Google Earth Engine, Open-Access Satellite Data, and Machine Learning in Support of Large-Area Probabilistic Wetland Mapping





Abstract
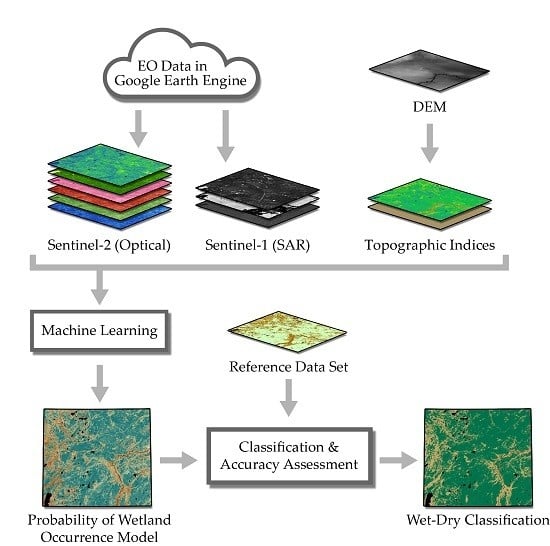
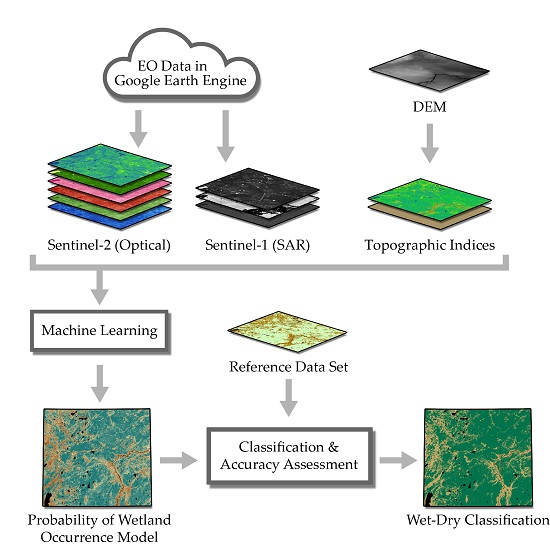
:
1. Introduction
1.1. Trends in Satellite-Data Availability, Cloud Computing, and Machine Learning
1.2. The Need for Comprehensive Wetland Mapping and Monitoring Programs
1.3. Research Objectives and Approach
2. Materials and Methods
2.1. Study Area
2.2. Data Sets
2.2.1. Topographic Data
2.2.2. Optical Data
2.2.3. Radar Data
2.2.4. Training and Reference Data
2.2.5. Other Data
2.3. Modeling and Evaluation
3. Results
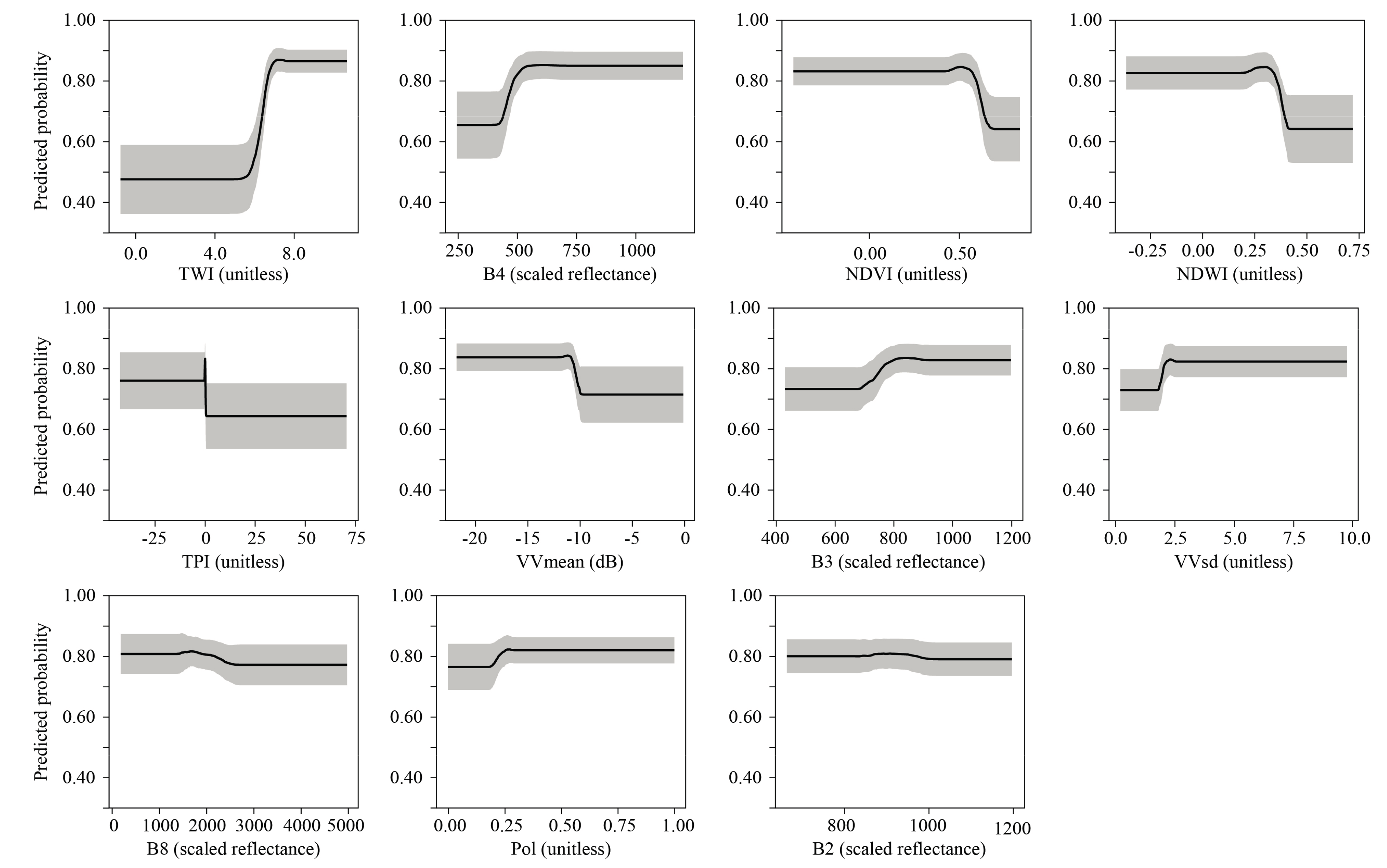
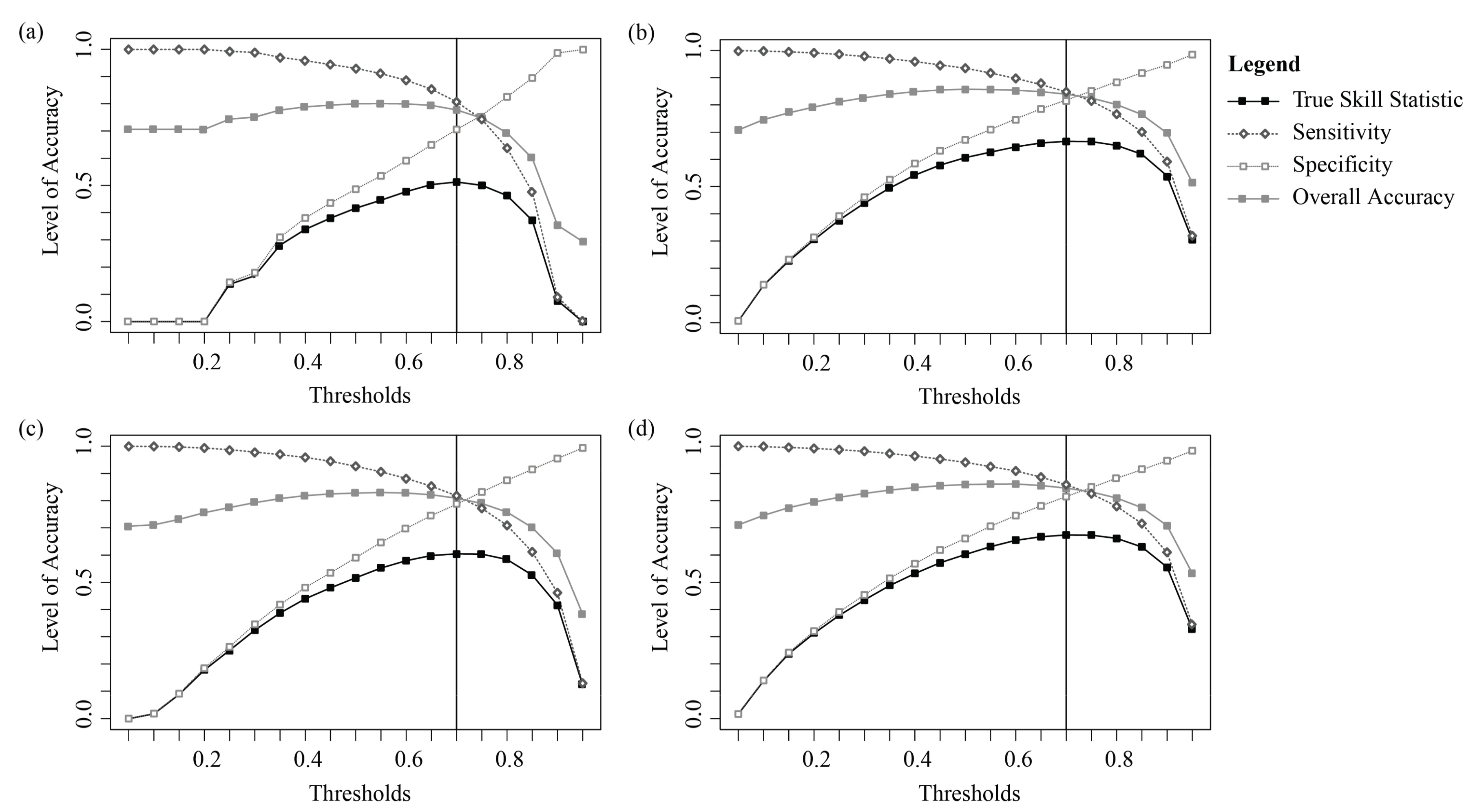
3.1. Probability Models
3.2. Classification
4. Discussion
4.1. Modeling Wetland Occurrence
4.2. The Value of Optical and SAR Inputs
4.3. Towards Alberta-Wide Mapping
5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Woodcock, C.; Allen, R.; Anderson, M.; Belward, A.; Bindschadler, R.; Cohen, W.; Gao, F.; Goward, S.N.; Helder, D.; Helmer, E.; et al. Free access to landsat imagery. Science 2008, 320, 1011–1012. [Google Scholar] [CrossRef] [PubMed]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Google. A Planetary-Scale Platform for Earth Science Data & Analysis. Available online: https://earthengine.google.com/ (accessed on 29 May 2017).
- National Aeronautics and Space Administration Welcome to the NASA Earth Exchange (NEX). Available online: https://nex.nasa.gov/nex/ (accessed on 12 September 2016).
- Amazon Web Services Inc. Earth on AWS: Build Planetary-Scale Applications in the Cloud with Open Geospatial Data. Available online: https://aws.amazon.com/earth/ (accessed on 28 November 2017).
- Chandrashekar, S. Announcing Real-Time Geospatial Analytics in Azure Stream Analytics. Available online: https://azure.microsoft.com/en-us/blog/announcing-real-time-geospatial-analytics-in-azure-stream-analytics/ (accessed on 12 September 2017).
- Yang, C.; Yu, M.; Hu, F.; Jiang, Y.; Li, Y. Utilizing Cloud Computing to address big geospatial data challenges. Comput. Environ. Urban Syst. 2017, 61, 120–128. [Google Scholar] [CrossRef]
- Warren, M.S.; Brumby, S.P.; Skillman, S.W.; Kelton, T.; Wohlberg, B.; Mathis, M.; Chartrand, R.; Keisler, R.; Johnson, M. Seeing the Earth in the Cloud: Processing one petabyte of satellite imagery in one day. In Proceedings of the 2015 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 13–15 October 2015. [Google Scholar]
- Hansen, M.C.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.V.; Goetz, S.J.J.; Loveland, T.R.R.; et al. High-resolution global maps of 21st-century forest cover change. Science 2013, 342, 850–854. [Google Scholar] [CrossRef] [PubMed]
- Pekel, J.-F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-resolution mapping of global surface water and its long-term changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef] [PubMed]
- Yamazaki, D.; Trigg, M.A. The dynamics of Earth’s surface water. Nature 2016, 540, 348–349. [Google Scholar] [CrossRef] [PubMed]
- DeLancey, E.R.; Kariyeva, J.; Cranston, J.; Brisco, B. Monitoring hydro temporal variability in Alberta, Canada with multi-temporal Sentinel-1 SAR data. Can. J. Remote Sens. 2017, in press. [Google Scholar]
- Moody, D.I.; Warren, M.S.; Skillman, S.W.; Chartrand, R.; Brumby, S.P.; Keisler, R.; Kelton, T.; Mathis, M. Building a living Atlas of the earth in the cloud. In Proceedings of the 50th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 6–9 November 2016; pp. 1273–1277. [Google Scholar]
- Goldblatt, R.; You, W.; Hanson, G.; Khandelwal, A.K. Detecting the boundaries of urban areas in India: A dataset for pixel-based image classification in google earth engine. Remote Sens. 2016, 8, 634. [Google Scholar] [CrossRef]
- Zhou, L.; Chen, N.; Chen, Z.; Xing, C. ROSCC: An efficient remote sensing observation-sharing method based on cloud computing for soil moisture mapping in precision agriculture. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 5588–5598. [Google Scholar] [CrossRef]
- Huntington, J.L.; Hegewisch, K.C.; Daudert, B.; Morton, C.G.; Abatzoglou, J.T.; McEvoy, D.J.; Erickson, T. Climate Engine: Cloud computing and visualization of climate and remote sensing data for advanced natural resource monitoring and process understanding. Bull. Am. Meteorol. Soc. 2017. [Google Scholar] [CrossRef]
- Waske, B.; Fauvel, M.; Benediktsson, J.A.; Chanussot, J. Machine learning techniques in remote sensing data analysis. In Kernel Methods for Remote Sensing Data Analysis; Camps-Valls, G., Bruzzone, L., Eds.; John Wiley & Sons: Chichester, UK, 2009; pp. 3–24. [Google Scholar]
- Richards, J.A. Analysis of remotely sensed data: The formative decades and the future. IEEE Trans. Geosci. Remote Sens. 2005, 43, 422–432. [Google Scholar] [CrossRef]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef]
- Bey, A.; Sánchez-Paus Díaz, A.; Maniatis, D.; Marchi, G.; Mollicone, D.; Ricci, S.; Bastin, J.-F.; Moore, R.; Federici, S.; Rezende, M.; et al. Collect Earth: Land use and land cover assessment through augmented visual interpretation. Remote Sens. 2016, 8, 807. [Google Scholar] [CrossRef]
- Azzari, G.; Lobell, D.B. Landsat-based classification in the cloud: An opportunity for a paradigm shift in land cover monitoring. Remote Sens. Environ. 2017. [Google Scholar] [CrossRef]
- Ozesmi, S.L.; Bauer, M.E. Satellite remote sensing of wetlands. Wetl. Ecol. Manag. 2002, 10, 381–402. [Google Scholar] [CrossRef]
- Corcoran, J.; Knight, J.; Brisco, B.; Kaya, S.; Cull, A.; Murnaghan, K. The integration of optical, topographic, and radar data for wetland mapping in northern Minnesota. Can. J. Remote Sens. 2011, 37, 564–582. [Google Scholar] [CrossRef]
- Gabrielsen, C.G.; Murphy, M.A.; Evans, J.S. Using a multiscale, probabilistic approach to identify spatial-temporal wetland gradients. Remote Sens. Environ. 2016, 184, 522–538. [Google Scholar] [CrossRef]
- Maxa, M.; Bolstad, P. Mapping northern wetlands with high resolution satellite images and LiDAR. Wetlands 2009, 29, 248–260. [Google Scholar] [CrossRef]
- Alberta Environment and Sustainable Resource Development. Alberta Wetland Policy; Alberta Environment and Sustainable Resource Development: Edmonton, AB, Canada, 2013. [Google Scholar]
- Alberta Environment and Parks. Alberta Merged Wetland Inventory. Available online: https://geodiscover.alberta.ca/geoportal/catalog/main/home.page (accessed on 29 May 2017).
- Kloiber, S.M.; Macleod, R.D.; Smith, A.J.; Knight, J.F.; Huberty, B.J. A semi-automated, multi-source data fusion update of a wetland inventory for East-Central Minnesota, USA. Wetlands 2015, 35, 335–348. [Google Scholar] [CrossRef]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modeling : A review of hydrological geomorphological and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Gómez-Plaza, A.; Alvarez-Rogel, J.; Albaladejo, J.; Castillo, V.M. Spatial patterns and temporal stability of soil moisture across a range of scales in a semi-arid environment. Hydrol. Process. 2000, 14, 1261–1277. [Google Scholar] [CrossRef]
- Hogg, A.R.; Todd, K.W. Automated discrimination of upland and wetland using terrain derivatives. Can. J. Remote Sens. 2007, 33, S68–S83. [Google Scholar] [CrossRef]
- Devito, K.; Creed, I.; Gan, T.; Mendoza, C.; Petrone, R.; Silins, U.; Smerdon, B. A framework for broad-scale classification of hydrologic response units on the Boreal Plain: Is topography the last thing to consider? Hydrol. Process. 2005, 19, 1705–1714. [Google Scholar] [CrossRef]
- Sass, G.Z.; Creed, I.F. Characterizing hydrodynamics on boreal landscapes using archived synthetic aperture radar imagery. Hydrol. Process. 2008, 22, 1687–1690. [Google Scholar] [CrossRef]
- Natural Regions Committee. Natural Regions and Subregions of Alberta; Natural Regions Committee: Edmonton, AB, Canada, 2006. [Google Scholar]
- Bourgeau-Chavez, L.; Endres, S.; Powell, R.; Battaglia, M.; Benscoter, B.; Turetsky, M.; Kasischke, E.; Banda, E. Mapping boreal peatland ecosystem types from a fusion of multi-temporal radar and optical satellite imagery. Can. J. For. Res. 2017, 559, 545–559. [Google Scholar] [CrossRef]
- Alberta Environment and Sustainable Resource Development. Alberta Wetland Classification System; Water Policy Branch, Policy and Planning Division: Edmonton, AB, Canada, 2015. [Google Scholar]
- Smith, D.W.; Prepas, E.E.; Putz, G.; Burke, J.M.; Meyer, W.L.; Whitson, I. The Forest Watershed and Riparian Disturbance study: A multi-discipline initiative to evaluate and manage watershed disturbance on the Boreal Plain of Canada. J. Environ. Eng. Sci. 2003, 2, S1–S13. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google earth engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2016. [Google Scholar] [CrossRef]
- Weiss, A. Topographic position and landforms analysis. In Proceedings of the Poster Presentation, ESRI User Conference, San Diego, CA, USA, 9–13 July 2001; Volume 200. [Google Scholar]
- Alexander, C.; Deak, B.; Heilmeier, H. Micro-topography driven vegetation patterns in open mosaic landscapes. Ecol. Indic. 2016, 60, 906–920. [Google Scholar] [CrossRef]
- De Reu, J.; Bourgeois, J.; Bats, M.; Zwertvaegher, A.; Gelorini, V.; De Smedt, P.; Chu, W.; Antrop, M.; De Maeyer, P.; Finke, P.; et al. Application of the topographic position index to heterogeneous landscapes. Geomorphology 2013, 186, 39–49. [Google Scholar] [CrossRef]
- Gallant, J.C.; Wilson, J.P. Primary topographic attributes. In Terrain Analysis: Principles and Applications; Wilson, J.P., Gallant, J.C., Eds.; Wiley: New York, NY, USA, 2000; pp. 51–85. [Google Scholar]
- Laamrani, A.; Valeria, O.; Bergeron, Y.; Fenton, N.; Cheng, L.Z. Distinguishing and mapping permanent and reversible paludified landscapes in Canadian black spruce forests. Geoderma 2015, 237, 88–97. [Google Scholar] [CrossRef]
- Lang, M.; McCarty, G.; Oesterling, R.; Yeo, I.Y. Topographic metrics for improved mapping of forested wetlands. Wetlands 2013, 33, 141–155. [Google Scholar] [CrossRef]
- Beven, K.J.; Kirkby, M.J. A physically based, variable contributing area model of basin hydrology. Hydrol. Sci. Bull. 1979, 24, 43–69. [Google Scholar] [CrossRef]
- Google. Sentinel-2: MultiSpectral Instrument (MSI), Level-1C. Available online: https://explorer.earthengine.google.com/#detail/COPERNICUS%2FS2 (accessed on 29 May 2017).
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with ERTS; Paper-A20; National Aeronautics and Space Administration (NASA): Washington, DC, USA, 1974; pp. 309–317. [Google Scholar]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Fensholt, R.; Rasmussen, K.; Nielsen, T.T.; Mbow, C. Evaluation of earth observation based long term vegetation trends—Intercomparing NDVI time series trend analysis consistency of Sahel from AVHRR GIMMS, Terra MODIS and SPOT VGT data. Remote Sens. Environ. 2009, 113, 1886–1898. [Google Scholar] [CrossRef]
- Adam, E.; Mutanga, O.; Rugege, D. Multispectral and hyperspectral remote sensing for identification and mapping of wetland vegetation: A review. Wetl. Ecol. Manag. 2010, 18, 281–296. [Google Scholar] [CrossRef]
- Wu, Q.; Lane, C.; Liu, H. An effective method for detecting potential woodland vernal pools using high-resolution LiDAR data and aerial imagery. Remote Sens. 2014, 6, 11444–11467. [Google Scholar] [CrossRef]
- Tang, Z.; Li, Y.; Gu, Y.; Jiang, W.; Xue, Y.; Hu, Q.; LaGrange, T.; Bishop, A.; Drahota, J.; Li, R. Assessing Nebraska playa wetland inundation status during 1985–2015 using Landsat data and Google Earth Engine. Environ. Monit. Assess. 2016, 188, 654. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Zhang, Y.; Ling, F.; Wang, Q.; Li, W.; Li, X. Water bodies’ mapping from Sentinel-2 imagery with Modified Normalized Difference Water Index at 10-m spatial resolution produced by sharpening the swir band. Remote Sens. 2016, 8, 354. [Google Scholar] [CrossRef] [Green Version]
- European Space Agency. The SENTINEL-1 Toolbox. Available online: https://sentinel.esa.int/web/sentinel/toolboxes/sentinel-1 (accessed on 29 May 2017).
- Ulaby, F.T.; Moore, R.K.; Fung, A.K. Microwave Remote Sensing Active and Passive-Volume III: From Theory to Applications; Artech House, Inc.: Dedham, MA, USA, 1986. [Google Scholar]
- Patel, P.; Srivastava, H.S.; Panigrahy, S.; Parihar, J.S. Comparative evaluation of the sensitivity of multi-polarized multi-frequency SAR backscatter to plant density. Int. J. Remote Sens. 2006, 27, 293–305. [Google Scholar] [CrossRef]
- Kornelsen, K.C.; Coulibaly, P. Advances in soil moisture retrieval from synthetic aperture radar and hydrological applications. J. Hydrol. 2013, 476, 460–489. [Google Scholar] [CrossRef]
- Mattia, F.; Le Toan, T.; Souyris, J.-C.; De Carolis, C.; Floury, N.; Posa, F.; Pasquariello, N.G. The effect of surface roughness on multifrequency polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 1997, 35, 954–966. [Google Scholar] [CrossRef]
- Gherboudj, I.; Magagi, R.; Berg, A.A.; Toth, B. Soil moisture retrieval over agricultural fields from multi-polarized and multi-angular RADARSAT-2 SAR data. Remote Sens. Environ. 2011, 115, 33–43. [Google Scholar] [CrossRef]
- Becker, F.; Choudhury, B.J. Relative sensitivity of normalized difference vegetation Index (NDVI) and microwave polarization difference Index (MPDI) for vegetation and desertification monitoring. Remote Sens. Environ. 1988, 24, 297–311. [Google Scholar] [CrossRef]
- Chauhan, S.; Srivastava, H.S. Comparative evaluation of the sensitivity of multi-polarised sar and optical data for various land cover. Int. J. Adv. Remote Sens. Gis Geogr. 2016, 4, 1–14. [Google Scholar]
- European Space Agency. SENTINEL-1 Observation Scenario. Available online: https://sentinel.esa.int/web/sentinel/missions/sentinel-1/observation-scenario (accessed on 21 November 2017).
- Pamaploni, P.; Marcelloni, G.; Paloscia, S.; Sigismondi, S. The potential of C- and L- band SAR in assessing vegetation biomass: The Ers-1 and JERS-1 experiments. In Proceedings of the 3rd ERS Symposium on Space at the Service of Our Environment, Florence, Italy, 14–21 March 1997; p. 1729. [Google Scholar]
- Baghdadi, N.; Bernier, M.; Gauthier, R.; Neeson, I. Evaluation of C-band SAR data for wetlands mapping. Int. J. Remote Sens. 2001, 22, 71–88. [Google Scholar] [CrossRef]
- Pope, K.O.; Rejmankova, E.; Paris, J.F.; Woodruff, R. Detecting seasonal cycle of the Yucatan Peninsula with SIR-C polarmetric radar imagery. Remote Sens. Environ. 1997, 59, 157–166. [Google Scholar] [CrossRef]
- Alberta Vegetation Inventory Interpretation Standards; Resource Information Management Branch, Alberta Sustainable Resource Development: Edmonton, AB, Canada, 2005.
- Ducks Unlimited Canada. Enhanced Wetland Classification Inferred Products User Guide; Version 1.0; Ducks Unlimited Canada: Stonewall, MB, Canada, 2011. [Google Scholar]
- De’ath, G. Boosted regression trees for ecological modeling and prediction. Ecology 2007, 88, 243–251. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Buston, P.M.; Elith, J. Determinants of reproductive success in dominant pairs of clownfish: A boosted regression tree analysis. J. Anim. Ecol. 2011, 80, 528–538. [Google Scholar] [CrossRef] [PubMed]
- Parisien, M.A.; Parks, S.A.; Krawchuk, M.A.; Flannigan, M.D.; Bowman, L.M.; Moritz, M.A. Scale-dependent controls on the area burned in the boreal forest of Canada, 1980–2005. Ecol. Appl. 2011, 21, 789–805. [Google Scholar] [CrossRef] [PubMed]
- Parisien, M.A.; Parks, S.A.; Krawchuk, M.A.; Little, J.M.; Flannigan, M.D.; Gowman, L.M.; Moritz, M.A. An analysis of controls on fire activity in boreal Canada: Comparing models built with different temporal resolutions. Ecol. Appl. 2014, 24, 1341–1356. [Google Scholar] [CrossRef] [PubMed]
- R Development Core Team R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2016.
- Ridgeway, G. GBM: Generalized Boosted Regression Models. 2017. Available online: https://cran.r-project.org/web/packages/gbm/gbm.pdf (accessed on 8 December 2017).
- Swets, J.A. Measuring the accuracy of diagnostic systems. Science 1988, 240, 1285–1293. [Google Scholar] [CrossRef] [PubMed]
- Zweig, M.H.; Campbell, G. Receiver-operating characteristic (ROC) plots: A fundamental evaluation tool in clinical medicine. Clin. Chem. 1993, 39, 561–577. [Google Scholar] [PubMed]
- Freeman, E.A.; Moisen, G.G. A comparison of the performance of threshold criteria for binary classification in terms of predicted prevalence and kappa. Ecol. Model. 2008, 217, 48–58. [Google Scholar] [CrossRef]
- Guisan, A.; Zimmermann, N.E. Predictive habitat distribution models in ecology. Ecol. Model. 2000, 135, 147–186. [Google Scholar] [CrossRef]
- Allouche, O.; Tsoar, A.; Kadmon, R. Assessing the accuracy of species distribution models: Prevalence, kappa and the true skill statistic (TSS). J. Appl. Ecol. 2006, 43, 1223–1232. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Murphy, P.N.C.; Ogilvie, J.; Connor, K.; Arp, P.A. Mapping wetlands: A comparison of two different approaches for New Brunswick, Canada. Wetlands 2007, 27, 846–854. [Google Scholar] [CrossRef]
- Ågren, A.M.; Lidberg, W.; Strömgren, M.; Ogilvie, J.; Arp, P.A. Evaluating digital terrain indices for soil wetness mapping-a Swedish case study. Hydrol. Earth Syst. Sci. 2014, 18, 3623–3634. [Google Scholar] [CrossRef]
- Hogg, A.R.; Holland, J. An evaluation of DEMs derived from LiDAR and photogrammetry for wetland mapping. For. Chron. 2008, 84, 840–849. [Google Scholar] [CrossRef]
- Riley, J.W.; Calhoun, D.L.; Barichivich, W.J.; Walls, S.C. Identifying small depressional wetlands and using a topographic position index to infer hydroperiod regimes for pond-breeding amphibians. Wetlands 2017, 37, 325–338. [Google Scholar] [CrossRef]
- Kasischke, E.S.; Melack, J.M.; Craig Dobson, M. The use of imaging radars for ecological applications—A review. Remote Sens. Environ. 1997, 59, 141–156. [Google Scholar] [CrossRef]
- Government of Canada. Historical Climate Data. Available online: http://climate.weather.gc.ca/index_e.html (accessed on 27 November 2017).
- Alberta Agriculture and Forestry. Current and Historical Alberta Weather Station Data Viewer. Available online: https://agriculture.alberta.ca/acis/alberta-weather-data-viewer.jsp (accessed on 27 November 2017).
- Alberta Biodiversity Monitoring Institute. 3 × 7-km Photoplot Land Cover Data. Available online: http://abmi.ca/home/data-analytics/da-top/da-product-overview/GIS-Human-Footprint-Land-Cover-Data/Photoplot-Land-Cover-Dataset.html (accessed on 2 October 2017).
- Alberta Biodiversity Monitoring Institute. 3 × 7-km Sample-Based Human Footprint Data. Available online: http://abmi.ca/home/data-analytics/da-top/da-product-overview/GIS-Human-Footprint-Land-Cover-Data/Human-Footprint-Sample-Based-Inventory.html (accessed on 2 October 2017).
- European Space Agency. The Sentinel-2 Toolbox. Available online: https://sentinel.esa.int/web/sentinel/toolboxes/sentinel-2 (accessed on 27 November 2017).
- Alberta Environment and Parks. Available online: http://aep.alberta.ca/forms-maps-services/maps/resource-data-product-catalogue/biophysical.aspx (accessed on 8 December 2017).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Description | Derived Variables |
|---|---|---|
| LiDAR (Light Detection and Ranging) Elevation | 1-m LiDAR-derived Digital Terrain Model, combination of products based on LiDAR acquired between 2006 and 2010 by Airborne Imaging, provided by the Government of Alberta | Topographic Position Index (TPI), Topographic Wetness Index (TWI) |
| Optical Imagery | 140 individual 10-m Sentinel-2 optical satellite images from May–August 2016 were acquired over the study area, provided by the European Space Agency | Blue (B2), Green (B3), Red (B4), Near Infrared (B8), Normalized Difference Vegetation Index (NDVI), Normalized Difference Water Index (NDWI) |
| Radar Imagery | 37 individual 10-m Sentinel-1 polarimetric Synthetic Aperture Radar images were acquired over the study area; VV-VH (Pol) data was acquired May to August 2016, and VVsd and VV data were acquired April to October, 2014–2016, provided by the European Space Agency | Normalized Polarization (Pol), Vertical Polarization (VV), VV Standard Deviation (VVsd) |
| Reference Data | Vector polygon-based Alberta Vegetation Inventory Enhanced data, produced by aerial photograph manual interpretation, compiled and provided by the Government of Alberta * | Wetland—Non-Wetland Classification |
| Existing Wetland Inventory | Vector polygon-based Alberta Merged Wetland Inventory data, produced by Ducks Unlimited Canada using satellite image classification of imagery acquired between 1999 and 2002, provided by the Government of Alberta | Wetland—Non-Wetland Classification |
| Model | AUC | D2 | No. of Trees |
|---|---|---|---|
| Tmodel | 0.804 (0.037) | 0.371 (0.061) | 378 (100) |
| TOmodel | 0.894 (0.026) | 0.664 (0.069) | 627 (154) |
| TSmodel | 0.868 (0.027) | 0.568 (0.065) | 531 (105) |
| TOSmodel | 0.898 (0.024) | 0.708 (0.071) | 671 (136) |
| Classification | Overall Accuracy | True Skill Statistic | Kappa | Wet Producer’s Accuracy * | Wet User’s Accuracy | Dry Producer’s Accuracy ** | Dry User’s Accuracy |
|---|---|---|---|---|---|---|---|
| Tmodel | 0.777 | 0.513 | 0.489 | 0.807 | 0.868 | 0.706 | 0.603 |
| TOmodel | 0.840 | 0.666 | 0.633 | 0.848 | 0.918 | 0.818 | 0.692 |
| TSmodel | 0.809 | 0.604 | 0.568 | 0.818 | 0.902 | 0.786 | 0.642 |
| TOSmodel | 0.855 | 0.674 | 0.645 | 0.859 | 0.918 | 0.815 | 0.706 |
| AMWI | 0.854 | 0.672 | 0.656 | 0.878 | 0.911 | 0.794 | 0.731 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hird, J.N.; DeLancey, E.R.; McDermid, G.J.; Kariyeva, J. Google Earth Engine, Open-Access Satellite Data, and Machine Learning in Support of Large-Area Probabilistic Wetland Mapping. Remote Sens. 2017, 9, 1315. https://doi.org/10.3390/rs9121315
Hird JN, DeLancey ER, McDermid GJ, Kariyeva J. Google Earth Engine, Open-Access Satellite Data, and Machine Learning in Support of Large-Area Probabilistic Wetland Mapping. Remote Sensing. 2017; 9(12):1315. https://doi.org/10.3390/rs9121315
Chicago/Turabian StyleHird, Jennifer N., Evan R. DeLancey, Gregory J. McDermid, and Jahan Kariyeva. 2017. "Google Earth Engine, Open-Access Satellite Data, and Machine Learning in Support of Large-Area Probabilistic Wetland Mapping" Remote Sensing 9, no. 12: 1315. https://doi.org/10.3390/rs9121315
APA StyleHird, J. N., DeLancey, E. R., McDermid, G. J., & Kariyeva, J. (2017). Google Earth Engine, Open-Access Satellite Data, and Machine Learning in Support of Large-Area Probabilistic Wetland Mapping. Remote Sensing, 9(12), 1315. https://doi.org/10.3390/rs9121315