
Advancements in Microprocessor Architecture for Ubiquitous AI—An Overview on History, Evolution, and Upcoming Challenges in AI Implementation


Abstract
:1. Introduction
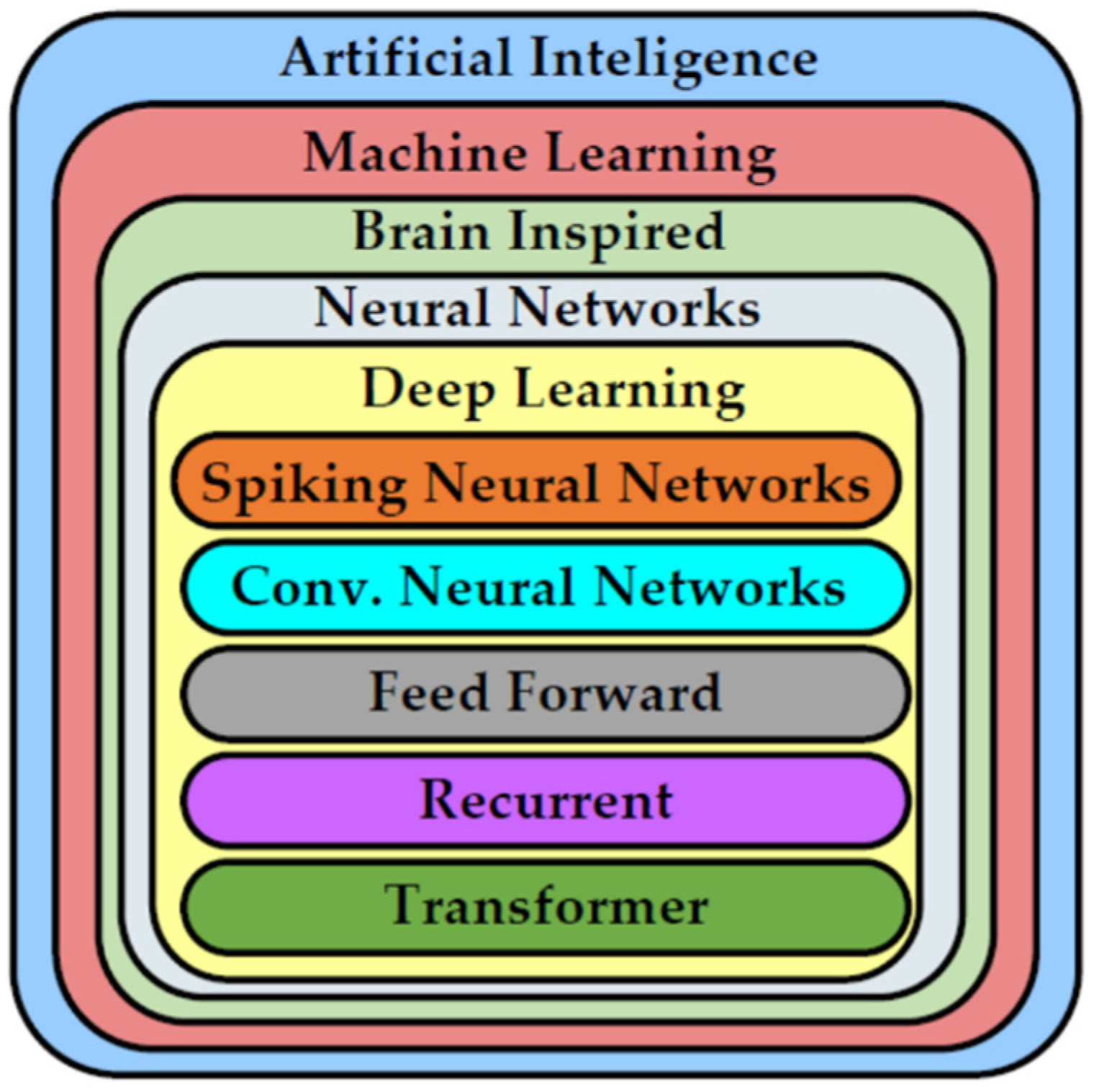
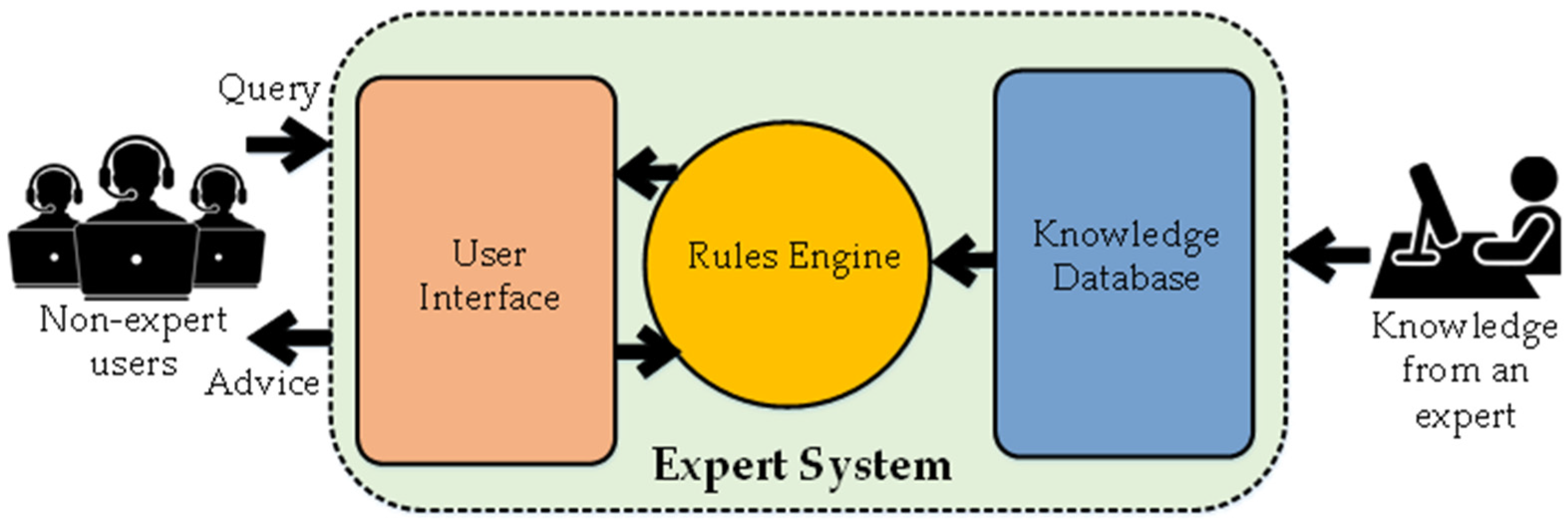
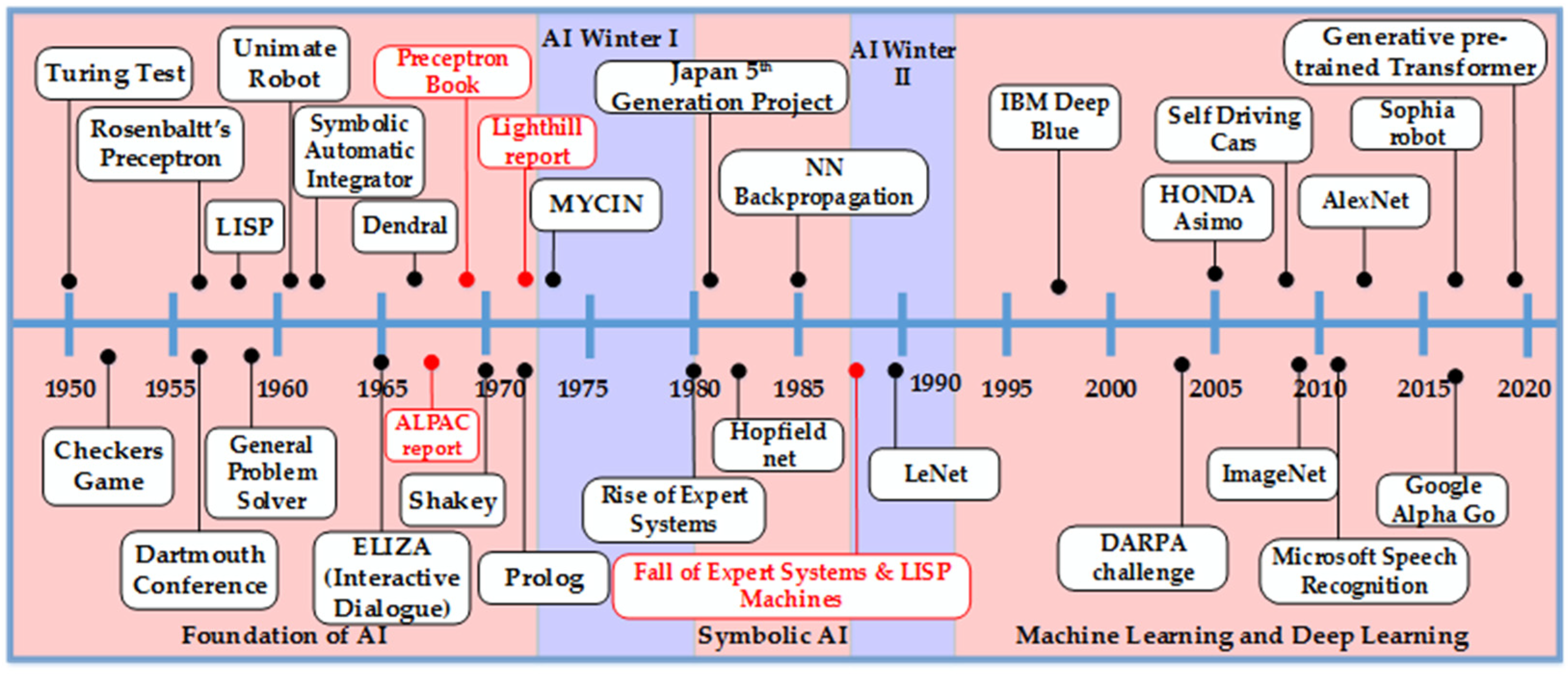
2. Origin and Evolution of AI
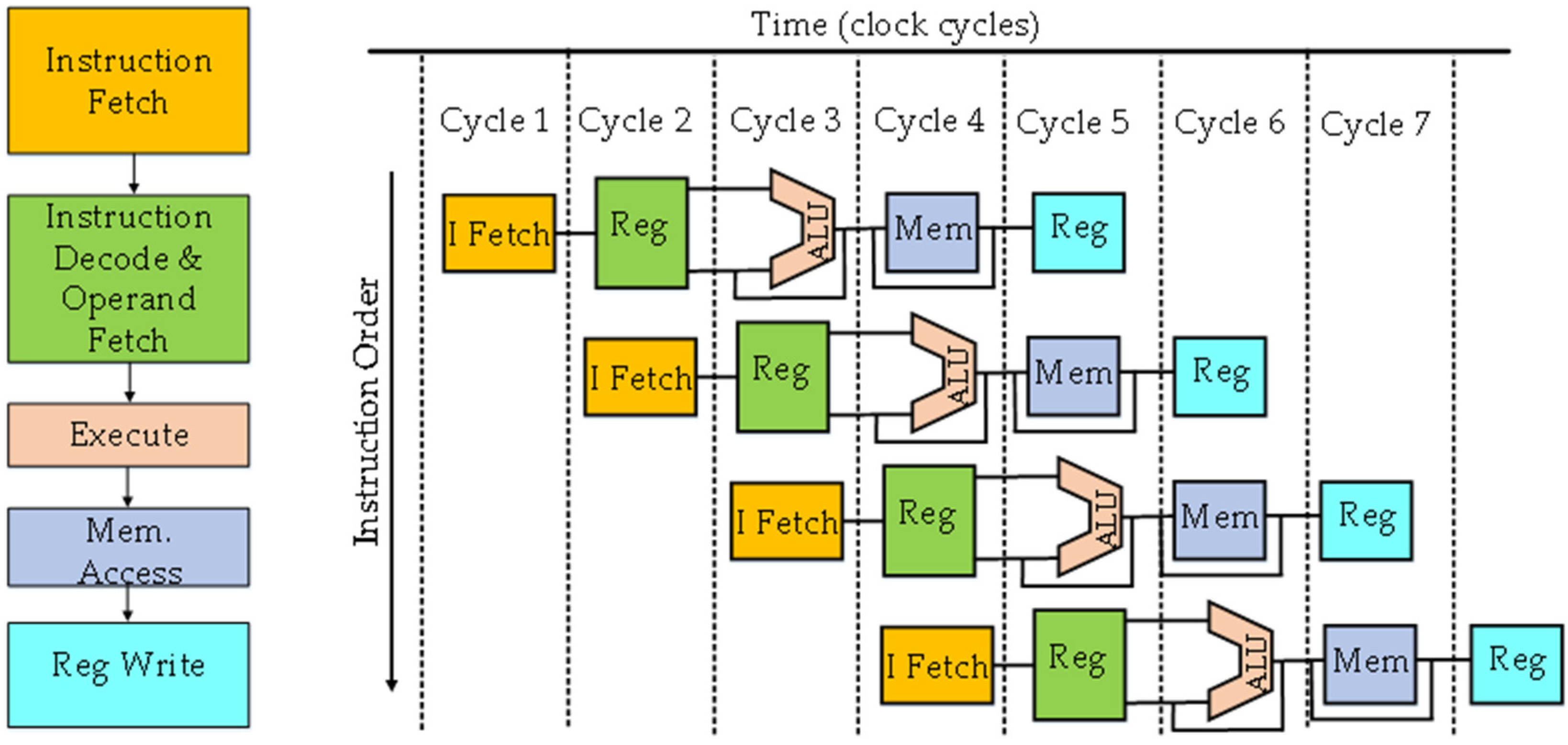
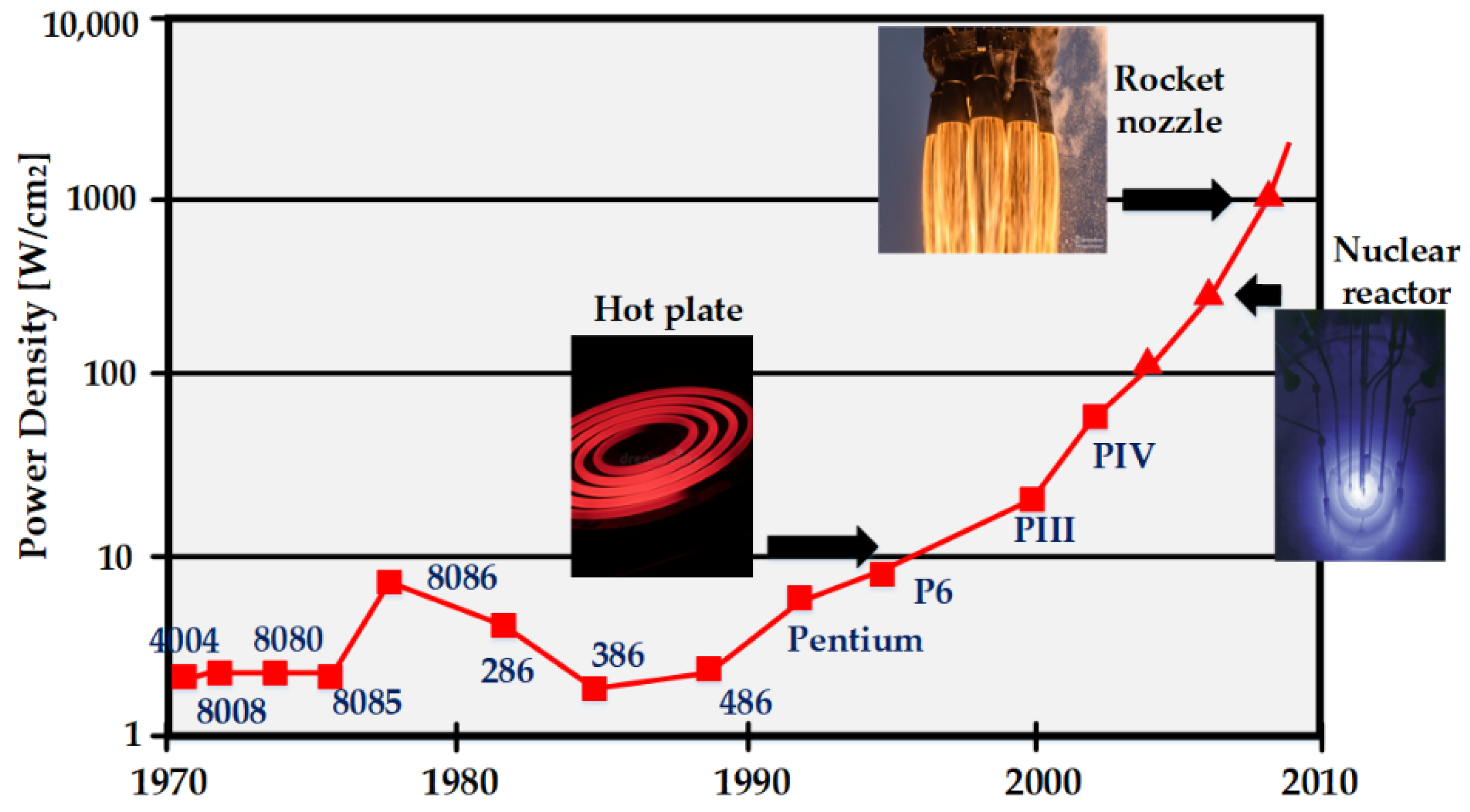
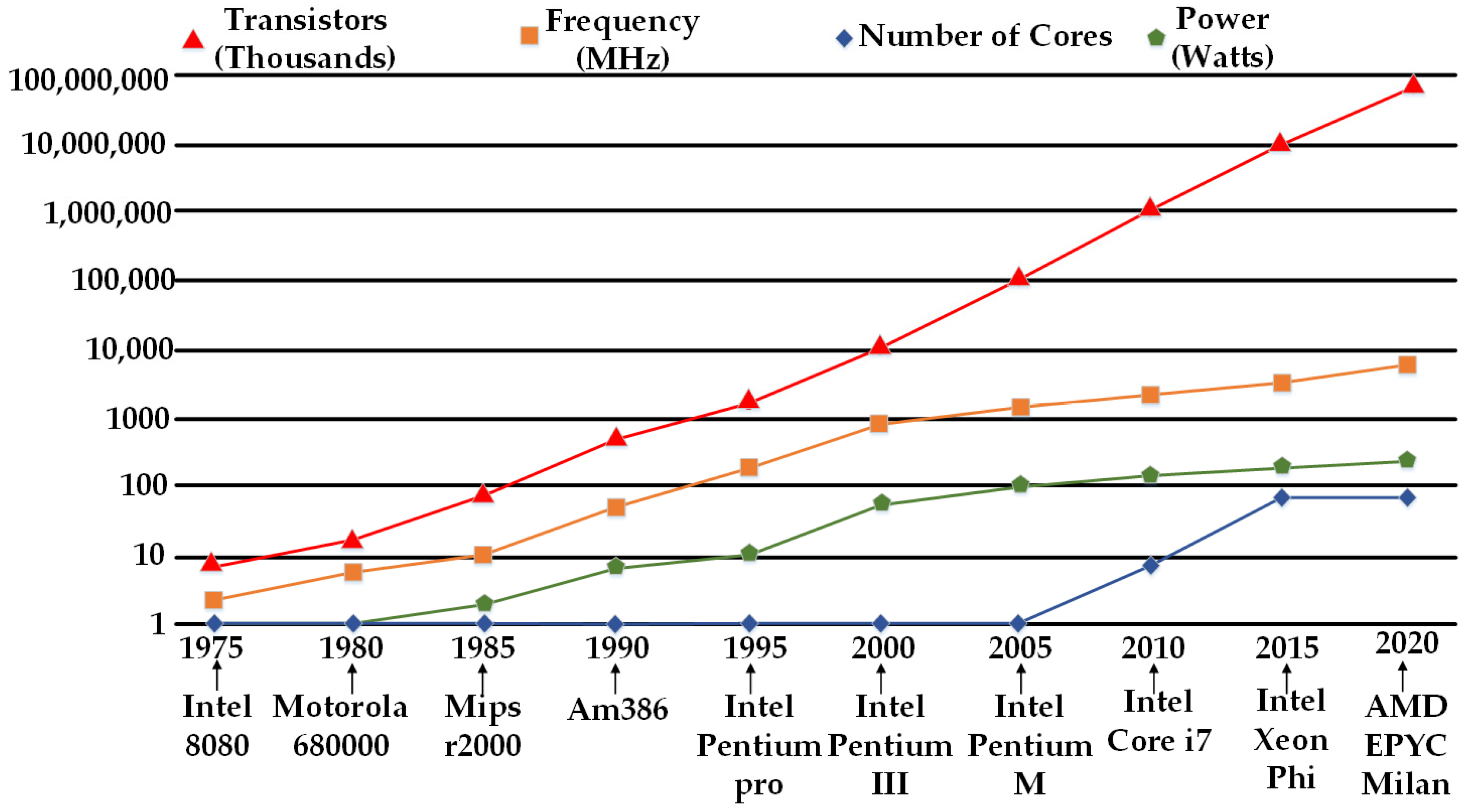
3. Emergence of Microprocessors
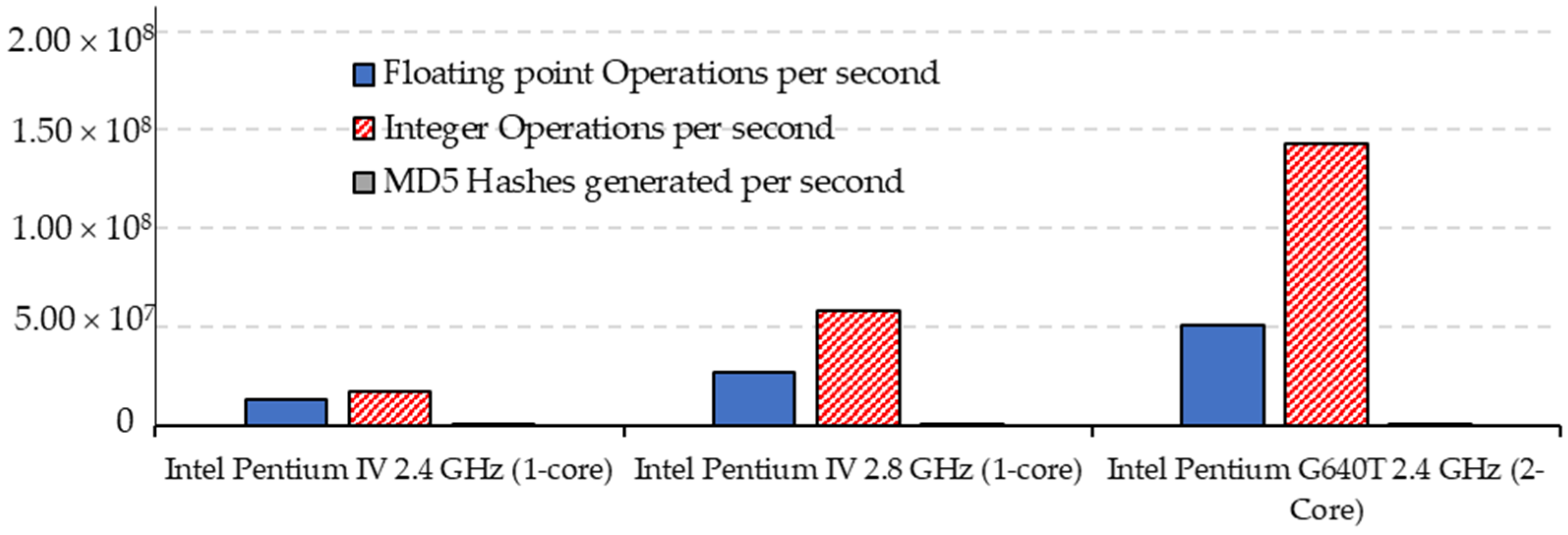
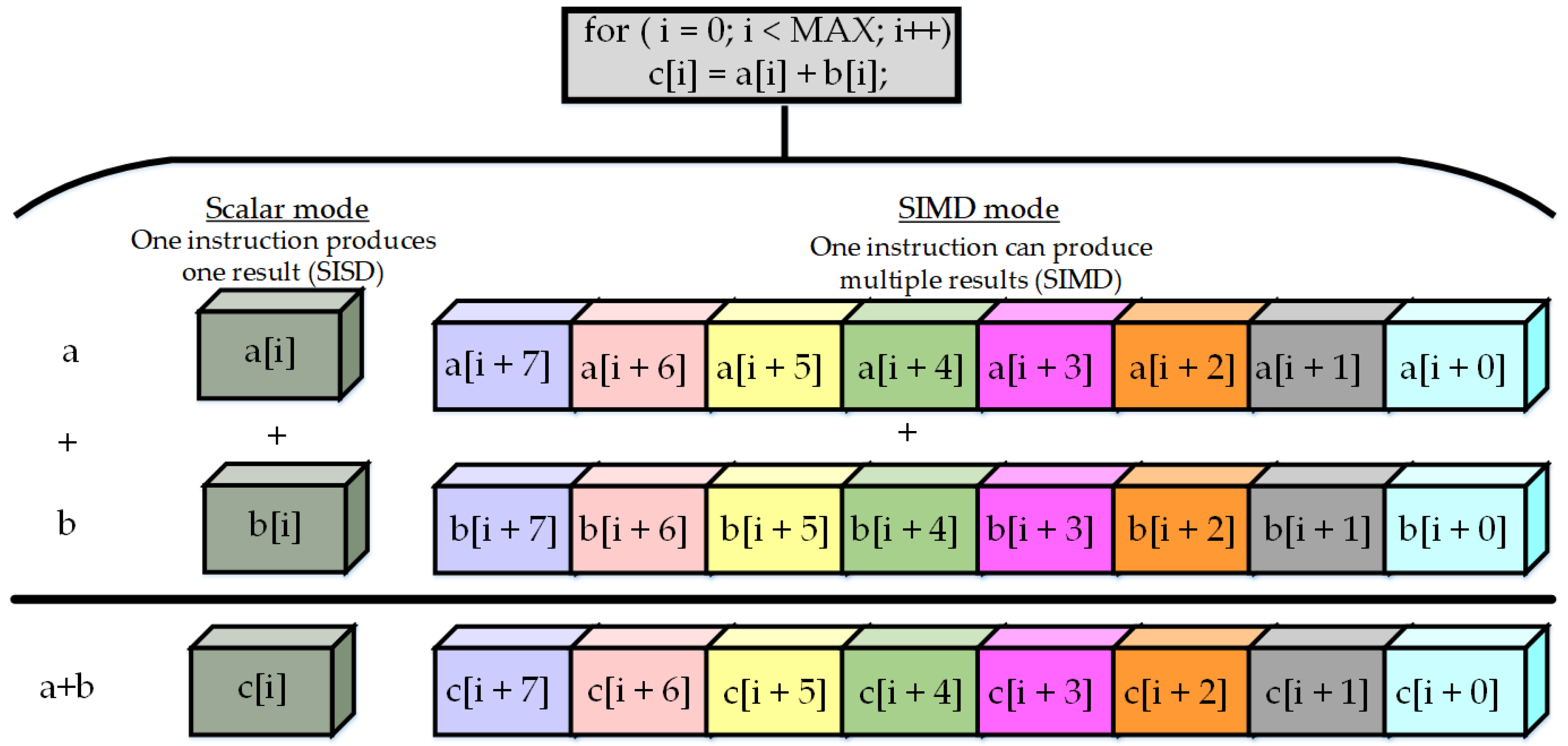
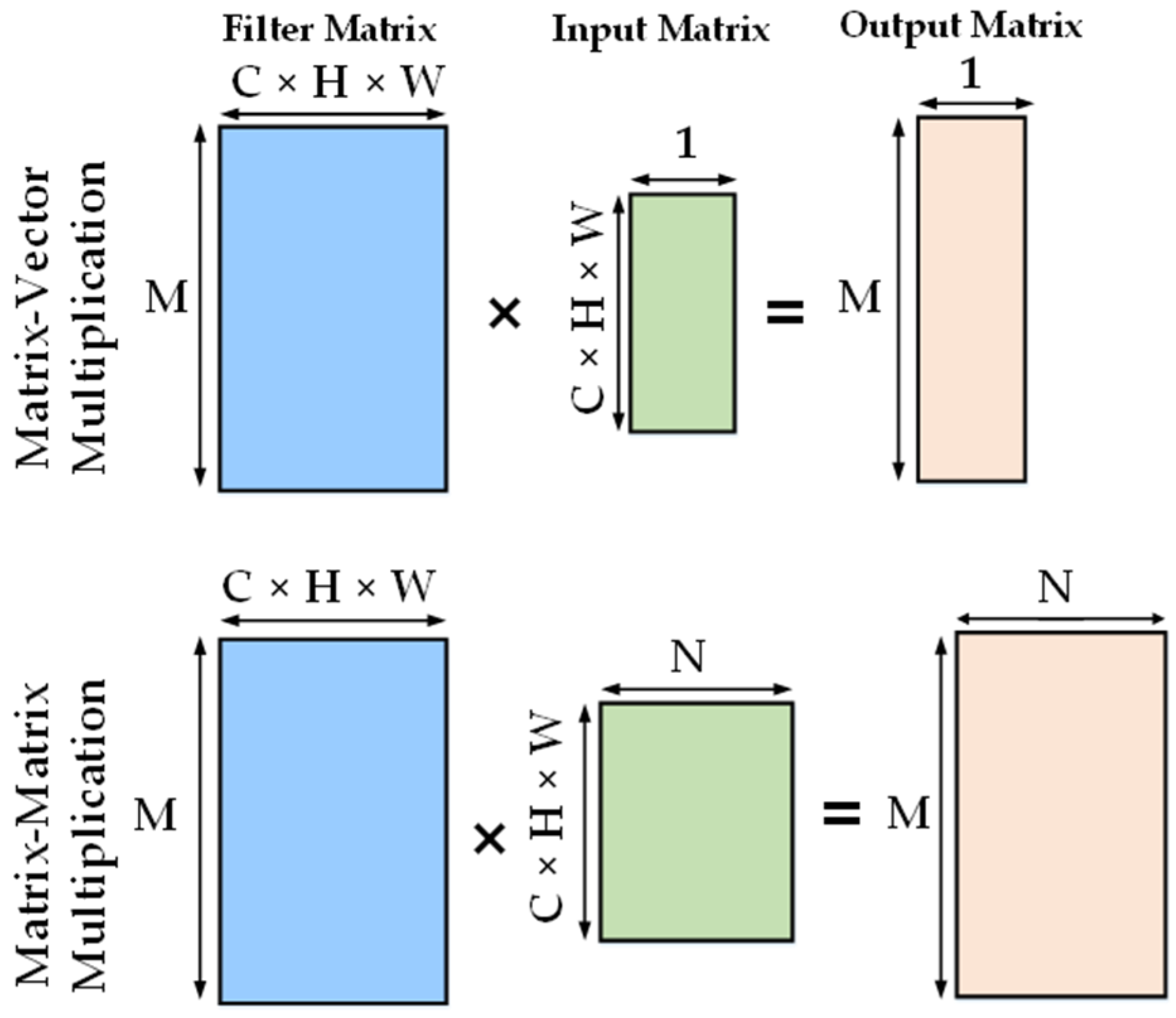
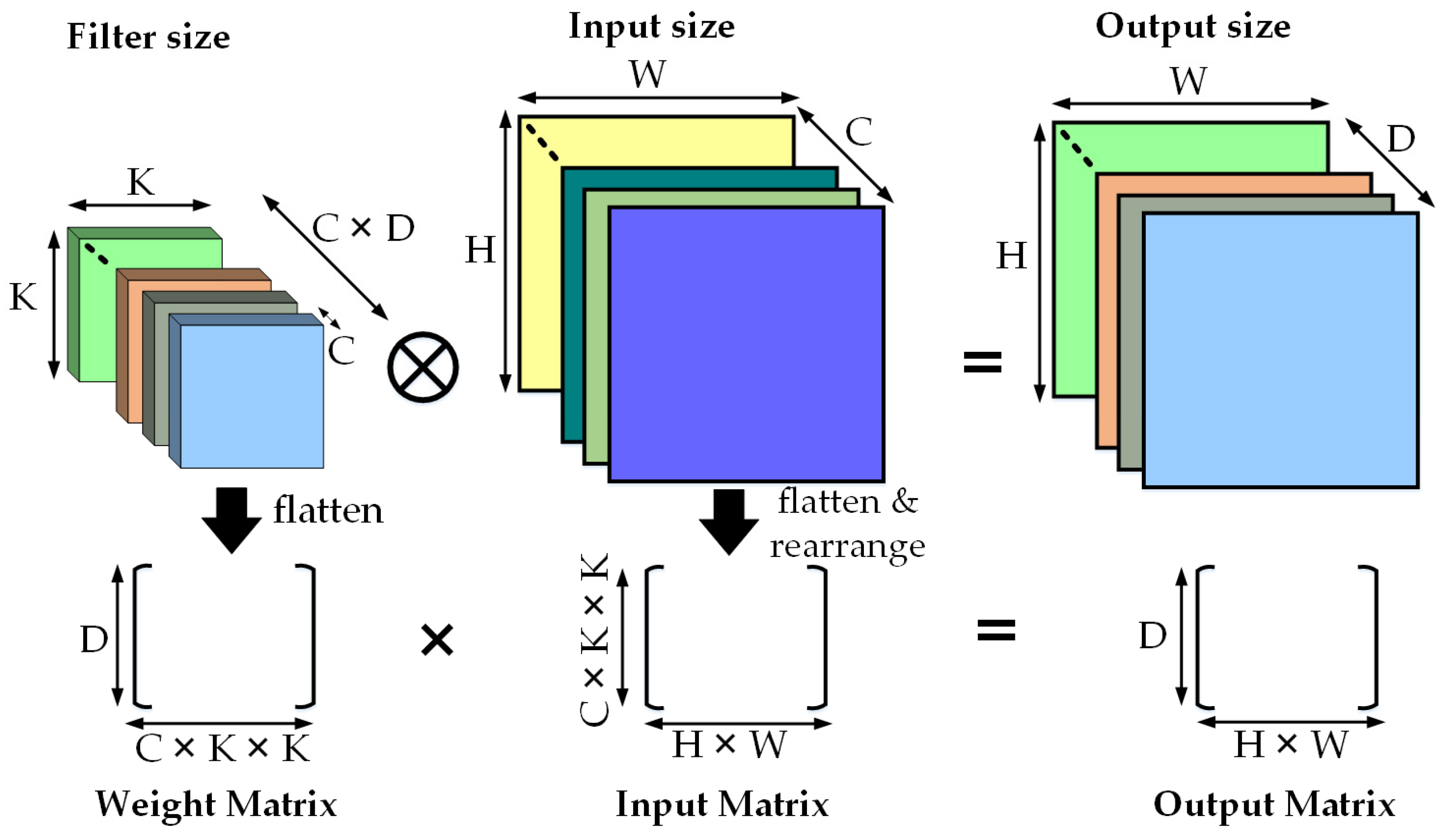
4. Confluence between Artificial Intelligence and Microprocessors
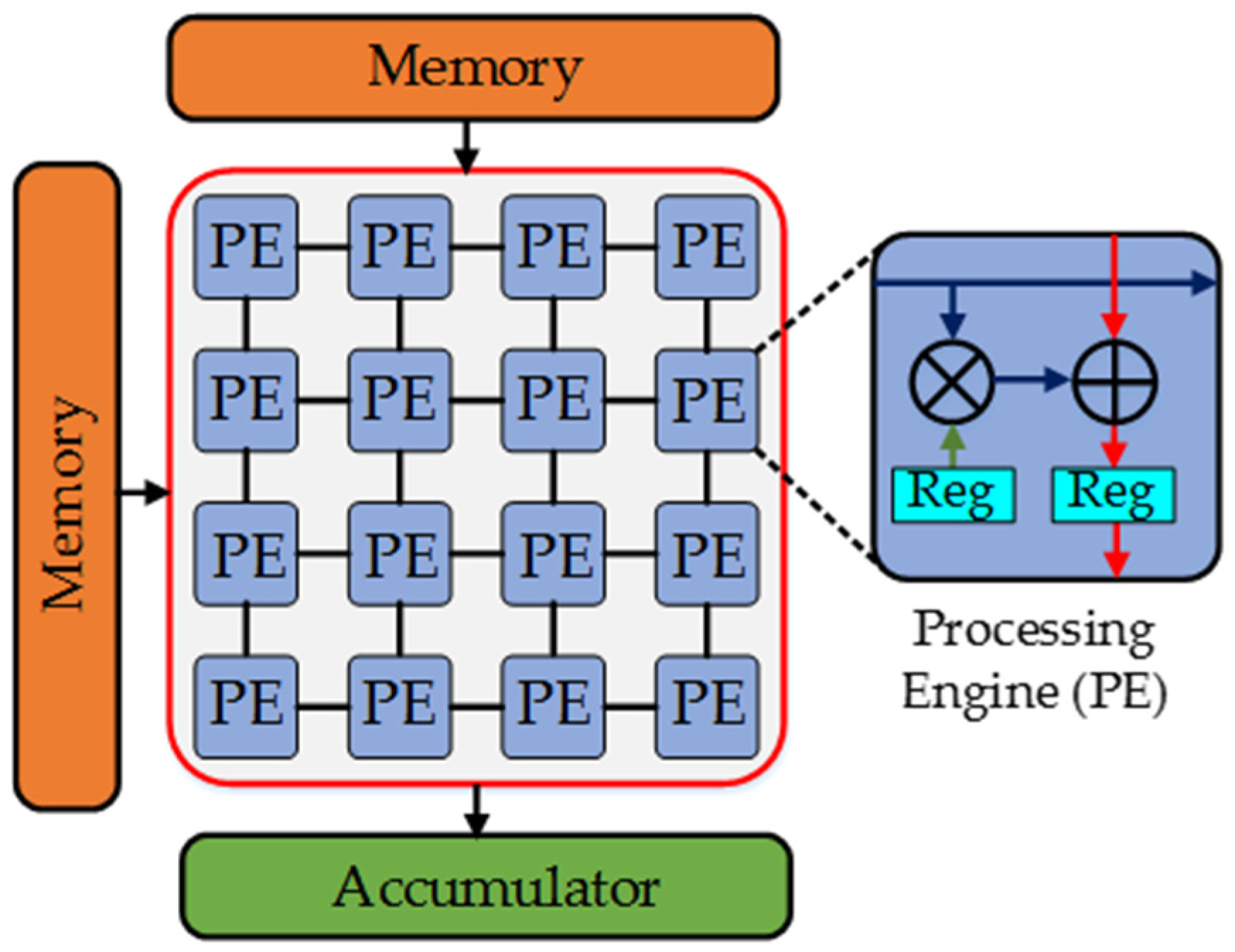
- Output Stationary (OS): The accumulation of partial sums is kept constant in PEs to minimize the energy consumption of reading and writing partial sums while broadcasting the inputs and weights to the array of PEs just like in ShiDianNao [142].
- No Local Reuse (NLR): Nothing stays stationary, as the local memory for PEs is eliminated to reduce the area requirement. For instance, DianNao [143] has an NLR dataflow.
- Row Stationary (RS): It aims to minimize the memory access cost by reusing all types of data (weights, inputs, and partial sums) by mapping the rows of convolution on PEs for each sliding window. Eyeriss [144] is one of the accelerators based on RS architecture.
5. Future Roadmap and Challenges
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Turing, A.M. Computing Machinery and Intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- Newell, A.; Shaw, J.C.; Simon, H.A. Report on General Problem-Solving Program. In Proceedings of the International Conferenceon Information Processing, Paris, France, 30 December 1958. [Google Scholar]
- Gelernter, H.L.; Rochester, N. Intelligent Behaviour in Problem- Solving Machines. IBM J. Res. Dev. 1958, 2, 336. [Google Scholar] [CrossRef]
- Weizenbaum, J. ELIZA—A Computer Program for the Study of Natural Language Communication between Man and Machine. Commun. Assoc. Comput. Mach. (ACM) 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Rosenblatt, F. The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Delipetrev, B.; Tsinaraki, C.; Kostic, U. Historical Evolution of Artificial Intelligence; EUR 30221 EN; Publications Office of the European Union: Luxembourg, 2020. [Google Scholar]
- Nikolopoulos, C. Expert Systems: Introduction to First and Second Generation and Hybrid Knowledge Based Systems; Marcel Dekker, Inc.: New York, NY, USA, 1997. [Google Scholar]
- Shortliffe, E.H.; Davis, R.; Axline, S.G.; Buchanan, B.G.; Green, C.C.; Cohen, S.N. Computer-based Consultations in Clinical Therapeutics: Explanation and Rule Acquisition Capabilities of the MYCIN System. Comput. Biomed. Res. 1975, 8, 303–320. [Google Scholar] [CrossRef]
- Shafique, M.; Theocharides, T.; Bouganis, C.S.; Hanif, M.A.; Khalid, F.; Hafız, R.; Rehman, S. An overview of next-generation architectures for machine learning: Roadmap, opportunities and challenges in the IoT era. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018. [Google Scholar]
- Khan, F.H.; Ashraf, U.; Altaf, M.A.B.; Saadeh, W. A Patient-Specific Machine Learning based EEG Processor for Accurate Estimation of Depth of Anesthesia. In Proceedings of the 2018 IEEE Biomedical Circuits and Systems Conference (BioCAS), Cleveland, OH, USA, 17–19 October 2018. [Google Scholar]
- Cao, B.; Zhan, D.; Wu, X. Application of SVM in Financial Research. In Proceedings of the 2009 International Joint Conference on Computational Sciences and Optimization, Sanya, China, 24–26 April 2009. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Wiafe, I.; Koranteng, F.N.; Obeng, E.N.; Assyne, N.; Wiafe, A.; Gulliver, A.S.R. Artificial Intelligence for Cybersecurity: A Systematic Mapping of Literature. IEEE Access 2020, 8, 146598–146612. [Google Scholar] [CrossRef]
- Vishnukumar, H.J.; Butting, B.; Müller, C.; Sax, E. Machine learning and Deep Neural Network—Artificial Intelligence Core for Lab and Real-world Test and Validation for ADAS and Autonomous Vehicles: AI for Efficient and Quality Test and Validation. In Proceedings of the Intelligent Systems Conference (IntelliSys), London, UK, 7–8 September 2017. [Google Scholar]
- Hashimoto, Y.; Murase, H.; Morimoto, T.; Torii, T. Intelligent Systems for Agriculture in Japan. IEEE Control Syst. Mag. 2001, 21, 71–85. [Google Scholar]
- Khan, F.H.; Saadeh, W. An EEG-Based Hypnotic State Monitor for Patients During General Anesthesia. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2021, 29, 950–961. [Google Scholar] [CrossRef]
- Mohsen, H.; El-Dahshan, E.-S.A.; El-Horbaty, E.-S.M.; Salem, A.-B.M. Classification using Deep Learning Neural Networks for Brain Tumors. Future Comput. Inform. J. 2018, 3, 68–71. [Google Scholar] [CrossRef]
- Ying, J.J.; Huan, P.; Chang, C.; Yang, D. A preliminary study on deep learning for predicting social insurance payment behavior. In Proceedings of the IEEE International Conference on Big Data (Big Data), Boton, MA, USA, 11–14 December 2017. [Google Scholar]
- Zanc, R.; Cioara, T.; Anghel, I. Forecasting Financial Markets using Deep Learning. In Proceedings of the IEEE 15th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 5–7 September 2019. [Google Scholar]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of Deep Learning Techniques for Autonomous Driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Huang, P.-S.; He, X.; Gao, J.; Deng, A.A.L.; Heck, L. Learning Deep Structured Semantic Models for Web Wearch using Clickthrough Data. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management (CIKM ‘13), New York, NY, USA, 27 October–1 November 2013. [Google Scholar]
- Dahl, G.E.; Sainath, T.N.; Hinton, G.E. Improving Deep Neural Networks for LVCSR using Rectified Linear Units and Dropout. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Zhang, D.; Liu, S.E. Top-Down Saliency Object Localization Based on Deep-Learned Features. In Proceedings of the 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018. [Google Scholar]
- Quillian, M.R. The Teachable Language Comprehender: A Simulation Program and Theory of Language. Assoc. Comput. Mach. 1969, 12, 459–476. [Google Scholar] [CrossRef]
- Details for Component Intel Core i7-8086K. SiSoftware Official Live Ranker. Available online: https://ranker.sisoftware.co.uk/show_device.php?q=c9a598d1bfcbaec2e2a1cebcd9f990a78ab282ba8cc7e186bb96a781f3ceffd9b08dbd9bf3cefed8a09dad8bee8bb686a0d3eed6&l=en (accessed on 6 April 2021).
- Cray-1 Computer System Hardware Reference Manual 2240004. Cray Research, Inc., 4 November 1977. Available online: http://bitsavers.trailing-edge.com/pdf/cray/CRAY-1/2240004C_CRAY-1_Hardware_Reference_Nov77.pdf (accessed on 6 April 2021).
- Xiao, L.; Bahri, Y.; Sohl-Dickstein, J.; Schoenholz, S.S.; Pennington, J. Dynamical Isometry and a Mean Field Theory of CNNs: How to Train 10000-layer Vanilla Convolutional Neural Networks. 2018. Available online: http://arxiv.org/abs/1806.05393 (accessed on 6 April 2021).
- Intel’s Museum Archive, i4004datasheet. Available online: http://www.intel.com/Assets/PDF/DataSheet/4004_datasheet.pdf (accessed on 10 April 2021).
- iAPX 86, 88 USER’S MANUAL. August 1981. Available online: http://www.bitsavers.org/components/intel/_dataBooks/1981_iAPX_86_88_Users_Manual.pdf (accessed on 4 June 2021).
- Patterson, D.A.; Ditzel, D.R. The Case for the Reduced Instruction Set Computer. SIGARCH Comput. Archit. News 1980, 8, 25–33. [Google Scholar] [CrossRef]
- History of the Development of the Arm Chip at Acorn. Available online: https://www.cs.umd.edu/~meesh/cmsc411/website/proj01/arm/history.html (accessed on 6 April 2021).
- Moore, G. Cramming more Components onto Integrated Circuits. Electronics 1965, 114–117. [Google Scholar] [CrossRef]
- Hennessy, J.L.; Patterson, D.A. Computer Architecture: A Quantitative Approach; Morgan Kaufman Publishers, Inc.: San Mateo, CA, USA, 2012. [Google Scholar]
- Seto, K.; Nejatollah, H.; Kang, J.A.S.; Dutt, N. Small Memory Footprint Neural Network Accelerators. In Proceedings of the 20th International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 6–7 March 2019. [Google Scholar]
- Guo, X.; Ipek, E.; Soyata, T. Resistive Computation: Avoiding the Power Wall with Low-Leakage, STT-MRAM based Computing. SIGARCH Comput. Archit. 2010, 38, 371–382. [Google Scholar] [CrossRef]
- Wulf, W.A.; McKee, S.A. Hitting the memory wall: Implications of the obvious. SIGARCH Comput. Archit. 1995, 23, 20–24. [Google Scholar] [CrossRef]
- Baji, T. Evolution of the GPU Device widely used in AI and Massive Parallel Processing. In Proceedings of the 2018 IEEE 2nd Electron Devices Technology and Manufacturing Conference (EDTM), Kobe, Japan, 13–16 March 2018. [Google Scholar]
- Deng, L.; Li, G.; Han, S.; Shi, L.; Xie, Y. Model Compression and Hardware Acceleration for Neural Networks: A Comprehensive Survey. Proc. IEEE 2020, 108, 485–532. [Google Scholar] [CrossRef]
- Chen, Y.; Luo, T.; Liu, S.; Zhang, S.; He, L.; Wang, J.; Li, L.; Chen, T.; Xu, Z.; Sun, N.; et al. DaDianNao: A Machine-Learning Supercomputer. In Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, UK, 13–17 December 2014. [Google Scholar]
- Liu, D.; Chen, T.; Liu, S.; Zhou, J.; Zhou, S.; Teman, O.; Feng, X.; Zhou, X.; Chen, Y. PuDianNao: A Polyvalent Machine Learning Accelerator. SIGARCH Comput. Archit. 2015, 43, 369–381. [Google Scholar] [CrossRef]
- Liu, S.; Du, Z.; Tao, J.; Han, D.; Luo, T.; Xie, Y.; Chen, Y.; Chen, T. Cambricon: An Instruction Set Architecture for Neural Networks. In Proceedings of the ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016. [Google Scholar]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter Performance Analysis of a Tensor Processing Unit. In Proceedings of the 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017. [Google Scholar]
- Betker, M.R.; Fernando, J.S.; Whalen, S.P. The History of the Microprocessor. Bell Labs Tech. J. 1997, 2, 29–56. [Google Scholar] [CrossRef]
- Furber, S. Microprocessors: The Engines of the Digital Age. Proc. R. Soc. 2017, 473, 20160893. [Google Scholar] [CrossRef] [Green Version]
- Brunette, E.S.; Flemmer, R.C.; Flemmer, C.L. A Review of Artificial Intelligence. In Proceedings of the 4th International Conference on Autonomous Robots and Agents, Wellington, New Zealand, 10–12 February 2009. [Google Scholar]
- Bush, V. The Differental Analyzer. J. Frankl. Inst. 1931, 212, 447–488. [Google Scholar] [CrossRef]
- Turing, A.M. On Computable Numbers, with an Application to the Entscheidungs problem. Proc. Lond. Math. Soc. 1937, 2, 230–265. [Google Scholar] [CrossRef]
- Strachey, C. Logical or Non-Mathematical Programmes. In Proceedings of the 1952 ACM National Meeting, Toronto, ON, Canada, 1 June 1952; pp. 46–49. [Google Scholar]
- Samuel, A. Some Studies in Machine Learning using the Game of Checkers. IBM J. 1959, 3, 210–299. [Google Scholar] [CrossRef]
- Newell, A.; Simon, H.A. The Logic Theory Machine a Complex Information Processing System. 15 June 1956. Available online: http://shelf1.library.cmu.edu/IMLS/MindModels/logictheorymachine.pdf (accessed on 10 April 2021).
- McCarthy, J. Recursive Functions of Symbolic Expressions and their Computation by Machine, Part I. Commun. ACM 1960, 3, 184–195. [Google Scholar] [CrossRef] [Green Version]
- Minsky, M.; Papert, S.A. Perceptrons: An introduction to Computational Geometry; MIT Press: Cambridge, MA, USA, 1969. [Google Scholar]
- Nof, S.Y. Handbook of Industrial Robotics, 2nd ed.; John Wiley & Sons: New York, NY, USA, 1999; pp. 3–5. [Google Scholar]
- Slagle, J.R. A Heuristic Program that Solves Symbolic Integration Problems in Freshman Calculus. J. ACM 1963, 10, 507–520. [Google Scholar]
- Bobrow, D.G. A Question-Answering System for High School Algebra Word Problems. In Proceedings of the Fall Joint Computer Conference, Part I (AFIPS ‘64 (Fall, Part I)), New York, NY, USA, 27–29 October 1964. [Google Scholar]
- Raphael, B. Robot Research at Stanford Research Institute; Stanford Research Institute: Menlo Park, CA, USA, 1972. [Google Scholar]
- Winograd, T. Procedures as a Representation for Data in a Computer Program for Understanding Natural Language. Cogn. Psychol. 1972, 3, 1–191. [Google Scholar] [CrossRef]
- Pierce, J.R.; Carroll, J.B.; Hamp, E.P.; Hays, D.G.; Hockett, C.F.; Oettinger, A.G.; Perlis, A. Languages and Machines: Computers in Translation and Linguistics; The National Academies Press: Washington, DC, USA, 1966. [Google Scholar] [CrossRef]
- Artificial Intelligence: A Paper Symposium; Science Research Council: London, UK, 1973.
- Buchanan, B.G.; Feigenbaum, E.A. Dendral and Meta-dendral: Their Applications Dimension. Artif. Intell. 1978, 11, 5–24. [Google Scholar] [CrossRef]
- Colmerauer, A.; Roussel, P. The Birth of Prolog. Assoc. Comput. Mach. 1993, 28, 37–52. [Google Scholar]
- Crevier, D. AI: The Tumultuous Search for Artificial Intelligence; Basic Books: New York, NY, USA, 1993; p. 198. [Google Scholar]
- Enslow, B. The Payoff from Expert Systems. Across Board 1989, 54. Available online: https://stacks.stanford.edu/file/druid:sb599zp1950/sb599zp1950.pdf (accessed on 6 May 2021).
- McKinzie, W. The fifth generation. Proc. IEEE 1985, 73, 493–494. [Google Scholar] [CrossRef]
- Hopfield, J.J. Neural Networks and Physical Systems with Emergent Collective Computational Abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation. Calif. Univ. San Diego La Jolla Inst Cogn. Sci. 1986, 1, 318–362. [Google Scholar]
- Coats, P.K. Why Expert Systems Fail. Financ. Manag. 1988, 17, 77–86. [Google Scholar] [CrossRef]
- Boone, G.W. Variable Function Programmed Calculator. US Patent 4,074,351, 14 February 1978. [Google Scholar]
- Laws, D. Motorola 6800 Oral History Panel: Development and Promotion; Computer History Museum: Tempe, AZ, USA, 2008. [Google Scholar]
- IEEE Standard for Binary Floating-Point Arithmetic. ANSI/IEEE Stand. 1985, 754, 1–20.
- Patterson, D. Reduced Instruction Set Computers. Commun. Assoc. Mach. 1985, 28, 14. [Google Scholar] [CrossRef]
- Mead, C.; Conway, L. Introduction to VSLI Systems; Addison-Wesley: Boston, MA, USA, 1980. [Google Scholar]
- The Street How Cadence Designs the Future. Available online: https://www.thestreet.com/tech/news/cadence072120 (accessed on 7 April 2021).
- Freeman, R.; Kawa, J.; Singhal, K. Synopsys’ Journey to Enable TCAD and EDA Tools for Superconducting Electronics. 2020. Available online: https://www.synopsys.com/content/dam/synopsys/solutions/documents/gomac-synopsys-supertools-paper.pdf (accessed on 7 April 2021).
- Yilmaz, M.; Erdogan, E.S.; Roberts, M.B. Introduction to Mentor Graphics Design Tools. 2009. Available online: http://people.ee.duke.edu/~jmorizio/ece261/LABMANUALS/mentor_toolsv7_windows.pdf (accessed on 7 April 2021).
- How Intel Makes Chips: Transistors to Transformations. Available online: https://www.intel.com/content/www/us/en/history/museum-transistors-to-transformations-brochure.html (accessed on 7 April 2021).
- Patterson, D.A.; Sequin, C.H. RISC I: A Reduced Instruction Set VLSI Computer. In Proceedings of the 8th Annual Symposium on Computer Architecture, Washington, DC, USA, 27 June–2 July 1981. [Google Scholar]
- Radin, G. The 801 Minicomputer. IBM J. Res. Dev. 1982, 27, 237–246. [Google Scholar] [CrossRef]
- Hennessy, J.; Hennessy, J.N.; Przybylski, S.; Rowen, C.; Gross, T.; Baskett, F.; Gill, J. MIPS: A Microprocessor Architecture. SIGMICRO Newsl. 1982, 13, 17–22. [Google Scholar] [CrossRef]
- MC68030 Product Summary Page-Freescale. 2012. Available online: https://web.archive.org/web/20141006204732/http://www.freescale.com/webapp/sps/site/prod_summary.jsp?code=MC68030 (accessed on 6 April 2021).
- Intel 80486 DX Microprocessor Datasheet. Available online: https://datasheetspdf.com/pdf-file/493187/Intel/80486DX/1 (accessed on 6 April 2021).
- Patterson, D.; Hennessy, J. Computer Organization and Design: The Hardware Software Interface, 5th ed.; Morgan Kaufmann: Burlington, MA, USA, 2013. [Google Scholar]
- Smith, E.; Weiss, S. PowerPC601 and Alpha21064: A Tale of Two RISCs. Computer 1994, 27, 46–58. [Google Scholar] [CrossRef]
- Intel® Pentium® III Processor 1.00 GHz, 256K Cache, 133 MHz FSB. Available online: https://ark.intel.com/content/www/us/en/ark/products/27529/intel-pentium-iii-processor-1-00-ghz-256k-cache-133-mhz-fsb.html (accessed on 6 April 2021).
- Welker, M.W. AMD Processor Performance Evaluation Guide; ADVANCED MICRO DEVICES One AMD Place: Sunnyvale, CA, USA, 2005. [Google Scholar]
- Jagger, D. Advanced RISC Machines Architecture Reference Manual, 1st ed.; Prentice Hall: Englewood Cliffs, NJ, USA, 1997. [Google Scholar]
- Furber, S. ARM System-on-Chip Architecture; Addison Wesley: Boston, MA, USA, 2020. [Google Scholar]
- Gelsinger, P. Microprocessors for the new millennium: Challenges, opportunities, and new frontiers. In Proceedings of the 2001 IEEE International Solid-State Circuits Conference, Digest of Technical Papers, ISSCC, San Francisco, CA, USA, 7 February 2001. [Google Scholar]
- Asanovic, K.; Bodik, R.; Catanzaro, B.C.; Gebis, J.J.; Husbands, P.; Keutzer, K.; Patterson, D.A.; Plishker, W.L.; Shalf, J.; Williams, S.W.; et al. The Landscape of Parallel Computing Research: A View from Berkeley; Electrical Engineering and Computer Sciences University of California at Berkeley: Berkeley, CA, USA, 2006. [Google Scholar]
- Dual-Core Processors Microprocessors Types and Specifications. 12 June 2006. Available online: https://www.informit.com/articles/article.aspx?p=481859&seqNum=21 (accessed on 6 April 2021).
- R. Ramanathan Intel® Multi-Core Processors Making the Move to Quad-Core and Beyond White Paper Intel Multi-Core Processors. Available online: https://web.cse.ohio-state.edu/~panda.2/775/slides/intel_quad_core_06.pdf (accessed on 6 April 2021).
- Hong, S.; Graves, L. AMD Announces Worldwide Availability of AMD Ryzen™ PRO 3000 Series Processors Designed to Power the Modern Business PC. 2019. Available online: https://www.amd.com/en/press-releases/2019-09-30-amd-announces-worldwide-availability-amd-ryzen-pro-3000-series-processors (accessed on 2 June 2021).
- Havemann, R.; Hutchby, J. High-performance interconnects: An integration overview. Proc. IEEE 2001, 89, 586–601. [Google Scholar] [CrossRef] [Green Version]
- Le Cun, Y.; Jackel, L.D.; Boser, B.; Denker, J.S.; Graf, H.P.; Guyon, I.; Henderson, D.; Howard, R.E.; Hubbard, W. Handwritten Digit Recognition: Applications of Neural Network Chips and Automatic Learning. IEEE Commun. Mag. 1989, 27, 41–46. [Google Scholar] [CrossRef]
- Holler, M.; Tam, S.; Castro, H.; Benson, R. An Electrically Trainable Artificial Neural Network (ETANN) with 10240 floating gate synapses. In Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, June 1989. [Google Scholar]
- Castro, H.A.; Tam, S.M.; Holler, M.A. Implementation and Performance of an Analog Nonvolatile Neural Network. Analog. Integr. Circuits Signal Process. 1993, 4, 97–113. [Google Scholar] [CrossRef]
- Ramacher, U.; Raab, W.; Hachmann, J.U.; Beichter, J.; Bruls, N.; Wesseling, M.; Sicheneder, E.; Glass, J.; Wurz, A.; Manner, R. SYNAPSE-1: A High-Speed General Purpose Parallel Neurocomputer System. In Proceedings of the 9th International Parallel Processing Symposium, Santa Barbara, CA, USA, 25–28 April 1995. [Google Scholar]
- Sackinger, E.; Boser, B.E.; Bromley, J.; LeCun, Y.; Jackel, L.D. Application of the ANNA Neural Network Chip to High-Speed Character Recognition. IEEE Trans. Neural Netw. 1992, 3, 498–505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Dang, H.; Liang, Y.; Wei, L.; Li, C.; Dang, S. Artificial Neural Network Design for Enabling Relay Selection by Supervised Machine Learning. In Proceedings of the 2018 Eighth International Conference on Instrumentation & Measurement, Computer, Communication and Control (IMCCC), Harbin, China, 19–21 July 2018. [Google Scholar]
- Amirhossein, T.; Anthony, S. A Spiking Network that Learns to Extract Spike Signatures from Speech Signals. Neurocomput 2017, 240, 191–199. [Google Scholar]
- Yann, C.J.B.; LeCun, Y.; Cortes, C. The MNIST Database of Handwritten Digits. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 6 April 2021).
- Krizhevsky, A.; Nair, V.; Hinton, G. The CIFAR-10 Dataset. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 6 April 2021).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Deng, L.; Li, J.; Huang, J.T.; Yao, K.; Yu, D.; Seide, F.; Seltzer, M.; Zweig, G.; He, X.; Williams, J.; et al. Recent Advances in Deep Learning for Speech Research at Microsoft. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8604–8608. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Proc. NIPS 2012, 1097–1105. [Google Scholar] [CrossRef]
- BASU, S. A Cursory Look at Parallel Architectures and Biologically Inspired Computing. In Academic Press Series in Engineering, Soft Computing and Intelligent Systems; Academic Press: Cambridge, MA, USA, 2000; pp. 185–216. [Google Scholar]
- Johnson, O.; Omosehinmi, D. Comparative Analysis of Single-Core and Multi-Core Systems. Int. J. Comput. Sci. Inf. Technol. 2015, 7, 117–130. [Google Scholar] [CrossRef]
- James, R. Intel AVX-512 Instructions. 2017. Available online: https://software.intel.com/content/www/cn/zh/develop/articles/intel-avx-512-instructions.html (accessed on 3 April 2021).
- Raskulinec, G.M.; Fiksman, E. SIMD Functions Via OpenMP. In High Performance Parallelism Pearls; Morgan Kaufmann: Burlington, MA, USA, 2015. [Google Scholar]
- Arm Neon Intrinsics Reference for ACLE Q3. Available online: https://developer.arm.com/architectures/system-architectures/software-standards/acle (accessed on 3 April 2021).
- Vasudevan, A.; Anderson, A.; Gregg, D. Parallel Multi Channel Convolution using General Matrix Multiplication. In Proceedings of the 2017 IEEE 28th International Conference on Application-specific Systems Architectures and Processors (ASAP), Seattle, WA, USA, 10–12 July 2017. [Google Scholar]
- Chellapilla, K.; Puri, S.; Simard, P. High Performance Convolutional Neural Networks for Document Processing. In Proceedings of the Tenth International Workshop on Frontiers in Handwriting Recognition, La Baule, France, 1 October 2006. [Google Scholar]
- Intel Math Kernel Library. Available online: https://software.intel.com/en-us/mkl (accessed on 6 April 2021).
- Vedaldi, A.; Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Darrell, T. Convolutional Architecture for Fast Feature Embedding. In Proceedings of the ACM International Conference on Multimedia, MM’14, Orlando, FL, USA, 7 November 2014. [Google Scholar]
- Intel Deep Learning Boost (Intel DL Boost). Available online: https://www.intel.com/content/www/us/en/artificial-intelligence/deep-learning-boost.html (accessed on 7 April 2021).
- Horowitz, M. Computing’s Energy Problem (and What We Can Do About It). In Proceedings of the 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 9–13 February 2014. [Google Scholar]
- Rodriguez, A.; Segal, E.; Meiri, E.; Fomenko, E.; Kim, Y.; Shen, H.; Ziv, B. Lower Numerical Precision Deep Learning Inference and Training. Intel White Paper 2018, 3, 1–19. [Google Scholar]
- bfloat16-Hardware Numerics Definition. 2018. Available online: https://software.intel.com/content/www/us/en/develop/download/bfloat16-hardware-numerics-definition.html (accessed on 6 April 2021).
- Developments in the Arm A-Profile Architecture: Armv8.6-A. Available online: https://community.arm.com/developer/ip-products/processors/b/processors-ip-blog/posts/arm-architecture-developments-armv8-6-a (accessed on 7 April 2021).
- rocBLAS Documentation-Advanced Micro Devices. Available online: https://rocblas.readthedocs.io/en/master/index.html (accessed on 7 April 2021).
- The Intel® Xeon Phi™ Product Family Product Brief. Available online: https://www.intel.com/content/dam/www/public/us/en/documents/product-briefs/high-performance-xeon-phi-coprocessor-brief.pdf (accessed on 6 April 2021).
- Capra, M.; Bussolino, B.; Marchisio, A.; Shafique, M.; Masera, G.; Martina, M. An Updated Survey of Efficient Hardware Architectures for Accelerating Deep Convolutional Neural Networks. Future Internet 2020, 12, 113. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Szeged, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-V4, inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1–3. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vega, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. In Proceedings of the NIPS 2017 Workshop on Autodiff, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: Tensorflow.org (accessed on 4 June 2021).
- Chetlur, S.; Woolley, C.; Vandermersch, P.; Cohen, J.; Tran, J.; Catanzaro, B.; Shelhamer, E. cuDNN: Efficient Primitives for Deep Learning. arXiv 2014, arXiv:1410.0759. [Google Scholar]
- NVIDIA CUDA-X GPU-Accelerated Libraries. 2020. Available online: https://developer.nvidia.com/gpu-accelerated-libraries (accessed on 6 April 2021).
- Nvidia Tesla V100 GPU Architecture. 2017. Available online: https://images.nvidia.com/content/technologies/volta/pdf/437317-Volta-V100-DS-NV-US-WEB.pdf (accessed on 6 April 2021).
- Nvidia A100 Tensor core GPU Architecture. 2020. Available online: https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/nvidia-ampere-architecture-whitepaper.pdf (accessed on 4 June 2021).
- Aimar, A.; Mostafa, H.; Calabrese, E.; Rios-Navarro, A.; Tapiador-Morales, R.; Lungu, I.; Milde, M.; Corradi, F.; Linares-Barranco, A.; Liu, S. NullHop: A Flexible Convolutional Neural NetworkAccelerator Based on Sparse Representations of Feature Maps. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 644–656. [Google Scholar] [CrossRef] [Green Version]
- Gokhale, V.; Jin, J.; Dundar, A.; Martini, B.; Culurciello, E. A 240 G-ops/s mobile Coprocessor for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Sankaradas, M.; Jakkula, V.; Cadambi, S.; Chakradhar, S.; Durdanovic, I.; Cosatto, E.; Graf, H.P. A Massively Parallel Coprocessor for Convolutional Neural Networks. In Proceedings of the 2009 20th IEEE International Conference on Application-specific Systems, Architectures and Processors, Boston, MA, USA, 7–9 July 2009; pp. 53–60. [Google Scholar]
- Du, Z.; Fasthuber, R.; Chen, T.; Ienne, P.; Li, L.; Luo, T.; Feng, X.; Chen, Y.; Temam, O. ShiDianNao: Shifting Vision Processing Closer to the Sensor. In Proceedings of the 42nd Annual International Symposium on Computer Architecture, Portland, OR, USA, 13–17 June 2015; pp. 92–104. [Google Scholar]
- Chen, T.; Du, Z.; Sun, N.; Wang, J.; Wu, C.; Chen, Y.; Temam, O. DianNao: A Small-footprint High-throughput Accelerator for Ubiquitous Machine-Learning. Proc. ASPLOS 2014, 4, 269–284. [Google Scholar]
- Chen, Y.; Krishna, T.; Emer, J.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Google I/O’17 California: Google. Available online: https://events.google.com/io2017/ (accessed on 7 April 2021).
- Google Cloud Next’18. California: Google. Available online: https://cloud.withgoogle.com/next18/sf/ (accessed on 7 April 2021).
- Chen, X.; Lin, X. Big Data Deep Learning: Challenges and Perspectives. IEEE Access 2014, 2, 514–525. [Google Scholar] [CrossRef]
- Shabbir, J.; Anwer, T. Artificial Intelligence and its Role in Near Future. arXiv 2018, arXiv:1804.01396. [Google Scholar]
- Pavlidis, V.F.; Savidis, I.; Friedman, E.G. Three-Dimensional Integrated Circuit Design; Morgan Kaufmann: San Francisco, CA, USA, 2009. [Google Scholar]
- Patterson, D.A. Microprocessors in 2020. Sci. Am. 1995, 273, 62–67. [Google Scholar]
- Jouppi, N.P.; Yoon, D.H.; Kurian, G.; Li, S.; Patil, N.; Laudon, J.; Young, C.; Patterson, D. A domain-specific supercomputer for training deep neural networks. Commun. ACM 2020, 63, 67–78. [Google Scholar] [CrossRef]
- Biggio, B.; Fumera, G.; Roli, F. Security Evaluation of Pattern Classifiers under Attack. IEEE Trans. Knowl. Data Eng. 2013, 26, 984–996. [Google Scholar] [CrossRef] [Green Version]
- Finlayson, S.G.; Bowers, J.D.; Ito, J.; Zittrain, J.L.; Beam, A.L.; Kohane, I.S. Adversarial Attacks on Medical Machine Learning. Science 2019, 363, 1287–1289. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| High-Performance (Superscalar) Microprocessors | |||||
|---|---|---|---|---|---|
| Microprocessor | Year | Clock Speed (MHz) | Transistor Size (microns) | Cache Size (KB) | Pipe Stages |
| Intel 486 (Intel, Santa Clara, CA, USA) | 1989 | 25 to 50 | 0.8–1 | 8 | 5 |
| Intel Pentium Pro (Intel, Santa Clara, CA, USA) | 1995 | 200 | 0.35–0.6 | 8/8 | 12–14 |
| DEC Alpha 21164 (DEC, Maynard, MA, USA) | 1996 | 500 | 0.5 | 8/8/96 | 7 |
| Power PC 604e | 1997 | 233 | 0.25 | 32/32 | 6 |
| AMD K5 (AMD, Santa Clara, CA, USA) | 1996 | 75–133 | 0.35–0.5 | 8/16 | 5 |
| MIPS R10000 (MIPS Technologies, Sunnyvale, CA, USA) | 1996 | 200 | 0.35 | 32/32 | 5 |
| Intel Pentium IV (Intel, Santa Clara, CA, USA ) | 2000 | 1400–2000 | 0.18 | 256 | 20 |
| Multicore Microprocessors | |||||
|---|---|---|---|---|---|
| Microprocessor | Year | Clock Speed (GHz) | Transistor Size (nm) | Caches (MB) | Cores |
| AMD Athlon 64 X2 | 2005 | 2 | 90–65 | 0.5 | 2 |
| Intel Core 2 Duo | 2006 | 2.66 | 65 | 4 | 2 |
| Intel Core 2 Quad Q6600 | 2007 | 2.4 | 65 | 8 | 4 |
| Intel Core i7-3770 | 2012 | 3.4 | 22 | 8 | 4 |
| AMD Ryzen 7 1700x | 2017 | 3-3.6 | 14 | 4/16 | 8 |
| Intel Core i9 10900 | 2020 | 5.20 | 14 | 20 | 10 |
| Intel Xeon Platinum 9282 | 2019 | 3.8 | 14 | 77 | 56 |
| AMD Ryzen Threadripper 3990X (AMD, Santa Clara, CA, USA) | 2020 | 4.3 | 7 | 32/256 | 64 |
| CPU | GPU | ||||
|---|---|---|---|---|---|
| Processors | Minimum Cores | Maximum Cores | Processors | Tensor Cores | CUDA Cores |
| Intel Core i7, 10th Gen | 4 | 8 | Nvidia RTX 2080 | - | 4352 |
| AMD Ryzen | 4 | 16 | |||
| Intel Core i9, 10th Gen | 8 | 28 | Nvidia V100 | 640 | 5120 |
| Intel Xeon Plat. I Gen | 4 | 28 | |||
| Intel Xeon Plat. II Gen | 4 | 56 | Nvidia A100 | 432 | 6912 |
| AMD Ryzen Threadripper | 24 | 64 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, F.H.; Pasha, M.A.; Masud, S. Advancements in Microprocessor Architecture for Ubiquitous AI—An Overview on History, Evolution, and Upcoming Challenges in AI Implementation. Micromachines 2021, 12, 665. https://doi.org/10.3390/mi12060665
Khan FH, Pasha MA, Masud S. Advancements in Microprocessor Architecture for Ubiquitous AI—An Overview on History, Evolution, and Upcoming Challenges in AI Implementation. Micromachines. 2021; 12(6):665. https://doi.org/10.3390/mi12060665
Chicago/Turabian StyleKhan, Fatima Hameed, Muhammad Adeel Pasha, and Shahid Masud. 2021. "Advancements in Microprocessor Architecture for Ubiquitous AI—An Overview on History, Evolution, and Upcoming Challenges in AI Implementation" Micromachines 12, no. 6: 665. https://doi.org/10.3390/mi12060665
APA StyleKhan, F. H., Pasha, M. A., & Masud, S. (2021). Advancements in Microprocessor Architecture for Ubiquitous AI—An Overview on History, Evolution, and Upcoming Challenges in AI Implementation. Micromachines, 12(6), 665. https://doi.org/10.3390/mi12060665