
Scalable Bag of Subpaths Kernel for Learning on Hierarchical Image Representations and Multi-Source Remote Sensing Data Classification



Abstract
:
1. Introduction
2. Related Work
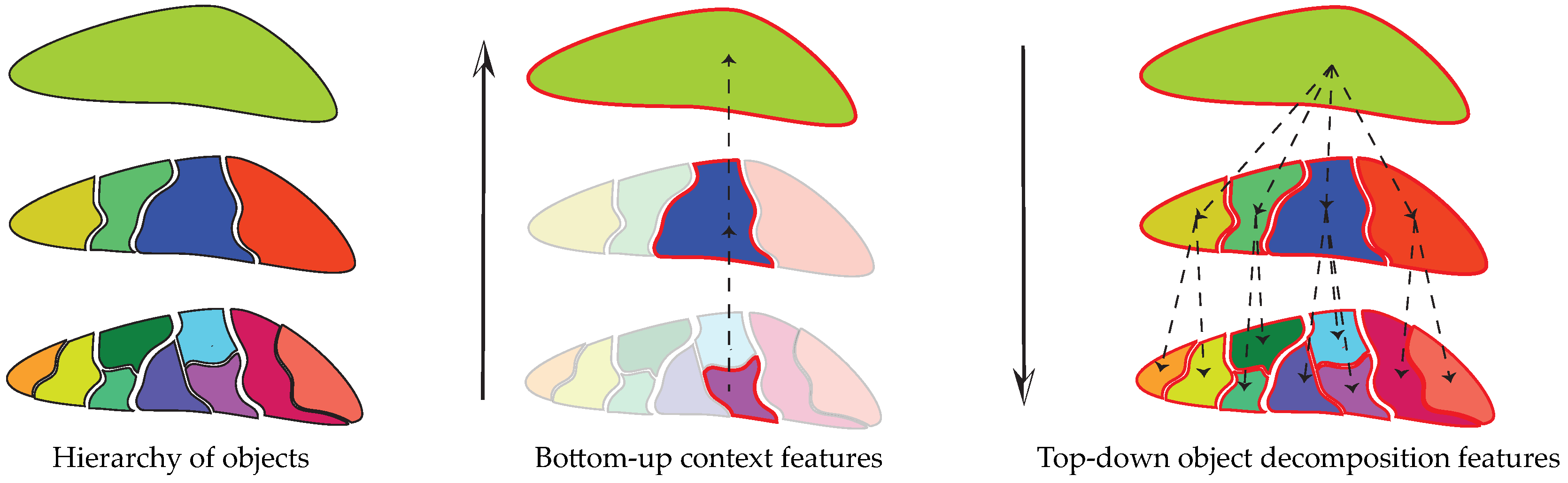
2.1. Context Features
2.2. Object Decomposition Features
2.3. Data Fusion with Multiple Remote Sensing Images
2.4. Large-Scale Kernels
3. Kernel Definition and Approximation
3.1. Bag of Subpaths Kernel
3.2. Ensuring Scalability Using Random Fourier Features
3.3. Kernel Normalization
3.4. Complexity
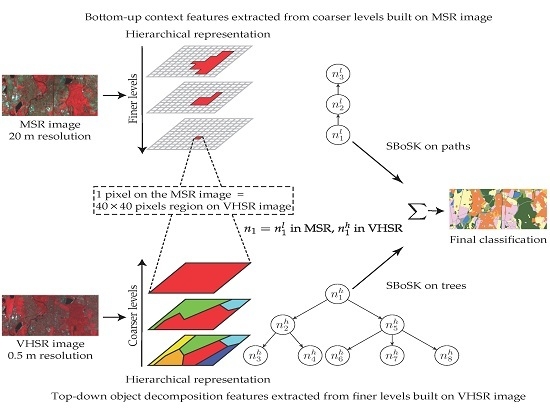
4. Image Classification with Multi-Source Images
- an MSR image, captured by a Spot-4 sensor, containing pixels at a 20-m spatial resolution, described by four spectral bands: green, red, NIR, MIR (Figure 4a).
- a VHSR image, captured by a Pleiades satellite, containing pixels at a 0.5-m spatial resolution (obtained with pan-sharpening technique), described by four spectral bands: red, green, blue, NIR (Figure 4b).
- On the MSR image, we generate, from the bottom (leaves) level of single pixels, seven additional levels of multiscale segmentation by increasing the region dissimilarity criteria . We observe that with such parameters, the number of segmented regions is roughly decreasing by a factor of two between each level.
- On the VHSR image, we generate, from the top (root) level of each square region of size pixels (i.e., equivalent to a single pixel in Strasbourg Spot-4 dataset), four additional levels of multiscale segmentation by decreasing the region dissimilarity criteria . Using such parameters, we observe that the number of segmented regions is roughly increasing by a factor of two between each level.
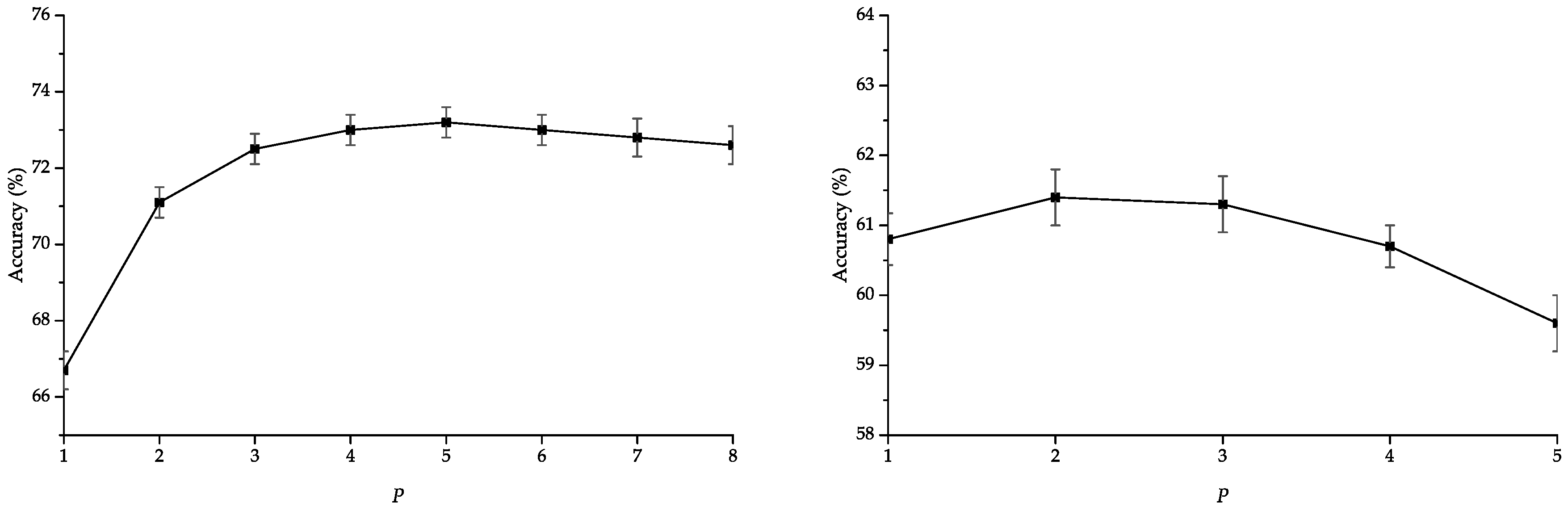
4.1. Random Fourier Features Analysis
4.2. Bottom-Up Context Features
4.3. Top-Down Object Decomposition Features
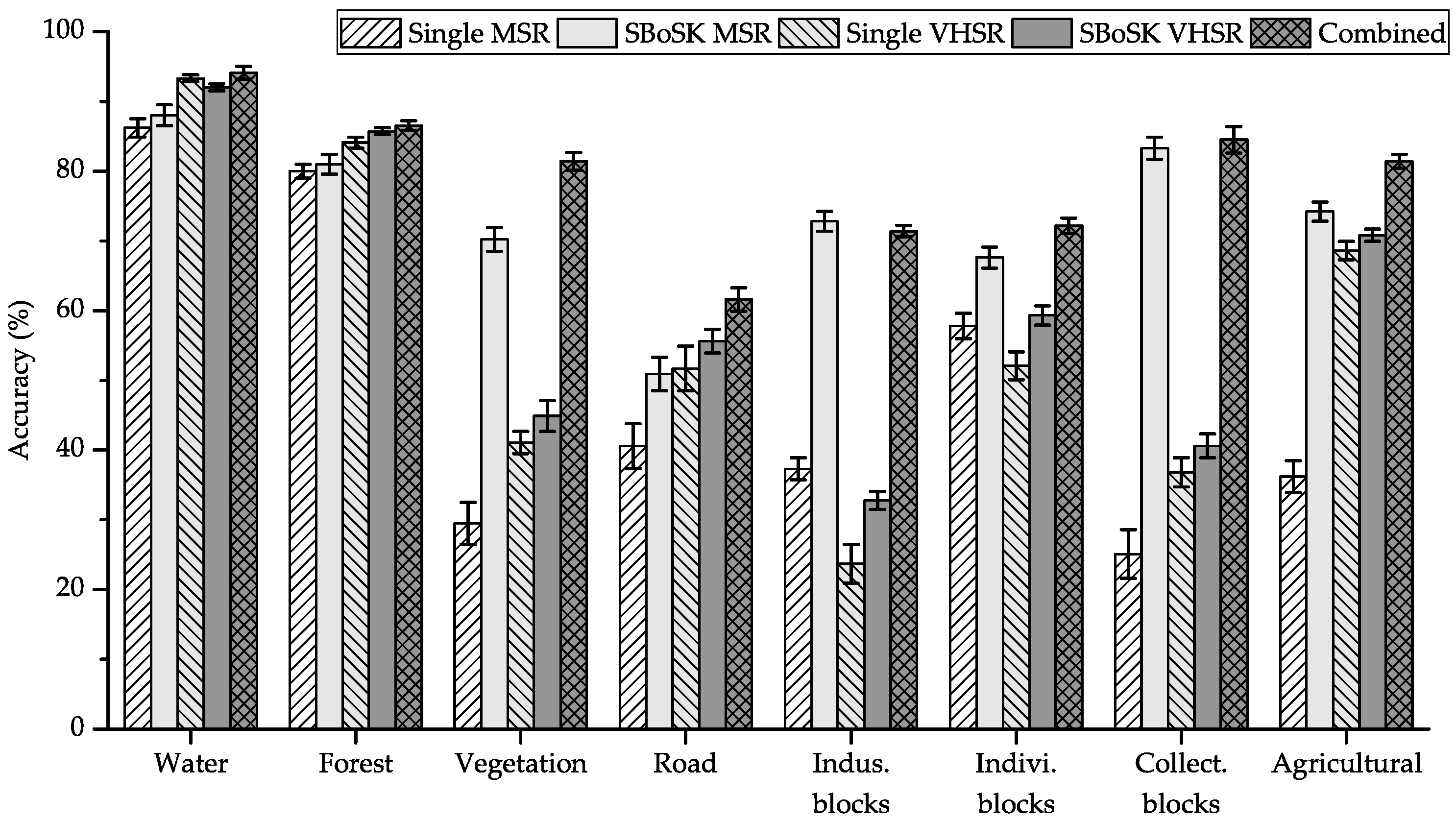
4.4. Combining Context and Object Decomposition Features
5. Evaluations on Large-Scale Datasets
5.1. Zurich Summer Dataset
5.2. UC Merced Dataset
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.Q.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [PubMed]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Bruzzone, L.; Carlin, L. A Multilevel Context-Based System for Classification of Very High Spatial Resolution Images. IEEE Trans. Geosci. Remote Sens 2006, 44, 2587–2600. [Google Scholar] [CrossRef]
- Shackelford, A.K.; Davis, C.H. A combined fuzzy pixel-based and object-based approach for classification of high-resolution multispectral data over urban areas. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2354–2363. [Google Scholar] [CrossRef]
- Lefèvre, S.; Chapel, L.; Merciol, F. Hyperspectral image classification from multiscale description with constrained connectivity and metric learning. In Proceedings of the 6th International Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Lausanne, Switzerland, 24–27 June 2014.
- Chen, S.; Tian, Y. Pyramid of spatial relatons for scene-level land use classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1947–1957. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Zhang, L. A spectral-structural bag-of-features scene classifier for very high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2016, 116, 73–85. [Google Scholar] [CrossRef]
- Liu, Y.; Guo, Q.; Kelly, M. A framework of region-based spatial relations for non-overlapping features and its application in object based image analysis. ISPRS J. Photogramm. Remote Sens. 2008, 63, 461–475. [Google Scholar] [CrossRef]
- Qiao, C.; Wang, J.; Shang, J.; Daneshfar, B. Spatial relationship-assisted classification from high-resolution remote sensing imagery. Int. J. Digit. Earth 2015, 8, 710–726. [Google Scholar] [CrossRef]
- Aksoy, S.; Cinbis, R.G. Image mining using directional spatial constraints. IEEE Geosci. Remote Sens. Lett. 2010, 7, 33–37. [Google Scholar] [CrossRef] [Green Version]
- Cui, Y.; Chapel, L.; Lefèvre, S. Combining multiscale features for classification of hyperspectral images: A sequence based kernel approach. In Proceedings of the 8th IEEE International Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Los Angeles, LA, USA, 21–24 August 2016.
- Cui, Y.; Chapel, L.; Lefèvre, S. A subpath kernel for learning hierarchical image representations. In Proceedings of the International Workshop on Graph-Based Representations in Pattern Recognition, Beijing, China, 13–15 May 2015; pp. 34–43.
- Gomez-Chova, L.; Tuia, D.; Moser, G.; Camps-Valls, G. Multimodal classification of remote sensing images: A review and future directions. Proc. IEEE 2015, 103, 1560–1584. [Google Scholar] [CrossRef]
- Chen, Y.; Su, W.; Li, J.; Sun, Z. Hierarchical object oriented classification using very high resolution imagery and LIDAR data over urban areas. Adv. Space Res. 2009, 43, 1101–1110. [Google Scholar] [CrossRef]
- Zhang, J. Multi-source remote sensing data fusion: Status and trends. Int. J. Image Data Fusion 2010, 1, 5–24. [Google Scholar] [CrossRef]
- Cui, Y.; Lefèvre, S.; Chapel, L.; Puissant, A. Combining Multiple Resolutions into Hierarchical Representations for kernel-based Image Classification. In Proceedings of the International Conference on Geographic Object-Based Image Analysis, Enschede, The Netherlands, 14–16 September 2016.
- Nowozin, S.; Lampert, C.H. Structured learning and prediction in computer vision. Found. Trends Comput. Graph. Vis. 2011, 6, 185–365. [Google Scholar] [CrossRef]
- Volpi, M.; Ferrari, V. Semantic segmentation of urban scenes by learning local class interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 1–9.
- Schindler, K. An overview and comparison of smooth labeling methods for land-cover classification. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4534–4545. [Google Scholar] [CrossRef]
- Damodaran, B.B.; Nidamanuri, R.R.; Tarabalka, Y. Dynamic ensemble selection approach for hyperspectral image classification with joint spectral and spatial information. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2405–2417. [Google Scholar] [CrossRef]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A. A spatial–spectral kernel-based approach for the classification of remote-sensing images. Pattern Recognit. 2012, 45, 381–392. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Benediktsson, J.A.; Waske, B.; Bruzzone, L. Extended profiles with morphological attribute filters for the analysis of hyperspectral data. Int. J. Remote Sens. 2010, 31, 5975–5991. [Google Scholar] [CrossRef]
- Eisank, C.; Drăguţ, L.; Götz, J.; Blaschke, T. Developing a semantic model of glacial landforms for object-based terrain classification—The example of glacial cirques. In Proceedings of the Geographic Object-Based Image Analysis (GEOBIA), Ghent, Belgium, 29 June–2 July 2010; pp. 1682–1777.
- Argyridis, A.; Argialas, D.P. A fuzzy spatial reasoner for multi-scale GEOBIA ontologies. Photogramm. Eng. Remote Sens. 2015, 81, 491–498. [Google Scholar] [CrossRef]
- Yang, J.; Yu, K.; Gong, Y.; Huang, T. Linear spatial pyramid matching using sparse coding for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–26 June 2009; pp. 1794–1801.
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279.
- Gönen, M.; Alpaydın, E. Multiple kernel learning algorithms. J. Mach. Learn. Res. 2011, 12, 2211–2268. [Google Scholar]
- Anees, A.; Aryal, J.; O’Reilly, M.M.; Gale, T.J.; Wardlaw, T. A robust multi-kernel change detection framework for detecting leaf beetle defoliation using Landsat 7 ETM+ data. ISPRS J. Photogramm. Remote Sens. 2016, 122, 167–178. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gomez-Chova, L.; Muñoz-Marí, J.; Vila-Francés, J.; Calpe-Maravilla, J. Composite kernels for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2006, 3, 93–97. [Google Scholar] [CrossRef]
- Tuia, D.; Ratle, F.; Pozdnoukhov, A.; Camps-Valls, G. Multisource composite kernels for urban-image classification. IEEE Geosci. Remote Sens. Lett. 2010, 7, 88–92. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gómez-Chova, L.; Muñoz-Marí, J.; Rojo-Álvarez, J.L.; Martínez-Ramón, M. Kernel-based framework for multitemporal and multisource remote sensing data classification and change detection. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1822–1835. [Google Scholar] [CrossRef] [Green Version]
- Mahé, P.; Vert, J.P. Graph kernels based on tree patterns for molecules. Mach. Learn. 2009, 75, 3–35. [Google Scholar] [CrossRef]
- Harchaoui, Z.; Bach, F. Image classification with segmentation graph kernels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8.
- Vishwanathan, S.; Smola, A.J. Fast kernels for string and tree matching. In Kernel Methods in Computational Biology; MIT Press: Cambridge, MA, USA, 2004; pp. 113–130. [Google Scholar]
- Kimura, D.; Kashima, H. Fast Computation of Subpath Kernel for Trees. In Proceedings of the 29th International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012; pp. 393–400.
- Cuturi, M. Fast global alignment kernels. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 929–936.
- Garro, V.; Giachetti, A. Scale space graph representation and kernel matching for non rigid and textured 3D shape retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1258–1271. [Google Scholar] [CrossRef] [PubMed]
- Yang, T.; Li, Y.F.; Mahdavi, M.; Jin, R.; Zhou, Z.H. Nyström method vs random fourier features: A theoretical and empirical comparison. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 476–484.
- Rahimi, A.; Recht, B. Random features for large-scale kernel machines. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1177–1184.
- Rahimi, A.; Recht, B. Weighted sums of random kitchen sinks: Replacing minimization with randomization in learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 1313–1320.
- Lu, Z.; May, A.; Liu, K.; Garakani, A.B.; Guo, D.; Bellet, A.; Fan, L.; Collins, M.; Kingsbury, B.; Picheny, M.; et al. How to scale up kernel methods to be as good as deep neural nets. arXiv 2014, 14, 1–11. [Google Scholar]
- Bo, L.; Sminchisescu, C. Efficient match kernel between sets of features for visual recognition. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 135–143.
- Haussler, D. Convolution Kernels on Discrete Structures; Technical Report; University of California: Santa Cruz, CA, USA, 1999. [Google Scholar]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Sutherland, D.J.; Schneider, J. On the error of random Fourier features. arXiv 2015, 15, 1–11. [Google Scholar]
- Collins, M.; Duffy, N. Convolution kernels for natural language. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2001; pp. 625–632.
- Perronnin, F.; Sánchez, J.; Mensink, T. Improving the fisher kernel for large-scale image classification. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 143–156.
- Tolias, G.; Avrithis, Y.; Jégou, H. To aggregate or not to aggregate: Selective match kernels for image search. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1401–1408.
- Kurtz, C.; Passat, N.; Gancarski, P.; Puissant, A. Extraction of complex patterns from multiresolution remote sensing images: A hierarchical top-down methodology. Pattern Recognit. 2012, 45, 685–706. [Google Scholar] [CrossRef]
- Tilton, J.C. Image segmentation by region growing and spectral clustering with a natural convergence criterion. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Seattle, WA, USA, 6–10 July 1998; pp. 1766–1768.
- Forestier, G.; Puissant, A.; Wemmert, C.; Gançarski, P. Knowledge-based region labeling for remote sensing image interpretation. Comput. Environ. Urban Syst. 2012, 36, 470–480. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Ghamisi, P.; Benediktsson, J.A.; Cavallaro, G.; Plaza, A. Automatic framework for spectral–spatial classification based on supervised feature extraction and morphological attribute profiles. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2147–2160. [Google Scholar] [CrossRef]
- Huo, L.Z.; Tang, P.; Zhang, Z.; Tuia, D. Semisupervised Classification of Remote Sensing Images with Hierarchical Spatial Similarity. IEEE Geosci. Remote Sens. Lett. 2015, 12, 150–154. [Google Scholar]
- Ghamisi, P.; Dalla Mura, M.; Benediktsson, J.A. A survey on spectral–spatial classification techniques based on attribute profiles. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2335–2353. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Moser, G. Getting pixels and regions to agree with conditional random fields. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016; pp. 3290–3293.
- Perronnin, F.; Sénchez, J.; Xerox, Y.L. Large-scale image categorization with explicit data embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2297–2304.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Color | Nb of Pixels |
|---|---|---|
| Water surfaces (water) | Blue ■ | 1653 |
| Forest areas (forest) | Dark green ■ | 9315 |
| Urban vegetation (vegetation) | Light green ■ | 1835 |
| Road (road) | Grey ■ | 3498 |
| Industrial blocks (indus. blocks) | Pink ■ | 8906 |
| Individual housing blocks (indiv. blocks) | Dark orange ■ | 9579 |
| Collective housing blocks (collect. blocks) | Light orange ■ | 1434 |
| Agricultural zones (agricultural) | Yellow ■ | 7790 |
| Total | 44,010 |
| n | Pixel | Spatial-Spectral | Attribute Profile | Stacked Vector | SBoSK | |
|---|---|---|---|---|---|---|
| 50 | OA | 45.3 (2.3) | 53.2 (1.0) | 51.9 (2.1) | 49.8 (1.8) | 57.8 (1.3) |
| AA | 43.9 (1.0) | 53.7 (1.4) | 51.7 (1.4) | 48.4 (1.1) | 57.9 (0.8) | |
| 100 | OA | 47.9 (1.3) | 57.7 (0.9) | 57.1 (1.4) | 54.3 (1.4) | 63.3 (0.7) |
| AA | 46.2 (0.5) | 59.2 (0.7) | 57.3 (0.7) | 52.9 (1.0) | 64.0 (0.7) | |
| 200 | OA | 51.4 (0.8) | 63.1 (0.9) | 61.7 (0.5) | 59.0 (0.5) | 68.4 (0.7) |
| AA | 48.1 (0.4) | 64.6 (0.6) | 62.2 (0.2) | 57.5 (0.6) | 69.7 (0.5) | |
| 400 | OA | 52.2 (0.4) | 67.3 (0.8) | 65.0 (0.5) | 62.7 (0.6) | 73.0 (0.4) |
| AA | 49.1 (0.2) | 68.5 (0.5) | 66.3 (0.4) | 62.6 (0.4) | 74.8 (0.4) |
| Root | SPM (L2) | SBoSK (L2) | SBoSK (Hseg) | ||
|---|---|---|---|---|---|
| 50 | OA | 52.2 (0.9) | 48.3 (1.8) | 53.2 (1.2) | 54.3 (0.9) |
| AA | 51.2 (0.7) | 46.9 (1.4) | 51.7 (0.4) | 52.4 (1.2) | |
| 100 | OA | 54.2 (0.6) | 50.5 (1.3) | 56.0 (1.1) * | 56.5 (1.4) |
| AA | 53.6 (0.4) | 49.3 (0.7) | 54.5 (0.7) * | 54.9 (1.1) | |
| 200 | OA | 55.7 (0.6) | 52.4 (0.8) | 57.7 (0.7) | 59.2 (0.9) |
| AA | 55.1 (0.3) | 51.3 (0.3) | 56.5 (0.5) | 57.8 (0.9) | |
| 400 | OA | 56.5 (0.5) | 54.7 (0.5) | 59.9 (0.7) | 61.4 (0.3) |
| AA | 56.4 (0.2) | 53.7 (0.3) | 59.0 (0.6) | 60.3 (0.3) |
| Single MSR | SBoSK MSR | Single VHSR | SBoSK VHSR | Combined | ||
|---|---|---|---|---|---|---|
| 50 | OA | 45.3 (2.3) | 57.8 (1.3) | 52.2 (0.9) | 54.3 (0.9) | 65.3 (0.6) |
| AA | 43.9 (1.0) | 57.9 (0.8) | 51.2 (0.7) | 52.4 (1.2) | 64.3 (0.8) | |
| 100 | OA | 47.9 (1.3) | 63.3 (0.7) | 54.2 (0.6) | 56.5 (1.4) | 69.8 (0.7) |
| AA | 46.2 (0.5) | 64.0 (0.7) | 53.6 (0.4) | 54.9 (1.1) | 69.8 (0.8) | |
| 200 | OA | 51.4 (0.8) | 68.4 (0.7) | 55.7 (0.6) | 59.2 (0.9) | 73.9 (0.5) |
| AA | 48.1 (0.4) | 69.7 (0.5) | 55.1 (0.3) | 57.8 (0.9) | 74.8 (0.3) | |
| 400 | OA | 52.2 (0.4) | 73.0 (0.4) | 56.5 (0.5) | 61.4 (0.3) | 77.3 (0.3) |
| AA | 49.1 (0.2) | 74.8 (0.4) | 56.4 (0.2) | 60.3 (0.3) | 79.1 (0.4) |
| Image | Pixel | CRF [56] | Spatial-Spectral | Attribute Profile | Stacked Vector | SBoSK | |
|---|---|---|---|---|---|---|---|
| 16 | OA | 71.8 (0.8) | 82.8 | 81.6 (0.9) | 78.5 (0.6) | 83.4 (0.6) * | 83.9 (0.5) |
| AA | 63.7 (2.1) | - | 62.6 (1.1) | 62.3 (0.8) | 68.3 (1.1) | 70.8 (0.4) | |
| 17 | OA | 75.1 (0.7) | 82.6 | 80.3 (0.6) | 80.7 (0.9) | 82.1 (0.6) | 83.2 (0.6) |
| AA | 61.2 (3.6) | - | 66.3 (1.8) | 60.8 (1.9) | 65.3 (1.6) | 67.7 (3.3) | |
| 18 | OA | 81.1 (0.8) | 73.0 | 85.1 (0.7) | 83.1 (1.4) | 85.7 (0.6) | 87.5 (0.3) |
| AA | 74.0 (3.1) | - | 78.6 (1.2) | 74.5 (3.5) | 78.6 (1.6) | 82.4 (0.6) | |
| 19 | OA | 69.7 (0.7) | 67.5 | 72.1 (1.8) | 78.4 (1.2) | 74.8 (0.6) | 76.0 (0.6) |
| AA | 71.5 (0.9) | - | 77.2 (1.5) | 80.4 (2.3) | 76.2 (2.9) | 79.6 (1.4) * | |
| 20 | OA | 76.9 (1.1) | 80.2 | 83.6 (0.9) | 81.2 (1.2) | 82.2 (1.2) | 84.0 (1.3) |
| AA | 74.2 (1.2) | - | 74.8 (1.4) | 72.7 (2.1) | 75.3 (4.8) | 77.4 (2.4) | |
| avg | OA | 74.9 (0.6) | 77.2 | 80.5 (0.5) | 80.4 (0.7) | 81.7 (0.4) | 82.9 (0.3) |
| AA | 68.9 (1.8) | - | 71.8 (0.6) | 70.1 (1.5) | 72.7 (1.2) | 75.6 (0.8) |
| K | Root | SPM (L2) | SPM (L4) | Spatial Relatons [6] | SBoSK (L2) | SBoSK (L4) | SBoSK (Hseg) |
|---|---|---|---|---|---|---|---|
| 50 | 64.7 (0.7) | 76.4 (0.5) | 69.0 (0.3) | 75.3 | 80.2 (0.3) | 85.6 (0.3) | 87.2 (0.4) |
| 100 | 71.7 (0.4) | 79.8 (0.4) | 72.5 (0.4) | 79.6 | 84.0 (0.3) | 87.2 (0.3) | 88.1 (0.3) |
| 300 | 78.3 (0.3) | 83.6 (0.3) | 75.5 (0.3) | 83.4 | 86.3 (0.2) | 88.1 (0.3) * | 88.5 (0.3) |
| 500 | 79.8 (0.4) | 84.2 (0.2) | 75.9 (0.2) | 85.8 | 87.5 (0.3) | 88.7 (0.2) * | 88.7 (0.3) |
| 1000 | 81.6 (0.4) | 85.1 (0.3) | 75.9 (0.2) | 87.6 | 87.9 (0.3) | 88.9 (0.3) * | 88.9 (0.3) |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Y.; Chapel, L.; Lefèvre, S. Scalable Bag of Subpaths Kernel for Learning on Hierarchical Image Representations and Multi-Source Remote Sensing Data Classification. Remote Sens. 2017, 9, 196. https://doi.org/10.3390/rs9030196
Cui Y, Chapel L, Lefèvre S. Scalable Bag of Subpaths Kernel for Learning on Hierarchical Image Representations and Multi-Source Remote Sensing Data Classification. Remote Sensing. 2017; 9(3):196. https://doi.org/10.3390/rs9030196
Chicago/Turabian StyleCui, Yanwei, Laetitia Chapel, and Sébastien Lefèvre. 2017. "Scalable Bag of Subpaths Kernel for Learning on Hierarchical Image Representations and Multi-Source Remote Sensing Data Classification" Remote Sensing 9, no. 3: 196. https://doi.org/10.3390/rs9030196
APA StyleCui, Y., Chapel, L., & Lefèvre, S. (2017). Scalable Bag of Subpaths Kernel for Learning on Hierarchical Image Representations and Multi-Source Remote Sensing Data Classification. Remote Sensing, 9(3), 196. https://doi.org/10.3390/rs9030196