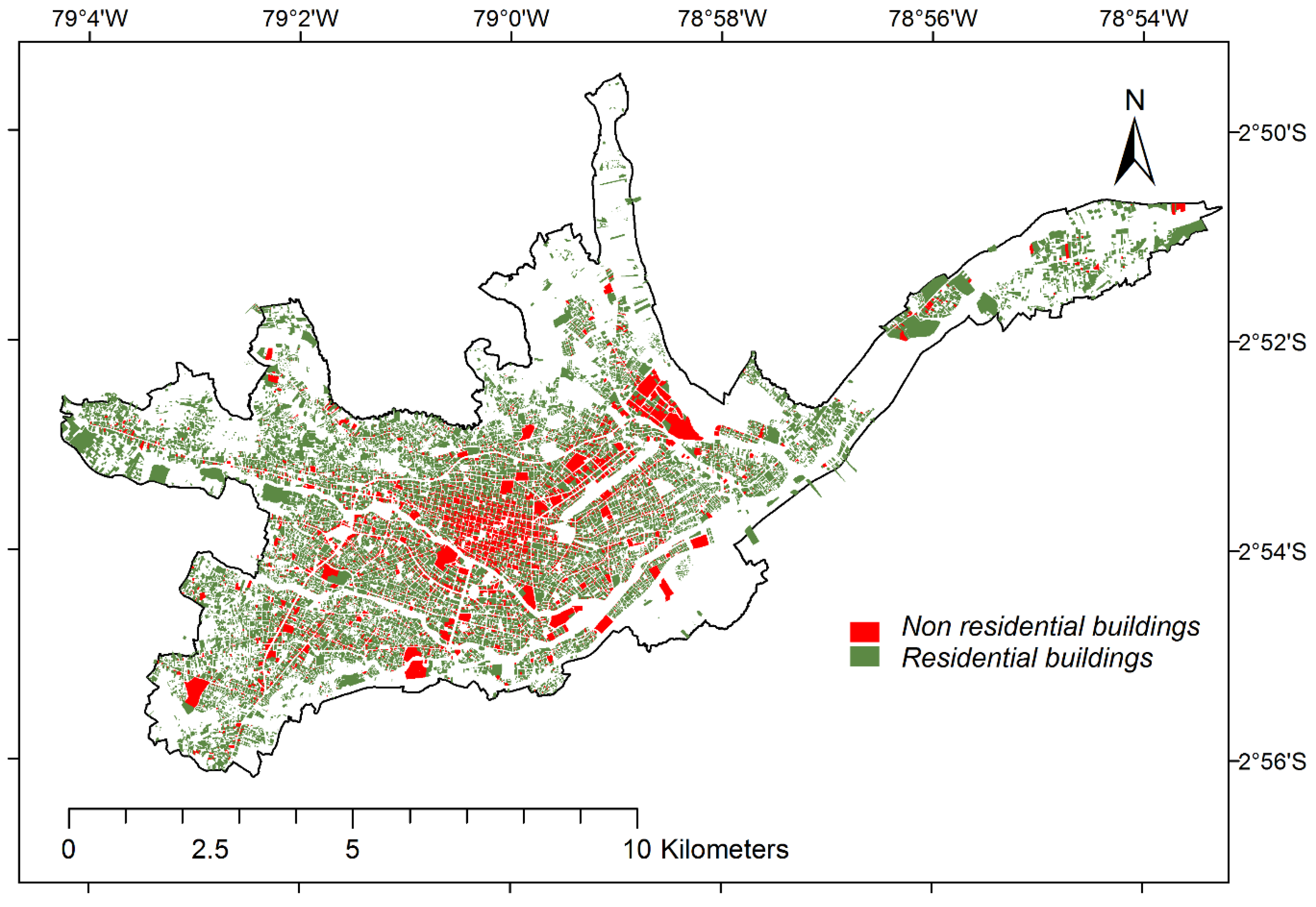
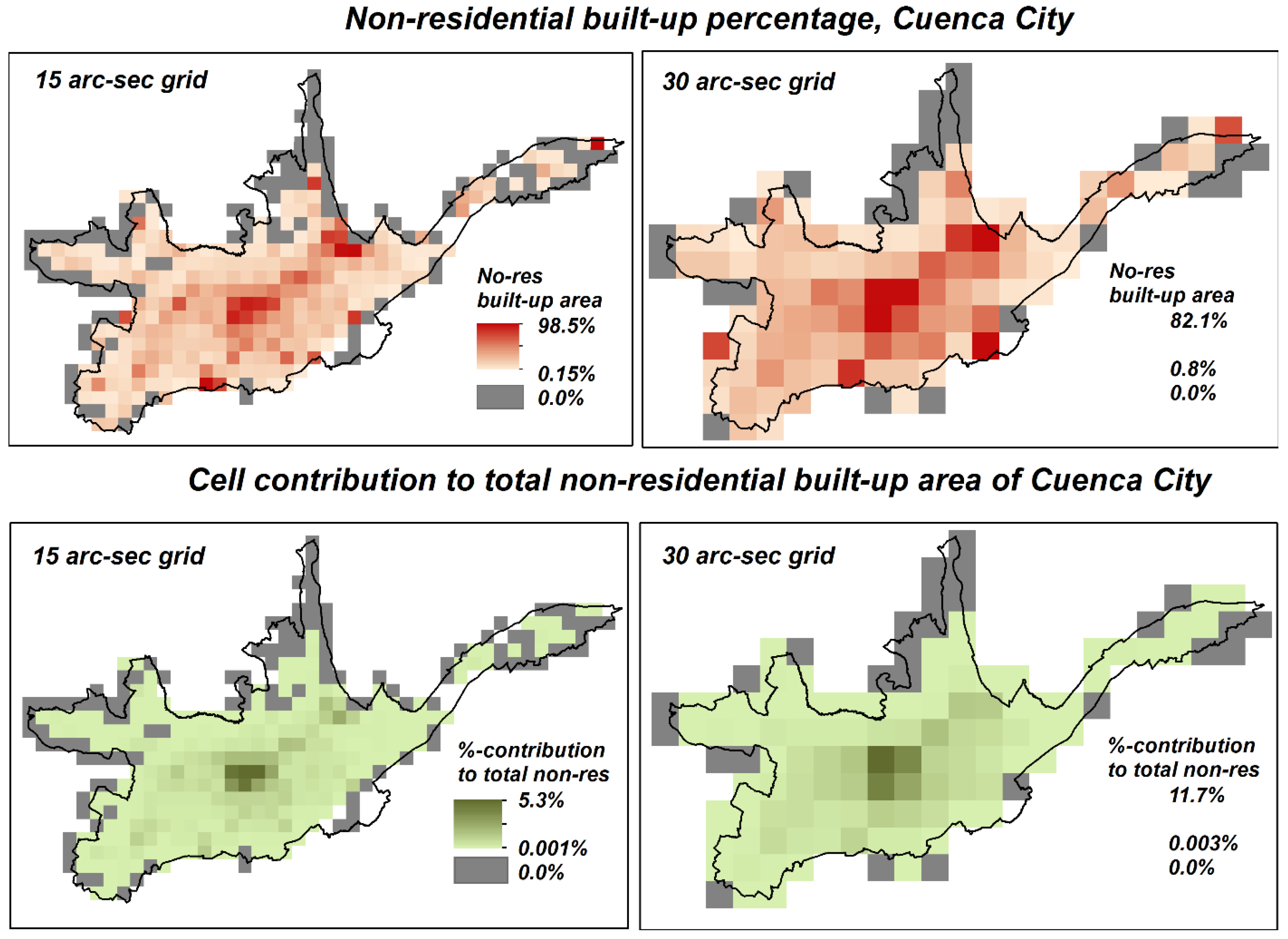
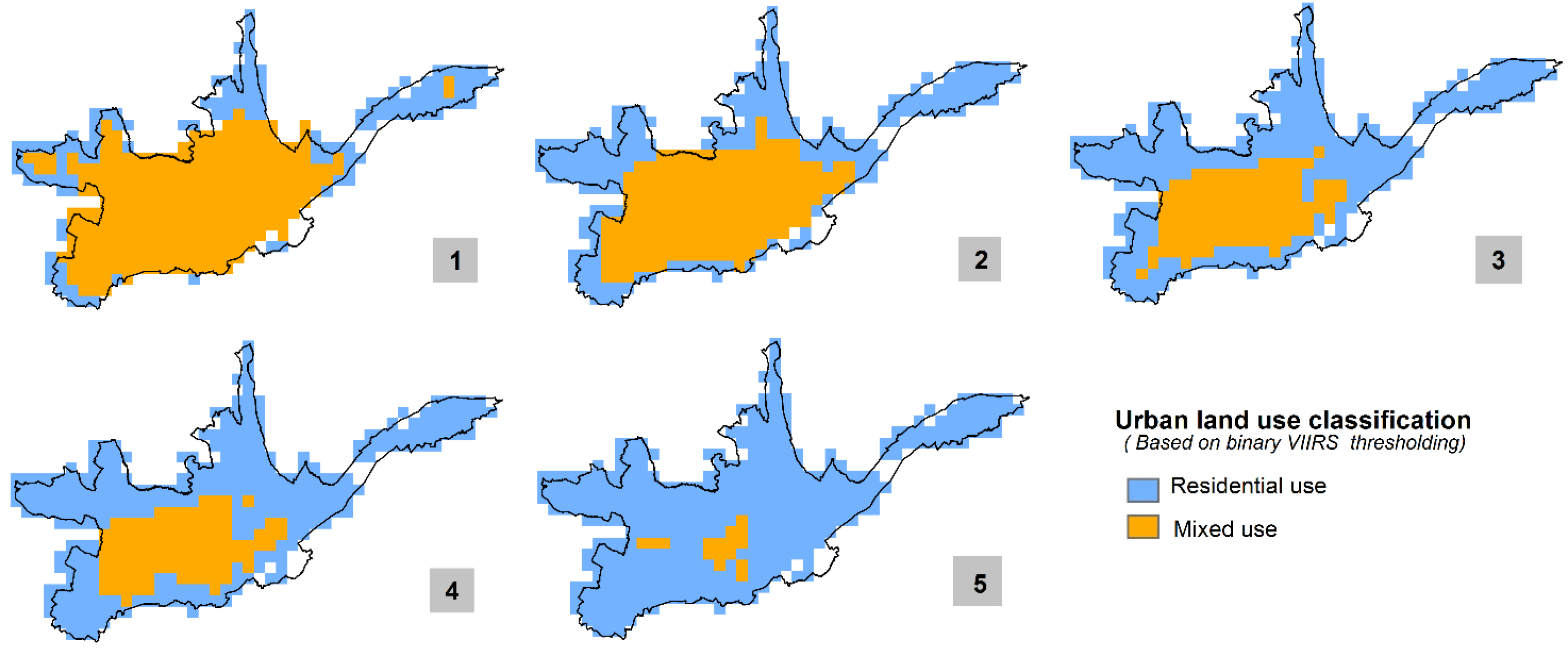
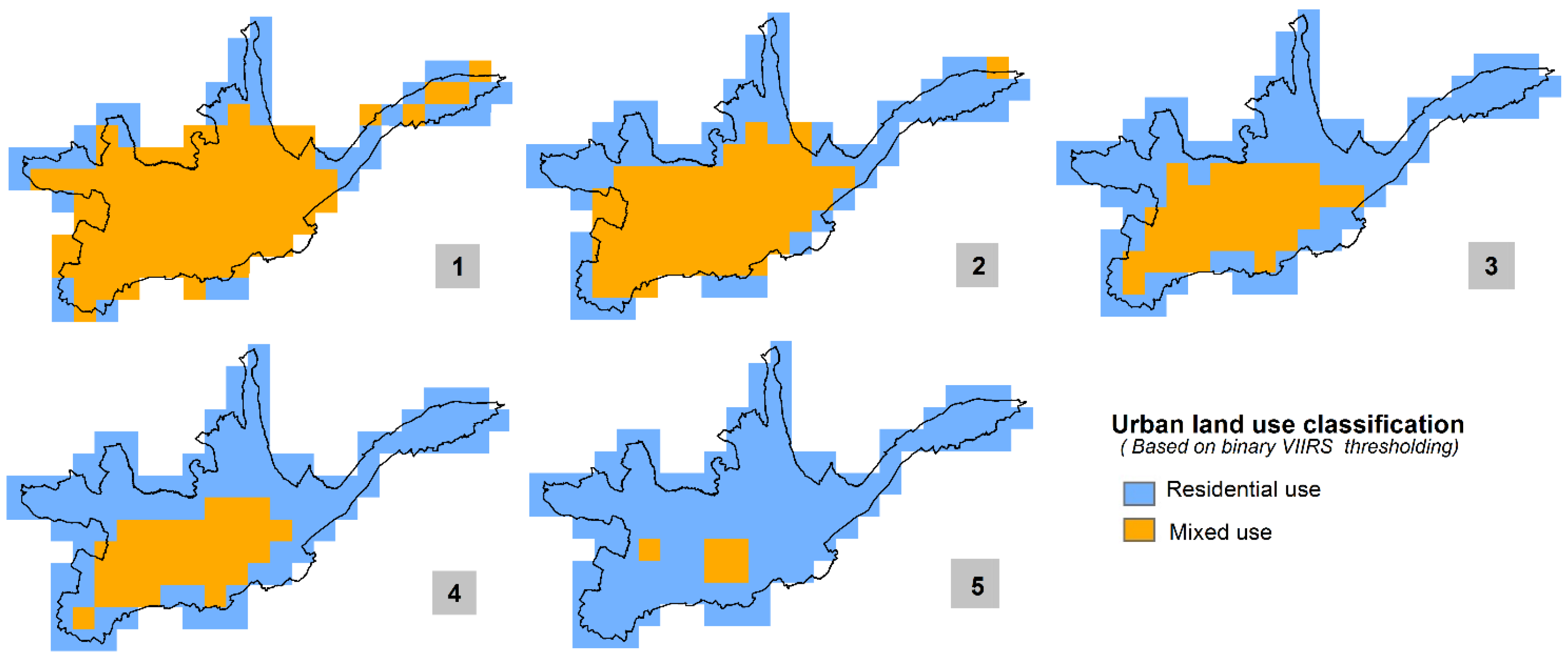
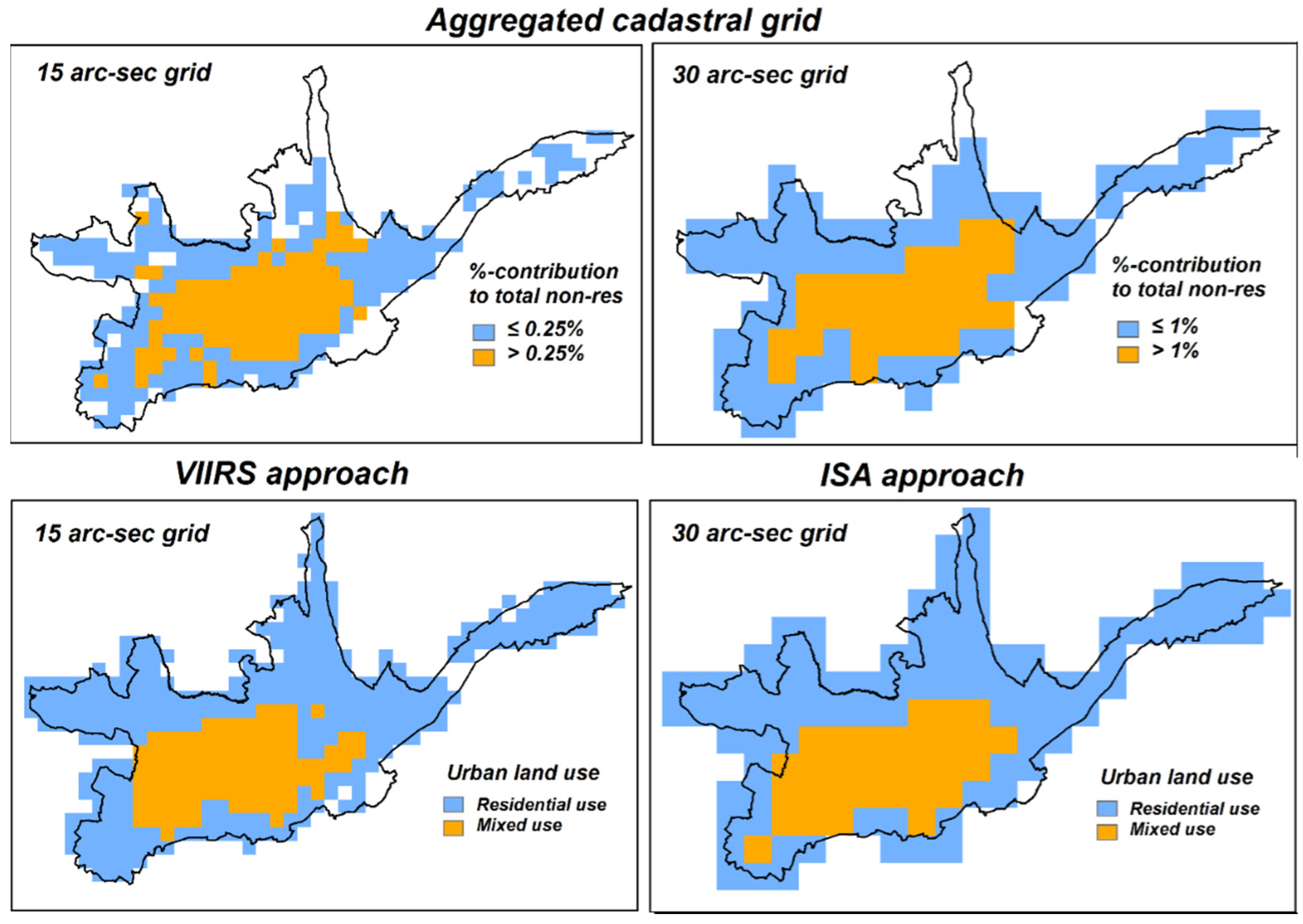
Figure 11 shows the binary classification of the aggregated cadastral data (top), both for the 15 arc-sec (left) and the 30 arc-sec (right) aggregate. The binary mask separates cells that contribute strongly to the total non-residential area from cells that only have a marginal share. This approach is congruent to the nightlights thresholding approach in a sense that it aims at separating high-intensity from low-intensity cells (referring to “non-residential” as observed parameter). The thresholds are determined in a way that, as for the nightlights data thresholding, the 75:25 residential-mixed occupancy type reference ratio split is matched best-possible. For the 15 arc-sec grid the threshold is identified at 0.25% (
i.e., cells that have a percent-contribution to the total non-residential area of less or equal than 0.25%), while for the 30 arc-sec grid the derived threshold value is 1%. Interestingly, the difference in fact exactly reflects the scale difference between the two datasets (
i.e., factor of 4). The binary 15 arc-sec classification results in a non-residential mask (in dark blue) that captures 88.3% of the total non-residential building area of Cuenca City on an area of 25.5 km
2, thus an average density of 14.9% per km
2 (compared to the 12.7%/km
2 average density in the VIIRS-derived 15 arc-sec binary mask). The 30 arc-sec mask on the other hand captures 86%.
Figure 11.
Binary classification of the non-residential cadastral built-up area aggregated to 15 arc-sec (top-left) and 30 arc-sec grids (top-right) based on the percent-contribution to the total non-residential area of Cuenca City. Best-matching binary classifications as derived from 15 arc-sec VIIRS (bottom-left) and 30 arc-sec ISA (bottom-right) data.
Figure 11.
Binary classification of the non-residential cadastral built-up area aggregated to 15 arc-sec (top-left) and 30 arc-sec grids (top-right) based on the percent-contribution to the total non-residential area of Cuenca City. Best-matching binary classifications as derived from 15 arc-sec VIIRS (bottom-left) and 30 arc-sec ISA (bottom-right) data.
For comparative purposes, the bottom two illustrations in
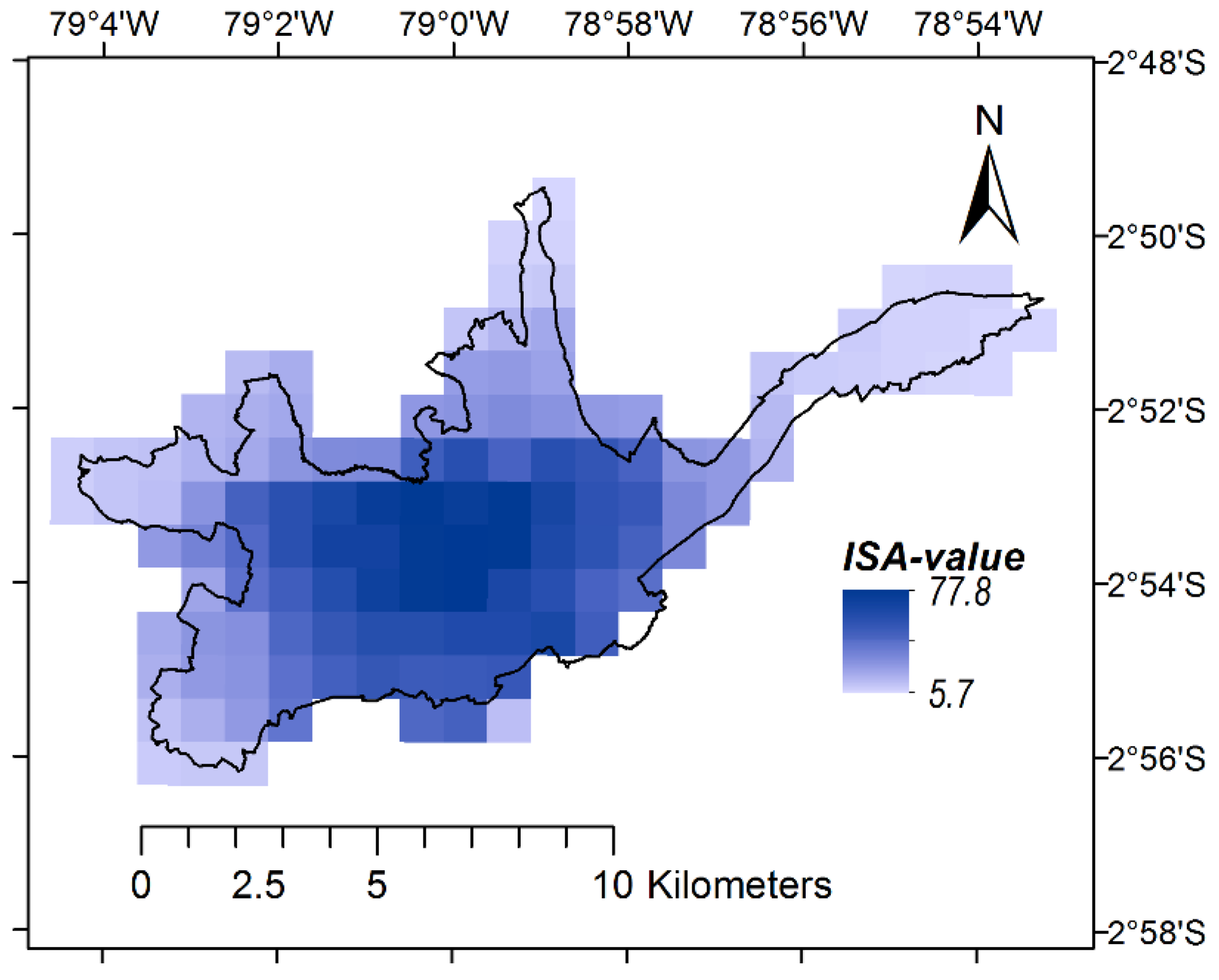
Figure 11 show the above-presented best-matching binary masks derived from the 15 arc-sec VIIRS and the 30 arc-sec ISA data. Visually evaluating spatial distribution and extent of the non-residential class in the two maps reveals interesting patterns. The VIIRS-derived mask covers the south-western corner of the corresponding cadaster-based non-residential mask well and misses out on the north-eastern corner whereas it is the other way around with the ISA-derived mask. VIIRS in that context seems not to detect above-average light intensities from the Cuenca City Airport (Aeropuerto Mariscal La Mar), whereas it is a major contributing factor in the ISA data. The latter could be explained with the inherent data configuration of ISA, which per se is more correlated with built-up area rather than pure light intensity.
5.3. Evaluating Model Sensitivity via Application of Different Spatial Urban Delineation
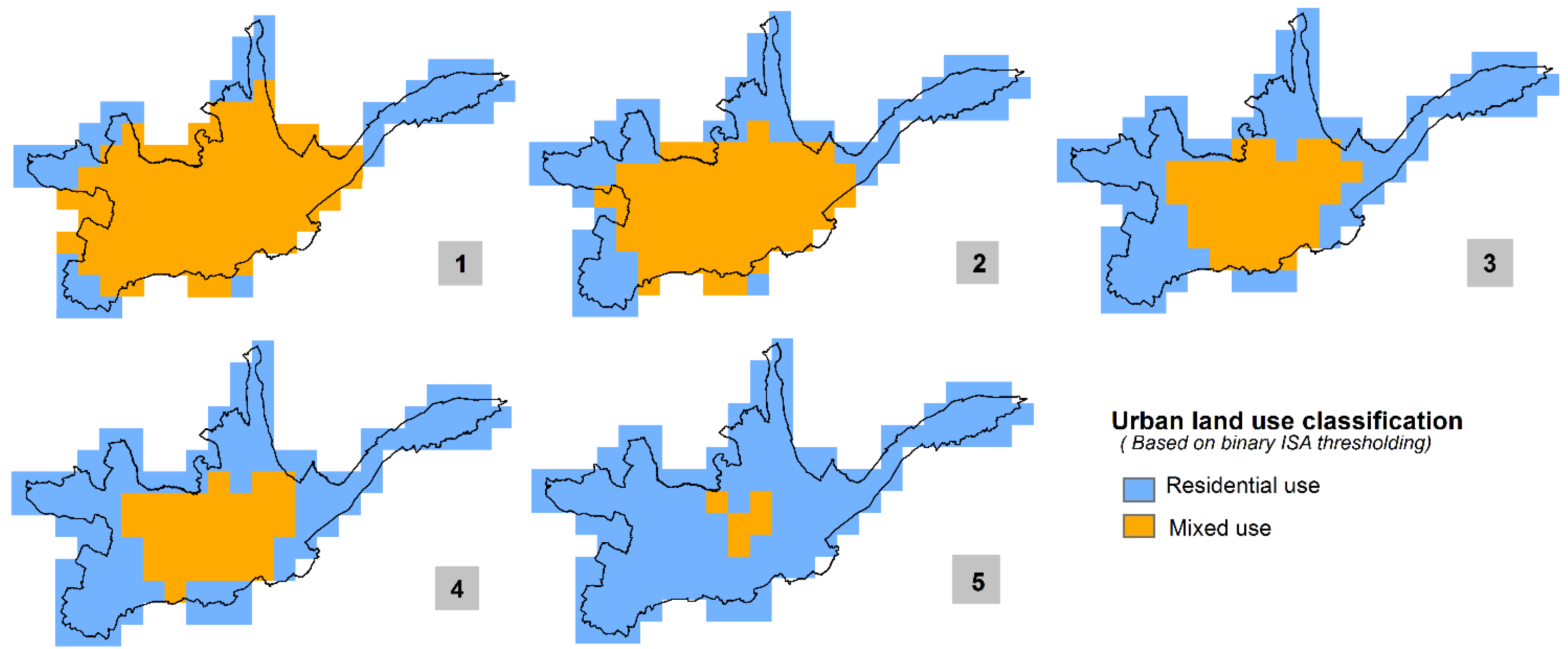
For further evaluation of the model sensitivity we re-run the implemented approach with a geospatially shrunk urban mask. While in the above-outlined implementations all the ISA and VIIRS grid cells were considered that fall within a pre-defined urban area of Cuenca City, now a more central part of the urban agglomeration is selected. Two tests are carried out in that context. For the first one, we keep the same built-up area occupancy type distributions (75% residential vs. 25% mixed use for VRIIS original resolution and 74% residential vs. 26% mixed use for the aggregated grid). In the second test, we keep the same threshold values identified above as the best match, respectively, for each dataset (50th percentile for the ISA data and 53rd percentile for the VIIRS data).
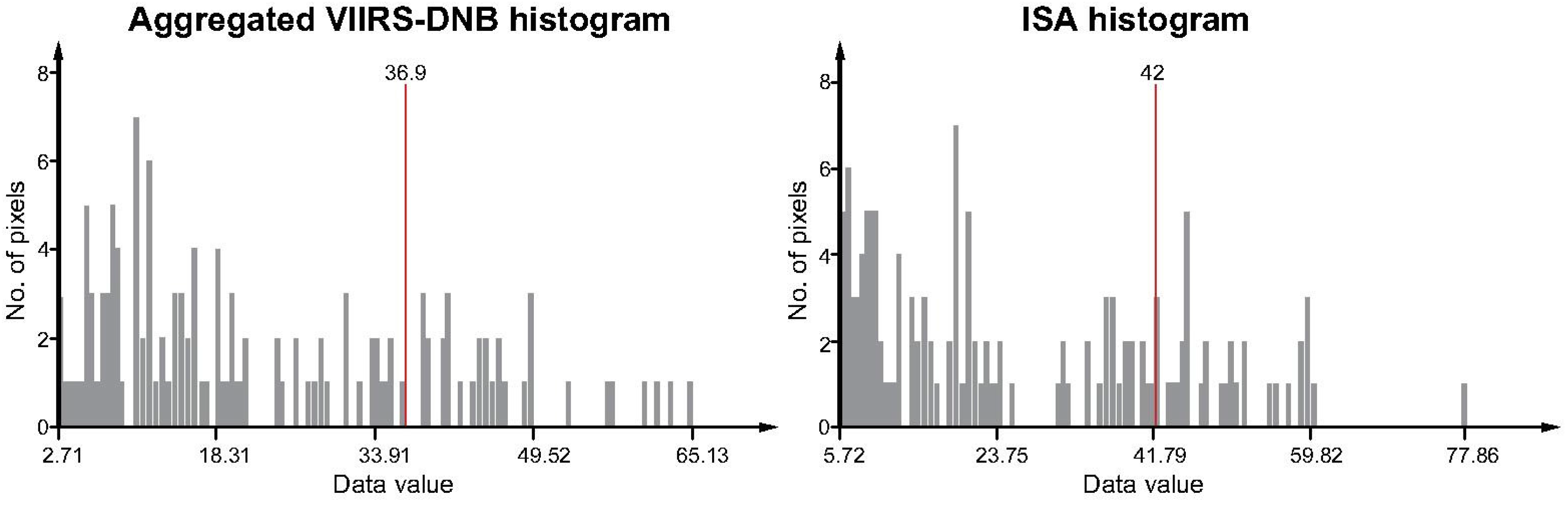
For the first test, the derived best-matching thresholds are now higher for both datasets. For the ISA data the 55th percentile and for the VIIRS-original and aggregated grids the 63rd and 65th percentile are identified respectively. This was expected as predominantly residential areas in the periphery of the city are now not included in the newly-defined urban mask and those cells (featuring lower ISA and light intensity values) are thus missing in the histograms. The threshold increment is higher for the VIIRS data application (roughly 10%–12%-increase) as compared to the ISA data application (5%-increase). This aspect can be associated with different sensitivity of the identified VIIRS and ISA thresholds due to varying histogram distributions (see
Figure 12). Given the purpose of the presented modeling, a more even histogram distribution could imply less sensitivity in the threshold determination.
Figure 12.
VIIRS-DNB (aggregated) and ISA histograms for the Cuenca city case study.
Figure 12.
VIIRS-DNB (aggregated) and ISA histograms for the Cuenca city case study.
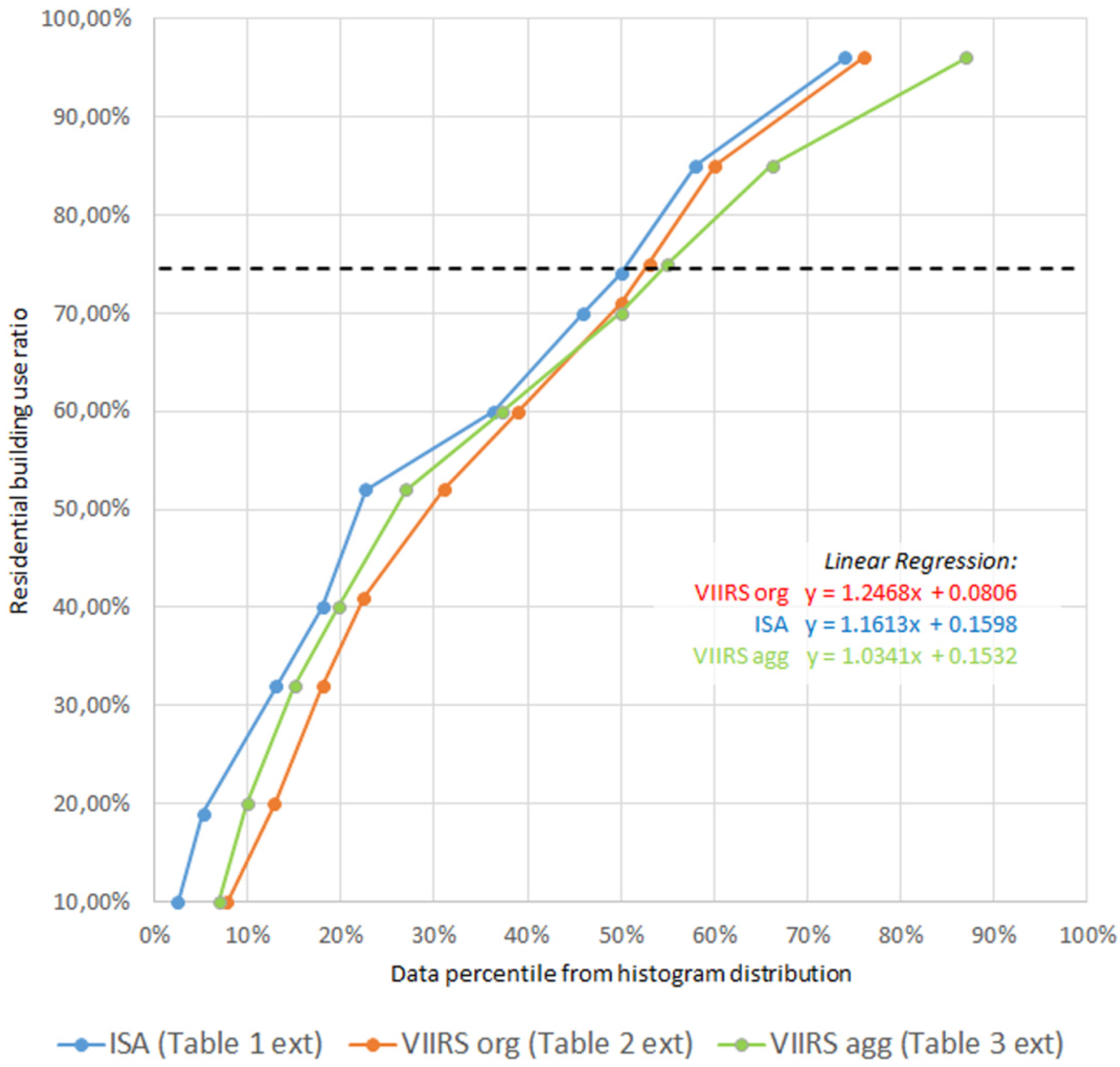
In fact, using the ISA composite, it only takes an increment of 24% (raising the threshold from 50% to 74%) to change the building occupancy type distribution ratio from 74:26 to 96:4. Regarding the aggregated DNB-VIIRS it would require a 35% increment (raising the threshold from 55% to 90%) to achieve the same theoretic change of the built-up area distribution. Small threshold shifts therefore have a bigger impact when using ISA as compared to VIIRS. To illustrate and emphasize this statistically, we use a sample of 10 value pairs each for ISA, original-resolution VIIRS, and aggregated VIIRS as compared to the cadastral building use distribution, and run a linear regression (see
Figure 13). Considering all the value pairs, in fact the original-resolution VIIRS data shows the steepest slope in the regression (1.2468) whereas the aggregated VIIRS data indeed show the flattest slope (1.0341) with ISA in between (1.1613). The aggregated VIIRS would thus be the least sensitive to threshold shifting in a sense that the building use distribution ratios would accordingly deviate less from the target value (see dashed line in
Figure 13). While steepest when considering all value pairs, the slope of the original VIIRS graph matches ISA almost identically around the relevant target value (dashed line). Threshold shifts in the nightlights products would therefore have a similar impact on the resulting building use distribution ratios.
Figure 13.
Plot of residential building use ratio
vs. data percentile from histogram distribution for ISA (extended data sample of
Table 1), original-resolution VIIRS (extended data sample of
Table 2), and aggregated VIIRS (extended data sample of
Table 3). The dashed line shows the residential building use ratio for Cuenca City (75%) as derived from cadastral data. Regression equations are colored according to the respective graphs.
Figure 13.
Plot of residential building use ratio
vs. data percentile from histogram distribution for ISA (extended data sample of
Table 1), original-resolution VIIRS (extended data sample of
Table 2), and aggregated VIIRS (extended data sample of
Table 3). The dashed line shows the residential building use ratio for Cuenca City (75%) as derived from cadastral data. Regression equations are colored according to the respective graphs.
In the second test using the best-matching thresholds identified with the initial urban mask (50th percentile for ISA and 53rd and 55th percentile respectively for VIIRS) the newly obtained built-up area occupancy type distribution for the ISA data now corresponds to a 50% residential and 50% mixed use share while for the VIIRS data the distribution now shows a pattern of 56% residential and 44% mixed use considering the original resolution and a 48:52 ratio taking in account the aggregated 30 arc-sec grid. These newly derived built-up area occupancy type distribution patterns are similar for both data sources (ISA and VIIRS) and clearly overestimate the share of mixed use area. This, again, was expected in the same way than the first test result inasmuch as in the selected central part of the urban area there are a decreased number of residential buildings as compared to the sub-urban periphery.
Both tests are correlated in a sense that they give indication on higher light intensity values being clustered in central core urban areas of Cuenca City whereas sub-urban areas feature dimmer lights (and consequently also lower ISA values) on average as a result of higher residential densities. This exercise basically highlights the importance of correct spatial pre-identification of the urban area for subsequent intra-urban analysis. If the urban mask is spatially over- or under-defined, the appropriate nightlights threshold values would de- or increase respectively.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







