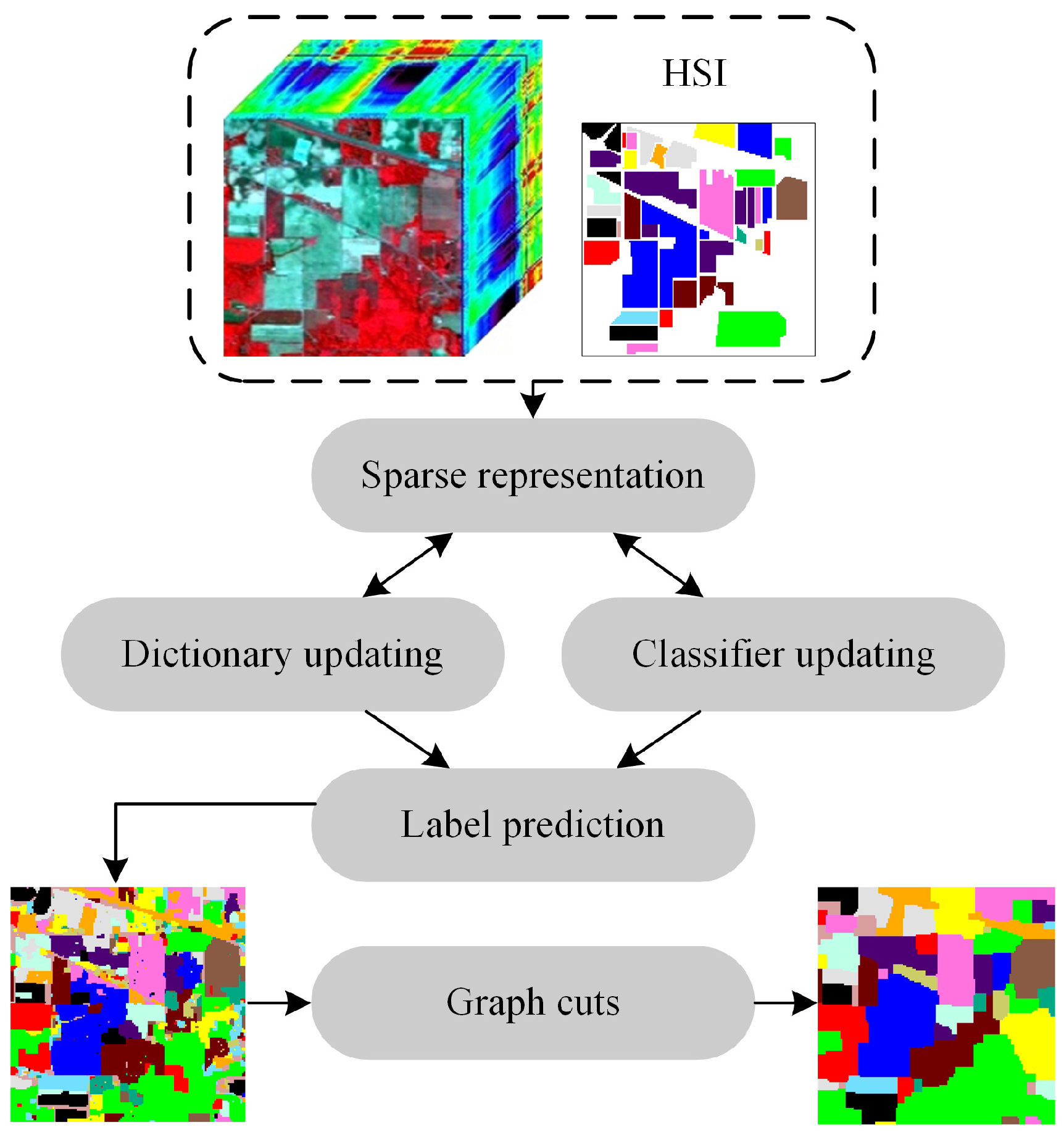
4.1. Experimental Settings
For performance comparison, some strongly related dictionary learning algorithms are considered. The unsupervised methods are MOD, K-SVD, D-KSVD, and OnlineDL. The supervised category includes LC-KSVD and SDL. We also implemented a semi-supervised method, semi-supervised joint dictionary learning with logistic loss function (S
JDL-Log, “Log” for Logistic loss function), which is a variant of the proposed method. We then denote by S
JDL-Sof (“Sof” for soft-max loss function) the proposed method to differentiate them. It is worth noting that all the methods employ a multivariate ridge regression model for classifier learning (see Equation (
14)), and adopt orthogonal matching pursuit (OMP) [
54] for sparse coding.
It is worth noting that MOD, K-SVD, D-KSVD, LC-KSVD, OnlineDL, and SDL are implemented based on their original source codes released to the public by their owners, and they share the common parameters of sparsity level (T = 5), reconstruction error (E = 1 × 10), and -norm penalty (). In addition, three other parameters in SDL have been set as the recommended values. We also note that these parameters have been selected by careful cross-validation. In this context, the parameter settings always ensure a fair comparison even if they are suboptimal. For dictionary and classifier update, the initial learning rate is set to , and the tradeoff between the unsupervised and supervised learning ingredients is set to 0.5.
We randomly select labeled training samples from the ground-truth to initialize the dictionary and classifier. The
-norm penalty parameter is set to
when initializing the classifier using Equation (
14).
For classification, we set the maximum number of iterations to , which means that the reported overall accuracies (OAs), average accuracies (AAs), kappa statistic (), and class individual accuracies are derived by averaging the results after conducting ten independent Monte Carlo runs with respect to the initialized labeled training set. In addition, the smoothness parameter () in graph cuts is set to 3, and we adopt graph cuts for all the methods.
Finally, it is worth noting that all the implementations were carried out using Matlab R2015b on a desktop PC equipped with an Intel Xeon E3 CPU (at 3.4 GHz) and 32 GB of RAM. It should be emphasized that all the results are derived from our own implementations and the involved parameters for these methods have been carefully optimized in order to ensure a fair comparison.
4.3. Experiments with AVIRIS Indian Pines Dataset
Experiment 1: We first analyze the sensitivity of parameters for the proposed method.
Figure 5 illustrates the sensitivity of the proposed method to parameters
,
, and
under the condition that 10% of labeled samples per class are used for training and 15 labeled samples per class are used to build the dictionary. As we can see from
Figure 5a, the OA is insensitive to
and
. Therefore, we roughly set
and
. This observation is reasonable since
controls the uniqueness of sparse coding and
determines the initial performance of the classifier parameter. The impacts of the two parameters are reduced in a iterative learning scheme since sparse coding and classifier update are alternatively conducted. According to
Figure 5b, we found that OA is sensitive to
, and the optimal value is set to
. This observation is in accordance with that made in [
50].
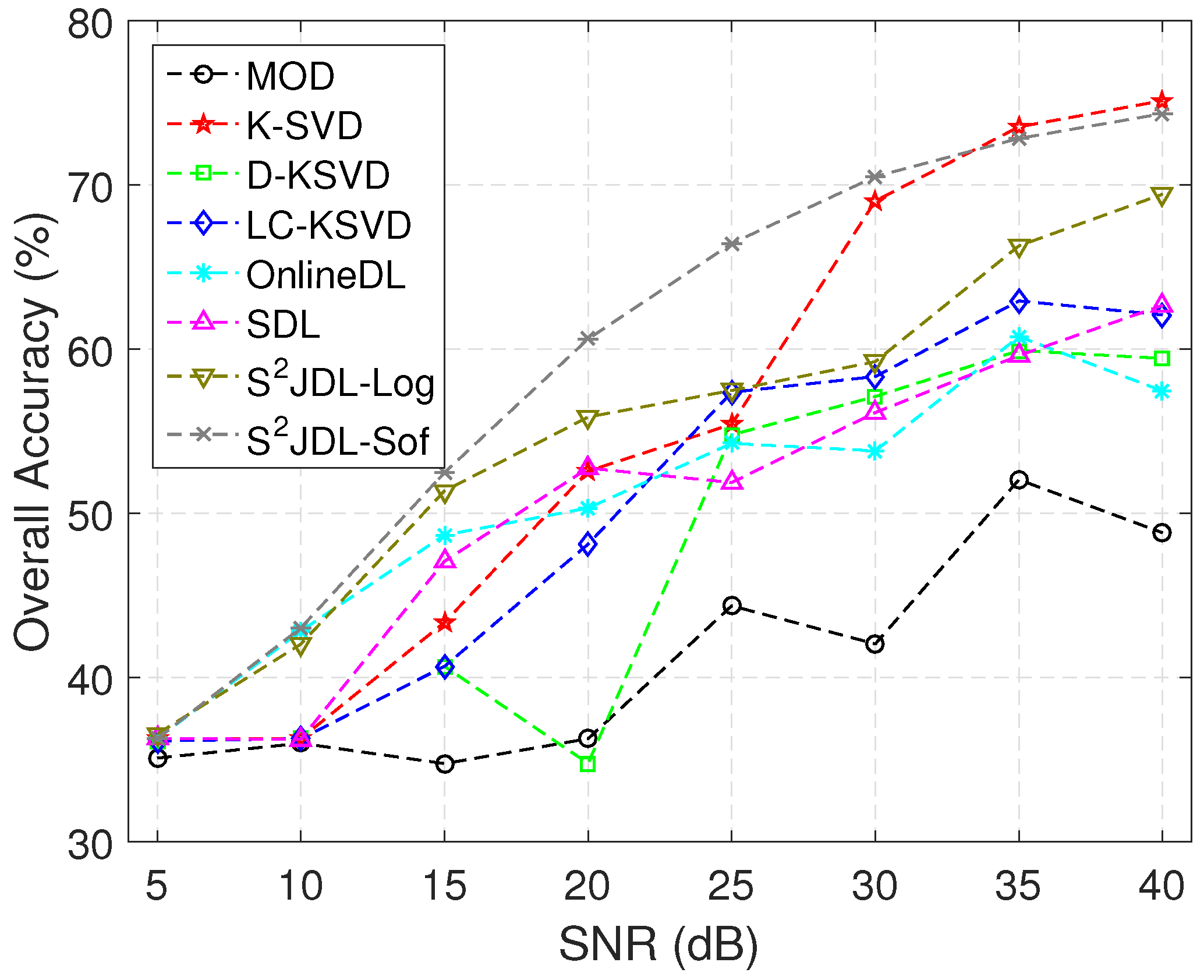
Experiment 2: In this test, Gaussian random noise with a pre-defined signal-to-noise ratio (SNR) (
) is generated and added to the original imagery.
Figure 6 illustrates the evolution of OA with SNR for different classifiers. As shown in the figure, the proposed method outperforms others in most cases with SNR = 5, 10, etc. The interval between the curve of the proposed method and others visually indicates the significances, which confirms the robustness of the proposed method to data noise.
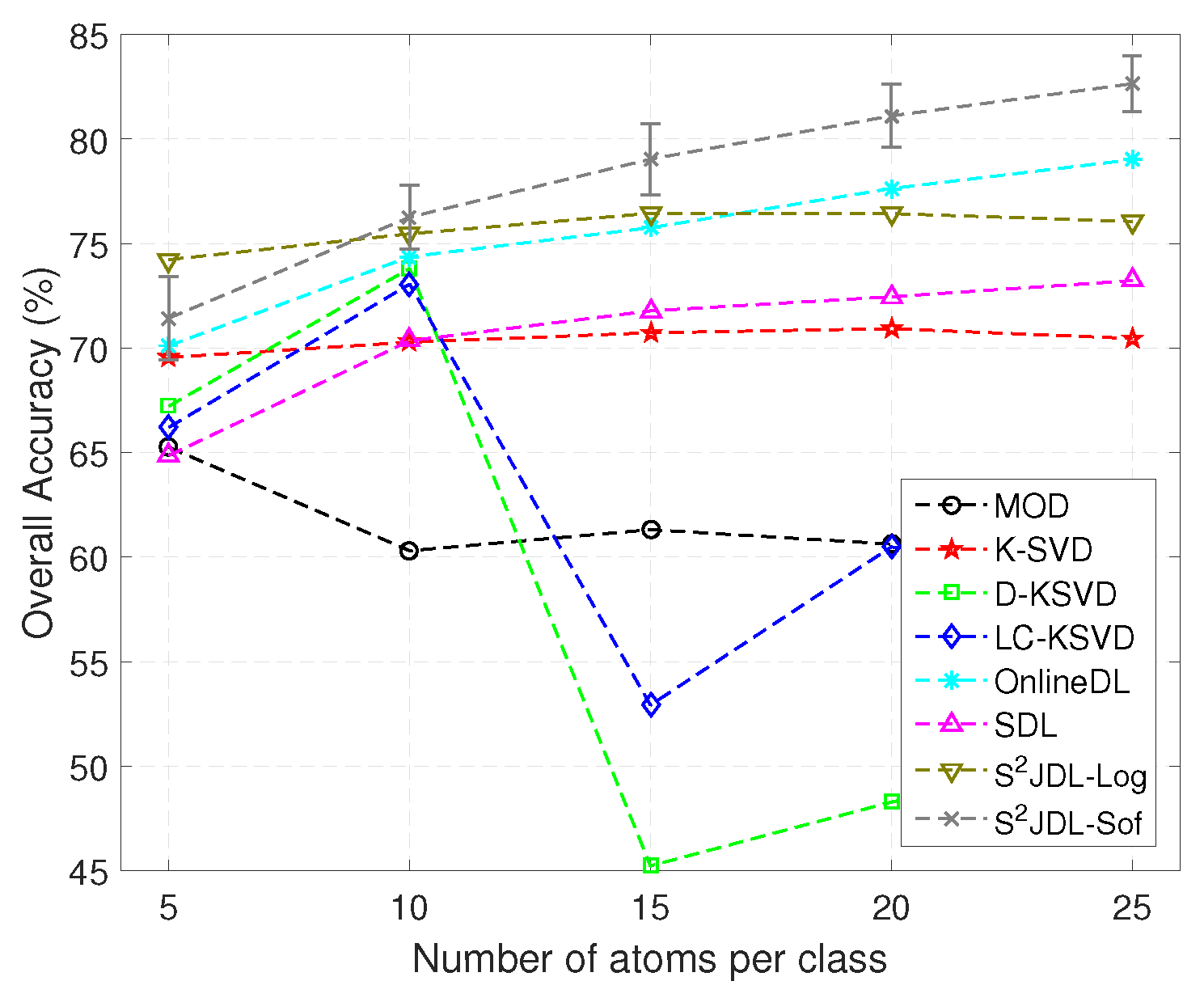
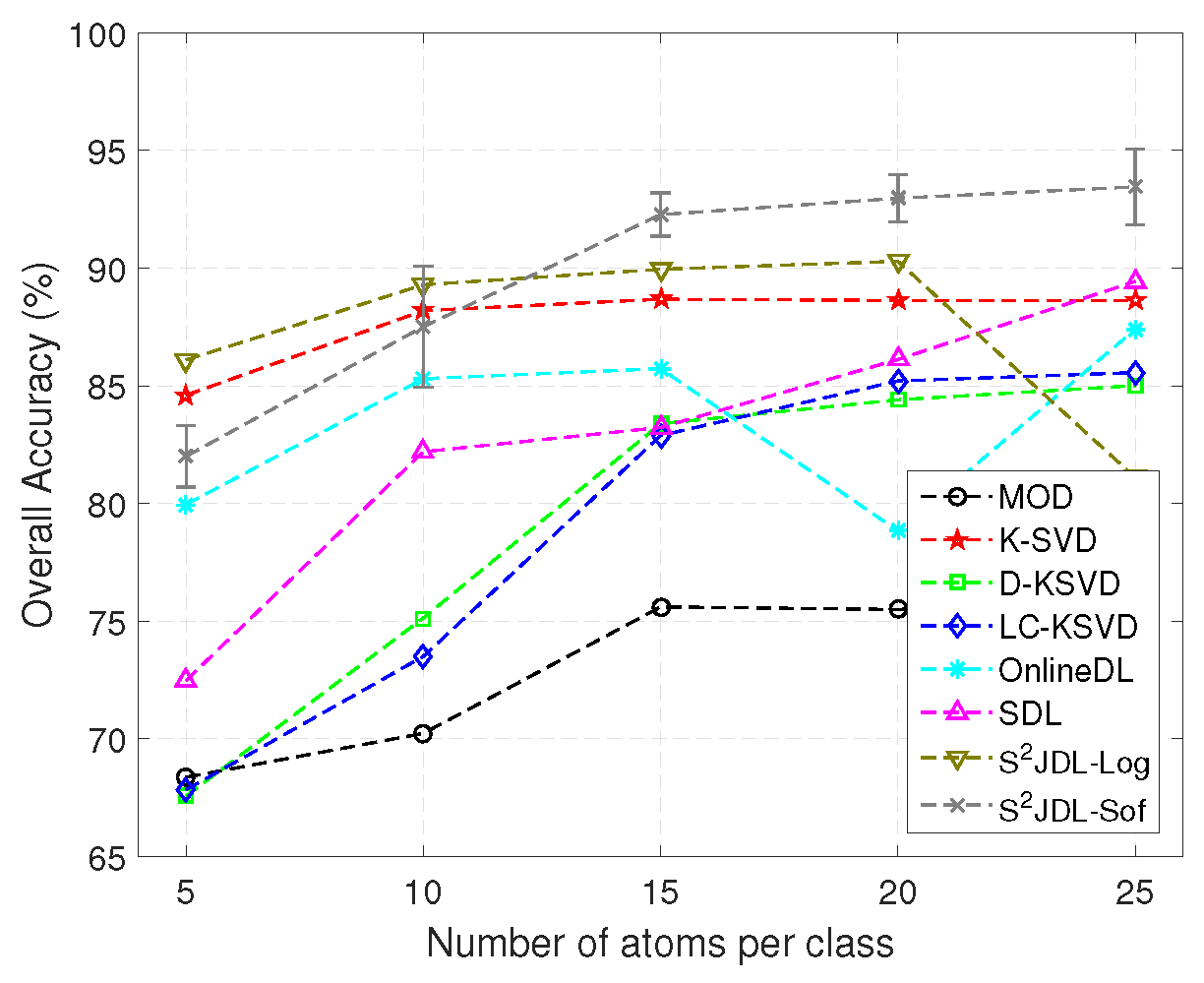
Experiment 3: We then analyze the impact of training data size on classification accuracy. To this end, we randomly choose 10% of labeled samples per class (a total of 1027 samples) to initialize the training data and evaluate the impact of the number of atoms on the classification performance.
Figure 7 shows the OAs as a function of the number of atoms per class obtained by different methods. As we can see from the figure, the proposed method obtains the highest accuracies in all cases. Another observation is that, as the number of atoms increases, the OAs also increase. When the number of atoms per class is equal to 15, the proposed method reaches a stable level, with an OA higher than 80%. It is interesting to note that D-KSVD and LC-KSVD obtain very similar results.
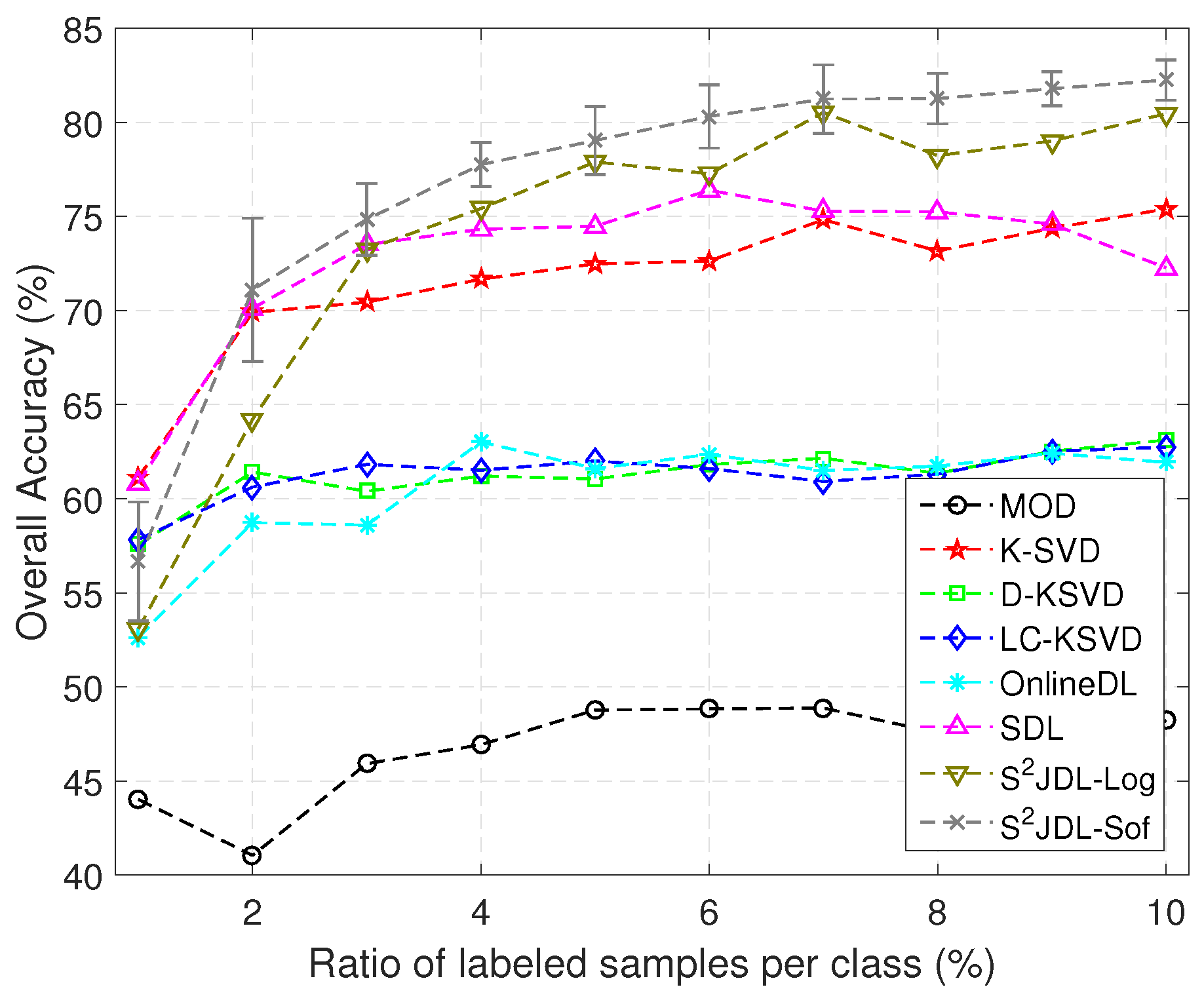
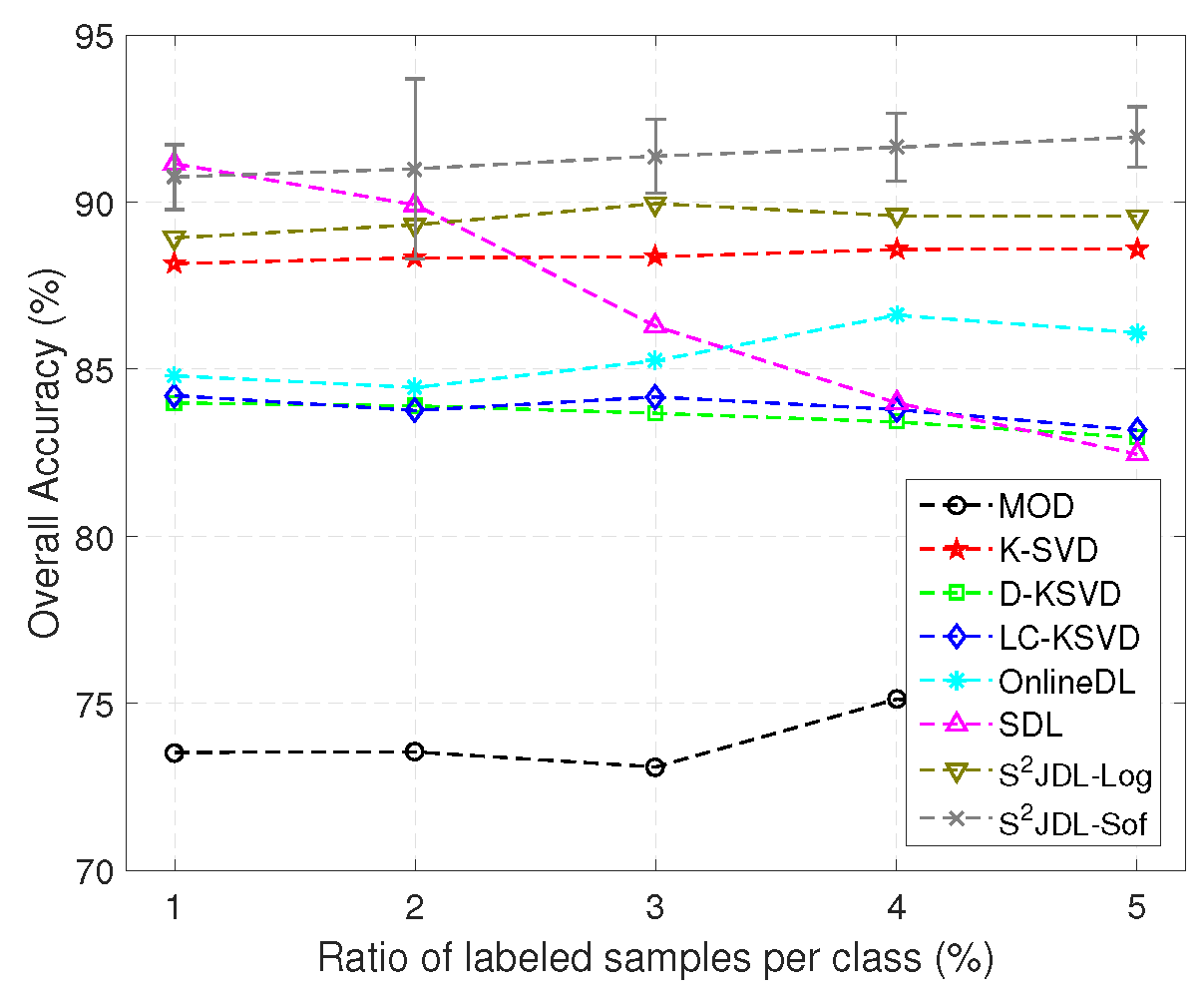
Figure 8 shows the OAs as a function of the ratio of labeled samples per class for different methods. As we can see from the figure, the proposed method obtains higher accuracies when the ratio is larger than 5%. It is worth noting that the proposed method can stably obtain improved classification performance with additional labeled samples. However, the other methods cannot produce higher OAs as the ratio ranges from 3% to 10%. This observation can be explained by the increase of the number of labeled samples; the proposed method can exploit more information from both the labeled and unlabeled training samples, whereas the supervised dictionary learning methods can only rely on the labeled information, and the performance cannot be improved significantly. Another observation is that S
JDL-Log yields a very competitive classification performance. This is due to the fact that S
JDL-Log is based on semi-supervised learning fashion.
Experiment 4: Table 1 reports the OA, AA, individual classification accuracies, and
statistic. The results of the proposed algorithm are listed in the last column of the table and we have marked in bold typeface the best result for each class and the best results of OA, AA, and
statistic. Our method achieves the best results compared to the other supervised dictionary learning methods. The improvements of classification accuracy are around 10%–40% when compared to other methods. Especially, when classifying the class
Wheat, our method performs very well. Although our method may not always obtain the best accuracy in some specific classes, AA, OA, and kappa are more convincing metrics measuring the classification performance. In addition, the time costs of different methods are listed in the table, where we can see that the proposed method is more efficient than K-SVD, D-KSVD, and LC-KSVD. However, MOD, OnlineDL, and SDL take less time. The time cost of the proposed method mainly comes from the optimization step, which can be reduced by exploiting more efficient optimization strategy.
Table 2 reports the statistical tests between-classifier in terms of Kappa
z-score and McNemar
z-score. The critical value of
z-score is 1.96 at a confidence level of 0.95, and all the tests are significant with 95% confidence, which indicates that the proposed method significantly outperforms the other methods. Another observation is that the lower value of
z-score demonstrates the closer classification results, e.g., the Kappa
z-score value for S
JDL-Log/S
JDL-Sof is 4.4. Similar observation can be made for the tests using McNemar
z-score.
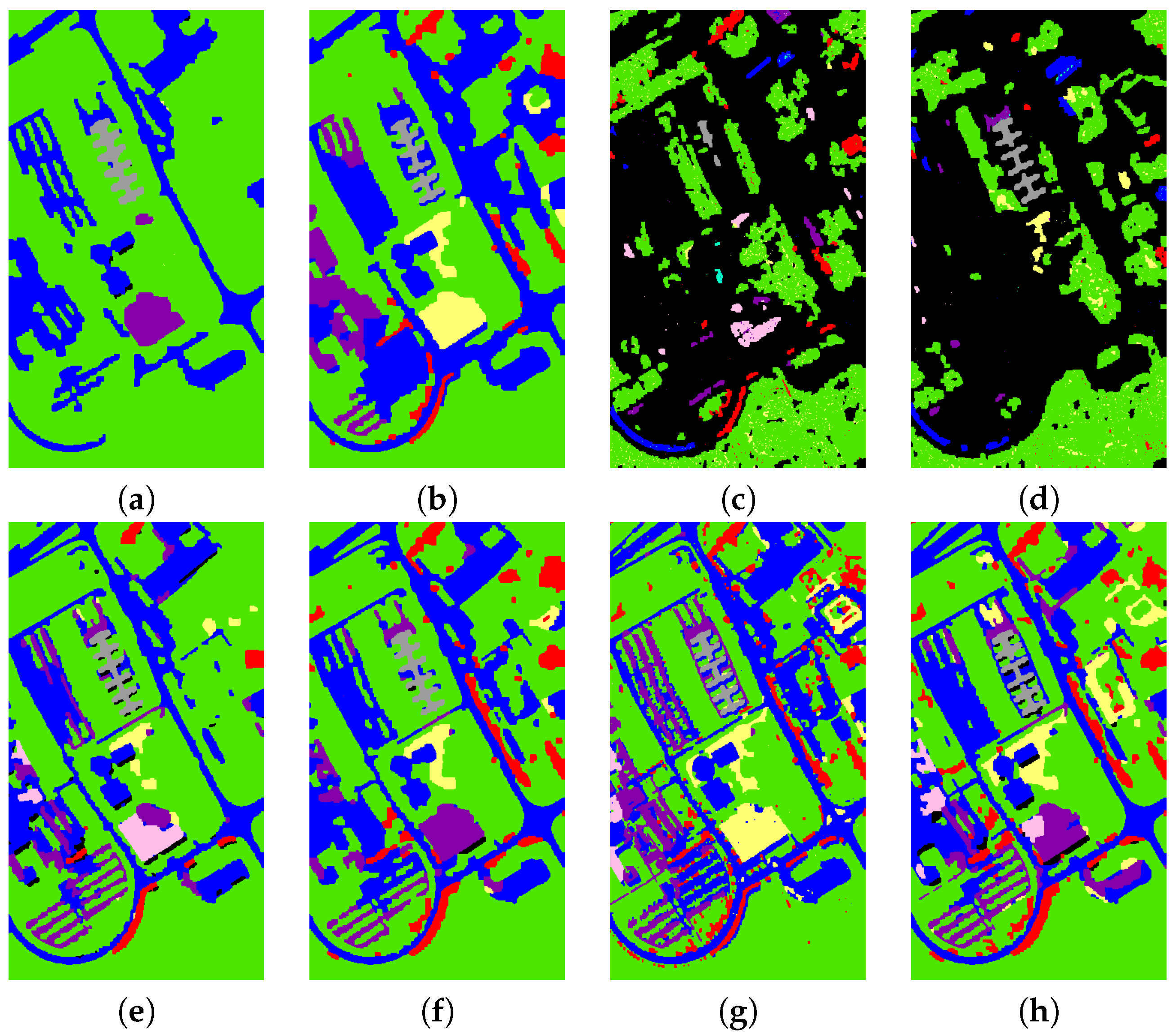
For illustrative purposes,
Figure 9 shows the obtained classification maps (corresponding to the best one after ten Monte Carlo runs). The advantages obtained by adopting the semi-supervised dictionary learning approach with regard to the corresponding supervised and unsupervised cases can be visually appreciated in the classification maps displayed in
Figure 9, where the classification OAs obtained for each method are reported in the parentheses. Compared to the ground-truth map, the proposed method obtains a more accurate and smoother classification map. Significant differences can be observed when classifying the class
Wheat in this scene, which is in accordance with the former results. However, the classification maps obtained by D-KSVD and LC-KSVD are much less homogeneous than the other methods. This observation can be explained by the fact that Graph cuts are adopted as a post processing strategy, which largely relies on the initial classification probabilities obtained by the classifiers. If the initial classification results are poor, then the classification improvements may not be satisfied. That is the case for D-KSVD and LC-KSVD with an initial OA = 60.07% for the former and an initial OA = 60.52% for the latter.
Experiment 5: In the last experiment, we analyze the mechanism of the proposed method. Firstly, we plot the stem distributions of sparse coefficients obtained by different methods. As we can see from
Figure 10, the distributions between-classifier are significantly different. Precisely, the corresponding atoms belonging to the same land cover type contribute more than the others, thus making the associated coefficients sparsely locate at those atoms. For example, the atoms indexed by 146–160 in the dictionary belong to the class
Wheat, and the sparse coefficients will mainly locate at these atoms if this class is well represented. Obviously, the proposed method produces more accurate sparse coefficients since the stem distributions mainly locate at the corresponding atoms (see
Figure 10g). As for the other methods, the associated sparse atoms cannot be accurately found, i.e., the stem distributions obtained by OnlineDL partially locate at the class
Woods.
Figure 11 spatially exhibits the sparse coefficients relative to the class
Wheat for different methods. As shown in
Figure 11, the proposed method yields more accurate sparse coefficients relative to the class
Wheat. Therefore, the aggregation characteristics of sparse coefficients naturally enlarge the discrimination between different land cover types, and the spatial variations of sparse coefficients explain the accuracy of the prosed method for sparse representation. The above observations demonstrate the good performance of the proposed method in dictionary learning, and the discrimination performance of our method has been validated in the former experiments.
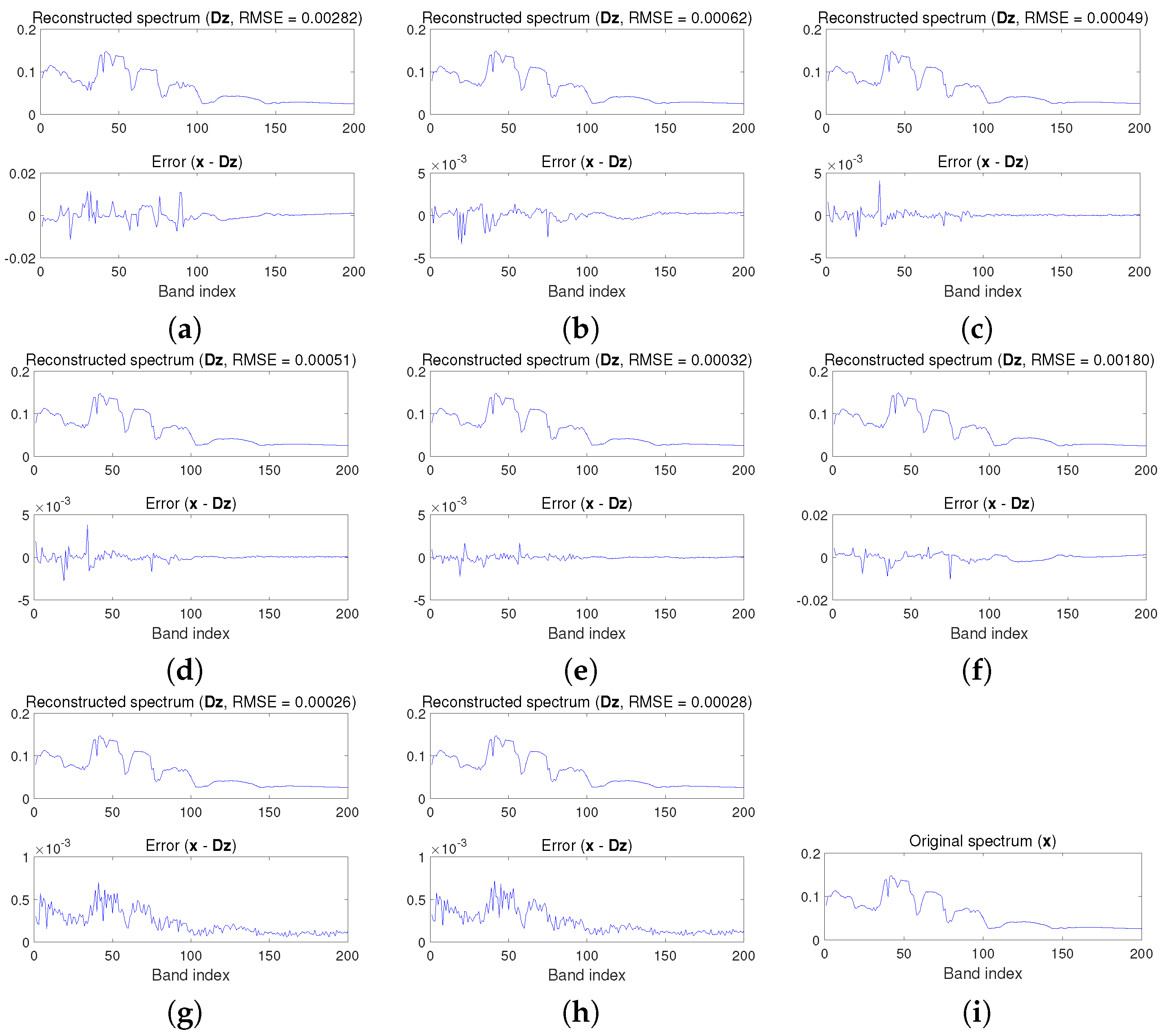
Secondly, we analyze the denoising power of the proposed method by plotting the original spectrum, the reconstructed spectrum, and the noise for the class
Wheat. From the results shown in
Figure 12, we can see the original spectrum can be accurately reconstructed with a very small Root-Mean-Square Error (RMSE) (The RMSE for two observations
and
can be defined as: RMSE =
), which is the difference between the original spectrum (
x) and the reconstructed spectrum (
Dz). It is worth noting that the proposed method obtains a very small RMSE value. In this context, the proposed method can accurately reconstruct the original spectrum with high fidelity by removing noise, which explains the robustness to noise of the proposed method in the former experiment. We then evaluate the global reconstruction performance of the proposed method by considering all classes. As reported in
Table 3, the proposed method obtains the smallest RMSE value. This experiment also hints at the good performance of the proposed method in dictionary learning.
Finally, we attempt to analyze the dictionary structure by visually illustrating the matrix
D learnt by different methods. As shown in
Figure 13, S
JDL-Sof and S
JDL-Log yield similar data structure, and the atoms belonging to the same class are more similar to each other, while the atoms belonging to different classes are more distinctive between each other. Similar observations can be made for D-KSVD, LC-KSVD, and SDL. However, the dictionaries learnt by OnlineDL model very little data structure, as shown in the figure. Note that we cannot currently explain the factors inducing the differences of dictionary structure.
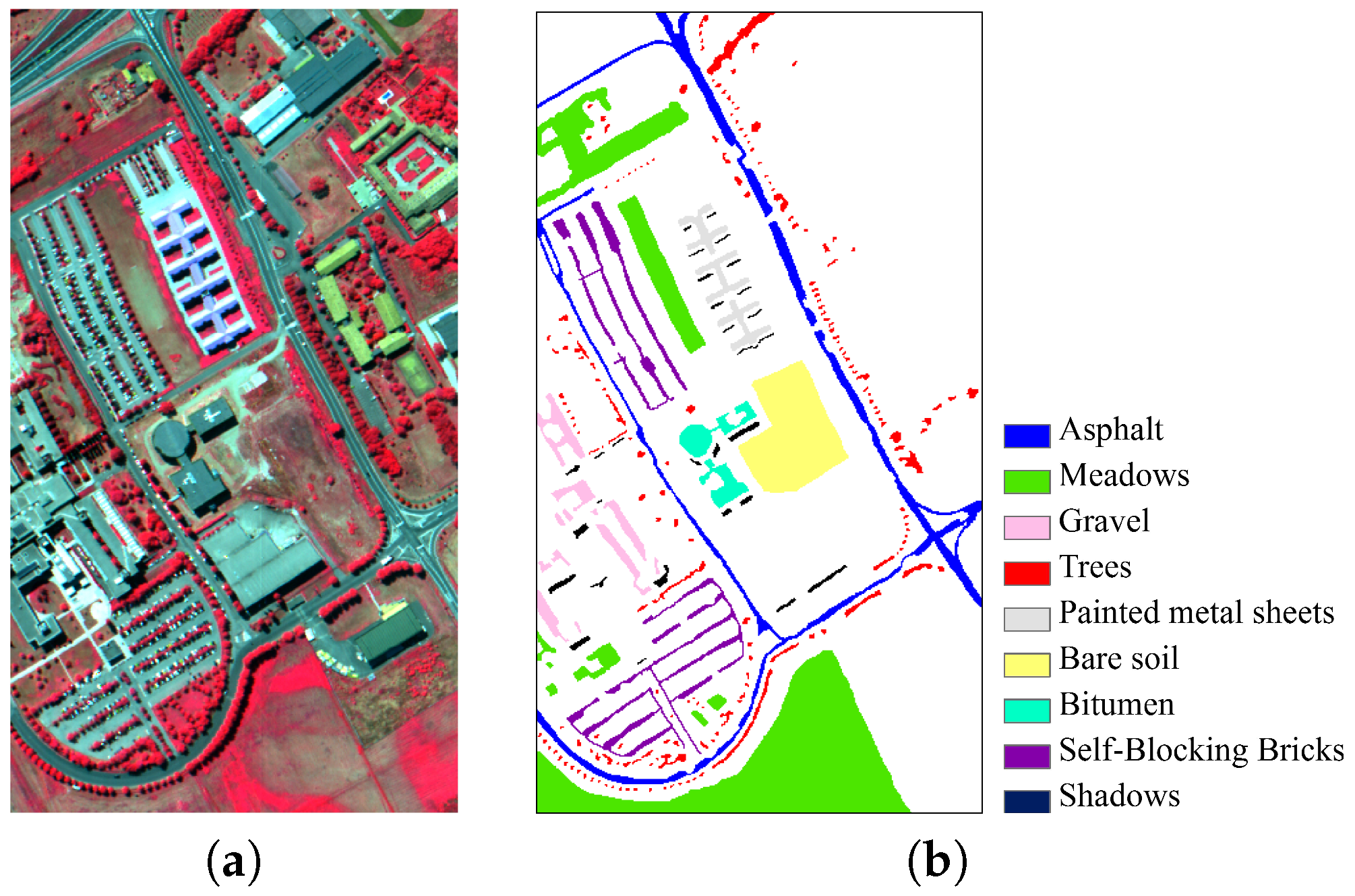
4.4. Experiments with ROSIS University of Pavia Dataset
Experiment 1: We first analyze the impact of training data size on classification accuracy. We randomly choose 5% of labeled samples per class (a total of 2138 samples) to initialize the training data and evaluate the impact of the number of atoms on classification performance achieved by the proposed method for the ROSIS University of Pavia dataset.
Figure 14 shows the OAs as a function of the number of atoms per class obtained by different methods. Again, the proposed method obtains the highest accuracies in all cases. Another observation is that, for most of the methods, the OAs increase as the number of atoms also increase. Different from the former experiments, when the number of atoms per class is larger than 10, the OAs obtained by D-KSVD and LC-KSVD become lower. In this scene, MOD does not perform very well in all cases.
Figure 15 depicts the OAs as a function of the ratio of labeled samples per class for different methods. As we can see from the figure, the proposed method obtains the highest accuracies in all cases. It is interesting to note that the proposed method cannot stably obtain improved classification performances with additional labeled samples. This may be due to the fact that the homogeneity in this scene is not so significant, and graph cuts reduce the effects of the learning phase since the classification accuracy cannot be significantly improved by using additional labeled samples. In addition, similar observations can be made for other methods. In this scene, D-KSVD does not perform very well in different cases. Again, S
JDL-Log provides competitive performance.
Experiment 2: Table 4 lists the OA, AA, individual classification accuracies, and
statistic. As reported in the table, the proposed method achieves the best results compared to the other supervised dictionary learning methods. The improvements of classification accuracy are around 3%–30% when compared to other methods. When classifying the class
Bare soil, our method obtains the highest accuracy, with an OA of 23.10%. Although this accuracy is not very high, it demonstrates the merit of the proposed method since
Bare soil is very difficult to accurately classify. In addition, the time costs of different methods are listed in the table, where we can see that the proposed method is more efficient than K-SVD, D-KSVD, and LC-KSVD. Again, MOD, OnlineDL, and SDL take less time.
Table 5 also reports the statistical tests between-classifier in terms of Kappa
z-score and McNemar
z-score. Again, the results indicate that the proposed method significantly outperforms the other methods. In this scene, we observe that OnlineDL is closer to our method, i.e., the Kappa
z-score value for OnlineDL/S
JDL is 14.2, which is in accordance with the results reported in
Table 4.
Figure 16 visually depicts the obtained classification maps. The advantages obtained by adopting the semi-supervised dictionary learning approach with regard to the corresponding supervised case can be visually appreciated in the classification maps displayed in
Figure 16, which also reports the classification OAs obtained for each method in the parentheses. As shown in the figure, the homogeneity is very clear for this scene, and the proposed method depicts a more accurate and smoother classification map. As expected, D-KSVD and LC-KSVD obtain poor classification maps for this scene.
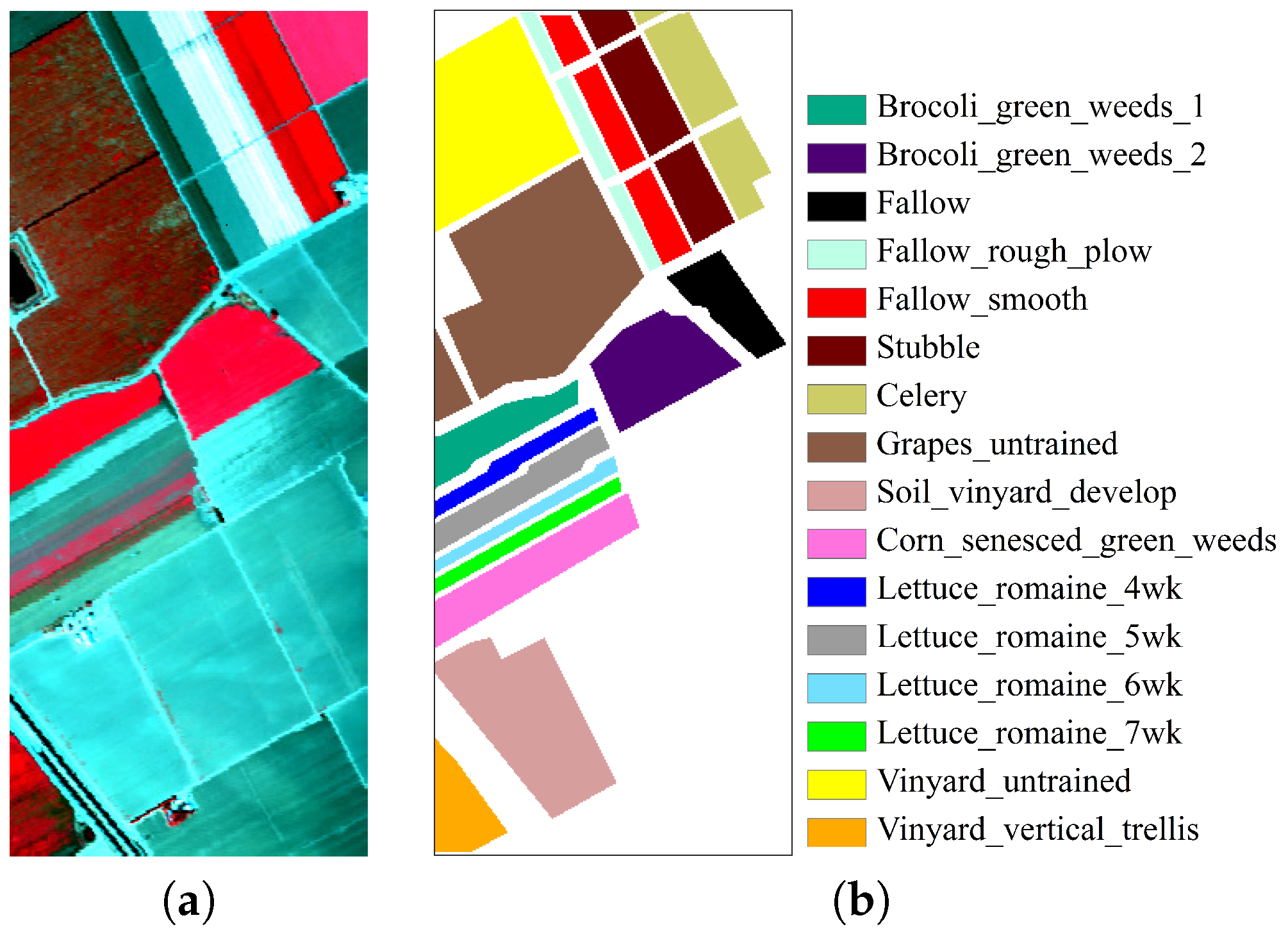
4.5. Experiments with AVIRIS Salinas Dataset
Experiment 1: Similarly, we first analyze the impact of training data size on classification accuracy. A total of 5% of labeled samples per class (a total of 2706 samples) are randomly selected to initialize the training data. We evaluate the impact of the number of atoms on the classification performance achieved by the proposed method for the AVIRIS Salinas dataset.
Figure 17 shows the OAs as a function of the number of atoms per class obtained by different methods. Similar to the experiments implemented for the AVIRIS Indian Pines dataset, the OAs become stable when 15 atoms per class are used to build the dictionary. Another observation is that when the number of atoms per class is larger than 10, our method stably outperforms the other methods. It is interesting to note that D-KSVD and LC-KSVD obtain similar results even when the latter is incorporated with the class-label information. For most of the cases, the OAs increase as the number of atoms also increases.
Figure 18 plots the OAs as a function of the ratio of labeled samples per class for different methods. As we can see from the figure, the proposed method obtains the highest accuracies in all cases. Different from the former experiments, the proposed method can stably obtain improved classification performance with the additional labeled samples in this scene. However, the additional labeled samples deteriorate the classification performance for SDL.
Experiment 2: Table 6 gives the OA, AA, individual classification accuracies, and
statistic. As reported in the table, the proposed method achieves the best results compared to the other supervised dictionary learning methods. The improvements of classification accuracy are around 10%–20% when compared to the other methods. As for the specific classification accuracy, the proposed method obtains higher accuracy when classifying the class
Lettuce_romaine_6wk. In addition, the time costs of different methods are listed in the table, where we can see that the proposed method is more efficient than D-KSVD and LC-KSVD. Again, MOD, OnlineDL, and SDL take less time.
Similarly, we conduct the statistical tests between-classifier in terms of Kappa
z-score and McNemar
z-score in this scene. According to the results reported in
Table 7, we observe that the proposed method significantly outperforms the other methods since all the tests are significant with 95% confidence. Another observation is that K-SVD and the proposed method produce similar results, with the Kappa
z-score value of 22.9.
The classification maps are given in
Figure 19, where the OAs obtained for each method are reported in the parentheses. As shown in the figure, we can see clear differences between different methods. For example, when classifying the class
Lettuce_romaine_6wk, the proposed method is more accurate compared to the other methods. In addition, the homogeneity is very clear for this scene, which is similar to the AVIRIS Indian Pines dataset. Also, our method produces a more accurate and smoother classification map compared to the other methods.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}