
Automated Industrial Composite Fiber Orientation Inspection Using Attention-Based Normalized Deep Hough Network


Abstract
:1. Introduction
2. Related Work
2.1. Statistical Methods
2.2. Spectral Methods
2.3. Structural and Deep Learning Methods
3. Materials and Methods
3.1. Composite Specimen and Image Acquisition
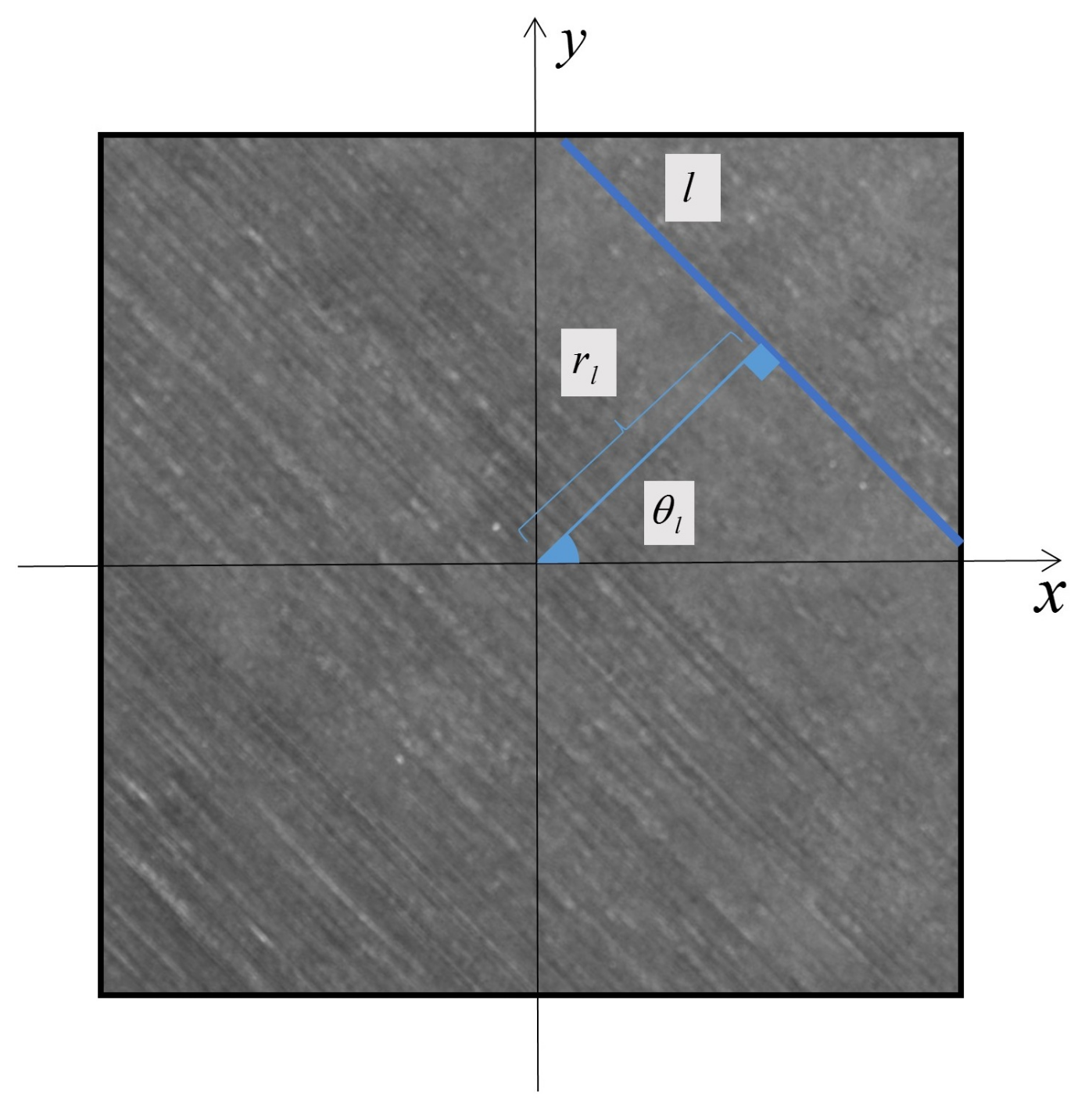
3.2. Preliminaries
3.3. Attention-Based Normalized Deep Hough Network
3.3.1. Encoder Network
3.3.2. Attention Network
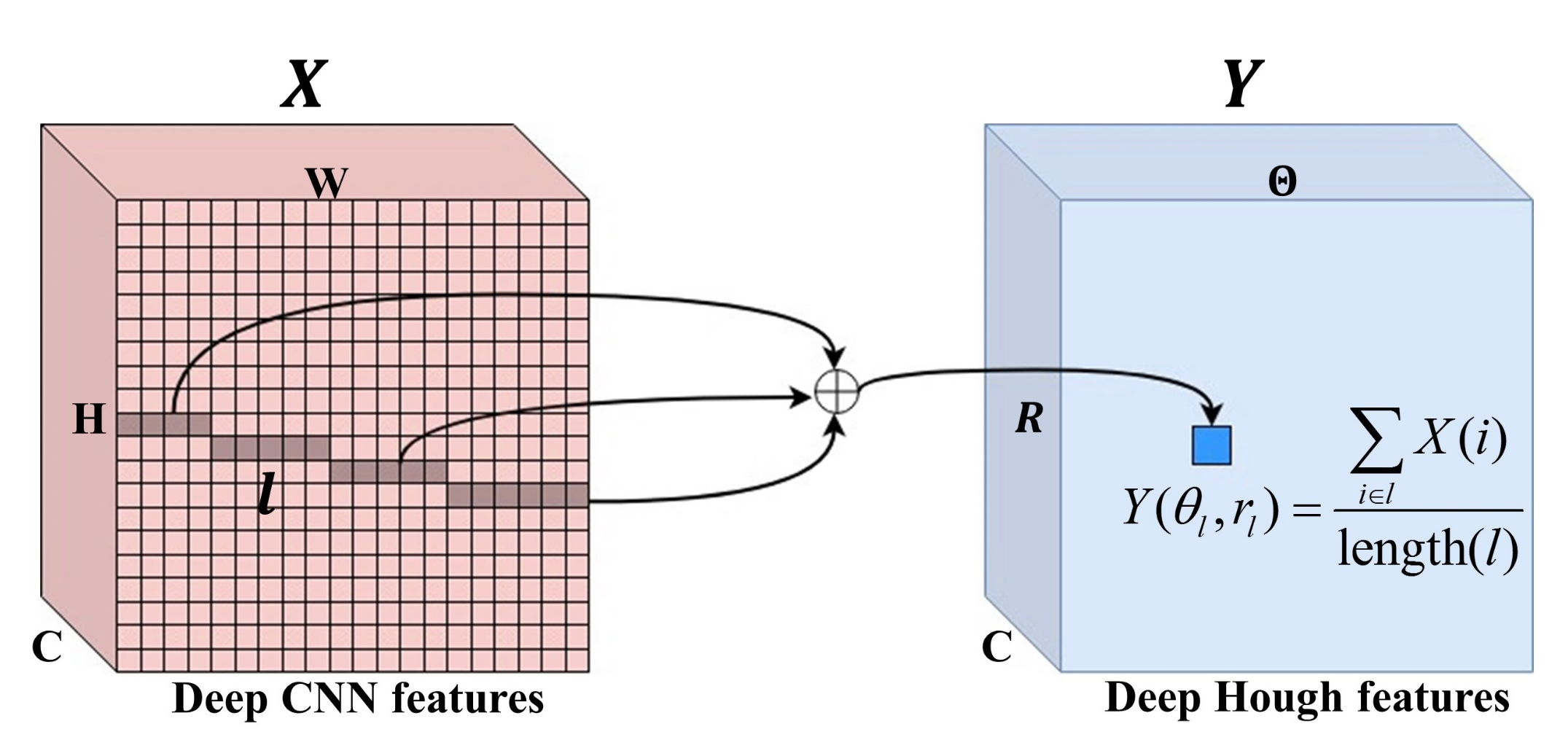
3.3.3. Feature Transformation with Normalized Deep Hough Transform
3.3.4. Orientation Measurement Module
3.3.5. Loss Function
4. Experiments
4.1. Experimental Setups
4.1.1. Evaluation Metric
4.1.2. Implementation Details
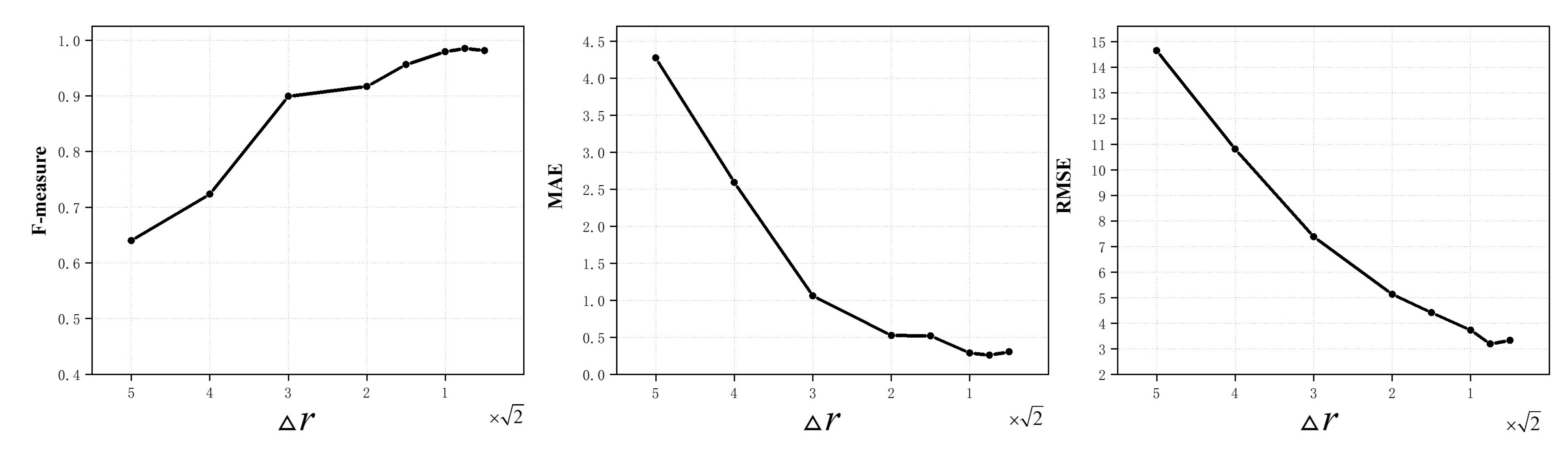
4.2. Quantization Interval Tunings
4.3. Comparison with the State-of-the-Art Methods
4.3.1. Comparison of the Evaluation Metrics
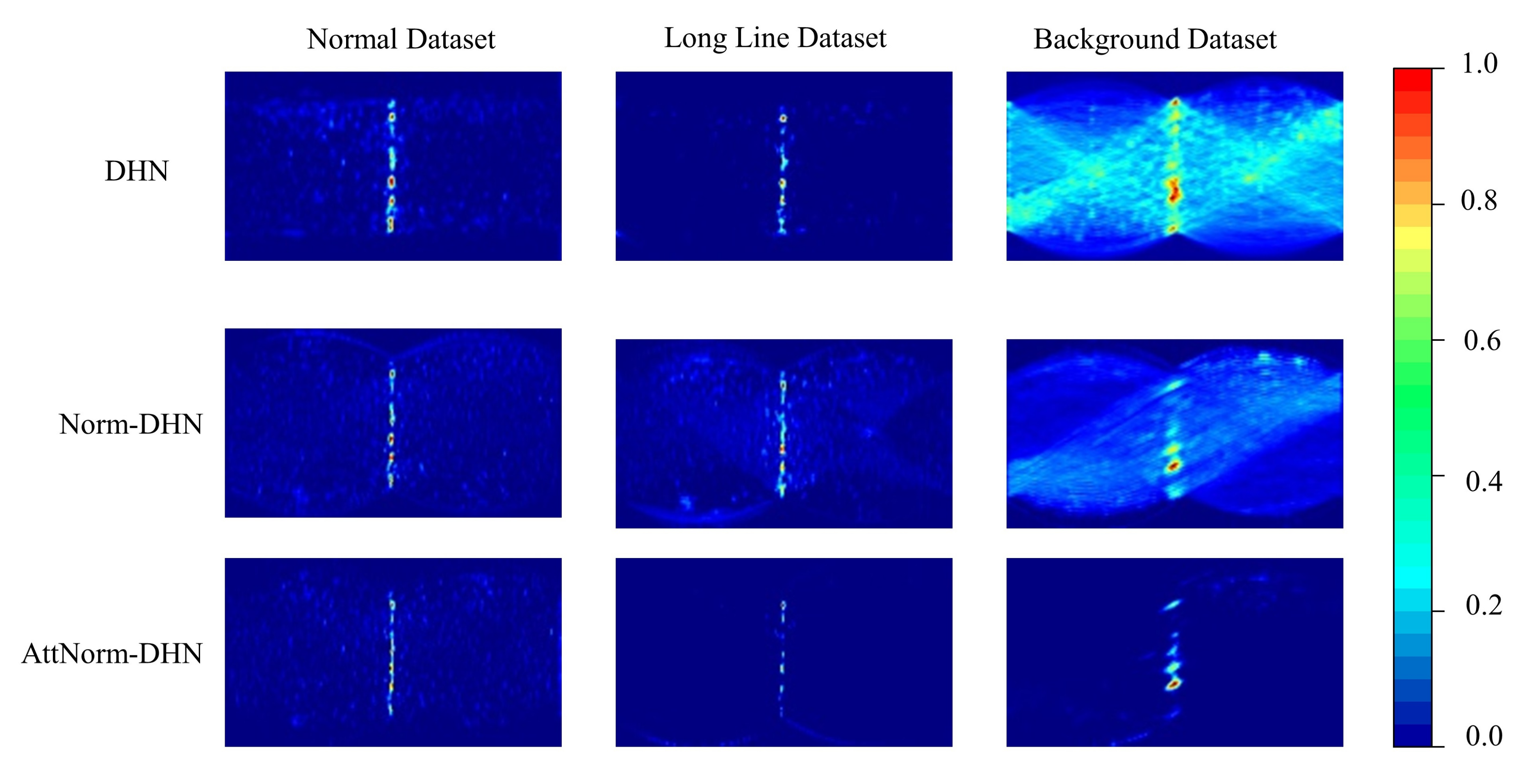
4.3.2. Comparison of the Final Hough Space
4.4. Importance of Deep Hough Normalization for Attention
4.5. Weakly Supervised Semantic Segmentation
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jiao, J.; Cheng, X.; Wang, J.; Sheng, L.; Zhang, Y.; Xu, J.; Jing, C.; Sun, S.; Xia, H.; Ru, H. A Review of Research Progress on Machining Carbon Fiber-Reinforced Composites with Lasers. Micromachines 2023, 14, 24. [Google Scholar] [CrossRef]
- Vallons, K.; Duque, I.; Lomov, S.; Verpoest, I. Fibre orientation effects on the tensile properties of biaxial carbon/epoxy NCF composites. In Proceedings of the ICCM International Conference on Composite Materials, Edinburgh, UK, 27–31 July 2009; pp. 27–31. [Google Scholar]
- Wang, B.; Zhong, S.; Lee, T.L.; Fancey, K.S.; Mi, J. Non-destructive testing and evaluation of composite materials/structures: A state-of-the-art review. Adv. Mech. Eng. 2020, 12, 1687814020913761. [Google Scholar] [CrossRef]
- Albano, C.; Camacho, N.; Reyes, J.; Feliu, J.; Hernández, M. Influence of scrap rubber addition to Portland I concrete composites: Destructive and non-destructive testing. Compos. Struct. 2005, 71, 439–446. [Google Scholar] [CrossRef]
- Şerban, A. Automatic detection of fiber orientation on CF/PPS composite materials with 5-harness satin weave. Fibers Polym. 2016, 17, 1925–1933. [Google Scholar] [CrossRef]
- Yang, X.; Ju, B.; Kersemans, M. Ultrasonic tomographic reconstruction of local fiber orientation in multi-layer composites using Gabor filter-based information diagram method. NDT E Int. 2021, 124, 102545. [Google Scholar] [CrossRef]
- Emerson, M.J.; Jespersen, K.M.; Dahl, A.B.; Conradsen, K.; Mikkelsen, L.P. Individual fibre segmentation from 3D X-ray computed tomography for characterising the fibre orientation in unidirectional composite materials. Compos. Part A Appl. Sci. Manuf. 2017, 97, 83–92. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, Z.; Yin, W.; Chen, H.; Liu, Y. Defect Detection Method for CFRP Based on Line Laser Thermography. Micromachines 2022, 13, 612. [Google Scholar] [CrossRef]
- Fujita, R.; Nagano, H. Novel fiber orientation evaluation method for CFRP/CFRTP based on measurement of anisotropic in-plane thermal diffusivity distribution. Compos. Sci. Technol. 2017, 140, 116–122. [Google Scholar] [CrossRef]
- Zhou, J.; Du, W.; Yang, L.; Deng, K.; Addepalli, S.; Zhao, Y. Pattern recognition of barely visible impact damage in carbon composites using pulsed thermography. IEEE Trans. Ind. Inform. 2021, 18, 7252–7261. [Google Scholar] [CrossRef]
- Zhao, K.; Han, Q.; Zhang, C.B.; Xu, J.; Cheng, M.M. Deep Hough Transform for Semantic Line Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4793–4806. [Google Scholar] [CrossRef]
- Lin, Y.; Pintea, S.L.; van Gemert, J.C. Deep hough-transform line priors. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Proceedings, Part XXII 16, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 323–340. [Google Scholar] [CrossRef]
- Zambal, S.; Palfinger, W.; Stöger, M.; Eitzinger, C. Accurate fibre orientation measurement for carbon fibre surfaces. Pattern Recognit. 2015, 48, 3324–3332. [Google Scholar] [CrossRef]
- Krieger Lassen, N. Automatic localisation of electron backscattering pattern bands from Hough transform. Mater. Sci. Technol. 1996, 12, 837–843. [Google Scholar] [CrossRef]
- Fitton, N.; Cox, S. Optimising the application of the Hough transform for automatic feature extraction from geoscientific images. Comput. Geosci. 1998, 24, 933–951. [Google Scholar] [CrossRef]
- Karamov, R.; Martulli, L.M.; Kerschbaum, M.; Sergeichev, I.; Swolfs, Y.; Lomov, S.V. Micro-CT based structure tensor analysis of fibre orientation in random fibre composites versus high-fidelity fibre identification methods. Compos. Struct. 2020, 235, 111818. [Google Scholar] [CrossRef]
- Nelson, L.; Smith, R.; Mienczakowski, M. Ply-orientation measurements in composites using structure-tensor analysis of volumetric ultrasonic data. Compos. Part A Appl. Sci. Manuf. 2018, 104, 108–119. [Google Scholar] [CrossRef]
- Zheng, G.; Li, X.; Zhou, L.; Yang, J.; Ren, L.; Chen, P.; Zhang, H.; Lou, X. Development of a gray-level co-occurrence matrix-based texture orientation estimation method and its application in sea surface wind direction retrieval from SAR imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5244–5260. [Google Scholar] [CrossRef]
- AlShehri, H.; Hussain, M.; Aboalsamh, H.A.; Emad-ul Haq, Q.; AlZuair, M.; Azmi, A.M. Alignment-free cross-sensor fingerprint matching based on the co-occurrence of ridge orientations and Gabor-HoG descriptor. IEEE Access 2019, 7, 86436–86452. [Google Scholar] [CrossRef]
- Baranowski, T.; Dobrovolskij, D.; Dremel, K.; Hölzing, A.; Lohfink, G.; Schladitz, K.; Zabler, S. Local fiber orientation from X-ray region-of-interest computed tomography of large fiber reinforced composite components. Compos. Sci. Technol. 2019, 183, 107786. [Google Scholar] [CrossRef]
- Pinter, P.; Dietrich, S.; Bertram, B.; Kehrer, L.; Elsner, P.; Weidenmann, K. Comparison and error estimation of 3D fibre orientation analysis of computed tomography image data for fibre reinforced composites. NDT E Int. 2018, 95, 26–35. [Google Scholar] [CrossRef]
- Bardl, G.; Nocke, A.; Cherif, C.; Pooch, M.; Schulze, M.; Heuer, H.; Schiller, M.; Kupke, R.; Klein, M. Automated detection of yarn orientation in 3D-draped carbon fiber fabrics and preforms from eddy current data. Compos. Part B Eng. 2016, 96, 312–324. [Google Scholar] [CrossRef]
- Brandley, E.; Greenhalgh, E.S.; Shaffer, M.S.; Li, Q. Mapping carbon nanotube orientation by fast fourier transform of scanning electron micrographs. Carbon 2018, 137, 78–87. [Google Scholar] [CrossRef]
- Hughes, R.; Drinkwater, B.; Smith, R. Characterisation of carbon fibre-reinforced polymer composites through radon-transform analysis of complex eddy-current data. Compos. Part B Eng. 2018, 148, 252–259. [Google Scholar] [CrossRef]
- Legaz-Aparicio, Á.G.; Verdú-Monedero, R.; Engan, K. Noise robust and rotation invariant framework for texture analysis and classification. Appl. Math. Comput. 2018, 335, 124–132. [Google Scholar] [CrossRef]
- Lefebvre, A.; Corpetti, T.; Moy, L.H. Estimation of the orientation of textured patterns via wavelet analysis. Pattern Recognit. Lett. 2011, 32, 190–196. [Google Scholar] [CrossRef]
- Sabiston, T.; Inal, K.; Lee-Sullivan, P. Application of Artificial Neural Networks to predict fibre orientation in long fibre compression moulded composite materials. Compos. Sci. Technol. 2020, 190, 108034. [Google Scholar] [CrossRef]
- Bleiziffer, P.; Hofmann, J.; Zboray, R.; Wiege, T.; Herger, R. Predicting the fiber orientation in glass fiber reinforced polymers using the moment of inertia and convolutional neural networks. Eng. Appl. Artif. Intell. 2021, 104, 104351. [Google Scholar] [CrossRef]
- Kociołek, M.; Kozłowski, M.; Cardone, A. A Convolutional Neural Networks-Based Approach for Texture Directionality Detection. Sensors 2022, 22, 562. [Google Scholar] [CrossRef]
- Schmitt, R.; Fürtjes, T.; Abbas, B.; Abel, P.; Kimmelmann, W.; Kosse, P.; Buratti, A. Real-Time Machine Vision System for an Automated Quality Monitoring in Mass Production of Multiaxial Non-Crimp Fabrics. IFAC-PapersOnLine 2015, 48, 2393–2398. [Google Scholar] [CrossRef]
- Holder, D.; Buser, M.; Boley, S.; Weber, R.; Graf, T. Image processing based detection of the fibre orientation during depth-controlled laser ablation of CFRP monitored by optical coherence tomography. Mater. Des. 2021, 203, 109567. [Google Scholar] [CrossRef]
- Nelson, L.; Smith, R. Fibre direction and stacking sequence measurement in carbon fibre composites using Radon transforms of ultrasonic data. Compos. Part A Appl. Sci. Manuf. 2019, 118, 1–8. [Google Scholar] [CrossRef]
- Palmer, P.L.; Kittler, J.; Petrou, M. Using focus of attention with the Hough transform for accurate line parameter estimation. Pattern Recognit. 1994, 27, 1127–1134. [Google Scholar] [CrossRef]
- Meister, S.; Möller, N.; Stüve, J.; Groves, R.M. Synthetic image data augmentation for fibre layup inspection processes: Techniques to enhance the data set. J. Intell. Manuf. 2021, 32, 1767–1789. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 315–323. [Google Scholar]
- Nagi, J.; Ducatelle, F.; Di Caro, G.A.; Cireşan, D.; Meier, U.; Giusti, A.; Nagi, F.; Schmidhuber, J.; Gambardella, L.M. Max-pooling convolutional neural networks for vision-based hand gesture recognition. In Proceedings of the 2011 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 16–18 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 342–347. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Proceedings, Part III 18, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Zhang, B.; Xiao, J.; Wei, Y.; Huang, K.; Luo, S.; Zhao, Y. End-to-end weakly supervised semantic segmentation with reliable region mining. Pattern Recognit. 2022, 128, 108663. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operation | Activation Function | Output Shape |
|---|---|---|
| Input image | 1 × 200 × 200 | |
| Conv 3 × 3 | ReLU | 64 × 200 × 200 |
| Conv 3 × 3 | ReLU | 64 × 200 × 200 |
| Maxpool 2 × 2 | 64 × 100 × 100 | |
| Conv 3 × 3 | ReLU | 128 × 100 × 100 |
| Conv 3 × 3 | ReLU | 128 × 100 × 100 |
| Conv 1 × 1 | ReLU | 64 × 100 × 100 |
| Operation | Activation Function | Output Shape |
|---|---|---|
| Input image | 1 × 200 × 200 | |
| Conv 3 × 3 | ReLU | 64 × 200 × 200 |
| Conv 3 × 3 | ReLU | 64 × 200 × 200 |
| Maxpool 2 × 2 | 64 × 100 × 100 | |
| Conv 3 × 3 | ReLU | 128 × 100 × 100 |
| Conv 3 × 3 | ReLU | 128 × 100 × 100 |
| Maxpool 2 × 2 | 128 × 50 × 50 | |
| Conv 3 × 3 | ReLU | 256 × 50 × 50 |
| Conv 3 × 3 | ReLU | 256 × 50 × 50 |
| Maxpool 2 × 2 | 256 × 25 × 25 | |
| Conv 3 × 3 | ReLU | 512 × 25 × 25 |
| Conv 3 × 3 | ReLU | 512 × 25 × 25 |
| Upsample 2 × 2 | 512 × 50 × 50 | |
| Conv 3 × 3 | ReLU | 256 × 50 × 50 |
| Conv 3 × 3 | ReLU | 256 × 50 × 50 |
| Upsample 2 × 2 | 256 × 100 × 100 | |
| Conv 3 × 3 | ReLU | 128 × 100 × 100 |
| Conv 3 × 3 | ReLU | 128 × 100 × 100 |
| Conv 1 × 1 | ReLU | 1 × 100 × 100 |
| Operation | Activation Function | Output Shape |
|---|---|---|
| Input features | 64 × 100 × 100 | |
| Norm-DHT | 64 × 101 × 180 | |
| Conv 3 × 3 | ReLU | 64 × 101 × 180 |
| Conv 3 × 3 | ReLU | 64 × 101 × 180 |
| Conv 1 × 1 | ReLU | 1 × 101 × 180 |
| Method | Normal Dataset | Longline Dataset | Background Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F-Measure | MAE | RMSE | F-Measure | MAE | RMSE | F-Measure | MAE | RMSE | |
| Canny+HT [31] | 0.705 | 1.997 | 9.711 | 0.0158 | 5.993 | 6.883 | 0.193 | 26.651 | 39.458 |
| DHN [11] | 0.981 | 0.018 | 0.137 | 0.97 | 0.689 | 6.49 | 0.714 | 4.122 | 14.568 |
| Norm-DHN | 0.986 | 0.022 | 0.676 | 0.984 | 0.015 | 0.126 | 0.767 | 2.191 | 10.502 |
| AttNorm-DHN | 0.990 | 0.07 | 2.102 | 0.981 | 0.241 | 3.167 | 0.855 | 0.239 | 2.401 |
| Method | F-Measure | MAE | RMSE |
|---|---|---|---|
| DHN [11] | 0.714 | 4.122 | 14.568 |
| Att-DHN | 0.824 | 0.468 | 4.23 |
| AttNorm-DHN | 0.855 | 0.239 | 2.401 |
| Method | IOU | PA |
|---|---|---|
| U-Net [37] | 0.994 | 0.986 |
| AttNorm-DHN | 0.941 | 0.863 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Zhang, Y.; Liang, W. Automated Industrial Composite Fiber Orientation Inspection Using Attention-Based Normalized Deep Hough Network. Micromachines 2023, 14, 879. https://doi.org/10.3390/mi14040879
Xu Y, Zhang Y, Liang W. Automated Industrial Composite Fiber Orientation Inspection Using Attention-Based Normalized Deep Hough Network. Micromachines. 2023; 14(4):879. https://doi.org/10.3390/mi14040879
Chicago/Turabian StyleXu, Yuanye, Yinlong Zhang, and Wei Liang. 2023. "Automated Industrial Composite Fiber Orientation Inspection Using Attention-Based Normalized Deep Hough Network" Micromachines 14, no. 4: 879. https://doi.org/10.3390/mi14040879
APA StyleXu, Y., Zhang, Y., & Liang, W. (2023). Automated Industrial Composite Fiber Orientation Inspection Using Attention-Based Normalized Deep Hough Network. Micromachines, 14(4), 879. https://doi.org/10.3390/mi14040879