1. Introduction
With the rapid development of remote sensing technology, the volume of acquired high-resolution remote sensing images has dramatically increased. The automatic management of large volumes of high-resolution remote sensing images has become an urgent problem to be solved. Among the new emerging high-resolution remote sensing image management tasks, content-based high-resolution remote sensing image retrieval (CB-HRRS-IR) is one of the most basic and challenging technologies [
1]. Based on the query image provided by the data administrator, CB-HRRS-IR specifically works by searching for similar images in the high-resolution remote sensing image archives. Due to its potential applications in high-resolution remote sensing image management, CB-HRRS-IR has attracted increasing attention [
2].
In the remote sensing community, conventional image retrieval systems rely on manual tags describing the sensor type, waveband information, and geographical location of remote sensing images. Accordingly, the retrieval performance of these tag-matching-based methods highly depends on the availability and quality of the manual tags. However, the creation of image tags is usually time-consuming and becomes impossible when the volume of acquired images explosively increases. Recent research has shown that the visual contents themselves are more relevant than the manual tags [
3]. With this consideration, more and more researchers have started to exploit the CB-HRRS-IR technology. In recent decades, different types of CB-HRRS-IR have been proposed. Generally, existing CB-HRRS-IR methods can be classified into two categories: those that take only one single image as the query image [
1,
2,
4,
5,
6,
7] and those that simultaneously take multiple images as the query images [
3,
8]. In the latter category, multiple query images including positive and negative samples are iteratively generated during the feedback retrieval process. Accordingly, the approaches from the latter category involve multiple interactive annotations. It is noted that the approaches from the former category take only one query image as the input in one retrieval trial. To minimize the manual burden, this paper follows the style of the former category. Of the methods in the former category, all of them consist of two essential modules: the feature representation module and the feature searching module. The feature representation module extracts the feature vector from the image to describe the visual content of the image. Based on the extracted feature vectors, the feature searching module calculates the similarity values between images and outputs the most similar images by sorting the similarity values.
For charactering high-resolution remote sensing images, low-level features such as spectral features [
9,
10], shape features [
11,
12], morphological features [
5], texture features [
13], and local invariant features [
2] have been adopted and evaluated in the CB-HRRS-IR task. Although low-level features have been employed with a certain degree of success, they have a very limited capability in representing the high-level concepts presented by remote sensing images (i.e., the semantic content). This issue is known as the semantic gap between low-level features and high-level semantic features. To narrow this gap, Zhou et al. utilized the auto-encoder model to encode the low-level feature descriptor for pursing sparse feature representation [
6]. Although the encoded feature can achieve a higher retrieval precision, this strategy is limited because the re-representation approach takes the low-level feature descriptor as the input, which has lost some spatial and spectral information. As high-resolution remote sensing images are rich in complex structures, high-level semantic feature extraction is an exceptionally difficult task and a direction worthy of in-depth study.
In the feature searching module, both precision and speed are pursued. In [
2], different similarity metrics for single features are systematically evaluated. Shyu et al. utilized the linear combination approach to measure the similarity when multiple features of one image are simultaneously utilized [
1]. In very recent years, the volume of available remote sensing images has dramatically increased. Accordingly, the complexity of the feature searching is very high, as the searching process should access all the images in the dataset. To decrease the searching complexity, the tree-based indexing approach [
1] and the hashing-based indexing approach [
5] were proposed. The acceleration of the existing approaches can be implemented by the use of parallel devices, so the key problem in the feature searching module is to exploit good similarity measures.
In order to address these problems in CB-HRRS-IR, this paper proposes a novel approach using unsupervised feature learning and collaborative metric fusion. In [
14], unsupervised multilayer feature learning is proposed for high-resolution remote sensing image scene classification. As depicted there, unsupervised multilayer feature learning could extract complex structure features via a hierarchical convolutional scheme. For the first time, this paper extends unsupervised multilayer feature learning to CB-HRRS-IR. Derived from unsupervised multilayer feature learning, one-layer, two-layer, three-layer, and four-layer feature extraction frameworks are constructed for mining different characteristics from different scales. In addition to these features generated via unsupervised feature learning, we also re-implement traditional features including local binary pattern (LBP) [
15], gray level co-occurrence matrix (GLCM) [
16], maximal response 8 (MR8) [
17], and scale-invariant feature transform (SIFT) [
18] in computer vision. Based on these feature extraction approaches, we can obtain a set of features for each image. Generally, different features can reflect the different characteristics of one given image and play complementary roles. To make multiple complementary features effective in CB-HRRS-IR, we utilize the graph-based cross-diffusion model [
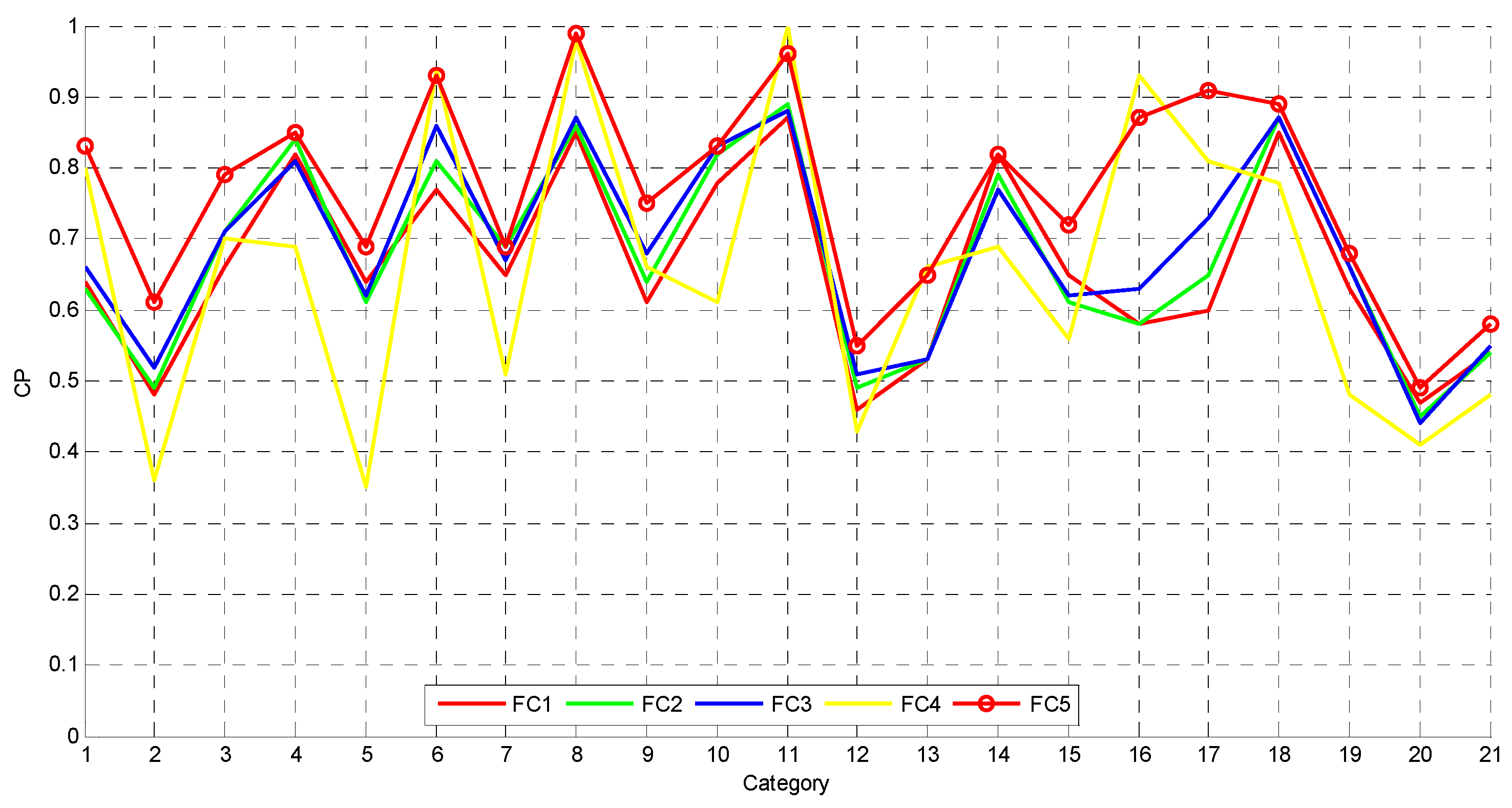
19] to measure the similarity between the query image and the test image. In this paper, the proposed similarity measure approach is named collaborative metric fusion because it can collaboratively exchange information from multiple feature spaces in the fusion process. Experimental results show that the proposed unsupervised features derived from unsupervised feature learning can achieve higher precision than the conventional features in computer vision such as LBP, GLCM, MR8, and SIFT. Benefiting from the utilized collaborative metric fusion approach, the retrieval results can be significantly improved by use of multiple features. The feature set containing unsupervised features can outperform the feature set containing conventional features, and the combination of unsupervised features and conventional features can achieve the highest retrieval precision. The main contributions of this paper are twofold:
Unsupervised features derived from unsupervised multilayer feature learning are utilized in CB-HRRS-IR for the first time and could significantly outperform the conventional features such as LBP, GLCM, MR8, and SIFT in CB-HRRS-IR.
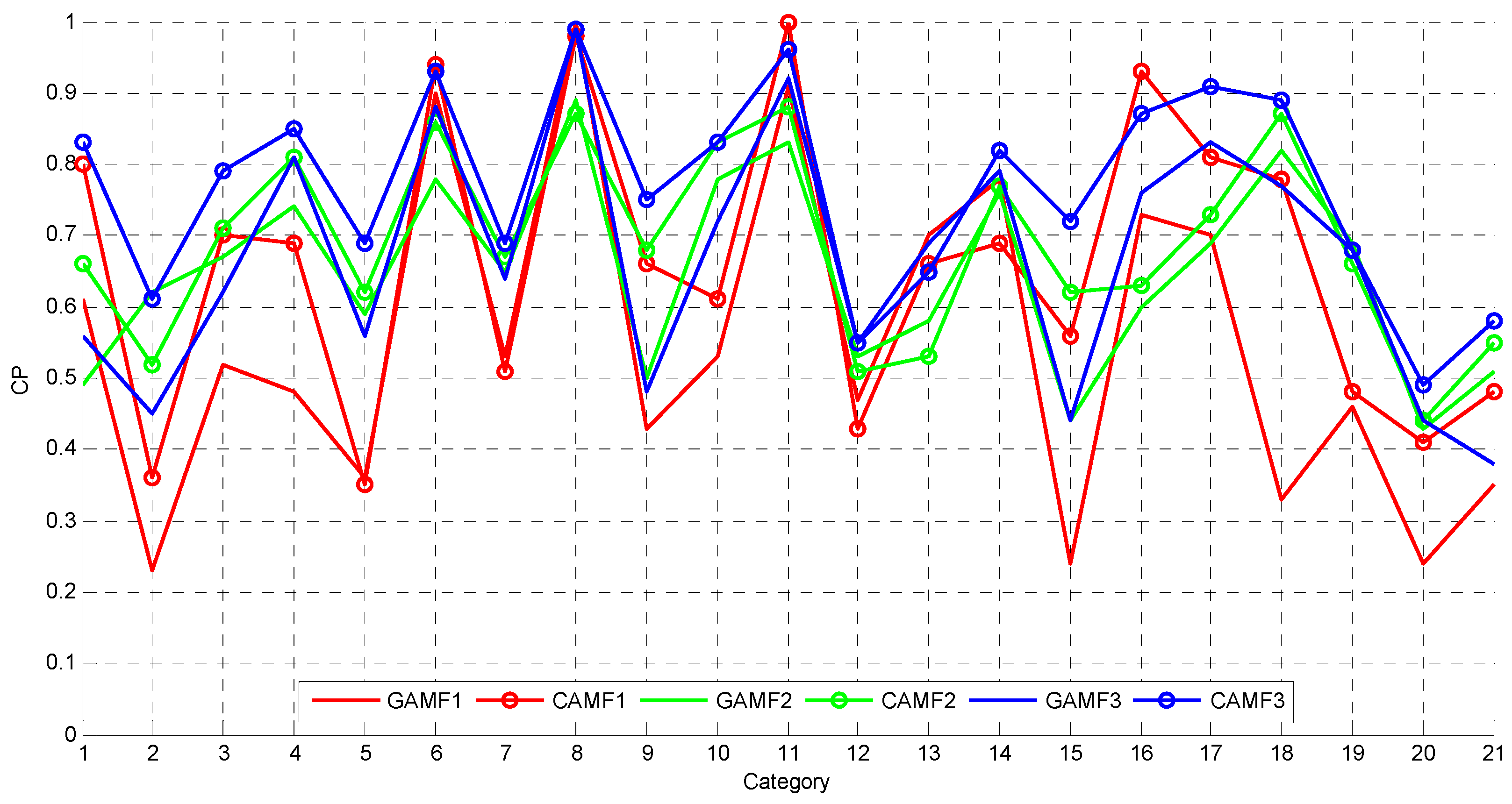
In the remote sensing community, collaborative affinity metric fusion is utilized for the first time. Compared with greedy affinity metric fusion, in which multiple features are integrated and further measured by the Euclidean distance, collaborative affinity metric fusion can make the introduced complementary features more effective in CB-HRRS-IR.
This paper is organized as follows. The generation process of unsupervised features is presented in
Section 2. In
Section 3, collaborative affinity metric fusion is described and utilized to measure the similarity when multiple features of one image are available and simultaneously utilized for calculating the similarity.
Section 4 summarizes the proposed algorithm for CB-HRRS-IR, and the overall performance of the proposed approach is presented in
Section 5. Finally,
Section 6 provides the conclusion of this paper.
2. Unsupervised Feature Learning
With the development of deep learning [
20,
21,
22], the performances of many visual recognition and classification tasks have been significantly improved. However, supervised deep learning methods [
23], e.g., deep convolutional neural networks (DCNN), rely heavily on millions of human-annotated data that are non-trivial to obtain. In visual recognition and classification tasks, supervised deep learning outputs class-specific feature representation via large-scale supervised learning. However, content-based high-resolution remote sensing image retrieval (CB-HRRS-IR) pursues generic feature representation. Accordingly, this paper exploits unsupervised feature learning approaches [
14,
24,
25] to implement generic feature representation. To improve the image retrieval performance, this paper tries to extract as many complementary features as possible to depict the high-resolution remote sensing images. Accordingly, each satellite image can be expressed by one feature set that contains multiple complementary features. In the high-resolution remote sensing image scene classification task, the data-driven features derived from unsupervised multilayer feature learning [
14] outperform many state-of-the-art approaches. In addition, the features from different layers of the unsupervised multilayer feature extraction network show complementary discrimination abilities. Hence, this paper utilizes unsupervised multilayer feature learning [
14] to generate the feature set of each image for CB-HRRS-IR, where the feature set of one image is composed of multiple feature vectors mined from the corresponding image.
In [
14], the proposed feature extraction framework contains two feature layers, and two different feature representations are extracted by implementing a global pooling operation on the first feature layer and the second feature layer of the same feature extraction network. The number of bases of the intermediate feature layer is set to a relatively small value because too large a number would dramatically increase the computation complexity and memory consumption [
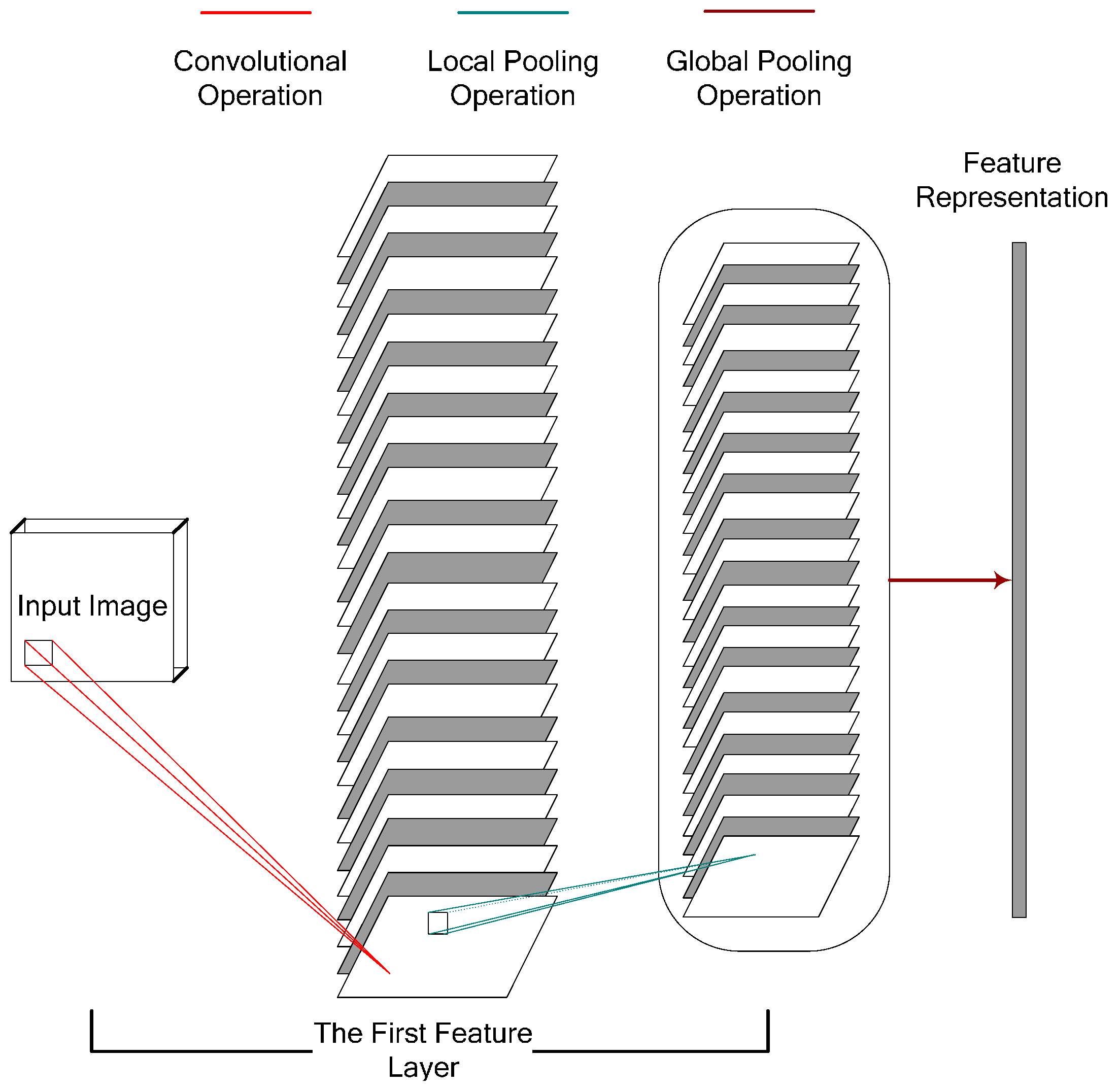
14]. Accordingly, the representation characteristic of the lower feature layer is not fully exploited. To overcome this drawback, this paper designs four unsupervised convolution feature extraction networks via unsupervised multilayer feature learning to fully mine the representation characteristics of different feature layers. More unsupervised convolution feature extraction networks can be similarly derived from unsupervised multilayer feature learning. Four unsupervised feature extraction networks contain one feature layer, two feature layers, three feature layers, and four feature layers, respectively. Although the layer numbers of the four unsupervised feature extraction networks are different, any unsupervised feature extraction network includes three basic operations: (1) the convolutional operation; (2) the local pooling operation; and (3) the global pooling operation. In addition, each feature layer contains one convolution operation and one local pooling operation, as illustrated in
Figure 1 and
Figure 2.
More specifically, convolutional operation works for feature mapping, which is constrained by the function bases (i.e., the convolutional templates). In addition, the function bases are generated by unsupervised
K-means clustering. Local pooling operation works to keep the layer invariant to slight translation and rotation and is implemented by the traditional calculation process (i.e., the local maximum). Generally, the global pooling operation is implemented by sum-pooling in multiple large windows [
14,
25], and multiple sum-pooling results are integrated as a feature vector. For simplifying the computational complexity and improving the rotation invariance, global pooling in this paper is implemented by sum-pooling in the whole window. The global pooling result (i.e., the feature representation)
can be formulated as
where
denotes the local pooling result of the last layer. In addition,
,
, and
denote the height, the width, and the depth of
.
In order to facilitate the understanding of the feature extraction framework, feature extraction networks with one feature extraction layer and two feature extraction layers are visually illustrated in
Figure 1 and
Figure 2. Through stacking convolution operations and local pooling operations, the feature extraction networks with three feature extraction layers and four feature extraction layers can be analogously constructed.
In our implementation, the numbers of bases of the different feature layers in each feature extraction network are specifically demonstrated in the following. As depicted in [
14], the more bases that the intermediate feature layers have, the better the performance of the generated feature. However, more bases would remarkably increase the computational complexity. To achieve a balance between performance and complexity, the number of bases is set to a relatively small value in the following. For the feature extraction network with one feature extraction layer, the number of bases of the first layer is 1024. For the feature extraction network with two feature extraction layers, the number of bases in the first layer is 100, and the number of bases in the second layer is 1024. For the feature extraction network with three feature extraction layers, the number of bases in the first layer is 64, the number of bases in the second layer is 100, and the number of bases in the third layer is 1024. For the feature extraction network with four feature extraction layers, the number of bases in the first layer is 36, the number of bases in the second layer is 64, the number of bases in the third layer is 100, and the number of bases in the fourth layer is 1024. Other parameters such as the receptive field and the local window size of the local pooling operation are set according to [
14].
As depicted in [
14], the bases of the aforementioned unsupervised convolution feature extraction networks can be learnt via layer-wise unsupervised learning. Once the parameters of the aforementioned four feature extraction networks are determined, the four different feature extraction networks can be used for feature representation. Given one input remote sensing image, we can obtain four different types of features via the four feature extraction networks. In the following, the four different types of features represented by the introduced four Unsupervised Convolutional Neural Networks with one feature layer, two feature layers, three feature layers, and four feature layers are abbreviated as UCNN1, UCNN2, UCNN3, and UCNN4, respectively.
As mentioned, the feature extraction pipeline of these neural networks is fully learned from unlabeled data. The size and band of the input image are highly flexible. Hence, this unsupervised feature learning approach can be easily extended to different types of remote sensing image without any dimension reduction of the bands.
In addition to UCNN1, UCNN2, UCNN3, and UCNN4, we re-implement the conventional feature descriptors in computer vision, including LBP [
15], GLCM [
16], MR8 [
17], and SIFT [
18], which are taken as the baselines for comparison. In the extraction process of the LBP feature, the uniform rotation-invariant feature is computed by 16 sampling points on a circle with a radius equal to 3. The LBP feature is generated through quantifying the uniform rotation-invariant features under the constraint of the mapping tables with 36 patterns. The GLCM feature encodes the contrast, the correlation, the energy, and the homogeneity along three offsets (i.e., 2, 4, and 6). The MR8 and SIFT features are histogram features using the bag of visual words model, and the volume of the visual dictionary is set to 1024.
As demonstrated in
Table 1, conventional features including LBP, GLCM, MR8, and SIFT and unsupervised convolution features including UCNN1, UCNN2, UCNN3, and UCNN4 constitute the feature set for comprehensively depicting and indexing the remote sensing image. Features from this feature set are utilized to implement high-resolution remote sensing image retrieval via collaborative metric fusion, as is specifically introduced in
Section 3.
3. Collaborative Affinity Metric Fusion
In
Section 2, we introduce unsupervised features derived from unsupervised multilayer feature learning and review several conventional feature extraction approaches in computer vision. The content of each high-resolution remote sensing image can be depicted by a set of feature representations using the aforementioned feature extraction approaches. In addition, the affinity of two images can be measured by the similarity of their corresponding feature representations. Although more feature representations intuitively benefit measuring the similarity between two images, how to effectively measure the similarity is still a challenging task when multiple features are available. With this consideration, this section introduces collaborative affinity metric fusion to measure the similarity of two images when each image is represented by multiple features. To address the superiority of collaborative affinity metric fusion, this section first describes greedy affinity metric fusion.
To facilitate clarifying and understanding the affinity metric fusion methods, the adopted feature set is first demonstrated. Assuming that the adopted feature set contains types of features, the feature set of the -th high-resolution remote sensing image can be formulated as , where denotes the vector of the -th type of feature and denotes the dimension of the -th type of feature.
3.1. Greedy Affinity Metric Fusion
In the literature, when an image is represented by only one type of feature, the dissimilarity between two images can be easily calculated by the Euclidean distance or other metrics [
2], and the affinity between two images can be further achieved. In this paper, one image is represented by one feature set that contains multiple types of features. Although the representations of the images become richer, how to robustly measure the affinity between images becomes more difficult.
Here, we first present a plain approach (i.e., greedy affinity metric fusion) to combine multiple features to measure the affinity between images. More specifically, multiple features from the feature set can be first integrated as a super feature vector, and the distance between two feature sets can be greedily calculated by the Euclidean distance between two super feature vectors. Before the features are integrated, each type of feature is first normalized. For conciseness, we only introduce the normalization process of one type of feature, in which each dimension of the feature has the mean value subtracted from it and is further divided by the standard deviation. In addition, the feature is divided by its dimension to reduce the dimension influence of the different types of features.
In this paper, the Euclidean distance is adopted for the primary attempt, and more metrics will be tested in future work. The formulation of greedy affinity metric fusion is as follows. Given the
-th and
-th high-resolution remote sensing images, the super feature vectors can be expressed by
and
, where
and
. The affinity between the
-th and
-th high-resolution remote sensing images can be expressed by
where
denotes the Euclidean distance or the L2 distance [
2], and
is the control constant.
Although greedy metric fusion can utilize multiple features to calculate the similarity between images, its use would be not ideal when the super feature vectors in Equation (2) are highly hybrid [
26]. Accordingly, how to fully incorporate the merit of multiple features for measuring the affinity between two images deserves more explanation.
3.2. Collaborative Affinity Metric Fusion
For greedy affinity metric fusion, the affinity calculation of two high-resolution remote sensing images considers only the images themselves. However, the affinity calculation can be improved by importing other auxiliary images in the image dataset. Greedy affinity metric fusion also suffers from the weakness that the Euclidean distance is unsuitable when the super feature vector is highly hybrid. With this consideration, this section introduces collaborative affinity metric fusion to address these problems. Collaborative affinity metric fusion originates from the self-smoothing operator [
27], which can robustly measure the affinity by propagating the similarities among auxiliary images when only one type of feature is utilized and is fully proposed in [
19] for natural image retrieval by fusing multiple metrics. Afterwards, collaborative affinity metric fusion is utilized in genome-wide data aggregation [
28] and multi-cue fusion for salient object detection [
29]. In this paper, we utilize collaborative affinity metric fusion to fully incorporate the merit of multiple features introduced in
Section 2 for content-based high-resolution remote sensing image retrieval (CB-HRRS-IR).
3.2.1. Graph Construction
As depicted in [
19], collaborative affinity metric fusion is based on multiple graphs. As mentioned, the adopted feature set is assumed to contain
types of features. Here, the number of graphs is equal to
, and each graph can be constructed from one type of feature in the feature set, using an image dataset that is assumed to contain
images.
For the
-th feature, the corresponding full graph is expressed by
, where
stands for the node set,
is the edge set, and
denotes the affinity matrix. Using the
-th feature,
denotes the similarity or affinity value between the
-th node (i.e., the
-th image) and the
-th node (i.e., the
-th image) and can be formulated as
where
is the control constant, which is the median value of the distances of two arbitrary feature vectors.
By normalizing
along each row, we can get the status matrix
, which is defined by
Given the fully connected graph
, we can construct the locally connected graph
.
has the same node set as
(i.e.,
). However, different from
, each node of
is only locally connected with its
nearest neighboring nodes, that is,
if and only if
, where
denotes the neighboring node set of the
-th node. In addition, the local affinity matrix
can be defined by
By normalizing
along each row, the kernel matrix
can be formulated as
It is noted that the status matrix carries the affinity information in the global domain among graph nodes, while the kernel matrix encodes the local affinity information in the local domain among graph nodes. Replicating the above steps, we can similarly construct fully connected graphs and locally connected graphs .
3.2.2. Affinity Metric Fusion via Cross-Diffusion
Supposing that
fully connected graphs
and
locally connected graphs
have been constructed, this section introduces the generation process of the fused affinity matrix
. Before giving the final fused affinity matrix
, we first give the cross-diffusion formulation,
where
,
,
denotes the original status matrix
,
is the diffusion result at the
-th iteration step,
is an identity matrix, and
is a scalar regularization penalty that works to avoid the loss of self-similarity through the diffusion process and benefits achieving consistency and convergence in different tasks [
19]. Previous studies [
29] have shown that the values of the iteration step
and the regularization penalty
are not sensitive to the final results. Hence, in this paper,
and
are empirically set to 20 and 1.
In the above cross-diffusion process, and are taken as the original inputs. After one iteration, can be calculated via Equation (7). In addition, , , and can be successively calculated.
Generally, the success of the diffusion process in Equation (7) benefits from the constraint of the kernel matrices , which are locally connected. In the kernel matrices, only nodes with high reliability are connected, which makes the diffusion process robust to the noise of similarity measures in the fully connected graph. In addition, the diffusion process in Equation (7) is implemented across graphs that are constructed of different types of features. This makes the diffusion process incorporate the complementary merit of different features.
The fused affinity matrix
can be expressed by the average of the cross-diffusion results of the status matrices after
iterations:
where
is the final cross-diffusion result of the status matrix that corresponds to the
-th type of feature. It is noted that
incorporates information from other types of features in the diffusion process, as depicted in Equation (7).
Finally, the affinity value between the
-th and
-th high-resolution remote sensing images in the image dataset can be expressed by
where
is the cross-diffusion result of Equation (7). In
, the similarity between two arbitrary nodes (i.e., the images) is the diffusion result with the aid of auxiliary nodes (i.e., auxiliary images).
As a whole, compared with greedy affinity metric fusion, collaborative affinity metric fusion can not only propagate the affinity values among auxiliary images for improving the affinity calculation of two images of interest, but can also flexibly incorporate the merit of multiple features.
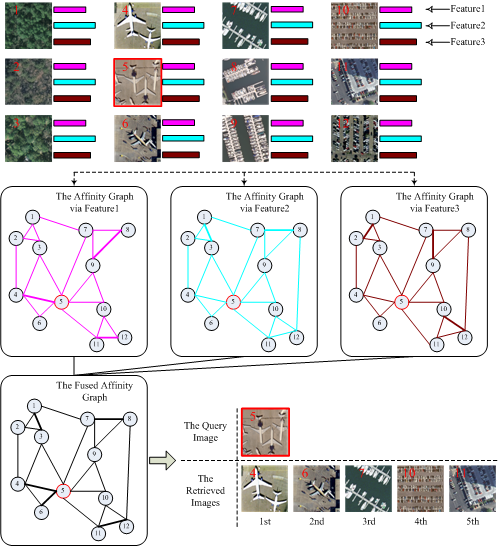
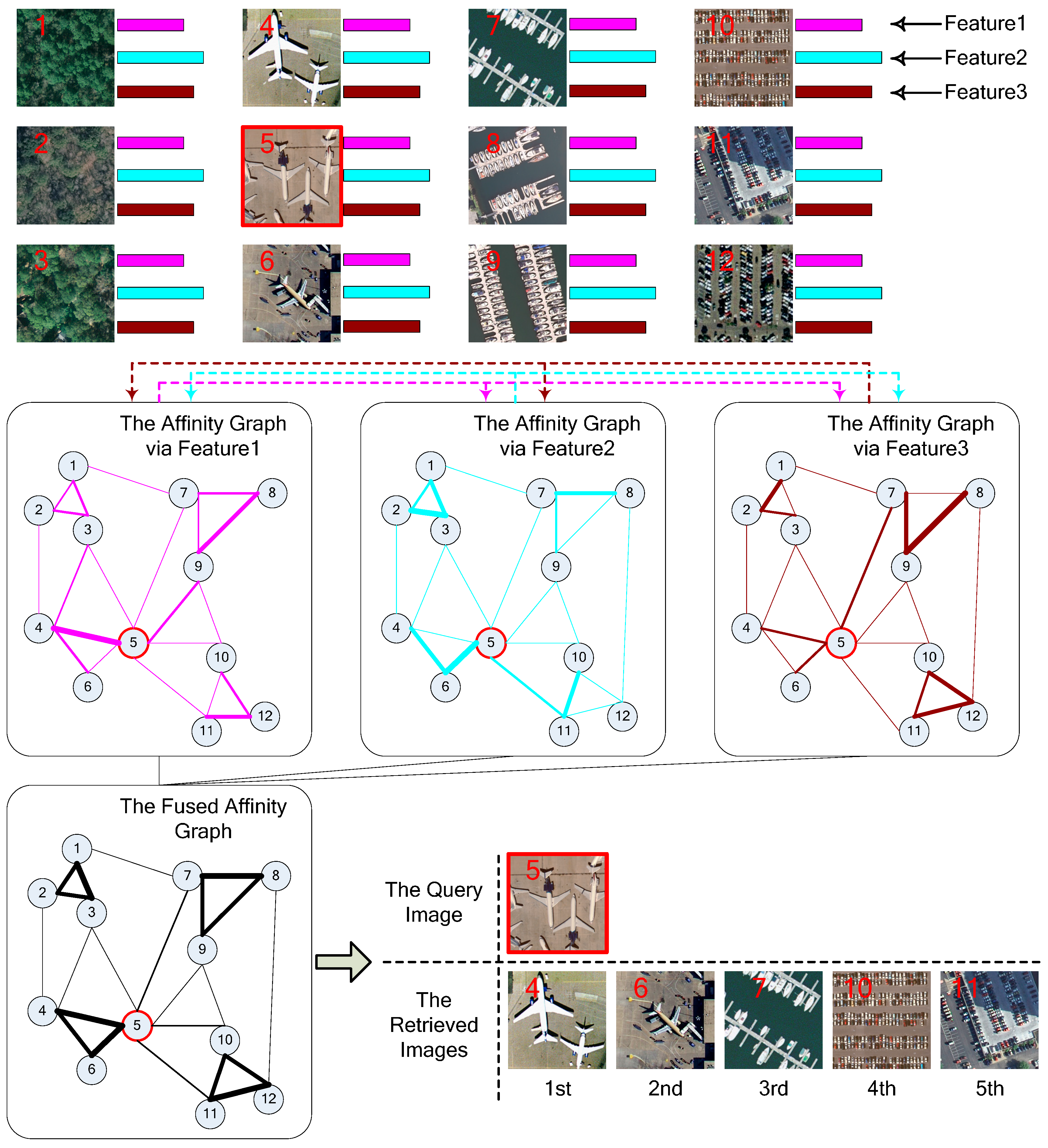
4. Image Retrieval via Multiple Feature Representation and Collaborative Affinity Metric Fusion
As mentioned, this paper proposes a robust high-resolution remote sensing Image Retrieval approach via Multiple Feature Representation and Collaborative Affinity Metric Fusion, which is called IRMFRCAMF in the following. The main processing procedures of our proposed IRMFRCAMF are visually illustrated in
Figure 3. As depicted, each high-resolution remote sensing image is represented by multiple types of features. Using each type of feature, one fully connected graph and one corresponding locally connected graph are constructed. Furthermore, we can achieve a fused graph by implementing a cross-diffusion operation on all of the constructed graphs. From the fused graph, we can obtain an affinity value between two nodes that directly reflects the affinity between two corresponding images. Accordingly, we can easily finish the image retrieval task after achieving the affinity values between the query image and the other images in the image dataset.
With the consideration that
Figure 3 only gives a simplified exhibition of our proposed IRMFRCAMF, to deeply demonstrate our proposed IRMFRCAMF, the generalized description of our proposed IRMFRCAMF is specifically introduced in the following. Corresponding to the aforementioned definitions, the image dataset is assumed to contain
images, and each image is assumed to be represented by
types of features. Accordingly,
images can be represented by
feature sets
. Furthermore,
fully connected graphs
can be constructed, and
is constructed using the features sets
. Let
denote the number of nearest neighboring nodes, and
locally connected graphs
can be correspondingly constructed. Let the
-th image in the image dataset denote the query image, and the most related images can be automatically accurately retrieved using our proposed IRMFRCAMF, which is elaborately described in Algorithm 1.
In many applications, such as image management in a local repository, the volume of the image dataset is fixed over a period of time, and the query image also comes from the image dataset. In this case, the features of images can be calculated in advance, and the affinity matrix calculation can be performed as an offline process. Accordingly, the image retrieval task can be instantaneously completed just through searching the affinity matrix.
However, the volume of the image dataset may be increased after a long time, and the query image may not be from the image dataset. Even in this extreme circumstance, the existing features of the images in the original dataset can be reused, but the affinity matrix should be recalculated. To facilitate the evaluation of the time cost of data updating, we provide the computational complexity of the affinity matrix calculation process in the following. The complexity of constructing
fully connected graphs is
, where
is the volume of the dataset. As depicted in
Section 3.2.1, searching
nearest neighbors for each feature vector is the premise for constructing locally connected graphs. In addition, the time complexity of searching
nearest neighbors for each feature vector is close to
by using the
k-d tree [
30], and the complexity of constructing
locally connected graphs is close to
. The complexity of the cross-diffusion process in
Section 3.2.2 is
, where
is the iteration number in the cross-diffusion process. The total complexity of the affinity matrix calculation is
, and the primary complexity is introduced by the cross-diffusion process. The time cost of the affinity matrix calculation is mainly influenced by the volume of the image dataset.
| Algorithm 1. High-resolution remote sensing image retrieval via multiple feature representation and collaborative affinity metric fusion. |
| Input: the high-resolution remote sensing image dataset that contains images; the query image (i.e., the -th image); the number of nearest neighboring nodes ; other parameters set according to [19]. |
| 1. Calculate the feature sets according to the feature extraction approaches defined in Section 2. |
| 2. Construct the fully connected graphs and the locally connected graphs using the extracted feature sets according to Section 3.2.1. |
| 3. Calculate the fused affinity matrix using the constructed graphs via cross-diffusion according to Section 3.2.2. |
| 4. Generate the affinity vector that records the affinity values between the query image and the other images in the image dataset. |
| 5. Get the indexes of the most related images by ranking the affinity vector in descending order. |
| Output: the most related images. |
6. Conclusions
In order to improve the automatic management of high-resolution remote sensing images, this paper proposes a novel content-based high-resolution remote sensing image retrieval approach via multiple feature representation and collaborative affinity metric fusion (IRMFRCAMF). Derived from unsupervised multilayer feature learning [
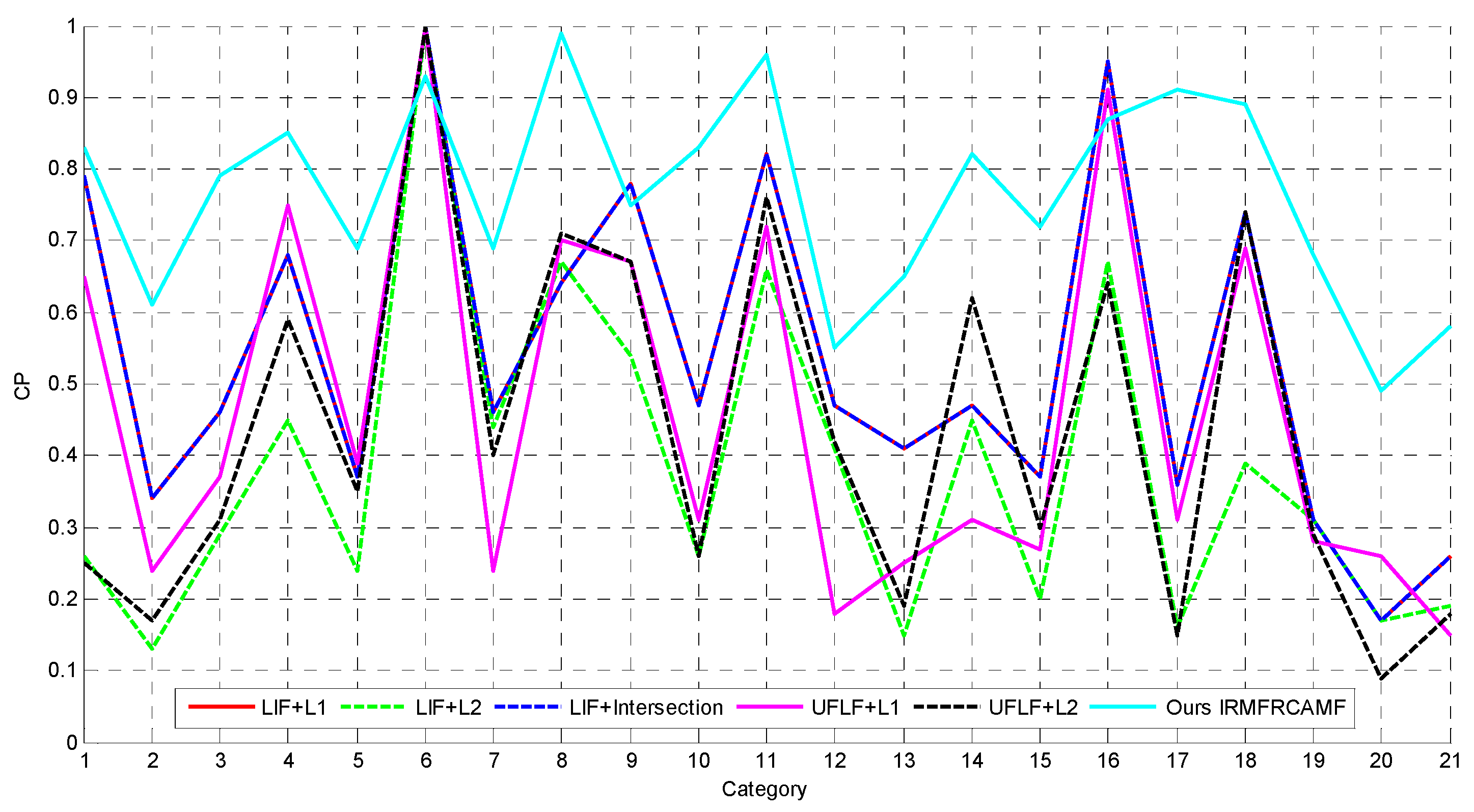
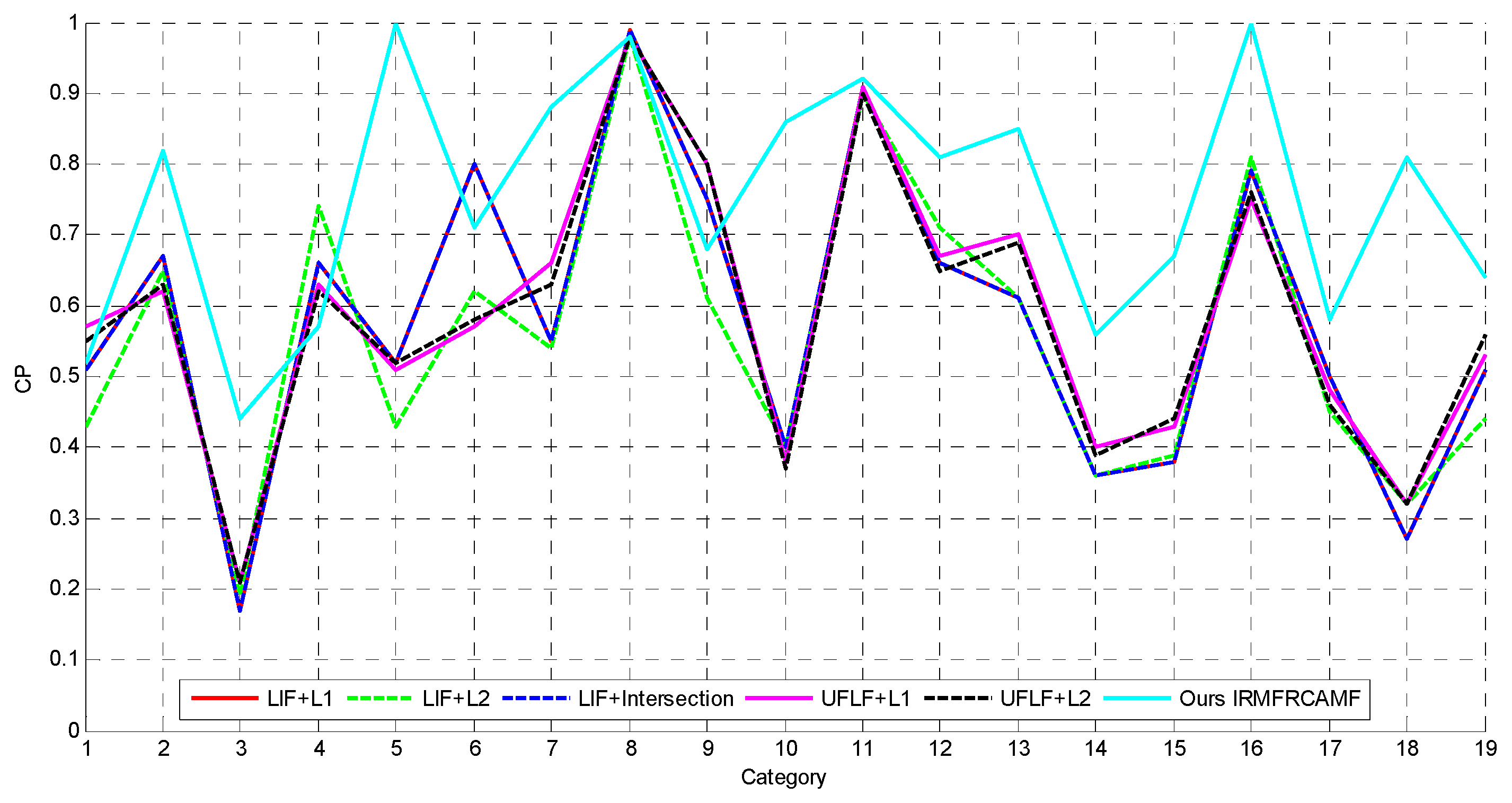
14], this paper designs four networks that can generate four types of unsupervised features: the aforementioned UCNN1, UCNN2, UCNN3, and UCNN4. The proposed unsupervised features can achieve better image retrieval performance than the traditional feature extraction approaches such as LBP, GLCM, MR8, and SIFT. In order to make the most of the introduced complementary features, this paper advocates collaborative affinity metric fusion to measure the affinity between images. Large numbers of experiments show that the proposed IRMFRCAMF can dramatically outperform two existing approaches, including LIF in [
2] and UFLF in [
6].
It is well known that feature representation is a fundamental module in various visual tasks. Hence, in addition to high-resolution remote sensing image retrieval, the proposed unsupervised features would probably benefit other tasks in computer vision such as feature matching [
45,
46], image fusion [
47], and target detection [
48]. In our future work, the proposed unsupervised features will be evaluated on more tasks. In addition, we will extend the proposed IRMFRCAMF to more applications in the remote sensing community. For example, the proposed IRMFRCAMF will be utilized to generate labeled samples for scene-level remote sensing image interpretation tasks such as land cover classification [
14], built-up area detection [
49], urban village detection [
50], and urban functional zoning recognition [
51].


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}