1. Introduction
Target classification techniques based on remotely sensed data are widely used in many disciplines such as resource exploration, outcrop geology, urban environmental management, and agriculture and forestry management [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11]. Target classification enables a more accurate understanding of targets and therefore supports better decision-making. Thus, the remote sensing community has been studying classification techniques and methods for many years. Target classification techniques and methods have matured and become diverse, given the recent advances in remote sensing technology and pattern recognition, newer approaches have extended and built upon traditional technologies.
Before multispectral LiDAR, two major technologies provided data for target classification, spectral imaging and light detection and ranging (LiDAR). Multispectral LiDAR data have similarities to both spectral imaging and LiDAR, thus the classification methods based on spectral images, and LiDAR data have acted as a reference when multispectral LiDAR techniques were initially developed. Support vector machine (SVM) is a supervised [
12] classification method, and a popular non-parametric classifier widely used in the machine learning and remote sensing communities [
13,
14,
15]. SVM can effectively overcome the curse of dimensionality and overfitting [
16,
17,
18]. With the help of SVM, spectral image classification has performed successfully in many experiments [
19,
20]. Compared to spectral images, the classification of LiDAR point clouds is less mature because LiDAR requires complicated data processing and its wide application emerged only recently. LiDAR classification experiments have been conducted for applications in urban building extraction and forest management [
21,
22,
23]. Spectral imaging and LiDAR have demonstrated their effectiveness for target classification; however, spectral imaging lacks three-dimensional (3D) spatial information, and conventional LiDAR systems operate on a single wavelength, which lacks spectra for objects.
Classification experiments employing complementary information from both LiDAR and images were conducted. The performance of classification generally were improved with the complementary information. Guo et al. [
24] selected the random forests algorithm as a classifier and used margin theory as a confidence measure of the classifier to confirm the relevance of input features for urban classification. The quantitative results confirmed the importance of the joint use of optical multispectral and LiDAR data. García et al. [
25] presented a method for mapping fuel types using LiDAR and multispectral data. Spectral intensity, the mean height of LiDAR returns and the vertical distribution of fuels were used with an SVM classification combining LiDAR and multispectral data. Laible et al. [
26] conducted an object-based terrain classification with random forests by extracting 3D LIDAR-based and camera-based features. The 3D LIDAR-based features included maximum height, the standard deviation of height, distance, and the number of points. The results showed that classification based on extracted features from camera and LiDAR was feasible under different lighting conditions. The complementary information of LiDAR and images, however, can only be used effectively after accurate registration, which involves many difficulties [
27].
As a novel remote sensing technology, multispectral LiDAR can capture both spectral and spatial information simultaneously [
28,
29], and has been used in various fields [
30,
31,
32,
33]. The introduction of the first commercial airborne multispectral LiDAR, Optech Titan, made multispectral LiDAR land cover classification feasible. Wichmann et al. [
34] conducted an exploratory analysis of airborne-collected multispectral LiDAR data with a focus on classifying specific spectral signatures by using spectral patterns, thereby showing that a flight dataset is suitable for conventional spatial classification and mapping procedures. Zou et al. [
35] presented an Object Based Image Analysis (OBIA) approach, which only used multispectral LiDAR point clouds datasets for 3D land cover classification. The results show that an overall accuracy of over 90% can be achieved for 3D land cover classification. Ahokas et al. [
36] suggested that intensity-related and waveform-type features can be combined with point height metrics for forest attribute derivation in area-based prediction, and currently is an operatively applied forest inventory process used in Scandinavia. The airborne multispectral LiDAR Optech Titan system shows promising potential for land cover classification; however, as Optech Titan acquires LiDAR points in three channels at different angles, points from different channels do not coincide at the same GPS time [
34]. Therefore, data processing involves finding corresponding points, which is a disadvantage of Optech Titan data.
Terrestrial multispectral LiDAR however, can overcome this disadvantage, and classification attempts have been undertaken. Hartzell et al. [
37] classified rock types using the data from three different commercial terrestrial laser scanning systems with different wavelengths and compared the results with passive visible wavelength imagery. This analysis indicated that rock types could be successfully identified with radiometrically calibrated multispectral terrestrial laser scanning (TLS) data, with enhanced classification performance when fused with passive visible imagery. Gong et al. [
38] compared the performance of different detection systems finding that classification based on multispectral LiDAR was more accurate than single-wavelength LiDAR and multispectral imaging. Vauhkonen et al. [
39] studied the classification of spruce and pine species using multispectral LiDAR data with linear discriminant analysis. They found that the accuracies of two spectrally similar species could be improved by simultaneously analyzing reflectance values and pulse penetration. There are two kinds of classification for point clouds: object-based classification and point-based classification [
40,
41]. Object-based classification is for objects, which are composed of many points while point-based classification is for individual points. Most of the aforementioned classification experiments were point-based, based on statistical models and image analysis; but have not yet employed neighborhood spatial information to improve and enhance classification results.
The classification results could be improved considering the low signal to noise ratio of this kind of novel sensor data. Moreover, the reasons of low signal to noise ratio could be: high noise in the reflection signal collection [
42,
43], the close range experimental setup that caused high sensitivity of the sensing process [
44], the instability of the laser power and the multi-return of the LiDAR beam [
45]. The low signal to noise ratio brings about instability in the spectral intensity value of points, creating salt and pepper noise in the spectral-only classification [
38] and thus lowering overall classification accuracy. To solve this problem, we proposed a subsequent k-nearest neighbors (k-NN) clustering step using neighborhood spatial information with a better classification outcome, overall.
This article proposes a two-step approach for point-based multispectral LiDAR point cloud classification. First, we classified a point cloud based on spectral information (spectral reflectance or vegetation index). Second, we reclassified the point cloud using neighborhood spatial information. In the first step, the vegetation index (VI) was introduced into the classification of healthy and withered leaves. In the second step, the k-NN algorithm was employed with neighborhood spatial information for reclassification. The feasibility of the two-step classification method and the efficiency of neighborhood spatial information for increasing classification accuracy were assessed.
3. Methods
The classification process consisted of two steps: routine classification based on spectral information followed by spatial majority k-NN clustering. First, we classified the multispectral LiDAR point cloud with an SVM classifier using spectral information (raw spectral reflectance and VI). Second, the k-NN algorithm was used by neighborhood spatial information to reclassify the multispectral LiDAR point cloud based on the first step. The details are described in the following sections.
In the first step, the classification experiments using raw spectral reflectance value included: (1) seven individual targets; (2) artificial and vegetable targets; and (3) healthy and withered scindapsus leaves. The classification based on VI included: (1) artificial and vegetable targets; and (2) healthy and withered scindapsus leaves. In the second step, all the aforementioned classification experiments were reclassified using neighborhood spatial information with the k-NN algorithm.
3.1. Classification Based on Raw Spectral Reflectance
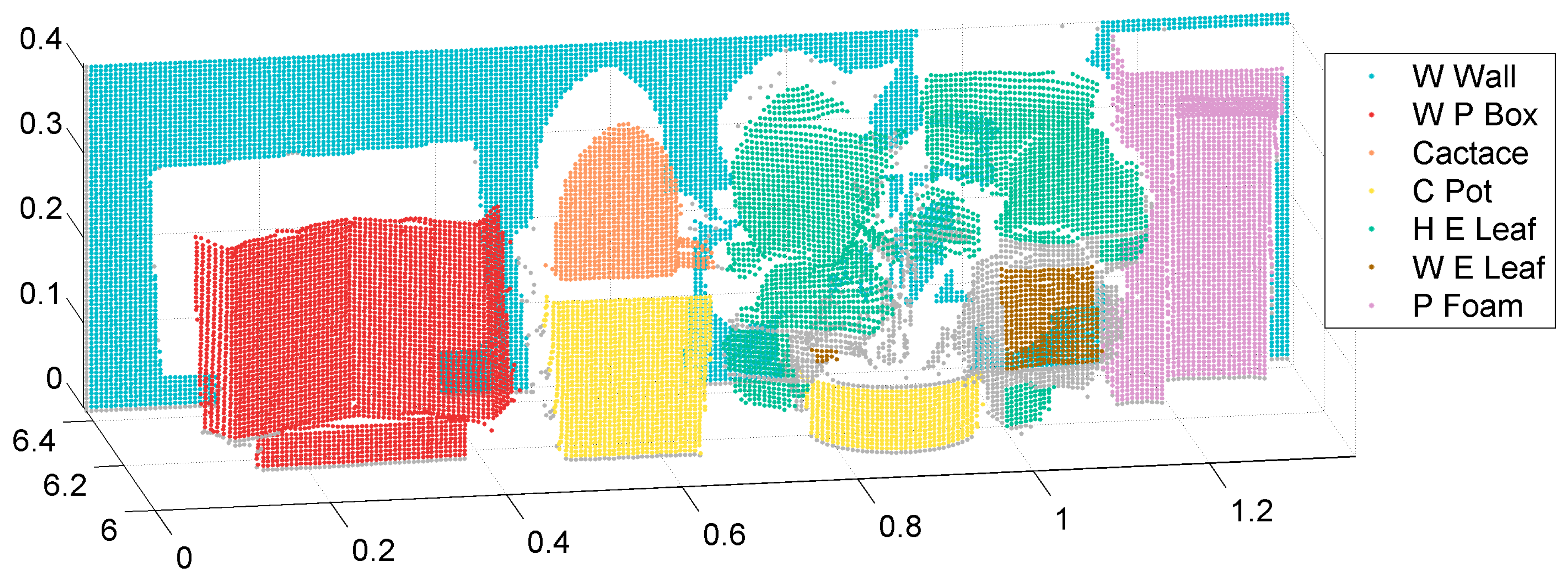
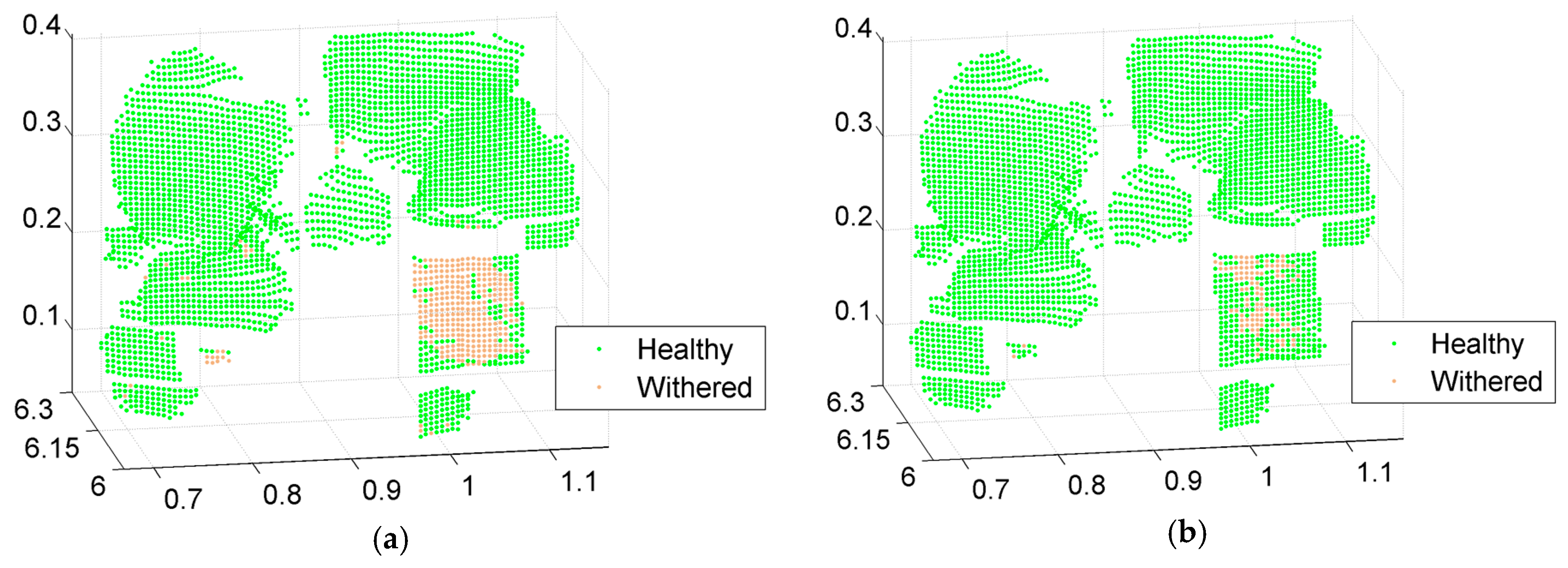
To evaluate classification accuracy, most points (92%) in the multispectral LiDAR point cloud were labeled manually using MATLAB software, with the spatial limitation for every target, as shown in
Figure 4. Spatial outliers and points that were difficult to label manually were excluded (8%). The raw spectral reflectance of the multispectral LiDAR point cloud was normalized by spectraLon. SpectraLon is a fluoropolymer, and has the highest diffuse reflectance of any known material or coating over the ultraviolet, visible, and near-infrared regions of the spectrum [
46]. An SVM classifier was used to train the classification model with the LibSVM proposed by Chang [
47].
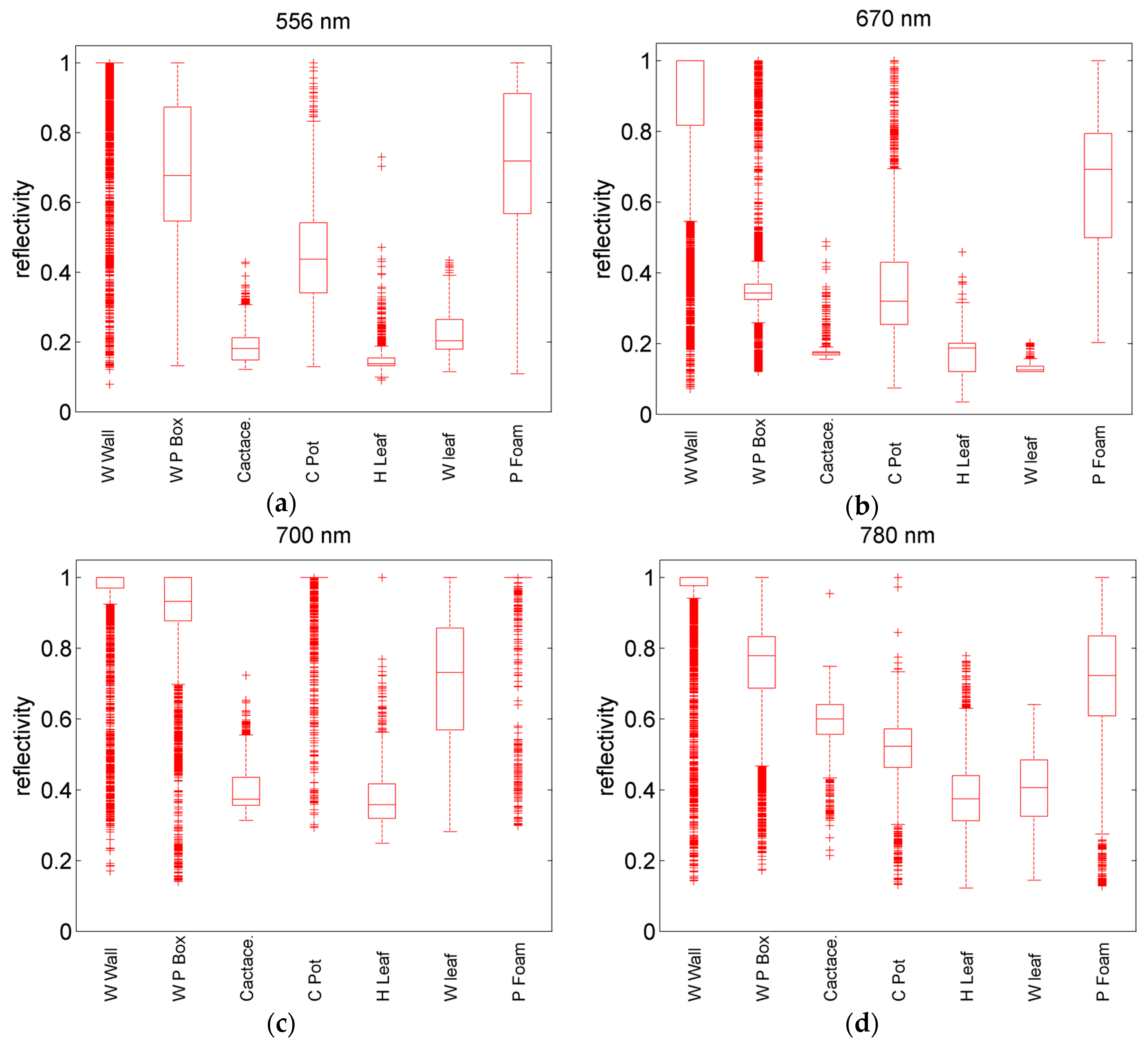
In this section, three classification sub-experiments were conducted with the use of raw spectral reflectance: (1) seven individual targets; (2) artificial (white wall, white paper box, ceramic flowerpot, plastic foam) and vegetable (cactus, healthy scindapsus leaves, withered scindapsus leaves) targets; and (3) healthy and withered scindapsus leaves. Training samples were a quarter of the total manually labeled points and were selected randomly with MATLAB. In this way, the spectral and spatial information of training samples were randomly distributed, and the integrity of training was ensured. The input parameters of the SVM classifier were four channels of raw spectral reflectance (556, 670, 700, and 780 nm). Results are shown in Figures 5, 6, and 8 in
Section 4.
3.2. Classification Based on Vegetation Index (VI)
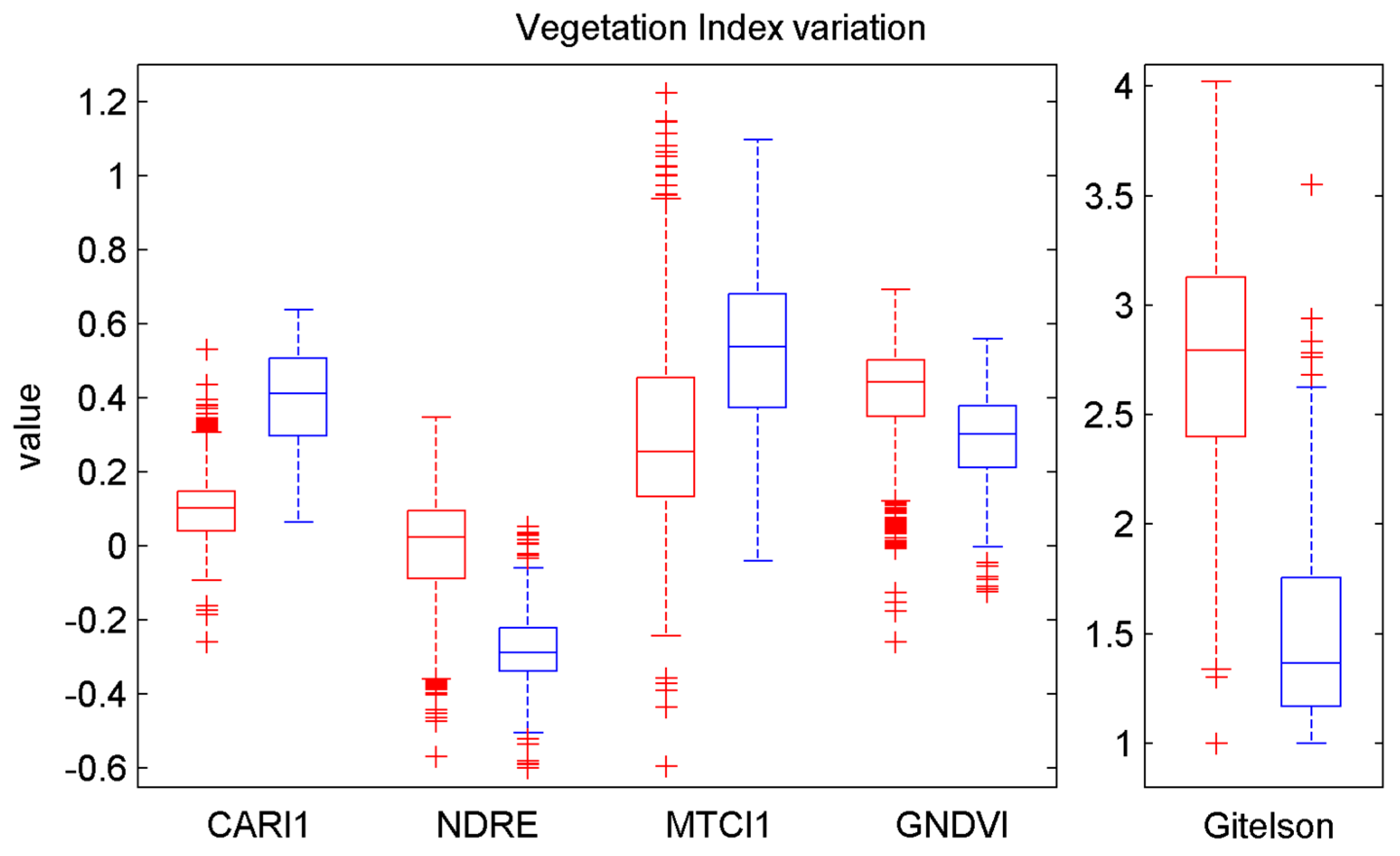
To enhance the capability of distinguishing artificial, healthy, and withered vegetable targets, VI was introduced to the classification. A VI is a spectral transformation of two or more bands designed to enhance the contribution of vegetation properties and allow reliable spatial and temporal inter-comparisons of terrestrial photosynthetic activity and canopy structural variations [
48]. In consideration of the four wavelengths of the MWCL, namely, 556, 670, 700, and 780 nm, 14 types of VI were tested for the experiment separately, and are listed in
Table 1 and
Appendix A. A comparison among the classification results obtained by every single VI indicated that five VIs performed best; and were therefore selected as the input parameters of the SVM. The defined wavelengths in the original formula were replaced by the closest adapted wavelengths of the MWCL. The five VIs were calculated by the MWCL adapted formula for every point. These were additional classification features related to the biochemistry status of the vegetation.
For this section, two classification sub-experiments were conducted with the use of the five VIs: (1) the artificial and vegetable targets; and (2) the healthy and withered scindapsus leaves. The training samples were the same as those in
Section 3.1, and the classifier was SVM. Thus, only the input parameters were changed from
Section 3.1 (from four channels of raw spectral reflectance to five channels of VI), thereby ensuring a comparison between the classification capability of VI and raw spectral reflectance.
3.3. Reclassification Based on Neighborhood Spatial Information with k-Nearest Neighbors Algorithm
After spectral information (raw spectral reflectance and VI) classification had allocated every point a class attribute, the k-NN classification algorithm was employed with the neighborhood spatial information for reclassification. The k-nearest neighbors algorithm is a non-parametric method for classification or regression [
54]. In this experiment, the k-NN algorithm was used for classification in consideration of the nearest neighborhood point class.
Reclassification was based on the hypothesis that most of the neighborhood point class was correct after the first classification, where every point was assigned to the most common class considering its k (k is a positive integer) closest neighbors class attribute, in a fixed neighborhood distance. With a view to the scale of the targets, the density of point cloud, and the practical test, the k and neighborhood distance in this experiment were empirically set to 15 and two centimeters, respectively.
The two drawbacks of the k-NN algorithm are its sensitivity to the local samples of the data and the non-uniform distribution of samples. These two shortcomings can be overcome by the property of spatial distribution of the LiDAR point cloud. The distribution of one target in space is uninterrupted, thus, the points that describe one target are assembled in space. One point is usually surrounded by the points of the same target, and, furthermore, because of the steady scanning frequency, the density of points that describe one target is uniform.
Another advantage of employing k-NN to reclassify the multispectral LiDAR point cloud is the edge process. In images, most edges are surrounded by two or more classes of targets, thereby complicating the classification of the pixel on the edges. By contrast, most edges in a point cloud have only one class of target surrounding itself unless it is at the junction of different targets. Thus, the neighborhood points of the edge points are usually of the same class. Thus, the k-NN algorithm is suitable for the reclassification of the edges of the point cloud. The performance of k-NN is detailed in
Section 4.3.
5. Discussion
The proposed two-step method was compared with the Gong method [
38]. In Gong’s method, multispectral LiDAR point cloud was classified with the SVM. There were five dimensions of input parameters of the SVM: four for spectra, one for distance. Thus, the spatial information was not adequately used, and only used as one dimension of the input parameter of the SVM. For fair comparison, the training points were the same as those in our proposed two-step method. Therefore, the classification result of Gong’s method in this paper was slightly different from the result in Reference [
38]. The confusion matrix and results are shown in
Table 6 and
Figure 11.
When comparing
Table 5 and
Table 6, our proposed two-step method had higher both user and producer accuracy for every class than via Gong’s method, except for the user accuracy of plastic foam. The lower user accuracy of plastic foam may be due to its great reflectance fluctuations at 556, 670 and 780 nm. However, in terms of the number of correctly classified points for plastic foam, our proposed method was better (1659 to 1639) and also the overall accuracy (87.188%) was higher than Gong’s method (82.797%).
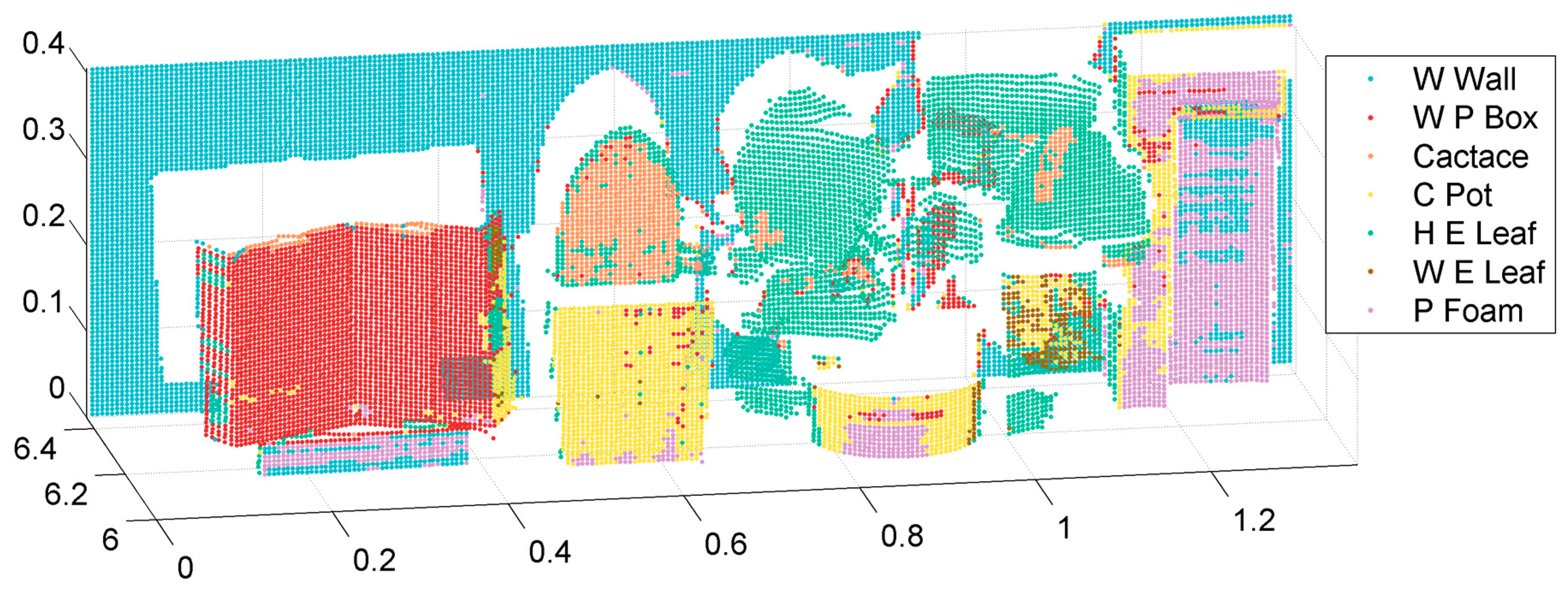
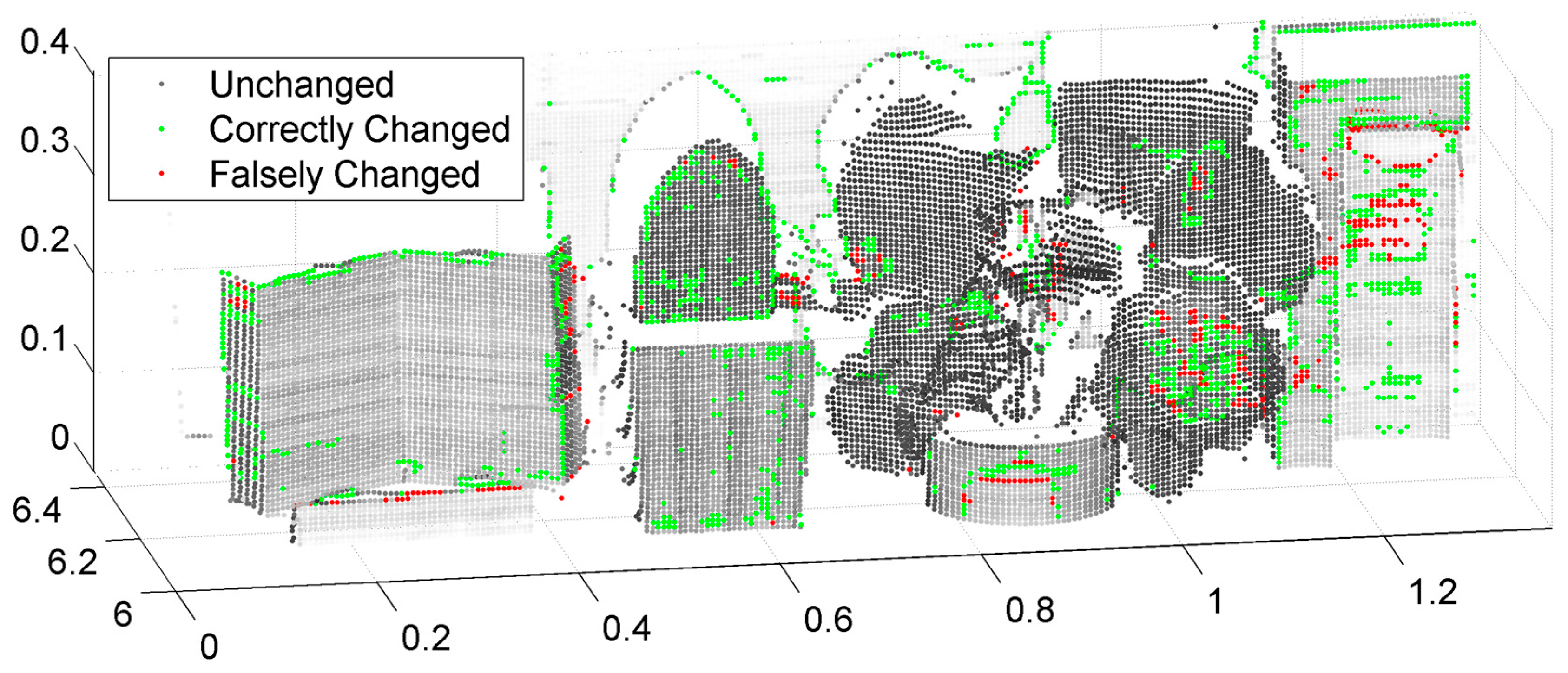
When comparing
Figure 9 and
Figure 11, the distribution of erroneously classified points was similar to our proposed method. The reason may be due to the role played by the spectral information in these two methods. Furthermore, the spectral information quality was actually not ideal in the area of error. In addition, there are many scatter error points in Gong’s method (
Figure 11), unlike the result seen in
Figure 9 classified by our two-step method. This also demonstrates the effectiveness of the k-NN algorithm with neighborhood spatial information.
The demerit of this two-step approach is that it cannot increase the classification accuracy if the first spectral classification accuracy is low. If the first classification accuracy of one class was low, then the class attributes of most neighborhood points will be wrong. The principle of k-NN is that every point was assigned to the most common class of neighborhood points, considering its k (k is a positive integer) closest neighbors class attribute. Therefore, the k-NN algorithm by neighborhood spatial information cannot work in this low spectral classification accuracy situation.
6. Conclusions
The data form of the multispectral LiDAR point cloud is unique because of its combination of spatial and spectral information, which is helpful for target classification. The properties of the data ensure that targets can be classified; first by using spectral information and then reclassified by using neighborhood spatial information. Experiments demonstrate the feasibility of this two-step classification method for multispectral LiDAR point cloud in most scenarios.
The first classification based on raw spectral reflectance performed well in most scenarios, aside from the classification of healthy and withered scindapsus leaves. After using the vegetation index, the classification accuracy of artificial and vegetable targets did not increase considerably. However, the overall classification accuracy of healthy and withered scindapsus leaves increased from 90.039% to 95.556%, compared with that obtained by raw spectral reflectance. For the identification of the withered scindapsus leaves, the accuracy increased from 23.272% to 70.507%, thereby indicating that vegetation indexes are more effective in classifying healthy and withered scindapsus leaves by multispectral LiDAR.
An analysis of the reclassification experiments indicates that the k-nearest neighbors algorithm with neighborhood spatial information can mitigate the salt and pepper noise and increase accuracy in most scenarios unless the first spectral classification accuracy was too low. Producer and user accuracies of every target rose in the confusion matrix in the seven-target classification (
Table 1 and
Table 2). The k-nearest neighbor algorithm in conjunction with neighborhood spatial information performed well in raw spectral reflectance and in the vegetation index experiments in most cases (overall accuracies increased by 1.50–11.06%). These results show that the proposed two-step classification method is feasible for multispectral LiDAR point clouds and that the k-nearest neighbor algorithm with neighborhood spatial information is an effective tool for increasing classification accuracy.
One disadvantage of this method is that the k-nearest neighbors algorithm with neighborhood spatial information will not work in low first spectral-information-based classification accuracy situations. In addition, it was conducted in a laboratory and the experimental targets were limited. Further outdoor experiments with more complicated targets would be required to complete the assessment of its feasibility.
Furthermore, a better algorithm for the spatial information to increase classification accuracy requires more research to utilize the spatial information more adequately. For example, the spectral-spatial method for hyperspectral imagery might be considered for the introduction for multispectral LiDAR. In addition, research on object and point classification, and the internal relation of object and point classification for multispectral LiDAR will be conducted.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










