
Urine-Based Metabolomics and Machine Learning Reveals Metabolites Associated with Renal Cell Carcinoma Stage

 , ,
, ,  and
and 
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Tumor Size Estimation
2.2. Feature Selection for the RCC Stage Stratification
2.3. Machine Learning-Enabled RCC Stage Stratification
2.4. Implementation Environment and Computational Libraries
3. Results
3.1. Patient Cohort Characteristics
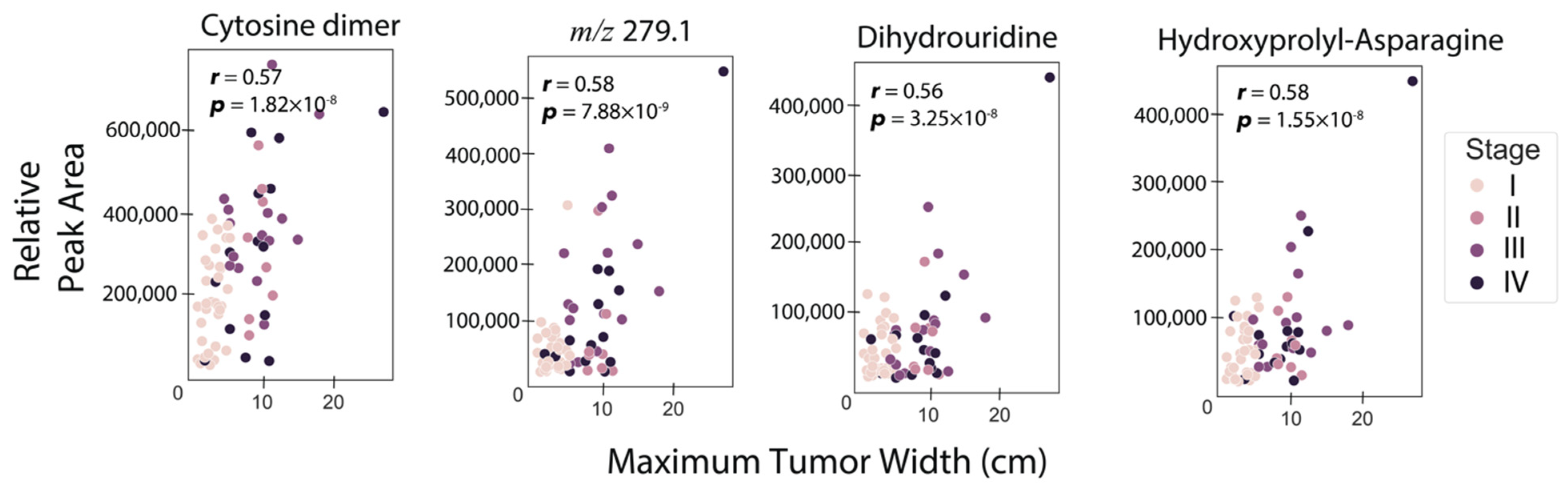
3.2. Correlation of RCC Tumor Size with Urine Metabolite Abundances
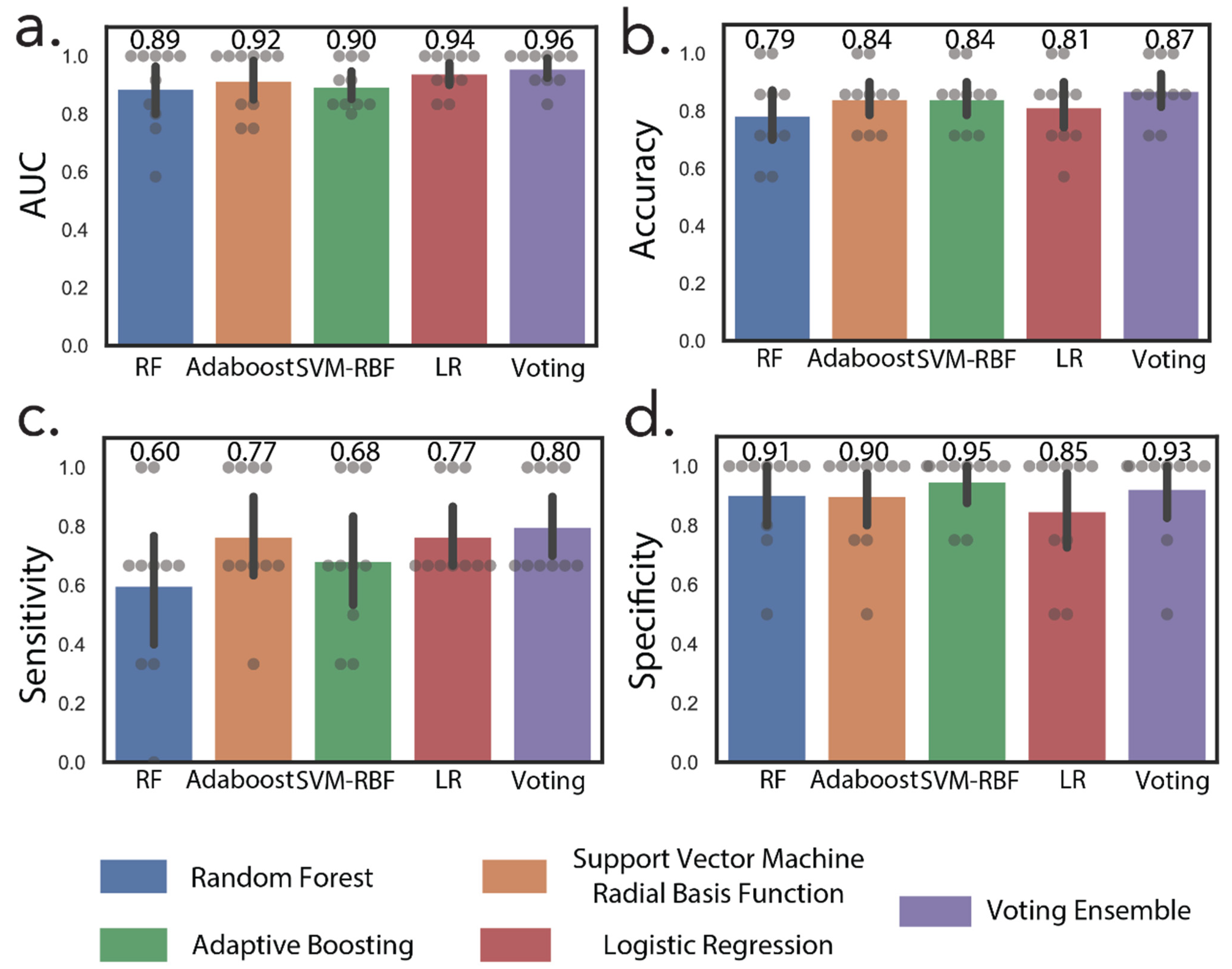
3.3. Machine Learning Accurately Discriminates Early and Advanced Stage RCC
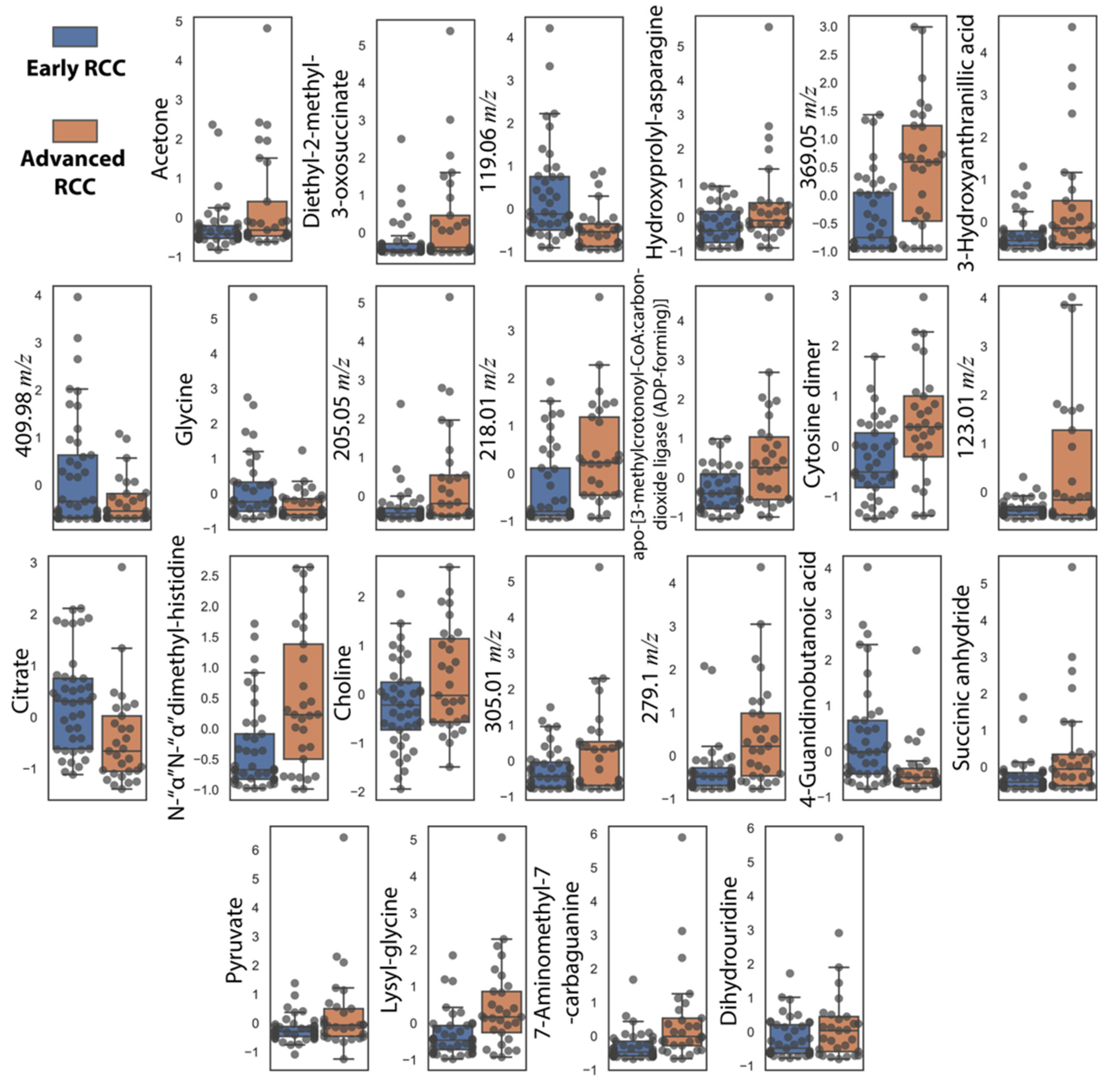
3.4. Comparison of RCC Stages and Healthy Controls Reveals Metabolic Trends of RCC Staging Markers
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Padala, S.A.; Barsouk, A.; Thandra, K.C.; Saginala, K.; Mohammed, A.; Vakiti, A.; Rawla, P.; Barsouk, A. Epidemiology of Renal Cell Carcinoma. World J. Oncol. 2020, 11, 79–87. [Google Scholar] [CrossRef] [PubMed]
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer Statistics, 2021. CA Cancer J. Clin. 2021, 71, 7–33. [Google Scholar] [CrossRef] [PubMed]
- Escudier, B.; Porta, C.; Schmidinger, M.; Rioux-Leclercq, N.; Bex, A.; Khoo, V.; Grunwald, V.; Gillessen, S.; Horwich, A. Renal cell carcinoma: ESMO Clinical Practice Guidelines for diagnosis, treatment and follow-up. Ann. Oncol. 2019, 30, 706–720. [Google Scholar] [CrossRef] [Green Version]
- Bifarin, O.O.; Gaul, D.A.; Sah, S.; Arnold, R.S.; Ogan, K.; Master, V.A.; Roberts, D.L.; Bergquist, S.H.; Petros, J.A.; Fernandez, F.M.; et al. Machine Learning-Enabled Renal Cell Carcinoma Status Prediction Using Multiplatform Urine-Based Metabolomics. J. Proteome Res. 2021, 20, 3629–3641. [Google Scholar] [CrossRef]
- Faubert, B.; Solmonson, A.; DeBerardinis, R.J. Metabolic reprogramming and cancer progression. Science 2020, 368, eaaw5473. [Google Scholar] [CrossRef]
- Lameirinhas, A.; Miranda-Goncalves, V.; Henrique, R.; Jeronimo, C. The Complex Interplay between Metabolic Reprogramming and Epigenetic Alterations in Renal Cell Carcinoma. Genes 2019, 10, 264. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wettersten, H.I.; Aboud, O.A.; Lara, P.N., Jr.; Weiss, R.H. Metabolic reprogramming in clear cell renal cell carcinoma. Nat. Rev. Nephrol. 2017, 13, 410–419. [Google Scholar] [CrossRef] [PubMed]
- Pomyen, Y.; Wanichthanarak, K.; Poungsombat, P.; Fahrmann, J.; Grapov, D.; Khoomrung, S. Deep metabolome: Applications of deep learning in metabolomics. Comput. Struct. Biotechnol. J. 2020, 18, 2818–2825. [Google Scholar] [CrossRef]
- Liebal, U.W.; Phan, A.N.T.; Sudhakar, M.; Raman, K.; Blank, L.M. Machine Learning Applications for Mass Spectrometry-Based Metabolomics. Metabolites 2020, 10, 243. [Google Scholar] [CrossRef]
- Cuperlovic-Culf, M. Machine Learning Methods for Analysis of Metabolic Data and Metabolic Pathway Modeling. Metabolites 2018, 8, 4. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Khan, S.R.; Manialawy, Y.; Wheeler, M.B.; Cox, B.J. Unbiased data analytic strategies to improve biomarker discovery in precision medicine. Drug. Discov. Today 2019, 24, 1735–1748. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, M.; Liu, X.; Sun, H.; Guo, Z.; Tang, X.; Wang, Z.; Li, J.; Li, H.; Sun, W.; et al. Urine Metabolomics for Renal Cell Carcinoma (RCC) Prediction: Tryptophan Metabolism as an Important Pathway in RCC. Front. Oncol. 2019, 9, 663. [Google Scholar] [CrossRef] [Green Version]
- Falegan, O.S.; Ball, M.W.; Shaykhutdinov, R.A.; Pieroraio, P.M.; Farshidfar, F.; Vogel, H.J.; Allaf, M.E.; Hyndman, M.E. Urine and Serum Metabolomics Analyses May Distinguish between Stages of Renal Cell Carcinoma. Metabolites 2017, 7, 6. [Google Scholar] [CrossRef] [Green Version]
- Manzi, M.; Palazzo, M.; Knott, M.E.; Beauseroy, P.; Yankilevich, P.; Gimenez, M.I.; Monge, M.E. Coupled Mass-Spectrometry-Based Lipidomics Machine Learning Approach for Early Detection of Clear Cell Renal Cell Carcinoma. J. Proteome Res. 2021, 20, 841–857. [Google Scholar] [CrossRef]
- Arendowski, A.; Ossolinski, K.; Ossolinska, A.; Ossolinski, T.; Niziol, J.; Ruman, T. Serum and urine analysis with gold nanoparticle-assisted laser desorption/ionization mass spectrometry for renal cell carcinoma metabolic biomarkers discovery. Adv. Med. Sci. 2021, 66, 326–335. [Google Scholar] [CrossRef]
- Niziol, J.; Ossolinski, K.; Tripet, B.P.; Copie, V.; Arendowski, A.; Ruman, T. Nuclear magnetic resonance and surface-assisted laser desorption/ionization mass spectrometry-based metabolome profiling of urine samples from kidney cancer patients. J. Pharm. Biomed. Anal. 2021, 193, 113752. [Google Scholar] [CrossRef]
- Fabian Pedregosa, G.V.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; Vanderplas, J.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Nembrini, S.; Konig, I.R.; Wright, M.N. The revival of the Gini importance? Bioinformatics 2018, 34, 3711–3718. [Google Scholar] [CrossRef] [Green Version]
- McKinney, W. Data structures for statistical computing in python. In Proceedings of the 9th Python in Science Conference 2010, Austin, TX, USA, 28 June–3 July 2010; Volume 445, pp. 56–61. [Google Scholar] [CrossRef] [Green Version]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Stéfan van der Walt, C.C.; Varoquaux, G. The NumPy Array: A Structure for Efficient Numerical Computation. Comput. Sci. Eng. 2011, 13, 22–30. [Google Scholar] [CrossRef] [Green Version]
- Oliphant, T.E. Python for Scientific Computing. Comput. Sci. Eng. 2007, 9, 10–20. [Google Scholar] [CrossRef] [Green Version]
- Seabold Skipper, J.P. Statsmodels: Econometric and statistical modeling with python. In Proceedings of the 9th Python in Science Conference 2010, Austin, TX, USA, 28 June–3 July 2010. [Google Scholar]
- Fernando Pérez, B.E.G. IPython: A System for Interactive Scientific Computing. Comput. Sci. Eng. 2007, 9, 21–29. [Google Scholar] [CrossRef]
- Hu, J.; Locasale, J.W.; Bielas, J.H.; O’Sullivan, J.; Sheahan, K.; Cantley, L.C.; Vander Heiden, M.G.; Vitkup, D. Heterogeneity of tumor-induced gene expression changes in the human metabolic network. Nat. Biotechnol. 2013, 31, 522–529. [Google Scholar] [CrossRef]
- Vander Heiden, M.G.; Cantley, L.C.; Thompson, C.B. Understanding the Warburg effect: The metabolic requirements of cell proliferation. Science 2009, 324, 1029–1033. [Google Scholar] [CrossRef] [Green Version]
- Jin, L.; Zhou, Y. Crucial role of the pentose phosphate pathway in malignant tumors. Oncol. Lett. 2019, 17, 4213–4221. [Google Scholar] [CrossRef] [Green Version]
- Seidel, A.; Brunner, S.; Seidel, P.; Fritz, G.I.; Herbarth, O. Modified nucleosides: An accurate tumour marker for clinical diagnosis of cancer, early detection and therapy control. Br. J. Cancer 2006, 94, 1726–1733. [Google Scholar] [CrossRef] [Green Version]
- Harada, F.; Nishimura, S. Possible anticodon sequences of tRNA His, tRNA Asm, and tRNA Asp from Escherichia coli B. Universal presence of nucleoside Q in the first postion of the anticondons of these transfer ribonucleic acids. Biochemistry 1972, 11, 301–308. [Google Scholar] [CrossRef]
- Pathak, C.; Jaiswal, Y.K.; Vinayak, M. Hypomodification of transfer RNA in cancer with respect to queuosine. RNA Biol. 2005, 2, 143–148. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, Q.; He, J. Enhanced expression of queuine tRNA-ribosyltransferase 1 (QTRT1) predicts poor prognosis in lung adenocarcinoma. Ann. Transl. Med. 2020, 8, 1658. [Google Scholar] [CrossRef]
- Emmerich, B.; Zubrod, E.; Weber, H.; Maubach, P.A.; Kersten, H.; Kersten, W. Relationship of queuine-lacking transfer RNA to the grade of malignancy in human leukemias and lymphomas. Cancer Res. 1985, 45, 4308–4314. [Google Scholar]
- Baranowski, W.; Dirheimer, G.; Jakowicki, J.A.; Keith, G. Deficiency of queuine, a highly modified purine base, in transfer RNAs from primary and metastatic ovarian malignant tumors in women. Cancer Res. 1994, 54, 4468–4471. [Google Scholar] [PubMed]
- Zhang, J.; Lu, R.; Zhang, Y.; Matuszek, Z.; Zhang, W.; Xia, Y.; Pan, T.; Sun, J. tRNA Queuosine Modification Enzyme Modulates the Growth and Microbiome Recruitment to Breast Tumors. Cancers 2020, 12, 628. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Teulings, F.A.; Mulder-Kooy, G.E.; Peters, H.A.; Fokkens, W.; Van Der Werf-Messing, B. The excretion of 3-hydroxyanthranilic acid in patients with bladder and kidney carcinoma. Acta Vitam. Enzym. 1975, 29, 108–112. [Google Scholar]
- Hornigold, N.; Dunn, K.R.; Craven, R.A.; Zougman, A.; Trainor, S.; Shreeve, R.; Brown, J.; Sewell, H.; Shires, M.; Knowles, M.; et al. Dysregulation at multiple points of the kynurenine pathway is a ubiquitous feature of renal cancer: Implications for tumour immune evasion. Br. J. Cancer 2020, 123, 137–147. [Google Scholar] [CrossRef] [PubMed]
- Badawy, A.A. Kynurenine Pathway of Tryptophan Metabolism: Regulatory and Functional Aspects. Int. J. Tryptophan Res. 2017, 10, 1178646917691938. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fallarino, F.; Grohmann, U.; Vacca, C.; Bianchi, R.; Orabona, C.; Spreca, A.; Fioretti, M.C.; Puccetti, P. T cell apoptosis by tryptophan catabolism. Cell Death Differ. 2002, 9, 1069–1077. [Google Scholar] [CrossRef]
- Hakimi, A.A.; Reznik, E.; Lee, C.H.; Creighton, C.J.; Brannon, A.R.; Luna, A.; Aksoy, B.A.; Liu, E.M.; Shen, R.; Lee, W.; et al. An Integrated Metabolic Atlas of Clear Cell Renal Cell Carcinoma. Cancer Cell 2016, 29, 104–116. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Commisso, C.; Davidson, S.M.; Soydaner-Azeloglu, R.G.; Parker, S.J.; Kamphorst, J.J.; Hackett, S.; Grabocka, E.; Nofal, M.; Drebin, J.A.; Thompson, C.B.; et al. Macropinocytosis of protein is an amino acid supply route in Ras-transformed cells. Nature 2013, 497, 633–637. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mizushima, N.; Komatsu, M. Autophagy: Renovation of cells and tissues. Cell 2011, 147, 728–741. [Google Scholar] [CrossRef] [Green Version]
- Vanholder, R.; De Smet, R.; Glorieux, G.; Argiles, A.; Baurmeister, U.; Brunet, P.; Clark, W.; Cohen, G.; De Deyn, P.P.; Deppisch, R.; et al. Review on uremic toxins: Classification, concentration, and interindividual variability. Kidney Int. 2003, 63, 1934–1943. [Google Scholar] [CrossRef] [Green Version]
- Sweedman, M.C.; Tizzotti, M.J.; Schafer, C.; Gilbert, R.G. Structure and physicochemical properties of octenyl succinic anhydride modified starches: A review. Carbohydr. Polym. 2013, 92, 905–920. [Google Scholar] [CrossRef]
- Shuch, B.; Linehan, W.M.; Srinivasan, R. Aerobic glycolysis: A novel target in kidney cancer. Expert Rev. Anticancer. 2013, 13, 711–719. [Google Scholar] [CrossRef] [Green Version]
- Ragone, R.; Sallustio, F.; Piccinonna, S.; Rutigliano, M.; Vanessa, G.; Palazzo, S.; Lucarelli, G.; Ditonno, P.; Battaglia, M.; Fanizzi, F.P.; et al. Renal Cell Carcinoma: A Study through NMR-Based Metabolomics Combined with Transcriptomics. Diseases 2016, 4, 7. [Google Scholar] [CrossRef]
- Falegan, O.S.; Arnold Egloff, S.A.; Zijlstra, A.; Hyndman, M.E.; Vogel, H.J. Urinary Metabolomics Validates Metabolic Differentiation Between Renal Cell Carcinoma Stages and Reveals a Unique Metabolic Profile for Oncocytomas. Metabolites 2019, 9, 155. [Google Scholar] [CrossRef] [Green Version]
- Icard, P.; Poulain, L.; Lincet, H. Understanding the central role of citrate in the metabolism of cancer cells. Biochim. Biophys. Acta 2012, 1825, 111–116. [Google Scholar] [CrossRef]
- Teng, L.; Chen, Y.; Cao, Y.; Wang, W.; Xu, Y.; Wang, Y.; Lv, J.; Li, C.; Su, Y. Overexpression of ATP citrate lyase in renal cell carcinoma tissues and its effect on the human renal carcinoma cells in vitro. Oncol. Lett. 2018, 15, 6967–6974. [Google Scholar] [CrossRef] [Green Version]
- Jain, M.; Nilsson, R.; Sharma, S.; Madhusudhan, N.; Kitami, T.; Souza, A.L.; Kafri, R.; Kirschner, M.W.; Clish, C.B.; Mootha, V.K. Metabolite profiling identifies a key role for glycine in rapid cancer cell proliferation. Science 2012, 336, 1040–1044. [Google Scholar] [CrossRef] [Green Version]
- Villa, E.; Ali, E.S.; Sahu, U.; Ben-Sahra, I. Cancer Cells Tune the Signaling Pathways to Empower de Novo Synthesis of Nucleotides. Cancers 2019, 11, 688. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.C.; Shyh-Chang, N.; Yang, H.; Rai, A.; Umashankar, S.; Ma, S.; Soh, B.S.; Sun, L.L.; Tai, B.C.; Nga, M.E.; et al. Glycine decarboxylase activity drives non-small cell lung cancer tumor-initiating cells and tumorigenesis. Cell 2012, 148, 259–272. [Google Scholar] [CrossRef] [Green Version]
- Reina-Campos, M.; Diaz-Meco, M.T.; Moscat, J. The complexity of the serine glycine one-carbon pathway in cancer. J. Cell Biol. 2020, 219, e201907022. [Google Scholar] [CrossRef]
- Glunde, K.; Bhujwalla, Z.M.; Ronen, S.M. Choline metabolism in malignant transformation. Nat. Rev. Cancer 2011, 11, 835–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, J.H.; Mehta, R.S.; Baek, H.M.; Nie, K.; Liu, H.; Lin, M.Q.; Yu, H.J.; Nalcioglu, O.; Su, M.Y. Clinical characteristics and biomarkers of breast cancer associated with choline concentration measured by 1H MRS. NMR Biomed. 2011, 24, 316–324. [Google Scholar] [CrossRef] [Green Version]
- Scheenen, T.W.; Futterer, J.; Weiland, E.; van Hecke, P.; Lemort, M.; Zechmann, C.; Schlemmer, H.P.; Broome, D.; Villeirs, G.; Lu, J.; et al. Discriminating cancer from noncancer tissue in the prostate by 3-dimensional proton magnetic resonance spectroscopic imaging: A prospective multicenter validation study. Investig. Radiol. 2011, 46, 25–33. [Google Scholar] [CrossRef]
- McKnight, T.R.; Lamborn, K.R.; Love, T.D.; Berger, M.S.; Chang, S.; Dillon, W.P.; Bollen, A.; Nelson, S.J. Correlation of magnetic resonance spectroscopic and growth characteristics within Grades II and III gliomas. J. Neurosurg. 2007, 106, 660–666. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Q.; Liu, H.; Zhang, K.; Li, C.; Zhou, G. Noninvasive evaluation of cerebral glioma grade by using multivoxel 3D proton MR spectroscopy. Magn. Reson. Imaging 2011, 29, 25–31. [Google Scholar] [CrossRef]
- Janfaza, S.; Khorsand, B.; Nikkhah, M.; Zahiri, J. Digging deeper into volatile organic compounds associated with cancer. Biol. Methods Protoc. 2019, 4, bpz014. [Google Scholar] [CrossRef]
- Amaro, F.; Pinto, J.; Rocha, S.; Araujo, A.M.; Miranda-Goncalves, V.; Jeronimo, C.; Henrique, R.; de Lourdes Bastos, M.; Carvalho, M.; de Pinho, P.G. Volatilomics Reveals Potential Biomarkers for Identification of Renal Cell Carcinoma: An In Vitro Approach. Metabolites 2020, 10, 174. [Google Scholar] [CrossRef] [PubMed]
- Sud, M.; Fahy, E.; Cotter, D.; Azam, K.; Vadivelu, I.; Burant, C.; Edison, A.; Fiehn, O.; Higashi, R.; Nair, K.S.; et al. Metabolomics Workbench: An international repository for metabolomics data and metadata, metabolite standards, protocols, tutorials and training, and analysis tools. Nucleic Acids Res. 2016, 44, D463–D470. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Early RCC | Advanced RCC | |
|---|---|---|
| No of Urine Samples | 41 | 29 |
| Mean Age ± SD | 60.1 ± 13.3 | 61.6 ± 13.2 a |
| Mean BMI ± SD | 29.9 ± 5.2 | 27.9 ± 6.2 b |
| Race | ||
| Caucasian | 26 (63.4%) | 21 (72.4%) |
| Black/African American | 14 (34.1%) | 5 (17.2%) |
| American-Indian/Alaskan- Native | 1 (2.4%) | 1 (3.4%) |
| Mixed | - | 1 (3.4%) |
| Unknown/Missing | - | 1 (3.4%) |
| Smoker | ||
| Never | 24 (58.5%) | 19 (65.5%) |
| Former/Current | 17 (41.5%) | 10 (34.5%) |
| Gender | ||
| Male | 19 (46.3%) | 20 (68.9%) |
| Female | 22 (53.7%) | 9 (31.1%) |
| Histological Subtypes | ||
| Pure Clear Cell | 23 (56.1%) | 26 (89.6%) |
| Papillary | 9 (21.9%) | 1 (3.4%) |
| Clear Cell Papillary | 4 (9.8%) | - |
| Chromophobe | 4 (9.8%) | - |
| Unclassified | 1 (2.4%) | 2 (6.9%) |
| Nuclear Grade | ||
| 1 | - | - |
| 2 | 21 (51.2%) | 3 (10.3%) |
| 3 | 17 (41.5%) | 10 (34.5%) |
| 4 | 3 (7.3%) | 16 (55.2%) |
| RCC Stage | ||
| I | 33 (80.5%) | - |
| II | 8 (19.5%) | - |
| III | - | 15 (51.7%) |
| IV | - | 14 (48.3%) |
| ID No. | Retention Time (min) | m/z | Adduct Type | Mass Error (ppm) | Elemental Formula | Metabolite Name | Confidence Level | |
|---|---|---|---|---|---|---|---|---|
| Theoretical | Experimental | |||||||
| 2745 | 1.87 | 223.0938 | 223.0936 | [M + H]+ | −0.64 | C8H10N6O2 | cytosine dimer | 2 |
| 3163 | 3.53 | 279.1187 | 279.1194 | [M + H]+ | 2.54 | C10H18N2O7 | - | 4 |
| 5362 | 3.46 | 245.0774 | 245.0775 | [M − H]− | 0.61 | C9H14N2O6 | dihydrouridine | 2 |
| 6681 | 2.80 | 244.0933 | 244.0934 | [M − H]− | 0.31 | C9H15N3O5 | hydroxyprolyl-asparagine/asparaginylhydroxyproline | 2 |
| ID | Retention Time (min) | m/z | Adduct Type | Mass Error (ppm) | Elemental Formula | Metabolite Identity | Confidence Level | |
|---|---|---|---|---|---|---|---|---|
| Theoretical | Experimental | |||||||
| 1372 | 3.94 | 146.0924 | 146.0924 | [M + H]+ | 0.03 | C5H11N3O2 | 4-guanidinobutanoic acid | 2 |
| 1904 | 4.00 | 180.0879 | 180.0880 | [M + H]+ | 0.08 | C7H9N5O | 7-aminomethyl-7-carbaguanine | 2 |
| 2122 | 1.20 | 184.1081 | 184.1080 | [M + H]+ | −0.36 | C8H13N3O2 | N,N-dimethyl-histidine | 2 |
| 2317 | 0.89, 0.89 | 203.0913, 422.2020 | 203.0912, 422.2023 | [M + H]+ | −0.44 0.71 | C9H14O5 | diethyl-2-methyl-3-oxosuccinate | 3 |
| 2465 | 0.89, 0.89 | 154.0498 136.0393 | 154.0497, 136.0392 | [M + H]+ | −0.62 −0.73 | C7H7NO3 | 3-hydroxyanthranilic acid | 2 |
| 3163 | 3.53 | 279.1187 | 279.1194 | [M + H]+ | 2.54 | C10H18N2O7 | -- | 4 |
| 3766 | 3.63 | 174.1237 | 174.1238 | [M + H]+ | 0.37 | C7H15N3O2 | apo-[3-methylcrotonoyl-CoA:carbon-dioxide ligase (ADP-forming)] | 2 |
| 4116 | 3.79 | 119.0577 | 119.0580 | [M + H]+ | 4.51 | C4H8NO3 | -- | 4 |
| 5045 | 3.49 | 218.0129 | 218.0123 | [M − H]− | −3.50 | C7H9NO5S | -- | 4 |
| 5420 | 3.38 | 205.0526 | 205.0535 | [M − H]− | 4.32 | C4H12N6P2 | -- | 4 |
| 5437 | 0.76 | 123.0114 | 123.0108 | [M − H]− | −4.47 | C9H2N | -- | 4 |
| 5713 | 1.23 | 305.0990 | 305.0989 | [M − H]− | −0.58 | C11H18N2O8 | -- | 4 |
| 5737 | 3.99 | 202.1197 | 202.1190 | [M − H]− | −3.58 | C8H17N3O3 | lys-gly/gly-lys | 2 |
| 5985 | 0.94 | 99.0087 | 99.0088 | [M − H]− | 0.21 | C4H4O3 | succinic anhydride | 2 |
| 6687 | 0.86 | 369.0517 | 369.0502 | [M − H]− | −4.30 | C6H14N10O5S2 | -- | 4 |
| 6694 | 3.82 | 409.9786 | 409.9770 | [M − H]− | −3.47 | C4H12N7O10P3 | -- | 4 |
| Metabolite/Features | 1H (ppm) | 13C(ppm) | Peak Patterns | Confidence Score | Fold Change | p-Value |
|---|---|---|---|---|---|---|
| acetone | 2.23 | 32.40 | (s) | 3 | 0.49 | 0.029 |
| pyruvate | 2.41 | - | (s) | 2 | 0.31 | 0.028 |
| citrate | 2.53 | 48.52 | (d) | 3 | −0.54 | 0.003 |
| choline | 3.19 | 56.69 | (s) | 3 | 0.22 | 0.026 |
| glycine | 3.56 | 44.18 | (s) | 3 | −0.66 | 0.032 |
| Metabolite or ID | Early RCC/Healthy Controls | Advanced RCC/Healthy Controls | Advanced RCC/Early RCC |
|---|---|---|---|
| citrate | 0.39 | −0.16 | −0.54 |
| choline | −0.21 | 0.02 | 0.22 |
| glycine | 0.82 | 0.16 | −0.66 |
| 3-hydroxyanthranilic acid | −0.87 | 0.53 | 1.41 |
| 5045 | −1.05 | −0.02 | 1.03 |
| cytosine dimer | −0.41 | 0.29 | 0.70 |
| lys-gly/gly-lys | 0.73 | 1.87 | 1.14 |
| 7-aminomethyl-7-carbaguanine | 0.69 | 2.07 | 1.38 |
| 5713 | −0.49 | 0.53 | 1.01 |
| hydroxyprolyl-asparagine/asparaginylhydroxyproline | 0.50 | 1.44 | 0.93 |
| pyruvate | 0.09 | 0.40 | 0.31 |
| 4-guanidinobutanoic acid | 0.49 | −0.63 | −1.12 |
| diethyl-2-methyl-3-oxosuccinate | −0.82 | 0.69 | 1.51 |
| succinic anhydride | −0.50 | 1.03 | 1.53 |
| acetone | 0.16 | 0.65 | 0.49 |
| 3163 | −0.36 | 1.17 | 1.53 |
| N,N-dimethyl-histidine | −0.24 | 0.87 | 1.12 |
| dihydrouridine | 0.22 | 1.07 | 0.80 |
| 5420 | 0.22 | 1.95 | 1.73 |
| 4116 | −0.09 | −1.33 | −1.24 |
| apo-[3-methylcrotonoyl-CoA:carbon-dioxide ligase (ADP-forming)] | 0.01 | 1.05 | 1.04 |
| 6687 | −2.53 | −1.20 | 1.33 |
| 5437 | −1.67 | 0.50 | 2.18 |
| 6694 | −1.02 | −2.32 | −1.30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bifarin, O.O.; Gaul, D.A.; Sah, S.; Arnold, R.S.; Ogan, K.; Master, V.A.; Roberts, D.L.; Bergquist, S.H.; Petros, J.A.; Edison, A.S.; et al. Urine-Based Metabolomics and Machine Learning Reveals Metabolites Associated with Renal Cell Carcinoma Stage. Cancers 2021, 13, 6253. https://doi.org/10.3390/cancers13246253
Bifarin OO, Gaul DA, Sah S, Arnold RS, Ogan K, Master VA, Roberts DL, Bergquist SH, Petros JA, Edison AS, et al. Urine-Based Metabolomics and Machine Learning Reveals Metabolites Associated with Renal Cell Carcinoma Stage. Cancers. 2021; 13(24):6253. https://doi.org/10.3390/cancers13246253
Chicago/Turabian StyleBifarin, Olatomiwa O., David A. Gaul, Samyukta Sah, Rebecca S. Arnold, Kenneth Ogan, Viraj A. Master, David L. Roberts, Sharon H. Bergquist, John A. Petros, Arthur S. Edison, and et al. 2021. "Urine-Based Metabolomics and Machine Learning Reveals Metabolites Associated with Renal Cell Carcinoma Stage" Cancers 13, no. 24: 6253. https://doi.org/10.3390/cancers13246253
APA StyleBifarin, O. O., Gaul, D. A., Sah, S., Arnold, R. S., Ogan, K., Master, V. A., Roberts, D. L., Bergquist, S. H., Petros, J. A., Edison, A. S., & Fernández, F. M. (2021). Urine-Based Metabolomics and Machine Learning Reveals Metabolites Associated with Renal Cell Carcinoma Stage. Cancers, 13(24), 6253. https://doi.org/10.3390/cancers13246253