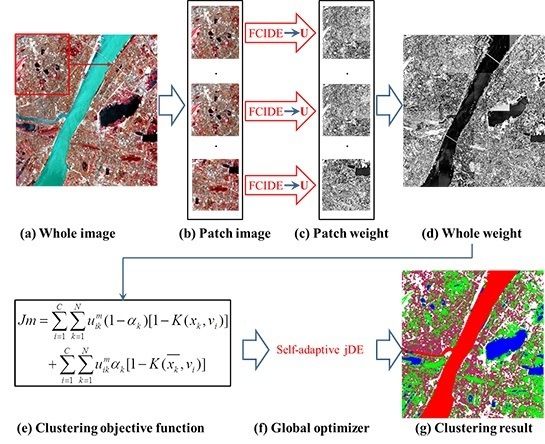
5.1. Discussion on Selection of Patch Size
The patch size has an impact on the performance of the proposed method L-SSC. Therefore, we discuss the selection of patch size visually and quantitatively based on the weight parameter image and clustering accuracy of different patch sizes.
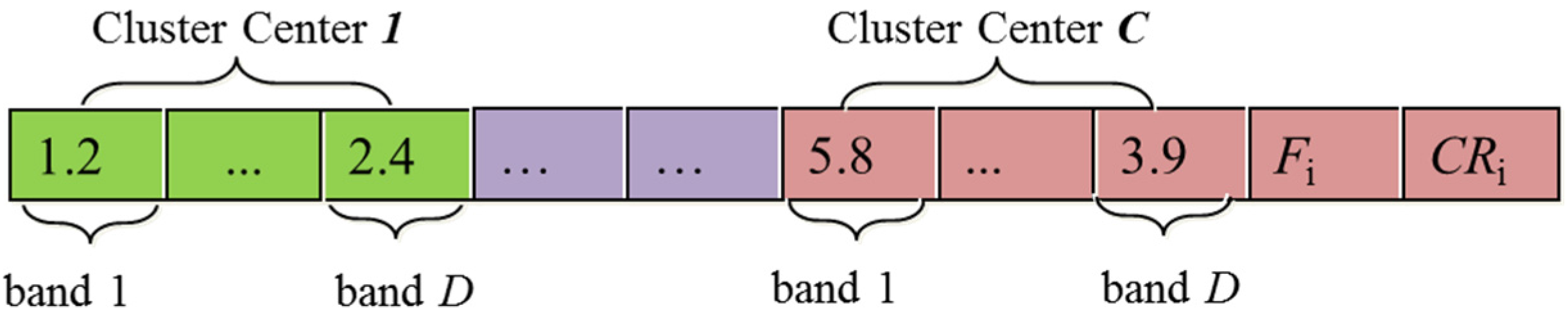
- (1)
Visual Comparison (Weight Parameter Image) of Different Patch Sizes
For Wuhan TM, Fancun Quickbird, and Indian Pine AVIRIS images,
Figure 11,
Figure 12 and
Figure 13 list the weight parameter images based on different patch sizes including 25 × 25, 50 × 50, 75 × 75, 100 × 100, 145 × 145, 150 × 150, 200 × 200, 300 × 300, and 400 × 400. In
Figure 11,
Figure 12 and
Figure 13, the darker the pixel is, the smaller the local weight parameter value is, and
vice versa. It should be noted that the patch size of 400 × 400 for Wuhan TM or Fancun Quickbird, and 145 × 145 for Indian Pine AVIRIS image is equal to the size of the corresponding whole image. Thus, the comparison between 400 × 400 for Wuhan TM or Fancun Quickbird and 145 × 145 for Indian Pine AVIRIS image with other patch sizes can be used to demonstrate the effectiveness of FCIDE-based local weight parameter determination method.
Figure 11.
The weight parameter image of the Wuhan TM image for different patch sizes (refer to the text for a detailed description of the markup).
Figure 11.
The weight parameter image of the Wuhan TM image for different patch sizes (refer to the text for a detailed description of the markup).
Figure 12.
The weight parameter image of the Fancun image for different patch sizes (refer to the text for a detailed description of the markup).
Figure 12.
The weight parameter image of the Fancun image for different patch sizes (refer to the text for a detailed description of the markup).
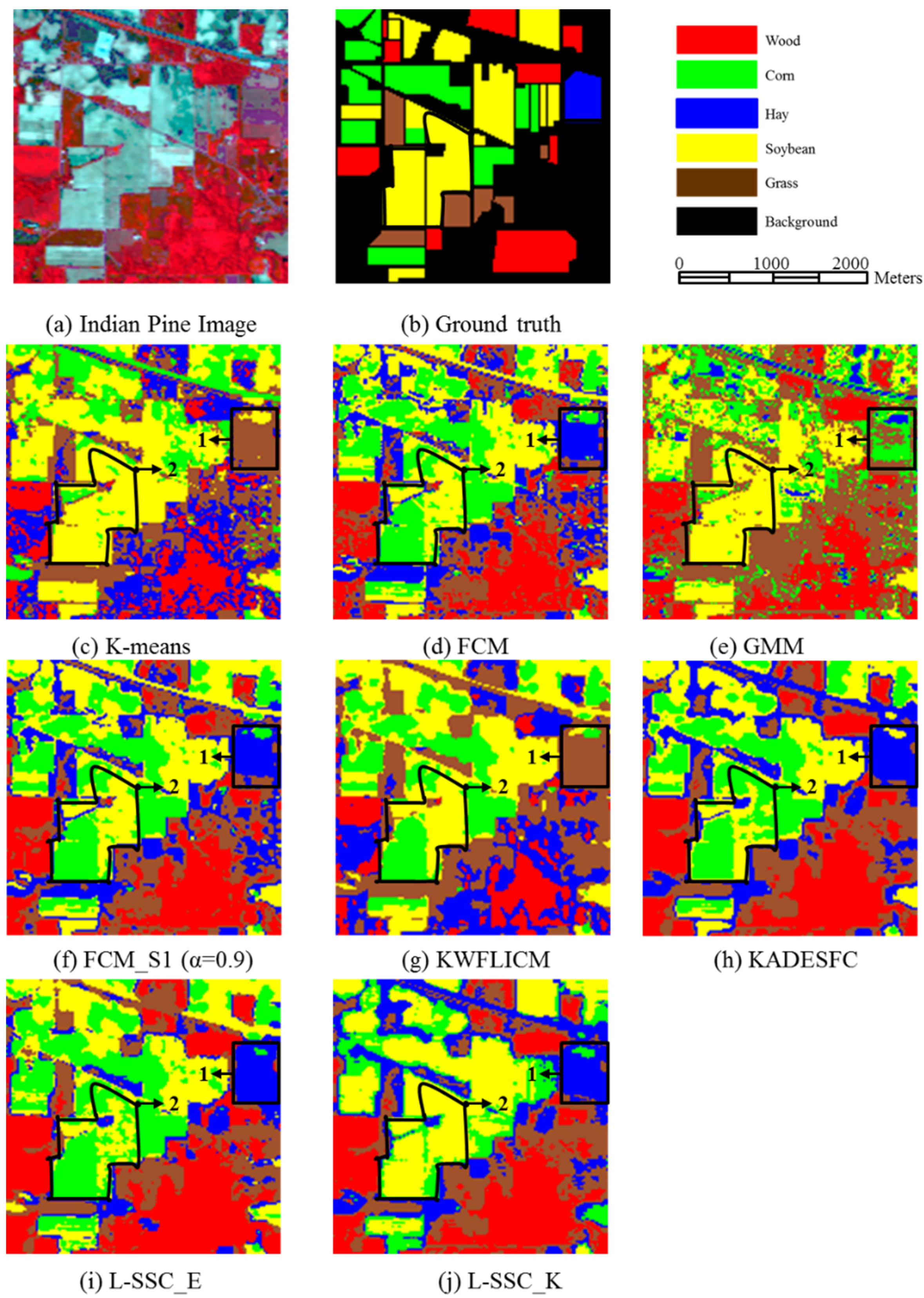
Figure 13.
The weight parameter image of the Indian Pine image for different patch sizes.
Figure 13.
The weight parameter image of the Indian Pine image for different patch sizes.
For the Wuhan TM image in
Figure 11, the pixels in the region (labelled red circle) belong to town, which has a variety of objects. However, when the patch size is 400 × 400, these pixels are assigned excessive weight parameter values, which can result in over-smoothing. That is, the complex distribution of objects in this region may be smoothed due to the excessive weight parameter value calculated by whole image. When the patch size is smaller than 200 × 200, the weight parameter value in these regions become small, which can prevent over-smoothing. We also can see that when the patch size is equal to 25 × 25, or 50 × 50 (labelled red rectangle), mosaic appearance will emerge, which are not in line with the real situation. Therefore, based on visual comparison of different patch sizes, the patch size (75 × 75–200 × 200) is much preferred for the Wuhan TM image. For the Fancun image in
Figure 12, when the patch size is 400 × 400, the building class (labelled red circle) is assigned an excessive weight parameter value, compared with the weight parameter calculated by a patch image with 100 × 100. Moreover, as for the road class (labelled red lines), the weight parameter value is relatively small (
i.e., dark) when patch size is equal to 100 × 100, compared with weight parameter calculated by the whole image (400 × 400), in which the weight parameter value of these pixels is excessive and unacceptable, resulting in the smoothing of the road class. Furthermore, like the Wuhan TM image, when the patch size is too small, a mosaic appearance (labelled red rectangle) will also emerge. For the Indian Pine AVIRIS image in
Figure 13, due to the fact the shapes of the different farmlands is regular (e.g., rectangle) and with small area, it weakens the impact of the mosaic.
- (2)
Quantitative Comparison (Clustering Accuracy) of Different Patch Sizes
Table 7,
Table 8 and
Table 9 show the clustering accuracy of L-SSC_E and L-SSC_K for different patch sizes, namely 25 × 25, 50 × 50, 75 × 75, 100 × 100, 145 × 145, 150 × 150, 200 × 200, 300 × 300 and 400 × 400.
Table 7.
The clustering accuracy of different patch sizes for the Wuhan TM image.
Table 7.
The clustering accuracy of different patch sizes for the Wuhan TM image.
| Patch Size | 25 × 25 | 50 × 50 | 75 × 75 | 100 × 100 | 150 × 150 | 200 × 200 | 300 × 300 | 400 × 400 |
|---|
| -- | L-SSC_E |
| OA (%) | 82.14 | 71.80 | 79.79 | 87.46 | 92.00 | 92.03 | 82.78 | 88.29 |
| Kappa | 0.7687 | 0.6407 | 0.7370 | 0.8399 | 0.8969 | 0.8971 | 0.7772 | 0.8483 |
| -- | L-SSC_K |
| OA (%) | 78.79 | 81.44 | 89.49 | 91.50 | 90.58 | 91.73 | 92.41 | 87.48 |
| Kappa | 0.7246 | 0.7587 | 0.8648 | 0.8901 | 0.8789 | 0.8926 | 0.9018 | 0.8379 |
Table 8.
The clustering accuracy of different patch sizes for the Fancun image.
Table 8.
The clustering accuracy of different patch sizes for the Fancun image.
| Patch Size | 25 × 25 | 50 × 50 | 75 × 75 | 100 × 100 | 150 × 150 | 200 × 200 | 300 × 300 | 400 × 400 |
|---|
| -- | L-SSC_E |
| OA (%) | 61.82 | 71.28 | 75.36 | 70.48 | 65.54 | 75.30 | 64.68 | 67.4 |
| Kappa | 0.5272 | 0.6371 | 0.6794 | 0.6307 | 0.5718 | 0.6843 | 0.5342 | 0.5922 |
| -- | L-SSC_K |
| OA (%) | 63.68 | 65.69 | 76.18 | 75.56 | 67.06 | 66.62 | 64.84 | 66.10 |
| Kappa | 0.5494 | 0.5735 | 0.6920 | 0.6820 | 0.5939 | 0.5810 | 0.5648 | 0.5835 |
Table 9.
The clustering accuracy of different patch sizes for the Indian Pine AVIRIS image.
Table 9.
The clustering accuracy of different patch sizes for the Indian Pine AVIRIS image.
| Patch Size | 25 × 25 | 50 × 50 | 75 × 75 | 100 × 100 | 150 × 150 |
|---|
| -- | L-SSC_E |
| OA (%) | 61.47 | 62.33 | 58.14 | 57.36 | 57.41 |
| Kappa | 0.4814 | 0.4969 | 0.4307 | 0.4332 | 0.4322 |
| -- | L-SSC_K |
| OA (%) | 61.02 | 64.49 | 60.37 | 60.29 | 63.63 |
| Kappa | 0.4828 | 0.5126 | 0.4567 | 0.4734 | 0.4985 |
In
Table 7, for the Wuhan TM image, it can be seen that L-SSC_E can acquire higher clustering accuracy when the patch size is 150 × 150–200 × 200, and L-SSC_K can perform better when the patch size is 75 × 75–300 × 300. In both above situations, they can achieve better clustering performance than the clustering result when the patch size is 400 × 400 (
i.e., the whole image), validating the effectiveness of local weight parameter. On the other hand, when the patch size is small (e.g., 25 × 25, 50 × 50), their clustering accuracy is not so satisfying. To some extent, this is consistent with the visual comparison in
Figure 11. Therefore, based on the visual and quantitative comparison, the optimal patch size for the Wuhan TM image can be 150 × 150–200 × 200. In
Table 8, for the Fancun Quickbird image, the same conclusion can be made that the optimal patch size for the Fancun Quickbird image can be 75 × 75–200 × 200. It should be specified that, in
Table 9, for the Indian Pine AVIRIS image, the optimal patch size is smaller (
i.e., 50 × 50) due to the fact the regular shape and small size of farm land in the region decreases the impact of the mosaic, which is also consistent with the conclusion made in the visual comparison of different patch sizes in
Figure 13.
Based on the visual and quantitative comparison of L-SSC for different patch sizes, it can be seen that L-SSC with the local weight parameter can achieve higher clustering accuracy than the method with the weight parameter calculated by the whole image (e.g., 400 × 400 for the Wuhan TM and Fancun Quickbird images, or 145 × 145 for the Indian Pine AVIRIS image). Especially, visual comparison shows that it can also preserve the detail of some classes, such as road and building. However, it is not so easy to select one optimal patch size for all remote sensing images due to the different characteristics of different images (e.g., the shape and size of objects). Firstly, when the patch is smaller, the more accurate local weight parameter can be acquired. However, more patch images mean that huge amounts of clustering results with different degrees of detail may emerge, resulting in the mosaic appearance (e.g., for Wuhan TM and Fancun Quickbird images). Therefore, in this situation, a middle-size (150 × 150–200 × 200) can be selected. Secondly, when the shape of the objects is regular (e.g., a rectangle for the Indian Pine AVIRIS image), the degree of detail of clustering results with different patch size is similar, weakening the impact of mosaic. Thus, for the Indian Pine AVIRIS image, a small patch size will be preferred (50 × 50).
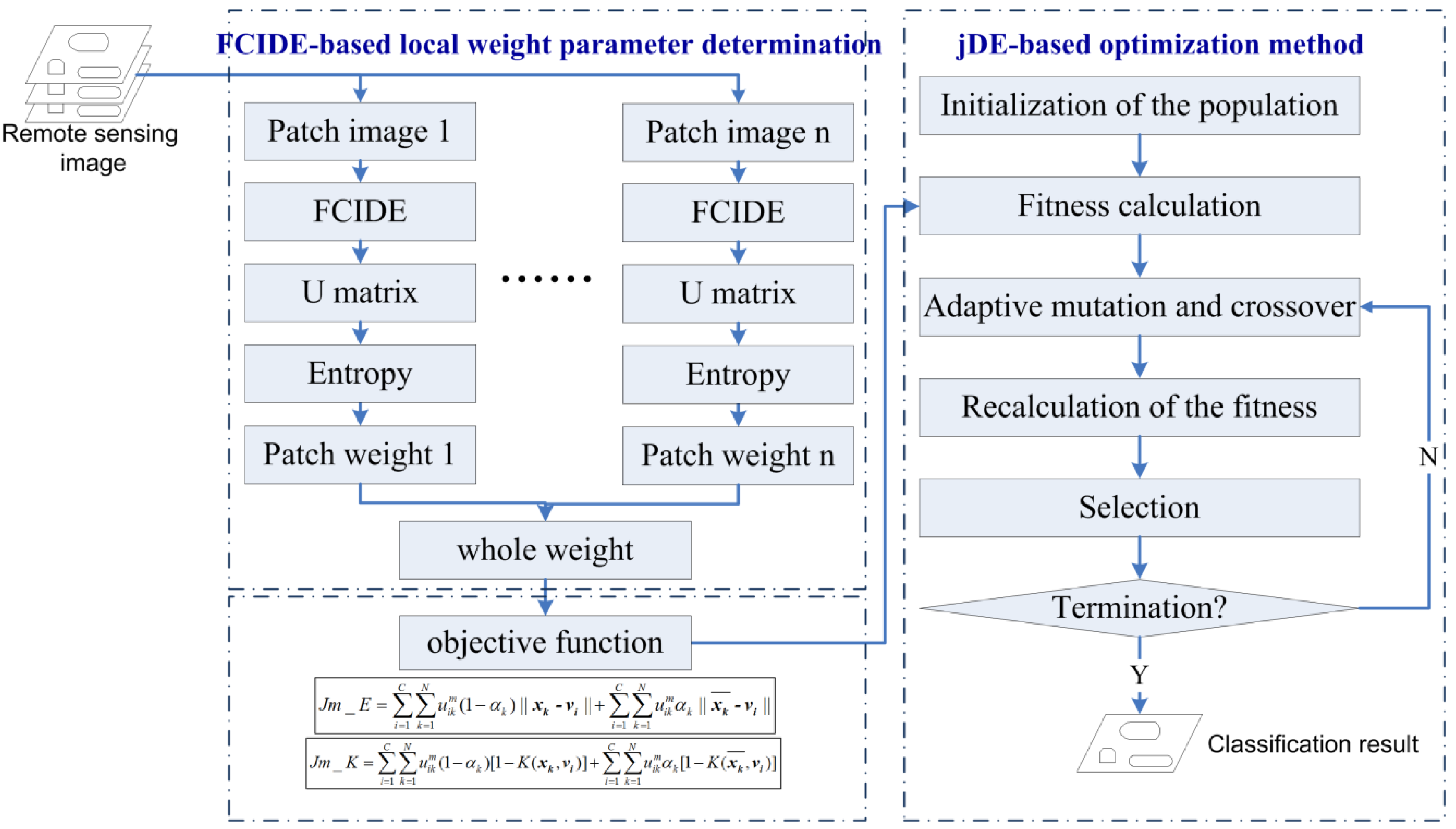
5.2. Computational Complexity Analysis
The computational complexity of L-SSC is analyzed, which includes the parts: the FCIDE-based local weight parameter determination method, and the jDE-based clustering method.
Part 1: FCIDE-based local weight parameter determination method:
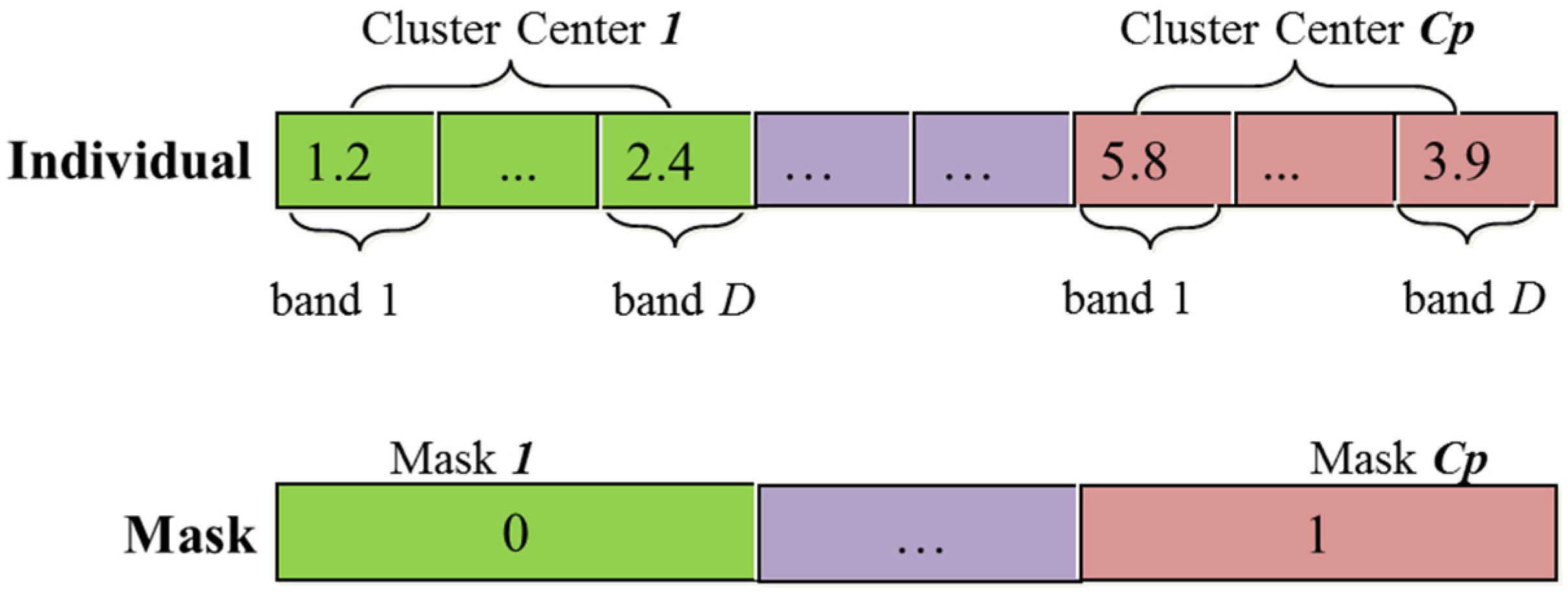
Initialization. The computational complexity of initialization is , where represents the number of individuals, is the maximum number of cluster numbers.
Fitness calculation. (a) Supposing there are pixels in each patch image, the computational complexity of this step is . (b) The time for updating the clusters is . Thus, the total time that is spent on fitness calculation is .
Mutation and crossover operation. In this step, the time consumed is .
Selection. The selection operation’s time is .
The computational complexity for the FCIDE-based local weight parameter determination method is , namely , where is the number of patch images, and is the maximum generation for the FCIDE-based local weight parameter determination method, is the number of pixels in the whole image.
Part 2: jDE-based clustering method:
Initialization. The time which this step needs is , where represents the number of individuals, is the number of cluster numbers.
Fitness calculation. (a) Supposing there are pixels in the whole image, the computational complexity of this step is . (b) The time for updating the clusters is . Thus, the total time that is spent on fitness calculation is .
Mutation and crossover operation. In this step, the time consumed is .
Selection. The selection operation’s time is .
The computational complexity for the jDE-based clustering method is , where is the maximum generation for the jDE-based clustering method.
Based on the above analysis, the computational complexity of L-SSC is
or
. The time consumed by each algorithm is shown in
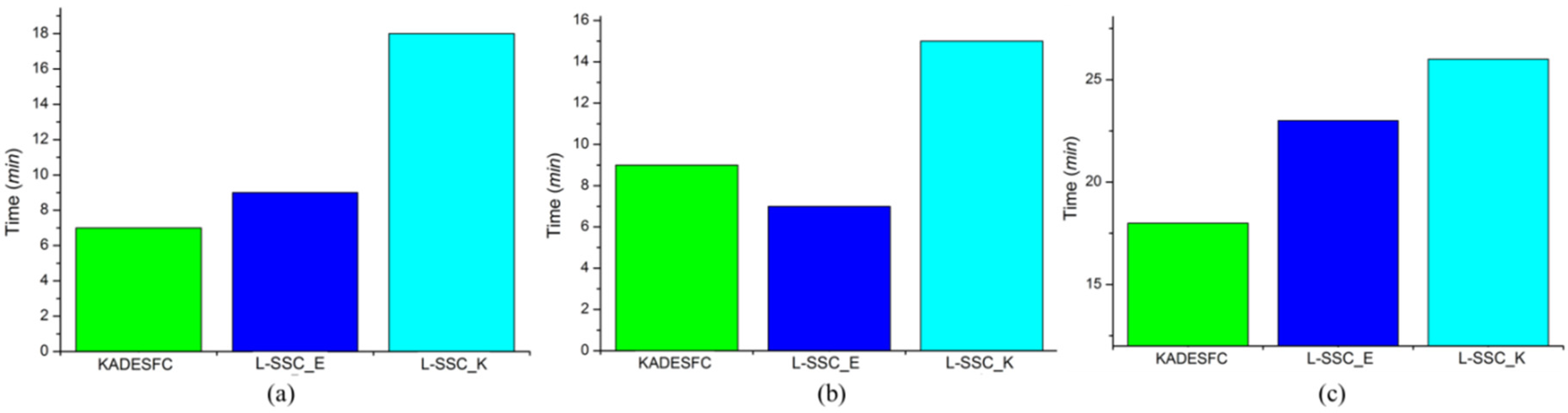
Figure 14. Although the computation cost of L-SSC is slightly more than KADESFC, it can be acceptable with regard to the clustering accuracy improvement.
Figure 14.
Comparison of computational time for (a) Wuhan TM; (b) Fancun IKONOS; and (c) Indian Pine AVIRIS.
Figure 14.
Comparison of computational time for (a) Wuhan TM; (b) Fancun IKONOS; and (c) Indian Pine AVIRIS.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





