MagIO: Magnetic Field Strength Based Indoor- Outdoor Detection with a Commercial Smartphone




Abstract
:1. Introduction
1.1. GPS-Based IO Detection
1.2. Smartphone Sensor-Based Indoor-Outdoor Detection
- A feasibility study of using the geomagnetic field (referred to as ’magnetic field’ in the rest of the paper) to detect the user IO state.
- The performance appraisal of machine learning-based techniques to predict IO state with smartphone sensor data alone.
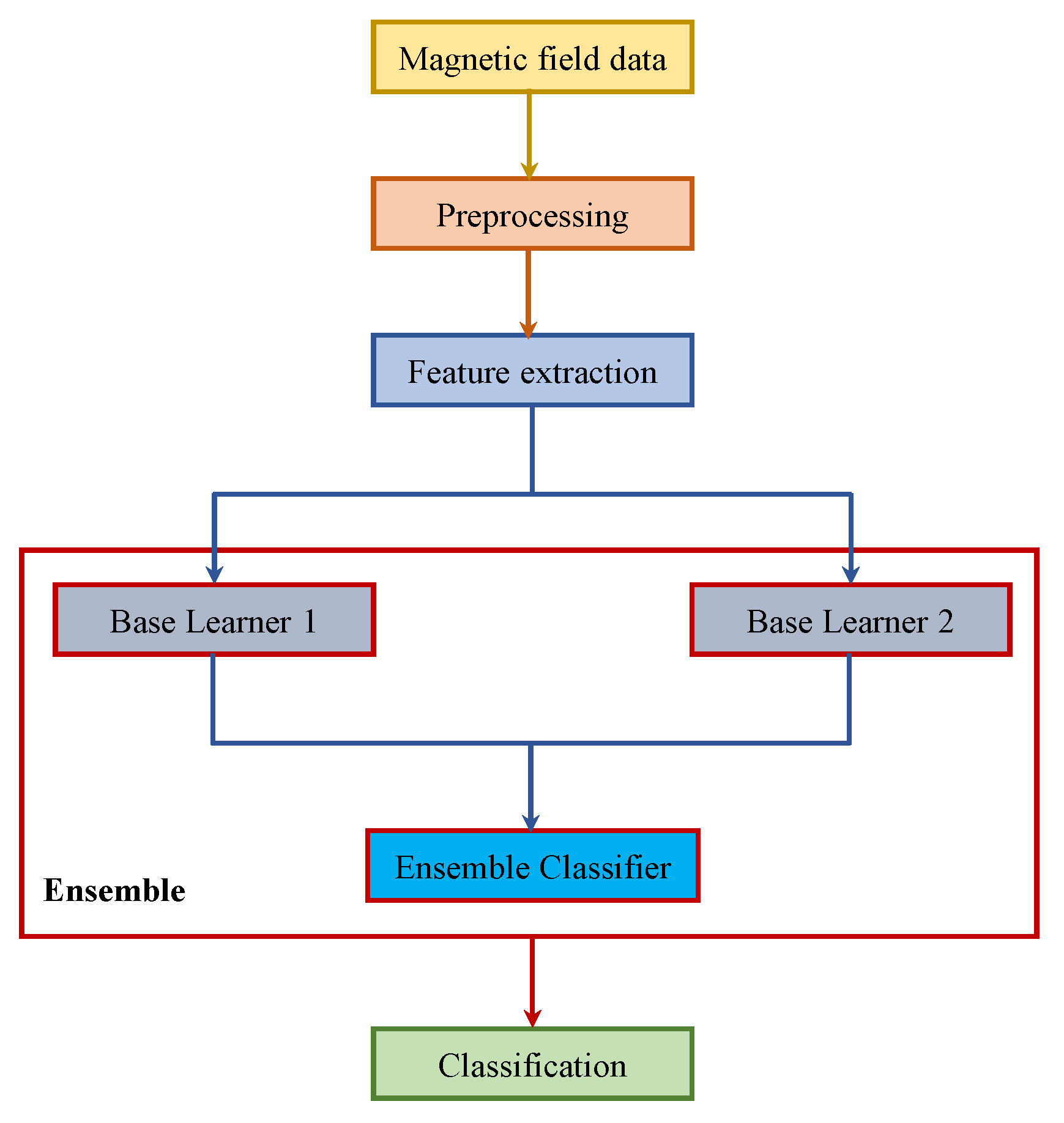
- An ensemble-based classifier to perform IO environment classification using magnetic field data from a smartphone.
2. An Insight on the Magnetic Field
3. Related Work
4. The Feasibility of Using the Magnetic Field for IO Detection
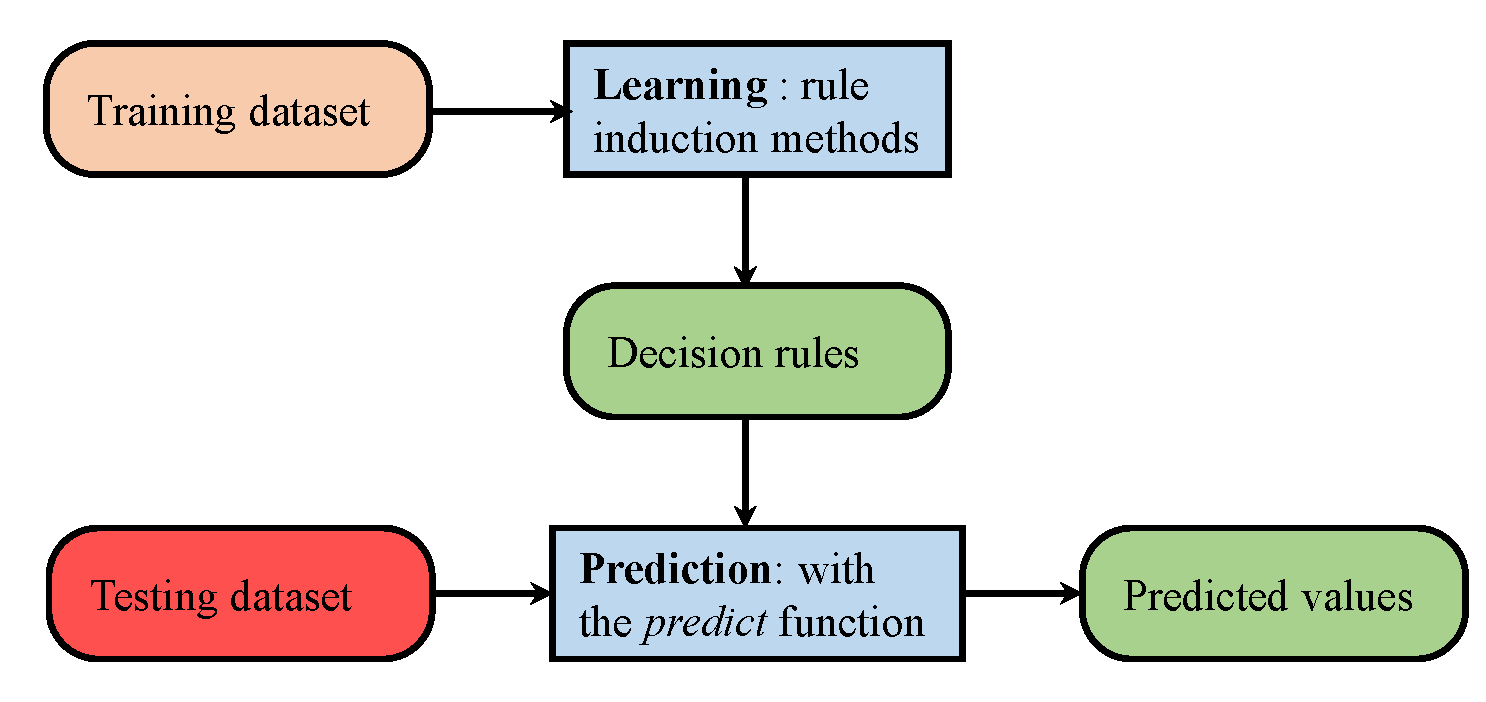
5. Machine Learning Techniques Used for Classification
5.1. Decision Trees
5.2. k-Nearest Neighbor
5.3. Naive Bayes
5.4. Random Forest
5.5. Gradient Boosting Machines
5.6. Rule Induction
5.7. Support Vector Machines
6. Experiment and Results
6.1. Experimental Setup
6.2. Data Collection
6.3. Results
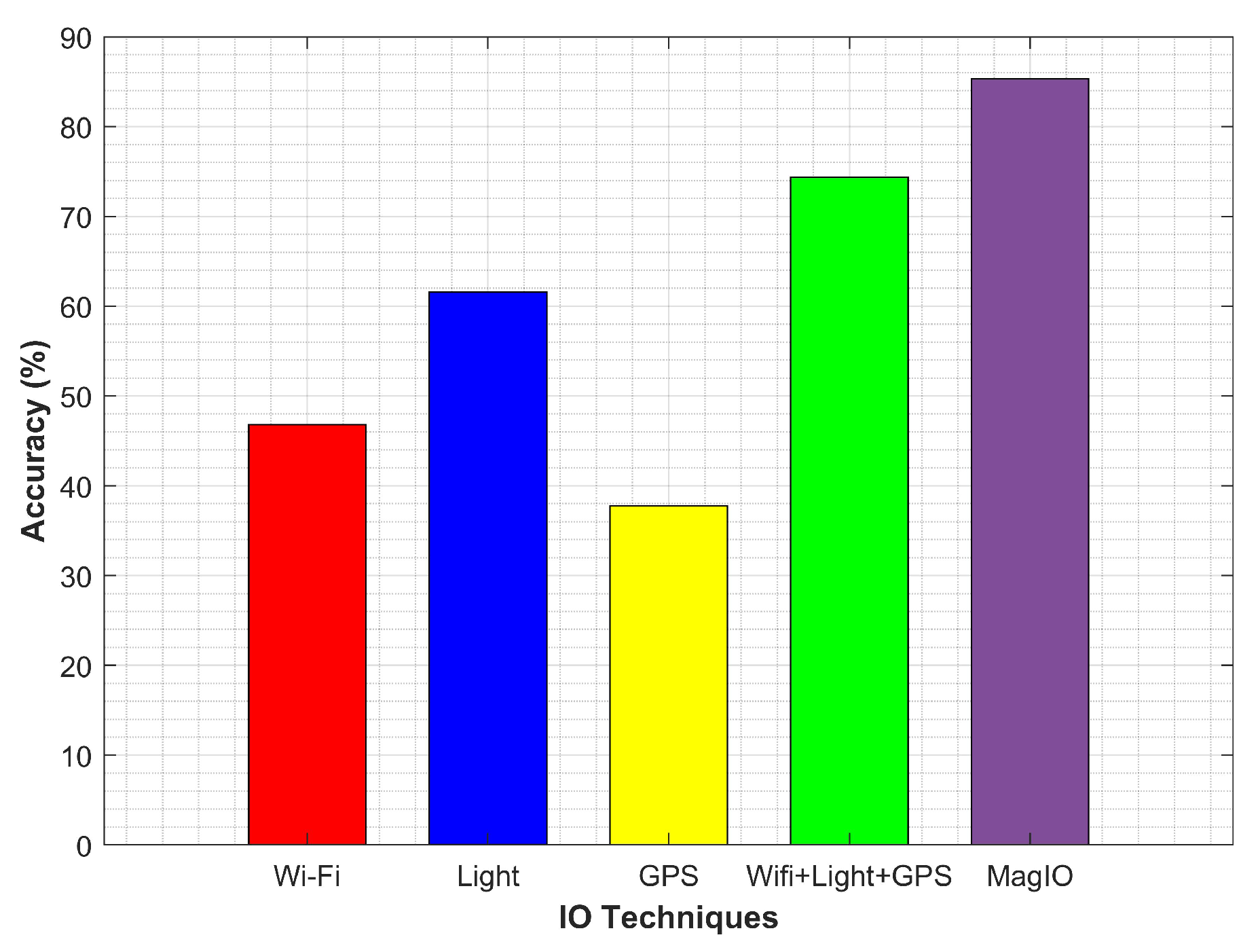
6.4. Performance Comparison and Energy Consumption
7. Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- World Bank Report on Mobile Devices. Available online: https://data.worldbank.org/indicator/it.cel.sets.p2 (accessed on 25 August 2018).
- Xu, H.; Teo, H.-H.; Tan, B.C.; Agarwal, R. The role of push-pull technology in privacy calculus: The case of location-based services. J. Manag. Inf. Syst. 2009, 26, 135–174. [Google Scholar] [CrossRef]
- Raper, J.; Gartner, G.; Karimi, H.; Rizos, C. A critical evaluation of location based services and their potential. J. Locat. Based Serv. 2007, 1, 5–45. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Gao, S. Location-Based Services. In The Geographic Information Science & Technology Body of Knowledge, 1st Quarter 2018 ed.; Wilson, J.P., Ed.; UCGIS: Ithaca, NY, USA, 2018. [Google Scholar] [CrossRef]
- Kiefer, P.; Huang, H.; Van de Weghe, N.; Raubal, M. Progress in Location Based Services; Springer: Berlin, Germany, 2018. [Google Scholar]
- Zhang, D.; Huang, H.; Lai, C.-F.; Liang, X.; Zou, Q.; Guo, M. Survey on context-awareness in ubiquitous media. Multimed. Tools Appl. 2013, 67, 179–211. [Google Scholar] [CrossRef]
- Krumm, J. Ubiquitous Computing Fundamentals; Chapman and Hall/CRC: London, UK, 2016. [Google Scholar]
- Karimi, H.A. Advanced Location-Based Technologies and Services; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Wang, H.; Sen, S.; Elgohary, A.; Farid, M.; Youssef, M.; Choudhury, R.R. No need to war-drive: Unsupervised indoor localization. In Proceedings of the 10th International Conference on Mobile Systems, Applications, and Services, Lake District, UK, 25–29 June 2012; ACM: New York, NY, USA, 2012; pp. 197–210. [Google Scholar]
- Lee, B.; Lim, C.; Lee, K. Classification of indoor-outdoor location using combined global positioning system (GPS) and temperature data for personal exposure assessment. Environ. Healthand Prev. Med. 2017, 22, 29. [Google Scholar] [CrossRef] [PubMed]
- Chintalapudi, K.; Padmanabha Iyer, A.; Padmanabhan, V.N. Indoor localization without the pain. In Proceedings of the Sixteenth Annual International Conference on Mobile Computing and Networking, Chicago, IL, USA, 20–24 September 2010; ACM: New York, NY, USA, 2010; pp. 173–184. [Google Scholar] [Green Version]
- Capurso, N.; Song, T.; Cheng, W.; Yu, J.; Cheng, X. An android-based mechanism for energy efficient localization depending on indoor/outdoor context. IEEE Internet Things J. 2017, 4, 299. [Google Scholar] [CrossRef]
- Radu, V.; Katsikouli, P.; Sarkar, R.; Marina, M.K. A semi-supervised learning approach for robust indoor-outdoor detection with smartphones. In Proceedings of the 12th ACM Conference on Embedded Network Sensor Systems, Memphis, TN, USA, 3–6 November 2014; ACM: New York, NY, USA, 2014; pp. 280–294. [Google Scholar] [Green Version]
- Dhondge, K.; Choi, B.-Y.; Song, S.; Park, H. Optical wireless authentication for smart devices using an onboard ambient light sensor. In Proceedings of the 2014 23rd International Conference on Computer Communication and Networks (ICCCN), Shanghai, China, 4–7 August 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–8. [Google Scholar]
- Spreitzer, R. Pin skimming: Exploiting the ambient-light sensor in mobile devices. In Proceedings of the 4th ACM Workshop on Security and Privacy in Smartphones & Mobile Devices, Scottsdale, AZ, USA, 3–7 November 2014; ACM: New York, NY, USA, 2014; pp. 51–62. [Google Scholar]
- Gutierrez-Martinez, J.-M.; Castillo-Martinez, A.; Medina-Merodio, J.-A.; Aguado-Delgado, J.; Martinez-Herraiz, J.-J. Smartphones as a Light Measurement Tool: Case of Study. Appl. Sci. 2017, 7, 616. [Google Scholar] [CrossRef]
- Liu, Q.; Yang, X.; Deng, L. An IBeacon-Based Location System for Smart Home Control. Sensors 2018, 18, 1897. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.-W.; Lin, C.-Y. An Interactive Real-Time Locating System Based on Bluetooth Low-Energy Beacon Network. Sensors 2018, 18, 1637. [Google Scholar] [CrossRef] [PubMed]
- Shu, Y.; Bo, C.; Shen, G.; Zhao, C.; Li, L.; Zhao, F. Magicol: Indoor localization using pervasive magnetic field and opportunistic WiFi sensing. IEEE J. Sel. Areas Commun. 2015, 33, 1443–1457. [Google Scholar] [CrossRef]
- Ashraf, I.; Hur, S.; Park, Y. MDIRECT-Magnetic field strength and peDestrIan dead RECkoning based indoor localizaTion. In Proceedings of the 2018 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Nantes, France, 24–27 September 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Subbu, K.P.; Gozick, B.; Dantu, R. LocateMe: Magnetic-fields-based indoor localization using smartphones. ACM Trans. Intell. Syst. Technol. (TIST) 2013, 4, 73. [Google Scholar] [CrossRef]
- Ashraf, I.; Hur, S.; Park, Y. mPILOT-magnetic field strength based pedestrian indoor localization. Sensors 2018, 18, 2283. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Zheng, Y.; Li, Z.; Li, M.; Shen, G. Iodetector: A generic service for indoor outdoor detection. In Proceedings of the 10th ACM Conference on Embedded Network Sensor Systems, Toronto, ON, Canada, 6–9 November 2012; ACM: New York, NY, USA, 2012; pp. 113–126. [Google Scholar]
- Chulliat, A.; Macmillan, S.; Alken, P.; Beggan, C.; Nair, M.; Hamilton, B.; Woods, A.; Ridley, V.; Maus, S.; Thomson, A. The US/UK World Magnetic Model for 2015–2020; National Geophysical Data Center: Edinburgh, UK, 2015.
- Blankenbach, J.; Norrdine, A. Position estimation using artificial generated magnetic fields. In Proceedings of the 2010 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Zurich, Switzerland, 15–17 September 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1–5. [Google Scholar]
- Chung, J.; Donahoe, M.; Schmandt, C.; Kim, I.-J.; Razavai, P.; Wiseman, M. Indoor location sensing using geo-magnetism. In Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services, Bethesda, MD, USA, 28 June–1 July 2011; ACM: New York, NY, USA, 2011; pp. 141–154. [Google Scholar]
- Zhang, C.; Subbu, K.P.; Luo, J.; Wu, J. GROPING: Geomagnetism and crowdsensing powered indoor navigation. IEEE Trans. Mobile Comput. 2015, 14, 387–400. [Google Scholar] [CrossRef]
- Carrillo, D.; Moreno, V.; Úbeda, B.; Skarmeta, A.F. Magicfinger: 3d magnetic fingerprints for indoor location. Sensors 2015, 15, 17168–17194. [Google Scholar] [CrossRef] [PubMed]
- Ali, M.U.; Hur, S.; Park, Y. Locali: Calibration-free systematic localization approach for indoor positioning. Sensors 2017, 17, 1213. [Google Scholar] [CrossRef] [PubMed]
- Bhargava, P.; Gramsky, N.; Agrawala, A. SenseMe: A system for continuous, on-device, and multi-dimensional context and activity recognition. In Proceedings of the 11th International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services; ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering), London, UK, 2–5 December 2014; pp. 40–49. [Google Scholar]
- Canovas, O.; Lopez-de-Teruel, P.E.; Ruiz, A. WiFiBoost: A terminal-based method for detection of indoor/outdoor places. In Proceedings of the 11th International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services; ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering), London, UK, 2–5 December 2014; pp. 352–353. [Google Scholar]
- Sung, R.; Jung, S.; Han, D. Sound based indoor and outdoor environment detection for seamless positioning handover. ICT Express 2015, 1, 106–109. [Google Scholar] [CrossRef]
- Liu, Z.; Park, H.; Chen, Z.; Cho, H. An energy-efficient and robust indoor-outdoor detection method based on cell identity map. Procedia Comput. Sci. 2015, 56, 189–195. [Google Scholar] [CrossRef]
- Okamoto, M.; Chen, C. Improving GPS-based indoor-outdoor detection with moving direction information from smartphone. In Adjunct, Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2015 ACM International Symposium on Wearable Computers, Osaka, Japan, 7–11 September 2015; ACM: New York, NY, USA, 2015; pp. 257–260. [Google Scholar]
- Bisio, I.; Delfino, A.; Lavagetto, F. A simple ultrasonic indoor/outdoor detector for mobile devices. In Proceedings of the 2015 International Wireless Communications and Mobile Computing Conference (IWCMC), Dubrovnik, Croatia, 24–27 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 137–141. [Google Scholar]
- Zou, H.; Jiang, H.; Luo, Y.; Zhu, J.; Lu, X.; Xie, L. Bluedetect: An ibeacon-enabled scheme for accurate and energy-efficient indoor-outdoor detection and seamless location-based service. Sensors 2016, 16, 268. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Chang, Q.; Li, Q.; Shi, Z.; Chen, W. Indoor-outdoor detection using a smart phone sensor. Sensors 2016, 16, 1563. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Tan, J.; Chan, S.-H.G. Towards area classification for large-scale fingerprint-based system. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; ACM: New York, NY, USA, 2016; pp. 232–243. [Google Scholar]
- Li, S.; Qin, Z.; Song, H.; Si, C.; Sun, B.; Yang, X.; Zhang, R. A lightweight and aggregated system for indoor/outdoor detection using smart devices. Future Gener. Comput. Syst. 2017. [Google Scholar] [CrossRef]
- Tan, P.N. Introduction to Data Mining; Pearson Education India: Uttar Pradesh, India, 2007. [Google Scholar]
- Breiman, L. Classification and Regression Trees; Routledge: Abingdon, UK, 2017. [Google Scholar]
- Rutkowski, L.; Jaworski, M.; Pietruczuk, L.; Duda, P. Decision trees for mining data streams based on the gaussian approximation. IEEE Trans. Knowl. Data Eng. 2014, 26, 108–119. [Google Scholar] [CrossRef]
- Roussopoulos, N.; Kelley, S.; Vincent, F. Nearest neighbor queries. In ACM Sigmod Record; ACM: New York, NY, USA, 1995; Volume 24, pp. 71–79. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Leung, K.M. Naive Bayesian Classifier; Polytechnic University Department of Computer Science/Finance and Risk Engineering: Brooklyn, NY, USA, 2007. [Google Scholar]
- Murphy, K.P. Naive Bayes Classifiers; University of British Columbia: Vancouver, BC, Canada, 2006; p. 18. [Google Scholar]
- Twala, B. Multiple classifier application to credit risk assessment. Expert Syst. Appl. 2010, 37, 3326–3336. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Deng, X.-B.; Ye, Y.-M.; Li, H.-B.; Huang, J.Z. An improved random forest approach for detection of hidden web search interfaces. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; IEEE: Piscataway, NJ, USA, 2008; Volume 3, pp. 1586–1591. [Google Scholar]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Michalski, R.S.; Carbonell, J.G.; Mitchell, T.M. Machine Learning: An Artificial Intelligence Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Johnson, R.; Zhang, T. Learning nonlinear functions using regularized greedy forest. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 942–954. [Google Scholar] [CrossRef] [PubMed]
- Pittman, S.J.; Brown, K.A. Multi-scale approach for predicting fish species distributions across coral reef seascapes. PLoS ONE 2011, 6, e20583. [Google Scholar] [CrossRef] [PubMed]
- Qabajeh, I.; Thabtah, F.; Chiclana, F. A dynamic rule-induction method for classification in data mining. J. Manag. Anal. 2015, 2, 233–253. [Google Scholar] [CrossRef]
- Grzymala-Busse, J.W. A new version of the rule induction system LERS. Fundam. Inform. 1997, 31, 27–39. [Google Scholar]
- Mining, W.I.D. Data Mining: Concepts and Techniques; Morgan Kaufinann: Burlington, MA, USA, 2006. [Google Scholar]
- Cohen, W.W. Fast effective rule induction. In Machine Learning Proceedings 1995; Elsevier: Amsterdam, The Netherlands, 1995; pp. 115–123. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef] [Green Version]
- Bennett, K.P.; Campbell, C. Support vector machines: Hype or hallelujah? ACM Sigkdd Explor. Newsl. 2000, 2, 1–13. [Google Scholar] [CrossRef]
- Shmilovici, A. Support vector machines. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin, Germany, 2009; pp. 231–247. [Google Scholar]
- Epanechnikov, V.A. Non-parametric estimation of a multivariate probability density. Theoryof Probab. Appl. 1969, 14, 153–158. [Google Scholar] [CrossRef]
- Asahi Kasei Microdevices Data Sheet. Available online: https://www.akm.com/akm/en/file/datasheet/AK09916C.pdf (accessed on 5 September 2018).
- Al-Hasan, A.A.; El-Alfy, E.-S.M. Dendritic cell algorithm for mobile phone spam filtering. Procedia Comput. Sci. 2015, 52, 244–251. [Google Scholar] [CrossRef]
- Rokach, L. Ensemble-based classifiers. Artif. Intell. Rev. 2010, 33, 1–39. [Google Scholar] [CrossRef]
- Seni, G.; Elder, J.F. Ensemble Methods in Data Mining: Improving Accuracy through Combining Predictions; Synthesis Lectures on Data Mining and Knowledge Discovery; Morgan & Claypool Publishers: San Rafael, CA, USA, 2010; Volume 2, pp. 1–26. [Google Scholar]
- Tang, E.K.; Suganthan, P.N.; Yao, X. Gene selection algorithms for microarray data based on least squares support vector machine. BMC Bioinform. 2006, 7, 95. [Google Scholar] [CrossRef]
- Schapire, R.E.; Freund, Y. Boosting: Foundations and Algorithms; MIT Press: Cambridge, MA, USA, 2012; Volume 5. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef] [Green Version]
- Caruana, R.; Niculescu-Mizil, A.; Crew, G.; Ksikes, A. Ensemble selection from libraries of models. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; ACM: New York, NY, USA, 2004; p. 18. [Google Scholar] [Green Version]
- Niculescu-Mizil, A.; Perlich, C.; Swirszcz, G.; Sindhwani, V.; Liu, Y.; Melville, P.; Wang, D.; Xiao, J.; Hu, J.; Singh, M. Winning the KDD cup orange challenge with ensemble selection. In Proceedings of the 2009 International Conference on KDD-Cup 2009, Paris, France, 28 June–1 July 2009; pp. 23–34. [Google Scholar]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Weiss, G.M.; Provost, F. Learning when training data are costly: The effect of class distribution on tree induction. J. Artif. Intell. Res. 2003, 19, 315–354. [Google Scholar] [CrossRef]
- Hernandez, P.A.; Graham, C.H.; Master, L.L.; Albert, D.L. The effect of sample size and species characteristics on performance of different species distribution modeling methods. Ecography 2006, 29, 773–785. [Google Scholar] [CrossRef] [Green Version]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khan, I.; Khusro, S.; Ali, S.; Ahmad, J. Sensors are Power Hungry: An Investigation of Smartphone Sensors Impact on Battery Power from Lifelogging Perspective. Bahria Univ. J. Inf. Commun. Technol. 2016, 9, 8–19. [Google Scholar]
- Horvath, Z.; Jenak, I.; Brachmann, F. Battery consumption of smartphone sensors. J. Reliab. Intell. Environ. 2017, 3, 131–136. [Google Scholar] [CrossRef]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Equation |
|---|---|
| Mean | |
| Median | |
| Variance | |
| Standard deviation | |
| Trimmed mean | |
| Coefficient of variance | |
| Kurtosis | |
| Interquartile | |
| Percentiles (1,10,25,50,75,99) | |
| Squared deviation | |
| Average absolute dev. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ashraf, I.; Hur, S.; Park, Y. MagIO: Magnetic Field Strength Based Indoor- Outdoor Detection with a Commercial Smartphone. Micromachines 2018, 9, 534. https://doi.org/10.3390/mi9100534
Ashraf I, Hur S, Park Y. MagIO: Magnetic Field Strength Based Indoor- Outdoor Detection with a Commercial Smartphone. Micromachines. 2018; 9(10):534. https://doi.org/10.3390/mi9100534
Chicago/Turabian StyleAshraf, Imran, Soojung Hur, and Yongwan Park. 2018. "MagIO: Magnetic Field Strength Based Indoor- Outdoor Detection with a Commercial Smartphone" Micromachines 9, no. 10: 534. https://doi.org/10.3390/mi9100534
APA StyleAshraf, I., Hur, S., & Park, Y. (2018). MagIO: Magnetic Field Strength Based Indoor- Outdoor Detection with a Commercial Smartphone. Micromachines, 9(10), 534. https://doi.org/10.3390/mi9100534