

Acoustic Wake-Up Technology for Microsystems: A Review



Abstract
:1. Introduction
2. MEMS Acoustic Transducer
2.1. MEMS Microphone
- Capacitive MEMS Microphone
- Piezoelectric MEMS Microphone
2.2. MEMS Hydrophone
2.3. MEMS Acoustic Switch
3. Acoustic Recognition
3.1. Acoustic Features
3.1.1. Time Domain Features
- Amplitude
- Power
- Zero-Crossing
- Autocorrelation
- Duration
3.1.2. Frequency Domain Features
- Spectral Power
- Formant Frequency
- Bandwidth
- Spectral Centroid
- Spectral Spread
- Spectral Flatness
- Cepstral Coefficient
3.1.3. Time-Frequency Domain Features
- Spectral Correlation
- Spectral Flux
- Spectrogram
3.2. Acoustic Classification Algorithm
3.2.1. Linear Classification Algorithm
- Threshold-Based Method
- k-Nearest Neighbors Method
- Nearest Feature Line Method
3.2.2. Nonlinear Machine Learning Classification Algorithm
- Support Vector Machine
- Neural Network
- Gaussian Mixture Model
- Hidden Markov Model-Based
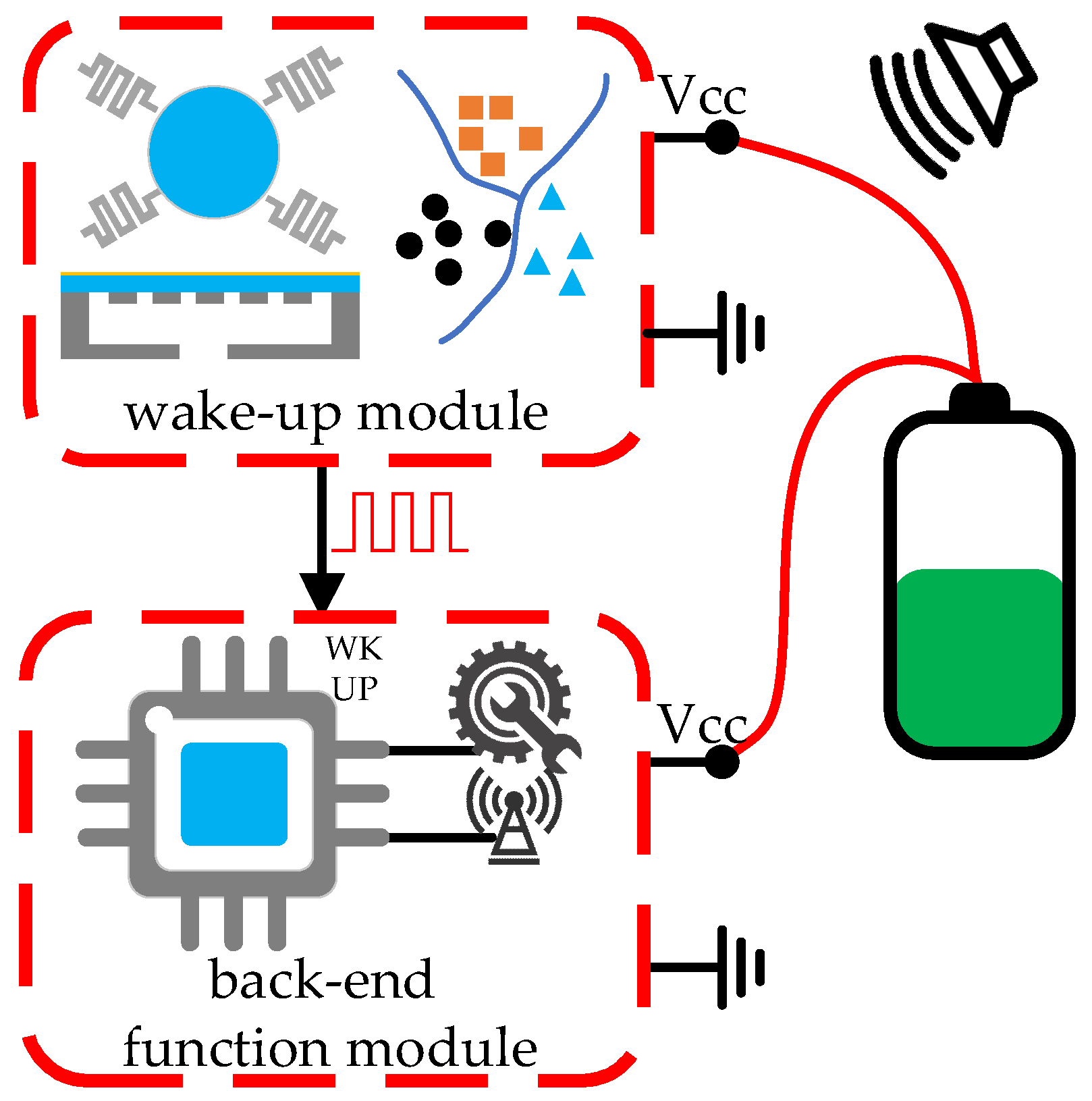
4. System Wake-Up Architecture
4.1. Architecture 1: Low-Power Recognition and Low-Power Sleep
4.2. Architecture 2: Zero-Power Recognition and Low-Power Sleep
4.3. Architecture 3: Low-Power Recognition and Zero-Power Sleep
4.4. Architecture 4: Zero-Power Recognition and Zero-Power Sleep
5. Applications
5.1. Perimeter Surveillance
5.2. Structure Health Monitoring
5.3. Human Health Monitoring
5.4. Agriculture Application
5.5. Biodiversity Research
5.6. Smart City
6. Challenges and Future Research Directions
6.1. Software
6.2. Hardware
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, J.; Liu, X.; Shi, Q.; He, T.; Sun, Z.; Guo, X.; Liu, W.; Sulaiman, O.B.; Dong, B.; Lee, C. Development Trends and Perspectives of Future Sensors and MEMS/NEMS. Micromachines 2020, 11, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Iannacci, J. Microsystem based Energy Harvesting (EH-MEMS): Powering pervasivity of the Internet of Things (IoT)–A review with focus on mechanical vibrations. J. King Saud Univ.-Sci. 2019, 31, 66–74. [Google Scholar] [CrossRef]
- Gazivoda, M.; Bilas, V. Always-on sparse event wake-up detectors: A Review. IEEE Sens. J. 2022, 22, 8313–8326. [Google Scholar] [CrossRef]
- Olsson, R.; Gordon, C.; Bogoslovov, R. Zero and near zero power intelligent microsystems. J. Phys. Conf. Ser. 2019, 1407, 012042. [Google Scholar] [CrossRef]
- Yang, D.; Duan, W.; Xuan, G.; Hou, L.; Zhang, Z.; Song, M.; Zhao, J. Self-Powered Long-Life Microsystem for Vibration Sensing and Target Recognition. Sensors 2022, 22, 9594. [Google Scholar] [CrossRef] [PubMed]
- Cook, E.H.; Tomaino-Iannucci, M.J.; Reilly, D.P.; Bancu, M.G.; Lomberg, P.R.; Danis, J.A.; Elliott, R.D.; Ung, J.S.; Bernstein, J.J.; Weinberg, M.S. Low-Power Resonant Acceleration Switch for Unattended Sensor Wake-Up. J. Microelectromech. Syst. 2018, 26, 1071–1081. [Google Scholar] [CrossRef]
- Pinrod, V.; Pancoast, L.; Davaji, B.; Lee, S.; Ying, R.; Molnar, A.; Lal, A. Zero-Power Sensors with near-Zero-Power Wakeup Switches for Reliable Sensor Platforms. In Proceedings of the 2017 IEEE 30th International Conference on Micro Electro Mechanical Systems (MEMS), Las Vegas, NV, USA, 22–26 January 2017; pp. 1236–1239. [Google Scholar]
- Wheeler, B.; Ng, A.; Kilberg, B.; Maksimovic, F.; Pister, K.S. A low-power optical receiver for contact-free programming and 3D localization of autonomous microsystems. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; pp. 371–376. [Google Scholar]
- Wang, P.-H.; Jiang, H.; Gao, L.; Sen, P.; Kim, Y.-H.; Rebeiz, G.M.; Mercier, P.P.; Hall, D.A. A near-zero-power wake-up receiver achieving−69-dBm sensitivity. IEEE J. Solid-State Circuits 2018, 53, 1640–1652. [Google Scholar] [CrossRef]
- Qian, Z.Y.; Kang, S.H.; Rajaram, V.; Cassella, C.; McGruer, N.E.; Rinaldi, M. Zero-power infrared digitizers based on plasmonically enhanced micromechanical photoswitches. Nat. Nanotechnol. 2017, 12, 969–973. [Google Scholar] [CrossRef]
- Zawawi, S.A.; Hamzah, A.A.; Majlis, B.Y.; Mohd-Yasin, F. A review of MEMS capacitive microphones. Micromachines 2020, 11, 484. [Google Scholar] [CrossRef]
- Citakovic, J.; Hovesten, P.F.; Rocca, G.; van Halteren, A.; Rombach, P.; Stenberg, L.J.; Andreani, P.; Bruun, E. A Compact Cmos Mems Microphone with 66db snr. In Proceedings of the 2009 IEEE International Solid-State Circuits Conference-Digest of Technical Papers, San Francisco, CA, USA, 8–12 February 2009; pp. 350–351. [Google Scholar]
- Huang, C.-H.; Lee, C.-H.; Hsieh, T.-M.; Tsao, L.-C.; Wu, S.; Liou, J.-C.; Wang, M.-Y.; Chen, L.-C.; Yip, M.-C.; Fang, W. Implementation of the CMOS MEMS condenser microphone with corrugated metal diaphragm and silicon back-plate. Sensors 2011, 11, 6257–6269. [Google Scholar] [CrossRef]
- Lo, S.-C.; Lai, W.-C.; Chang, C.-I.; Lo, Y.-Y.; Wang, C.; Bai, M.R.; Fang, W. Development of a No-Back-Plate SOI MEMS Condenser Microphone. In Proceedings of the 2015 Transducers-2015 18th International Conference on Solid-State Sensors, Actuators and Microsystems (Transducers), Anchorage, AK, USA, 21–25 June 2015; pp. 1085–1088. [Google Scholar]
- Ganji, B.A.; Sedaghat, S.B.; Roncaglia, A.; Belsito, L. Design and fabrication of very small MEMS microphone with silicon diaphragm supported by Z-shape arms using SOI wafer. Solid-State Electron. 2018, 148, 27–34. [Google Scholar] [CrossRef]
- Woo, S.; Han, J.-H.; Lee, J.H.; Cho, S.; Seong, K.-W.; Choi, M.; Cho, J.-H. Realization of a high sensitivity microphone for a hearing aid using a graphene–PMMA laminated diaphragm. ACS Appl. Mater. Interfaces 2017, 9, 1237–1246. [Google Scholar] [CrossRef] [PubMed]
- Lee, B.; Yang, J.; Cho, J.S.; Kim, S. A Low-Power Digital Capacitive MEMS Microphone Based on a Triple-Sampling Delta-Sigma ADC With Embedded Gain. IEEE Access 2022, 10, 75323–75330. [Google Scholar] [CrossRef]
- Ceballos, J.L.; Rogi, C.; Ciciotti, F.; Buffa, C.; Straeussnigg, D.; Wiesbauer, A. A 69 dBA–730 µW Silicon Microphone System with Ultra & Infra-Sound Robustness. In Proceedings of the ESSCIRC 2022-IEEE 48th European Solid State Circuits Conference (ESSCIRC), Milan, Italy, 19–22 September 2022; pp. 409–412. [Google Scholar]
- Prasad, M.; Khanna, V.K. Development of MEMS acoustic sensor with microtunnel for high SPL measurement. IEEE Trans. Ind. Electron. 2021, 69, 3142–3150. [Google Scholar] [CrossRef]
- Ali, W.R.; Prasad, M. Design and fabrication of piezoelectric MEMS sensor for acoustic measurements. Silicon 2022, 14, 6737–6747. [Google Scholar] [CrossRef]
- Lang, C.H.; Fang, J.; Shao, H.; Ding, X.; Lin, T. High-sensitivity acoustic sensors from nanofibre webs. Nat. Commun. 2016, 7, 11108. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reger, R.W.; Clews, P.J.; Bryan, G.M.; Keane, C.A.; Henry, M.D.; Griffin, B.A. Aluminum Nitride Piezoelectric Microphones as Zero-Power Passive Acoustic Filters. In Proceedings of the 2017 19th International Conference on Solid-State Sensors, Actuators and Microsystems (TRANSDUCERS), Kaohsiung, Taiwan, 18–22 June 2017; pp. 2207–2210. [Google Scholar]
- Pinrod, V.; Ying, R.; Ou, C.; Ruyack, A.; Davaji, B.; Molnar, A.; Lal, A. Zero Power, Tunable Resonant Microphone With Nanowatt Classifier for Wake-Up Sensing. In Proceedings of the 2018 IEEE SENSORS, New Delhi, India, 28–31 October 2018; pp. 1–4. [Google Scholar]
- Baumgartel, L.; Vafanejad, A.; Chen, S.-J.; Kim, E.S. Resonance-enhanced piezoelectric microphone array for broadband or prefiltered acoustic sensing. J. Microelectromech. Syst. 2012, 22, 107–114. [Google Scholar] [CrossRef]
- Zhang, Y.; Bauer, R.; Windmill, J.F.; Uttamchandani, D. Multi-Band Asymmetric Piezoelectric MEMS Microphone Inspired by the Ormia ochracea. In Proceedings of the2016 IEEE 29th International Conference on Micro Electro Mechanical Systems (MEMS), Shanghai, China, 24–28 January 2016; pp. 1114–1117. [Google Scholar]
- Wang, H.S.; Hong, S.K.; Han, J.H.; Jung, Y.H.; Jeong, H.K.; Im, T.H.; Jeong, C.K.; Lee, B.-Y.; Kim, G.; Yoo, C.D. Biomimetic and flexible piezoelectric mobile acoustic sensors with multiresonant ultrathin structures for machine learning biometrics. Sci. Adv. 2021, 7, eabe5683. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, X.; Fernando, S.N.; Chai, K.T.; Gu, Y. AlN-on-SOI platform-based micro-machined hydrophone. Appl. Phys. Lett. 2016, 109, 032902. [Google Scholar] [CrossRef]
- Xu, J.; Chai, K.T.-C.; Wu, G.; Han, B.; Wai, E.L.-C.; Li, W.; Yeo, J.; Nijhof, E.; Gu, Y. Low-cost, tiny-sized MEMS hydrophone sensor for water pipeline leak detection. IEEE Trans. Ind. Electron. 2018, 66, 6374–6382. [Google Scholar] [CrossRef]
- Jia, L.; Shi, L.; Liu, C.; Yao, Y.; Sun, C.; Wu, G. Design and characterization of an aluminum nitride-based MEMS hydrophone with biologically honeycomb architecture. IEEE Trans. Electron. Dev. 2021, 68, 4656–4663. [Google Scholar] [CrossRef]
- Bernstein, J.J.; Bancu, M.G.; Cook, E.H.; Duwel, A.E.; Elliott, R.D.; Gauthier, D.A.; Golmon, S.L.; LeBlanc, J.J.; Tomaino-Iannucci, M.J.; Ung, J.S. Resonant Acoustic MEMS Wake-Up Switch. J. Microelectromech. Syst. 2018, 27, 625–634. [Google Scholar] [CrossRef]
- Sharan, R.V.; Moir, T.J. An overview of applications and advancements in automatic sound recognition. Neurocomputing 2016, 200, 22–34. [Google Scholar] [CrossRef] [Green Version]
- Mitrović, D.; Zeppelzauer, M.; Breiteneder, C. Features for content-based audio retrieval. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 2010; Volume 78, pp. 71–150. [Google Scholar]
- Chu, S.; Narayanan, S.; Kuo, C.-C.J. Environmental sound recognition with time–frequency audio features. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1142–1158. [Google Scholar] [CrossRef]
- Chachada, S.; Kuo, C.-C.J. Environmental sound recognition: A survey. APSIPA Trans. Signal Inf. Process. 2014, 3, E14. [Google Scholar] [CrossRef] [Green Version]
- Zu, X.; Guo, F.; Huang, J.; Zhao, Q.; Liu, H.; Li, B.; Yuan, X. Design of an acoustic target intrusion detection system based on small-aperture microphone array. Sensors 2017, 17, 514. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giannakopoulos, T.; Pikrakis, A. Introduction to Audio Analysis: A MATLAB® Approach; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Fogel, E.; Gavish, M. Performance evaluation of zero-crossing-based bit synchronizers. IEEE Trans. Commun. 1989, 37, 663–665. [Google Scholar] [CrossRef]
- Martini, A.; Rivola, A.; Troncossi, M. Autocorrelation analysis of vibro-acoustic signals measured in a test field for water leak detection. Appl. Sci. 2018, 8, 2450. [Google Scholar] [CrossRef] [Green Version]
- Mazarakis, G.P.; Avaritsiotis, J.N. Vehicle classification in sensor networks using time-domain signal processing and neural networks. Microprocess. Microsyst. 2007, 31, 381–392. [Google Scholar] [CrossRef]
- Fourniol, M.; Gies, V.; Barchasz, V.; Kussener, E.; Barthelemy, H.; Vauché, R.; Glotin, H. Low-Power Wake-Up System Based on Frequency Analysis for Environmental Internet of Things. In Proceedings of the 2018 14th IEEE/ASME International Conference on Mechatronic and Embedded Systems and Applications (MESA), Oulu, Finland, 2–4 July 2018; pp. 1–6. [Google Scholar]
- Le, P.N.; Ambikairajah, E.; Epps, J.; Sethu, V.; Choi, E.H. Investigation of spectral centroid features for cognitive load classification. Speech Commun. 2011, 53, 540–551. [Google Scholar] [CrossRef]
- Johnston, J.D. Transform coding of audio signals using perceptual noise criteria. IEEE J. Sel. Areas Commun. 1988, 6, 314–323. [Google Scholar] [CrossRef] [Green Version]
- Tiwari, V. MFCC and its applications in speaker recognition. Int. J. Emerg. Technol. 2010, 1, 19–22. [Google Scholar]
- Sharan, R.V.; Moir, T.J. Noise robust audio surveillance using reduced spectrogram image feature and one-against-all SVM. Neurocomputing 2015, 158, 90–99. [Google Scholar] [CrossRef]
- Dennis, J.; Tran, H.D.; Li, H. Spectrogram image feature for sound event classification in mismatched conditions. IEEE Signal Process. Lett. 2010, 18, 130–133. [Google Scholar] [CrossRef]
- Sadjadi, S.O.; Hansen, J.H. Unsupervised speech activity detection using voicing measures and perceptual spectral flux. IEEE Signal Process. Lett. 2013, 20, 197–200. [Google Scholar] [CrossRef]
- Phaye, S.S.R.; Benetos, E.; Wang, Y. SubSpectralNet–Using Sub-spectrogram Based Convolutional Neural Networks for Acoustic Scene Classification. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 825–829. [Google Scholar]
- Tsalera, E.; Papadakis, A.; Samarakou, M. Monitoring, profiling and classification of urban environmental noise using sound characteristics and the KNN algorithm. Energy Rep. 2020, 6, 223–230. [Google Scholar] [CrossRef]
- Li, S.Z. Content-based audio classification and retrieval using the nearest feature line method. IEEE Trans. Speech Audio Process. 2000, 8, 619–625. [Google Scholar] [CrossRef]
- Aldarmaki, H.; Ullah, A.; Ram, S.; Zaki, N. Unsupervised automatic speech recognition: A review. Speech Commun. 2022, arXiv:2106.04897. [Google Scholar] [CrossRef]
- Manikandan, J.; Venkataramani, B. Design of a real time automatic speech recognition system using Modified One Against All SVM classifier. Microprocess. Microsyst. 2011, 35, 568–578. [Google Scholar] [CrossRef]
- Wang, Y.; Cheng, X.; Li, X.; Li, B.; Yuan, X. Powerset Fusion Network for Target Classification in Unattended Ground Sensors. IEEE Sens. J. 2021, 21, 13466–13473. [Google Scholar] [CrossRef]
- Maekaku, T.; Kida, Y.; Sugiyama, A. Simultaneous Detection and Localization of a Wake-Up Word Using Multi-Task Learning of the Duration and Endpoint. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 4240–4244. [Google Scholar]
- Han, J.H.; Bae, K.M.; Hong, S.K.; Park, H.; Kwak, J.-H.; Wang, H.S.; Joe, D.J.; Park, J.H.; Jung, Y.H.; Hur, S. Machine learning-based self-powered acoustic sensor for speaker recognition. Nano Energy 2018, 53, 658–665. [Google Scholar] [CrossRef]
- Yuan, M.; Lee, T.; Ching, P.; Zhu, Y. Speech recognition on DSP: Issues on computational efficiency and performance analysis. Microprocess. Microsyst. 2006, 30, 155–164. [Google Scholar] [CrossRef]
- Campbell, W.M. A SVM/HMM System for Speaker Recognition. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’03), Hong Kong, China, 6–10 April 2003; p. 7792224. [Google Scholar]
- Sigtia, S.; Stark, A.M.; Krstulović, S.; Plumbley, M.D. Automatic environmental sound recognition: Performance versus computational cost. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2096–2107. [Google Scholar] [CrossRef] [Green Version]
- Gavrilescu, M. Improved Automatic Speech Recognition System Using Sparse Decomposition by Basis Pursuit with Deep Rectifier Neural Networks and Compressed Sensing Recomposition of Speech Signals. In Proceedings of the2014 10th International Conference on Communications (COMM), Bucharest, Romania, 29–31 May 2014; pp. 1–6. [Google Scholar]
- Yamakawa, N.; Takahashi, T.; Kitahara, T.; Ogata, T.; Okuno, H.G. Environmental Sound Recognition for Robot Audition Using Matching-Pursuit. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Syracuse, NY, USA, 28 June–1 July 2011; pp. 1–10. [Google Scholar]
- Zhang, P.; Wei, J.; Liu, Z.; Ning, F. Abnormal Acoustic Event Detection Based on Orthogonal Matching Pursuit in Security Surveillance System. Wirel. Pers. Commun. 2020, 114, 1009–1024. [Google Scholar] [CrossRef]
- Liu, H.; Shi, J.; Huang, J.; Zhou, Q.; Wei, S.; Li, B.; Yuan, X. Single-mode wild area surveillance sensor with ultra-low power design based on microphone array. IEEE Access 2019, 7, 78976–78990. [Google Scholar] [CrossRef]
- Yang, Y.; Lee, B.; Cho, J.S.; Kim, S.; Lee, H. A Digital Capacitive MEMS Microphone for Speech Recognition With Fast Wake-Up Feature Using a Sound Activity Detector. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 1509–1513. [Google Scholar] [CrossRef]
- Oh, S.; Cho, M.; Shi, Z.; Lim, J.; Kim, Y.; Jeong, S.; Chen, Y.; Rothe, R.; Blaauw, D.; Kim, H.-S. An acoustic signal processing chip with 142-nW voice activity detection using mixer-based sequential frequency scanning and neural network classification. IEEE J. Solid-State Circuits 2019, 54, 3005–3016. [Google Scholar] [CrossRef]
- Jeong, S.; Chen, Y.; Jang, T.; Tsai, J.; Blaauw, D.; Kim, H.S.; Sylvester, D. A 12nW Always-On Acoustic Sensing and Object Recognition Microsystem Using Frequency-Domain Feature Extraction and SVM Classification. In Proceedings of the 2017 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 5–9 February 2017; p. 362. [Google Scholar]
- Mayer, P.; Magno, M.; Benini, L. Self-sustaining acoustic sensor with programmable pattern recognition for underwater monitoring. IEEE Trans. Instrum. Meas. 2019, 68, 2346–2355. [Google Scholar] [CrossRef]
- Goldberg, D.H.; Andreou, A.G.; Julian, P.; Pouliquen, P.O.; Riddle, L.; Rosasco, R. A wake-up detector for an acoustic surveillance sensor network: Algorithm and VLSI implementation. In Proceedings of the 2004 Third International Symposium on Information Processing in Sensor Networks (IPSN 2004), Berkeley, CA, USA, 27 April 2004; pp. 134–141. [Google Scholar]
- Wang, Z.; Zhang, H.; Zhang, Y.; Shen, L.; Ru, J.; Fan, H.; Tan, Z.; Wang, Y.; Ye, L.; Huang, R. A Software-Defined Always-On System with 57-75-nW Wake-Up Function Using Asynchronous Clock-Free Pipelined Event-Driven Architecture and Time-Shielding Level-Crossing ADC. IEEE J. Solid-State Circuits 2021, 56, 2804–2816. [Google Scholar] [CrossRef]
- Rekhi, A.S.; Arbabian, A. Ultrasonic wake-up with precharged transducers. IEEE J. Solid-State Circuits 2019, 54, 1475–1486. [Google Scholar] [CrossRef]
- Giraldo, J.S.P.; Lauwereins, S.; Badami, K.; Verhelst, M. Vocell: A 65-nm Speech-Triggered Wake-Up SoC for 10-$\mu $ W Keyword Spotting and Speaker Verification. IEEE J. Solid-State Circuits 2020, 55, 868–878. [Google Scholar] [CrossRef]
- Bannoura, A.; Hoflinger, F.; Gorgies, O.; Gamm, G.U.; Albesa, J.; Reindl, L.M. Acoustic Wake-Up Receivers for Home Automation Control Applications. Electronics 2016, 5, 4. [Google Scholar] [CrossRef] [Green Version]
- Pop, F.; Herrera, B.H.; Zhu, W.; Assylbekova, M.; Cassella, C.; McGruer, N.; Rinaldi, M. Zero-power acoustic wake-up receiver based on DMUT Transmitter, PMUTS arrays receivers and MEMS switches for intrabody links. In Proceedings of the 2019 20th International Conference on Solid-State Sensors, Actuators and Microsystems & Eurosensors XXXIII (TRANSDUCERS & EUROSENSORS XXXIII), Berlin, Germany, 23–27 June 2019. [Google Scholar]
- Pop, F.; Calisgan, S.D.; Herrera, B.; Risso, A.; Kang, S.; Rajaram, V.; Qian, Z.; Rinaldi, M. Zero-Power Ultrasonic Wakeup Receiver Based on MEMS Switches for Implantable Medical Devices. IEEE Trans. Electron. Dev. 2022, 69, 1327–1332. [Google Scholar] [CrossRef]
- Kaushik, B.; Nance, D.; Ahuja, K. A Review of the Role of Acoustic Sensors in the Modern Battlefield. In Proceedings of the 11th AIAA/CEAS Aeroacoustics Conference, Monterey, CA, USA, 23–25 May 2005; p. 2997. [Google Scholar]
- Zhao, Q.; Guo, F.; Zu, X.; Li, B.; Yuan, X. An acoustic-based feature extraction method for the classification of moving vehicles in the wild. IEEE Access 2019, 7, 73666–73674. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Guo, F.; Zhou, Q.; Liu, H.; Li, B. Design of an acoustic target classification system based on small-aperture microphone array. IEEE Trans. Instrum. Meas. 2014, 64, 2035–2043. [Google Scholar] [CrossRef]
- Ghiurcau, M.V.; Rusu, C.; Bilcu, R.C.; Astola, J. Audio based solutions for detecting intruders in wild areas. Signal Process. 2012, 92, 829–840. [Google Scholar] [CrossRef]
- Yu, Z.-J.; Dong, S.-L.; Wei, J.-M.; Xing, T.; Liu, H.-T. Neural Network Aided Unscented Kalman Filter for Maneuvering Target Tracking in Distributed Acoustic Sensor Networks. In Proceedings of the 2007 International Conference on Computing: Theory and Applications (ICCTA’07), Kolkata, India, 5–7 March 2007; pp. 245–249. [Google Scholar]
- Höflinger, F.; Hoppe, J.; Zhang, R.; Ens, A.; Reindl, L.; Wendeberg, J.; Schindelhauer, C. Acoustic Indoor-Localization System for Smart Phones. In Proceedings of the 2014 IEEE 11th International Multi-Conference on Systems, Signals & Devices (SSD14), Barcelona, Spain, 11–14 February 2014; pp. 1–4. [Google Scholar]
- Xiong, C.; Lu, W.; Zhao, X.; You, Z. Miniaturized multi-topology acoustic source localization network based on intelligent microsystem. Sens. Actuators A Phys. 2022, 345, 113746. [Google Scholar] [CrossRef]
- Behnia, A.; Chai, H.K.; Shiotani, T. Advanced structural health monitoring of concrete structures with the aid of acoustic emission. Constr. Build. Mater. 2014, 65, 282–302. [Google Scholar] [CrossRef]
- Baifeng, J.; Weilian, Q. The Research of Acoustic Emission Techniques for Non Destructive Testing and Health Monitoring on Civil Engineering Structures. In Proceedings of the 2008 International Conference on Condition Monitoring and Diagnosis, Beijing, China, 21–24 April 2008; pp. 782–785. [Google Scholar]
- Li, S.-H.; Lin, B.-S.; Tsai, C.-H.; Yang, C.-T.; Lin, B.-S. Design of wearable breathing sound monitoring system for real-time wheeze detection. Sensors 2017, 17, 171. [Google Scholar] [CrossRef] [Green Version]
- Istrate, D.; Castelli, E.; Vacher, M.; Besacier, L.; Serignat, J.-F. Information extraction from sound for medical telemonitoring. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 264–274. [Google Scholar] [CrossRef] [Green Version]
- Shkel, A.A.; Kim, E.S. Wearable Low-Power Wireless Lung Sound Detection Enhanced by Resonant Transducer Array for Pre-Filtered Signal Acquisition. In Proceedings of the 2017 19th International Conference on Solid-State Sensors, Actuators and Microsystems (TRANSDUCERS), Kaohsiung, Taiwan, 20–24 June 2021; pp. 842–845. [Google Scholar]
- Nystuen, J.A.; Selsor, H.D. Weather classification using passive acoustic drifters. J. Atmos. Ocean. Technol. 1997, 14, 656–666. [Google Scholar] [CrossRef]
- Baker, D.M.; Davies, K. F2-region acoustic waves from severe weather. J. Atmos. Terr. Phys. 1969, 31, 1345–1352. [Google Scholar] [CrossRef]
- Doohan, B.; Fuller, S.; Parsons, S.; Peterson, E. The sound of management: Acoustic monitoring for agricultural industries. Ecol. Indic. 2019, 96, 739–746. [Google Scholar] [CrossRef]
- Azfar, S.; Nadeem, A.; Alkhodre, A.; Ahsan, K.; Mehmood, N.; Alghmdi, T.; Alsaawy, Y. Monitoring, detection and control techniques of agriculture pests and diseases using wireless sensor network: A review. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 12. [Google Scholar] [CrossRef] [Green Version]
- Budka, M.; Jobda, M.; Szałański, P.; Piórkowski, H. Acoustic approach as an alternative to human-based survey in bird biodiversity monitoring in agricultural meadows. PLoS ONE 2022, 17, e0266557. [Google Scholar] [CrossRef] [PubMed]
- Shorten, P.R.; Welten, B.G. An acoustic sensor technology to detect urine excretion. Biosyst. Eng. 2022, 214, 90–106. [Google Scholar] [CrossRef]
- Marzetti, S.; Gies, V.; Barchasz, V.; Best, P.; Paris, S.; Barthelemy, H.; Glotin, H. Ultra-Low Power Wake-Up for Long-Term Biodiversity Monitorin. In Proceedings of the 2020 IEEE International Conference on Internet of Things and Intelligence System (IoTaIS), Bali, Indonesia, 27–28 January 2021; pp. 188–193. [Google Scholar]
- Buxton, R.T.; McKenna, M.F.; Clapp, M.; Meyer, E.; Stabenau, E.; Angeloni, L.M.; Crooks, K.; Wittemyer, G. Efficacy of extracting indices from large-scale acoustic recordings to monitor biodiversity. Conserv. Biol. 2018, 32, 1174–1184. [Google Scholar] [CrossRef]
- Desjonquères, C.; Gifford, T.; Linke, S. Passive acoustic monitoring as a potential tool to survey animal and ecosystem processes in freshwater environments. Freshw. Biol. 2020, 65, 7–19. [Google Scholar] [CrossRef] [Green Version]
- Harris III, A.F.; Stojanovic, M.; Zorzi, M. Idle-time energy savings through wake-up modes in underwater acoustic networks. Ad Hoc Netw. 2009, 7, 770–777. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Li, H.; Xie, Y.; Hu, X.; Fu, L. Channel-adaptive location-assisted wake-up signal detection approach based on LFM over underwater acoustic channels. IEEE Access 2019, 7, 93806–93819. [Google Scholar] [CrossRef]
- Su, R.; Gong, Z.; Zhang, D.; Li, C.; Chen, Y.; Venkatesan, R. An adaptive asynchronous wake-up scheme for underwater acoustic sensor networks using deep reinforcement learning. IEEE Trans. Veh. Technol. 2021, 70, 1851–1865. [Google Scholar] [CrossRef]
- Qu, B.; Zhang, L.; He, W.; Zhang, T.; Feng, X. LOS Acoustic Signal Recognition Indoor Based on the Dynamic Online Training. In Proceedings of the 2022 IEEE/CIC International Conference on Communications in China (ICCC), Foshan, China, 11–13 August 2022; pp. 280–285. [Google Scholar]
- Abu-El-Quran, A.R.; Goubran, R.A.; Chan, A.D. Security monitoring using microphone arrays and audio classification. IEEE Trans. Instrum. Meas. 2006, 55, 1025–1032. [Google Scholar] [CrossRef]
- Mielke, M.; Schäfer, A.; Brück, R. Integrated Circuit for Detection of Acoustic Emergency Signals in Road Traffic. In Proceedings of the 17th International Conference Mixed Design of Integrated Circuits and Systems-MIXDES 2010, Wroclaw, Poland, 24–26 June 2010; pp. 562–565. [Google Scholar]
- Lawson, A.; Vabishchevich, P.; Huggins, M.; Ardis, P.; Battles, B.; Stauffer, A. Survey and Evaluation of Acoustic Features for Speaker Recognition. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 5444–5447. [Google Scholar]
- Lin, Z.; Zhang, G.; Xiao, X.; Au, C.; Zhou, Y.; Sun, C.; Zhou, Z.; Yan, R.; Fan, E.; Si, S. A personalized acoustic interface for wearable human–machine interaction. Adv. Funct. Mater. 2022, 32, 2109430. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Principle | Main Structure and Material | Power Consumption | Size | Frequency Range (Hz) | Resonant Frequency (Hz) | Sensitivity | SNR | Year | Ref. |
|---|---|---|---|---|---|---|---|---|---|---|
| MEMS microphone | Capacitive | Compliant membrane | - | 2.6 × 3.2 × 0.865 mm3 | 20–20,000 | 24.15 k | - | 65.6 dB | 2009 | [11] |
| Capacitive | Corrugated diaphragm | 1.2 mW | 2.35 × 1.65 × 1.2 mm3 | 100–10,000 | - | 7.9 mV/Pa | 55 dB | 2011 | [12] | |
| Capacitive | Planar interdigitated | - | Φ600 μm2 | 1000–20,000 | - | 0.99 mV/Pa | - | 2015 | [13] | |
| Capacitive | Perforated diaphragm | - | 0.3 × 0.3 mm2 | 1–20,000 | 60 k | 2.46 mV/Pa | - | 2018 | [14] | |
| Capacitive | Graphene−PMMA diaphragm | - | Φ4 × 3.2 mm3 | 0–10,000 | 7 k | 100 mV/Pa | 20 dB | 2017 | [15] | |
| Capacitive | Triple-sampling ADC | 0.936 mW | 0.98 mm2 | 20–20,000 | - | 38.0 mV/Pa | 62.1 dBA | 2022 | [16] | |
| Capacitive | Differential circuits | 730 μW | 1.13 mm2 | - | - | - | 69 dBA | 2022 | [17] | |
| Piezoelectric | ZnO film | - | 3 × 3 mm2 | 30–8000 | 42.875 k | 320.1 μV/Pa | - | 2021 | [18] | |
| Piezoelectric | ZnO film | - | 1.5 × 1.5 mm2 | 48–54,000 | 99.6 k | 130 μV/Pa | - | 2022 | [19] | |
| Piezoelectric | Piezoelectric nanofiber | - | - | 400–1500 | - | 266 mV/Pa | - | 2016 | [20] | |
| Piezoelectric | AlN diagram | 0 | - | - | 0.43 k–10 k | 600 mV/Pa | - | 2017 | [21] | |
| Piezoelectric | PZT spiral | 0 | 3.2 × 2.2 × 1 cm3 | - | >25.2 | 12.6 V/Pa | - | 2018 | [22] | |
| Piezoelectric | ZnO film | - | 4 × 11 mm2 | 240–6500 | 0.86 k–6.263 k | 2.5–202.6 mV/Pa | - | 2012 | [23] | |
| Piezoelectric | AlN cantilevers | - | 5.5 × 5.5 mm2 | - | 2.4 k, 4.9 k, 8.0 k, 11.0 k | 19.7 mV/Pa | - | 2016 | [24] | |
| Piezoelectric | PZT membrane | - | 1 × 2.5 cm2 | - | 0.1 k–4 k | 103 mV/Pa | 92 dB | 2021 | [25] | |
| MEMS hydrophone | Piezoelectric | AlN film | - | Φ1.2 × 2.5 cm3 | 10–8000 | - | 1 μV/Pa | 60 dB | 2018 | [26] |
| Piezoelectric | AlN film | 4.5 mW | 1.5 × 0.8 × 2 cm3 | 10–50,000 | 1.26 μV/Pa | 58.7 dB | 2021 | [27] | ||
| MEMS acoustic switch | Resonant | Rotational Paddle | 0 | ≤15 cm3 | - | 62.7–80 | 0.005 Pa (threshold) | - | 2018 | [28] |
| Type | Classifier | Computation | Accuracy |
|---|---|---|---|
| Linear classification | Threshold-based | ★ | ★ |
| k-NN | ★☆ | ★☆ | |
| NFL | ★★ | ★★ | |
| Nonlinear machine learning classification | SVM | ★★★ | ★★★ |
| NN | ★★★★ | ★★★★ | |
| GMM | ★★★☆ | ★★★☆ | |
| HMM-based | ★★★★☆ | ★★★★☆ |
| System Architecture | Acoustic Recognition | Target | Size | Sleep Power Consumption | Accuracy | False Alarm | Year | Ref. | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Feature | Classifier | Wake-Up Module | Back-End Module | Total | |||||||
| Architecture 1 | Spectral correlation | Threshold and GMM | Truck, wheeled vehicle, tracked vehicle | Φ50 × 130 mm3 | - | - | 13.8 mW | 92.6% | <5% | 2019 | [61] |
| Amplitude envelope | Threshold | Voice-band | - | 8.25 μW | 44.55 μW | 52.8 μW | - | - | 2020 | [62] | |
| Sub-spectrum amplitude | NN | Speech/non-speech | 4.5 × 3.9 mm2 | 66 nW | 76 nW | 142 nW | >90% | - | 2019 | [63] | |
| Spectrum amplitude, average power | SVM | Generator, truck, car | 2.15 × 1.6 mm2 | - | - | 12 nW | >95% | - | 2017 | [64] | |
| Spectrogram | ML | Submarine, ship, rain, surface ice | - | 26.89 μW | 35.11 μW | 62 μW | 95.89% | - | 2019 | [65] | |
| Autocorrelation | Threshold | Wheeled vehicle, tracked vehicle | 3 × 1.5 mm2 | 305.5 μW | - | - | - | - | 2004 * | [66] | |
| Amplitude, slope | Threshold | Heart rate, epilepsy, keyword | - | 75 nW | - | - | - | - | 2021 * | [67] | |
| Envelope | Threshold | Ultrasonic signal | 14.5 mm2 | 8 nW | - | - | - | - | 2019 * | [68] | |
| Sub-spectrum energy | Threshold | Generator, truck | 3.2 × 2.2 × 1 cm3 | 6 nW | - | - | 100% | 1/h | 2018 * | [22] | |
| Power, MFCCs | GMM, NN | Keyword spotting | 2 × 2 mm2 | 10.6 μW | - | - | >94% | - | 2020 * | [69] | |
| Architecture 2 | Sub-spectrum energy | Threshold | Generator, truck | - | <1 nW | - | - | 100% | 0 | 2018 * | [28] |
| Architecture 3 | Sub-spectrum energy | Threshold | Ultrasonic signal | - | 420 μW | 0 | 420 μW | - | - | 2016 * | [70] |
| Architecture 4 | Sub-spectrum energy | Threshold | Fixed frequency ultrasound | - | 0 | <10 nW | <10 nW | - | - | 2022 | [71] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, D.; Zhao, J. Acoustic Wake-Up Technology for Microsystems: A Review. Micromachines 2023, 14, 129. https://doi.org/10.3390/mi14010129
Yang D, Zhao J. Acoustic Wake-Up Technology for Microsystems: A Review. Micromachines. 2023; 14(1):129. https://doi.org/10.3390/mi14010129
Chicago/Turabian StyleYang, Deng, and Jiahao Zhao. 2023. "Acoustic Wake-Up Technology for Microsystems: A Review" Micromachines 14, no. 1: 129. https://doi.org/10.3390/mi14010129
APA StyleYang, D., & Zhao, J. (2023). Acoustic Wake-Up Technology for Microsystems: A Review. Micromachines, 14(1), 129. https://doi.org/10.3390/mi14010129