
Detection of High-Density Crowds in Aerial Images Using Texture Classification



Abstract
:
1. Introduction
1.1. Background and Motivation
1.2. Related Work
1.3. Contribution
- We concentrate on the potentially most hazardous regions in VIC images—the high-density crowds. We show that crowded regions in aerial images can indeed be regarded as a texture, and propose robust patch-based Bag-of-Words methods for the detection of these regions.
- We run extensive tests on a database that contains a wide variety of aerial image patches. These patches are categorized into four classes where the continuous crowd-density function is partitioned into four ranges of decreasing crowd density.
- Through the evaluation and comparison, we demonstrate that Bag-of-Words features with appropriate chosen local features perform significantly better than conventional Gabor texture features on the task of aerial crowd detection.
2. Methodology
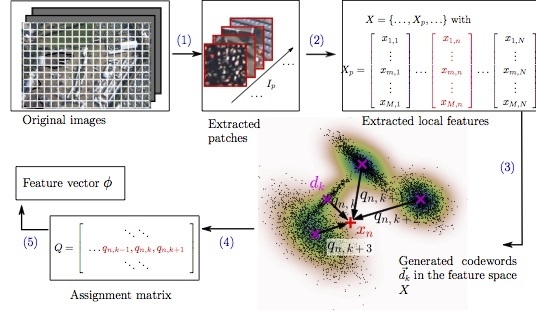
2.1. Crowd Features Using the Bag-of-Words Model
2.1.1. Local Feature Extraction
Local Binary Pattern (LBP)
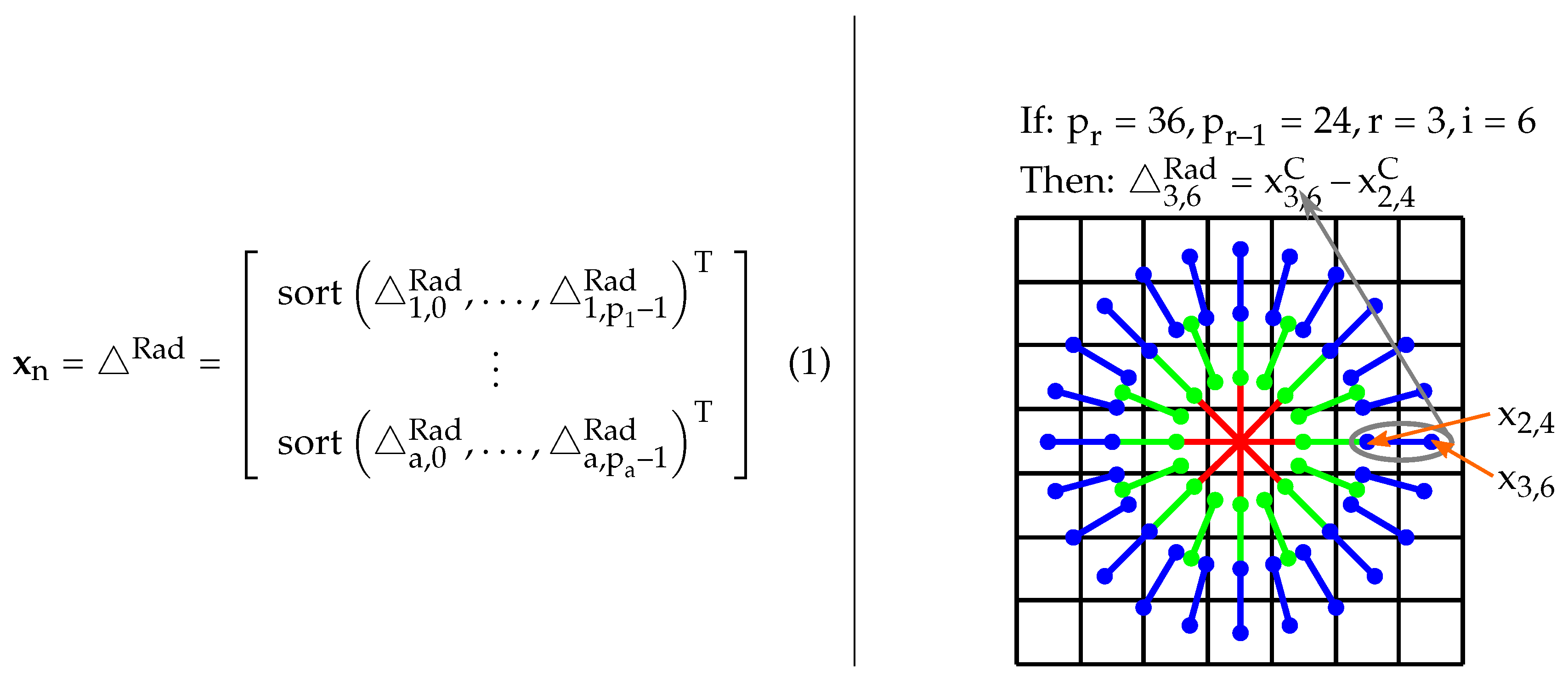
Sorted Random Projections (SRP)
2.1.2. Codeword Generation
2.1.3. Feature Encoding
2.1.4. Feature Pooling
2.2. Crowd Features Using a Gabor Filter Bank
3. Test Data and Tools
- class
- 1—dense crowd This class represents image patches which have at least covered 80% with a crowd density of two persons per square meter () or more. Individuals in these areas can only walk slowly to other locations or cannot move at all. Because of the large number of patches and the small object size of one person in these images, the manual estimation of the actual crowd density is difficult. We assume that a density of is reached as soon as the surface the persons are standing on is no longer visible.
- class
- 2—medium dense crowd In this class, the crowd density is between and . If the whole patch is covered homogeneously with such a density, it can be assumed that the surface is visible at several spots in one patch, which gives enough space for the persons to walk around. If the patch happens to be covered with a class 1 crowd up to 80% and devoid regions otherwise, it is also considered as a patch of this class 2. This special case happens at festival barriers which often appear in this data set, naturally (e.g., Figure 6, row 1, column 4).
- class
- 3—sparse crowd A crowd with a density between and is defined as a “sparse crowd”. Here, single persons are able to roam freely, although groups of persons might still appear frequently.
- class
- 4—no crowd In image patches of this class, there are hardly any persons visible. Buildings, tree canopies, streets, and vehicles are the dominant objects in this class. A randomly sampled subset of these patches is used in the test runs as negative samples.
4. Results
- One-vs.-All
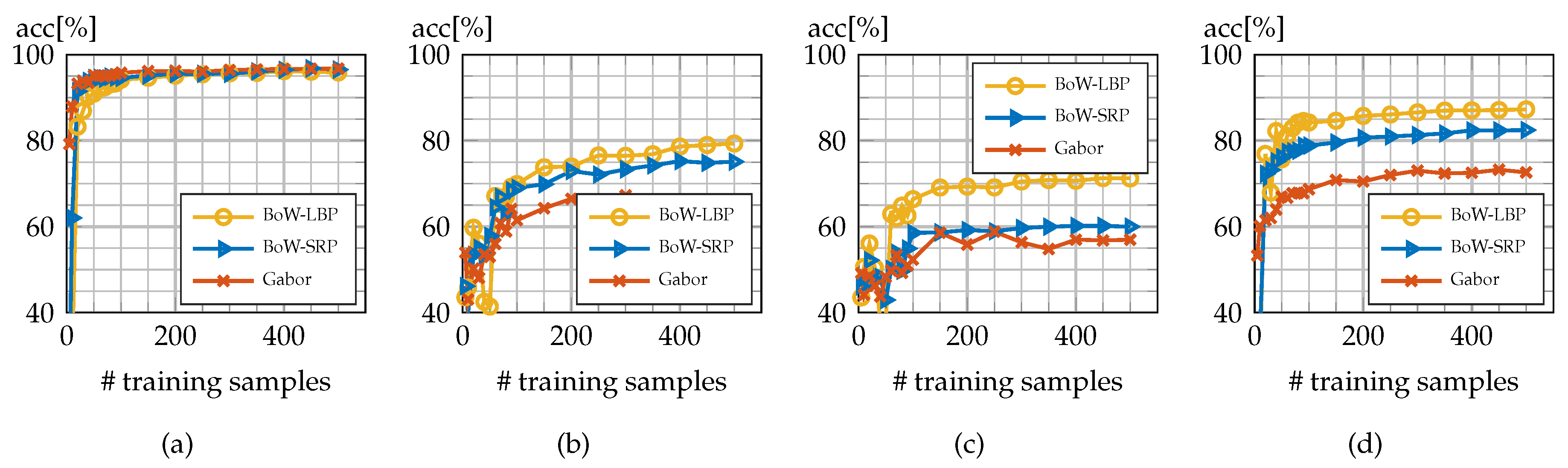
- This classification experiment tests the general ability of both Gabor and BoW classifiers to separate a class with a given crowd-density range from the other classes.
- One-vs.-One
- This experiment clearly shows the ability of the two approaches to distinguish between adjacent crowd classes with only small differences in crowd density.
- Multi-class
- Both BoW and Gabor classifiers are evaluated on all four available classes in a multi-class setup. This experiment is the desired use case for an operational “crowd detector”.
4.1. One-vs.-All Classification
4.2. One-vs.-One Classification
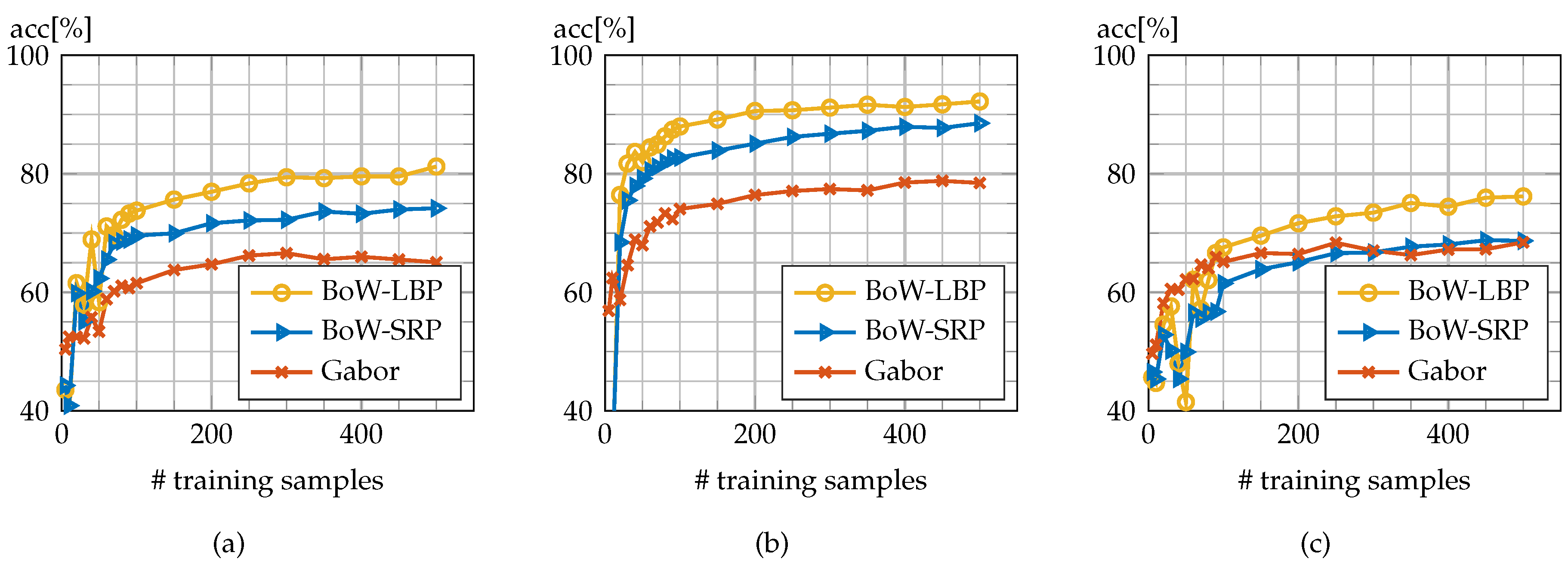
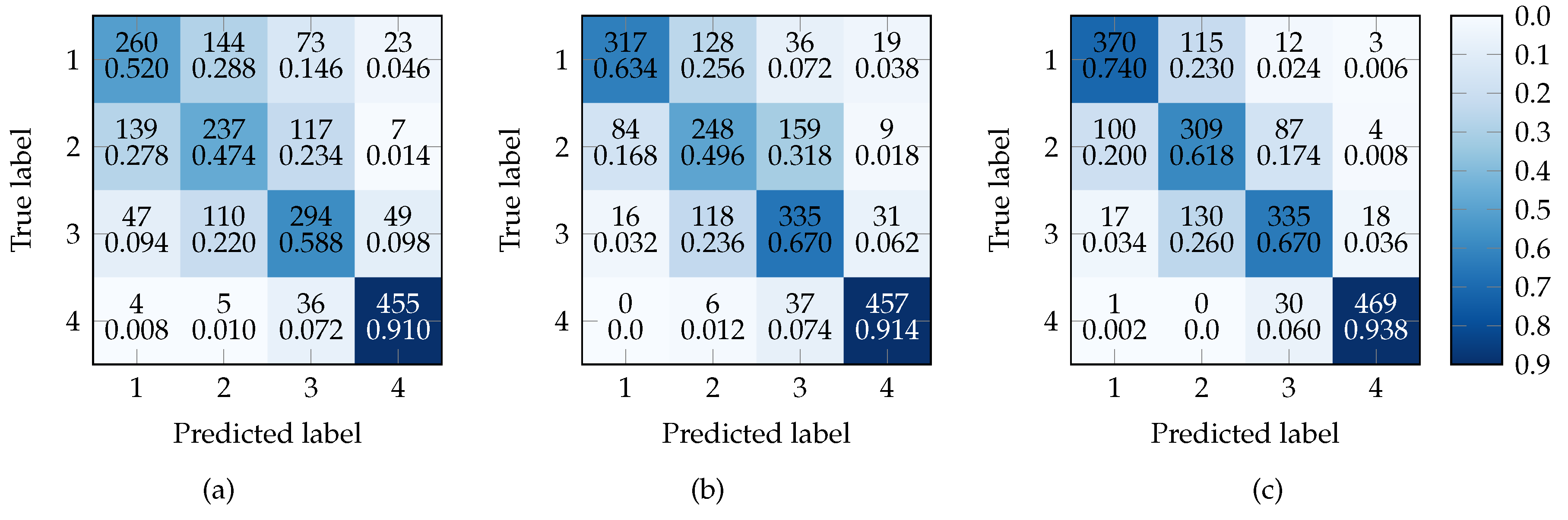
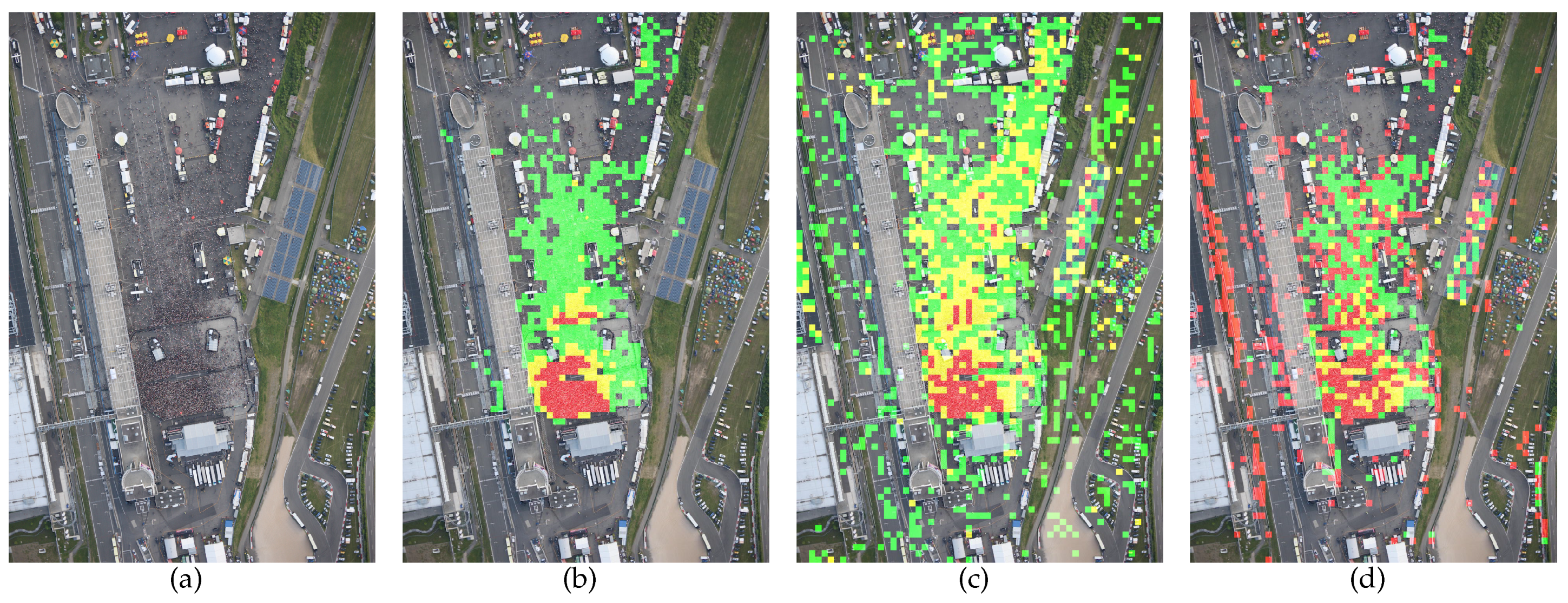
4.3. Multi-Class Classification
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ryan, D.; Denman, S.; Sridharan, S.; Fookes, C. An evaluation of crowd counting methods, features and regression models. Comput.Vis. Image Underst. 2015, 130, 1–17. [Google Scholar] [CrossRef]
- Jacques Junior, J.; Musse, S.; Jung, C. Crowd analysis using computer vision techniques. IEEE Signal Process. Mag. 2010, 27, 66–77. [Google Scholar] [CrossRef]
- Zhan, B.; Monekosso, D.; Remagnino, P.; Velastin, S.; Xu, L.Q. Crowd analysis: A survey. Mach.Vis. Appl. 2008, 19, 345–357. [Google Scholar] [CrossRef]
- Munder, S.; Gavrila, D.M. An experimental study on pedestrian classification. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1863–1868. [Google Scholar] [CrossRef] [PubMed]
- Idrees, H.; Soomro, K.; Shah, M. Detecting humans in dense crowds using locally-consistent scale prior and global occlusion reasoning. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1986–1998. [Google Scholar] [CrossRef] [PubMed]
- Lempitsky, V.; Zisserman, A. Learning to count objects in images. In Advances in Neural Information Processing Systems; Lafferty, J., Williams, C., Shawe-Taylor, J., Zemel, R., Culotta, A., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2010; Volume 23, pp. 1324–1332. [Google Scholar]
- Kong, D.; Gray, D.; Tao, H. A viewpoint tnvariant approach for crowd counting. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, 20–24 August 2006; Volume 3, pp. 1187–1190.
- Fagette, A.; Courty, N.; Racoceanu, D.; Dufour, J.Y. Unsupervised dense crowd detection by multiscale texture analysis. Pattern Recogn. Lett. 2014, 44, 126–133. [Google Scholar] [CrossRef]
- Ali, S.; Shah, M. Floor fields for tracking in high density crowd scenes. In Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008.
- Rodriguez, M.; Laptev, I.; Sivic, J.; Audibert, J.Y. Density-aware person detection and tracking in crowds. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2423–2430.
- Mehran, R.; Oyama, A.; Shah, M. Abnormal crowd behavior detection using social force model. In Proceedings of the 2009 Conference onComputer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 935–942.
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1975–1981.
- Herrmann, C.; Metzler, J. Density estimation in aerial images of large crowds for automatic people counting. Proc. SPIE 2013, 8713, 87130V. [Google Scholar]
- Perko, R.; Schnabel, T.; Fritz, G.; Almer, A.; Paletta, L. Airborne based high performance crowd monitoring for security applications. In Image Analysis; Springer: Berlin, Germany, 2013; pp. 664–674. [Google Scholar]
- Hinz, S. Density and motion estimation of people in crowded environments based on aerial image sequences. In Proceedings of ISPRS Hannover Workshop 2009: High-Resolution Earth Imaging for Geospatial Information, Hannover, Germany, 2–5 June 2009; Volume XXXVIII-1-4-7/W5.
- Sirmacek, B.; Reinartz, P. Feature analysis for detecting people from remotely sensed images. J. Appl. Remote Sens. 2013, 7, 073594. [Google Scholar] [CrossRef]
- Sirmacek, B.; Reinartz, P. Automatic crowd analysis from very high resolution satellite images. In Proceedings of the Photogrammetric Image Analysis Conference (PIA11), Munich, Germany, 5–7 October 2011; pp. 221–226.
- Meynberg, O.; Kuschk, G. Airborne crowd density estimation. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, II-3/W, 49–54. [Google Scholar] [CrossRef]
- Csurka, G.; Dance, C.R.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the 8th European Conference on Computer Vision, Workshop on Statistical Learning in Computer Vision, Prague, Czech Republic, 10–16 May 2004; pp. 1–22.
- Varma, M.; Zisserman, A. A statistical approach to texture classification from single images. Int. J. Comput. Vis. 2005, 62, 61–81. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. A sparse texture representation using local affine regions. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1265–1278. [Google Scholar] [CrossRef] [PubMed]
- Kannala, J.; Rahtu, E. BSIF: Binarized statistical image features. In Proceedings of the 2012 21st International Conference on Pattern Recognition (ICPR), Tsukuba, Japan, 11–15 November 2012; pp. 1363–1366.
- Nanni, L.; Brahnam, S.; Ghidoni, S.; Menegatti, E.; Barrier, T. Different approaches for extracting information from the co-occurrence matrix. PLoS ONE 2013, 8, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Cui, S.; Schwarz, G.; Datcu, M. Remote sensing image classification: No features, no clustering. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 5158–5170. [Google Scholar]
- Hu, J.; Xia, G.S.; Hu, F.; Zhang, L. A comparative study of sampling analysis in the scene classification of optical high-spatial resolution remote sensing imagery. Remote Sens. 2015, 7, 14988. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Liu, L.; Fieguth, P.; Clausi, D.; Kuang, G. Sorted random projections for robust rotation-invariant texture classification. Pattern Recognit. 2012, 45, 2405–2418. [Google Scholar] [CrossRef]
- Guo, Y.; Zhao, G.; Pietikainen, M. Texture classification using a linear cConfiguration model based descriptor. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; pp. 119.1–119.10. Available online: http://dx.doi.org/10.5244/C.25.119 (accessed on 1 June 2016).
- Guo, Y.; Zhao, G.; Pietiken, M. Discriminative features for texture description. Pattern Recognit. 2012, 45, 3834–3843. [Google Scholar] [CrossRef]
- Perronnin, F.; Sánchez, J.; Mensink, T. Improving the Fisher kernel for large-scale image classification. In Computer Vision ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin, Germany, 2010; Volume 6314, pp. 143–156. [Google Scholar]
- Manjunath, B.S.; Ma, W.Y. Texture features for browsing and retrieval of image data. Pattern Anal. Mach. Intell. IEEE Trans. 1996, 18, 837–842. [Google Scholar] [CrossRef]
- Kurz, F.; Türmer, S.; Meynberg, O.; Rosenbaum, D.; Runge, H.; Reinartz, P.; Leitloff, J. Low-cost optical Camera Systems for real-time Mapping Applications. PFG Photogramm. Fernerkund. Geoinform. 2012, 2012, 159–176. [Google Scholar] [CrossRef]
- Vedaldi, A.; Fulkerson, B. VLFeat: An Open and Portable Library of Computer Vision Algorithms. 2008. Available online: http://www.vlfeat.org/ (accessed on 1 June 2016).
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27:1–27:27. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvm (accessed on 1 June 2016). [Google Scholar] [CrossRef]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J.Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cl-1 | Cl-2 | Cl-3 | Cl-4 | Cl-1 | Cl-2 | Cl-3 | Cl-4 | Cl-1 | Cl-2 | Cl-3 | Cl-4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | 0.578 | 0.478 | 0.565 | 0.852 | 0.760 | 0.496 | 0.591 | 0.886 | 0.758 | 0.558 | 0.722 | 0.949 |
| Recall | 0.520 | 0.474 | 0.588 | 0.91 | 0.634 | 0.496 | 0.670 | 0.914 | 0.740 | 0.618 | 0.670 | 0.938 |
| Score | 0.547 | 0.476 | 0.576 | 0.88 | 0.691 | 0.496 | 0.628 | 0.900 | 0.749 | 0.586 | 0.695 | 0.944 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meynberg, O.; Cui, S.; Reinartz, P. Detection of High-Density Crowds in Aerial Images Using Texture Classification. Remote Sens. 2016, 8, 470. https://doi.org/10.3390/rs8060470
Meynberg O, Cui S, Reinartz P. Detection of High-Density Crowds in Aerial Images Using Texture Classification. Remote Sensing. 2016; 8(6):470. https://doi.org/10.3390/rs8060470
Chicago/Turabian StyleMeynberg, Oliver, Shiyong Cui, and Peter Reinartz. 2016. "Detection of High-Density Crowds in Aerial Images Using Texture Classification" Remote Sensing 8, no. 6: 470. https://doi.org/10.3390/rs8060470
APA StyleMeynberg, O., Cui, S., & Reinartz, P. (2016). Detection of High-Density Crowds in Aerial Images Using Texture Classification. Remote Sensing, 8(6), 470. https://doi.org/10.3390/rs8060470