
Effect of Training Class Label Noise on Classification Performances for Land Cover Mapping with Satellite Image Time Series



Abstract
:
1. Introduction
2. Experimental Set-Up
2.1. Data
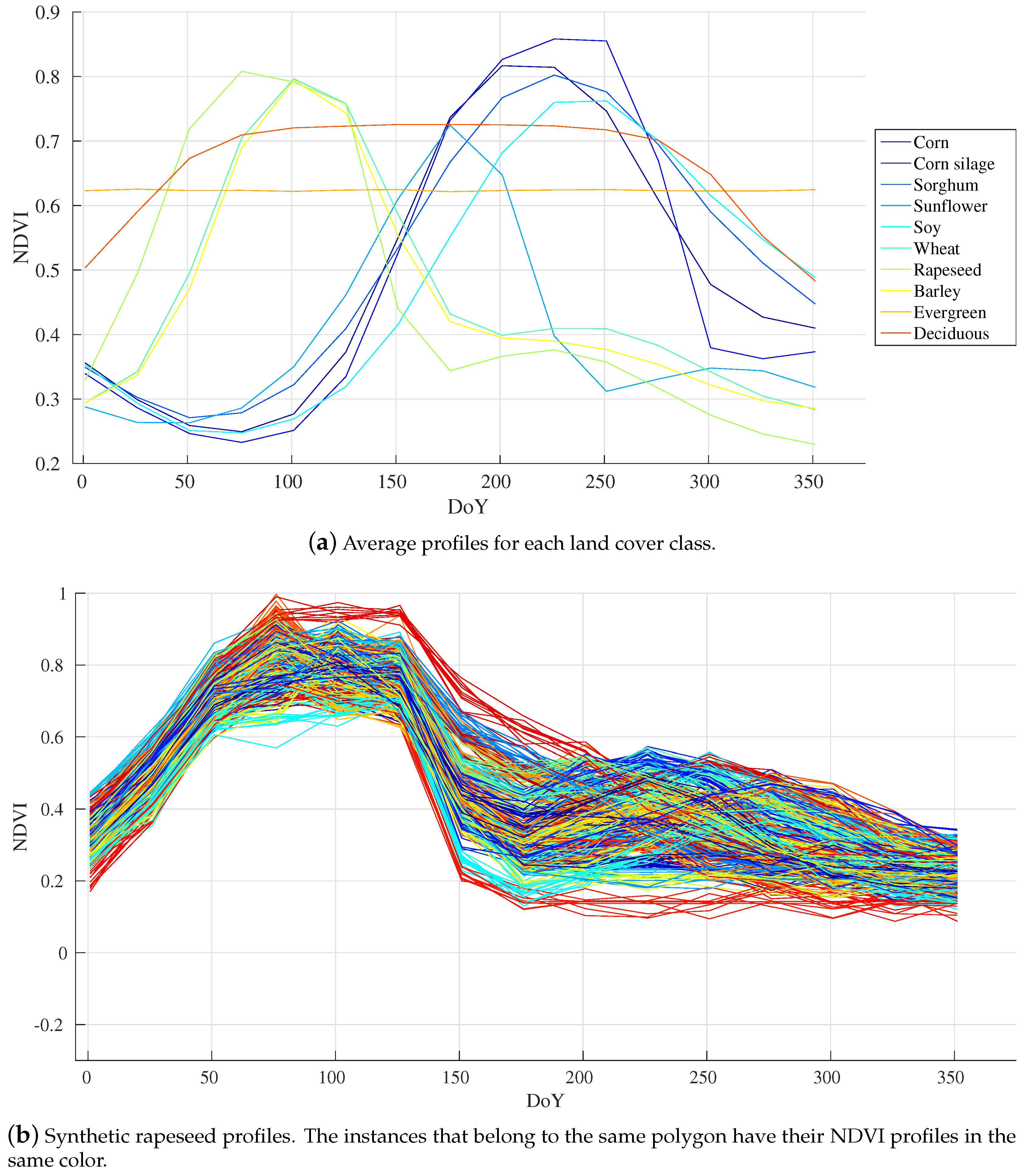
2.1.1. Synthetic Datasets
2.1.2. Real Datasets
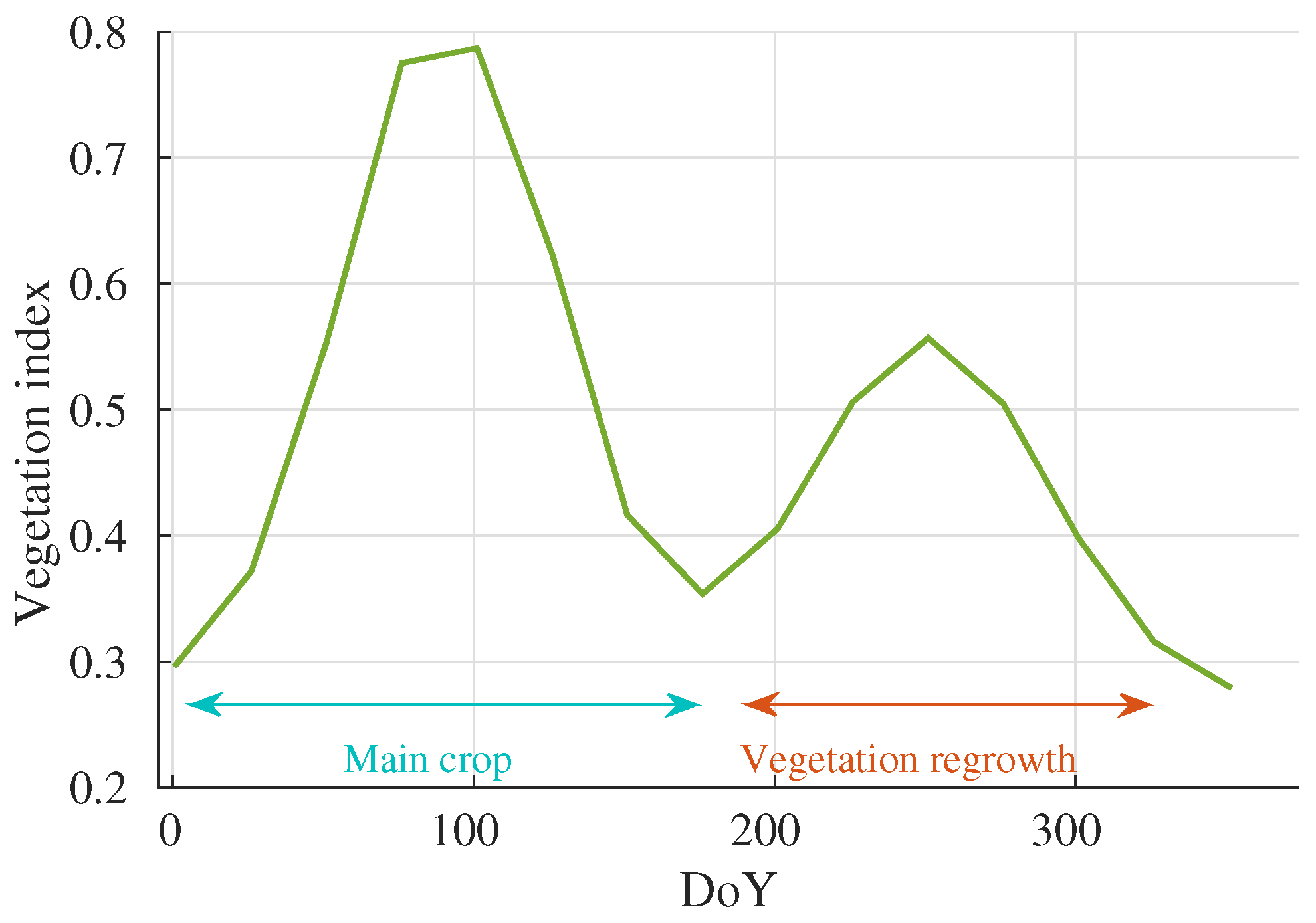
2.2. Noise Injection Procedure
3. Classification Scheme
3.1. Classifier Algorithms
3.1.1. Support Vector Machines
3.1.2. Random Forests
3.2. Sampling Strategy
3.3. Evaluation
4. Results and Discussions
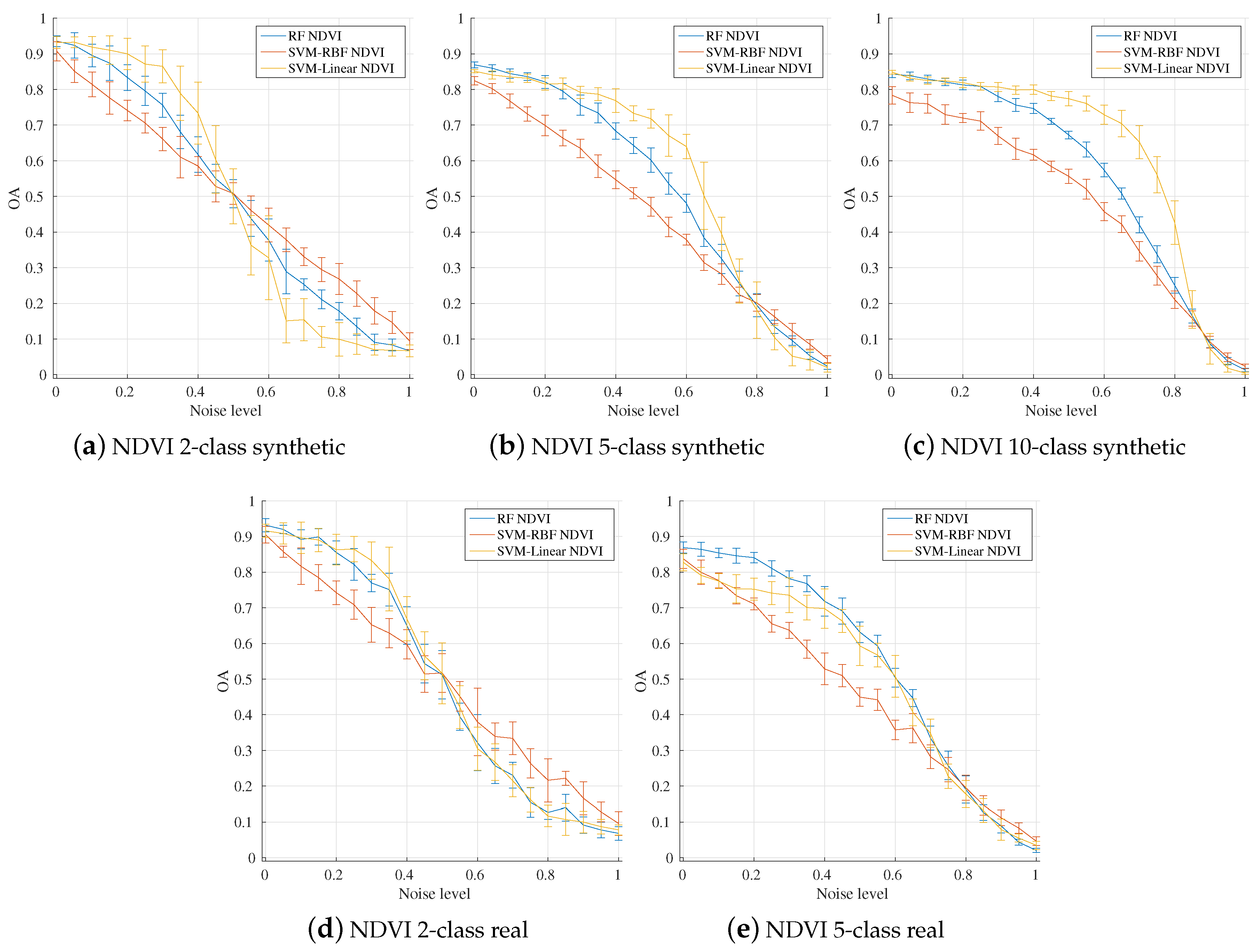
4.1. Influence of the Number of Classes
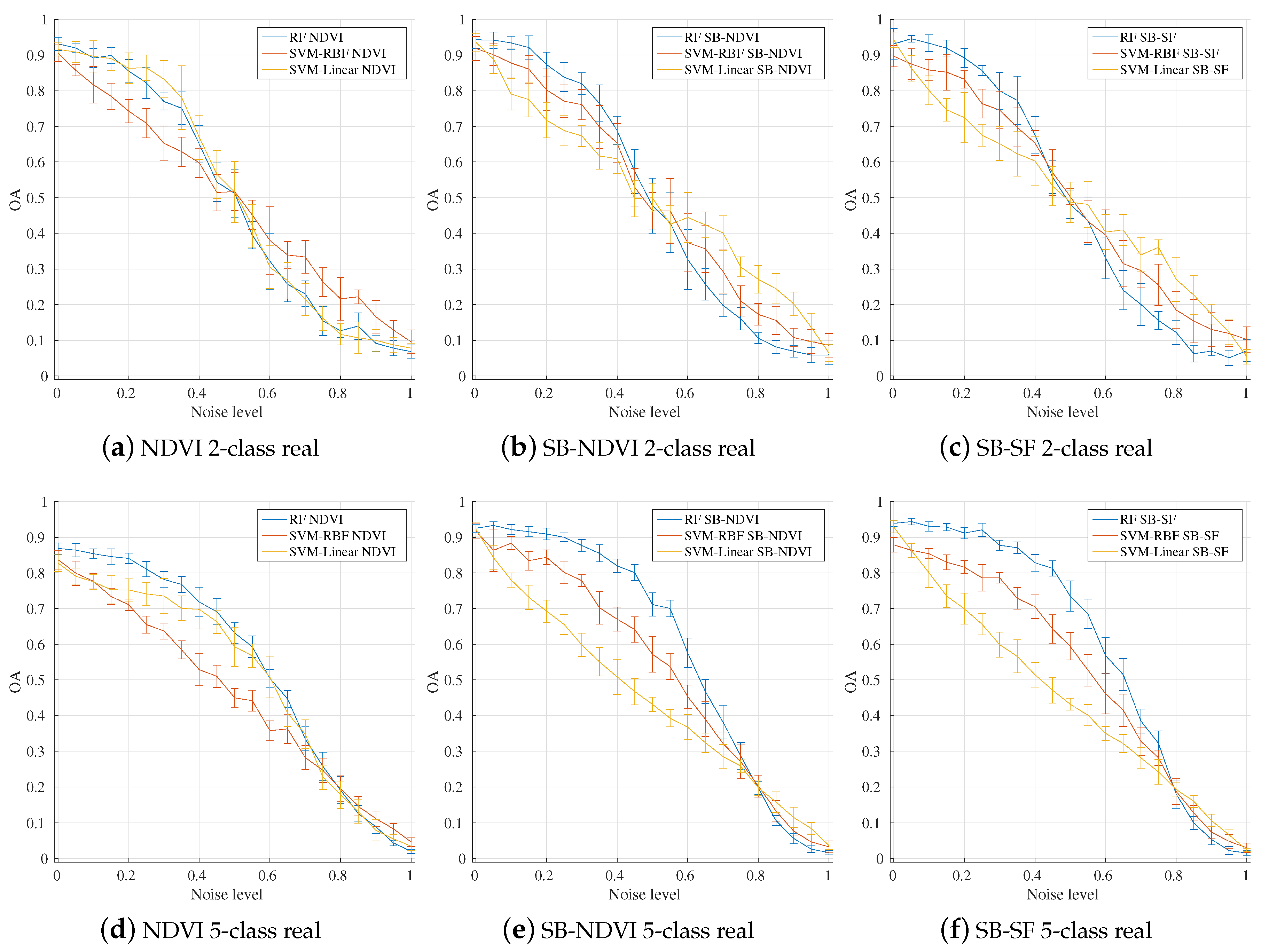
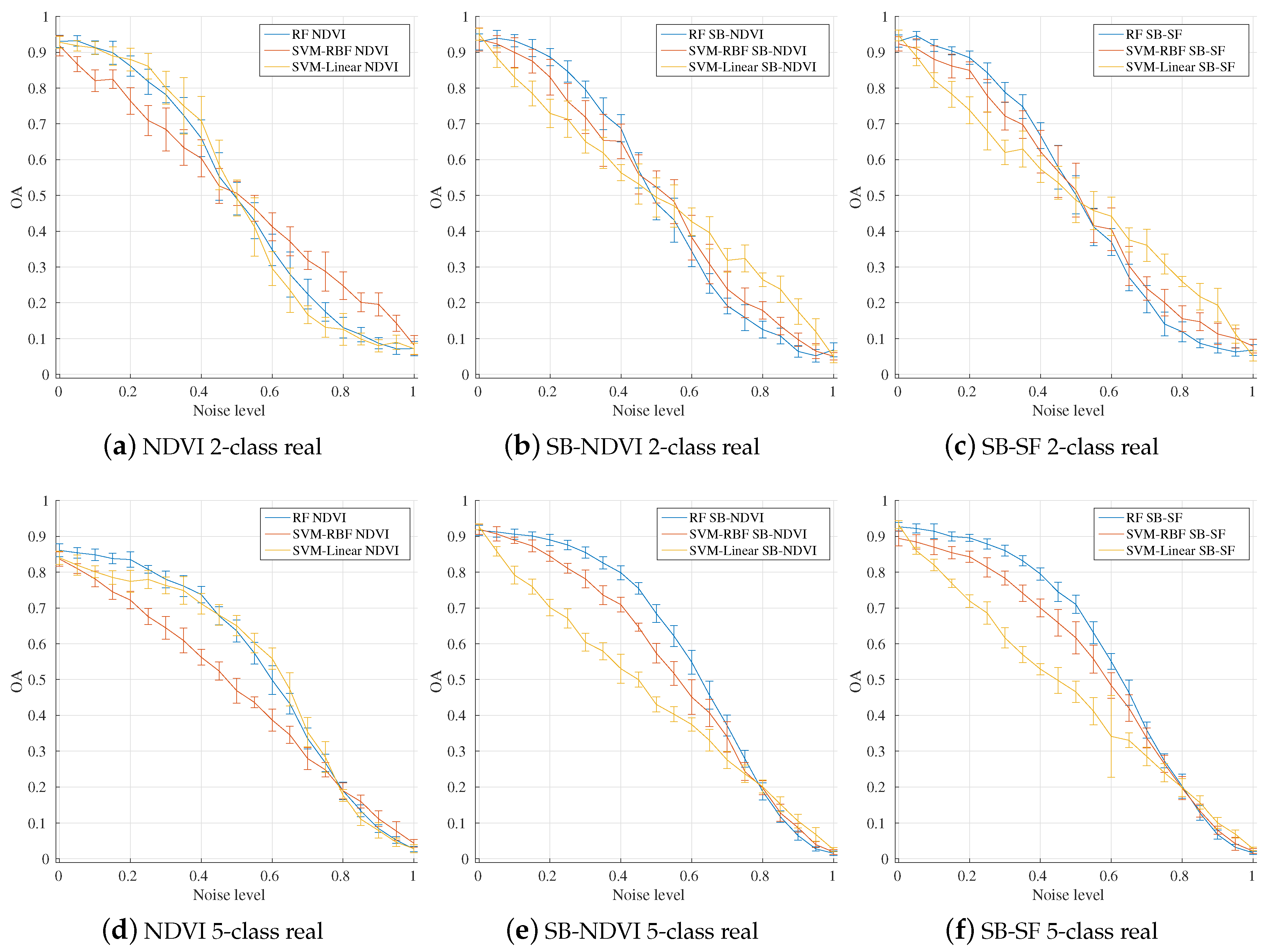
4.2. Influence of Input Feature Vectors
4.3. Influence of the Number of Training Instances
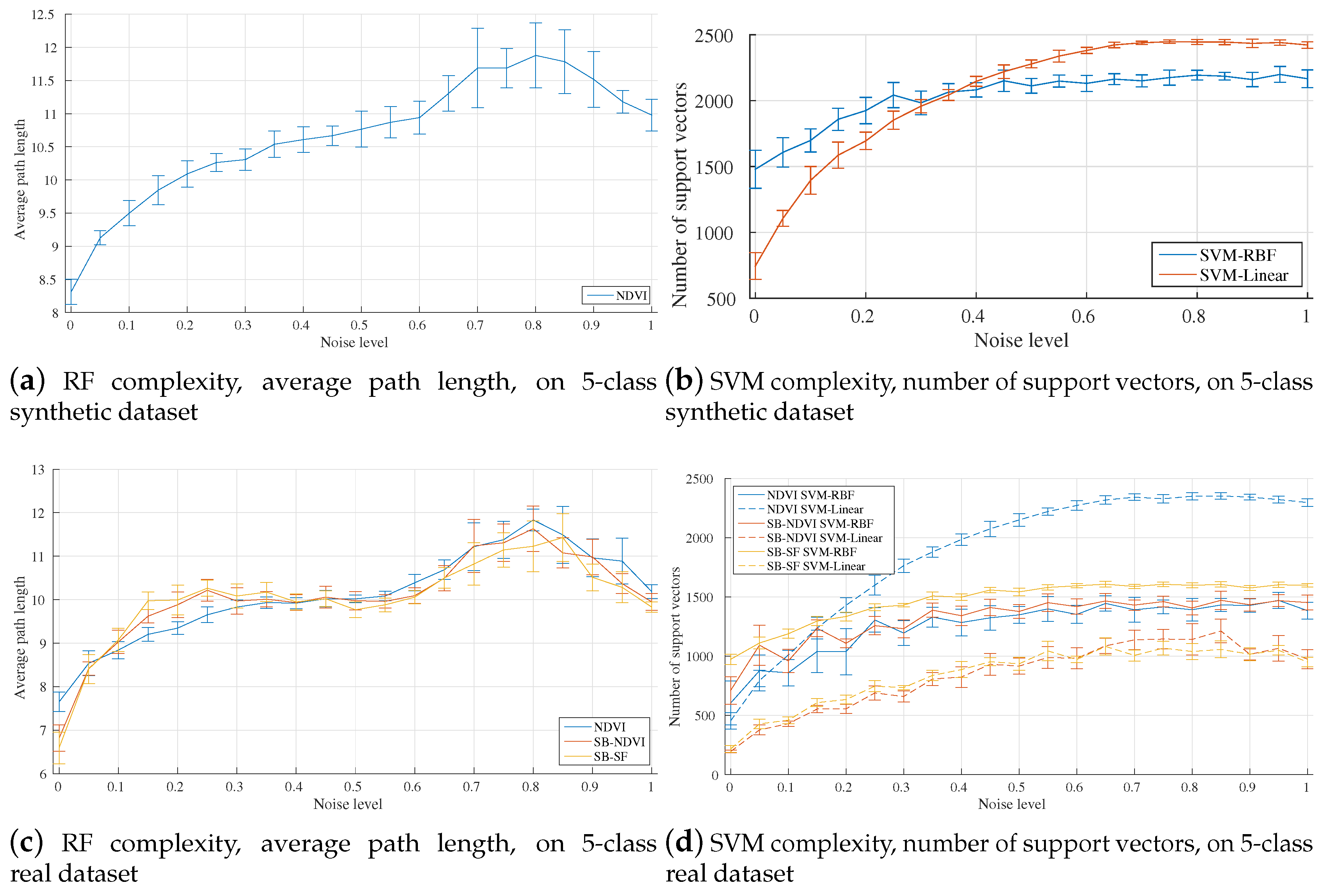
4.4. Algorithm Complexity
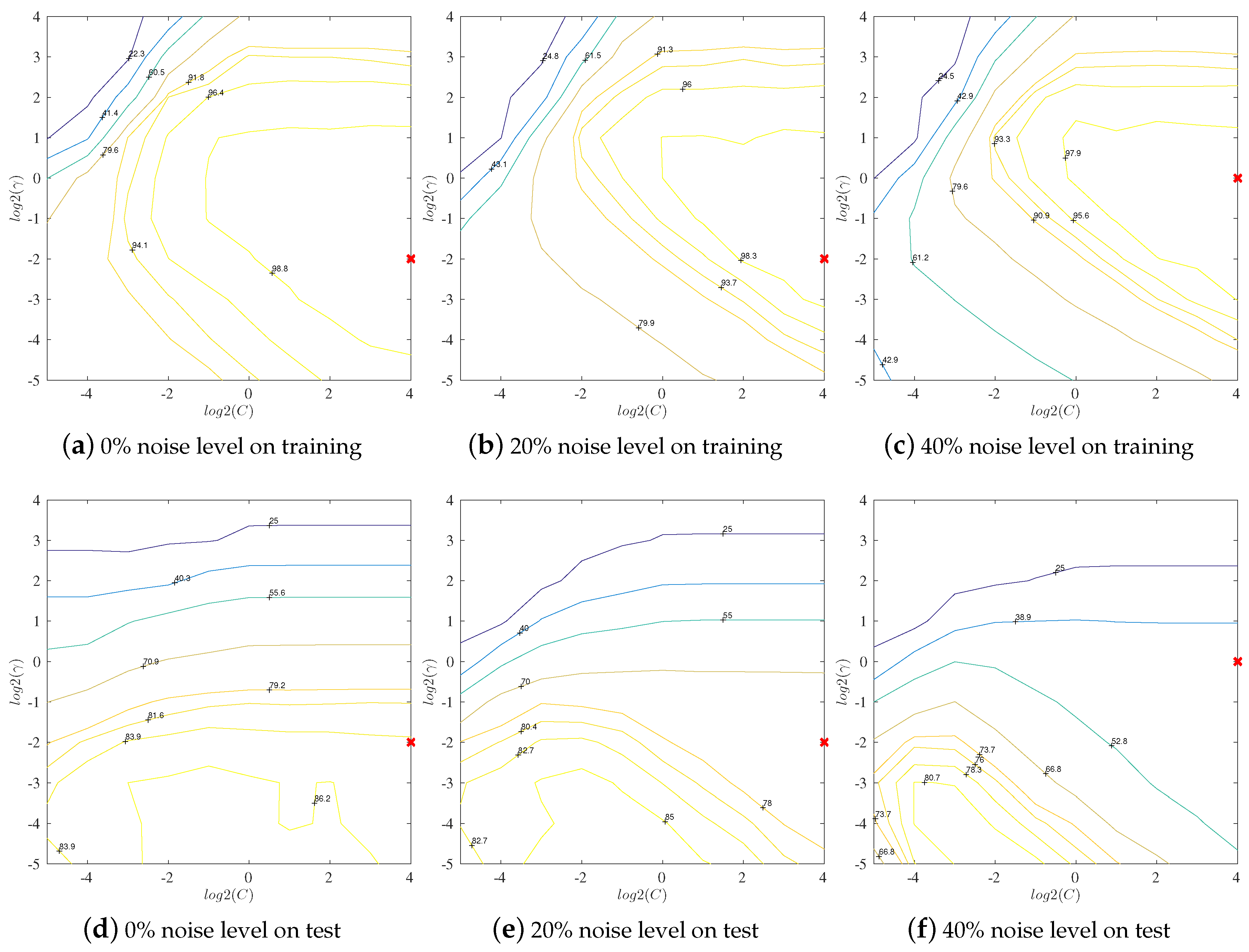
4.5. Study of Systematic Label Noise
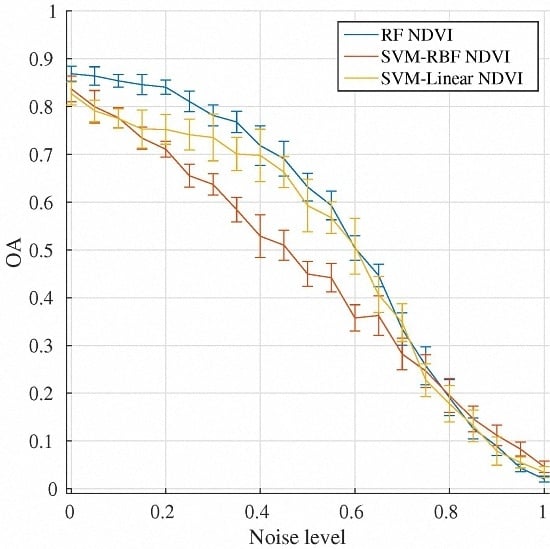
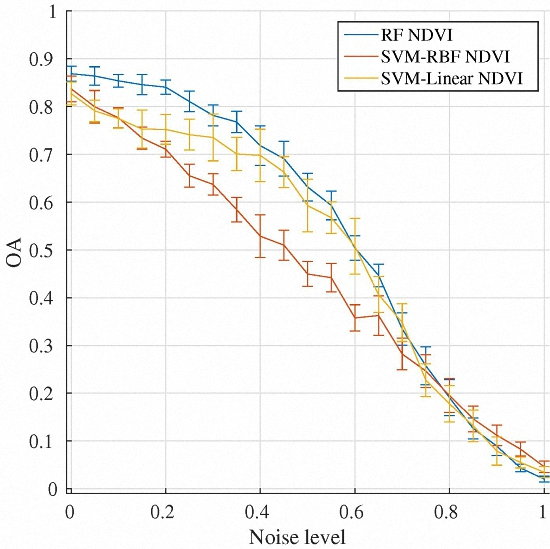
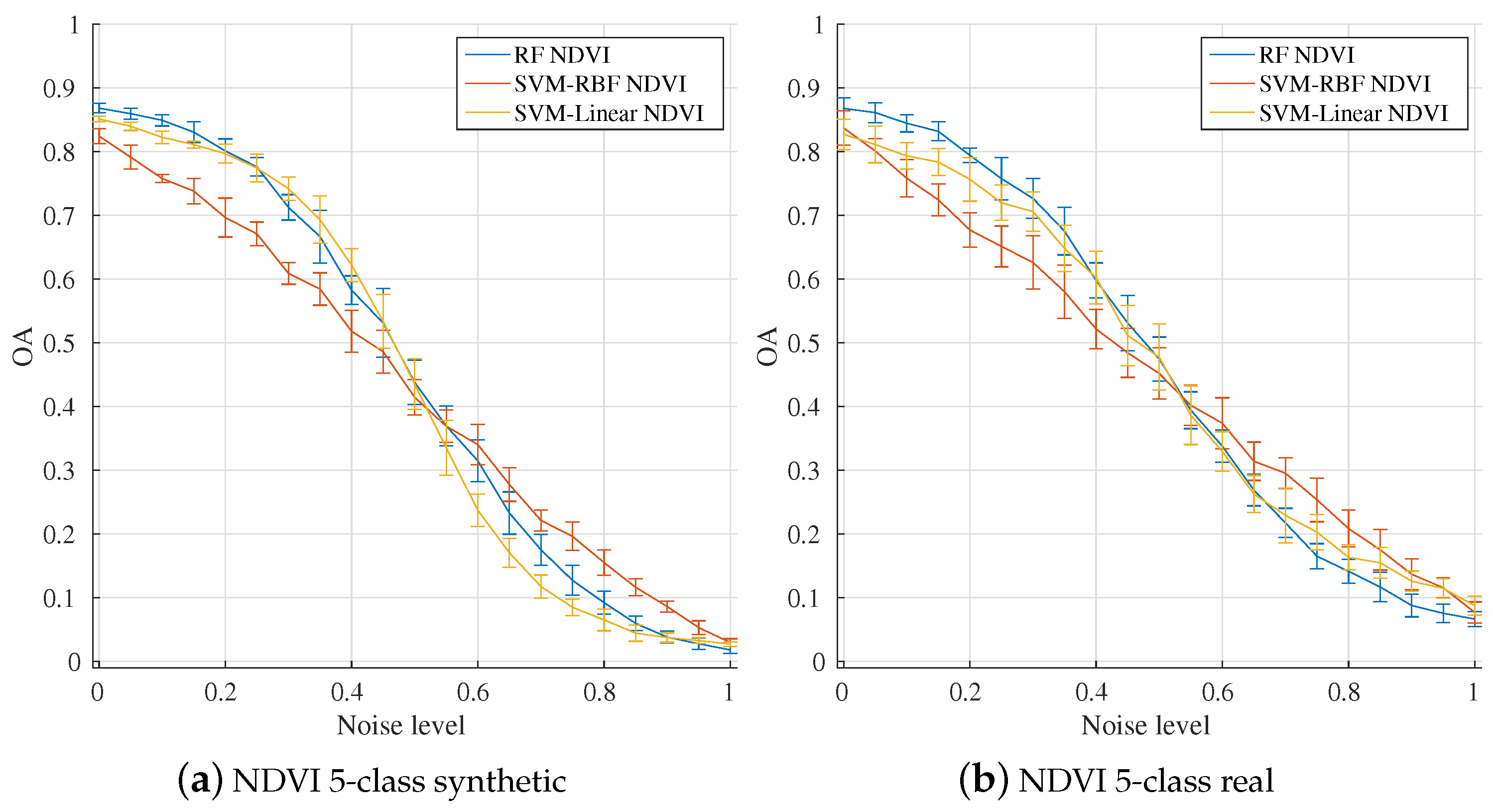
4.6. Comparison between Classifiers
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| RF | Random Forests |
| SVM | Support Vector Machines |
| RBF | Radial Basis Function |
| USGS | United States Geological Survey |
| MACCS | Multi-sensor Atmospheric Correction and Cloud Screening |
| NDVI | Normalized Difference Vegetation Index |
| SB | Spectral Bands |
| SF | Spectral Features |
References
- Alcantara, C.; Kuemmerle, T.; Prishchepov, A.V.; Radeloff, V.C. Mapping abandoned agriculture with multi-temporal MODIS satellite data. Remote Sens. Environ. 2012, 124, 334–347. [Google Scholar] [CrossRef]
- Qamer, F.M.; Shehzad, K.; Abbas, S.; Murthy, M.; Xi, C.; Gilani, H.; Bajracharya, B. Mapping deforestation and forest degradation patterns in western Himalaya, Pakistan. Remote Sens. 2016, 8, 385. [Google Scholar] [CrossRef]
- Lefebvre, A.; Sannier, C.; Corpetti, T. Monitoring urban areas with Sentinel-2A data: Application to the update of the Copernicus high resolution layer imperviousness degree. Remote Sens. 2016, 8, 606. [Google Scholar] [CrossRef]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Waske, B.; Braun, M. Classifier ensembles for land cover mapping using multitemporal SAR imagery. ISPRS J. Photogramm. Remote Sens. 2009, 64, 450–457. [Google Scholar] [CrossRef]
- Li, M.; Zang, S.; Zhang, B.; Li, S.; Wu, C. A review of remote sensing image classification techniques: The role of spatio-contextual information. Eur. J. Remote Sens. 2014, 47, 389–411. [Google Scholar] [CrossRef]
- Szuster, B.W.; Chen, Q.; Borger, M. A comparison of classification techniques to support land cover and land use analysis in tropical coastal zones. Appl. Geogr. 2011, 31, 525–532. [Google Scholar] [CrossRef]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef]
- Sharma, R.C.; Tateishi, R.; Hara, K.; Iizuka, K. Production of the Japan 30-m land cover map of 2013–2015 using a Random Forests-based feature optimization approach. Remote Sens. 2016, 8, 429. [Google Scholar] [CrossRef]
- Inglada, J.; Arias, M.; Tardy, B.; Hagolle, O.; Valero, S.; Morin, D.; Dedieu, G.; Sepulcre, G.; Bontemps, S.; Defourny, P.; et al. Assessment of an operational system for crop type map production using high temporal and spatial resolution satellite optical imagery. Remote Sens. 2015, 7, 12356–12379. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random Forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Tatsumi, K.; Yamashiki, Y.; Torres, M.A.C.; Taipe, C.L.R. Crop classification of upland fields using Random forest of time-series Landsat 7 ETM+ data. Comput. Electron. Agric. 2015, 115, 171–179. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J. An assessment of the effectiveness of a Random Forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Pal, M. Random Forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Meyer, H.; Kühnlein, M.; Appelhans, T.; Nauss, T. Comparison of four machine learning algorithms for their applicability in satellite-based optical rainfall retrievals. Atmos. Res. 2016, 169, 424–433. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Demir, B.; Persello, C.; Bruzzone, L. Batch-Mode active-learning methods for the interactive classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1014–1031. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Munoz-Mari, J. A survey of active learning algorithms for supervised remote sensing image classification. IEEE J. Sel. Top. Signal Process. 2011, 5, 606–617. [Google Scholar] [CrossRef]
- Radoux, J.; Lamarche, C.; Van Bogaert, E.; Bontemps, S.; Brockmann, C.; Defourny, P. Automated training sample extraction for global land cover mapping. Remote Sens. 2014, 6, 3965. [Google Scholar] [CrossRef]
- Fritz, S.; McCallum, I.; Schill, C.; Perger, C.; Grillmayer, R.; Achard, F.; Kraxner, F.; Obersteiner, M. Geo-Wiki.Org: The use of crowdsourcing to improve global land cover. Remote Sens. 2009, 1, 345–354. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Zhu, X.; Wu, X. Class noise vs. attribute noise: A quantitative study. Artif. Intell. Rev. 2004, 22, 177–210. [Google Scholar] [CrossRef]
- Nettleton, D.F.; Orriols-Puig, A.; Fornells, A. A study of the effect of different types of noise on the precision of supervised learning techniques. Artif. Intell. Rev. 2010, 33, 275–306. [Google Scholar] [CrossRef]
- Frénay, B.; Verleysen, M. Classification in the presence of label noise: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 845–869. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Wu, X.; Chen, Q. Eliminating class noise in large datasets. In Proceedings of the Twentieth International Conference on Machine Learning (ICML), Washington, DC, USA, 21–24 August 2003; pp. 920–927.
- Xiao, T.; Xia, T.; Yang, Y.; Huang, C.; Wang, X. Learning from massive noisy labeled data for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2691–2699.
- Teng, C.M. Correcting noisy data. In Proceedings of the International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; pp. 239–248.
- Rebbapragada, U.; Brodley, C.E. Class noise mitigation through instance weighting. In Proceedings of the European Conference on Machine Learning, Warsaw, Poland, 17–21 September 2007; pp. 708–715.
- Brodley, C.E.; Friedl, M.A. Identifying and eliminating mislabeled training instances. In Proceedings of the American Association for Artificial Intelligence (AAAI)/Innovative Applications of Artificial Intelligence (IAAI), Portland, OR, USA, 04–08 August 1996; American Association for Artificial Intelligence: Menlo Park, CA, USA, 1996; pp. 799–805. [Google Scholar]
- Brodley, C.E.; Friedl, M.A. Identifying mislabeled training data. J. Artif. Intell. Res. 1999, 11, 131–167. [Google Scholar]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring issues of training data imbalance and mislabelling on Random Forest performance for large area land cover classification using the ensemble margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Xiao, H.; Xiao, H.; Eckert, C. Adversarial Label Flips Attack on Support Vector Machines. In Proceedings of the Twentieth European Conference on Artificial Intelligence (ECAI), Montpellier, France, 27–31 August 2012; pp. 870–875.
- Biggio, B.; Nelson, B.; Laskov, P. Support Vector Machines under adversarial label noise. ACML 2011, 20, 97–112. [Google Scholar]
- Görnitz, N.; Porbadnigk, A.; Binder, A.; Sannelli, C.; Braun, M.L.; Müller, K.R.; Kloft, M. Learning and Evaluation in Presence of Non-IID Label Noise. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Reykjavik, Iceland, 22–25 April 2014; pp. 293–302.
- Teng, C.M. A Comparison of Noise Handling Techniques. In Proceedings of the International Florida Artificial Intelligence Research Society Conference, Key West, FL, USA, 21–23 May 2001; pp. 269–273.
- Folleco, A.; Khoshgoftaar, T.M.; Hulse, J.V.; Napolitano, A. Identifying Learners Robust to Low Quality Data. Informatica 2009, 33, 245–259. [Google Scholar]
- Garcia, L.P.; de Carvalho, A.C.; Lorena, A.C. Effect of label noise in the complexity of classification problems. Neurocomputing 2015, 160, 108–119. [Google Scholar] [CrossRef]
- Pechenizkiy, M.; Tsymbal, A.; Puuronen, S.; Pechenizkiy, O. Class noise and supervised learning in medical domains: The effect of feature extraction. In Proceedings of the 19th IEEE Symposium on Computer-Based Medical Systems (CBMS’06), Salt Lake City, UT, USA, 22–23 June 2006; pp. 708–713.
- Carlotto, M.J. Effect of errors in ground truth on classification accuracy. Int. J. Remote Sens. 2009, 30, 4831–4849. [Google Scholar] [CrossRef]
- Natarajan, N.; Dhillon, I.S.; Ravikumar, P.K.; Tewari, A. Learning with Noisy Labels. In Advances in Neural Information Processing Systems 26; Curran Associates, Inc.: Lake Tahoe, USA, 2013; pp. 1196–1204. [Google Scholar]
- Xiao, H.; Biggio, B.; Nelson, B.; Xiao, H.; Eckert, C.; Roli, F. Support Vector Machines under adversarial label contamination. Neurocomputing 2015, 160, 53–62. [Google Scholar] [CrossRef]
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: Predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar]
- DeFries, R.; Townshend, J. NDVI-derived land cover classifications at a global scale. Int. J. Remote Sens. 1994, 15, 3567–3586. [Google Scholar] [CrossRef]
- Senf, C.; Leitão, P.J.; Pflugmacher, D.; van der Linden, S.; Hostert, P. Mapping land cover in complex Mediterranean landscapes using Landsat: Improved classification accuracies from integrating multi-seasonal and synthetic imagery. Remote Sens. Environ. 2015, 156, 527–536. [Google Scholar] [CrossRef]
- Jönsson, P.; Eklundh, L. TIMESAT—A program for analyzing time-series of satellite sensor data. Comput. Geosci. 2004, 30, 833–845. [Google Scholar] [CrossRef]
- Zhang, X.; Friedl, M.A.; Schaaf, C.B.; Strahler, A.H.; Hodges, J.C.; Gao, F.; Reed, B.C.; Huete, A. Monitoring vegetation phenology using MODIS. Remote Sens. Environ. 2003, 84, 471–475. [Google Scholar] [CrossRef]
- Fisher, J.I.; Mustard, J.F.; Vadeboncoeur, M.A. Green leaf phenology at Landsat resolution: Scaling from the field to the satellite. Remote Sens. Environ. 2006, 100, 265–279. [Google Scholar] [CrossRef]
- Beck, P.S.; Atzberger, C.; Høgda, K.A.; Johansen, B.; Skidmore, A.K. Improved monitoring of vegetation dynamics at very high latitudes: A new method using MODIS NDVI. Remote Sens. Environ. 2006, 100, 321–334. [Google Scholar] [CrossRef]
- Inglada, J. PhenOTB, Phenological Analysis for Image Time Series. 2016. Available online: http://tully.ups-tlse.fr/jordi/phenotb (assessed on 16 February 2017).
- Hagolle, O.; Sylvander, S.; Huc, M.; Claverie, M.; Clesse, D.; Dechoz, C.; Lonjou, V.; Poulain, V. SPOT-4 (Take 5): Simulation of Sentinel-2 time series on 45 large sites. Remote Sens. 2015, 7, 12242–12264. [Google Scholar] [CrossRef]
- Hagolle, O.; Huc, M.; Villa Pascual, D.; Dedieu, G. A multi-temporal and multi-spectral method to estimate aerosol optical thickness over land, for the atmospheric correction of FormoSat-2, LandSat, VENμS and Sentinel-2 images. Remote Sens. 2015, 7, 2668. [Google Scholar] [CrossRef]
- Inglada, J. OTB Gapfilling, A Temporal Gapfilling for Image Time Series Library. 2016. Available online: http://tully.ups-tlse.fr/jordi/temporalgapfilling (assessed on 16 February 2017).
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Smith, M.R.; Martinez, T. Improving classification accuracy by identifying and removing instances that should be misclassified. In Proceedings of the 2011 International Joint Conference on Neural Networks (IJCNN), San Jose, CA, USA, 31 July–5 August 2011; pp. 2690–2697.
- Feng, W.; Boukir, S.; Guo, L. Identification and correction of mislabeled training data for land cover classification based on ensemble margin. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium 2015 (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4991–4994.
- Hüttich, C.; Gessner, U.; Herold, M.; Strohbach, B.J.; Schmidt, M.; Keil, M.; Dech, S. On the suitability of MODIS time series metrics to map vegetation types in dry savanna ecosystems: A case study in the Kalahari of NE Namibia. Remote Sens. 2009, 1, 620–643. [Google Scholar] [CrossRef]
- Corcoran, J.M.; Knight, J.F.; Gallant, A.L. Influence of multi-source and multi-temporal remotely sensed and ancillary data on the accuracy of Random Forest classification of wetlands in Northern Minnesota. Remote Sens. 2013, 5, 3212–3238. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First experience with Sentinel-2 data for crop and tree species classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.S.; Townshend, J. An assessment of Support Vector Machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Jia, K.; Liang, S.; Wei, X.; Yao, Y.; Su, Y.; Jiang, B.; Wang, X. Land cover classification of Landsat data with phenological features extracted from time series MODIS NDVI data. Remote Sens. 2014, 6, 11518–11532. [Google Scholar] [CrossRef]
- Dusseux, P.; Corpetti, T.; Hubert-Moy, L.; Corgne, S. Combined use of multi-temporal optical and radar satellite images for grassland monitoring. Remote Sens. 2014, 6, 6163–6182. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer-Verlag: New York, NY, USA, 1995. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: London, UK, 2002. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R. Classification and Regression Trees; Chapman & Hall/CRC: Bocar Raton, FL, USA, 1984. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by Random Forest. R News 2002, 2, 18–22. [Google Scholar]
- Cutler, D.R.; Edwards, T.C., Jr.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- Boulesteix, A.L.; Janitza, S.; Kruppa, J.; König, I.R. Overview of Random Forest methodology and practical guidance with emphasis on computational biology and bioinformatics. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 493–507. [Google Scholar] [CrossRef] [Green Version]
- Bhattacharyya, S.; Jha, S.; Tharakunnel, K.; Westland, J.C. Data mining for credit card fraud: A comparative study. Decis. Support Syst. 2011, 50, 602–613. [Google Scholar] [CrossRef]
- Segal, M.R. Machine Learning Benchmarks and Random Forest Regression; Technical report; Center for Bioinformatics and Molecular Biostatistics, UC San Fransisco: San Fransisco, CA, USA, 2004. [Google Scholar]
- Cawley, G.C.; Talbot, N.L. On over-fitting in model selection and subsequent selection bias in performance evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
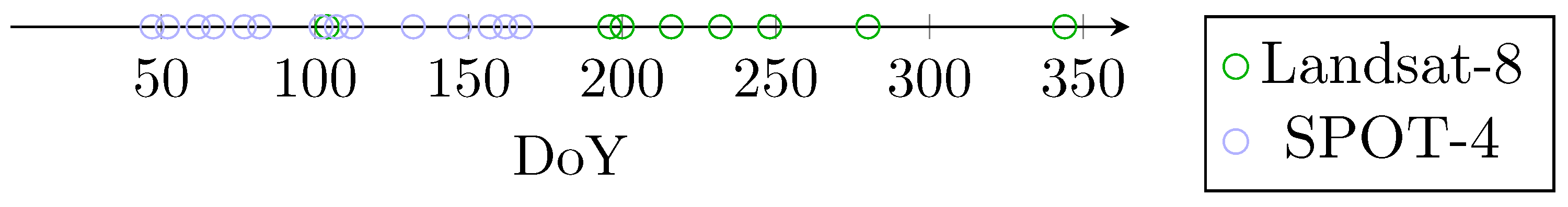{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A | B | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Summer crops | Corn | 0.57 | 0.72 | 0.15 | 0.30 | 100 | 200 | 05 | 25 | 250 | 310 | 10 | 30 |
| Corn silage | 0.57 | 0.72 | 0.15 | 0.30 | 100 | 200 | 05 | 25 | 250 | 310 | 05 | 10 | |
| Sorghum | 0.62 | 0.77 | 0.15 | 0.30 | 120 | 190 | 20 | 40 | 290 | 295 | 25 | 30 | |
| Sunflower | 0.67 | 0.82 | 0.15 | 0.30 | 102 | 192 | 15 | 40 | 180 | 240 | 05 | 20 | |
| Soy | 0.67 | 0.82 | 0.15 | 0.30 | 140 | 220 | 15 | 45 | 270 | 320 | 20 | 45 | |
| Winter crops | Wheat | 0.52 | 0.67 | 0.20 | 0.35 | 30 | 90 | 05 | 25 | 125 | 175 | 05 | 25 |
| Rapeseed | 0.70 | 0.80 | 0.05 | 0.20 | 30 | 45 | 15 | 25 | 80 | 90 | 03 | 12 | |
| 0.60 | 0.70 | 0.05 | 0.15 | 85 | 95 | 03 | 12 | 135 | 145 | 05 | 15 | ||
| Barley | 0.52 | 0.67 | 0.20 | 0.35 | 30 | 90 | 05 | 25 | 120 | 170 | 05 | 25 | |
| Forests | Evergreen | 0.01 | 0.015 | 0.55 | 0.70 | 0 | 365 | 100 | 150 | 0 | 365 | 100 | 150 |
| Deciduous | 0.20 | 0.35 | 0.40 | 0.50 | 23 | 27 | 15 | 20 | 315 | 320 | 15 | 20 | |
| 2-Class Dataset | 5-Class Dataset | 10-Class Dataset | |
|---|---|---|---|
| Land cover class | Corn Corn silage | Corn Corn silage Sorghum Sunflower Soy | Corn Corn silage Sorghum Sunflower Soy Wheat Rapeseed Barley Evergreen Deciduous |
| Class Name | No. of Available Polygons |
|---|---|
| Wheat | 1197 |
| Corn | 883 |
| Barley | 125 |
| Rapeseed | 164 |
| Sunflower | 851 |
| Dataset Number | Dataset Name | Land Cover Classes | n | Feature Vector Size | |
|---|---|---|---|---|---|
| 1 | NDVI 2-class 2000-instance | C/S | 10 | 100 | 23 |
| 2 | SB-NDVI 2-class 2000-instance | C/S | 10 | 100 | 139 |
| 3 | SB-SF 2-class 2000-instance | C/S | 10 | 100 | 302 |
| 4 | NDVI 5-class 5000-instance | W/C/B/ R/S | 10 | 100 | 23 |
| 5 | SB-NDVI 5-class 5000-instance | W/C/B/ R/S | 10 | 100 | 139 |
| 6 | SB-SF 5-class 5000-instance | W/C/B/ R/S | 10 | 100 | 302 |
| 7 | NDVI 2-class 9600-instances | C/S | 40 | 120 | 23 |
| 8 | SB-NDVI 2-class 9600-instance | C/S | 40 | 120 | 139 |
| 9 | SB-SF 2-class 9600-instance | C/S | 40 | 120 | 302 |
| 10 | NDVI 5-class 24000-instance | W/C/B/ R/S | 40 | 120 | 23 |
| 11 | SB-NDVI 5-class 24000-instance | W/C/B/ R/S | 40 | 120 | 139 |
| 12 | SB-SF 5-class 24000-instance | W/C/B/ R/S | 40 | 120 | 302 |
| Synthetic Dataset | Real Dataset | ||
|---|---|---|---|
| Original Label | Flip Label | Original Label | Flip Label |
| corn | corn silage | wheat | rapeseed |
| corn silage | sorghum | corn | sunflower |
| sorghum | sunflower | barley | wheat |
| sunflower | soy | rapeseed | barley |
| soy | corn | sunflower | corn |
| Noise Level | 0% | 10% | 20% | 30% | 40% | 50% |
|---|---|---|---|---|---|---|
| NDVI | 0.0825 | 0.5000 | 0.1895 | 0.3789 | 0.3299 | 0.4353 |
| SB-NDVI | 0.0156 | 0.0179 | 0.0179 | 0.0179 | 0.0312 | 0.0359 |
| SB-SF | 0.0156 | 0.0179 | 0.0156 | 0.0156 | 0.0156 | 0.0179 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Marais Sicre, C.; Dedieu, G. Effect of Training Class Label Noise on Classification Performances for Land Cover Mapping with Satellite Image Time Series. Remote Sens. 2017, 9, 173. https://doi.org/10.3390/rs9020173
Pelletier C, Valero S, Inglada J, Champion N, Marais Sicre C, Dedieu G. Effect of Training Class Label Noise on Classification Performances for Land Cover Mapping with Satellite Image Time Series. Remote Sensing. 2017; 9(2):173. https://doi.org/10.3390/rs9020173
Chicago/Turabian StylePelletier, Charlotte, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre, and Gérard Dedieu. 2017. "Effect of Training Class Label Noise on Classification Performances for Land Cover Mapping with Satellite Image Time Series" Remote Sensing 9, no. 2: 173. https://doi.org/10.3390/rs9020173
APA StylePelletier, C., Valero, S., Inglada, J., Champion, N., Marais Sicre, C., & Dedieu, G. (2017). Effect of Training Class Label Noise on Classification Performances for Land Cover Mapping with Satellite Image Time Series. Remote Sensing, 9(2), 173. https://doi.org/10.3390/rs9020173