1. Introduction
Land cover information about the Earth’s surface features in terms of their quantity, diversity, and spatial distribution has been identified as one of the crucial data components for many aspects of global change studies and environmental applications [
1,
2]. In the recent decade, with the great availability of high spatial resolution (HR) satellite remote sensing images, land cover mapping (LCM) at fine scales has increasingly attracted more attention [
3,
4,
5]. In particular, many studies have focused mainly on LCM in some complex landscapes, such as urban [
3,
6,
7], agricultural [
8,
9,
10,
11], surface-mined [
12,
13,
14,
15], Mediterranean [
4,
16,
17,
18], coastal [
19], and tropical landscapes [
20]. In the past 30 years, surface mining has greatly increased around the world [
21]. It is noted that surface mining and subsequent reclamation are the dominant drivers of land cover change in many mine areas, resulting in deforestation, damage to ecosystems and natural landscapes, and threats to human health [
12,
21,
22,
23]. Moreover, the intensification and extensification of agricultural production have caused biodiversity loss and damage to ecosystem functions and the global environment [
10,
24]. Since 2007, one project in particular has been conducted by the China Geological Survey to employ only the visual interpretation method to determine the mineral geo-environment of important deposit-intensive areas across China. However, there is currently no research on complex surface-mined and agricultural landscapes (CSMAL). There is no doubt that LCM in those mixed complex landscapes using HR images is indispensable for mine planning and management, and sustainable and efficient rural development.
However, in complex landscapes where various landscape elements of varying size, shape complexity, connectivity, and fragmentation are concentrated and interacted [
8,
25,
26], LCM at fine scales is challenging [
5,
17]. Aside from the above-mentioned characteristics, there are some special elements and characteristics in CSMAL. First, some special landscape elements resulting from surface mining processes exist, such as working faces (open/closed), mining buildings, transit sites (ore heap, mineral processing land), solid wastes (dumping sites, waste rock piles, tailing ponds, coal gangue heaps), and disturbed vegetation. Moreover, the complex surface-mined landscape areas are generally characterized by heterogeneous terrain due to human disturbance and reclamation, and have some spectrally similar (natural and reclaimed vegetation) or hardly differentiable objects (manmade structures, haul roads, and active quarries) [
12]. In addition, the complex agricultural landscapes involve crop fields of different phenological stages [
8,
10] which may be confused with other types of land covers (fallow land and exposed soil). Particularly, in CSMAL, there are some spectrally similar land covers between the two landscapes (fallow land, dumping site, and working face). In general, all these factors significantly increase the difficulty of LCM, especially with HR images.
In the past six years, numerous studies focusing on LCM in complex surface-mined landscapes [
12,
13,
14,
15] and complex agricultural landscapes [
8,
9,
10,
11] were conducted using HR images, and the following conclusions were drawn.
First, integrating HR images and topographic data is indispensable. However, the topographic data employed in the above-mentioned studies could be divided into two categories. One category is derived from airborne light detection and ranging (LiDAR) data [
13,
14,
15], with the disadvantage of being costly to obtain, and errors in mapping can result from the nonregistration of multitemporal data. The other [
9] category comprises Shuttle Radar Topography Mission digital elevation models (DEM) and Advanced Spaceborne Thermal Emission and Reflection Radiometer (ASTER) global DEM (GDEM), with coarse spatial resolution, and the earlier generation time results in the inability to meet the mapping requirements because land covers change greatly in time and space in surface-mined landscapes. As a result, several new stereo and HR satellite remote sensing sensors, such as the successfully launched ZiYuan-3 (ZY-3) and TianHui-1/2/3, were developed to provide both HR multispectral (MS) bands and topographic data simultaneously. These new tools are expected to reduce the limitations of topographic data, but have not been examined for LCM in complex landscapes.
Second, features such as texture measures [
9,
10,
12], filter features [
12], and topographic variables [
9,
13,
14,
15] and feature reduction methods [
11,
12] that help to improve classification accuracy should be used. Effective features were sometimes more important than classifiers, especially when combining HR data and MLAs [
27]. As a result, although the previous studies have used some effective features, more useful spectral features from optical images and topographic variables from stereo satellite sensors should be used and may be helpful. On the other hand, Fassnacht
et al. [
28] suggested that the wrapper feature selection (FS) methods often achieved higher performance than filter FS methods (for example, the FS method that was used in the study of Maxwell
et al. [
12] to map complex surface-mined landscapes) and might provide more information (such as the importance of features) than feature extraction methods (for example, minimum noise fraction transformation that was used for complex agricultural landscape of Piiroinen
et al. [
11]). Therefore, the wrapper FS methods may be positive for LCM in complex landscapes and should be investigated.
Third, comparison of machine learning algorithms (MLAs) that might show some interesting results should be performed. With respect to MLAs, random forest (RF) [
12,
14,
15], support vector machine (SVM) [
8,
9,
11,
12,
14,
15], boosted classification and regression trees (CART) [
14,
15], and k-nearest neighbor (KNN) [
14] algorithms have been used for those two complex landscapes, and some of them were compared only in complex surface-mined landscapes. For example, Maxwell
et al. [
12] compared RF and SVM. Maxwell
et al. [
15] assessed three MLAs, RF, SVM, and CART. Maxwell and Warner [
14] utilized all four algorithms. However, comparison of the three classical MLAs (RF, SVM, and artificial neural network, ANN) has not been examined.
Fourth, object-based image analysis (OBIA) and pixel-based image analysis (PBIA) are optional. Most of the aforementioned studies investigated either PBIA [
11,
12,
15] or OBIA [
9,
10,
13,
14], and only a few compared them [
8]. For LCM in complex surface-mined landscapes, studies [
12,
13,
14,
15] first attempted PBIA, and then further examined OBIA. Actually, the OBIA method may not achieve statistically significantly higher classification accuracies than PBIA [
8,
29]. Moreover, compared to PBIA, OBIA is more complex and involves heavy workloads which should consider the selections of input features for segmentation, segmentation methods, segmentation parameters, and calculation of object features. Considering the enormous workloads involved in comparing several feature sets and MLAs in this study, PBIA was first applied to obtain some pixel level findings. More complex OBIA, as well as the comparison of the two methods, will be conducted in the future.
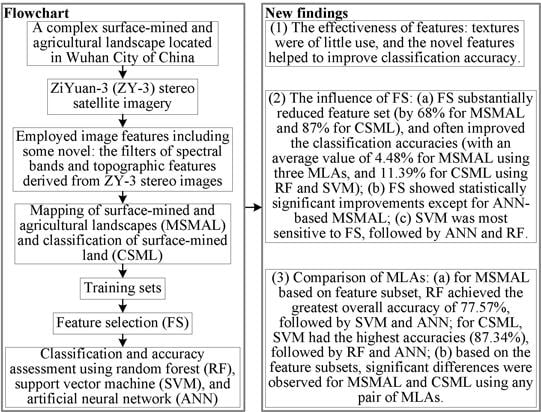
Based on the background described above, an area characterized by CSMAL, located in central China’s Wuhan City, was selected as the study area. A procedure combining a set of features derived from ZY-3 stereo imagery, a wrapper FS method, and three MLAs (RF, SVM, and ANN) was proposed and examined. This study focused on the following tasks: mapping of the surface-mined and agricultural landscapes (MSMAL),
i.e., the entire study area, and classification of the surface-mined land (CSML). Four bands of ZY-3 fused imagery, the normalized difference vegetation index (NDVI) layer, principal component (PC) bands, filter features, texture measures, and topographic variables were generated. The wrapper FS method was applied to select feature subsets for subsequent classifications. The classification accuracies of MLAs were assessed and compared using all features and feature subsets, respectively. Moreover, the McNemar test was performed to examine the influences of FS and MLAs. The detailed objectives of this study were:
Assessing the effectiveness of the employed features. The focus was on the following: determining whether the employed features, especially the newly introduced mean and standard deviation (StDev) filters of ZY-3 spectral bands and topographic features derived from ZY-3 stereo images, are effective for classification, and which features have higher importance; whether the NDVI layer and PC bands have higher importance than spectral bands, and whether it is possible to use them separately or jointly to substitute four spectral bands for the classification tasks in this study; and for Gaussian low-pass and mean filters derived from four spectral bands with different kernel sizes, which ones result in higher importance.
Investigating the influence of the FS method as to how it influences the feature set and classification accuracy; whether it results in statistically significant accuracy improvements; for three MLAs, whether there are different sensitivities to FS and which one is more sensitive; and whether the land covers show different sensitivities to FS.
Comparing different MLAs. The aim was to examine which algorithms achieve higher performance and whether there are statistically significant differences among the three MLAs.
3. Methods
First, ZY-3 satellite data were processed, and then a set of features was employed. In accordance with the field survey, two-level land cover schemes were developed. Training sets for MSMAL and CSML were obtained based on referenced training data polygons using stratified random sampling. Subsequently, the FS method was implemented to pick out the feature subsets for MSMAL and CSML. Finally, all feature- and feature subsets-based classification models using RF, SVM, and ANN algorithms were developed, and classification accuracies were assessed. A flowchart of the process is presented in
Figure 2, and details are given in the following sections.
3.1. ZY-3 Data Processing
The 3.6 m resolution front and backward looking panchromatic (PAN) data were used to extract relative digital terrain models (DTM) data with 10 m resolution using ENVI 5.0 software. The DTM was generated and used considering the following two factors: first, the height values of the ground control points in the surface-mined land changed by mining were difficult to obtain; second, it is possible for it to be only used to develop the topographic features for distinguishing land covers with heterogeneous terrain in the study area.
The 2.1 m resolution nadir-looking PAN and 5.8 m resolution nadir-looking MS images were orthorectified using a rational polynomial coefficient model and the 10 m resolution DTM. The MS image was then registered to the PAN image using a 2nd order polynomial transformation and 32 ground control points that were collected uniformly in the study area, with a root mean square error of 0.3 pixels (less than 0.5 pixels). According to our previous research, the Gram–Schmidt spectral sharpening (GS) method can achieve the best fusion performance for the mapping of surface-mined landscapes [
33]. As a result, the PAN–MS image fusion for the ZY-3 satellite was achieved using the GS method. The quality of employed ZY-3 imagery was good with free clouds, and the reflectance was not adopted in the present study; the atmosphere correction thus was not conducted.
3.2. Employed Features Derived from ZY-3 Image
A total of six types of image features with different significance were employed in this study. To sum up, 106 features were available, and are listed in
Table 2.
3.3. Developing LCM Schemes
Taking into consideration existing LCM systems (national standard of China: GB/T21010-2007) and field surveys, an LCM scheme consisting of seven first-level classes was developed, namely, cropland, forestland, water, road, urban and rural residential land, bare land, and surface-mined land. Owing to CSMAL, the intra-class spectral differences increased, which might reduce the classification accuracy. For example, cropland in the study area consists of traditional cropland such as dry land with corn, vegetable and fruit greenhouse, and fallow land, which have large spectral differences. The greenhouse in the study area is a special element of the agricultural landscape, and it may be confused with other land covers with high surface albedo. As a result, in order to obtain the first-level LCM results, more detailed land cover classes representing the second-level scheme were built up. Detailed descriptions relating to the two schemes in this study are shown in
Table 3.
This study focused on just two tasks: MSMAL,
i.e., the first-level LCM of the entire study area, and CSML,
i.e., the second-level LCM of the surface-mined land. For MSMAL, the detailed land cover classes were only used for the subsequent processes such as training set acquisition, FS, parameter optimization of classifiers, and classification model building and prediction (for details, see
Section 3.4,
Section 3.5 and
Section 3.6). Then, the classification results were grouped into seven first-level land classes. The accuracy assessments were based on the first-level land cover scheme. For MSMAL, misclassifications among the subclasses of each first-level class were not considered. For CSML, misclassifications between surface-mined land covers and other land covers were not involved. The fine classification of second-level land cover scheme will be investigated in the future.
3.4. Obtaining Training Data
All the referenced land cover data selected as training data polygons were obtained by visual interpretation of ZY-3 satellite imagery and extensive field investigation. The surface-mined land was completely delineated. Other land cover classes were collected randomly and uniformly in the study area. For MSMAL, a stratified random sampling of equal amounts was performed on the training polygons and resulted in a training set with 2000 training samples (number of pixels) for each second-level land cover class (
Table 4). For CSML, a stratified random sampling of equal fractions was performed on the referenced surface-mined land and resulted in a training set with 10% training samples (59,037, 20,614, and 18,490 pixels for opencast stope, mineral processing land, and dumping site, respectively) for each surface-mined land cover class.
3.5. FS Procedure
In this study, FS was performed using the varSelRF (variable selection using RF) package [
39] in the R programming language and operating environment [
40], which is a wrapper FS method. Specifically, the varSelRF package iteratively eliminates the least important variables using the out-of-bag error as the minimization criterion [
41]. The number of trees for the first forest used for obtaining the initial variable rank was set as 2000. Then, in each iterative process, an RF with 500 trees was constructed without the least important 20% of the features. Afterwards, the feature subset creating the lowest out-of-bag error was selected.
FS often achieved varied feature subsets owing to different training sets. As a result, 20 randomly selected training sets for MSMAL and CSML were used for FS and resulted in 20 feature subsets, respectively. Then, for each selected feature, its selected time, mean rank, and standard deviation of the rank were drawn and ranked, in order to pick out the final feature subsets for MSMAL and CSML.
3.6. Classification Model Development and Parameter Optimization
Three MLAs were employed in this study, such as RF, SVM, and ANN. Model development and parameter optimization were implemented within the R programming language and operating environment [
40].
The RF that incorporates a number of randomly generated trees [
42] is an increasingly popular non-parametric ensemble learning algorithm within the remote sensing community owing to its high classification accuracy [
43]. For details, see the formulas in [
42] and
Figure 1 in [
43]. SVM is based on kernel functions and structural risk minimization theory [
44]. It has been successfully used in numerous remote sensing studies [
45]. To understand the theoretical background of SVM, see
Figure 1 in [
45]. ANN is a family of models inspired by biological nervous systems to recognize patterns and objects [
46]. It also has long been used in the domain of remote sensing [
47]. For specific formulas and principles, see [
46]. The RF-, SVM-, and ANN-based models used the randomForest package [
48], e1071 package [
49], and nnet package [
50], respectively.
There are actually two crucial parameters in the RF-based models,
ntree (number of trees) and
mtry (number of features). The former would determine the number of trees to grow and its default value of 500 was hereby used [
51]. Belgiu and Drăguţ [
43] reviewed the applications of the RF algorithm in remote sensing, and they suggested using the default value of 500 for
ntree considering the following two factors: first, the classification accuracy was insensitive to
ntree compared to
mtry; second, the classification errors often stabilized before 500 trees were grown (in particular, some studies revealed that
ntree did not affect the classification accuracy). The latter that would control the number of features selected for each split needs to be optimized [
51]. The SVM-based models used the radial basis function (RBF) kernel and have two tuning parameters,
cost and
gamma. The
cost parameter trades off misclassification of training examples against simplicity of the decision surface and
gamma sets the width of the kernel function [
52]. The multi-layer perceptron ANN with a single hidden layer was used in this study, and there are three important parameters,
size,
decay, and
maxit [
52]. The
size parameter sets the number of units in the hidden layer and needs to be tuned. The
decay parameter controls the weight decay, and
maxit sets the maximum number of iterations; they are both left at their default values. A logistic activate/transfer function and the quasi-Newton optimization algorithm that does not use the parameters, such as learning rate and momentum, were used [
50].
Classification model building and tuning were all based on the e1071 package [
49], in which there is a function “best.tune” that can train and tune each of the employed MLAs. The MLAs-based models were built by the function “best.tune”, calling corresponding functions in the above-mentioned packages. A 10-fold cross-validation scheme in the function “best.tune” was used to obtain the “optimal” parameter combinations used for each classification model. First, the training set was randomly divided into 10 independent subsets of roughly equal size. Second, for each parameter combination, nine subsets were used to train the classifier and the remaining one was used for a test. This process was repeated 10 times, and the average values of the 10 overall accuracies were calculated. The “optimal” parameter settings of each algorithm were obtained based on the models that achieved the highest average overall accuracies during the cross-validation process.
3.7. Classification Accuracy Assessment
Classification accuracy was assessed based on the test data sets that were independent of the training sets. For MSMAL, based on the classification result grouped into seven first-level classes and derived from the RF algorithm and the feature subset, a stratified random sampling resulted in a test set with 700 pixels, 100 in each of the assigned classes. The referenced land cover classes of each selected pixel were determined based on visual identification of the ZY-3 imagery. All the classification algorithms and feature sets-based models were assessed based on this test set. The feature subset-based and all feature-based models for each classification algorithm were compared to evaluate the influence of FS on the classification accuracy. For CSML, all classification algorithms and feature sets-based models used the remaining 90% pixels (531,334, 185,522, and 166,408 for opencast stope, mineral processing land, and dumping site, respectively) as the test set.
The F1-measure and overall accuracy were drawn from the confusion matrix of each classification. The F1-measure is defined as the harmonic mean of the user’s accuracy and producer’s accuracy, which was used to assess the average class accuracy. A detailed description of the F1-measure can be found in Daskalaki
et al. [
53]. The differences in the results for the feature subset-based models and all feature-based models are quantified for the F1-measures of each class, and the overall accuracies by the percentage deviation [
54]. The McNemar test is a statistical test used to compare classifier performance [
55]. The test is based on chi-square statistics, computed from the error matrices of two classifications [
55]. The McNemar test was used in the present study to answer the following questions: whether there are statistically significant differences between the feature subsets- and all feature-based models; and whether there are statistically significant differences among three MLAs based on the feature subsets.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}