1. Introduction
Reference data maps, which are often called “ground truth” maps in remote sensing literature [
1,
2], are maps that accurately label areas or pixels of the map as belonging to a finite number of ground cover classes. Such maps have traditionally been used to assess the accuracy of classification algorithms. Well known examples of reference data (RD) include Cuprite [
3], Indian Pines [
4], Salinas [
5], and Pavia [
6]. These pixel-wise RD have been used extensively to quantitatively evaluate the performance of classification algorithms. Abundance map reference data (AMRD) are a special type of RD, where each pixel is allowed to be a mixture of the various ground cover classes. AMRD are designed to quantitatively evaluate the performance of spectral unmixing algorithms [
7,
8]. However, we are not aware of any similarly well-known and widely-available AMRD scenes for airborne imaging spectrometer (IS) data.
Traditional methods of generating RD, such as field surveys and imagery analysis, have not been undertaken frequently because of the time and expense required to accurately generate such data [
9]. The added complexity of allowing each RD pixel to be a mixture of the various ground cover classes further complicates the problem. In order to efficiently generate scene-wide AMRD, we proposed a technique called remotely sensed reference data (RSRD) [
7], which creates AMRD for coarse scale imagery using co-located fine scale imagery. Specifically, RSRD performs standard classification or unmixing on fine scale imagery (e.g., 1-m GSD National Ecological Observatory Network (NEON) IS), then aggregates fine scale results to co-registered coarse scale pixels (e.g., 15-m GSD Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) IS), thereby creating AMRD for the coarse scale imagery. RSRD methodology is similar to previous studies which have created sub-pixel RD using high-resolution RGB videography [
10], RGB imagery [
11], multi-spectral imagery [
12], and IS imagery [
13,
14,
15].
While RD frequently have been used to assess the performance of classification algorithms and occasionally have been used to assess unmixing algorithms, many studies neglect to account for the accuracy of the RD itself. This means that RD of unknown accuracy often have been used as the benchmark for assessing the accuracy of other algorithms. Indeed, we are not aware of any RD scenes with published validation studies of the RD itself.
In order to determine the accuracy of AMRD generated using the RSRD technique, we conducted an extensive validation study of AMRD for three remote sensing scenes [
8]. This paper continues our work with AMRD by applying our previously generated and validated AMRD to specific coarse scale airborne IS imagery. The main concepts involved in applying validated AMRD to coarse scale imagery are listed below.
Spatial alignment of fine and coarse scale imagery
Aggregation of fine scale abundances to produce specific coarse scale AMRD
Comparison of spectral unmixing results and AMRD.
The objective of this study, therefore, is to implement these main concepts using several versions of coarse scale imagery and spectral unmixing. The subsequent sections introduce these important concepts in more detail.
1.1. Spatial Alignment
Accurate spatial alignment between fine and coarse scale imagery is necessary to properly use validated AMRD. Misalignment by only half a coarse scale pixel would significantly increase the error in AMRD itself. Imprecise spatial alignment would necessitate scaling analysis to multiple pixel windows, for example, one previous study using RSRD-like RD recommended scaling analysis to 9 × 9 Landsat pixel windows (270 m × 270 m on the ground) due to inaccurate alignment between fine and coarse imagery [
10].
Airborne imagery georegistration is often accurate to 0.5–1.0 pixels. For example, AVIRIS does not claim sub-pixel accuracy from their improved (2010 version) orthorectification and georeferencing processing [
16]. We have observed registration errors of 15+ m between NEON and AVIRIS imagery [
7]. Lack of georeferencing accuracy necessitates image-to-image spatial alignment, rather than relying on imaging system geocoding.
Image registration is a vast field of research where numerous approaches and algorithms have been developed for a wide variety of image processing tasks. Common approaches include feature matching and intensity correlation, with comparisons made in both the spatial and frequency domains, while post registration resampling and alignment of data are carried out with affine transforms or warping [
17]. Remote sensing image registration has often relied on feature matching methods and warping [
18,
19]. It should be noted that image registration for RSRD is challenging due to highly dissimilar spatial resolution, the need for sub-pixel registration accuracy, and the use of different imaging sensors.
Spatial Fidelity of Individual Coarse Pixels
In addition to aligning fine and coarse scale imagery at the whole scene level, we must also concern ourselves with the spatial fidelity of individual coarse pixels. Much processing occurs between initial airborne collection of radiometric information and final output of imagery, which often includes atmospheric compensation, ortho-rectification, resampling to a north-south oriented grid, etc. [
1,
2,
20]. The method used to spatially resample imagery is of special importance to the spatial fidelity of individual coarse pixels. Nearest-neighbor resampling is often employed in the ortho-rectification and resampling to a north-south grid process [
21,
22], prioritizing the radiometric fidelity of each collected sample, rather than the spatial fidelity of radiometric information. In the best case, nearest-neighbor resampling results in some final pixels whose reflectance values are a result of initial collections at pixel edge rather than at pixel center. In the worst case, nearest-neighbor resampling results in significant pixel re-use, where adjacent pixels are identical, because one airborne collection sample was spatially closest to two or more final pixels.
1.2. Spatial Aggregation
Aggregation is the term we use to describe averaging together the spectra of many fine pixels that are co-located within a single coarse scale pixel. Aggregation can be implemented using a simple averaging filter covering the rectangular area conceptualized by each coarse scale pixel, or it can take into account the point spread function (PSF) of a pixel, where reflected light from the center of pixels contributes more to the final reflectance value of a pixel than light from pixel edges, and at the same time, each pixel is affected by reflected light originating from outside its rectangular pixel outline [
23,
24]. The rectangular method is more representative of cover class mixtures on the ground, while the later is more representative of the radiometric information that would have been collected by the imaging sensor. Both methods are used in this study for purpose of comparison.
1.3. Comparison of Unmixing Results and AMRD
In most cases, AMRD have not been available to quantitatively assess the performance of spectral unmixing algorithms. In the absence of AMRD, researchers have used various methods to assess performance. Qualitative assessments have visually compared unmixing results to well-known RD, such as Cuprite, Indian Pines, and Pavia [
25,
26,
27]. Quantitative assessments have used synthetic data [
25,
26,
27], average per-pixel residual error [
27,
28], used the mean of several algorithms as the ideal and computed residuals from the ideal [
28], etc.
Confusion matrices have been the standard method of quantitative comparison between RD maps and classification algorithms [
1,
2,
9]. A confusion matrix is an
matrix for an
n-class problem. Rows of the matrix typically represent RD, while columns represent classification data, where the
th entry represents the number of pixels in the image belonging to class-
i that were classified to class-
j. Confusion matrices allow the evaluation of overall classification accuracy, as well as providing insight into which classes tend to be confused with one another. Unfortunately, confusion matrices aren’t readily applicable to spectral unmixing and AMRD. Methods have been proposed to generalize confusion matrices for use with AMRD [
29], but these methods do not allow straight-forward comparison of individual matrix elements, and essentially amount to comparing total RD area to total unmixed area per class.
As mentioned previously, there are a number of studies that have produced sub-pixel RD through methodologies similar to our RSRD process. These studies also implemented methods to compare AMRD with spectral unmixing results, with the most common strategy being calculation of mean absolute error (MAE) and/or root-mean square error (RMSE) [
11,
12,
13]. Several studies plotted unmixed fraction versus RD fraction and computed a linear regression of the result. Using this technique, perfect unmixing would result in an
and slope equal to unity, with the intercept equal to zero [
10,
13].
2. Methodology
2.1. Data
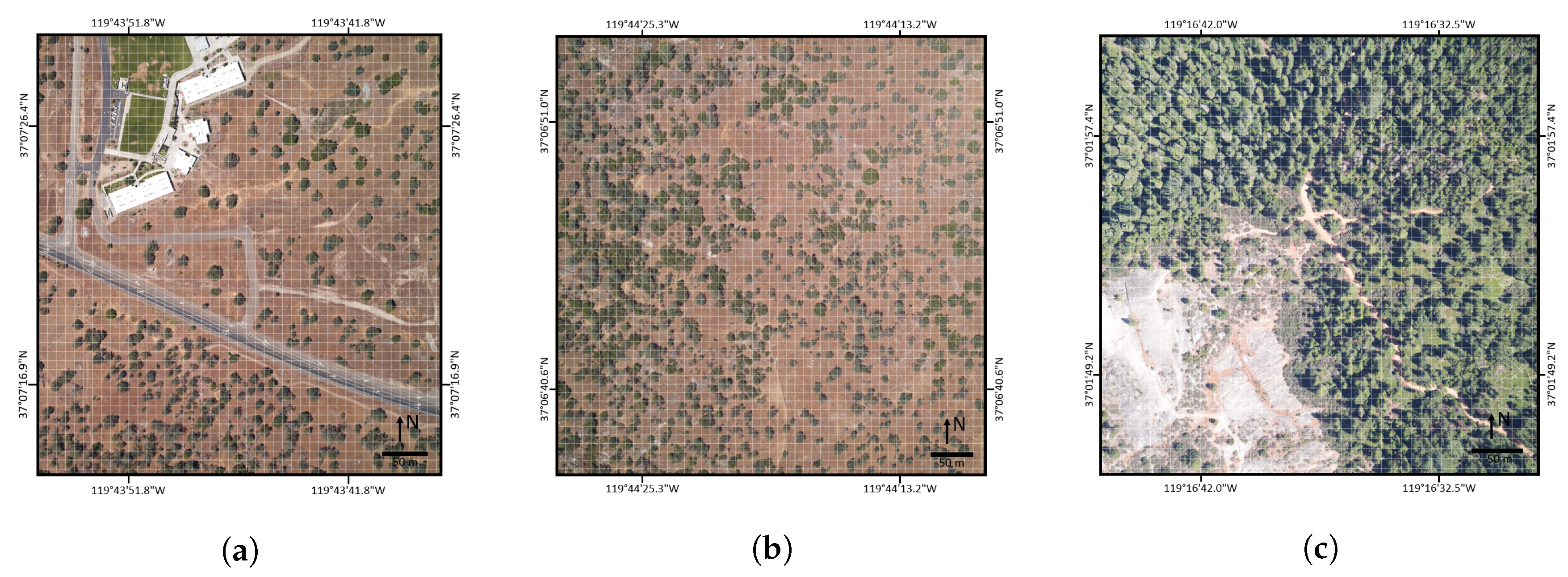
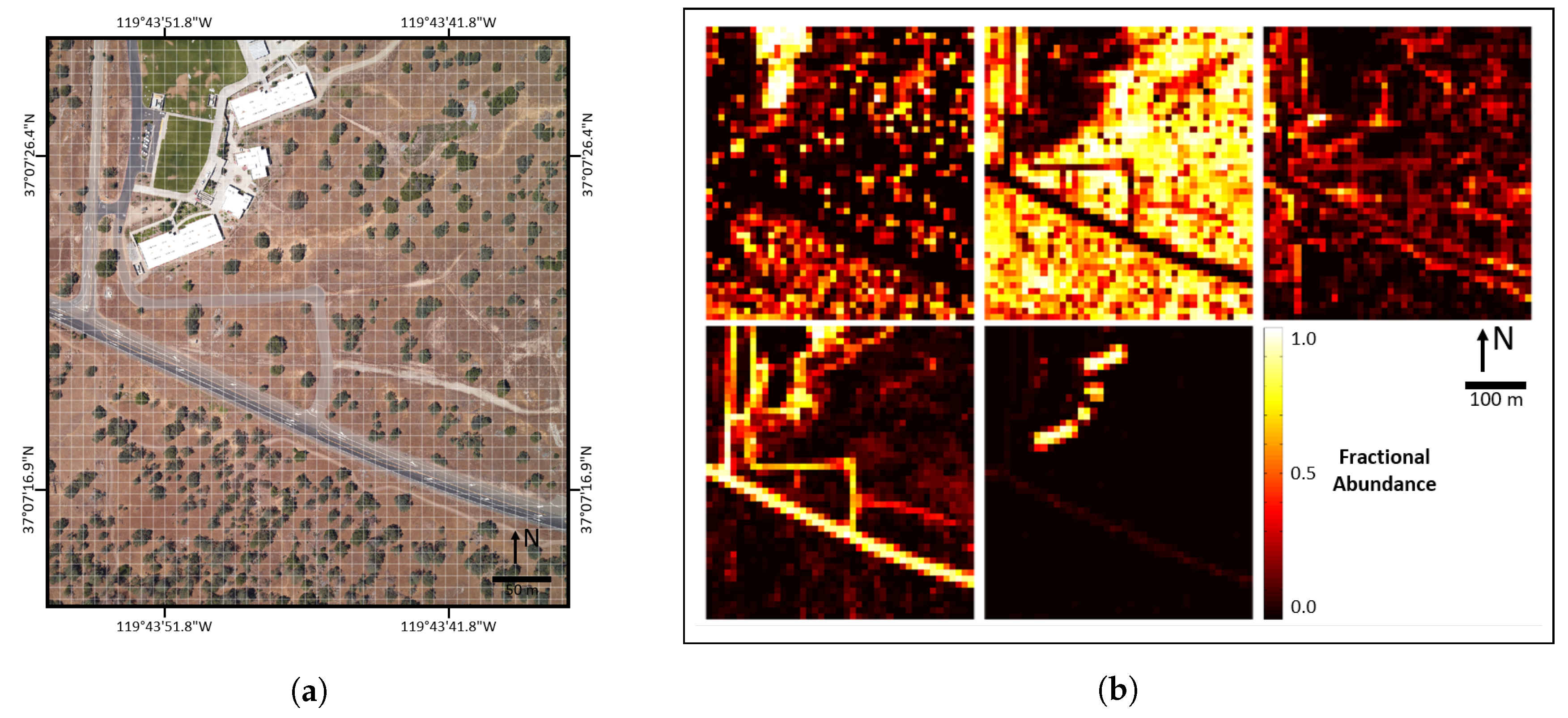
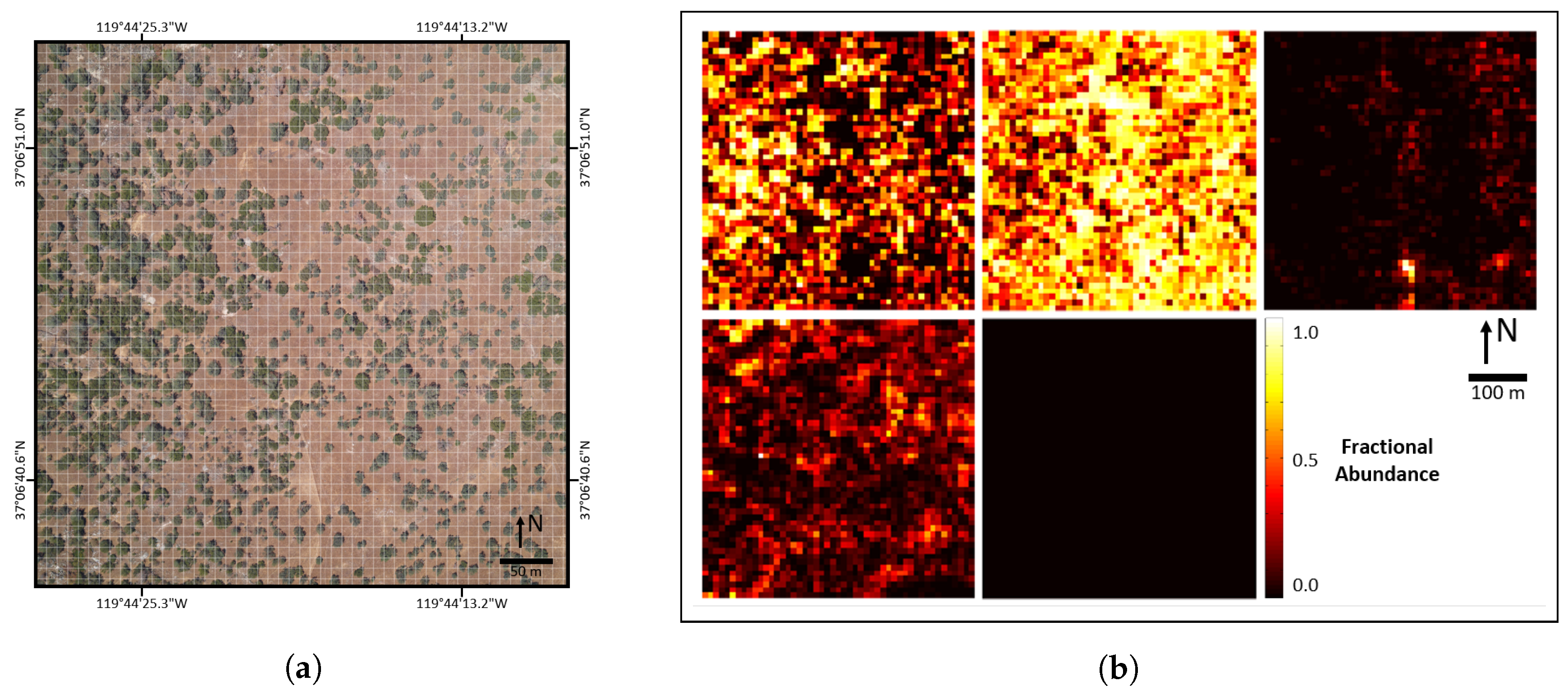
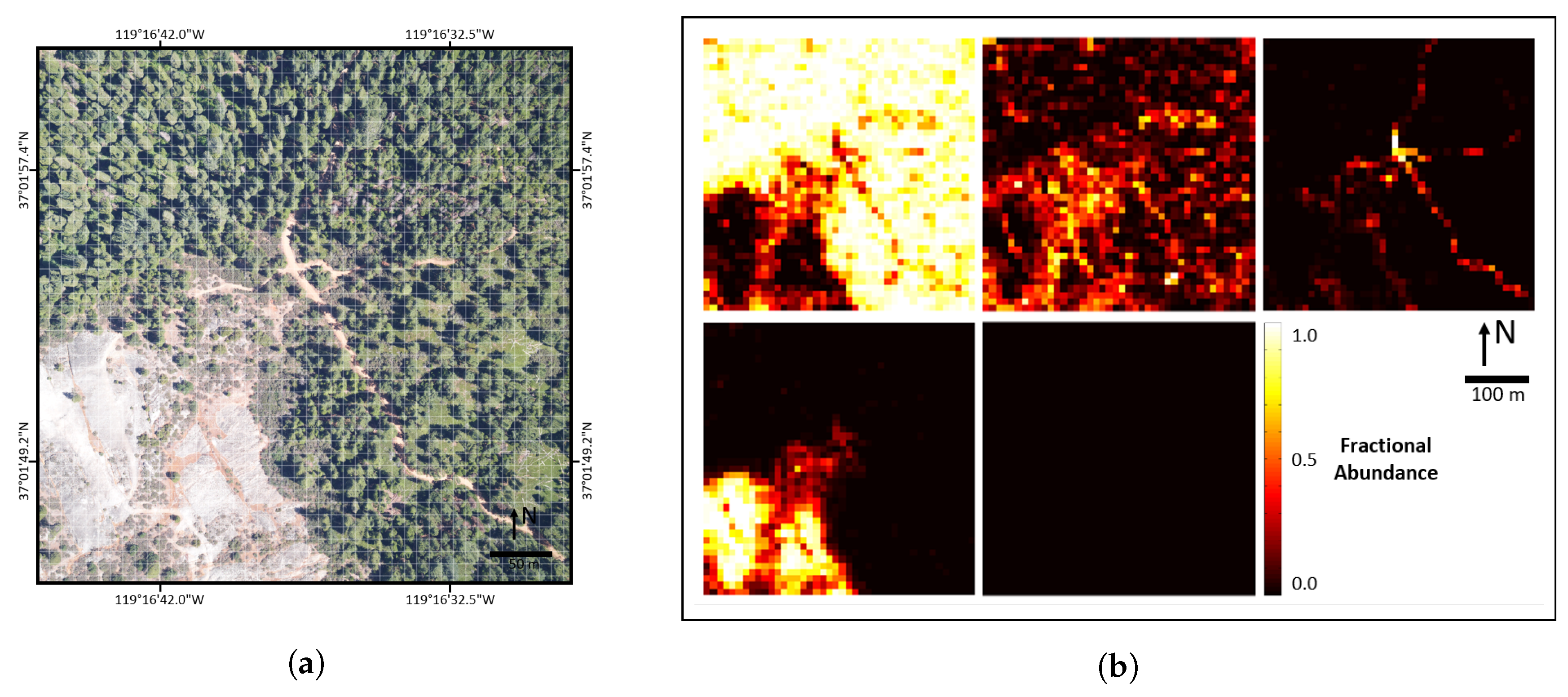
The three study scenes used in this paper are located on or near NEON Domain 17 (D17) research sites near Fresno, CA, USA. We selected these specific areas because they contained significant ground cover variation. The three scenes contain mostly natural landscapes, including high mountain forests, large rock outcroppings, dry valley grasslands, and oak savannah. We also included a developed area with buildings, roads, grass fields, etc. These cover types are representative of many remote sensing scenes and the results should be generally applicable to other similar studies. Extension of our methodologies to more complex urban landscapes should be possible, but we caution that each additional ground cover class increases the complexity of reference data generation and validation, while likely lowering the accuracy of resulting AMRD. Further information for each site is listed below and RGB imagery of the study areas is shown in
Figure 1.
SJERHS—San Joaquin Experimental Range (SJER), Minarets High School (HS)—Located just outside the northern extent of SJER land on privately owned Minarets High School property.
SJER116—San Joaquin Experimental Range (SJER), NEON field site 116—Located on public property in the area surrounding NEON SJER field site #116.
SOAP299—Soaproot (SOAP) Saddle, NEON field site 299—Located on public property in the area surrounding NEON SOAP field site #299.
NEON and AVIRIS conducted a joint aerial campaign over these areas in June 2013.
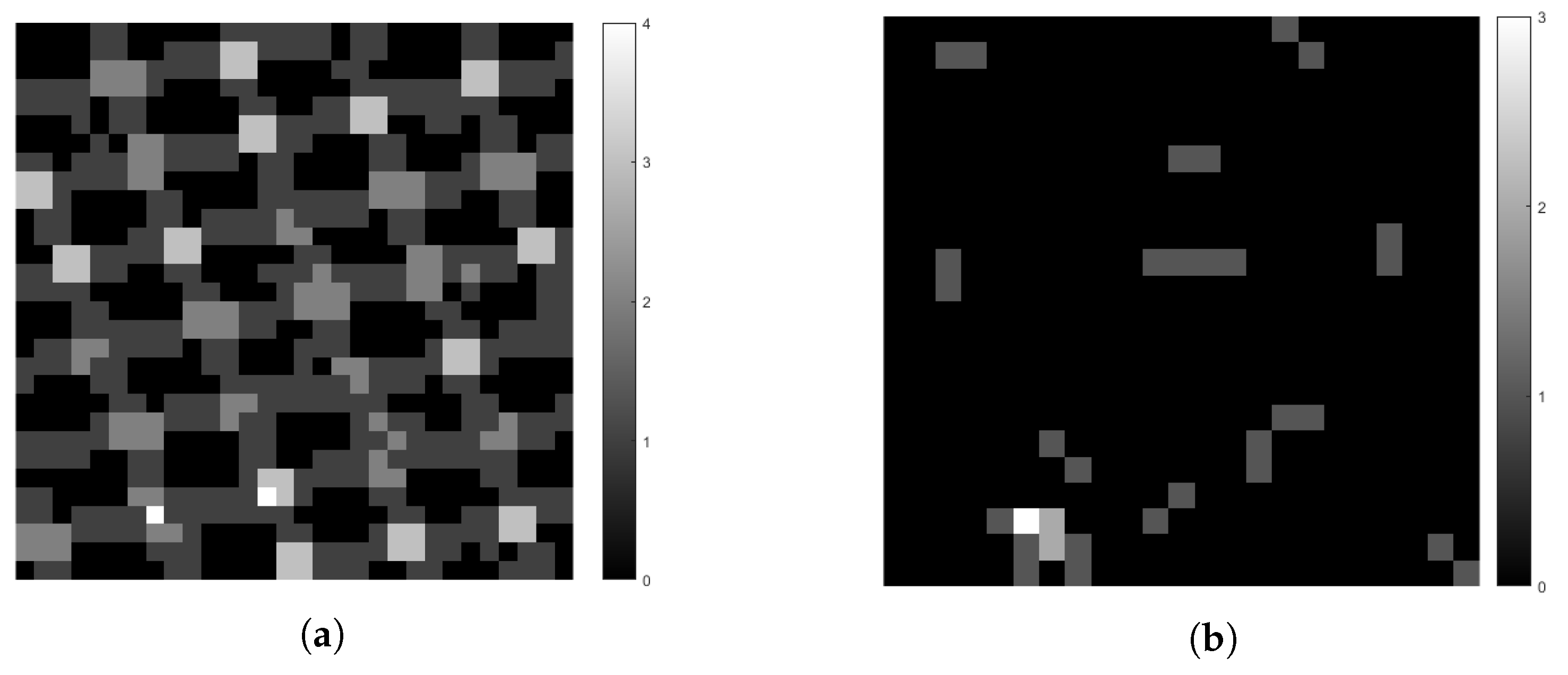
Table 1 contains detailed information on the imagery provided to us by NEON and AVIRIS, along with synthetic coarse scale imagery (NEON 15 m/29 m), which we used in this experiment. NEON RGB data were not used in processing tasks, but were useful for enhancing human analyst understanding of the study areas. Note that we used both orthorectified and unorthorectified AVIRIS data in this study, because AVIRIS’ orthorectification processing resulted in many replicated pixels due to nearest-neighbor resampling.
AVIRIS Ortho data were generated as part of the NASA HyspIRI preparatory campaign, which spatially resampled data to a 15-m GSD grid, rather than the standard 18-m GSD grid. This finer sample spacing resulted in higher than normal pixel reuse from nearest-neighbor resampling.
Figure 2 displays the amount of pixel reuse in AVIRIS Orthorectified vs AVIRIS Unorthorectified data for the SJERHS scene. This trend was present in all three scenes.
We generated synthetic coarse scale imagery from NEON IS data via frequency domain filtering and spatial domain downsampling of fine scale data using a Gaussian filter, whose spatial domain full width at half maximum (FWHM) was equal to the desired final GSD, thereby simulating coarse sensor PSF. We used this method to create NEON 15 m and NEON 29 m data. The NEON 15 m data were introduced for purposes of comparison with AVIRIS Ortho and Unortho data, while the NEON 29 m data were introduced to study the implications of applying our validated AMRD to coarser scale imagery.
2.2. Validated Abundance Map Reference Data
As mentioned previously, the primary purpose of this paper is to demonstrate the application of previously validated AMRD to specific examples of airborne remotely sensed imagery, such as the AVIRIS imagery described in
Table 1. We recommend reviewing the validation paper [
8] for detailed information on the validation process; however, we will mention the effort briefly here.
Let be an estimate of , using method m, where is the “true” abundance fraction of ground cover class c in coarse pixel p. We generated for 10 m × 10 m plots, randomly chosen from the three study scenes, ground cover classes, and independent methods of abundance estimates. Details of C and M are listed below. As discussed previously, RSRD aggregates fine scale classification or unmixing results to co-located coarse scale pixels, thereby estimating abundance fractions. We performed the underlying classification/unmixing using a Euclidean distance (ED) classifier, non-negative least squares (NNLS) spectral unmixing algorithm, and by taking the posterior probabilities from a maximum likelihood (ML) estimator, thereby estimating coarse scale abundances using independent algorithms employed within the RSRD framework.
: Field surveys by Observer-A (Field-A)
: Field surveys by Observer-B (Field-B)
: Imagery analysis by Observer-A on NEON IS, aided by NEON RGB (Analyst-A)
: Imagery analysis by Observer-B on NEON IS, aided by NEON RGB (Analyst-B)
: RSRD by Euclidean distance (ED) on NEON IS (RSRD-ED)
: RSRD by non-negative least squares (NNLS) spectral unmixing on NEON IS (RSRD-NNLS)
: RSRD by maximum likelihood (ML) on NEON IS (RSRD-ML)
We found statistically significant differences between
,
, … ,
, and concluded that no single estimate method was demonstrably superior, based on pairwise comparisons. Given that
was unknown, we concluded that the best estimate of true abundance fractions within each 10 m × 10 m plot was the mean of all (MOA) independent versions. MOA is defined in Equation (
1).
We then compared each estimation method to MOA using Equations (
2)–(
4), and found that
(Analyst-B) was the closest method to MOA; however,
(RSRD-NNLS) was nearly as close to MOA, and provided the opportunity to efficiently generate scene-wide AMRD. As such, we selected RSRD-NNLS to serve as AMRD for our three scenes, with validated accuracy documented in
Table 2. Note that we used our NNLS unmixing algorithm on fine scale imagery, but we later enforced a sum-to-one constraint on coarse scale AMRD pixels.
This validation was performed for generic 10 m × 10 m coarse scale imagery, such that the validated scenes could be applied to any co-located coarse scale imagery with GSD > 10 m, such as the AVIRIS data used in this study. The validation study suggested that further aggregation beyond 10 m GSD would decrease the expected standard deviation differences from MOA, but would have no expected effect on mean differences from MOA. Since the coarse data used in this study have GSD ≥ 15 m, we expect the resulting AMRD accuracy to be similar to that listed in
Table 2, with slightly reduced standard deviation.
The three scenes and corresponding validated AMRD are shown in
Figure 3,
Figure 4 and
Figure 5. Note that a fifth class, other (roof), was included in the abundance maps to account for the buildings in SJERHS. However, this class was excluded from analysis in the validation because we were not able to collect field survey validation samples on roof tops. We have also excluded it from analysis in this paper, since its accuracy was not validated.
2.3. Spatial Alignment
Spatially aligning fine scale NEON IS data and coarse scale AVIRIS IS data was an important step in applying validated AMRD to specific coarse scale imagery. We first attempted the image registration task using well known feature matching algorithms, including various configurations of ENVI’s image registration workflow [
19] and a Scale-Invariant Feature Transform (SIFT) based algorithm [
30]. In all cases, is was difficult to accurately identify matching features between fine and coarse scale imagery, leading to badly warped and misaligned output data. Furthermore, these algorithms resampled the warp image to coincide with the base image coordinate system, and did not provide a method to estimate registration accuracy in terms of distance on the ground. It is worth noting that the purpose of this study was not to optimize a state-of-the-art image registration algorithm; we simply needed a method capable of aligning fine and coarse scale imagery within a fraction of coarse scale pixels, thereby preserving the accuracy of validated AMRD.
As such, we used an enhanced version of our own image alignment algorithm [
7] to align NEON IS imagery with AVIRIS Ortho, AVIRIS Unortho, NEON 15 m, and NEON 29 m data. We coined this algorithm as “Scene-Wide Spectral Comparison” (SWSC). SWSC is an intensity comparison, spatial domain, affine transform class alignment algorithm that uses the full spectrum of IS data for alignment comparisons. Specifically, the algorithm iteratively rotates, scales, and translates scale imagery, and at each iteration, compares coarse scale pixel spectra to an aggregation of the underlying fine scale pixel spectra. Comparisons were made using Spectral Angle Mapper (SAM) [
1], which is described in Equation (
5), where
s represents an AVIRIS pixel spectrum and
x represents an aggregation of underlying NEON pixel spectra.
The following steps detail our use of the SWSC algorithm to align NEON and AVIRIS imagery:
Extract study scene imagery from flight-line imagery in such a way that AVIRIS scenes are larger than NEON scenes in terms of real distance on the ground.
Spectrally resample NEON data to match AVIRIS spectral sampling, using a Gaussian model with FWHM equal to band spacing.
Trim NEON and AVIRIS data, resulting in square study scenes with an odd number of pixels along each edge. AVIRIS should still be larger than NEON in real ground distance.
Construct an x-y coordinate system for each image, where the image center is located at the origin and each pixel is represented by an integer value.
Iteratively rotate (
R), scale (
S), and translate (
T) the NEON coordinate system using Equations (
6)–(
9) [
2].
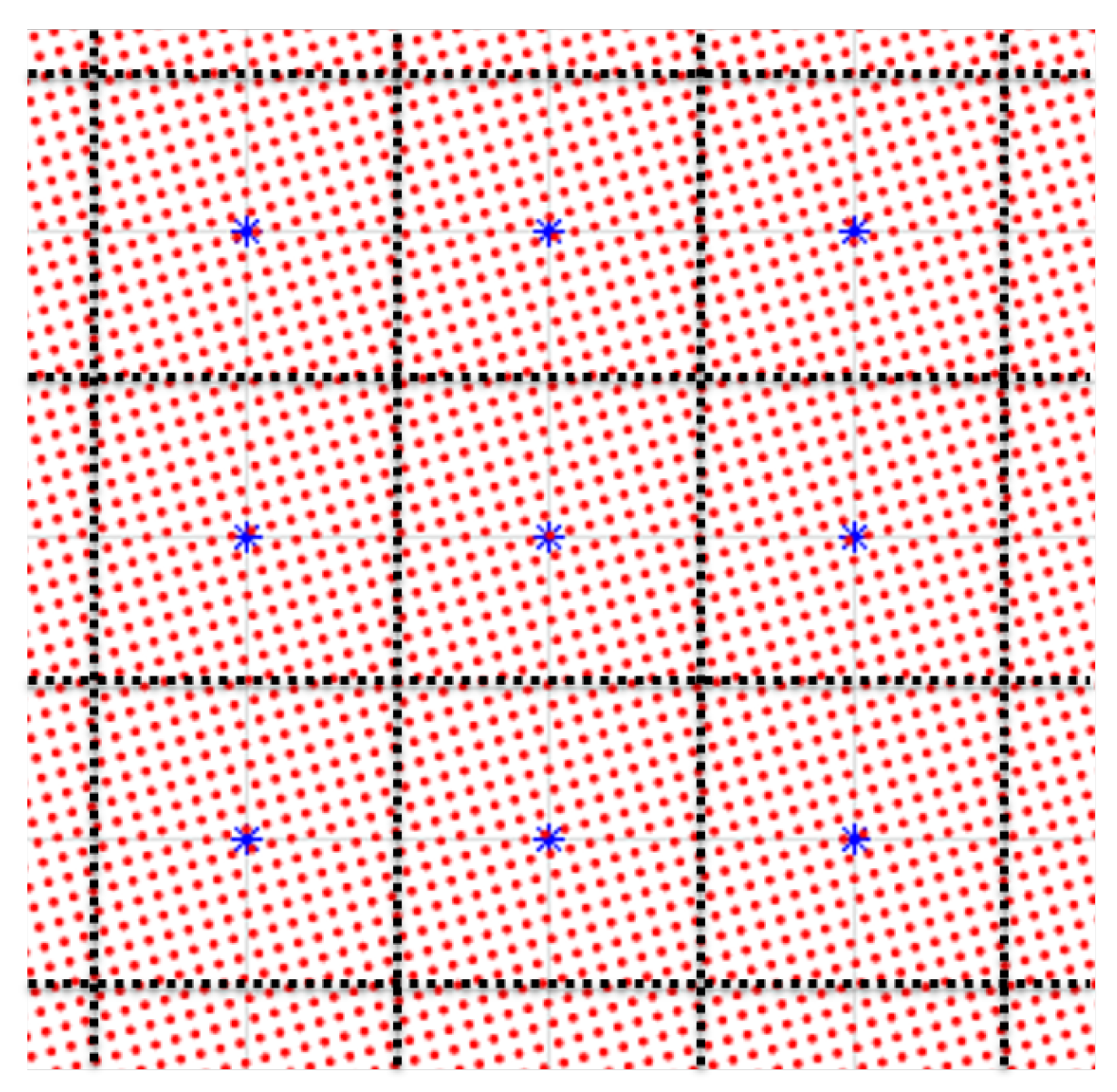
At each rotate, scale, and translate iteration, compare each AVIRIS pixel spectrum to the underlying aggregated NEON pixel spectra using Equation (
5) (see
Figure 6).
Compute the mean of all comparisons in the previous step.
Cycle through all rotation, scale, and translation iterations.
Examine the mean graphs to identify the rotation, scale, and translation position resulting in the minimum mean , this is the location of optimal alignment.
Based on the optimal alignment location, trim excess AVIRIS and NEON imagery, resulting in final aligned images.
Based on the optimal alignment location, aggregate validated AMRD corresponding to final aligned AVIRIS imagery, resulting in final aligned AVIRIS specific AMRD.
Confirm alignment via visual inspection of imagery and AMRD.
When aligning data, we first defined a range of possible parameters for rotation, scale, and translation via visual inspection of imagery. We then ran steps 5–8 of the algorithm described above several times, each time narrowing parameter ranges and sampling distances. This manual optimization of alignment parameters could likely be automated in the future to improve algorithm usability. Imagery was considered aligned when mean graphs showed well-defined troughs and parameter sampling distances had reached the following precision:
This sampling precision resulted in approximately single fine scale pixel precision at imagery edges, from each parameter. The combined precision error from the three parameters, along with uncertainty in mean graphs, could result in an absolute spatial alignment error greater than one fine pixel, with the error expected to increase toward imagery edges.
2.4. Spatial Aggregation
Aggregation of fine scale pixels corresponding to coarse scale pixels was used in both the SWSC algorithm and in subsequent generation of final coarse scale AMRD. We performed both these tasks using two versions of aggregation, a simple rectangular averaging filter the size of coarse scale pixels, and a Gaussian filter with full width half max (FWHM) equal to the GSD of coarse scale pixels. Gaussian aggregation of fine scale pixels was representative of the coarse scale sensor PSF [
20]. Rectangular aggregation was performed via averaging pixel spectra in the spatial domain, while PSF aggregation was performed via multiplication in the frequency domain and downsampling in the spatial domain.
2.5. Spectral Unmixing
Spectral unmixing of coarse imagery was performed in order to demonstrate assessment of unmixing performance using AMRD. We unmixed the coarse scale imagery using unconstrained least squares (LS) [
1], non-negative least squares (NNLS) [
31], and fully-constrained least squares (FCLS) [
31], represented by Equations (
10)–(
12), respectively. We re-used the same endmembers for coarse scale unmixing that we had used to produce our validated AMRD. In the case of AVIRIS Ortho/Unortho unmixing, NEON derived endmembers were spectrally resampled to match AVIRIS bands. Endmembers were obtained from NEON IS imagery by manual inspection and selection, including choosing ten exemplar pixels for each initial ground cover class, whose spectral mean served as the class endmember (
). While this method was somewhat simplistic compared to state of the art endmember generation and variability research, its accuracy compared to field surveys and imagery analysis was carefully validated in our previous work. Endmembers were selected independently for each of the three scenes and remained constant throughout validation and application. Unmixing was performed using a larger number of initial ground cover classes, which were subsequently combined into our final ground cover classes of PV, NPV, BS, and Rock. For example, in the SJERHS scene, initial ground cover classes were: white roof, grey roof, grass vegetation, tree vegetation, dry vegetation, dry grass, dirt road, dirt trail, concrete, and blacktop. We selected these initial ground cover classes to characterize the major spectral variation within the scene. Unmixing was performed using these initial ground cover classes, with resulting abundances being combined to produce abundances for our final cover classes. Further details are available in our AMRD validation paper [
8].
2.6. Comparison of Spectral Unmixing Results and AMRD
Previous methods of comparing spectral unmixing abundances to AMRD include mean absolute error (MAE), root-mean square error (RMSE), and linear regression. In this study, we compared spectral unmixing abundance maps to AMRD using the previously introduced MAE and LR methods, along with new methods called reference data mean adjusted MAE (MA-MAE) and reference data confidence interval adjusted MAE (CIA-MAE). These new methods take into account the known error in the AMRD itself, which is listed in
Table 2. While basic MAE measures error compared to AMRD, MA-MAE and CIA-MAE are more interesting because they remove mean error in the AMRD, thereby tying error estimation back to true ground abundances. The MAE-based comparisons are described in Equations (
13)–(
16), where
are unmixing abundances,
are reference data,
are AMRD mean distances from MOA, and
are AMRD confidence intervals.
The regression comparison methods are described in Equations (
17)–(
19), where Equation (
17) is solved using simple linear regression to obtain the slope
and intercept
. The calculated abundances,
, are found using Equation (
18), and the closeness of fit,
, is found using Equation (
19), where
represents the mean unmixing fraction of class
c.
3. Results
3.1. Spatial Alignment Accuracy
Spatial alignment was performed between NEON IS imagery and AVIRIS Ortho, AVIRIS Unortho, NEON 15 m, and NEON 29 m imagery for the SJERHS, SJER116, and SOAP299 scenes using Scene Wide Spectral Comparison (SWSC). SWSC alignment depended on identifying the rotation, scale, and translation parameters corresponding to the minimum mean between coarse and fine scale imagery.
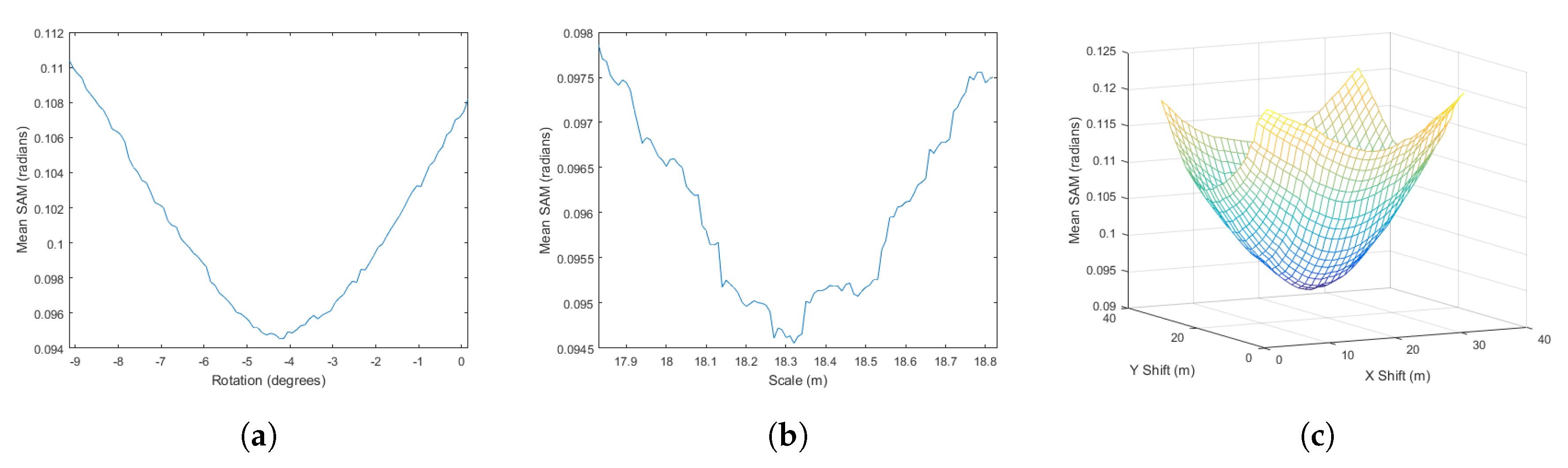
Figure 7 displays an example of the mean
graphs we used to identify rotation, scale, and translation parameters for optimal spatial alignment. This particular case is from alignment of NEON IS and AVIRIS Unortho imagery for the SJERHS scene. As
Figure 7a indicates, the troughs for scale were less smooth and well behaved than rotation and translation troughs, when all troughs were zoomed to a range equal to 100× the precision required for 1 m alignment accuracy at image edge.
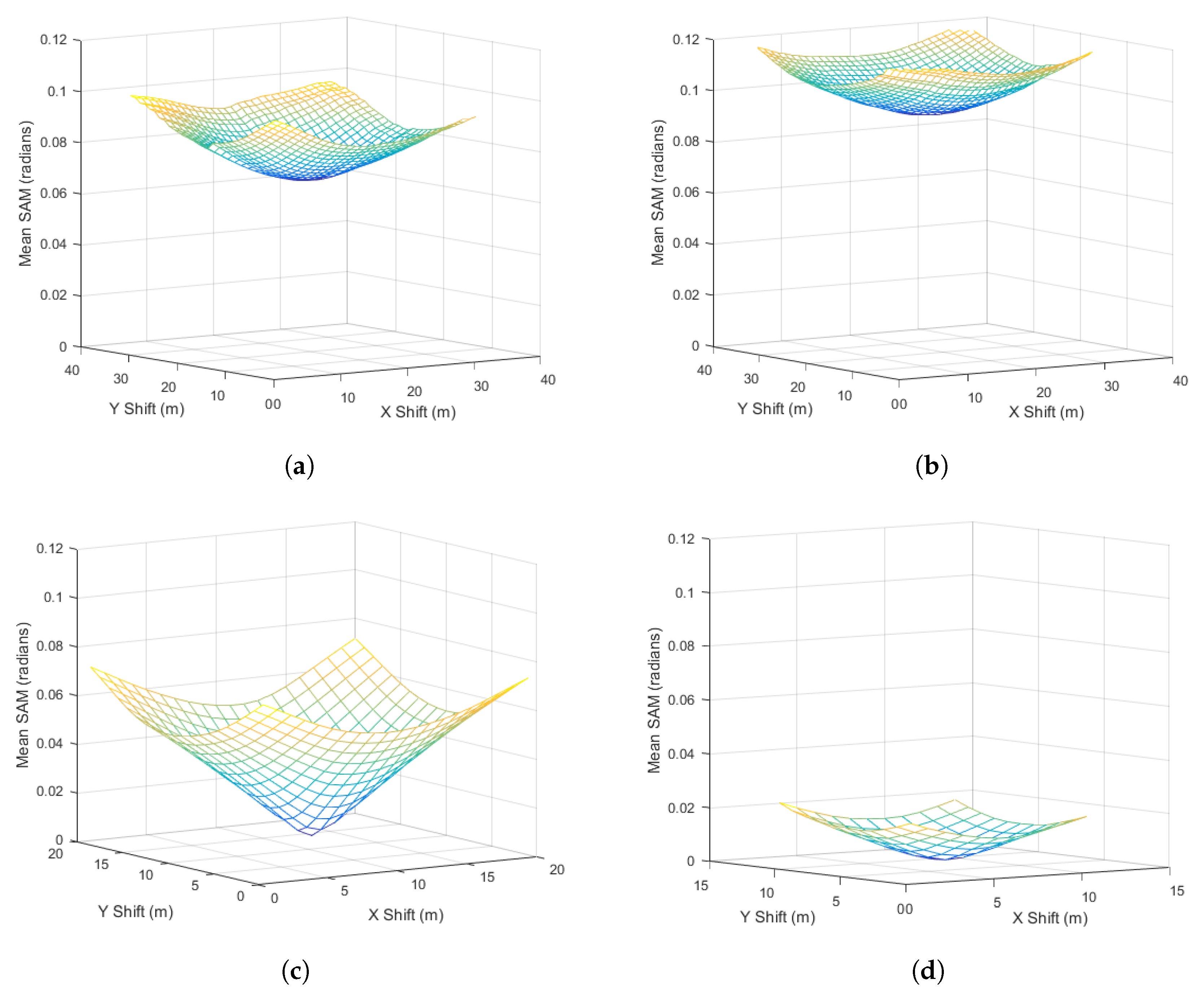
Figure 8 displays the translation parameter’s mean
troughs for AVIRIS Ortho, AVIRIS Unortho, NEON 15 m, and NEON 29 m. We chose the same vertical scale for all sub-figures in order to more easily compare the relative mean
ranges for the various versions of coarse imagery. Mean
values were significantly lower for the semi-synthetic coarse imagery, i.e., NEON 15 m and 29 m, than for the AVIRIS coarse imagery. Surprisingly, mean
values for AVIRIS Ortho were lower than AVIRIS Unortho, despite the high rate of pixel reuse from nearest-neighbor resampling.
Table 3 lists the minimum mean
values between NEON SI and all four versions of coarse imagery, using both PSF and rectangular aggregation, for the SJERHS, SJER116, and SOAP299 scenes. In general, mean
values were lowest for the SJERHS scene and highest for the SOAP299 scene. We attributed these differences in alignment accuracy to steep elevation gradients and shade shifting throughout the day in the SOAP299 scene. PSF aggregation returned slightly lower mean
results than the rectangular case. Similar to the results displayed in
Figure 8, alignment between NEON IS and semi-synthetic coarse imagery returned much lower mean
values than alignment with AVIRIS imagery.
Occasionally, PSF and rectangular aggregation methods yielded slightly different rotation, scale, and/or translation parameters, which amounted to alignment differences of less than 1 m. In these cases, we split the difference between the results from the two methods. Since NEON 15 m/29 m data were generated directly from NEON IS data, we knew the position of correct alignment, and in all cases, the SWSC method re-aligned NEON 15 m/29 m within one fine scale pixel of the true values.
3.2. Assessing the Performance of Unmixing Using Mean Absolute Error
We computed MAE, MA-MAE, and CIA-MAE for all permutations of four image types (
i,
I = 4), three unmixing types (
u,
U = 3), and two AMRD types (
r,
R = 2), resulting in
,
, and
. We then compared results within each category, by averaging across all permutations from the other categories. For example,
. The results of this analysis are shown in
Table 4. In this analysis, we combined results from three study scenes and four ground cover classes, due to the large amount of available data. Note that errors for certain scenes or classes may depart significantly from the mean, as shown in
Figure 9.
Our semi-synthetic coarse imagery, NEON 15 m/29 m, had far lower errors than AVIRIS Ortho/Unortho data, and unexpectedly, AVIRIS Ortho had lower errors than AVIRIS Unortho. LS unmixing produced far higher errors than NNLS and FCLS unmixing. PSF aggregated AMRD yielded slightly lower errors than the rectangular case. Finally, we found that the error of MAE was lower than MA-MAE, and that MA-MAE was lower than both CIA-MAE lower and upper levels. Given the inaccuracy of LS unmixing, we recomputed image and reference type error metrics, while excluding LS unmixing, resulting in
Table 5.
Table 5 confirmed most of the findings from
Table 4, including that the error in NEON 15 m/29 m < AVIRIS Ortho/Unortho, PSF < Rect, MAE < MA-MAE, and MA-MAE <
. However, with LS unmixing results removed, the errors in AVIRIS Ortho and Unortho were approximately the same. Also, the differences between the error in unmixing results from NEON 15 m/29 m and AVIRIS Ortho/Unortho were not as large. Large errors in unconstrained LS unmixing disproportionately affected the AVIRIS cases, especially AVIRIS Unortho. Given that the discrepancies between NEON and AVIRIS coarse imagery were also significant, we also recomputed unmixing and reference type error metrics, while including LS unmixing and excluding AVIRIS imagery, resulting in
Table 6.
Table 6 confirmed the findings from
Table 4 and
Table 5, as well as showing that the errors from LS unmixing were lower when AVIRIS data was excluded from the analysis. While FCLS < NNLS < LS still held true, the LS results in this synthetic imagery case were closer to those from FCLS/NNLS.
Thus far, we have used MAE analysis to explore general trends when using various versions of coarse imagery, unmixing algorithms, and reference data aggregations. We noted the following trends in unmixing errors associated with the various data and methods from this analysis:
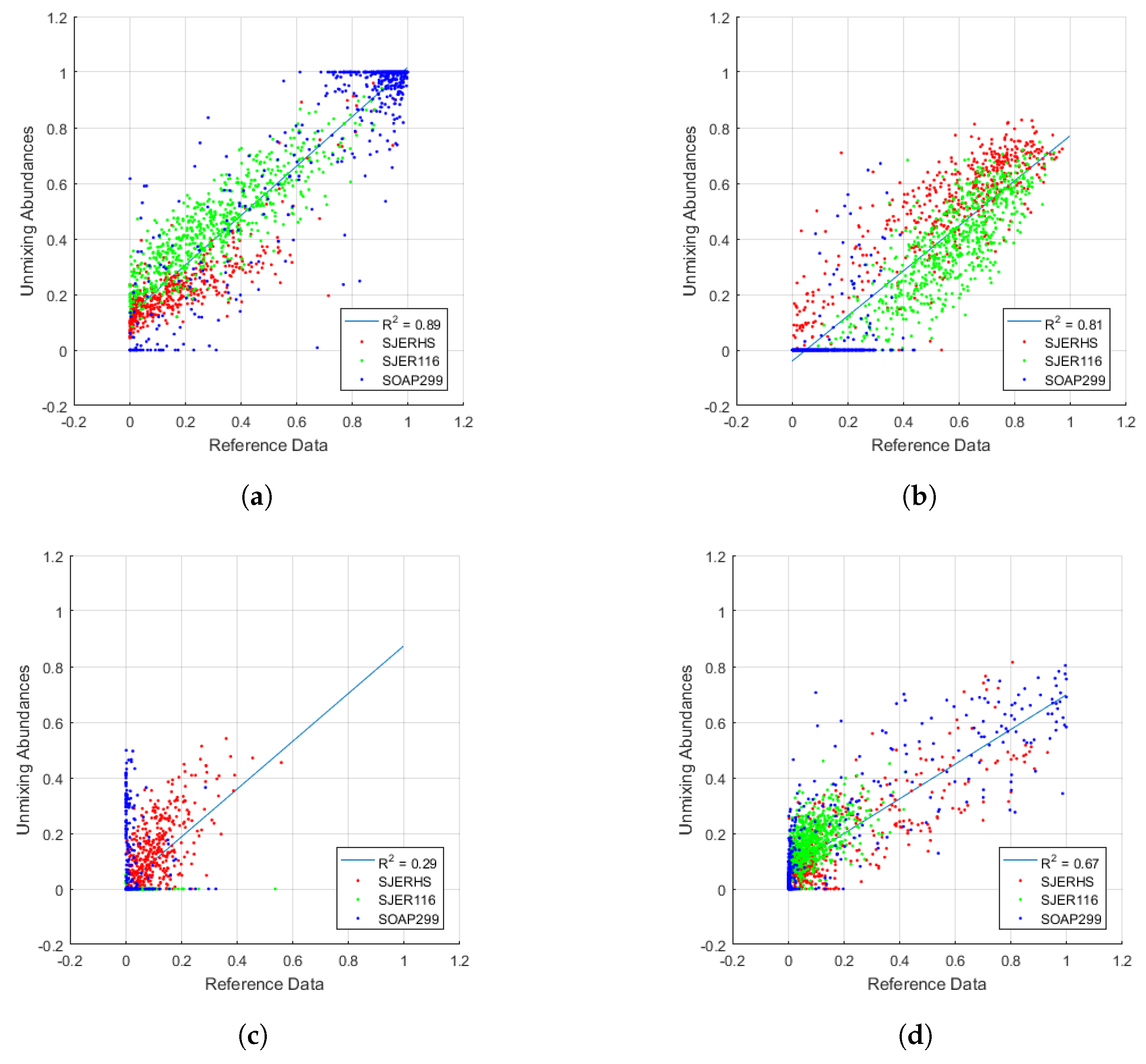
Table 7 presents specific error results for AVIRIS Unortho coarse imagery, FCLS unmixing, and rectangular aggregation of AMRD. These results are presented as an example of analysis that can be performed on unmixing abundances using AMRD. The table indicates that there was wide variation in the accuracy of different ground cover classes, including much higher error in NPV than BS. Similar tables could be produced for every combination of coarse imagery, unmixing type, and reference data type.
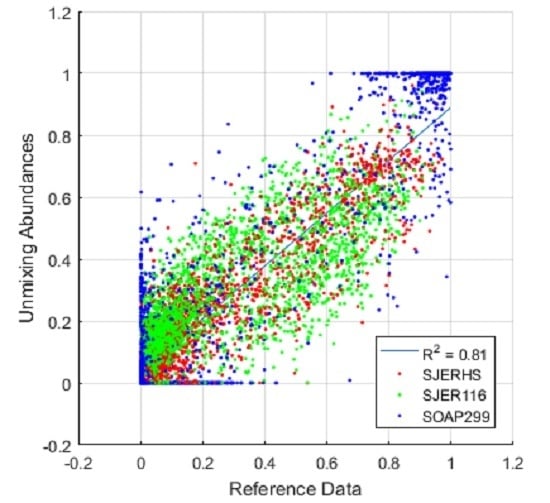
3.3. Assessing the Performance of Unmixing Using Regression
Linear regression between unmixing abundances and AMRD provided another method for analyzing the performance of unmixing algorithms.
Figure 9 shows the result of scatter plots of unmixing abundances versus AMRD for the same data analyzed in
Table 7. We combined results from all three scenes into single plots and
values in order to present more data in a limited space, and to follow the same convention we’ve used throughout our research, where results from all three scenes have been considered together. We have, however, provided color coded data per scene so that the reader can compare influences from individual scenes into the final results. Regression lines and
values are included on the graphs, while slope and intercept values are provided in
Table 8. Regression analysis added to the understanding provided by MAE, and clarified certain findings. For example, contrary to MAE findings, regression indicated that BS may have been the least accurate class, with low MAE simply due to lower abundance in general for BS. The combined use of MAE and regression analysis improved our understanding of unmixing results.
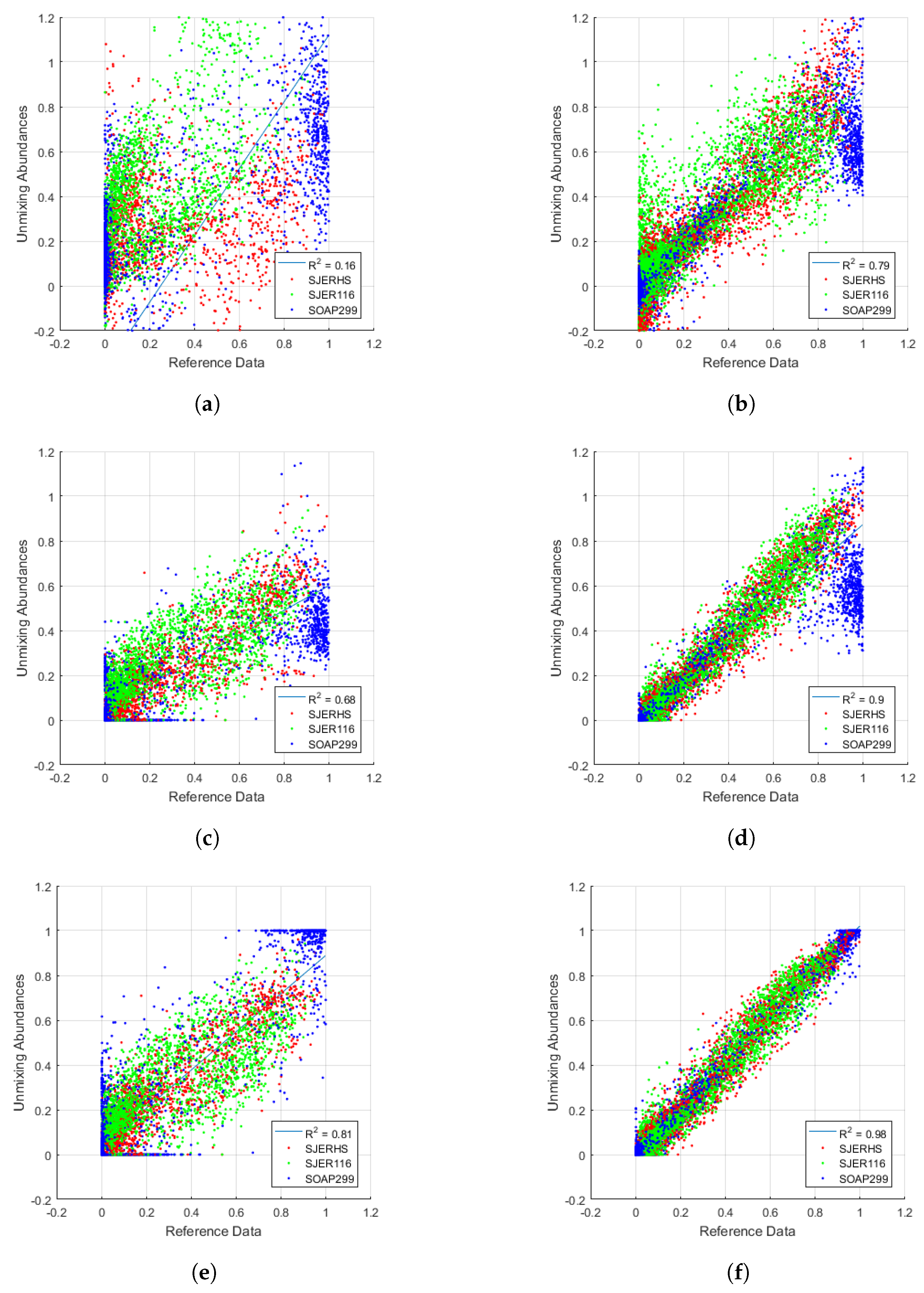
Figure 10 is similar to
Figure 9, except that data from all four classes were combined into single plots, and the regression was computed for all classes combined. The left side of
Figure 10 contains plots from LS, NNLS, and FCLS unmixing of AVIRIS Unortho data and rectangular AMRD, while the right side contains plots from LS, NNLS, and FCLS unmixing of NEON 15 m data and rectangular AMRD. This figure confirmed findings from MAE analysis, which suggested that differences between unmixing abundances and AMRD were smaller in the semi-synthetic NEON 15 m data, compared to fully independent AVIRIS Unortho data. Constraining unmixing continued to result in improved accuracy, with NNLS outperforming LS, and FCLS outperforming NNLS.
Table 8 lists the slope, intercept, and
values for the data displayed in
Figure 10, along with providing this same information for individual ground cover classes. Slope, intercept, and
values varied widely depending on the choice of coarse imagery and unmixing type, with
ranging from 0.16 to 0.98 in AVIRIS Unortho/LS and NEON 15 m/FCLS, respectively. Overall results improved predictably from the top to the bottom of the table, with AVIRIS Unortho/FCLS being roughly equivalent to NEON 15 m/LS.
4. Discussion
The alignment of our semi-synthetic downsampled NEON 15 m/29 m data to the original NEON IS imagery generated known test cases for comparison with AVIRIS alignment results. i.e., NEON 15 m/29 m imagery provided insight into what “perfect” alignment would look like, and provided a baseline against which to compare AVIRIS results. In this context, AVIRIS alignment results were far from the perfect test case, but ultimately resulted in well-defined troughs with the precision required to achieve single fine scale pixel accuracy per parameter. We interpreted these results as indicating successful spatial alignment between coarse and fine imagery. In making this interpretation, however, we acknowledge some level of misalignment, which lowers the accuracy of validated AMRD.
We used both orthorectified and unorthorectified versions of AVIRIS data in this study, due to high pixel replication rates from nearest-neighbor resampling during the orthorectification process. As such, we expected unorthorectified AVIRIS data to align more closely with NEON imagery, but our results indicated little difference between the two data sets, with orthorectified data slightly outperforming unorthorectified data in spatial alignment. Minimum mean values for AVIRIS Ortho ranged from 0.07–0.14 radians, while AVIRIS Unortho values ranged from 0.09–0.13 radians. The ideal coarse imagery for this study likely would have been orthorectified, but used interpolation, rather than nearest-neighbor resampling, during the orthorectification process.
We compared PSF and rectangular aggregation strategies for both spatial alignment and coarse imagery specific AMRD generation. As expected, PSF based spatial alignment returned lower minimum mean values than the rectangualar case, by a factor of approximately 10%. Similarly, unmixing assessments using PSF-aggregated AMRD resulted in slightly lower error than rectangular-aggregated AMRD, by a factor of approximately 5%. Nevertheless, we considered rectangular-aggregated AMRD to more accurately represent true ground cover per pixel. PSF aggregation more accurately represented sensor reaching radiance in our imagery, but our goal was to assess ground level abundances, which were better represented by rectangular aggregation. The difference between PSF and rectangular AMRD represents a persistent form of error in unmixing; i.e., even if we could perfectly unmix the signal measured by an imaging sensor, perfect unmixing of ground abundances would require undoing sensor PSF blurring. We recommend using PSF aggregation in spatial alignment and rectangular aggregation when generating imagery-specific AMRD.
Mean absolute error (MAE) and linear regression provided concise methods for evaluating unmixing performance. Furthermore, reference data mean adjusted MAE (MA-MAE) and confidence interval adjusted MAE (CIA-MAE) gave us the ability to factor in the known error of AMRD data itself. These metrics allowed us to bring the comparison back to MOA, which we determined to be the best available representation of true ground cover fractions. As such, we interpreted the MA-MAE metric as being the most likely error from true ground cover, with CIA-MAE providing bounds. Basic MAE turned out to have lower error for the cases in this study, but lower does not always mean better, as our goal was to assess the true error in unmixed abundances.
Based on MAE analysis alone, we might have concluded that BS was the overall most accurate class in our study. However, the regression results suggested that low MAE in BS may have been due to overall lower fractional abundances, rather than superior accuracy. While MAE answered the basic question of how far the average unmixed abundance was from its true abundance, regression scatter plots provided the ability to visualize and correctly interpret the differences. Scene-specific coloring in the regression figures allowed us to examine the influence of various ground cover classes from each scene. For example,
Figure 10a–d indicate that there were a large number of SOAP299 data (mountain forest) that fell near 1 in AMRD, but significantly lower than 1 in unmixing abundances. Further exploration of this phenomenon revealed that these data were primarily from the PV class. It appears that our selection of endmember spectra for PV in the SOAP299 scene emphasized the brightest areas of the image, and as such, the less bright PV areas were underestimated in LS and NNLS unmixing. FCLS unmixing compensated for some of this error. These findings emphasized the importance of endmember estimation and the strong effect of intra-class variability in the unmixing process. Combined use of MAE and regression analysis thus enhanced our understanding of unmixing accuracy.
5. Conclusions
The purpose of this paper was to apply our previously validated abundance map reference data (AMRD) to specific examples of coarse scale imagery. This application of AMRD involved three main parts: (1) spatial alignment of coarse and fine scale imagery; (2) aggregation of fine scale abundances to produce coarse imagery specific AMRD; and (3) demonstration of comparisons between coarse unmixing abundances and AMRD. To accomplish this, we produced AMRD for three study scenes, four versions of coarse scale imagery, two aggregation methods, and three unmixing algorithms, as specified below.
Scenes: SJERHS (suburban dry grassland), SJER116 (dry grassland), SOAP299 (mountain forest)
Imagery: AVIRIS Ortho, AVIRIS Unortho, NEON 15 m, NEON 29 m
Aggregation: PSF, Rectangular
Unmixing: LS, NNLS, FCLS
Spatial alignment between coarse and fine imagery was perhaps the most challenging aspect of applying validated AMRD to specific coarse scale imagery. After unsuccessfully attempting spatial alignment using standard remote sensing tools, we opted to implement our own spatial alignment algorithm, namely, scene-wide spectral comparison (SWSC), which was designed to use all of the spatial and spectral information from both scenes simultaneously to accomplish spatial alignment. We determined that this spatial alignment approach yielded accuracy approaching that of a single fine scale pixel.
We generated semi-synthetic downsampled coarse scale imagery, NEON 15 m and NEON 29 m, for use in our study. We included NEON 15 m data as a near perfect test case for comparison against AVIRIS data, and NEON 29 m data as a surrogate for satellite-based coarse scale imagery. Semi-synthetic data yielded closer spatial alignment and far superior unmixing performance than AVIRIS data, including an error of 5.35% for NEON 15 m, versus an error of 11.49% for AVIRIS Ortho, even once lower accuracy unconstrained LS unmixing results were removed from the analysis. NEON 29 m results were similar to those of NEON 15 m, indicating that larger GSD coarse imagery could be used with our methodologies, provided that the spatial and spectral attributes of such data allow for accurate spatial alignment. The significant differences in the error between NEON 15 m/29 m and AVIRIS Ortho/Unortho were a reminder that synthetic imagery can be highly useful in research studies, but that we should not underestimate the differences between synthetic and real imagery.
We compared unmixing results to AMRD using mean absolute error (MAE) and linear regression. Reference data mean adjusted MAE (MA-MAE) and confidence interval adjusted MAE (CIA-MAE) provided the ability to account for known error in the reference data itself. MA-MAE analysis indicated that fully constrained linear unmixing of AVIRIS imagery across all three scenes returned an error of 10.83% per class and pixel, with regression analysis yielding a slope = 0.85, intercept = 0.04, and = 0.81.
Our reference data research has demonstrated a viable methodology to efficiently generate, validate, and apply AMRD to specific examples of airborne remote sensing imagery, thereby enabling direct quantitative assessment of spectral unmixing performance. We encourage the remote sensing community to adopt a similarly robust treatment of reference data in future research efforts.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}