1. Introduction
Lung diseases are one of the leading causes of death worldwide [
1], with lung cancer being the most common cause of cancer death [
2]. Radiation-induced lung damage (RILD) is a common side effect of treatment for lung cancer and is one of the main factors reducing quality of life in lung cancer survivors [
3]. RILD is usually distinguished into (a) acute phase appearances—pneumonitis, which occurs within 6 months following radiotherapy, and (b) permanent fibrosis, stabilising up to 24 months after the radiotherapy [
4]. Until recently, poor long-term survival of lung-cancer patients limited interest in RILD research [
5]. Current state-of-the-art treatment, however, results in longer survival [
6]. Therefore it is more important to consider the quality of life of survivors and, in turn, the underlying mechanisms of RILD.
RILD can be characterized using computed tomography (CT) imaging. CT scans are routinely acquired prior to radiotherapy treatment to assess the tumour and the lung, and CT imaging is repeated after radiotherapy to monitor for disease recurrence and assess for RILD. The follow-up scans can be used to study lung damage associated with radiotherapy by comparing the imaging to the baseline scans obtained before treatment. Typical post-radiotherapy radiological findings include parenchymal damage, lung volume shrinkage, and anatomical distortion, which can be used to describe and quantify RILD with image analysis techniques [
7]. Our team has previously proposed a suite of CT imaging-based RILD biomarkers [
8] that describe common changes in the anatomy and shape of the respiratory system. They characterize normal lung volume shrinkage, increase in parenchymal consolidation volumes, and changes in: shape of the lungs, diaphragm, central airways, mediastinum, and pleura. Their applicability has been successfully presented on a cohort of homogeneously treated patients on serial CT imaging of up to 24 months post-RT [
9]. Most of the RILD biomarkers were focused on describing and measuring changes to the shape and anatomy of the lungs rather than morphology of lung parenchyma. The original biomarker used to characterise parenchymal change quantified ‘consolidation volume’ as the ratio of high-intensity volume normalised to the contralateral lung. Such a binary classification of parenchymal tissue, based on thresholding, included vessels as part of the volume of damaged lung and over-simplified the complex gradation of changes visually observed in the scans. Furthermore, thresholding is susceptible to acquisition artefacts and intensity variability caused by different imaging protocols (inspiration, expiration, contrast enhancement, 4D CT, etc). An additional challenge might be related to the fact that a systematic increase in volume of the contralateral lung post-RT has been observed [
9]. Therefore, that approach might not be well suited for distinguishing morphological sub-types or accounting for changes in the contralateral lung.
The ability to identify and quantify localised RILD changes within the lung parenchyma can provide an additional dimension to the study of RILD. Ultimately, this will allow us to track local disease involvement and longitudinal evolution of damage and relate it to radiotherapy dose and clinical outcomes [
10]. Analysis of the temporal evolution of RILD parenchymal changes can provide new insights into radiotherapy dose and time relations. Early and accurate diagnosis of different types of lung parenchymal changes has already been shown to be crucial in ensuring that patients with interstitial lung disease (ILD) are treated optimally [
11]. That, however, required detailed consideration of clinical, radiological, and histopathological features, including different types on lung tissue patterns.
The existing global lung tissue damage scoring systems, such as the Radiation Therapy Oncology Group (RTOG) or European Organization for Research and Treatment of Cancer (EORTC), describe radiologic parenchyma changes in the lungs as slight, patchy, or dense [
12]. They can be subjective, with users regularly interpreting patchy areas as ground-glass opacities and dense areas as consolidation. In the Common Terminology Criteria for Adverse Events (CTCAE), the degree of “radiologic pulmonary fibrosis” can range from <25% to <75% for grades 1 to 3, and in grade 4 includes the presence of severe “honeycombing” [
13]. The differences in RTOG/EORTC and CTCAE guidelines lead to significant variations in grading depending on the system used. For instance, in the multicentre, non-randomized, phase 1/2 chemo-radiation trial of stage II/III non-small cell lung cancer, the IDEAL-CRT [
14], 12 months follow-up scans were mostly scored as 2 or 3 using RTOG classification, at the same time being given grade 1 using CTCEA classification [
8]. This is because across the majority of scans RILD changes were present (thereby scoring 2 and 3 in RTOG), but were restricted in terms of volume (resulting in grade 1 CTCEA scores). Another limitation of these approaches is their global nature, where a single score is given to the whole scan [
8,
15]. These scoring criteria are therefore inadequate for detailed descriptions of the complex heterogeneous nature of the RILD parenchymal changes and cannot describe the changes in a localised, voxel-wise manner.
The local parenchymal changes, especially their spatial distribution and temporal evolution due to RILD, have not been widely studied. There are studies looking directly into mean Hounsfield unit (HU) changes as a measure of lung density changes associated with RILD [
16,
17]. Bernchou et al. investigated regional CT density changes following intensity modulated radiotherapy (IMRT) for non-small-cell lung cancer (NSCLC) with relation to the prescribed local doses [
18]. The analysis relies purely on HU as the lung density description, which might be susceptible to the level of inhalation, contralateral lung hyperinflation, imaging artefacts, or acquisition protocols, and does not incorporate texture features of the lung parenchyma. There have been attempts to classify and quantify RILD using multiple radiomics-based approaches [
19], where 20 features were identified in randomly chosen patches to assess the correlation between change in the features before and after radiotherapy with relation to the prescribed dose. In that study, most features were strongly related to the mean HU of the patch and only higher order features represented patterns. Another study looked at differences in inter- and intra-observer variability in delineation of fibrotic lung regions [
20]. However, there was no comprehensive classification method introduced dedicated to studying the general morphology of RILD. In a recent study, Al Feghali et al. looked at lung density changes relying directly on differences in HUs of CT scans after performing rigid registration between different time point images [
21]. Such an approach is prone to errors originating from different levels of inhalation that rigid registration cannot compensate for, requires CT scans acquired with the same acquisition protocol (without contrast, and the same CT reconstruction kernels), and limits the interpretability of observed lung tissue patterns. In [
22] the authors highlight that RILD could be divided into even finer temporal stages: early, latent, exudative, intermediate, and fibrotic phases. However, the lack of a tissue classification system suitable for describing the local changes present at different stages, along with the need for manual annotations for such a process, limits the ability to explore their radiological appearances and their evolution over time on a larger dataset. Therefore, the existing approaches either lack ability to describe local radiological changes or are limited in their power to describe the range of morphological patterns encountered in RILD.
There is currently no established classification system of local parenchymal changes due to RILD and no available annotated RILD dataset, which could be used for training an automatic segmentation method. That is most likely for two reasons: first, the definition of lung tissue patterns to be annotated is a challenge itself, and second, performing manual annotations is a laborious task. In the context of other lung diseases, commercial software tools, like CALIPER [
23], are available for automatic lung tissue classification. However, CALIPER was designed for automatic segmentation of different radiological lung patterns most commonly observed with interstitial lung disease (ILD) and is not suitable for RILD application. CALIPER requires high spatial resolution scans acquired at breath-hold and works optimally on data acquired with specific reconstruction filters, and it is not intended for contrast enhanced scans, which are commonly used in lung cancer surveillance scans. Existing voxel-wise annotated datasets, which include an ILD dataset [
24], are not designed to allow the analysis of RILD, as several patterns included in these datasets are rarely if ever seen in RILD. The other limiting factor of the ILD dataset is its sparse annotation, where only sections of an individual slice, and a limited number of slices from a volumetric scan, were labelled. These labelled areas usually represent regions where the annotator had high confidence in the labels. Such an approach provides good examples for certain tissue classes, but makes global evaluation challenging, particularly for the less represented classes.
The existing methods of describing RILD parenchymal changes are either global in nature and lacked spatial specificity [
12,
13,
15] or do not characterise the different morphological patterns present in the scans in detail [
16,
17,
20], therefore, are not well suited for investigating longitudinal characteristics of RILD parenchymal change. The main goal of this work was to develop, implement, and validate a novel image analysis method for lung tissue classification in the context of RILD. Therefore, our contributions in this work are:
To the best of our knowledge, it is the first attempt to produce an automated, detailed, and voxel-wise description of RILD.
4. Discussion
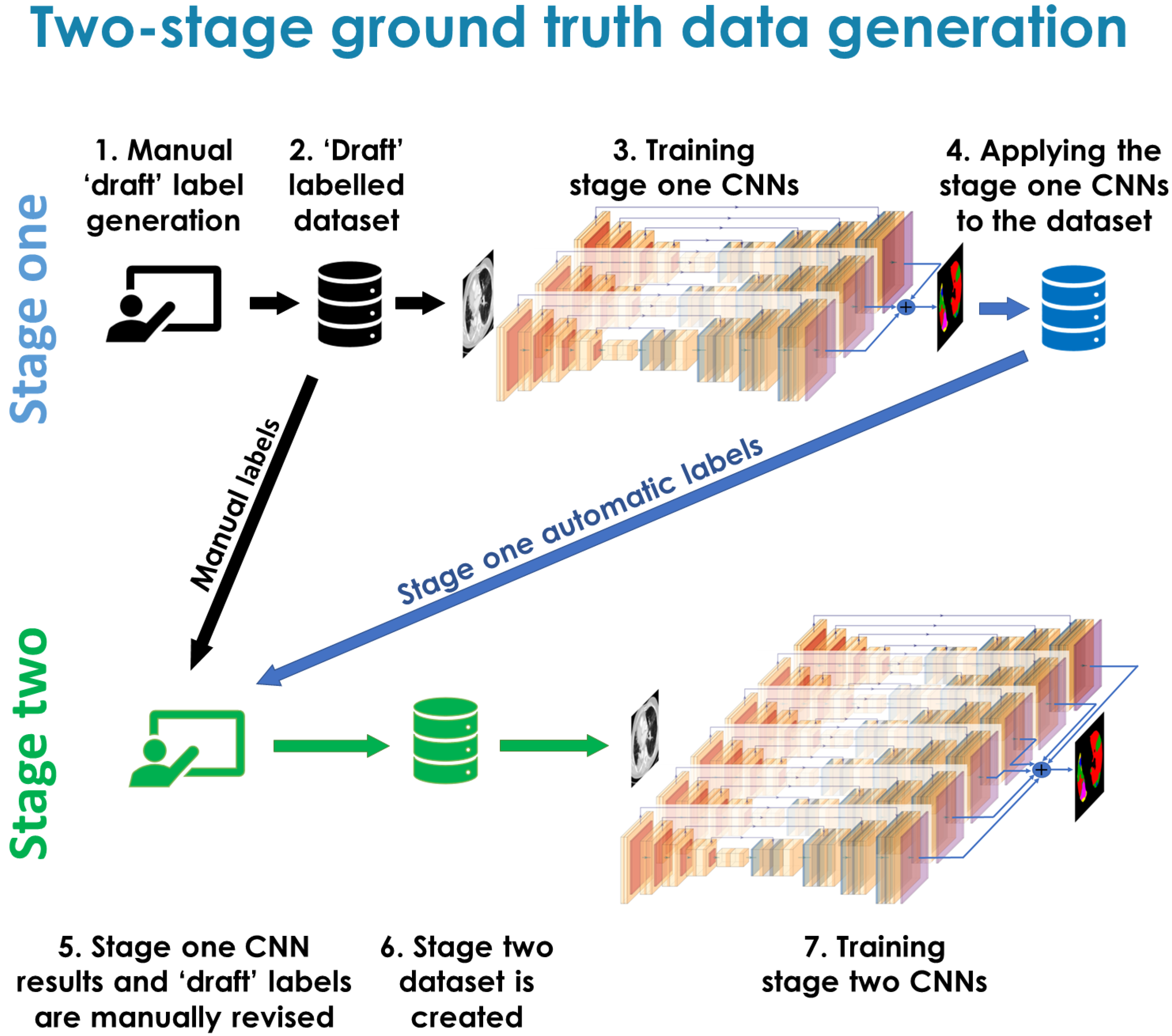
In this work we introduced a novel RILD-dedicated morphological lung tissue classification system. We used a two-stage ground truth label generation method, similar to the active learning approach. We developed a deep-learning framework, involving an ensemble of different 2D methods, to automatically generate the proposed labels. The work presented in this study addresses two challenges, first to introduce a labelling system suitable for capturing changes on longitudinal CT imaging that may be applicable to local RILD parenchymal change, and second to develop an automatic tool for their segmentation from unseen new data. It has been shown before that the global RILD characteristics change longitudinally [
9], however, local evolution of lung parenchymal changes remains rarely investigated.
During the development of the lung tissue labels, the main aim was to best capture RILD lung tissue parenchymal patterns in terms of lung tissue density and texture. The labels were devised with close discussion with an experienced thoracic radiologist. The main reason for creating morphological classes, rather than pathophysiological classes (for instance following classes used to describe ILD patterns, as in [
23,
24]), is that the pathophysiology of RILD parenchymal changes is not yet well understood, so defining classes based on morphology rather than pathophysiology allows for unbiased investigation of the radiologically observed changes in the parenchymal tissue. As RILD is very complicated and influenced by many factors including treatment, genetics, and underlying conditions [
22], the existing pre-assumptions originating from other lung pathologies could result in false interpretations. Solely morphological patterns could allow for novel insights in the analysis of their spatial and temporal evolution, without the context (e.g. patient history, treatment, or information from previous scans) that could potentially bias segmentation decisions. Our aim was first to establish a method of measuring the changes that can be observed in the scans. The images were annotated independently at every time point, which limited the bias of pre-assumptions imposed from the previous time points.
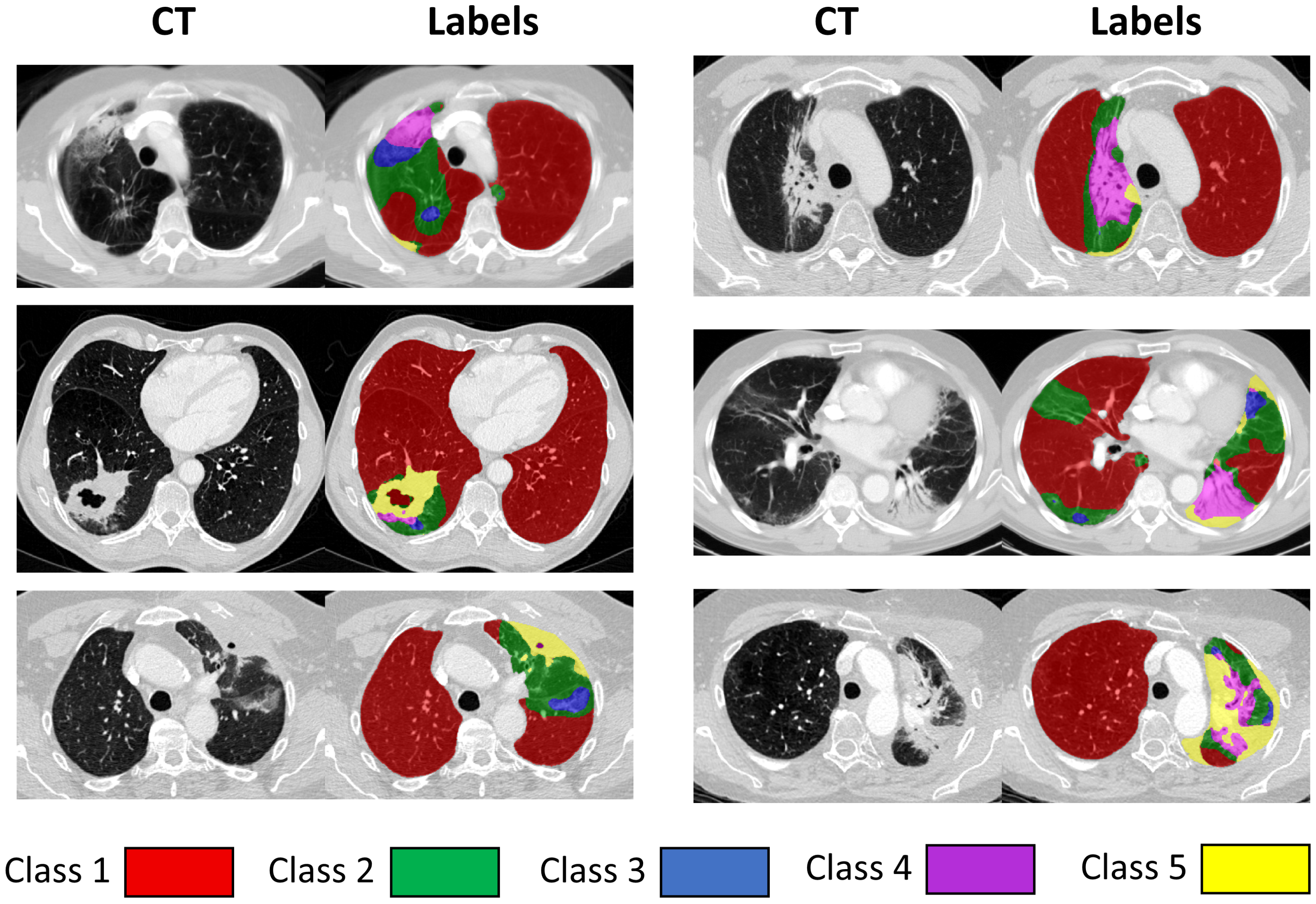
After thorough review of our data, we opted for five classes, as this allowed the annotators to robustly and confidently assign distinct labels to the classes, at the same time allowed for their meaningful gradation. In the process of developing the proposed classification system, some other classes were initially considered but eventually combined with one of the proposed classes if they were rarely present or were not well suited to describe RILD changes. For instance, pleural abnormalities were initially considered as a separate class, but this was subsumed under the Class 5 (describing opaque patterns) in order to maintain a purely morphological taxonomy. Pleural thickening is often continuous with lung parenchyma and a definitive boundary can often not be reliably distinguished on CT. Another class that was initially trialled aimed to describe ‘fibrosis’ and included honeycombing and reticulation (both representing irreversible lung damage in fibrotic lung disease). However, it was difficult to distinguish this pattern from traction bronchiectasis occurring on a background of emphysema based on its radiological appearance without context [
33], so it was included in Class 3. Additionally, it was a very rare label (present only in a handful of scans with a very small volume), and we assumed that it would be challenging to reliably train and evaluate an algorithm to segment such a minor class. In most of the cases the patients from our dataset presented with pre-existing damage in the lungs, which is unsurprising in a lung cancer population where smoking-induced lung damage is frequent. The proposed labelling system is not only capable of describing the RILD changes, but could potentially also be suitable for measuring other non-radiation induced pathologies, such as pneumonitis in patients receiving immunotherapy rather than radiotherapy. It is still possible to further subdivide the proposed classes, for instance to allow emphysematous lung or lung with air-trapping to be distinguished from normal lung in Class 1. We intend to do that in future work by relabelling emphysematous regions by a network trained on another dataset, for instance, ILD data.
Our method goes far beyond the other approaches investigated so far for RILD parenchymal changes, where only HU changes were considered [
16,
17]. The proposed method explores a wider range of tissue classes than just fibrosis [
20], allowing for a more detailed description of RILD paranchymal changes. Recently, much attention has been focused on COVID-19 lung related pathologies, when the majority of the approaches used binary abnormality classification [
34], with only a few studies extending analysis to more classes [
35].
The manual labelling process was inherently challenging due to the continuous nature of lung tissue changes, the subjective nature of assigning the labels, and the laborious nature of manual annotation in a voxel-wise manner of each individual scan. CNNs, with their ability to uncover differences in the images, as well as being trained on all of the images at once, had the potential to label the data in a more self-consistent manner. Ultimately, we wanted to develop an automatic CNN-based method to annotate the labels; therefore, we trained CNNs on the stage one manual labels with the aim of using the CNN labels and stage one manual labels to generate a revised set of ’ground-truth’ labels on the development dataset. During the revision step of the stage one manual and CNN generated labels for the same scans, it was often found that the CNN results were more consistent across the dataset. That was most likely due to the fact that the CNNs were effectively labelling them all at once. Indeed, the reason for using the two-stage approach was primarily because we hypothesized that it would result in more consistent and objective labels than doing a single stage of manual labelling.
In the ideal fully supervised approach, the labelling process would be conducted by a group of experts, providing an independent set of labels or by reaching consensus on the labels, which would serve as the ultimate ground truth. In the real world, this is very challenging due to human resource requirements. Based on our experience dealing with such a challenging segmentation task, we would still recommend a two-stage approach to help refine the classes, even if labels from multiple observers were available. The method can be perceived as joint work between a human and a machine, one supervising another, and to a certain extent serving the purpose of two annotators. The proposed two-stage data generation method can be applied to other tasks, where manual ground truth data are required but need to be generated, especially when the labels are initially not clear and subjective. The primary application of such approach would be to labels that are morphological, as CNNs are very well suited for finding underlying similarity in patterns and appearance, where context may act as a confounding factor.
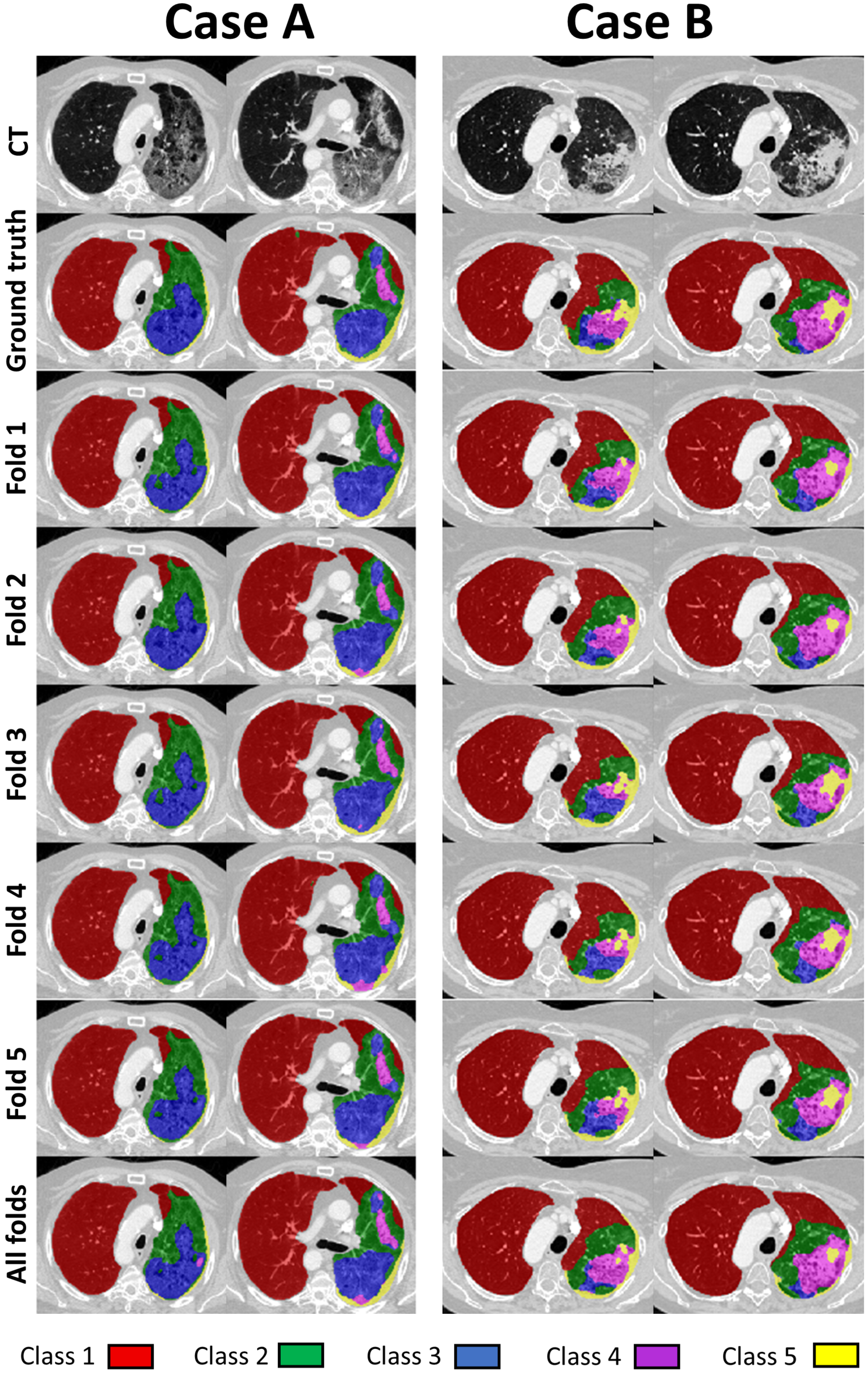
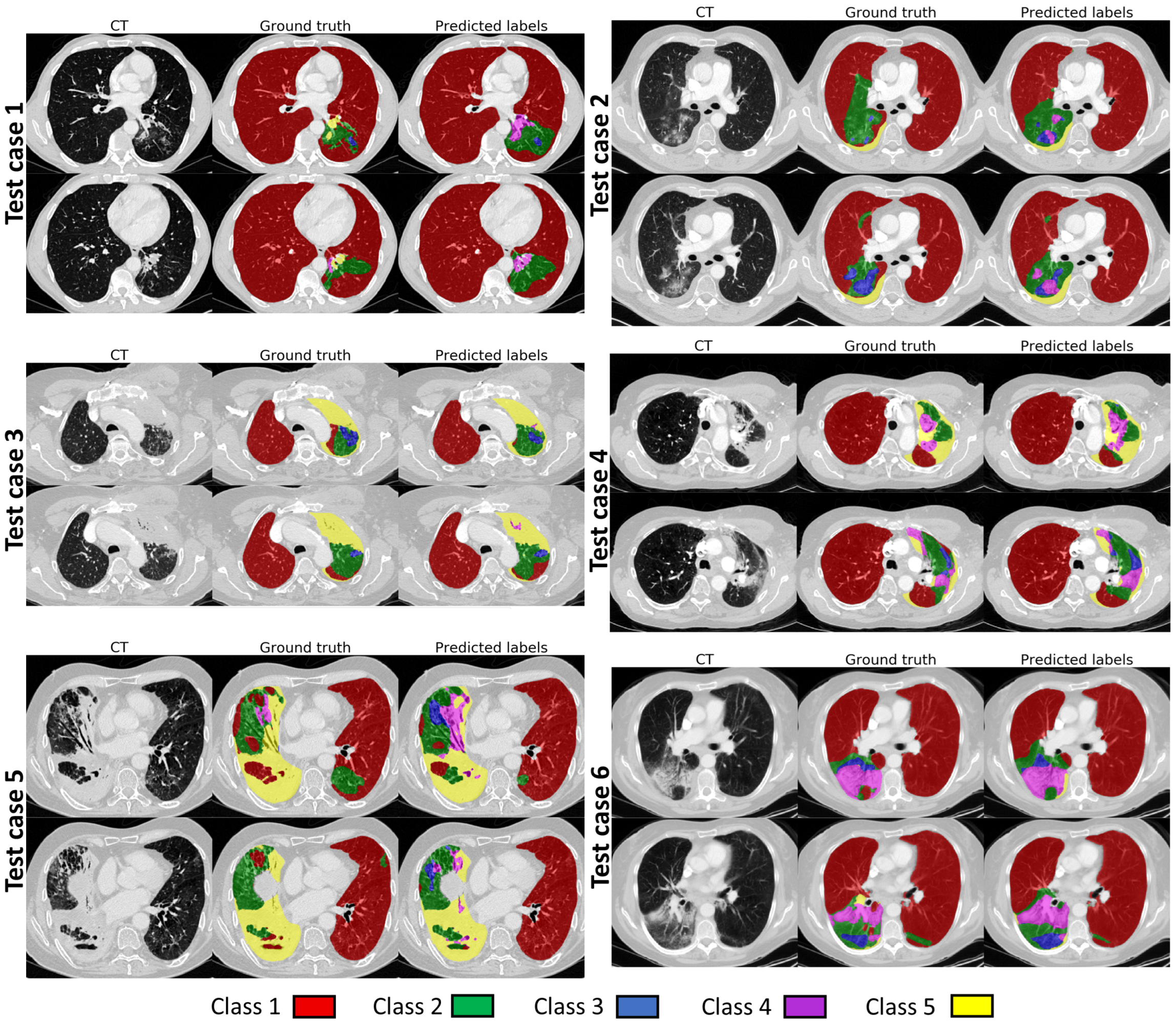
When the final network was evaluated on the hold out test dataset, the global Dice values were noticeably reduced when compared to the values for the validation data. The main reason for this is likely that the two-stage data labelling approach was used to produce the ground truth labels for the development dataset, but not for the test dataset. We did not want to apply the two-stage approach to the test data, as that could have potentially biased the development of the method and hence the results. However, this means that the test labels are likely less consistent and contain higher uncertainty than the labels for the development dataset. When the results of our automated segmentation method were compared visually with the ground truth, such as in
Figure 5, they showed a good level of visual agreement, even with very complicated underlying pathology.
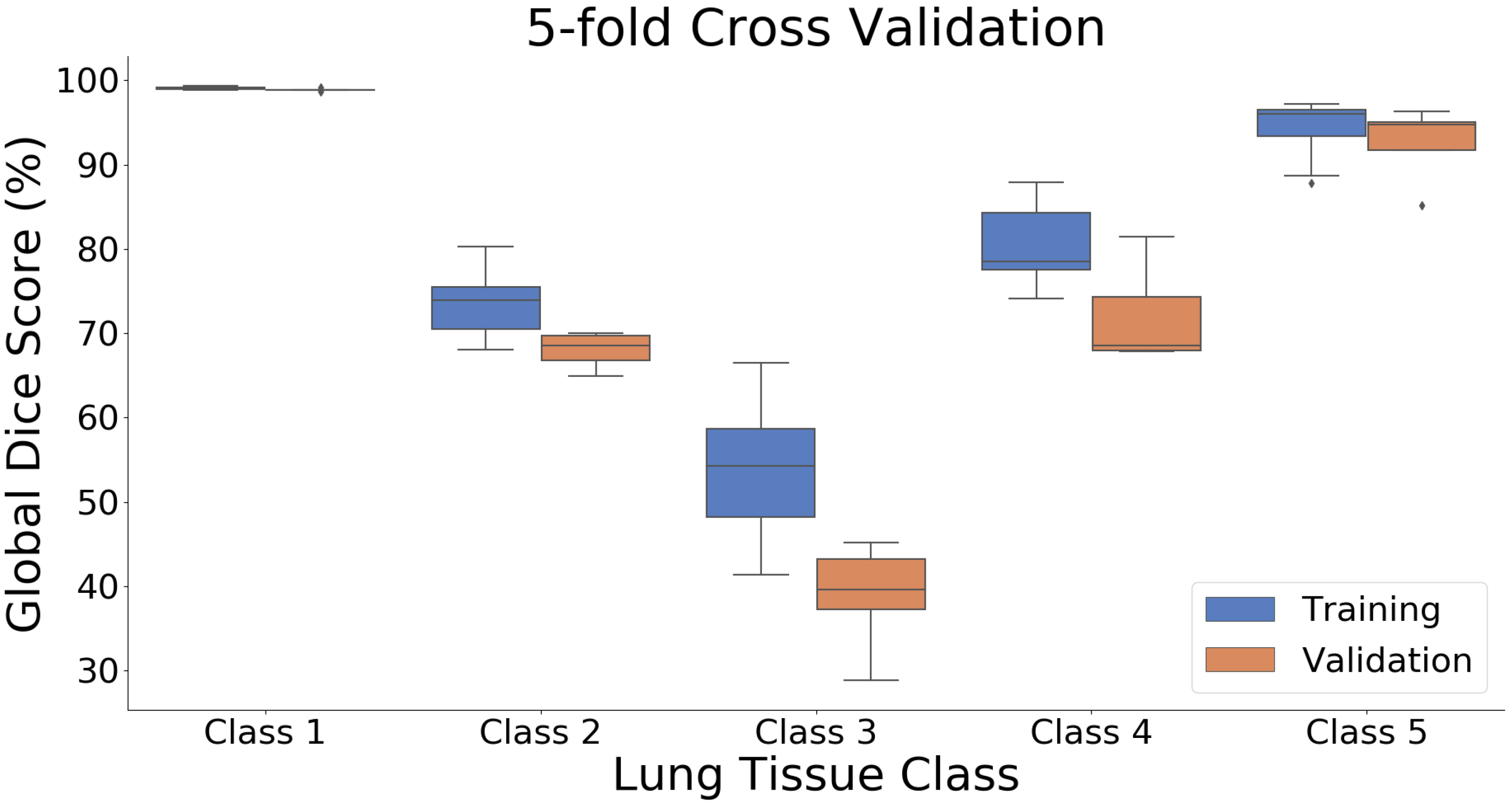
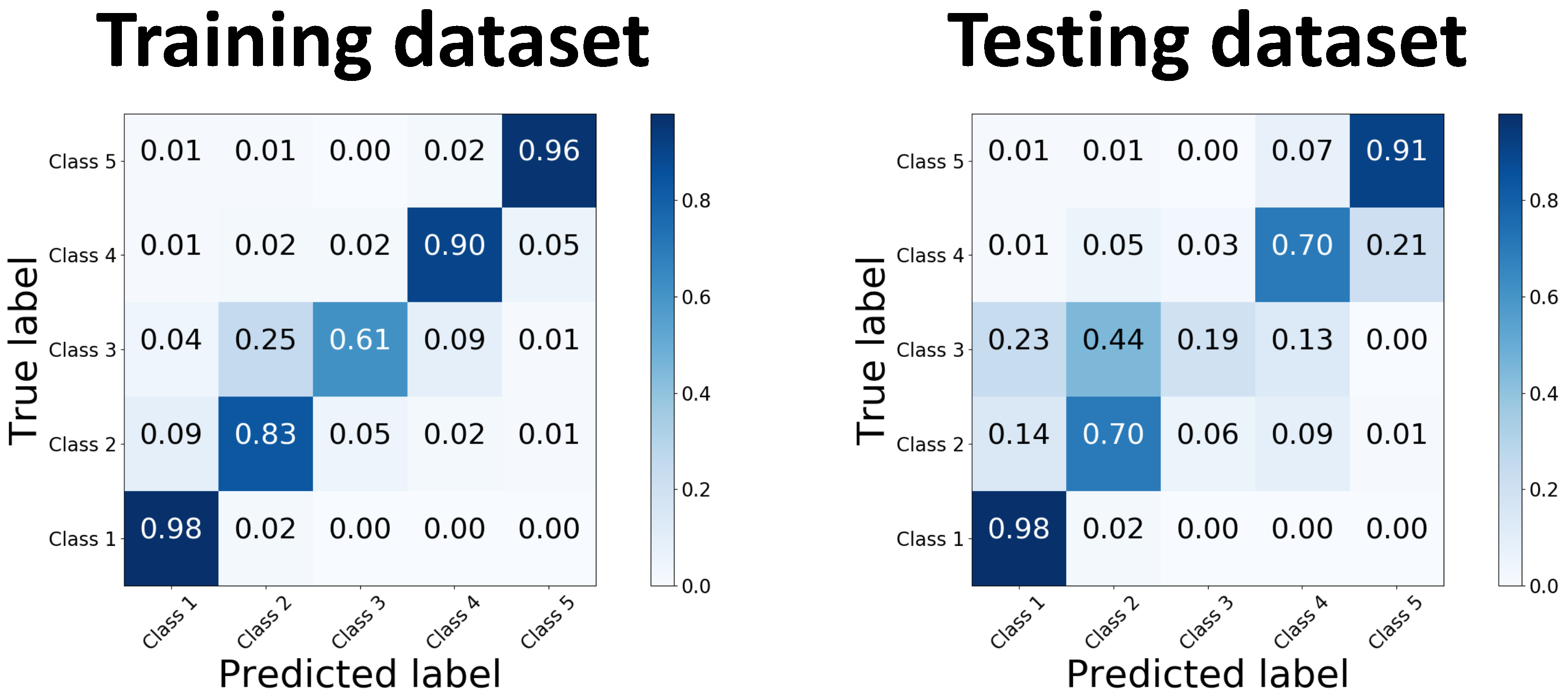
The qualitative evaluation supports the conclusion that our method is performing well, with almost as many cases being considered acceptable (88%) as for the manual segmentations (92.7%). We found that although the quantitative results for different classes varied on the testing dataset, ranging from 26% to 98% in terms of global Dice, they all performed more comparably in qualitative evaluation. An interesting observation is that the more represented classes, with theoretically higher confidence in annotation, received lower scores than underrepresented and more uncertain ones. This is in contrast to the quantitative evaluation observations, where more represented classes had superior global Dice values to the underrepresented ones. One potential explanation is that for classes with higher confidence in annotations, it is easier to identify when the segmentation is wrong (or not acceptable) but for the classes where there is more uncertainty it is harder to say the segmentations are definitely wrong, so they are considered acceptable.
The global Dice scores for the different classes were strongly influenced by the prevalence of each class in the data. The classes that included many voxels and were present in most or all slices had high global Dice values, whereas the classes that were only present in a few slices and were completely absent for some scans had low global Dice values [
36]. This is a well-known limitation of the Dice metric [
37] and is particularly evident for our application where there is also a high degree of uncertainty in the precise voxel-wise labelling of the classes, especially in the hold out test dataset. The Dice metric can be a useful tool for comparing the performance of different networks or methods on the same structures/classes, but it should be used with caution when comparing the performance of a method on different structures/classes, and in general is not an appropriate measure for validating that results are suitable for a specific application.
The data used in our study were from a multi-centre clinical trial. There were therefore significant differences in the scan resolution, acquisition protocols, and application of contrast. Acquisition parameters and image resolution in our dataset varied between patients and between time points for individual patients, with slice thickness ranging from 0.95 to 5 mm. We consider using such diverse data as a major strength of our work, as they better represent the diversity in scans seen in standard clinical practice. Therefore we would expect better generalisation of our trained networks on other datasets, although this will need to be verified and will be the focus of our future work. The diversity in the acquisition protocols and data quality was one of the reasons that supported our decision to apply a 2D approach. Otherwise we would need to resample the data or use patches containing a different anatomical region of the lungs. Using a 2D approach, our method could operate on 2D images similar to how a human observer would look at and segment CT images. That, however, restricted the field of view presented to the networks to just one slice.
One of the identified limitations of our automatic segmentation approach was its susceptibility to breathing motion artefacts or partial volume effect consequences, especially in the scans with larger slice thickness, when healthy regions close to diaphragm were occasionally classified as damaged tissue. These should have been limited at the image acquisition stage, when the scans are acquired at a breath-hold, therefore we were not initially considering any mitigation actions against them. Such artefacts might need an additional preprocessing or assessment step, which would identify cases that we suspect might not be suitable for being automatically processed or would require visual inspection. Alternatively, regions where motion artefacts were identified could be excluded from further analysis or classified as a new ’tissue class’ and used in the automated tissue training stage. Another possibility would be to include a dedicated data augmentation strategy at the training stage to help to limit their influence. The way in which a human observer deals with these challenges is by looking at adjacent slices and determining whether a pattern represents a manifestation of pathology or an acquisition artefact. That could be addressed by either incorporating 3D patches [
38,
39], which, however, comes with aforementioned challenges, or using only a few adjacent slices to predict labels for the middle slice [
40,
41], which we plan to explore in future.
In the proposed method we used manually segmented lung masks which were available for our dataset. Accurate segmentation of severely damaged lungs is very challenging by itself, and in this work we wanted to focus on the tissue classification task. For future work we would like to combine the proposed framework with an automatic lung segmentation method so it is suitable for fully automatic analysis of large volumes of data. A combination of the lung segmentation and tissue classification methods would have the ability to identify severely damaged or collapsed lungs, as, for instance, those with high level of opacity. That could help to identify cases where lung segmentation might perform sub-optimally and require manual inspection or corrections. It has been shown in a number of earlier studies that automatic lung segmentation methods tend to perform well in mild to moderately damaged lungs but mostly fail in severely damaged cases [
42,
43].
In this work we used an ensemble of relatively standard 2D UNets with well-known loss functions, as these have shown promising results in a wide range of medical imaging applications. Although these produced satisfactory results given the challenging and subjective nature of assigning voxel-wise tissue classifications, future work will explore state-of-the-art networks and methods that may give superior results to the standard networks used here.
In future work we aim to use our classes to investigate if and how tissue changes are linked to RILD pathophysiology. We have already conducted an analysis where we applied the presented classification method to investigate the degree of radiological change [
44]. In that study, the longitudinal data of 24 months follow up were registered to planning scans using a dedicated multi-channel deformable registration method [
45], tailored to deal with large anatomical changes. The analysis was conducted to investigate the distribution and evolution of the lung tissue classes with respect to the dose delivered to the tumour and the change in lung function of lung cancer patients. We observed a strong dose-dependent relationship between the proposed classes characteristics and locally prescribed doses.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}