A Probabilistic Weighted Archetypal Analysis Method with Earth Mover’s Distance for Endmember Extraction from Hyperspectral Imagery



Abstract
:1. Introduction
- (1)
- The PWAA-MED incorporates the dissimilarity information among pairwise pixels with the EMD metric to promote the behaviors of AA in selecting different endmembers. The EMD measure considers the manifold structure of the HSI data and it could fully describe spectral variations of all the pixels determined by low-dimensional manifolds of the hyperspectral data.
- (2)
- The PWAA-EMD adopts the Bayesian framework and formulates the endmember extraction of AA into a probabilistic inference problem. The Bayesian framework could represent spectral variability and accordingly the PWAA-EMD is more suitable for spectral unmixing in the realistic HSI data.
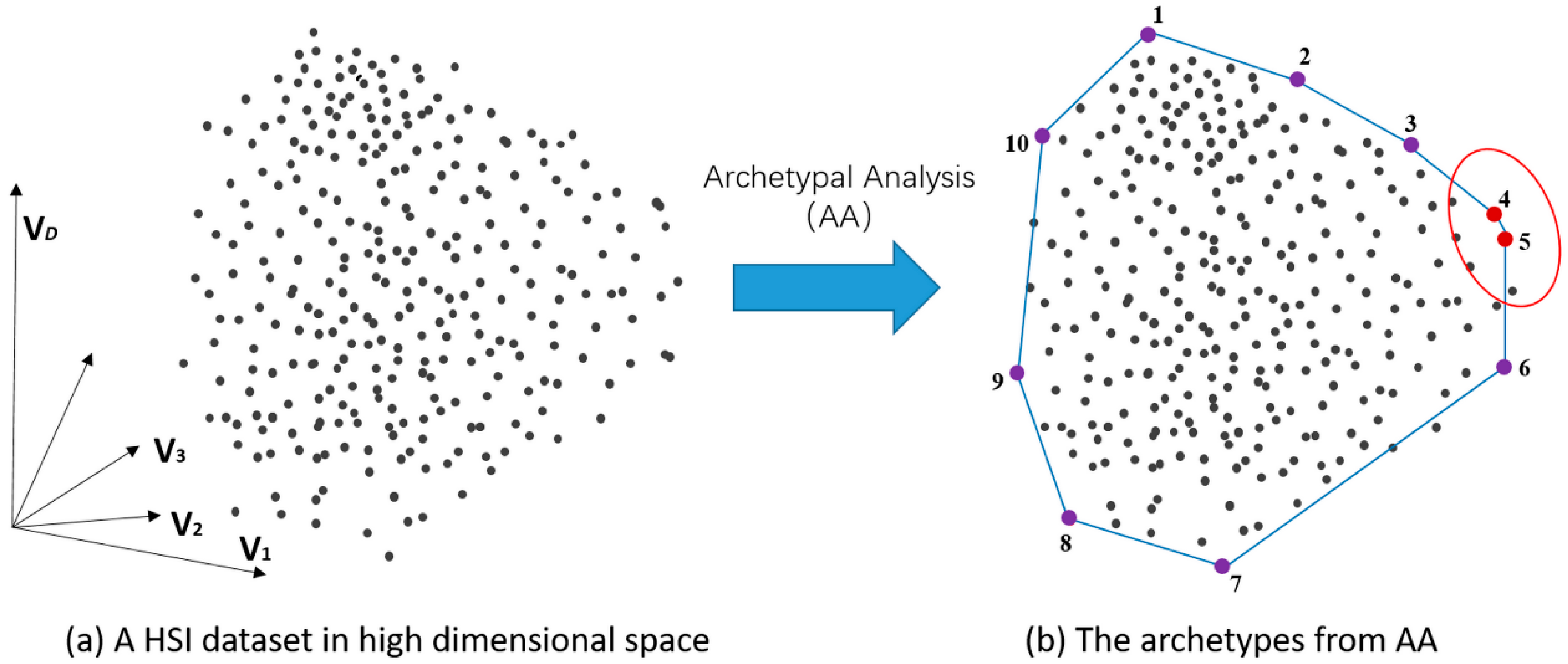
2. Brief Review of Archetypal Analysis
3. The PWAA-EMD Model for Endmember Extraction
3.1. The Formulation of PWAA-EMD Model
3.2. The Solution of PWAA-EMD Model
- (1)
- The stochastic stage: the algorithm computes the that consists the top r right singular vectors of , and selects random columns of . The columns are carefully chosen according to the nonuniform probability distribution that depends on the information in the top-r right singular subspace of .
- (2)
- The deterministic stage: the algorithm applies a deterministic column-selection procedure [49] to select exactly r columns from the set of columns of selected from the first stage. The algorithm finally outputs exactly r columns of the HSI data and we set it to be the initial endmembers .
3.3. The Summary of PWAA-EMD Model for Endmember Extraction
- (1)
- Hyperspectral images are transformed from a data cube into a matrix , where D is the number of bands and N is the number of pixels, respectively.
- (2)
- The dissimilarity information among all pixels are computed with the EMD measure in (3) and the dissimilarity information matrix are obtained.
- (3)
- The coefficient matrix is weighted by the EMD dissimilarity matrix and the Bayesian framework is then utilized to formulate the model of PWAA-EMD in (5).
- (4)
- The solution of PWAA-EMD is transformed into an optimization problem of a joint posterior density via the maximum a posterior estimator in (8). The Poisson distribution is utilized to quantify the prior knowledge of the HSI data from the consideration of quantum nature in hyperspectral imaging.
- (5)
- The two-stage algorithm is adopted to initialize the two coefficient matrices and the iterative multiplicative update rules in (9) and (10) are implemented to optimize the problem.
- (6)
- The coefficient matrix at the stopping iteration is set as the final coefficient matrix and the proper endmembers are finally estimated from .
4. Experimental Results
4.1. The Experiments on the Synthetic Data
4.1.1. The Experiment on the Synthetic Data without Gaussian Noise
4.1.2. The Experiment on the Synthetic Data with Gaussian Noise
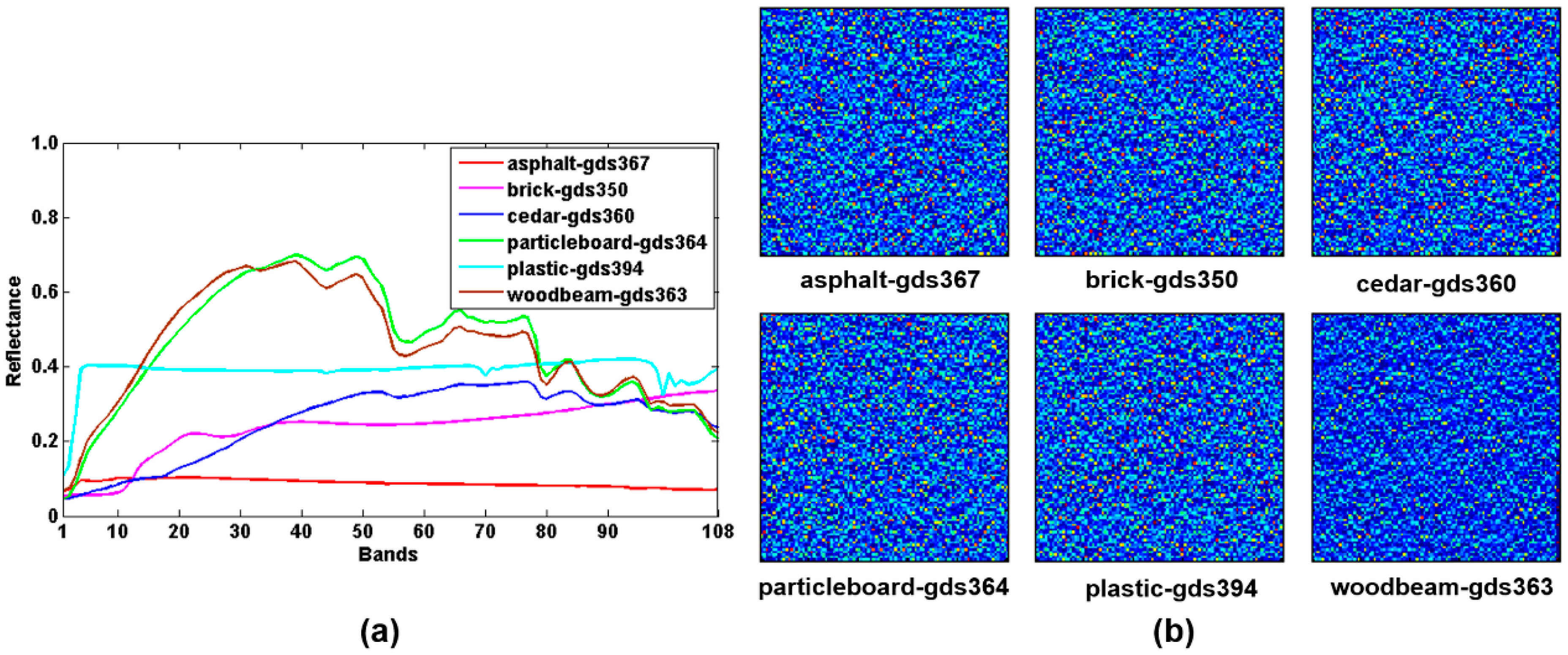
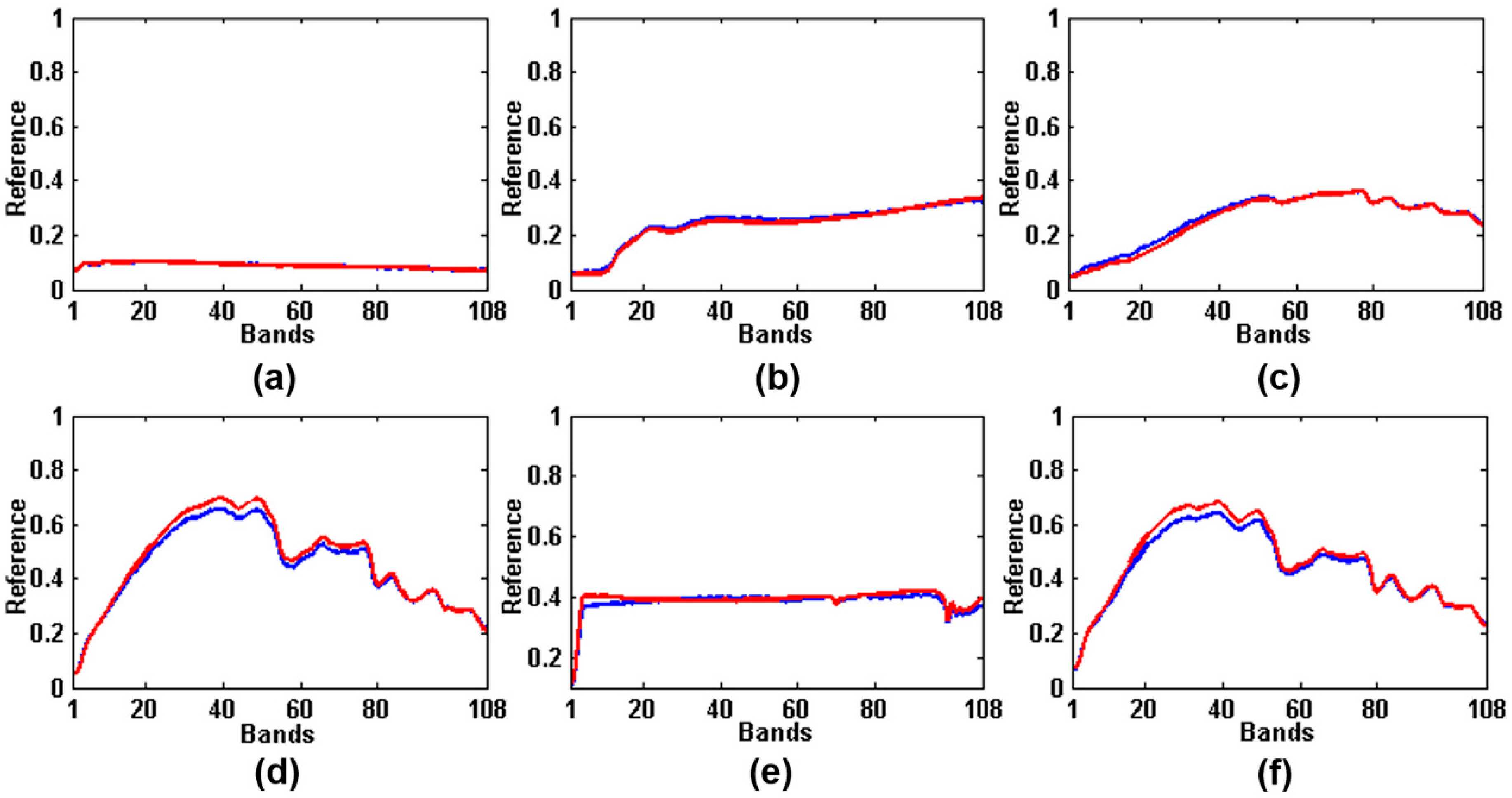
4.2. The Experiments on the Cuprite Data
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Chen, C.; Li, W.; Su, H.; Liu, K. Spectral-spatial classification of hyperspectral image based on kernel extreme learning machine. Remote Sens. 2014, 6, 5795–5814. [Google Scholar] [CrossRef]
- Ma, W.-K.; Bioucas-Dias, J.M.; Chan, T.-H.; Gillis, N.; Gader, P.; Plaza, A.J.; Ambikapathi, A.; Chi, C.-Y. A signal processing perspective on hyperspectral unmixing: Insights from remote sensing. IEEE Signal Process. Mag. 2014, 31, 67–81. [Google Scholar] [CrossRef]
- Li, C.; Ma, Y.; Mei, X.; Liu, C.; Ma, J. Hyperspectral unmixing with robust collaborative sparse regression. Remote Sens. 2016, 8, 588. [Google Scholar] [CrossRef]
- Priem, F.; Canters, F. Synergistic use of lidar and apex hyperspectral data for high-resolution urban land cover mapping. Remote Sens. 2016, 8, 787. [Google Scholar] [CrossRef]
- Makki, I.; Younes, R.; Francis, C.; Bianchi, T.; Zucchetti, M. A survey of landmine detection using hyperspectral imaging. ISPRS J. Photogramm. Remote Sens. 2017, 124, 40–53. [Google Scholar] [CrossRef]
- Zarco-Tejada, P.; González-Dugo, M.; Fereres, E. Seasonal stability of chlorophyll fluorescence quantified from airborne hyperspectral imagery as an indicator of net photosynthesis in the context of precision agriculture. Remote Sens. Environ. 2016, 179, 89–103. [Google Scholar] [CrossRef]
- Simon, A.; Shanmugam, P. Estimation of the spectral diffuse attenuation coefficient of downwelling irradiance in inland and coastal waters from hyperspectral remote sensing data: Validation with experimental data. Int. J. Appl. Earth Obs. Geoinf. 2016, 49, 117–125. [Google Scholar] [CrossRef]
- Cerra, D.; Bieniarz, J.; Müller, R.; Storch, T.; Reinartz, P. Restoration of simulated enmap data through sparse spectral unmixing. Remote Sens. 2015, 7, 13190–13207. [Google Scholar] [CrossRef] [Green Version]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef]
- Liu, R.; Du, B.; Zhang, L. Hyperspectral unmixing via double abundance characteristics constraints based nmf. Remote Sens. 2016, 8, 464. [Google Scholar] [CrossRef]
- Du, B.; Wang, S.; Wang, N.; Zhang, L.; Tao, D.; Zhang, L. Hyperspectral signal unmixing based on constrained non-negative matrix factorization approach. Neurocomputing 2016, 204, 153–161. [Google Scholar] [CrossRef]
- Xu, M.; Zhang, L.; Du, B.; Zhang, L.; Fan, Y.; Song, D. A mutation operator accelerated quantum-behaved particle swarm optimization algorithm for hyperspectral endmember extraction. Remote Sens. 2017, 9, 197. [Google Scholar] [CrossRef]
- Liu, R.; Zhang, L.; Du, B. A novel endmember extraction method for hyperspectral imagery based on quantum-behaved particle swarm optimization. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 99, 1–22. [Google Scholar] [CrossRef]
- Stagakis, S.; Vanikiotis, T.; Sykioti, O. Estimating forest species abundance through linear unmixing of chris/proba imagery. ISPRS J. Photogramm. Remote Sens. 2016, 119, 79–89. [Google Scholar] [CrossRef]
- Sun, W.; Ma, J.; Yang, G.; Du, B.; Zhang, L. A poisson nonnegative matrix factorization method with parameter subspace clustering constraint for endmember extraction in hyperspectral imagery. ISPRS J. Photogramm. Remote Sens. 2017, 128, 27–39. [Google Scholar] [CrossRef]
- Sun, W.; Liu, C.; Sun, Y.; Li, W.; Li, J. Extracting pure endmembers using symmetric sparse representation for hyperspectral imagery. J. Appl. Remote Sens. 2016, 10, 045023. [Google Scholar] [CrossRef]
- Fu, X.; Ma, W.-K.; Chan, T.-H.; Bioucas-Dias, J.M. Self-dictionary sparse regression for hyperspectral unmixing: Greedy pursuit and pure pixel search are related. IEEE J. Sel. Top. Signal Process. 2015, 9, 1128–1141. [Google Scholar] [CrossRef]
- Chang, C.-I.; Plaza, A. A fast iterative algorithm for implementation of pixel purity index. IEEE Geosci. Remote Sens. Lett. 2006, 3, 63–67. [Google Scholar] [CrossRef]
- Winter, M.E. N-findr: An algorithm for fast autonomous spectral end-member determination in hyperspectral data. In Proceedings of the 1999 SPIE’s International Symposium on Optical Science, Engineering, and Instrumentation, International Society for Optics and Photonics, Denver, CO, USA, 18–23 July 1999; pp. 266–275. [Google Scholar]
- Chan, T.-H.; Ambikapathi, A.; Ma, W.-K.; Chi, C.-Y. Robust affine set fitting and fast simplex volume max-min for hyperspectral endmember extraction. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3982–3997. [Google Scholar] [CrossRef]
- Nascimento, J.M.; Dias, J.M. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef]
- Gillis, N.; Kuang, D.; Park, H. Hierarchical clustering of hyperspectral images using rank-two nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2066–2078. [Google Scholar] [CrossRef]
- Gillis, N.; Vavasis, S.A. Fast and robust recursive algorithmsfor separable nonnegative matrix factorization. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 698–714. [Google Scholar] [CrossRef] [PubMed]
- Qu, Q.; Nasrabadi, N.M.; Tran, T.D. Subspace vertex pursuit: A fast and robust near-separable nonnegative matrix factorization method for hyperspectral unmixing. IEEE J. Sel. Top. Signal Process. 2015, 9, 1142–1155. [Google Scholar] [CrossRef]
- Chan, T.-H.; Chi, C.-Y.; Huang, Y.-M.; Ma, W.-K. A convex analysis-based minimum-volume enclosing simplex algorithm for hyperspectral unmixing. IEEE Trans. Signal Process. 2009, 57, 4418–4432. [Google Scholar] [CrossRef]
- Li, J.; Agathos, A.; Zaharie, D.; Bioucas-Dias, J.M.; Plaza, A.; Li, X. Minimum volume simplex analysis: A fast algorithm for linear hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5067–5082. [Google Scholar]
- Gillis, N.; Plemmons, R.J. Sparse nonnegative matrix underapproximation and its application to hyperspectral image analysis. Linear Algebra Appl. 2013, 438, 3991–4007. [Google Scholar] [CrossRef]
- Rajabi, R.; Ghassemian, H. Spectral unmixing of hyperspectral imagery using multilayer nmf. IEEE Geosci. Remote Sens. Lett. 2015, 12, 38–42. [Google Scholar] [CrossRef]
- Févotte, C.; Dobigeon, N. Nonlinear hyperspectral unmixing with robust nonnegative matrix factorization. IEEE Trans. Image Process. 2015, 24, 4810–4819. [Google Scholar] [CrossRef] [PubMed]
- Wang, N.; Du, B.; Zhang, L.; Zhang, L. An abundance characteristic-based independent component analysis for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2015, 53, 416–428. [Google Scholar] [CrossRef]
- Zhuang, L.; Zhang, B.; Gao, L.; Li, J.; Plaza, A. Normal endmember spectral unmixing method for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2598–2606. [Google Scholar] [CrossRef]
- Altmann, Y.; Pereyra, M.; McLaughlin, S. Bayesian nonlinear hyperspectral unmixing with spatial residual component analysis. IEEE Trans. Comput. Imaging 2015, 1, 174–185. [Google Scholar] [CrossRef]
- Lin, C.-H.; Chi, C.-Y.; Wang, Y.-H.; Chan, T.-H. A fast hyperplane-based mves algorithm for hyperspectral unmixing. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 1384–1388. [Google Scholar]
- Sun, L.; Zhao, G.; Du, X. Cur based initialization strategy for non-negative matrix factorization in application to hyperspectral unmixing. J. Appl. Math. Phys. 2016, 4, 614–617. [Google Scholar] [CrossRef]
- Mørup, M.; Hansen, L.K. Archetypal analysis for machine learning and data mining. Neurocomputing 2012, 80, 54–63. [Google Scholar] [CrossRef]
- Zhao, C.; Zhao, G.; Jia, X. Hyperspectral image unmixing based on fast kernel archetypal analysis. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 331–346. [Google Scholar] [CrossRef]
- Cutler, A.; Breiman, L. Archetypal analysis. Technometrics 1994, 36, 338–347. [Google Scholar] [CrossRef]
- Wang, N.; Du, B.; Zhang, L. An endmember dissimilarity constrained non-negative matrix factorization method for hyperspectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 554–569. [Google Scholar] [CrossRef]
- Nakhostin, S.; Courty, N.; Flamary, R.; Corpetti, T. Supervised planetary unmixing with optimal transport. In Proceedings of the WHISPERS 8th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Los Angeles, CA, USA, 21–24 August 2016; pp. 1–6. [Google Scholar]
- Hegde, C.; Sankaranarayanan, A.C.; Baraniuk, R.G. Learning manifolds in the wild. J. Mach. Learn. Res. 2012, 1, 4. [Google Scholar]
- Venkatasubramanian, S. Moving heaven and earth: Distances between distributions. ACM SIGACT News 2013, 44, 56–68. [Google Scholar] [CrossRef]
- Monge, G. M’emoire sur la theorie des deblais et des remblais. In Histoire de L’academie Royale des Sciences de Paris, avec les Memoire de Mathematique et de Physique Pour la Meme Annee; De l’Imprimerie Royale: Paris, France, 1781; pp. 666–704. [Google Scholar]
- Pele, O.; Werman, M. Fast and robust earth mover’s distances. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 460–467. [Google Scholar]
- Bernardo, J.M.; Smith, A.F. Bayesian Theory; IOP Publishing: Bristol, UK, 2001. [Google Scholar]
- Ma, L.; Moisan, L.; Yu, J.; Zeng, T. A dictionary learning approach for poisson image deblurring. IEEE Trans. Med. Imaging 2013, 32, 1277–1289. [Google Scholar] [PubMed]
- Seth, S.; Eugster, M.J. Probabilistic archetypal analysis. Mach. Learn. 2016, 102, 85–113. [Google Scholar] [CrossRef]
- Boutsidis, C.; Mahoney, M.W.; Drineas, P. An improved approximation algorithm for the column subset selection problem. In Proceedings of the Twentieth Annual ACM-SIAM Symposium on Discrete Algorithms, New York, NY, USA, 4–6 January 2009; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2009; pp. 968–977. [Google Scholar]
- Pan, C.-T. On the existence and computation of rank-revealing Lu factorizations. Linear Algebra Appl. 2000, 316, 199–222. [Google Scholar] [CrossRef]
- Wang, J.; Chang, C.-I. Independent component analysis-based dimensionality reduction with applications in hyperspectral image analysis. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1586–1600. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Collaborative nonnegative matrix factorization for remotely sensed hyperspectral unmixing. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Munich, Germany, 22–27 July 2012; pp. 3078–3081. [Google Scholar]
- Clark, R.N.; Swayze, G.A.; Wise, R.; Livo, K.E.; Hoefen, T.; Kokaly, R.F.; Sutley, S.J. USGS Digital Spectral Library splib06a; US Geological Survey: Denver, CO, USA, 2007; p. 231. [Google Scholar]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A.; Liu, L. Robust collaborative nonnegative matrix factorization for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6076–6090. [Google Scholar] [CrossRef]
- Heylen, R.; Parente, M.; Scheunders, P. Estimation of the number of endmembers in a hyperspectral image via the hubness phenomenon. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2191–2200. [Google Scholar] [CrossRef]
- Jutten, C. Estimating the number of endmembers to use in spectral unmixing of hyperspectral data with collaborative sparsity. In Proceedings of the 13th International Conference Latent Variable Analysis and Signal Separation (LVA/ICA 2017), Grenoble, France, 21–23 February 2017; Springer: Berlin, Germany; pp. 1–10. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Endmember Extraction Methods | |||||
|---|---|---|---|---|---|---|
| ICA | MLNMF | CONMF | RNMF | AA | PWAA-EMD | |
| SAD | 0.1275 | 0.0374 | 0.0074 | 0.2629 | 0.0349 | 0.0188 |
| RMSE | 0.1042 | 0.0404 | 0.0063 | 0.1016 | 0.0410 | 0.0137 |
| Endmembers | SAD | |||||
|---|---|---|---|---|---|---|
| ICA | MLNMF | CONMF | RNMF | AA | PWAA-EMD | |
| asphalt-gds367 | 0.1822 | 0.0694 | 0.1770 | 0.1481 | 0.0340 | 0.0174 |
| brick-gds350 | 0.2584 | 0.0391 | 0.1921 | 0.1717 | 0.0423 | 0.0257 |
| cedar-gds360 | 0.3074 | 0.0200 | 0.1245 | 0.1773 | 0.0412 | 0.0367 |
| particleboard-gds364 | 0.0895 | 0.0129 | 0.0355 | 0.0938 | 0.0479 | 0.0310 |
| plastic-gds394 | 0.2043 | 0.0092 | 0.3111 | 0.2545 | 0.0436 | 0.0287 |
| woodbeam-gds363 | 0.0979 | 0.0547 | 0.6074 | 0.1206 | 0.0376 | 0.0356 |
| Average | 0.1899 | 0.0342 | 0.2413 | 0.1610 | 0.0411 | 0.0292 |
| Endmembers | RMSE | |||||
|---|---|---|---|---|---|---|
| ICA | MLNMF | CONMF | RNMF | AA | PWAA-EMD | |
| asphalt-gds367 | 0.1786 | 0.0500 | 0.1695 | 0.0502 | 0.0187 | 0.0098 |
| brick-gds350 | 0.1100 | 0.0481 | 0.0741 | 0.0666 | 0.0404 | 0.0207 |
| cedar-gds360 | 0.1207 | 0.0342 | 0.0626 | 0.0680 | 0.0421 | 0.0313 |
| particleboard-gds364 | 0.0919 | 0.0319 | 0.0704 | 0.0666 | 0.0596 | 0.0346 |
| plastic-gds394 | 0.0898 | 0.0304 | 0.1282 | 0.0988 | 0.0445 | 0.0370 |
| woodbeam-gds363 | 0.0988 | 0.0627 | 0.2066 | 0.1142 | 0.0544 | 0.0335 |
| Average | 0.1150 | 0.0487 | 0.1186 | 0.0774 | 0.0433 | 0.0278 |
| Endmembers | Endmember Extraction Methods | |||||
|---|---|---|---|---|---|---|
| ICA | MLNMF | CONMF | RNMF | AA | PWAA-EMD | |
| Alunite1 | 0.2530 | 0.1112 | 0.1370 | 0.2548 | 0.1119 | 0.0651 |
| Alunite2 | 0.2357 | 0.1894 | 0.1338 | 0.2994 | 0.1904 | 0.1724 |
| Pyrophyllite | 0.0922 | 0.1007 | 0.1325 | 0.1976 | 0.0802 | 0.0776 |
| Buddingtonite | 0.1411 | 0.0845 | 0.1377 | 0.2257 | 0.1112 | 0.1037 |
| Chaledony | 0.1415 | 0.0820 | 0.1401 | 0.2600 | 0.1186 | 0.0937 |
| Jarosite | 0.2249 | 0.1846 | 0.2681 | 0.2596 | 0.2242 | 0.2081 |
| Kaolinite1 | 0.1858 | 0.1673 | 0.2386 | 0.2912 | 0.2122 | 0.1373 |
| Kaolinite2 | 0.2397 | 0.2432 | 0.3855 | 0.3286 | 0.2678 | 0.2105 |
| Montmorillonite | 0.2180 | 0.2846 | 0.4359 | 0.3411 | 0.2497 | 0.1706 |
| Muscovite1 | 0.0630 | 0.1150 | 0.2923 | 0.2448 | 0.0952 | 0.1231 |
| Muscovite2 | 0.1359 | 0.1893 | 0.4252 | 0.3846 | 0.1668 | 0.1276 |
| Nontronite | 0.1122 | 0.2826 | 0.6233 | 0.3851 | 0.1691 | 0.1024 |
| Average | 0.1702 | 0.1695 | 0.2792 | 0.2894 | 0.1665 | 0.1327 |
| Endmembers | Endmember Extraction Methods | |||||
|---|---|---|---|---|---|---|
| ICA | MLNMF | CONMF | RNMF | AA | PWAA-EMD | |
| Alunite1 | 0.1584 | 0.1282 | 0.1608 | 0.1710 | 0.1383 | 0.0741 |
| Alunite2 | 0.1655 | 0.1711 | 0.2657 | 0.1687 | 0.1056 | 0.1021 |
| Pyrophyllite | 0.1056 | 0.0791 | 0.1016 | 0.1255 | 0.0746 | 0.0778 |
| Buddingtonite | 0.0697 | 0.0911 | 0.1393 | 0.1551 | 0.0686 | 0.0647 |
| Chaledony | 0.1326 | 0.0776 | 0.1343 | 0.1296 | 0.1282 | 0.0854 |
| Jarosite | 0.1290 | 0.1481 | 0.1311 | 0.1439 | 0.1336 | 0.1346 |
| Kaolinite1 | 0.1939 | 0.1600 | 0.2320 | 0.1864 | 0.1435 | 0.0946 |
| Kaolinite2 | 0.1118 | 0.1553 | 0.1540 | 0.1379 | 0.1151 | 0.1031 |
| Montmorillonite | 0.1545 | 0.1386 | 0.1798 | 0.1677 | 0.1671 | 0.1057 |
| Muscovite1 | 0.0896 | 0.0723 | 0.1427 | 0.1223 | 0.1420 | 0.0874 |
| Muscovite2 | 0.0949 | 0.1257 | 0.0933 | 0.1009 | 0.1330 | 0.0876 |
| Nontronite | 0.0731 | 0.0895 | 0.1222 | 0.1031 | 0.0726 | 0.0673 |
| Average | 0.1232 | 0.1197 | 0.1547 | 0.1427 | 0.1185 | 0.0904 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, W.; Zhang, D.; Xu, Y.; Tian, L.; Yang, G.; Li, W. A Probabilistic Weighted Archetypal Analysis Method with Earth Mover’s Distance for Endmember Extraction from Hyperspectral Imagery. Remote Sens. 2017, 9, 841. https://doi.org/10.3390/rs9080841
Sun W, Zhang D, Xu Y, Tian L, Yang G, Li W. A Probabilistic Weighted Archetypal Analysis Method with Earth Mover’s Distance for Endmember Extraction from Hyperspectral Imagery. Remote Sensing. 2017; 9(8):841. https://doi.org/10.3390/rs9080841
Chicago/Turabian StyleSun, Weiwei, Dianfa Zhang, Yan Xu, Long Tian, Gang Yang, and Weiyue Li. 2017. "A Probabilistic Weighted Archetypal Analysis Method with Earth Mover’s Distance for Endmember Extraction from Hyperspectral Imagery" Remote Sensing 9, no. 8: 841. https://doi.org/10.3390/rs9080841
APA StyleSun, W., Zhang, D., Xu, Y., Tian, L., Yang, G., & Li, W. (2017). A Probabilistic Weighted Archetypal Analysis Method with Earth Mover’s Distance for Endmember Extraction from Hyperspectral Imagery. Remote Sensing, 9(8), 841. https://doi.org/10.3390/rs9080841