

Evaluating Recalibrating AI Models for Breast Cancer Diagnosis in a New Context: Insights from Transfer Learning, Image Enhancement and High-Quality Training Data Integration
 , ,
, ,
Abstract
:Simple Summary
Abstract
1. Introduction
- (1)
- Comparing the performance of these models on an Australian dataset, which differs from their original training data (both in terms of population characteristics and the types of mammography machines (vendors) used), highlighting the influence of dataset variations on predictions.
- (2)
- Investigating the potential improvement of model performance through transfer learning and, hence, the value of tailoring the AI models for other nationalities’ contexts.
- (3)
- Examining the impact of image enhancement techniques on model predictions to assess their potential to enhance diagnostic accuracy.
- (4)
- Exploring the association between the AI models’ malignancy probability outputs and histopathological features, offering insights into the models’ predictive accuracy and potential clinical relevance, aiding further treatment/triaging decision making.
2. Materials and Methods
2.1. Data Acquisition
2.2. AI Models
2.2.1. Globally-Aware Multiple Instance Classifier (GMIC)
2.2.2. Global-Local Activation Maps (GLAM)
2.2.3. I&H
2.2.4. End2End
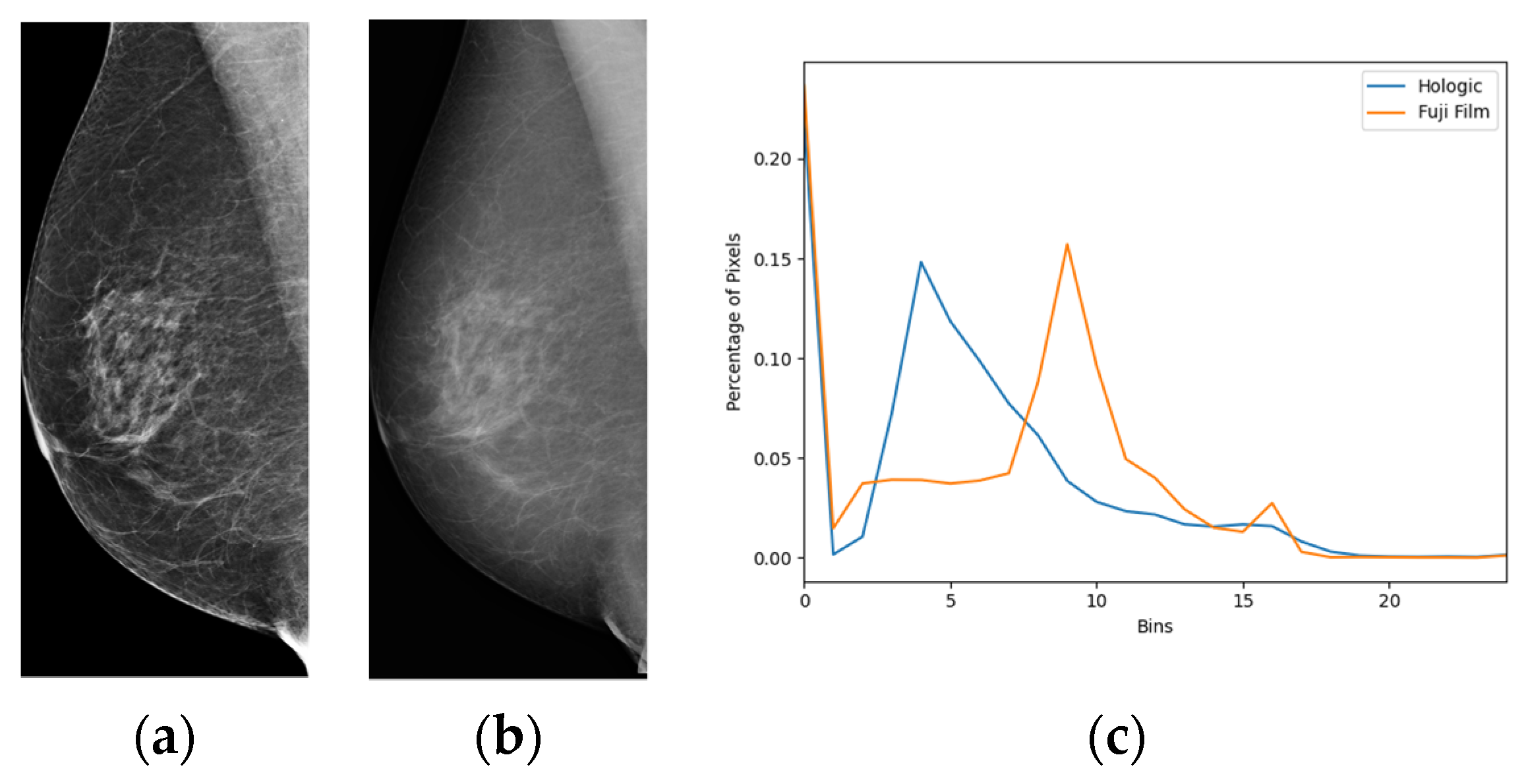
2.3. Image Enhancement
2.4. Transfer Learning
2.5. Evaluation Metrics
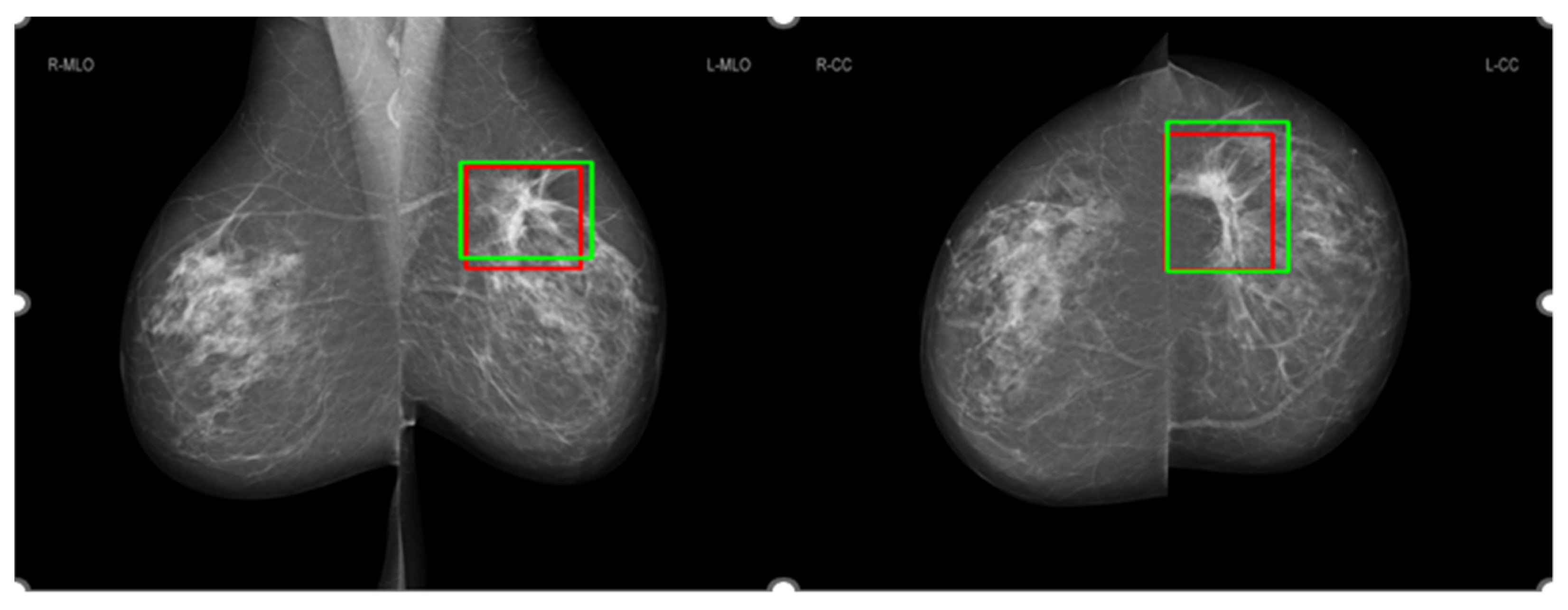
2.6. Association between the Malignancy Probability from the AI and Histopathological Features
3. Results
3.1. The Performances of Four AI Models
3.2. Pairwise Comparisons of Four AI Models
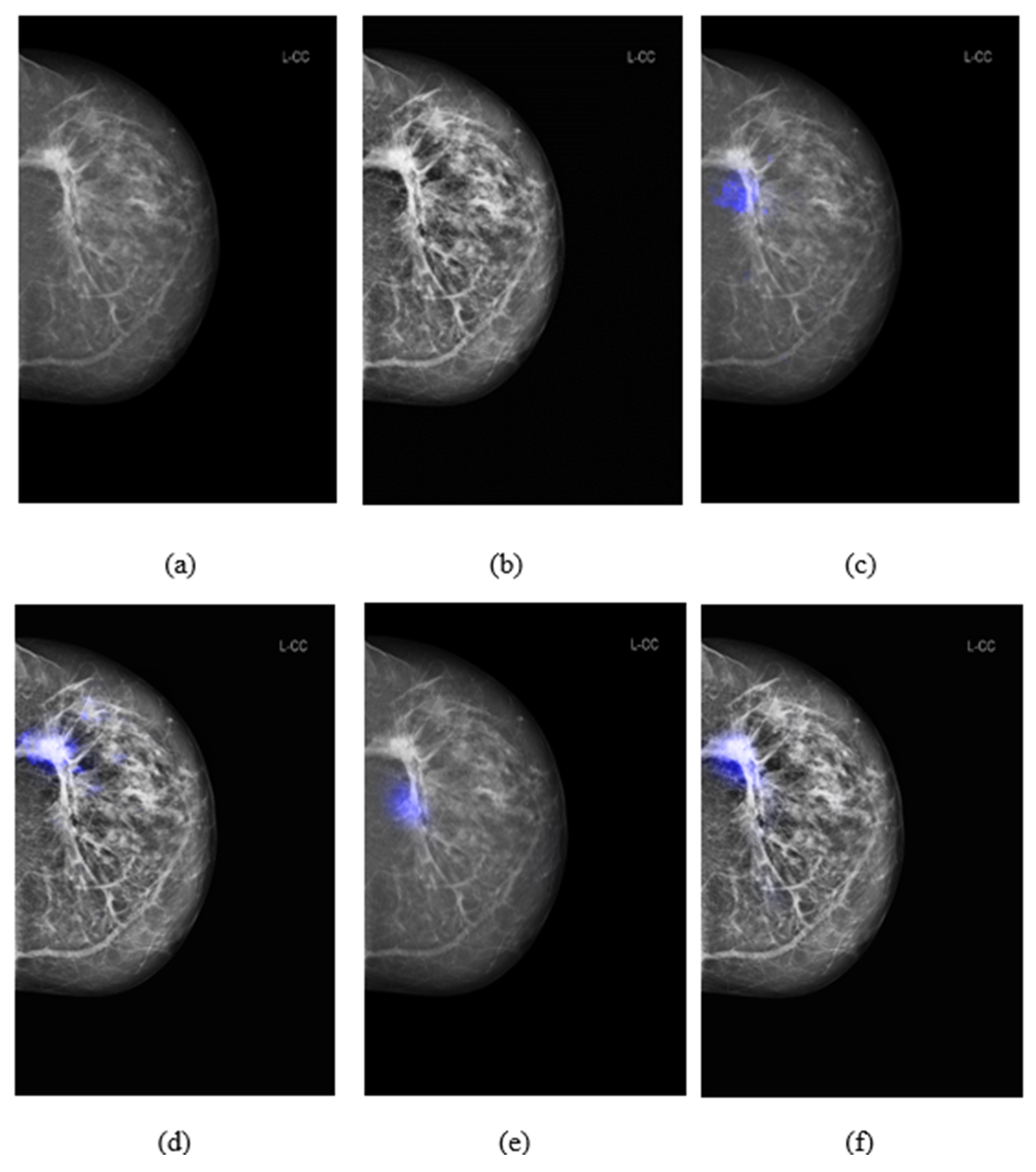
3.3. Comparison of Salience Maps on Original and Locally Enhanced Mammographic Images
3.4. Association between the Malignancy Probability from the AI and Histopathological Features
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef]
- Paci, E.; Broeders, M.; Hofvind, S.; Puliti, D.; Duffy, S.W. European breast Cancer service screening outcomes: A first balance sheet of the benefits and harms. Cancer Epidemiol. Biomark. Prev. 2014, 23, 1159–1163. [Google Scholar] [CrossRef] [PubMed]
- Kopans, D.B. An open letter to panels that are deciding guidelines for breast cancer screening. Breast Cancer Res. Treat. 2015, 151, 19–25. [Google Scholar] [CrossRef] [PubMed]
- Carney, P.A.; Miglioretti, D.L.; Yankaskas, B.C.; Kerlikowske, K.; Rosenberg, R.; Rutter, C.M.; Geller, B.M.; Abraham, L.A.; Taplin, S.H.; Dignan, M.; et al. Individual and combined effects of age, breast density, and hormone replacement therapy use on the accuracy of screening mammography. Ann. Intern. Med. 2003, 138, 168–175. [Google Scholar] [CrossRef] [PubMed]
- Al Mousa, D.S.; Brennan, P.C.; Ryan, E.A.; Lee, W.B.; Tan, J.; Mello-Thoms, C. How Mammographic Breast Density Affects Radiologists’ Visual Search Patterns. Acad. Radiol. 2014, 21, 1386–1393. [Google Scholar] [CrossRef] [PubMed]
- Chong, A.; Weinstein, S.P.; McDonald, E.S.; Conant, E.F. Digital Breast Tomosynthesis: Concepts and Clinical Practice. Radiology 2019, 292, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Chiu, H.Y.; Chao, H.S.; Chen, Y.M. Application of Artificial Intelligence in Lung Cancer. Cancers 2022, 14, 1370. [Google Scholar] [CrossRef]
- Othman, E.; Mahmoud, M.; Dhahri, H.; Abdulkader, H.; Mahmood, A.; Ibrahim, M. Automatic Detection of Liver Cancer Using Hybrid Pre-Trained Models. Sensors 2022, 22, 5429. [Google Scholar] [CrossRef]
- Akinyelu, A.A.; Zaccagna, F.; Grist, J.T.; Castelli, M.; Rundo, L. Brain Tumor Diagnosis Using Machine Learning, Convolutional Neural Networks, Capsule Neural Networks and Vision Transformers, Applied to MRI: A Survey. J. Imaging 2022, 8, 205. [Google Scholar] [CrossRef]
- Wu, N.; Phang, J.; Park, J.; Shen, Y.; Huang, Z.; Zorin, M.; Jastrzebski, S.; Fevry, T.; Katsnelson, J.; Kim, E.; et al. Deep Neural Networks Improve Radiologists’ Performance in Breast Cancer Screening. IEEE Trans. Med. Imaging 2020, 39, 1184–1194. [Google Scholar] [CrossRef]
- McKinney, S.M.; Sieniek, M.; Godbole, V.; Godwin, J.; Antropova, N.; Ashrafian, H.; Back, T.; Chesus, M.; Corrado, G.S.; Darzi, A.; et al. International evaluation of an AI system for breast cancer screening. Nature 2020, 577, 89–94. [Google Scholar] [CrossRef] [PubMed]
- Shen, L.; Margolies, L.R.; Rothstein, J.H.; Fluder, E.; McBride, R.; Sieh, W. Deep Learning to Improve Breast Cancer Detection on Screening Mammography. Sci. Rep. 2019, 9, 12495. [Google Scholar] [CrossRef]
- Al-Masni, M.; Al-Antari, M.; Park, J.M.; Gi, G.; Kim, T.Y.; Rivera, P.; Valarezo, E.; Choi, M.T.; Han, S.M.; Kim, T.S. Simultaneous detection and classification of breast masses in digital mammograms via a deep learning YOLO-based CAD system. Comput. Methods Programs Biomed. 2018, 157, 85–94. [Google Scholar] [CrossRef] [PubMed]
- Dhungel, N.; Carneiro, G.; Bradley, A.P. A deep learning approach for the analysis of masses in mammograms with minimal user intervention. Med. Image Anal. 2017, 37, 114–128. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Cao, Z.; Zhang, Y.; Tang, Y.; Lin, X.; Ouyang, R.; Wu, M.; Han, M.; Xiao, J.; Huang, L.; et al. MommiNet-v2: Mammographic multi-view mass identification networks. Med. Image Anal. 2021, 73, 102204. [Google Scholar] [CrossRef]
- Shen, Y.; Wu, N.; Phang, J.; Park, J.; Liu, K.; Tyagi, S.; Heacock, L.; Kim, S.G.; Moy, L.; Cho, K.; et al. An interpretable classifier for high-resolution breast cancer screening images utilizing weakly supervised localization. Med. Image Anal. 2021, 68, 101908. [Google Scholar] [CrossRef]
- Liu, K.; Shen, Y.; Wu, N.; Chledowski, J.; Fernandez-Granda, C.; Geras, K. Weakly-supervised High-resolution Segmentation of Mammography Images for Breast Cancer Diagnosis. Proc. Mach. Learn. Res. 2021, 143, 268–285. [Google Scholar] [PubMed]
- Ueda, D.; Yamamoto, A.; Onoda, N.; Takashima, T.; Noda, S.; Kashiwagi, S.; Morisaki, T.; Fukumoto, S.; Shiba, M.; Morimura, M.; et al. Development and validation of a deep learning model for detection of breast cancers in mammography from multi-institutional datasets. PLoS ONE 2022, 17, e0265751. [Google Scholar] [CrossRef]
- Yap, M.H.; Pons, G.; Marti, J.; Ganau, S.; Sentis, M.; Zwiggelaar, R.; Davison, A.K.; Marti, R.; Moi Hoon, Y.; Pons, G.; et al. Automated Breast Ultrasound Lesions Detection Using Convolutional Neural Networks. IEEE J. Biomed. Health Inform. 2018, 22, 1218–1226. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. arXiv 2019, arXiv:1911.02685. [Google Scholar] [CrossRef]
- Mina, L.M.; Mat Isa, N.A. Breast abnormality detection in mammograms using Artificial Neural Network. In Proceedings of the 2015 International Conference on Computer, Communications, and Control Technology (I4CT), Kuching, Malaysia, 21–23 April 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Karel, Z. Contrast limited adaptive histogram equalization. In Graphics Gems IV; Academic Press Professional, Inc.: Cambridge, MA, USA, 1994; pp. 474–485. [Google Scholar]
- Lin, L.I.-K. A concordance correlation coefficient to evaluate reproducibility. Biometrics 1989, 45, 255–268. [Google Scholar] [CrossRef]
- McBride, G.; Bland, J.M.; Altman, D.G.; Lin, L.I. A proposal for strength of agreement criteria for lin’s concordance correlation coefficient. In NIWA Client Report HAM2005-062; National Institute of Water & Atmospheric Research Ltd.: Hamilton, New Zealand, 2005. [Google Scholar]
- Rezatofighi, S.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. arXiv 2019, arXiv:1902.09630. [Google Scholar]
- Boels, L.; Bakker, A.; Dooren, W.; Drijvers, P. Conceptual difficulties when interpreting histograms: A review. Educ. Res. Rev. 2019, 28, 100291. [Google Scholar] [CrossRef]
- Elbatel, M. Mammograms Classification: A Review. arXiv 2022, arXiv:2203.03618. [Google Scholar]
- Mastyło, M. Bilinear interpolation theorems and applications. J. Funct. Anal. 2013, 265, 185–207. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Min, H.; Wilson, D.; Huang, Y.; Liu, S.; Crozier, S.; Bradley, A.; Chandra, S. Fully Automatic Computer-aided Mass Detection and Segmentation via Pseudo-color Mammograms and Mask R-CNN. In Proceedings of the 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1111–1115. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- DeLong, E.; DeLong, D.; Clarke-Pearson, D. Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef]
- Fluss, R.; Faraggi, D.; Reiser, B. Estimation of the Youden Index and its associated cutoff point. Biom. J. 2005, 47, 458–472. [Google Scholar] [CrossRef]
- Wu, N.; Phang, J.; Park, J.; Shen, Y.; Kim, S.G.; Heacock, L.; Moy, L.; Cho, K.; Geras, K.J. The NYU Breast Cancer Screening Dataset v1.0.; Technical Report; NYU Computer Science: New York, NY, USA, 2019. [Google Scholar]
- Lee, R.S.; Gimenez, F.; Hoogi, A.; Rubin, D. Curated Breast Imaging Subset of DDSM. Cancer Imaging Arch. 2016, 4, 170–177. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Zhang, B. Image enhancement based on equal area dualistic sub-image histogram equalization method. IEEE Trans. Consum. Electron. 1999, 45, 68–75. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original | Transfer Learning | |||||
|---|---|---|---|---|---|---|
| AUCEntire | AUCHigh | p-Values | AUCEntire | AUCHigh | p-Values | |
| GMIC | 0.824 | 0.865 | 0.0283 | 0.883 | 0.91 | 0.0416 |
| GLAM | 0.817 | 0.858 | 0.0305 | 0.877 | 0.906 | 0.0359 |
| I&H | 0.806 | 0.842 | 0.0454 | 0.852 | 0.891 | 0.0257 |
| End2End | 0.784 | 0.819 | 0.0368 | 0.824 | 0.874 | 0.0162 |
| GMIC + CLAHE | 0.836 | 0.870 | 0.0137 | 0.889 | 0.912 | 0.0348 |
| GLAM + CLAHE | 0.825 | 0.864 | 0.0181 | 0.886 | 0.909 | 0.0310 |
| I&H + CLAHE | 0.812 | 0.845 | 0.0339 | 0.855 | 0.893 | 0.0185 |
| End2End + CLAHE | 0.793 | 0.821 | 0.0286 | 0.828 | 0.875 | 0.0124 |
| AUCEntire | AUCHigh | |
|---|---|---|
| GMIC | <0.001 | 0.0034 |
| GLAM | <0.001 | 0.0041 |
| I&H | <0.001 | 0.0002 |
| End2End | 0.0093 | 0.0008 |
| GMIC + CLAHE | <0.001 | 0.004 |
| GLAM + CLAHE | <0.001 | 0.0121 |
| I&H + CLAHE | <0.001 | 0.0032 |
| End2End + CLAHE | 0.0219 | 0.001 |
| Model Images | Without Transferred Learning, Original | Without Transferred Learning, CLAHE | With Transferred Learning, Original | With Transferred Learning, CLAHE | ||||
|---|---|---|---|---|---|---|---|---|
| Dataset | Entire | High | Entire | High | Entire | High | Entire | High |
| GMIC vs. GLAM | 0.0362 | 0.0624 | 0.0331 | 0.0566 | 0.0193 | 0.0233 | 0.0141 | 0.0215 |
| GMIC vs. I&H | 0.0175 | 0.0387 | 0.0108 | 0.0369 | 0.0076 | 0.0135 | 0.0058 | 0.0121 |
| GMIC vs. End2End | 0.0062 | 0.0078 | 0.0049 | 0.0062 | 0.0027 | 0.0041 | 0.0015 | 0.0030 |
| GLAM vs. I&H | 0.0236 | 0.0294 | 0.0217 | 0.0279 | 0.0061 | 0.0093 | 0.0020 | 0.0075 |
| GLAM vs. End2End | 0.0064 | 0.0186 | 0.0059 | 0.017 | 0.0073 | 0.0142 | 0.0057 | 0.0128 |
| I&H vs. End2End | 0.0081 | 0.0351 | 0.0025 | 0.0344 | 0.0220 | 0.0327 | 0.0106 | 0.0310 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Z.; Gandomkar, Z.; Trieu, P.D.; Tavakoli Taba, S.; Barron, M.L.; Obeidy, P.; Lewis, S.J. Evaluating Recalibrating AI Models for Breast Cancer Diagnosis in a New Context: Insights from Transfer Learning, Image Enhancement and High-Quality Training Data Integration. Cancers 2024, 16, 322. https://doi.org/10.3390/cancers16020322
Jiang Z, Gandomkar Z, Trieu PD, Tavakoli Taba S, Barron ML, Obeidy P, Lewis SJ. Evaluating Recalibrating AI Models for Breast Cancer Diagnosis in a New Context: Insights from Transfer Learning, Image Enhancement and High-Quality Training Data Integration. Cancers. 2024; 16(2):322. https://doi.org/10.3390/cancers16020322
Chicago/Turabian StyleJiang, Zhengqiang, Ziba Gandomkar, Phuong Dung (Yun) Trieu, Seyedamir Tavakoli Taba, Melissa L. Barron, Peyman Obeidy, and Sarah J. Lewis. 2024. "Evaluating Recalibrating AI Models for Breast Cancer Diagnosis in a New Context: Insights from Transfer Learning, Image Enhancement and High-Quality Training Data Integration" Cancers 16, no. 2: 322. https://doi.org/10.3390/cancers16020322
APA StyleJiang, Z., Gandomkar, Z., Trieu, P. D., Tavakoli Taba, S., Barron, M. L., Obeidy, P., & Lewis, S. J. (2024). Evaluating Recalibrating AI Models for Breast Cancer Diagnosis in a New Context: Insights from Transfer Learning, Image Enhancement and High-Quality Training Data Integration. Cancers, 16(2), 322. https://doi.org/10.3390/cancers16020322