
Automated Detection and Classification of Oral Lesions Using Deep Learning to Detect Oral Potentially Malignant Disorders


Abstract
:Simple Summary
Abstract
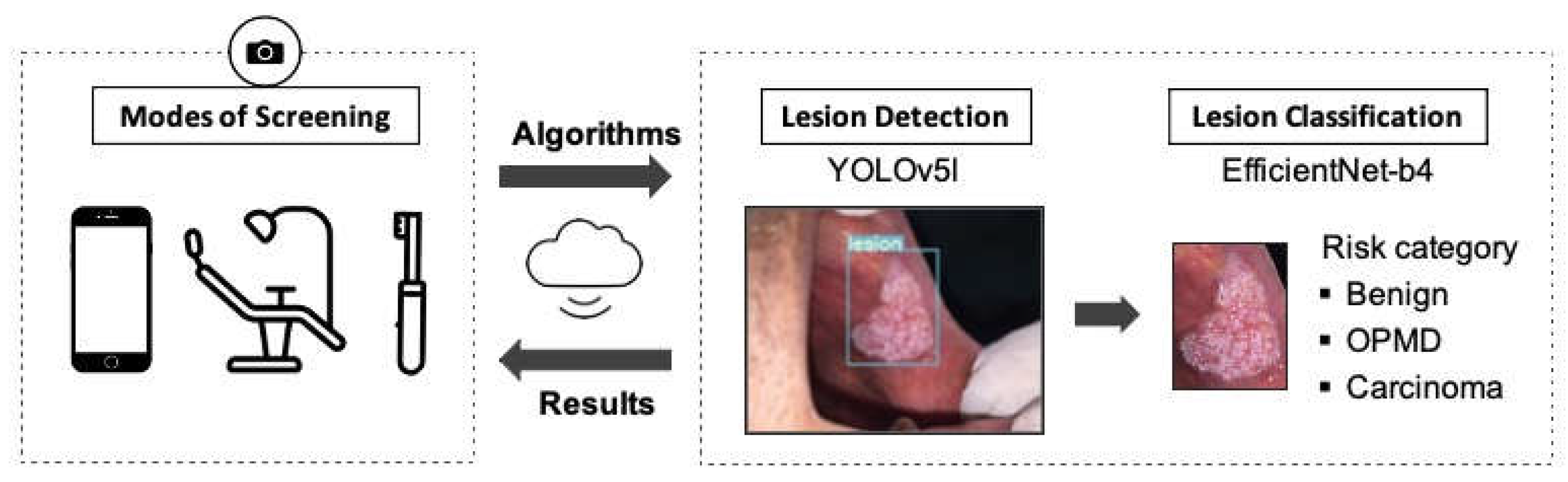
1. Introduction
2. Materials and Methods
2.1. Dataset
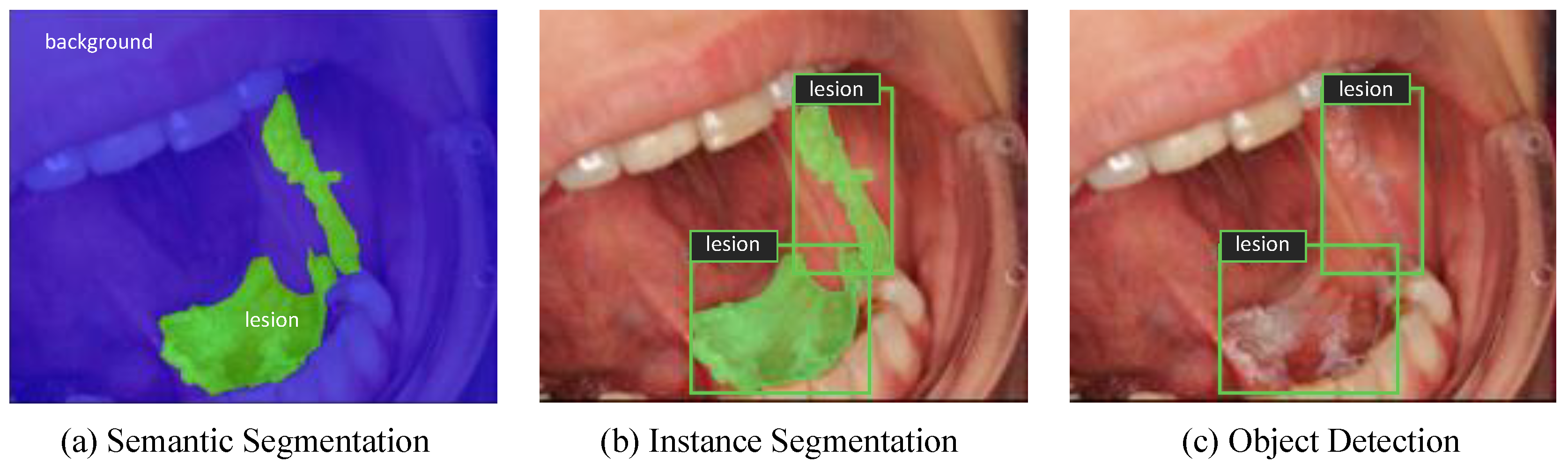
2.2. Semantic Segmentation Experiments
2.3. Instance Segmentation Experiments
2.4. Object Detection Experiments
2.5. Classification Experiments
3. Results
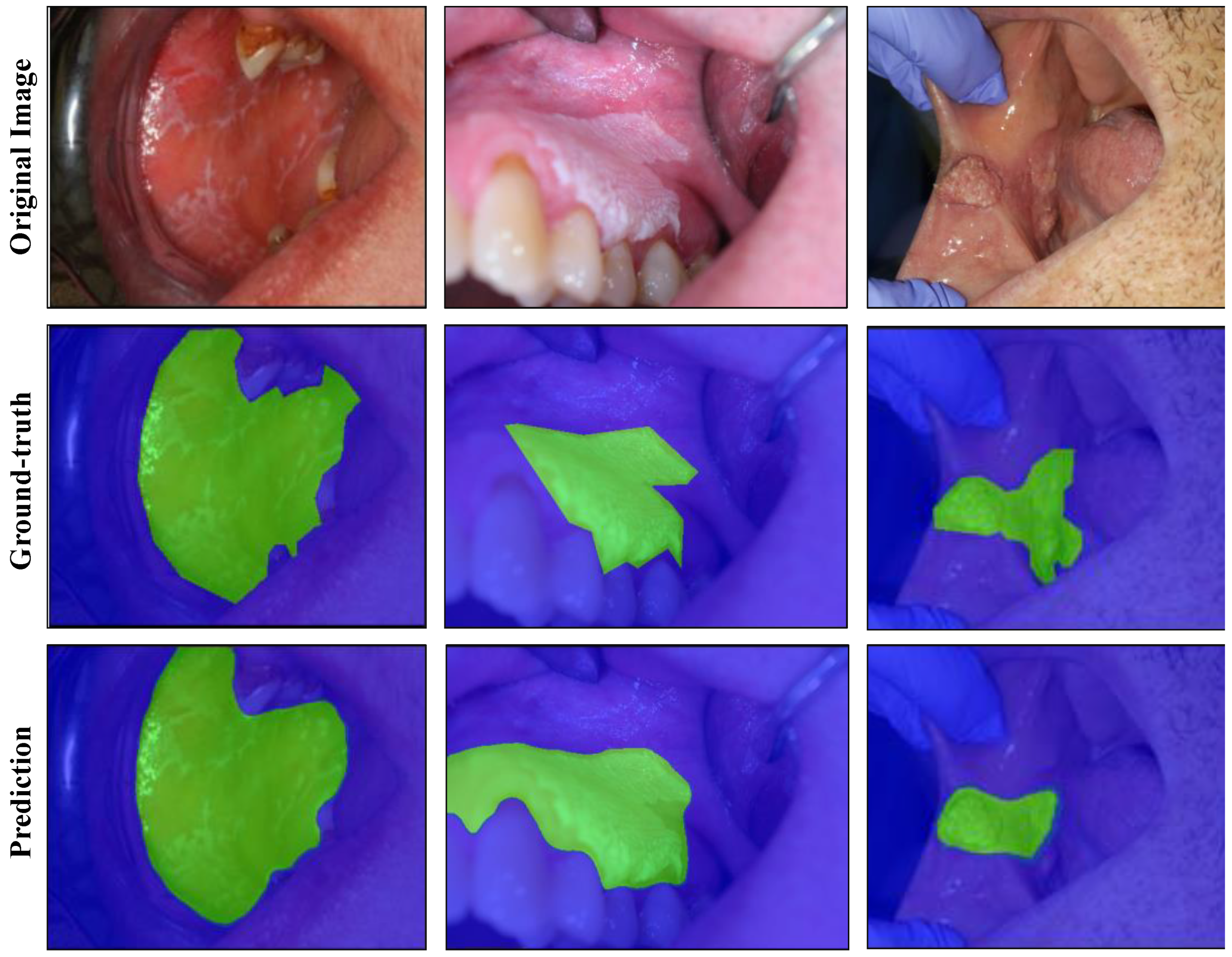
3.1. Semantic Segmentation Experiments
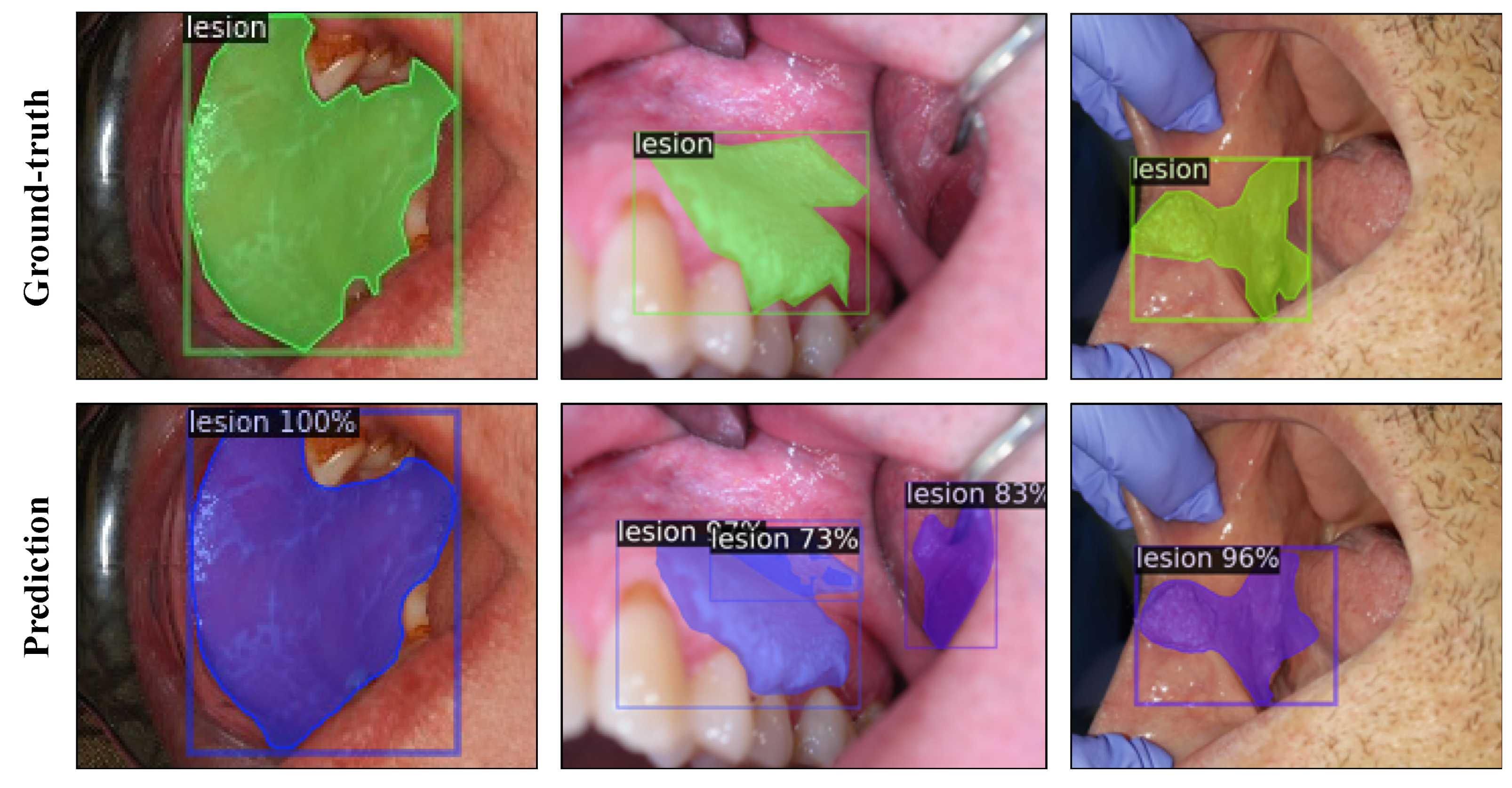
3.2. Instance Segmentation Experiments
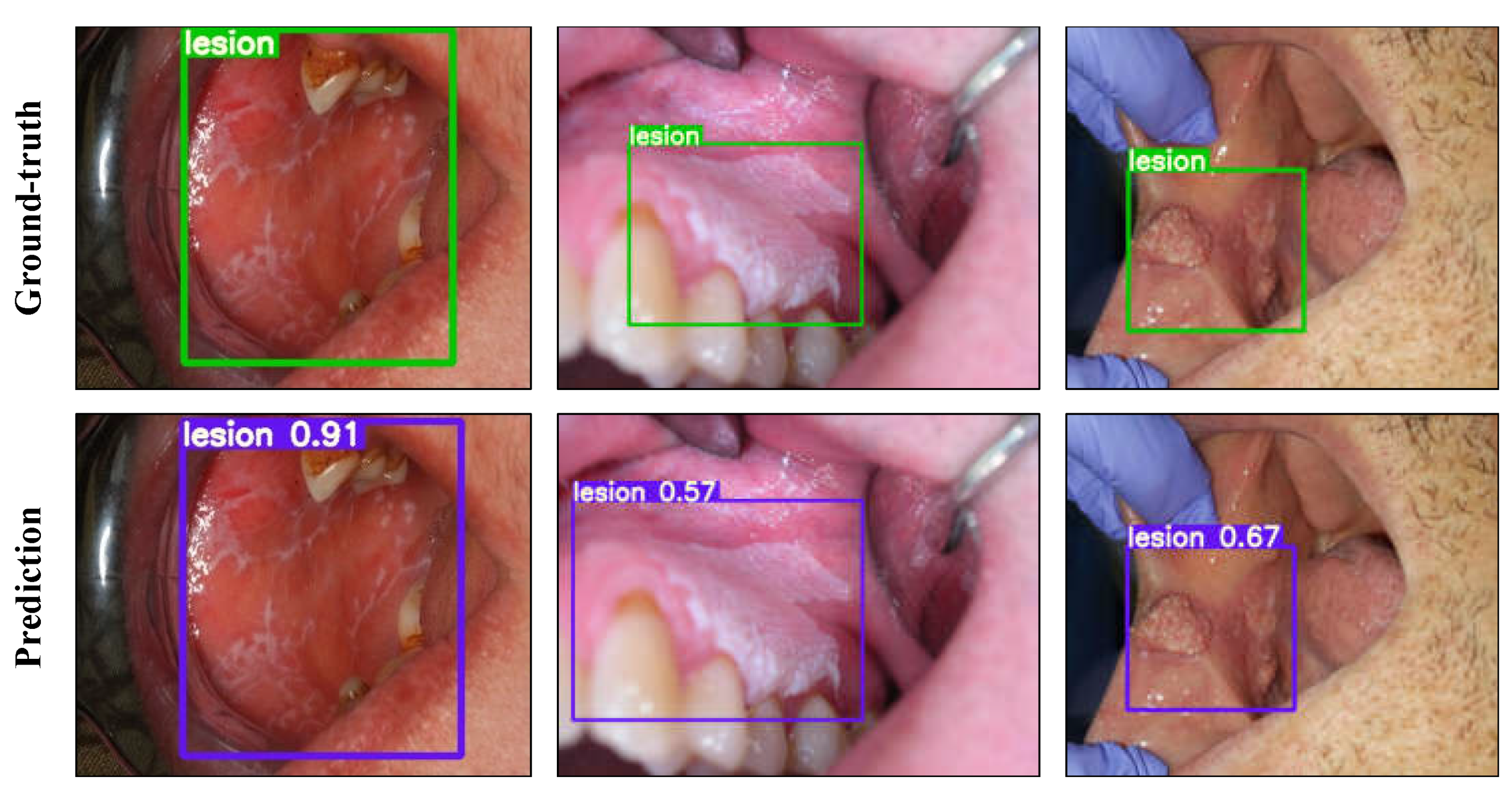
3.3. Object Detection Experiments
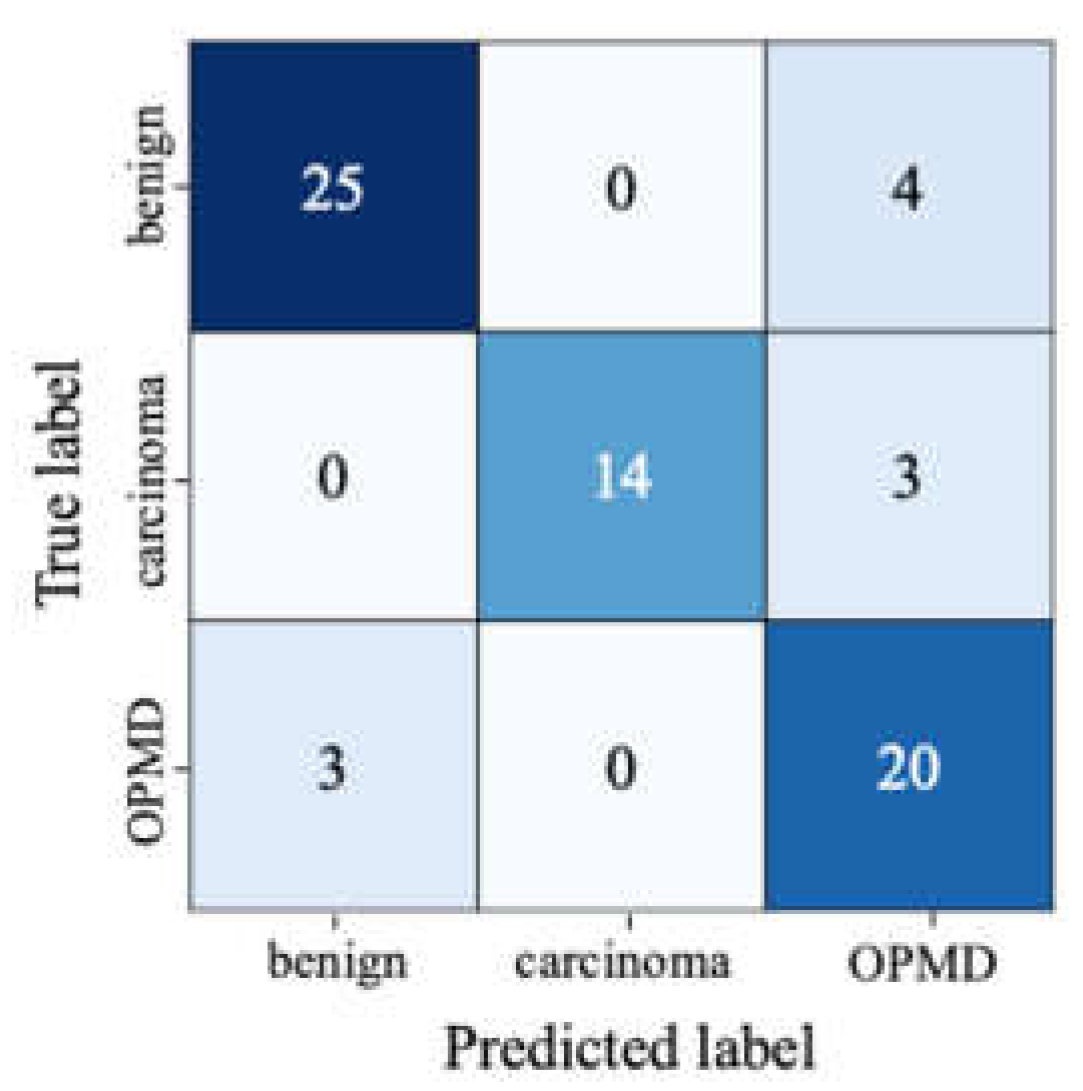
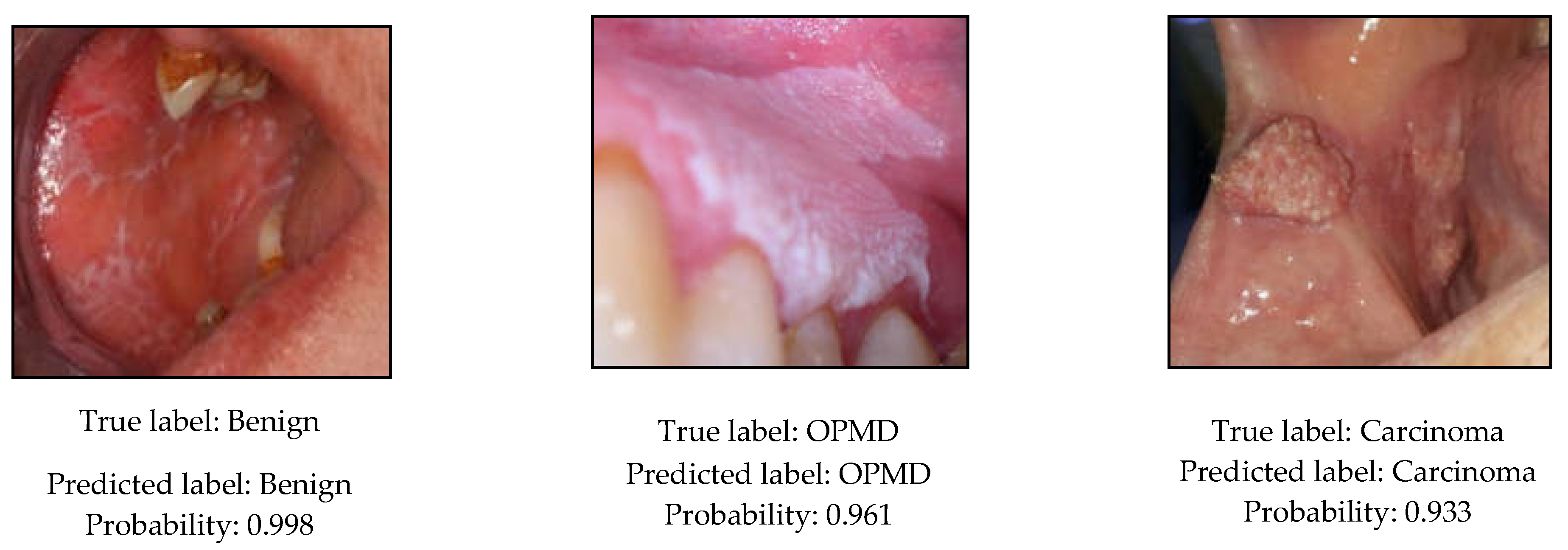
3.4. Classification Experiments
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- International Agency for Research on Cancer. 900 World Fact Sheets. Available online: https://gco.iarc.fr/today/data/factsheets/populations/900-world-fact-sheets.pdf (accessed on 27 August 2020).
- Stathopoulos, P.; Smith, W.P. Analysis of Survival Rates Following Primary Surgery of 178 Consecutive Patients with Oral Cancer in a Large District General Hospital. J. Maxillofac. Oral Surg. 2017, 16, 158–163. [Google Scholar] [CrossRef] [PubMed]
- Grafton-Clarke, C.; Chen, K.W.; Wilcock, J. Diagnosis and referral delays in primary care for oral squamous cell cancer: A systematic review. Br. J. Gen. Pract. 2018, 69, e112–e126. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seoane, J.; Alvarez-Novoa, P.; Gómez, I.; Takkouche, B.; Diz, P.; Warnakulasiruya, S.; Seoane-Romero, J.M.; Varela-Centelles, P. Early oral cancer diagnosis: The Aarhus statement perspective. A systematic review and meta-analysis. Head Neck 2015, 38, E2182–E2189. [Google Scholar] [CrossRef] [PubMed]
- WHO. Oral Cancer. Available online: https://www.who.int/cancer/prevention/diagnosis-screening/oral-cancer/en/ (accessed on 2 January 2021).
- Warnakulasuriya, S.; Greenspan, J.S. Textbook of Oral Cancer: Prevention, Diagnosis and Management; Springer Nature: Basingstoke, UK, 2020. [Google Scholar]
- Scully, C.; Bagan, J.V.; Hopper, C.; Epstein, J.B. Oral cancer: Current and future diagnostic techniques. Am. J. Dent. 2008, 21, 199–209. [Google Scholar]
- Wilder-Smith, P.; Lee, K.; Guo, S.; Zhang, J.; Osann, K.; Chen, Z.; Messadi, D. In Vivo diagnosis of oral dysplasia and malignancy using optical coherence tomography: Preliminary studies in 50 patients. Lasers Surg. Med. 2009, 41, 353–357. [Google Scholar] [CrossRef] [Green Version]
- Heidari, A.E.; Suresh, A.; Kuriakose, M.A.; Chen, Z.; Wilder-Smith, P.; Sunny, S.P.; James, B.L.; Lam, T.M.; Tran, A.V.; Yu, J.; et al. Optical coherence tomography as an oral cancer screening adjunct in a low resource settings. IEEE J. Sel. Top. Quantum Electron. 2018, 25, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Jeyaraj, P.R.; Nadar, E.R.S. Computer-assisted medical image classification for early diagnosis of oral cancer employing deep learning algorithm. J. Cancer Res. Clin. Oncol. 2019, 145, 829–837. [Google Scholar] [CrossRef]
- Song, B.; Sunny, S.; Uthoff, R.D.; Patrick, S.; Suresh, A.; Kolur, T.; Keerthi, G.; Anbarani, A.; Wilder-Smith, P.; Kuriakose, M.A.; et al. Automatic classification of dual-modalilty, smartphone-based oral dysplasia and malignancy images using deep learning. Biomed. Opt. Express 2018, 9, 5318–5329. [Google Scholar] [CrossRef]
- Uthoff, R.D.; Song, B.; Sunny, S.; Patrick, S.; Suresh, A.; Kolur, T.; Gurushanth, K.; Wooten, K.; Gupta, V.; Platek, M.E.; et al. Small form factor, flexible, dual-modality handheld probe for smartphone-based, point-of-care oral and oropharyngeal cancer screening. J. Biomed. Opt. 2019, 24, 1–8. [Google Scholar] [CrossRef]
- Uthoff, R.D.; Song, B.; Sunny, S.; Patrick, S.; Suresh, A.; Kolur, T.; Keerthi, G.; Spires, O.; Anbarani, A.; Wilder-Smith, P.; et al. Point-of-care, smartphone-based, dual-modality, dual-view, oral cancer screening device with neural network classification for low-resource communities. PLoS ONE 2018, 13, e0207493. [Google Scholar] [CrossRef]
- Uthoff, R.; Wilder-Smith, P.; Sunny, S.; Suresh, A.; Patrick, S.; Anbarani, A.; Song, B.; Birur, P.; Kuriakose, M.A.; Spires, O. Development of a dual-modality, dual-view smartphone-based imaging system for oral cancer detection. Des. Qual. Biomed. Technol. XI 2018, 10486, 104860V. [Google Scholar] [CrossRef]
- Rahman, M.S.; Ingole, N.; Roblyer, D.; Stepanek, V.; Richards-Kortum, R.; Gillenwater, A.; Shastri, S.; Chaturvedi, P. Evaluation of a low-cost, portable imaging system for early detection of oral cancer. Head Neck Oncol. 2010, 2, 10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roblyer, D.; Kurachi, C.; Stepanek, V.; Williams, M.D.; El-Naggar, A.K.; Lee, J.J.; Gillenwater, A.M.; Richards-Kortum, R. Objective detection and delineation of oral neoplasia using autofluorescence imaging. Cancer Prev. Res. 2009, 2, 423–431. [Google Scholar] [CrossRef] [Green Version]
- Anantharaman, R.; Anantharaman, V.; Lee, Y. Oro vision: Deep learning for classifying orofacial diseases. In Proceedings of the IEEE International Conference on Healthcare Informatics (ICHI), Institute of Electrical and Electronics Engineers (IEEE), Park City, UT, USA, 23–26 August 2017; pp. 39–45. [Google Scholar] [CrossRef]
- Anantharaman, R.; Velazquez, M.; Lee, Y. Utilizing Mask R-CNN for Detection and Segmentation of Oral Diseases. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine, BIBM 2018, Institute of Electrical and Electronics Engineers Inc., Madrid, Spain, 3–6 December 2018; pp. 2197–2204. [Google Scholar] [CrossRef]
- Shamim, M.Z.M.; Syed, S.; Shiblee, M.; Usman, M.; Ali, S. Automated Detection of Oral Pre-Cancerous Tongue Lesions Using Deep Learning for Early Diagnosis of Oral Cavity Cancer. arXiv 2019, arXiv:1909.08987. [Google Scholar] [CrossRef]
- Welikala, R.A.; Remagnino, P.; Lim, J.H.; Chan, C.S.; Rajendran, S.; Kallarakkal, T.G.; Zain, R.B.; Jayasinghe, R.D.; Rimal, J.; Kerr, A.R.; et al. Automated Detection and Classification of Oral Lesions Using Deep Learning for Early Detection of Oral Cancer. IEEE Access 2020, 8, 132677–132693. [Google Scholar] [CrossRef]
- Fu, Q.; Chen, Y.; Li, Z.; Jing, Q.; Hu, C.; Liu, H.; Bao, J.; Hong, Y.; Shi, T.; Li, K.; et al. A deep learning algorithm for detection of oral cavity squamous cell carcinoma from photographic images: A retrospective study. EClinicalMedicine 2020, 27, 100558. [Google Scholar] [CrossRef] [PubMed]
- Dutta, A.; Gupta, A.; Zissermann, A. VGG Image Annotator. 2020. Available online: https://www.robots.ox.ac.uk/~vgg/software/via/ (accessed on 15 December 2020).
- Dutta, A.; Zisserman, A. The VIA Annotation Software for Images, Audio and Video. In MM 2019, Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; Amsaleg, L., Huet, B., Larson, M., Eds.; ACM: New York, NY, USA, 2019; pp. 2276–2279. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Yakubovskiy, P. Segmentation Models Pytorch. 2019. Available online: https://github.com/qubvel/segmentation_models.pytorch (accessed on 16 December 2020).
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R.B. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 386–397. [Google Scholar] [CrossRef]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. Available online: https://github.com/facebookresearch/detectron2 (accessed on 10 November 2020).
- COCO Consortium. COCO—Common Objects in Context—Detection Evaluation. Available online: https://cocodataset.org/#detection-eval (accessed on 18 December 2020).
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Stan, C.; Changyu, L.; Hogan, A. Laughing; NanoCode012; yxNONG.; Diaconu, L.; et all. Ultralytics/Yolov5: V2.0. GitHub 2020. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 23–25 July 2017; Institute of Electrical and Electronics Engineers Inc.: Honolulu, HI, USA, 2017; Volume 2017, pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; AAAI Press: Palo Alto, CA, USA, 2017; pp. 4278–4284. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 2019, pp. 10691–10700. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., Alche-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Melas-Kyriazi, L. lukemelas/EfficientNet-PyTorch: A PyTorch Implementation of Efficient Net. Available online: https://github.com/lukemelas/EfficientNet-PyTorch (accessed on 3 December 2020).
- Cadene, R. cadene/pretrained-models.pytorch: Pretrained ConvNets for Pytorch. Available online: https://github.com/Cadene/pretrained-models.pytorch#modelinput_size (accessed on 1 December 2020).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Neville, B.; Damm, D.D.; Allen, C.; Chi, A. Oral and Maxillofacial Pathology, 4th ed.; Elsevier: St. Louis, MO, USA, 2016. [Google Scholar]
- Speight, P.M.; Khurram, S.A.; Kujan, O. Oral potentially malignant disorders: Risk of progression to malignancy. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2018, 125, 612–627. [Google Scholar] [CrossRef] [PubMed] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Disease | Number of Lesions |
|---|---|---|
| Benign | Dermatologic diseases (geographic tongue, lichen planus, systemic lupus erythematosus, pemphigoid, erythema multiforme, pemphigus vulgaris) | 90 |
| Fungal diseases (median rhomboid glossitis, candidal leukoplakia, pseudomembranous candidiasis) | 33 | |
| Inflammatory process (nicotine stomatitis, gingivitis, periodontitis, pericoronitis) | 30 | |
| Developmental defects (fissured tongue, thrush, hairy tongue, leukoedema, Fordyce granules) | 24 | |
| Ulcers (aphthous ulcer, traumatic ulcer, viral ulcers, TUGSE) | 54 | |
| Keratosis (reactive / traumatic keratosis, linea alba) | 36 | |
| Hairy leukoplakia | 7 | |
| OPMD | Leukoplakia | 156 |
| Erythroplakia | 35 | |
| Erythroleukoplakia | 46 | |
| Submucous fibrosis | 11 | |
| Carcinoma | Squamous cell carcinoma | 162 |
| Dataset Type | Benign | OPMD | Carcinoma | Total Number of Lesions |
|---|---|---|---|---|
| Training | 219 | 203 | 130 | 552 |
| Validation | 26 | 22 | 15 | 63 |
| Test | 29 | 23 | 17 | 69 |
| - | 274 | 248 | 162 | 684 |
| Backbone | Dicetest | Dicetest with TTA |
|---|---|---|
| EfficientNet-b3 | 0.925 | 0.927 |
| Densenet-161 | 0.921 | 0.927 |
| Inception-v4 | 0.915 | 0.922 |
| EfficientNet-b7 | 0.926 | 0.929 |
| ResNeXt-101_32x8d | 0.923 | 0.928 |
| Backbone | Box AP | Box AP50 | Mask AP | Mask AP50 | SpeedGPU |
|---|---|---|---|---|---|
| ResNet-50 FPN | 42.53 | 80.51 | 37.23 | 74.08 | 46 |
| ResNet-50 FPN + TTA | 42.65 | 82.63 | 37.98 | 76.19 | 361 |
| ResNet-101 FPN | 41.85 | 81.86 | 37.70 | 74.41 | 56 |
| ResNet-101 FPN + TTA | 40.54 | 83.64 | 37.52 | 72.96 | 442 |
| ResNeXt-101 FPN | 43.90 | 79.74 | 37.85 | 78.00 | 89 |
| ResNeXt-101 FPN + TTA | 43.35 | 81.60 | 37.80 | 78.92 | 786 |
| Model | AP | AP50 | SpeedGPU |
|---|---|---|---|
| YOLOv5s | 0.579 | 0.920 | 4.4 |
| YOLOv5m | 0.607 | 0.896 | 6.9 |
| YOLOv5l | 0.644 | 0.951 | 10.6 |
| YOLOv5l + TTA | 0.622 | 0.953 | 21.2 |
| YOLOv5x | 0.613 | 0.902 | 18 |
| YOLOv5x + TTA | 0.630 | 0.940 | 35.3 |
| YOLOv5s & 5m ensemble | 0.637 | 0.923 | 9 |
| Model | Input Size | Precision | Recall | F1-Score |
|---|---|---|---|---|
| EfficientNet-b4 | 380 | 0.869 | 0.855 | 0.858 |
| Inception-v4 | 299 | 0.877 | 0.855 | 0.858 |
| DenseNet-161 | 224 | 0.879 | 0.841 | 0.844 |
| Ensemble | 224 | 0.849 | 0.841 | 0.843 |
| ResNet-152 | 224 | 0.826 | 0.812 | 0.811 |
| Class | Precision | Recall | F1-score | Support |
|---|---|---|---|---|
| Benign | 0.89 | 0.86 | 0.88 | 29 |
| OPMD | 0.74 | 0.87 | 0.90 | 23 |
| Carcinoma | 1.00 | 0.82 | 0.90 | 17 |
| Weighted average | 0.87 | 0.86 | 0.86 | 69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tanriver, G.; Soluk Tekkesin, M.; Ergen, O. Automated Detection and Classification of Oral Lesions Using Deep Learning to Detect Oral Potentially Malignant Disorders. Cancers 2021, 13, 2766. https://doi.org/10.3390/cancers13112766
Tanriver G, Soluk Tekkesin M, Ergen O. Automated Detection and Classification of Oral Lesions Using Deep Learning to Detect Oral Potentially Malignant Disorders. Cancers. 2021; 13(11):2766. https://doi.org/10.3390/cancers13112766
Chicago/Turabian StyleTanriver, Gizem, Merva Soluk Tekkesin, and Onur Ergen. 2021. "Automated Detection and Classification of Oral Lesions Using Deep Learning to Detect Oral Potentially Malignant Disorders" Cancers 13, no. 11: 2766. https://doi.org/10.3390/cancers13112766
APA StyleTanriver, G., Soluk Tekkesin, M., & Ergen, O. (2021). Automated Detection and Classification of Oral Lesions Using Deep Learning to Detect Oral Potentially Malignant Disorders. Cancers, 13(11), 2766. https://doi.org/10.3390/cancers13112766