NADAL: A Neighbor-Aware Deep Learning Approach for Inferring Interpersonal Trust Using Smartphone Data


Abstract
:1. Introduction
- First effort to use neighboring relationships’ behavioral features for inferring interpersonal trust between two people.
- First effort to custom-design a deep learning architecture that leverages neighboring relationship properties to better model interpersonal trust.
2. Related Work
2.1. Trust as a Field of Study
2.2. Measuring Interpersonal Trust
2.3. Computational Modeling of Trust
2.4. Modeling Individuals and Relationships Based on Their Neighbors
2.5. Using Phone Logs and Machine Learning to Understand Individuals and Relationships
3. Datasets
- “Would you ask person X for help in sickness?”
- “Would you ask person X for a hundred-dollar loan?”
- “Would you ask person X for babysitting?”
3.1. Mobile Phone (Smartphone) Data Features
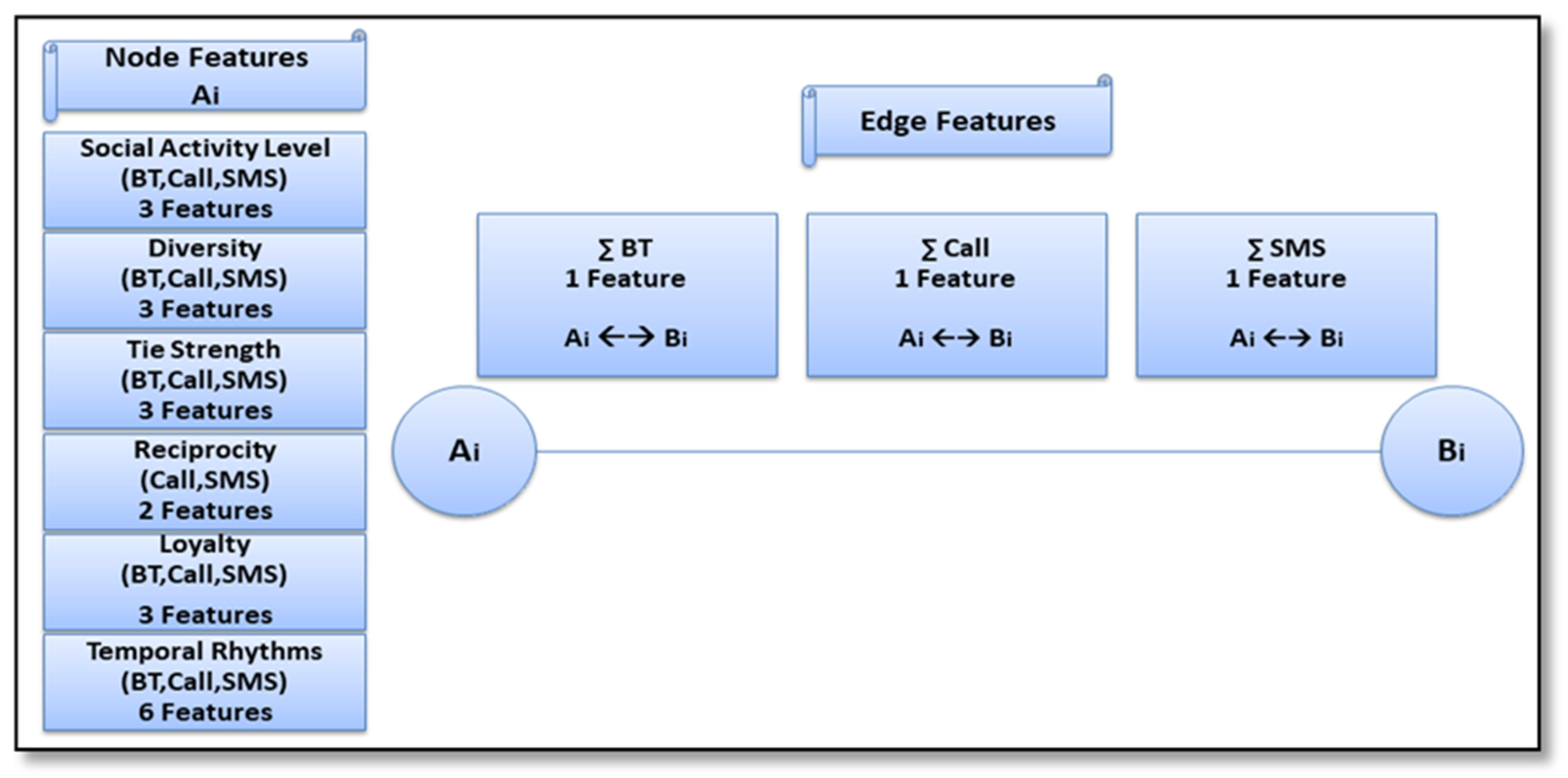
3.1.1. Node Properties
3.1.2. Edge Properties
4. Method
4.1. Dealing with Class Imbalance in the Datasets
4.2. Identifying Appropriate Neighbors for Better Interpersonal Trust Modeling
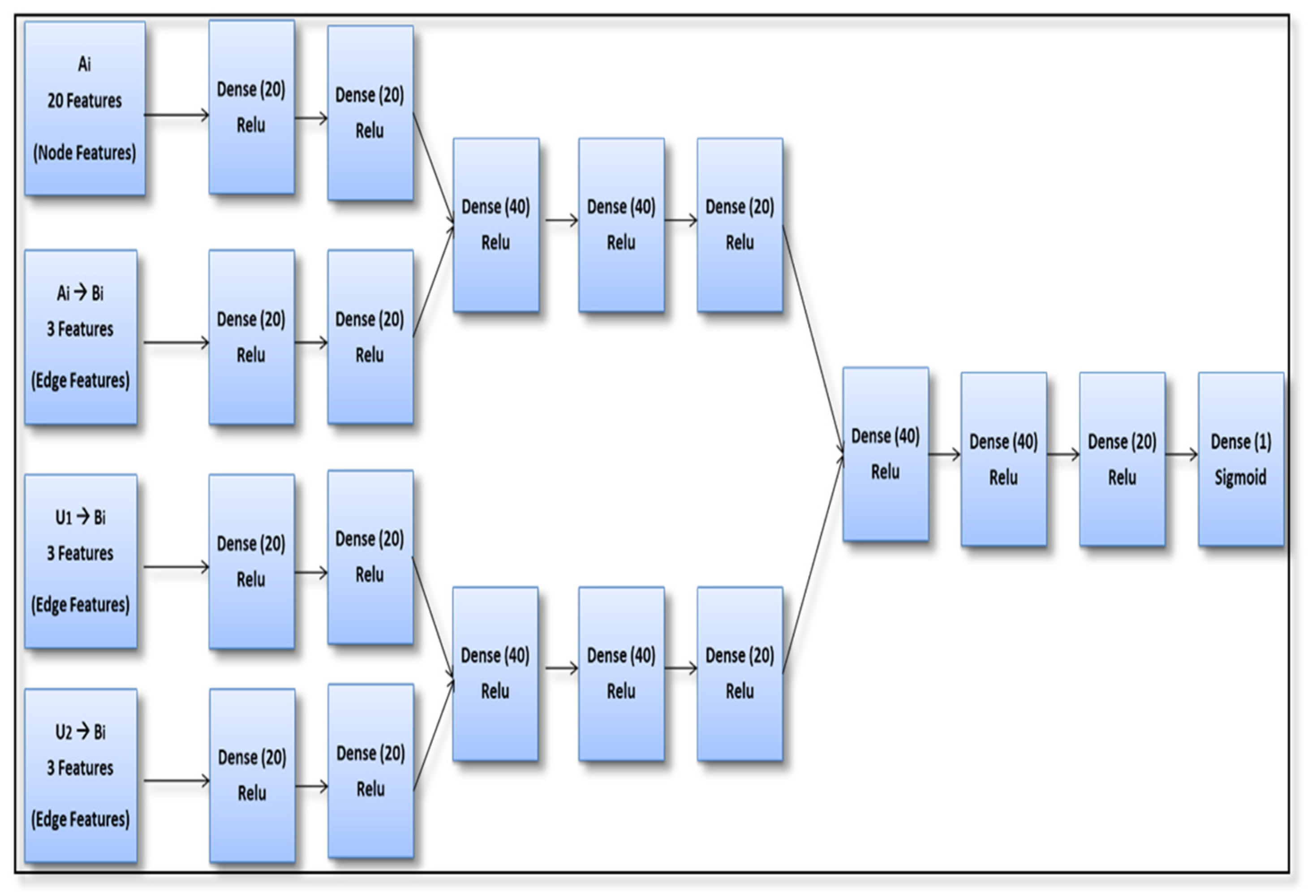
4.3. NADAL: A Neighbor-Aware Deep Learning Architecture
5. Results
5.1. Classification Results
5.1.1. TrustHWF Dataset
- 1.
- Sampling Technique: As-Is vs. SMOTE+Tomek Resampling
- 2.
- Neighbor Awareness: Individual Path (Non-Neighbor-Aware) vs. Neighbor-Aware
- 3.
- Machine Learning Approach: Shallow Learning (Random Forest) vs. Deep Learning (FC-DNN and NADAL)
5.1.2. TrustF Dataset
6. Discussion
6.1. Methodological Considerations
6.2. Privacy of User Data and Ethical Considerations
6.3. Limitations
6.4. Implications
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Borum, R. The Science of Interpersonal Trust. Available online: https://scholarcommons.usf.edu/cgi/viewcontent.cgi?article=1573&context=mhlp_facpub (accessed on 11 August 2018).
- Miranda, J.; Mäkitalo, N.; Garcia-Alonso, J.; Berrocal, J.; Mikkonen, T.; Canal, C.; Murillo, J.M. From the Internet of Things to the Internet of People. IEEE Internet Comput. 2015, 19, 40–47. [Google Scholar] [CrossRef]
- Sundsøy, P. Big Data for Social Sciences: Measuring patterns of human behavior through large-scale mobile phone data. arXiv 2017, arXiv:1702.08349. [Google Scholar]
- Giles, J. Computational social science: Making the links. Nature 2012, 488, 448–450. [Google Scholar] [CrossRef] [Green Version]
- Miller, G. The smartphone psychology manifesto. Perspect. Psychol. Sci. 2012, 7, 221–237. [Google Scholar] [CrossRef] [Green Version]
- Eagle, N.; Pentland, A.S. Reality mining: Sensing complex social systems. Pers. Ubiquitous Comput. 2006, 10, 255–268. [Google Scholar] [CrossRef]
- De Montjoye, Y.A.; Quoidbach, J.; Robic, F.; Pentland, A. Predicting personality using novel mobile phone-based metrics. In Proceedings of the 6th International Conference on Social Computing, Behavioral-Cultural Modeling, and Prediction, Washington, DC, USA, 2–5 April 2013. [Google Scholar]
- Qin, T.; Shangguan, W.; Song, G.; Tang, J. Spatio-Temporal Routine Mining on Mobile Phone Data. ACM Trans. Knowl. Discov. Data 2018, 12, 1–24. [Google Scholar] [CrossRef]
- Yabe, T.; Sekimoto, Y.; Tsubouchi, K.; Ikemoto, S. Cross-comparative analysis of evacuation behavior after earthquakes using mobile phone data. PLoS ONE 2019, 14, e0211375. [Google Scholar] [CrossRef]
- Bosse, S.; Engel, U. Real-Time Human-In-The-Loop Simulation with Mobile Agents, Chat Bots, and Crowd Sensing for Smart Cities. Sensors 2019, 19, 4356. [Google Scholar] [CrossRef] [Green Version]
- De Salve, A.; Guidi, B.; Ricci, L.; Mori, P. Discovering Homophily in Online Social Networks. Mob. Netw. Appl. 2018, 23, 1715–1726. [Google Scholar] [CrossRef]
- Hossain, H.M.S.; Al Haiz Khan, M.A.; Roy, N. DeActive: Scaling Activity Recognition with Active Deep Learning. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Peng, L.; Chen, L.; Ye, Z.; Zhang, Y. AROMA: A Deep Multi-Task Learning Based Simple and Complex Human Activity Recognition Method Using Wearable Sensors. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 1–16. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep Learning for Sensor-based Activity Recognition: A Survey. arXiv 2017, arXiv:1707.03502. [Google Scholar] [CrossRef] [Green Version]
- El Mougy, A. Character-IoT (CIoT): Toward Human-Centered Ubiquitous Computing. In Character Computing; El Bolock, A., Abdelrahman, Y., Abdennadher, S., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 99–121. ISBN 978-3-030-15953-5. [Google Scholar]
- Evans, A.M.; Revelle, W. Survey and behavioral measurements of interpersonal trust. J. Res. Personal. 2008, 42, 1585–1593. [Google Scholar] [CrossRef]
- Sullivan, J.L.; Transue, J.E. The Psychological Underpinnings of Democracy: A Selective Review of Research on Political Tolerance, Interpersonal Trust, and Social Capital. Annu. Rev. Psychol. 1999, 50, 625–650. [Google Scholar] [CrossRef]
- Tanis, M.; Postmes, T. A social identity approach to trust: Interpersonal perception, group membership and trusting behaviour. Eur. J. Soc. Psychol. 2005, 35, 413–424. [Google Scholar] [CrossRef] [Green Version]
- Ben-Ner, A.; Halldorsson, F. Trusting and trustworthiness: What are they, how to measure them, and what affects them. J. Econ. Psychol. 2010, 31, 64–79. [Google Scholar] [CrossRef]
- Ermisch, J.; Gambetta, D.; Laurie, H.; Siedler, T.; Uhrig, S.C.N. Measuring people’s trust. J. R. Stat. Soc. Ser. A 2009, 172, 749–769. [Google Scholar] [CrossRef] [Green Version]
- Dunbar, R.I.M. Breaking Bread: The Functions of Social Eating. Adaptive Human Behavior and Physiology 2017, 3, 198–211. [Google Scholar] [CrossRef] [Green Version]
- Sahi, G.K.; Sekhon, H.S.; Quareshi, T.K. Role of Trusting Beliefs in Predicting Purchase Intentions. Int. J. Retail. Distrib. Manag. 2016, 44, 860–880. [Google Scholar] [CrossRef]
- Kagal, L.; Finin, T.; Joshi, A. Trust-based security in pervasive computing environments. Computer 2001, 34, 154–157. [Google Scholar] [CrossRef]
- Golbeck, J. (Ed.) Computing with Social Trust; Springer Science & Business Media: New York, NY, USA, 2008. [Google Scholar]
- Granovetter, M.S. The Strength of Weak Ties. Am. J. Sociol. 1973, 78, 1360–1380. [Google Scholar] [CrossRef] [Green Version]
- Han, K.; He, Y.; Xiao, X.; Tang, S.; Gui, F.; Xu, C.; Luo, J. Organizing an Influential Social Event Under a Budget Constraint. IEEE Trans. Knowl. Data Eng. 2019, 31, 2379–2392. [Google Scholar] [CrossRef]
- Shmueli, E.; Singh, V.K.; Lepri, B.; Pentland, A. Sensing, understanding, and shaping social behavior. IEEE Trans. Comput. Soc. Syst. 2014, 1, 22–34. [Google Scholar] [CrossRef] [Green Version]
- Colquitt, J.A.; Scott, B.A.; LePine, J.A. Trust, Trustworthiness, and Trust Propensity: A Meta-Analytic Test of Their Unique Relationships with Risk Taking and Job Performance. J. Appl. Psychol. 2007, 92, 909–927. [Google Scholar] [CrossRef] [PubMed]
- McKnight, D.H.; Chervany, N.L. Trust and distrust definitions: One bite at a time. Trust Cyber-Soc. 2001, 2246, 27–54. [Google Scholar]
- Bati, G.F.; Singh, V.K. “Trust Us”: Mobile Phone Use Patterns Can Predict Individual Trust Propensity. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; p. 330. [Google Scholar]
- Barclay, P. Trustworthiness and Competitive Altruism Can Also Solve the “Tragedy of the Commons”. Evol. Hum. Behav. 2004, 25, 209–220. [Google Scholar] [CrossRef]
- Exadaktylos, F.; Espín, A.M.; Brañas-Garza, P. Experimental Subjects Are Not Different. Sci. Rep. 2013, 3, 1213. [Google Scholar] [CrossRef]
- Al-Oufi, S.; Kim, H.-N.; El Saddik, A. A Group Trust Metric for Identifying People of Trust in Online Social Networks. Expert Syst. Appl. 2012, 39, 13173–13181. [Google Scholar] [CrossRef]
- Adali, S.; Escriva, R.; Goldberg, M.; Hayvanovych, M.; Magdon-Ismail, M.; Szymanski, B.; Wallace, W.; Williams, G. Measuring behavioral trust in social networks. In Proceedings of the International Intelligence and Security Informatics (ISI), Vancouver, BC, Canada, 23–26 May 2010. [Google Scholar]
- Kelton, K.; Fleischmann, K.R.; Wallace, W.A. Trust in digital information. J. Am. Soc. Inf. Sci. Technol. 2008, 59, 363–374. [Google Scholar] [CrossRef]
- Farrahi, K.; Zia, K. Trust reality-mining: Evidencing the role of friendship for trust diffusion. Hum. Cent. Comput. Inf. Sci. 2017, 7, 4. [Google Scholar] [CrossRef] [Green Version]
- Roy, A.; Sarkar, C.; Srivastava, J.; Huh, J. Trustingness & trustworthiness: A pair of complementary trust measures in a social network. In Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016. [Google Scholar]
- Zolfaghar, K.; Aghaieb, A. Evolution of trust networks in social web applications using supervised learning. Procedia Comput. Sci. 2011, 3, 833–839. [Google Scholar] [CrossRef] [Green Version]
- Deng, S.; Huang, L.; Xu, G.; Wu, X.; Wu, Z. On Deep Learning for Trust-Aware Recommendations in Social Networks. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 1164–1177. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Liu, B.; Sun, C.; Liu, M.; Wang, X. Deep belief network-based approaches for link prediction in signed social networks. Entropy 2015, 17, 2140–2169. [Google Scholar] [CrossRef] [Green Version]
- Bonchi, F. Influence Propagation in Social Networks: A Data Mining Perspective. In Proceedings of the 2011 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology, Lyon, France, 22–27 August 2011; p. 2. [Google Scholar]
- Bisgin, H.; Agarwal, N.; Xu, X. Investigating homophily in online social networks. In Proceedings of the Web Intelligence and Intelligent Agent Technology (WI-IAT), 2010 IEEE/WIC/ACM International Conference, Toronto, ON, Canada, 31 August–3 September 2010; Volume 1, pp. 533–536. [Google Scholar]
- Olson, D.V.A. The Influence of Your Neighbors’ Religions on You, Your Attitudes and Behaviors, and Your Community. Sociol. Relig. 2019, 80, 147–167. [Google Scholar] [CrossRef]
- Fudolig, M.I.D.; Bhattacharya, K.; Monsivais, D.; Jo, H.-H.; Kaski, K. Link-centric analysis of variation by demographics in mobile phone communication patterns. PLoS ONE 2020, 15, e0227037. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lane, N.D.; Li, P.; Zhou, L.; Zhao, F. Connecting personal-scale sensing and networked community behavior to infer human activities. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; pp. 595–606. [Google Scholar]
- Khan, W.Z.; Xiang, Y.; Aalsalem, M.Y.; Arshad, K. Mobile Phone Sensing Systems: A Survey. IEEE Commun. Surv. Tutor. 2013, 15, 402–427. [Google Scholar] [CrossRef]
- Singh, V.K.; Agarwal, R.R. Cooperative phoneotypes: Exploring phone-based behavioral markers of cooperation. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 646–657. [Google Scholar]
- Ponciano, V.; Pires, I.M.; Ribeiro, F.R.; Villasana, M.V.; Teixeira, M.C.; Zdravevski, E. Experimental Study for Determining the Parameters Required for Detecting ECG and EEG Related Diseases during the Timed-Up and Go Test. Computers 2020, 9, 67. [Google Scholar] [CrossRef]
- Guan, Y.; Plötz, T. Ensembles of Deep LSTM Learners for Activity Recognition using Wearables. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Krishna, K.; Jain, D.; Mehta, S.V.; Choudhary, S. An LSTM Based System for Prediction of Human Activities with Durations. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 1, 1–31. [Google Scholar] [CrossRef]
- Aharony, N.; Pan, W.; Ip, C.; Khayal, I.; Pentland, A. Social fMRI: Investigating and shaping social mechanisms in the real world. Pervasive Mob. Comput. 2011, 7, 643–659. [Google Scholar] [CrossRef]
- Adali, S. Modeling Trust Context in Networks; Springer: New York, NY, USA, 2013. [Google Scholar]
- Singh, V.K.; Ghosh, I. Inferring Individual Social Capital Automatically via Phone Logs. Proc. ACM Hum. Comput. Interact. 2017, 1, 1–12. [Google Scholar] [CrossRef]
- Rauber, J.; Fox, E.B.; Gatys, L.A. Modeling patterns of smartphone usage and their relationship to cognitive health. arXiv 2019, arXiv:1911.05683. [Google Scholar]
- Putnam, R. Social capital: Measurement and consequences. Can. J. Policy Res. 2001, 2, 41–51. [Google Scholar]
- Putnam, R.D. Bowling alone: America’s declining social capital. J. Democr. 1995, 6, 65–78. [Google Scholar] [CrossRef] [Green Version]
- Williams, D. On and Off the’ Net: Scales for Social Capital in an Online Era. J. Comput. Mediat. Commun. 2006, 11, 593–628. [Google Scholar] [CrossRef] [Green Version]
- Yakoub, F.; Zein, M.; Yasser, K.; Adl, A.; Hassanien, A.E. Predicting personality traits and social context based on mining the smartphones SMS data. In Intelligent Data Analysis and Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 511–521. [Google Scholar]
- Jin, L.; Gao, S.; Li, Z.; Tang, J. Hand-Crafted Features or Machine Learnt Features? Together They Improve RGB-D Object Recognition. In Proceedings of the 2014 IEEE International Symposium on Multimedia, Taichung, Taiwan, 10–12 December 2014; pp. 311–319. [Google Scholar]
- Li, W.; Manivannan, S.; Akbar, S.; Zhang, J.; Trucco, E.; McKenna, S.J. Gland segmentation in colon histology images using handcrafted features and convolutional neural networks. In Proceedings of the 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016; pp. 1405–1408. [Google Scholar]
- Majtner, T.; Yildirim-Yayilgan, S.; Hardeberg, J.Y. Combining Deep Learning and Hand-Crafted Features for Skin Lesion Classification. In Proceedings of the 2016 Sixth International Conference on Image Processing Theory, Tools and Applications (IPTA), Oulu, Finland, 12–15 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Antipov, G.; Berrani, S.-A.; Ruchaud, N.; Dugelay, J.-L. Learned vs. Hand-Crafted Features for Pedestrian Gender Recognition. In Proceedings of the 23rd ACM international conference on Multimedia—MM ’15, Brisbane, Australia, 26–30 October 2015; ACM Press: New York, NY, USA, 2015; pp. 1263–1266. [Google Scholar]
- Golbeck, J.; Hendler, J. Inferring binary trust relationships in web-based social networks. ACM Trans. Internet Technol. 2006, 6, 497–529. [Google Scholar] [CrossRef]
- Greenspan, S.; Goldberg, D.; Weimer, D.; Basso, A. Interpersonal Trust and Common Ground in Electronically Mediated Communication. In Proceedings of the 2000 ACM Conference on Computer Supported Cooperative Work, Philadelphia, PA, USA, 2–6 December 2000; ACM: New York, NY, USA; pp. 251–260. [Google Scholar]
- De Montjoye, Y.A.; Wang, S.S.; Pentland, A.; Anh, D.T.; Datta, A. On the Trusted Use of Large-Scale Personal Data. IEEE Data Eng. Bull. 2012, 35, 5–8. [Google Scholar]
- Singh, V.K.; Freeman, L.; Lepri, B.; Pentland, A.P. Classifying spending behavior using socio-mobile data. Hum. J. 2013, 2, 99–111. [Google Scholar]
- Gilbert, E.; Karahalios, K. Predicting tie Strength with Social Media. In Proceedings of the 27th International Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009. [Google Scholar]
- Nelson, R.E. The strength of strong ties: Social networks and intergroup conflict in organizations. Acad. Manag. J. 1989, 32, 377–401. [Google Scholar]
- Gao, J.; Schoenebeck, G.; Yu, F.-Y. The Volatility of Weak Ties: Co-evolution of Selection and Influence in Social Networks. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 619–627. [Google Scholar]
- Singh, V.K.; Bozkaya, B.; Pentland, A. Money walks: Implicit mobility behavior and financial well-being. PLoS ONE 2015, 10, e0136628. [Google Scholar] [CrossRef] [Green Version]
- Jonasona, P.K.; Jonesb, A.; Lyonsb, M. Creatures of the night: Chronotypes and the Dark Triad traits. Personal. Individ. Differ. 2013, 55, 538–541. [Google Scholar] [CrossRef]
- Lyons, M.; Hughes, S. Feeling me, feeling you? Links between the Dark Triad and internal body awareness. Personal. Individ. Differ. 2015, 86, 308–311. [Google Scholar] [CrossRef]
- Adan, A.; Almirall, H. Horne & Östberg morningness-eveningness questionnaire: A reduced scale. Personal. Individ. Differ. 1991, 12, 241–253. [Google Scholar]
- Cai, G.; Lv, R.; Tang, J.; Liu, H. Temporal dynamics in social trust prediction. Wuhan Univ. J. Nat. Sci. 2014, 19, 369–378. [Google Scholar] [CrossRef]
- Lemaıtre, G.; Nogueira, F. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Batista, G.E.; Bazzan, A.L.; Monard, M.C. Balancing Training Data for Automated Annotation of Keywords: A Case Study. In Proceedings of the Brazilian Workshop on Bioinformatics, Macaé, RJ, Brazil, 3–5 December 2003; pp. 10–18. [Google Scholar]
- Chawla, N. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Ijaz, M.F.; Attique, M.; Son, Y. Data-Driven Cervical Cancer Prediction Model with Outlier Detection and Over-Sampling Methods. Sensors 2020, 20, 2809. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wu, C.; Zheng, K.; Niu, X.; Wang, X. SMOTETomek-Based Resampling for Personality Recognition. IEEE Access 2019, 7, 129678–129689. [Google Scholar] [CrossRef]
- Techniques to Deal with Imbalanced Data Kaggle. Available online: https://www.kaggle.com/npramod/techniques-to-deal-with-imbalanced-data (accessed on 11 August 2018).
- Buskens, V.; Raub, W.; Van Der Veer, J. Trust in triads: An experimental study. Soc. Netw. 2010, 32, 301–312. [Google Scholar] [CrossRef] [Green Version]
- Dang-Pham, D.; Pittayachawan, S.; Bruno, V. Applying network analysis to investigate interpersonal influence of information security behaviours in the workplace. Inf. Manag. 2017, 54, 625–637. [Google Scholar] [CrossRef]
- Radu, V.; Tong, C.; Bhattacharya, S.; Lane, N.D.; Mascolo, C.; Marina, M.K.; Kawsar, F. Multimodal deep learning for activity and context recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 1, 157. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chollet, F. Others Keras. Available online: https://keras.io (accessed on 10 August 2018).
- Chawla, N.V. Data mining for imbalanced datasets: An overview. In Data Mining and Knowledge Discovery Handbook; Springer: Boston, MA, USA, 2009; pp. 875–886. [Google Scholar]
- Zheng, A. Evaluating Machine Learning Models a Beginner’s Guide to Key Concepts and Pitfalls; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [Google Scholar]
- Tufekci, Z. Algorithmic harms beyond Facebook and Google: Emergent challenges of computational agency. Colo. Technol. Law J. 2015, 13, 203–218. [Google Scholar]
- Shifali, A.; Yttri, J.; Nilsen, W. Privacy and security in mobile health (mHealth) research. Alcohol Res. Curr. Rev. 2014, 36, 143–151. [Google Scholar]
- Jin, H.; Su, L.; Ding, B.; Nahrstedt, K.; Borisov, N. Enabling Privacy-Preserving Incentives for Mobile Crowd Sensing Systems. In Proceedings of the 2016 IEEE 36th International Conference on Distributed Computing Systems (ICDCS), Nara, Japan, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 344–353. [Google Scholar]
- Ivanov, A.; Sharman, R.; Rao, H.R. Exploring factors impacting sharing health-tracking records. Health Policy Technol. 2015, 4, 263–276. [Google Scholar] [CrossRef] [Green Version]
- Möhlmann, M.; Geissinger, A. Trust in the Sharing Economy: Platform-Mediated Peer Trust. In Cambridge Handbook on the Law of the Sharing; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Total | Mean | Median |
|---|---|---|---|
| BT | 474,340 | 4351.74 | 3864 |
| Call | 58,554 | 476.05 | 407 |
| SMS | 17,369 | 231.59 | 88 |
| Node/Edge | Feature Name | Definition |
|---|---|---|
| Node Features | Social Activity Level 3 Features | Social Activity (BT, Call, SMS) = ∑ Activityi |
| Diversity 3 Features | ||
| Tie Strength 3 Features | Strong/Weak Tie Ratio (SWTR) = | |
| Reciprocity 2 Features | In Out Ratio (Call, SMS): | |
| Loyalty 3 Features | ||
| Temporal Rhythms 6 Features | Diurnal Activity Ratio (BT, Call, SMS) DAR = Weekday/Weekend Activity Ratio (BT, Call, SMS) WWAR = | |
| Edge Features | Social Activity Level 3 Features | Social Activity (BT, Call, SMS) = ∑ Activityij |
| Dataset | Neighbor Awareness | Features | Instances | Class 0 | Class 1 |
|---|---|---|---|---|---|
| ORIGINAL | Only Main Edge (100%) | 23 | 2939 | 2492 | 447 |
| ORIGINAL | Main Edge + Two Neighbors (100%) | 29 | 2939 | 2492 | 447 |
| TRAINING SET: AS-IS | Only Main Edge (70%) | 23 | 2057 | 1739 | 318 |
| TRAINING SET: AS-IS | Main Edge + Two Neighbors (70%) | 29 | 2057 | 1739 | 318 |
| TRAINING SET: After Resampling | Only Main Edge (70%) | 23 | 3388 | 1694 | 1694 |
| TRAINING SET: After Resampling | Main Edge + Two Neighbors (70%) | 29 | 3388 | 1694 | 1694 |
| TEST SET | Only Main Edge (30%) | 23 | 882 | 753 | 129 |
| TEST SET | Main Edge + Two Neighbors (30%) | 29 | 882 | 753 | 129 |
| Sampling Approach | Algorithmic Approach | Individual Path (Non-Neighbor-Aware) | Neighbor-Aware | ||
|---|---|---|---|---|---|
| Acc | AUCROC | Acc | AUCROC | ||
| AS-IS | Decision Tree | 60.29% | 67.78% | 60.69% | 67.99% |
| AS-IS | Logistic Regression | 85.15% | 49.87% | 85.26% | 50.25% |
| AS-IS | Random Forest | 61.87% | 68.90% | 62.64% | 69.03% |
| SMOTE+Tomek | Decision Tree | 61.81% | 66.84% | 64.07% | 67.33% |
| SMOTE+Tomek | Logistic Regression | 69.05% | 63.56% | 66.33% | 63.58% |
| SMOTE+Tomek | Random Forest | 61.93% | 69.00% | 62.32% | 69.13% |
| Sampling Approach | Algorithmic Approach | Individual Path (Non-Neighbor-Aware) | Neighbor-Aware | ||
|---|---|---|---|---|---|
| Acc | AUCROC | Acc | AUCROC | ||
| AS-IS | Random Forest | 61.87% | 68.90% | 62.64% | 69.03% |
| AS-IS | FC-DNN | 85.36% | 53.66% | 85.31% | 55.41% |
| AS-IS | NADAL | 85.34% | 59.40% | 84.90% | 68.98% |
| SMOTE+Tomek | Random Forest | 61.93% | 69.00% | 62.32% | 69.13% |
| SMOTE+Tomek | FC-DNN | 47.31% | 62.58% | 47.57% | 64.01% |
| SMOTE+Tomek | NADAL | 61.29% | 68.08% | 62.11% | 70.38% |
| Dataset | Neighbor Awareness | Features | Instances | Class 0 | Class 1 |
|---|---|---|---|---|---|
| ORIGINAL | Only Main Edge (100%) | 23 | 13,163 | 12,998 | 165 |
| ORIGINAL | Main Edge + Two Neighbors (100%) | 29 | 13,163 | 12,998 | 165 |
| TRAINING SET: AS-IS | Only Main Edge (70%) | 23 | 9214 | 9103 | 111 |
| TRAINING SET: AS-IS | Main Edge + Two Neighbors (70%) | 29 | 9214 | 9103 | 111 |
| TRAINING SET: After Resampling | Only Main Edge (70%) | 23 | 18,170 | 9085 | 9085 |
| TRAINING SET: After Resampling | Main Edge + Two Neighbors (70%) | 29 | 18,168 | 9084 | 9084 |
| TEST SET | Only Main Edge (30%) | 23 | 3949 | 3895 | 54 |
| TEST SET | Main Edge + Two Neighbors (30%) | 29 | 3949 | 3895 | 54 |
| Sampling Approach | Algorithmic Approach | Individual Path (Non-Neighbor-Aware) | Neighbor-Aware | ||
|---|---|---|---|---|---|
| Acc | AUCROC | Acc | AUCROC | ||
| AS-IS | Decision Tree | 98.55% | 67.58% | 98.57% | 69.05% |
| AS-IS | Logistic Regression | 98.61% | 49.99% | 98.63% | 50.00% |
| AS-IS | Random Forest | 92.48% | 79.84% | 93.12% | 81.08% |
| SMOTE+Tomek | Decision Tree | 93.04% | 76.11% | 93.47% | 77.88% |
| SMOTE+Tomek | Logistic Regression | 77.94% | 80.60% | 78.12% | 81.60% |
| SMOTE+Tomek | Random Forest | 93.78% | 77.85% | 94.67% | 78.94% |
| Sampling Approach | Algorithmic Approach | Individual Path (Non-Neighbor-Aware) | Neighbor-Aware | ||
|---|---|---|---|---|---|
| Acc | AUCROC | Acc | AUCROC | ||
| AS-IS | Random Forest | 92.48% | 79.84% | 93.12% | 81.08% |
| AS-IS | FC-DNN | 85.37% | 50.72% | 98.63% | 60.48% |
| AS-IS | NADAL | 98.64% | 51.31% | 98.67% | 85.39% |
| SMOTE+Tomek | Random Forest | 93.78% | 77.85% | 94.67% | 78.94% |
| SMOTE+Tomek | FC-DNN | 73.67% | 78.28% | 93.35% | 82.16% |
| SMOTE+Tomek | NADAL | 92.54% | 90.63% | 94.55% | 93.23% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bati, G.F.; Singh, V.K. NADAL: A Neighbor-Aware Deep Learning Approach for Inferring Interpersonal Trust Using Smartphone Data. Computers 2021, 10, 3. https://doi.org/10.3390/computers10010003
Bati GF, Singh VK. NADAL: A Neighbor-Aware Deep Learning Approach for Inferring Interpersonal Trust Using Smartphone Data. Computers. 2021; 10(1):3. https://doi.org/10.3390/computers10010003
Chicago/Turabian StyleBati, Ghassan F., and Vivek K. Singh. 2021. "NADAL: A Neighbor-Aware Deep Learning Approach for Inferring Interpersonal Trust Using Smartphone Data" Computers 10, no. 1: 3. https://doi.org/10.3390/computers10010003
APA StyleBati, G. F., & Singh, V. K. (2021). NADAL: A Neighbor-Aware Deep Learning Approach for Inferring Interpersonal Trust Using Smartphone Data. Computers, 10(1), 3. https://doi.org/10.3390/computers10010003