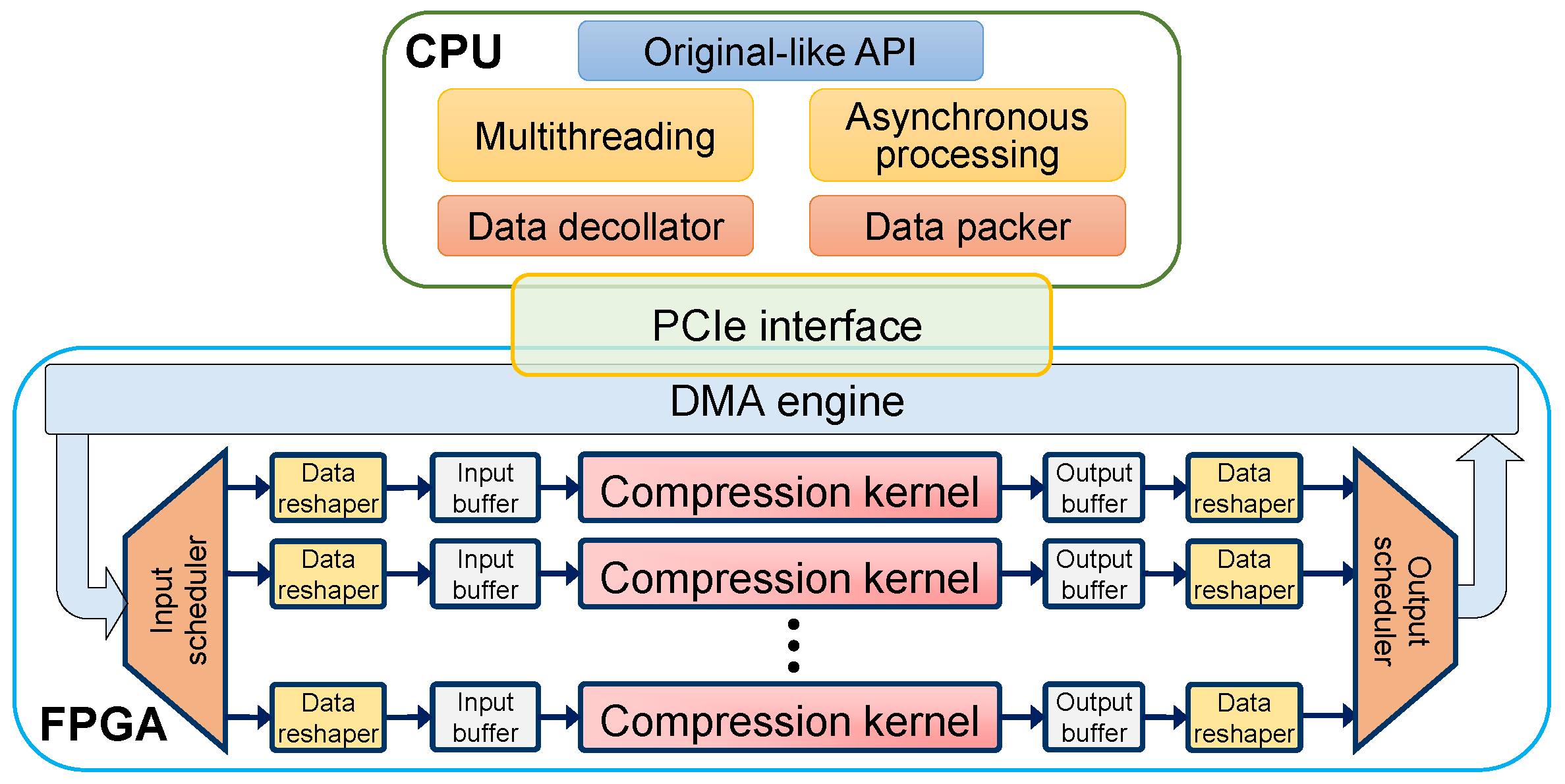
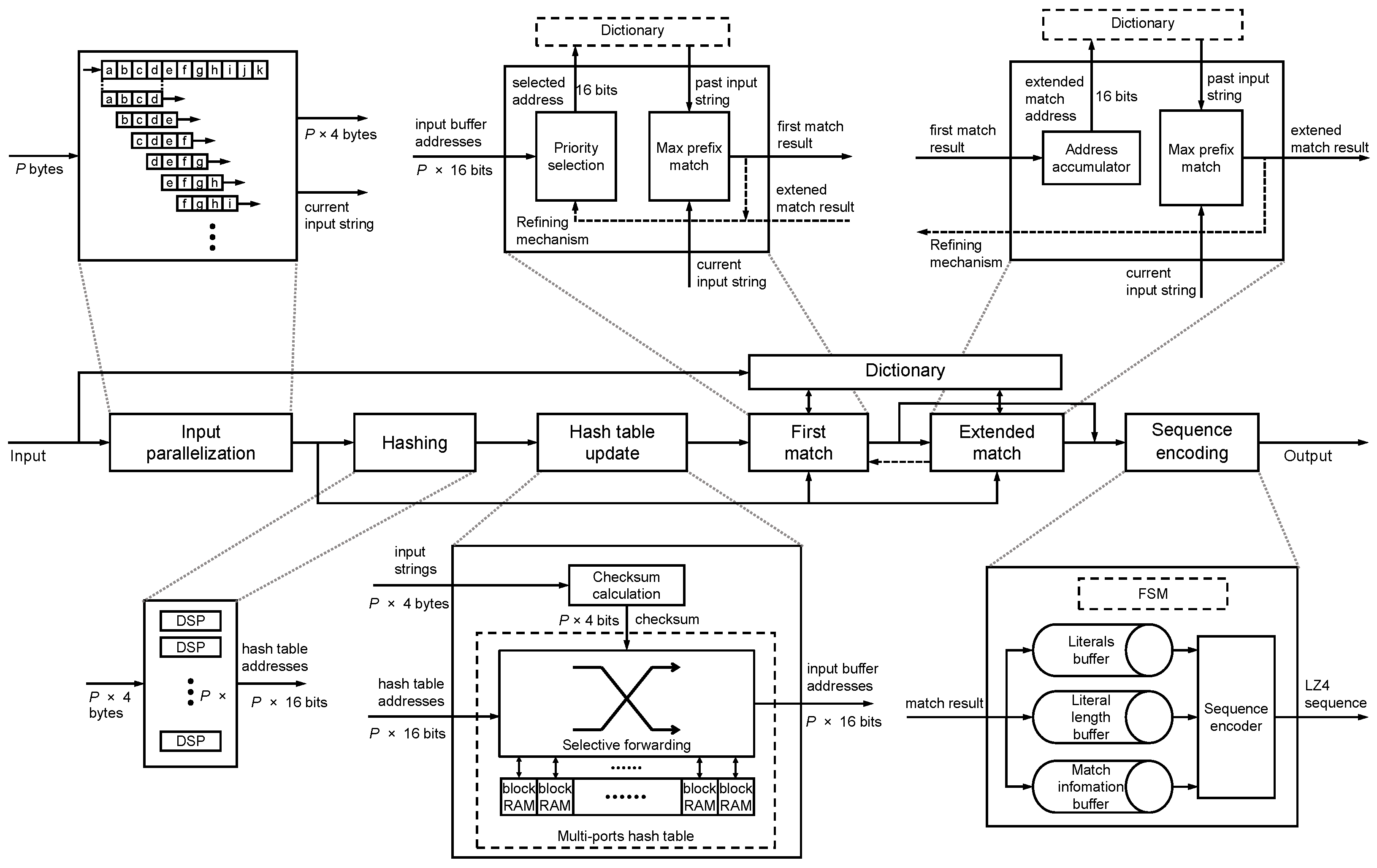
In HybriDC, the compression kernel was implemented to support intrakernel parallel processing. According to the resource-balanced design principle, LUTs and FFs are used more and the block RAM usage does not increase. In this section, we propose the detailed architecture of the parallel compression kernel (
Figure 5). Furthermore, we introduce the memory-efficient parallel hash table design, which is the core module of the compression kernel.
4.1. Compression Kernel Architecture
The HybriDC compression kernel consists of several modules. All modules are tailored to support multibyte parallel processing.
A. The input parallelization module. The input is parallelized to
P input strings in this module. As shown in the top left corner of
Figure 5,
P input strings are constructed from
bytes. In each new cycle, the processing window slides forward
P bytes, and the new
P input strings are generated.
B. The hashing module. In each cycle, the hashing module receives P strings from the input parallelization module and outputs their hash values to the next module. In this module, DSPs are used to implement the P-way Fibonacci hash calculation.
C. The hash table update module. In this module, a parallel hash table supporting updating
P records concurrently was implemented. For
P hash values,
P corresponding dictionary addresses are output in each cycle. In addition, for each record in the hash table, a checksum was implemented by idle block RAM space. The extra checksum reduces the number of false-positive lookups and improves the compression ratio indirectly. The details of the parallel hash table design are explained in
Section 4.2.
D. The dictionary. As mentioned in
Section 3.2, the dictionary stores the most recent input data. When receiving the read requests with addresses from two match modules, the dictionary returns the corresponding past input data. To avoid a possible access collision, the dictionary processes one read request in each cycle.
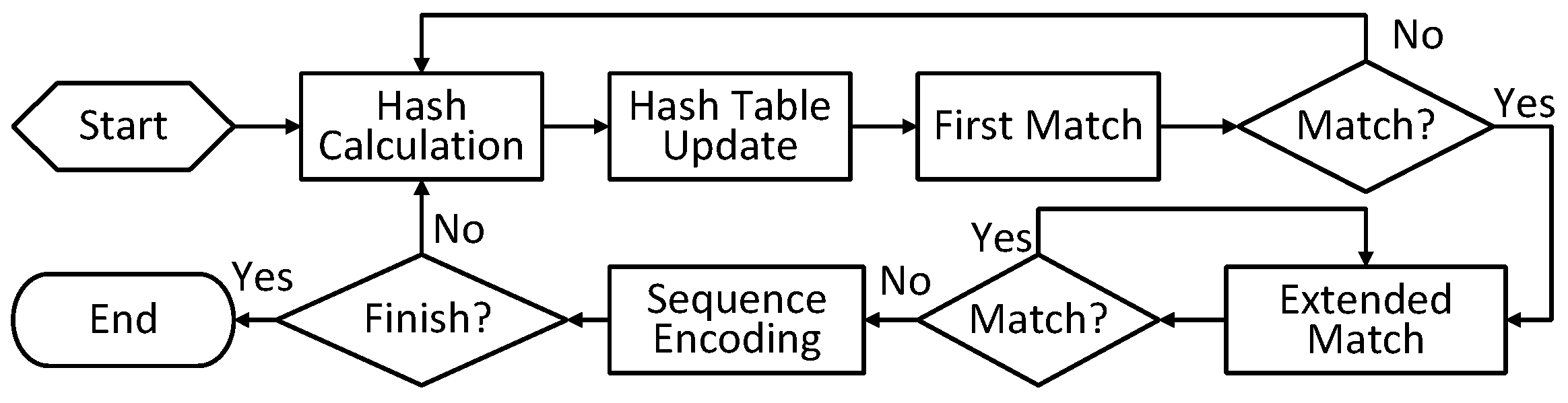
E. The first match module. The current and past strings are compared to confirm the match result in this module. Due to the read request limitation, just one candidate address can be processed in the dictionary. To find the longest match, the earliest candidate (the input string near the beginning) among P possible match candidates is selected. The P-byte past string reads from the dictionary and the P-byte current string are compared by the longest prefix match. Supposing the match length is l bytes, there are three possible match results, defined as failed match (), partial match (), and complete match ().
A failed match means this P-byte input string is unmatched. A partial match means that a matched string is found, but the last several bytes of the input string are unmatched. This match round is over with a partial match. A complete match means that a longer matched string can be found by the extended match.
F. The extended match module. When the match result in the last cycle is a complete match, the extended match module is used. Similarly, the P-byte past string reads from the dictionary are compared with the current string by the longest prefix match. The results can be classified into partial match () and complete match (). When obtaining a complete match, the extended match will work continuously in next cycle. If the result is a partial match, this match round finishes.
G. The output encoding module. Once a match round has finished, a set of compression information is generated, including the unmatched string, the unmatched length, and match information (length and offset). The output encoding module encodes the information into sequences. Specifically, different pieces of information are processed in order. Thus, a finite state machine (FSM) was designed to control these steps in this module.
H. The match-refining mechanism. As mentioned in
Section 3.2.2, some data may miss the matching process caused by the sliding input window. For example, assume that in an 8-byte processing window “abcdefgh”, the substring “abcd” is matched. If the processing window slides forward 8 bytes in the next cycle, the string “efgh” will be skipped and considered as an unmatched string. Nevertheless, the unmatched bytes “efgh” may be matched with other past strings. To address the problem, we propose a match-refining mechanism for finer-grained processing. If the last match result was a
partial match, the processing window begins after the last matched byte. In the previous example, the next 8-byte processing window will follow “abcd” and should be “efghxxxx”. Thanks to the refining mechanism, the compression ratio performance improves significantly. Naturally, the actual degree of intrakernel parallelism of the compression kernel is less than
P since the sliding step is less than
P.
4.2. Memory-Efficient Parallel Hash Table Design
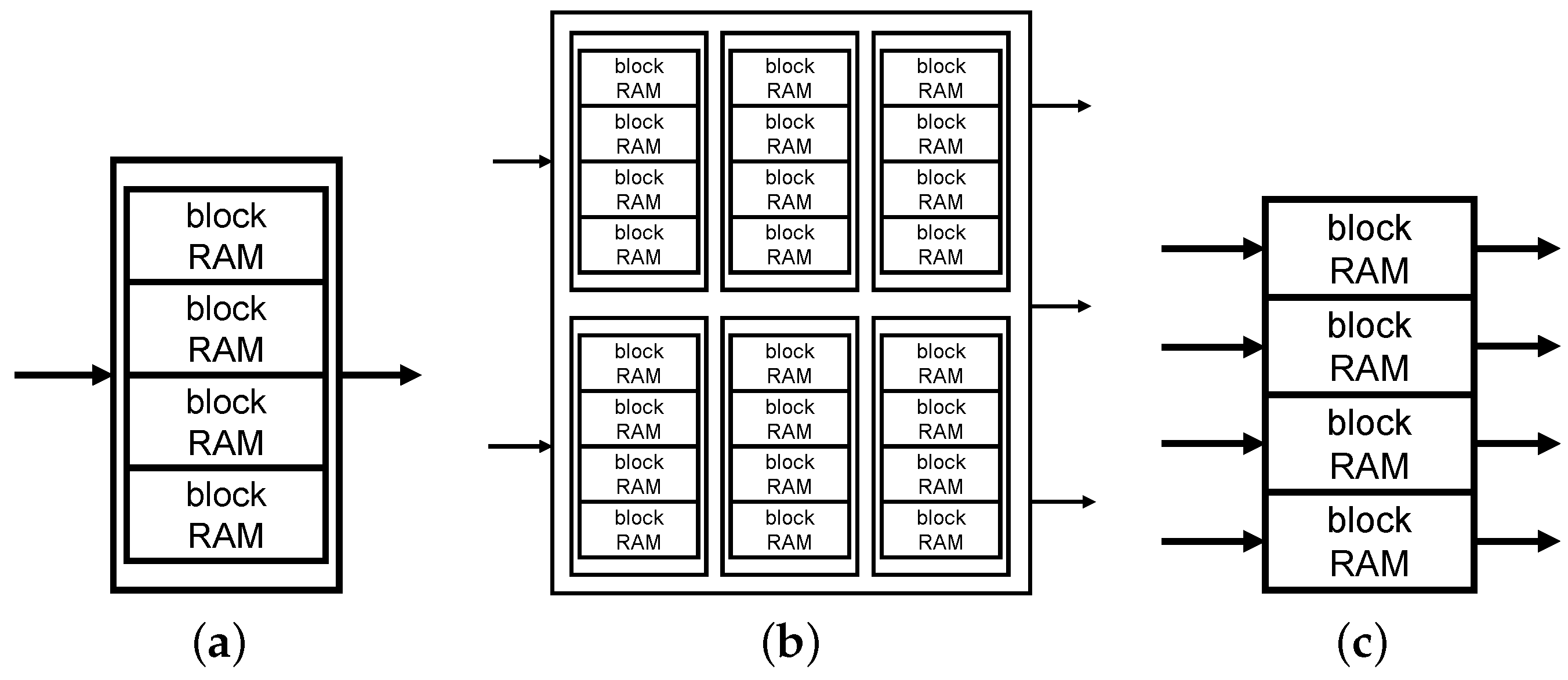
As mentioned before, the hash table is implemented by block RAMs. In general, a block RAM has two access ports for reading and writing data. Multiple block RAMs can be combined into a large storage component (
Figure 6a). However, the number of access ports does not increase for maintaining the data consistency. Thus, this combination of block RAMs cannot realize a parallel hash table.
Several studies applied the LVT-based multiport memory scheme to implement a parallel hash table [
16,
22] (
Figure 6b). Nevertheless, this scheme consumes many memory resources [
25]. For instance, to construct a 16 KB hash table with
P reading ports and
M writing ports,
KB block RAMs should be used. Obviously, this heavy use of block RAMs causes a worse imbalanced resource usage.
In HybriDC, we propose a memory-efficient parallel hash table design, which does not cause extra memory usage. In particular, we use the idle space of block RAMs to implement a novel checksum design and thus improve the compression ratio.
4.2.1. Multiport Hash Table Implementation
The hash table architecture in HybriDC is described in the middle bottom of
Figure 5. In the HybriDC hash table, each block RAM is instantiated individually, and each access port can be used concurrently (
Figure 6c). Meanwhile, an access forwarding component is designed to forward multiple access requests to the corresponding block RAMs.
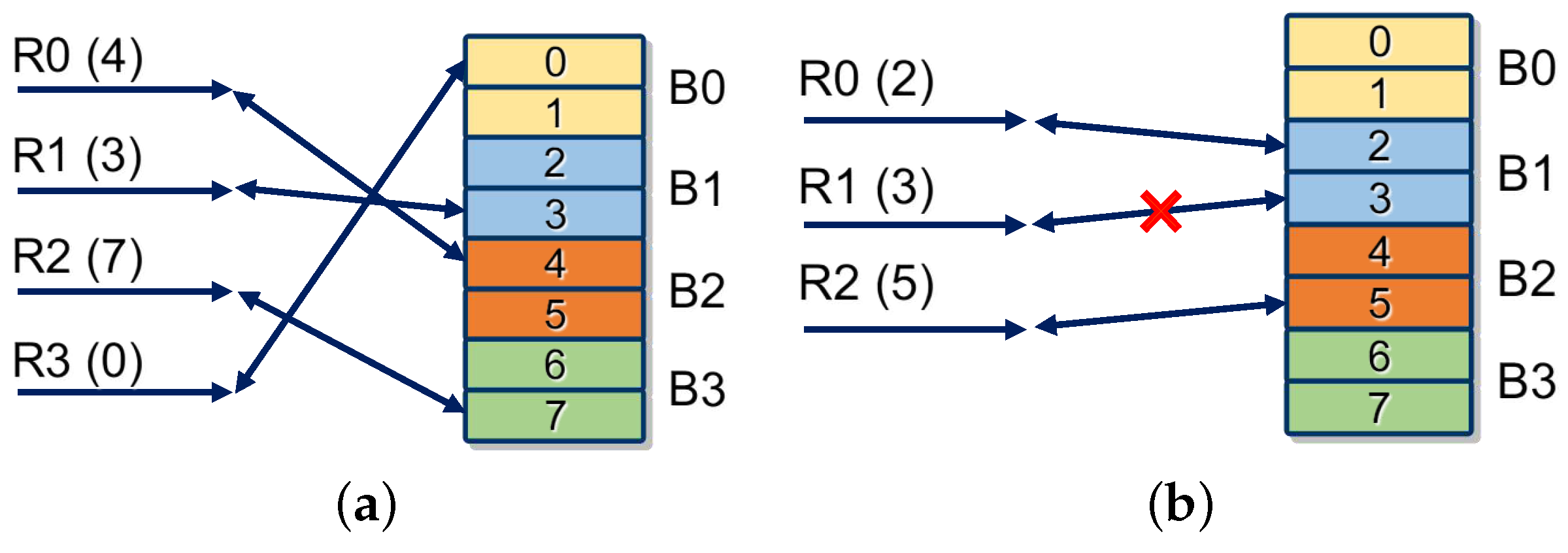
An example of parallel multiple access in our design is shown in
Figure 7a. Four access requests (R0, R1, R2, R3) in channels (C0, C1, C2, C3) are targeted at hash table addresses (4, 3, 7, 0). Addresses (4, 3, 7, 0) are located in block RAMs (B2, B1, B3, B0). In this case, R0, R1, R2, and R3 are forwarded to B2, B1, B3, and B0, respectively. Then, B0, B1, B2, and B3 read and update contents at addresses 0, 3, 4, and 7. Finally, results output from addresses 0, 3, 4, and 7 are sent back to the corresponding channels C3, C1, C0, and C2.
However, some requests may be targeted on the same block RAM. In this situation, only one request can be processed (supposing that one block RAM can handle only one request). As mentioned before, choosing the request of the earliest input string is helpful to find a longer match. Therefore, the earliest first selection strategy is applied in the forwarding component to alleviate the effects of access collision. As shown in
Figure 7b, R0 and R1 target the same block RAM B1. The earliest request R0 is processed, and R1 is abandoned.
4.2.2. Checksum Design for Lookup Optimization
The hash table designs of existing studies can be classified into two types: storing dictionary addresses with or without input strings. Both types waste much storage capacity due to inadequate block RAM utilization.
Type 1: the hash table stores only dictionary addresses. For the block RAM storage, its width and depth are fixed. Take the M20K block RAM in Intel FPGAs as an example, its width is 20 bits, and its depth is 1024. For a 64 KB dictionary, bits addresses are used as the index and stored in the hash table. Obviously, the 16-bit dictionary address cannot fill the 20-bit width of block RAMs, i.e., storage capacity is wasted.
Type 2: the hash table stores dictionary addresses and input strings. The hash table lookup may be a false positive due to the hash collision. Some studies proposed storing the 4-byte input string with its address in the hash table. By skipping reading data from the dictionary, this scheme can facilitate the match result verification in the first match phase. In this scheme, the 48-bit hash table records (16-bit addresses and 32-bit strings) consumes triple block RAMs. In this case, storage capacity is wasted.
In HybriDC, we propose a checksum design utilizing the spare space of block RAMs to filter the false-positive lookup. As shown in
Figure 5, a checksum calculation component is implemented in the hash table update module, which generates a checksum for each input string. The checksum size equals the width of the spare space of block RAMs. A checksum and a dictionary address are regarded as a record to be stored in the hash table. Once a hash table record has been looked up, the new checksum is compared with the fetched checksum. The failed matching result of the checksum comparison means that this lookup must be a false positive. Therefore, most false-positive lookups can be filtered by the checksum, which improves the compression ratio performance indirectly.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}