2.2. An Overview of xGenerator
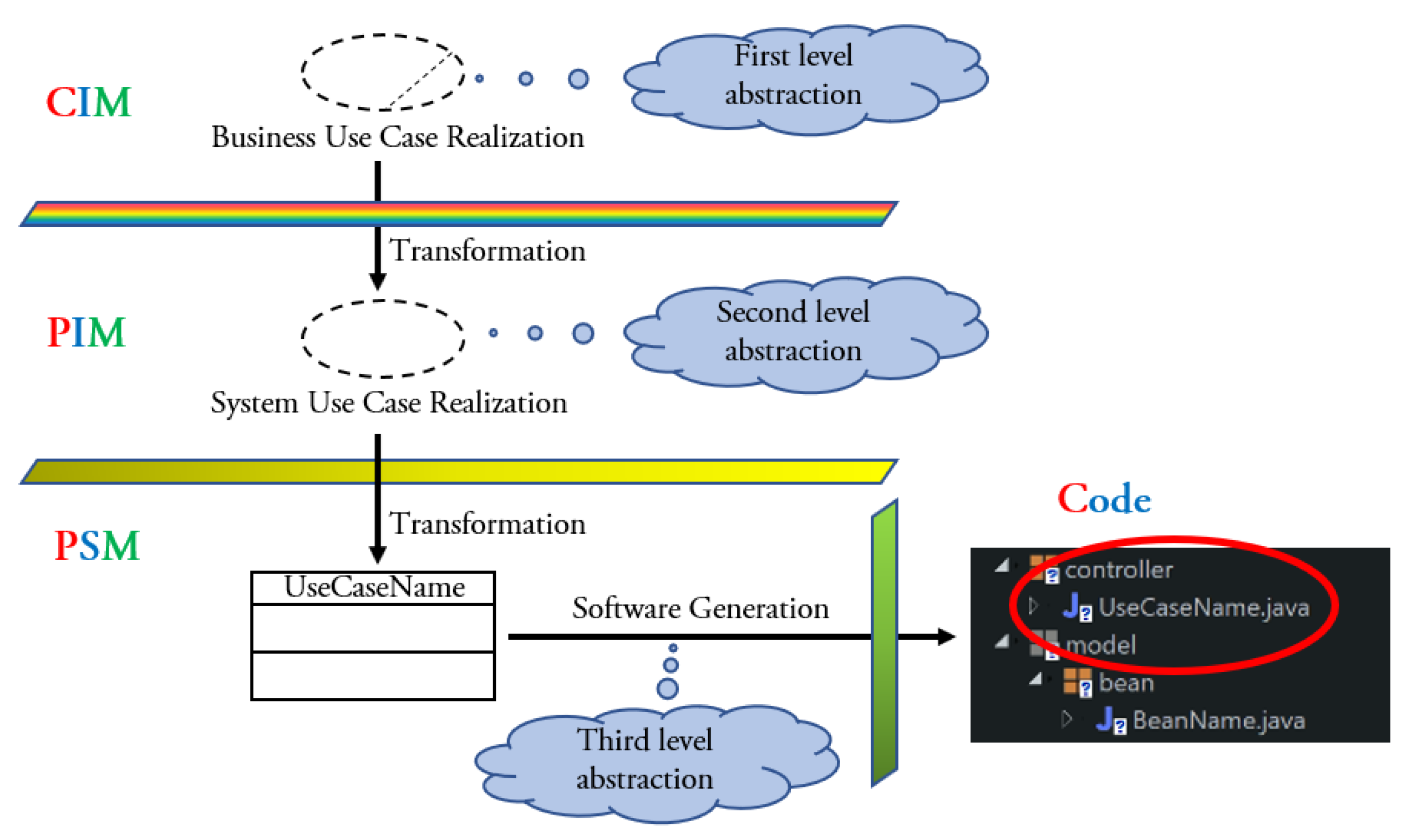
This tool supports the Software Development Process proposed in [
14]: analysts and designers develop the artefacts of CIM, while those of PIM and PSM, as well as the source code, are generated. The source Java code of the Web application is returned in the
Eclipse environment. In accordance with the
Generation gap pattern [
19], the classes are structured at two different levels of abstraction: for each class of the PSM, it is generated a superclass and a subclass. The artefacts of the code model are: (a) one Java class for each class of the PSM at each architectural layer; (b) a Java superclass for each class of the PSM at each architectural layer and a subclass that inherits from the superclass.
Each Java class returned by
xGenerator focuses on a specific task of the MVC layer the class belongs to (
high cohesion). The classes (returned by
xGenerator) belonging to different layers of the MVC architecture are independent of each other (
low coupling). Cohesion and coupling relate to the relationships that exist within a class and between classes, respectively (more in [
21,
22]). High cohesion and low coupling are desirable features of object-oriented software, e.g., [
23]. The classes belonging to the same layer of the MVC pattern are structurally identical. This does not necessarily happen if the classes are coded by a team of programmers. Such a feature of classes of Web applications has direct impact on the code readability that, in turn, is an essential characteristic of code quality [
24].
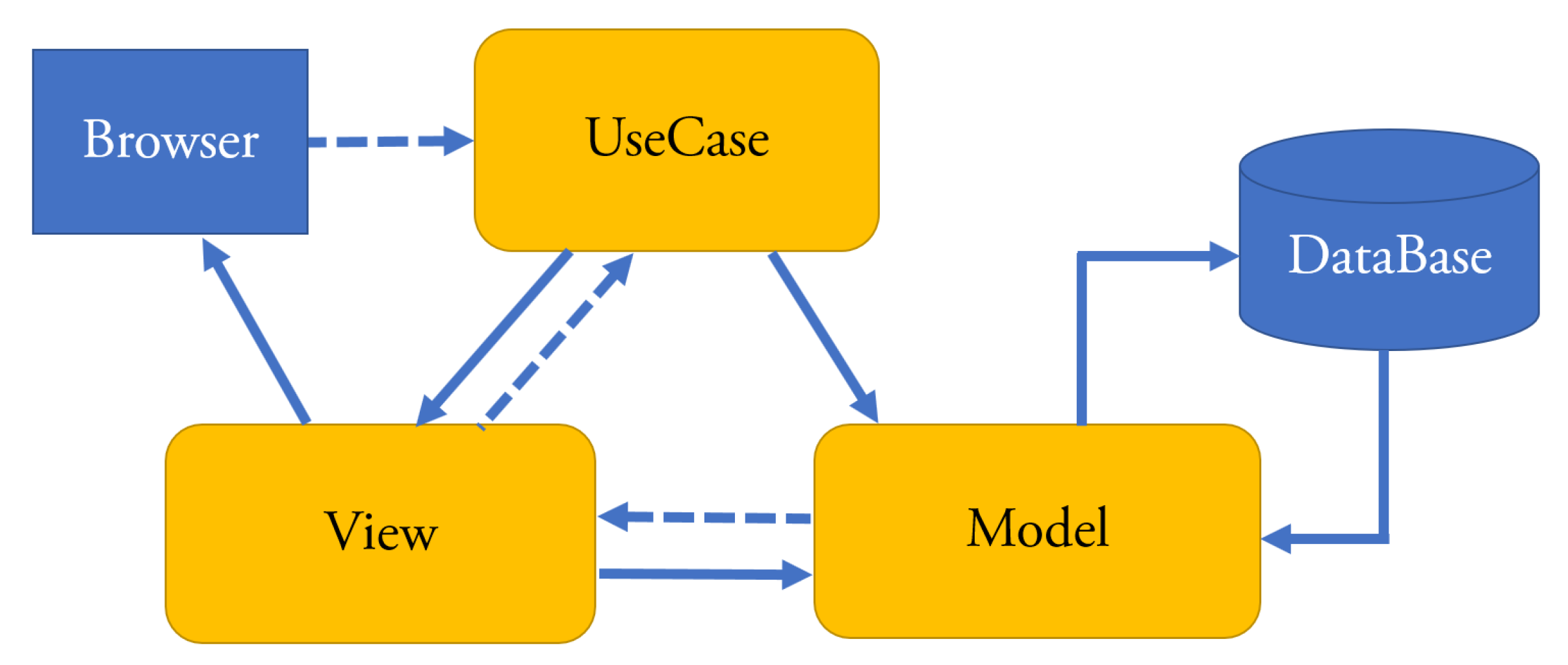
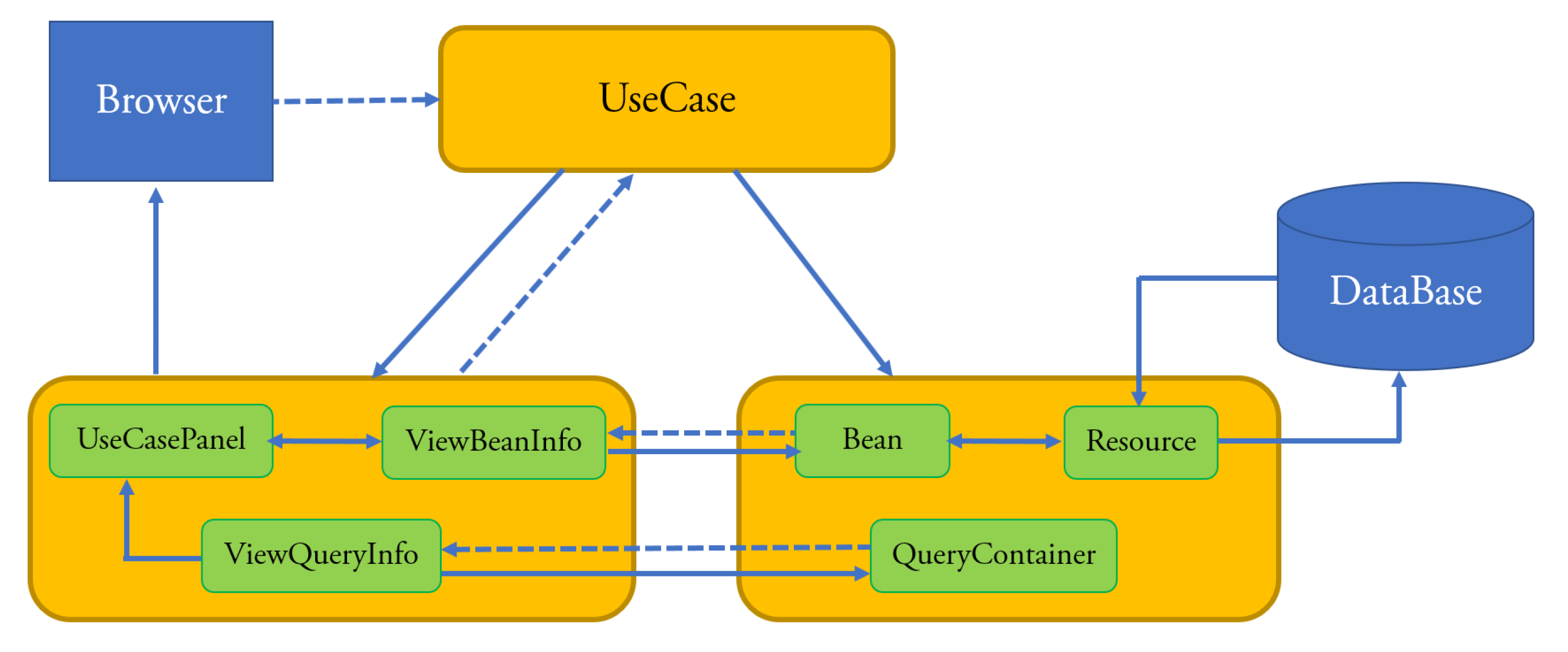
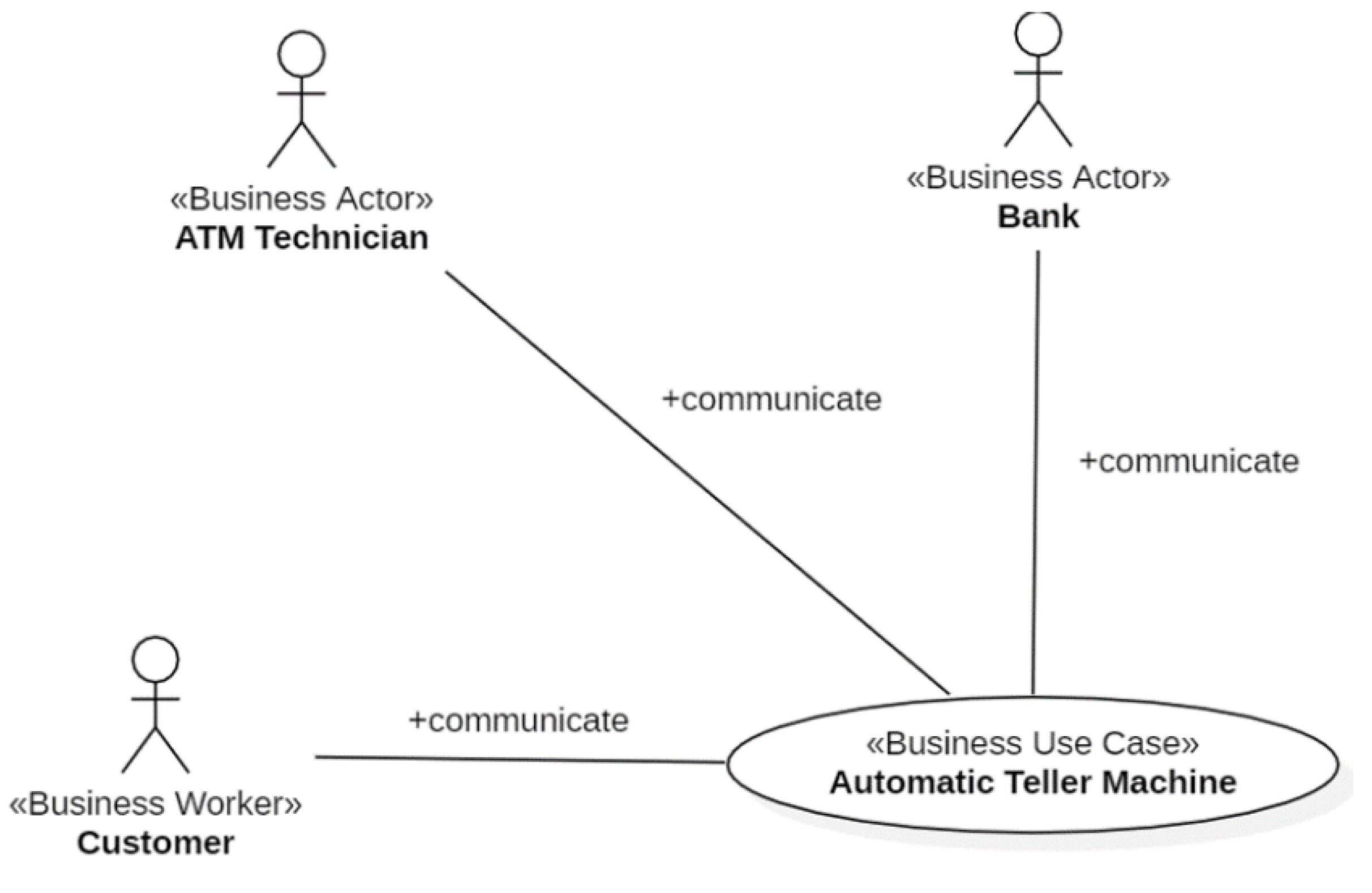
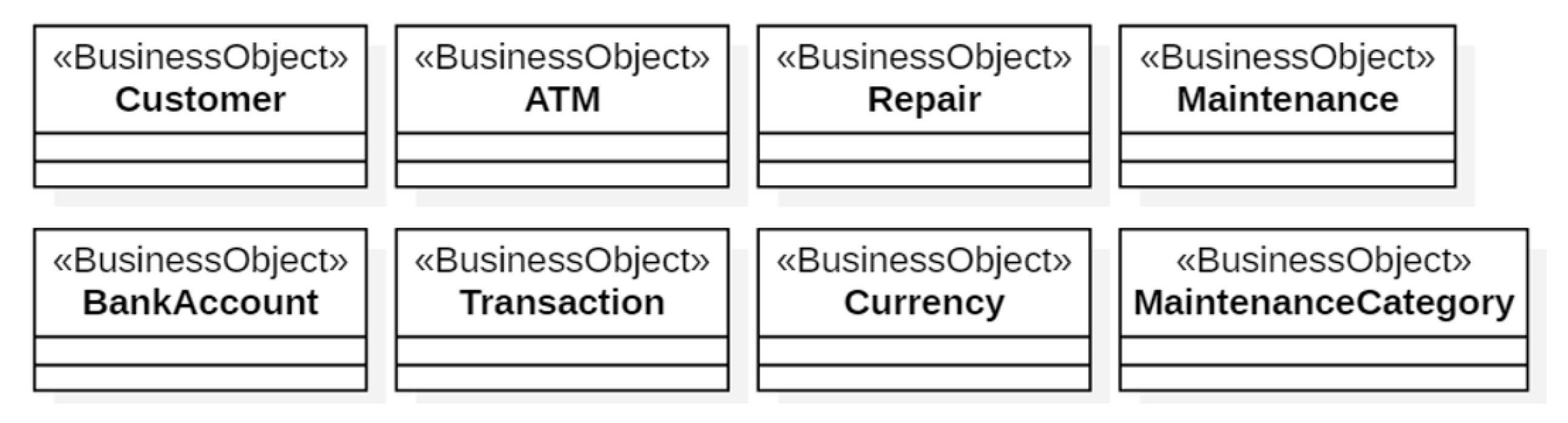
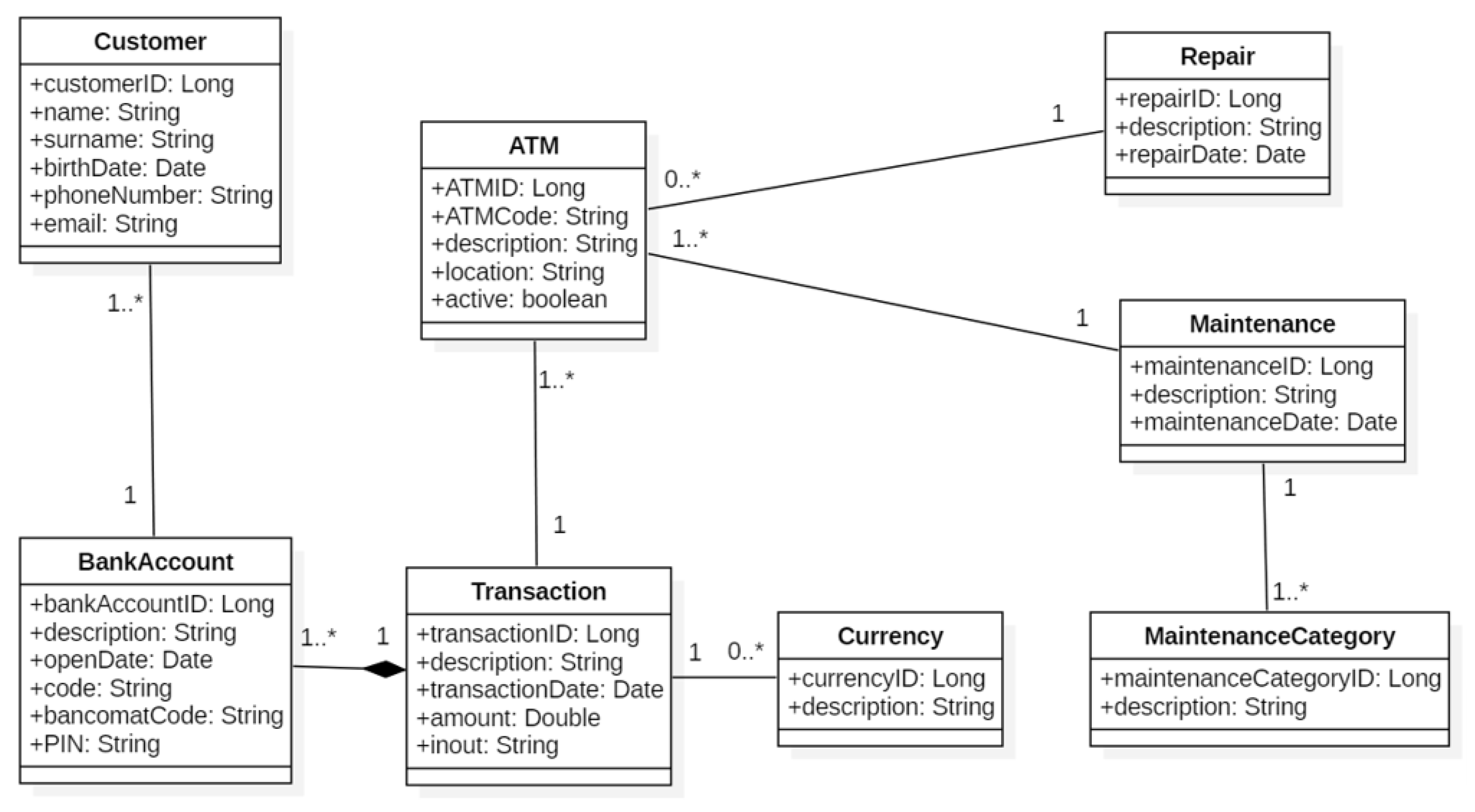
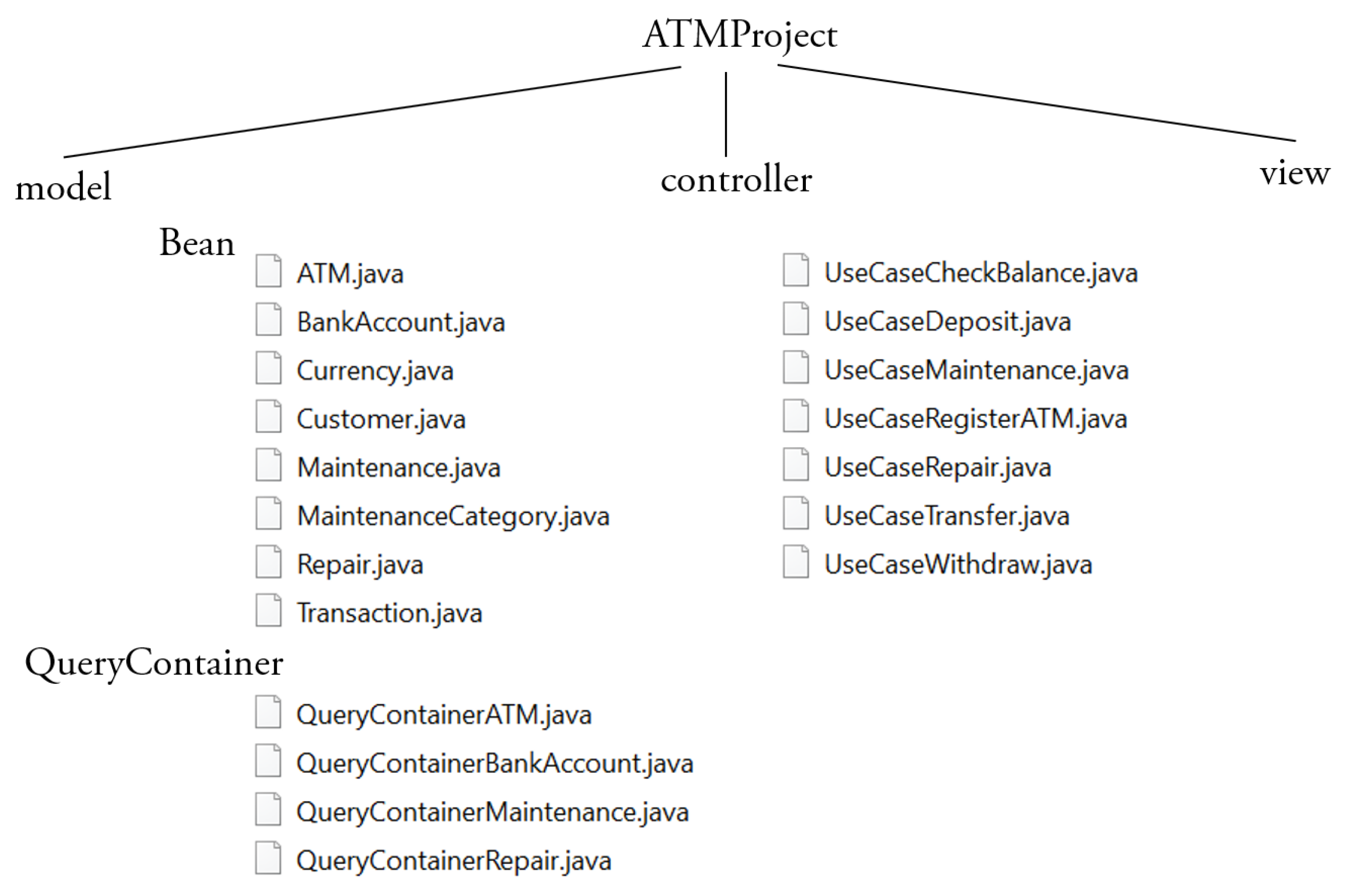
Figure 4 shows the architecture of the enterprise Web applications that can be developed with
xGenerator. This architecture instantiates the basic MVC pattern.
Bean and
QueryContainer classes belong to the Model layer. The
Bean classes are mapped to database’s tables through the
Resource component that wraps
Hibernate. The
QueryContainer classes define the filter criteria in the queries to be executed against the database. View is composed of three class sub-layers:
ViewBeanInfo displays (in a panel) the information of a
Bean,
ViewQueryInfo displays (in a panel) the query criteria and
UseCasePanel sends the information to the browser. Controller is composed of the layer of the
UseCases classes; the latter implement the standard behavior of use cases and the navigation of the panels they are composed of.
2.3. Code Metrics and Code Smells
Code metric analysis is the common method for assessing the quality of a software system. Kent Beck coined the term “code smell” in the context of identifying quality issues in object-oriented source code [
25]. Code smells is one of the symptoms of low-quality code that, therefore, is claiming for improvement. Code smells do not prevent the software from working; however, they denote weaknesses in the design part of the system.
The recent study by Tahir et al. [
26] has pointed out that there is a high debate between developers, across technical Stack Exchange sites, on code smells, their meaning and their impact. As an obvious consequence, the number of empirical studies on the topic is rising constantly. The smell metaphor has been adopted for several categories of software projects. Alkharabsheh et al. [
27] carried out a systematic analysis of the state-of-the-art about code smell detection spanning over the period 2000–2017 (the smell metaphor was introduced in 1999 by Kent Beck). Sharma and Spinellis [
28] is another up-to-date survey on studies about smell detection methods published in the period 1999–2016. Kaur [
29], in turn, conducted a literature review that assessed and reported the findings of empirical studies, published till March 2018, about the impact of code smells on software quality.
The code smell detection analysis can be carried out by taking into account structural, historical and semantic properties. In the first case, the smell detection task exploits metrics in order to describe the structure of the code. A well-known suite of object-oriented metrics is given in [
21].
Code smells impact understandability, maintainability, testability, complexity, performance, functionality, reusability and change-proneness of the software. Moreover, smells may increase the effort (and hence the cost) required to produce the code.
Table 1, built from the data in [
28], lists the five smell detection methods mentioned in such a paper together with the number of surveyed studies. From the table, we see that the metrics-based method is the most investigated by scholars.
Metrics-based smell detection methods are relatively easy to be implemented; however, a non-trivial challenge posed by those methods is the choice of the thresholds, as pointed out by the software engineering community (see, for instance, [
30,
31]). On this point, Lacerda et al. [
32] write the following: “There is no consensus on the standard threshold values for the detection of smells, which are the cause of the disparity in the results of different approaches.” Fontana et al. [
33] pointed out that the assessments produced by metrics-based smell detection tools are prone to high false-positive rates because, as already said, this category of methods depends on the metrics thresholds. In the metrics-based methods, the false-positives cannot be eliminated until the context is taken into account, and this is because one set of thresholds do not hold good necessarily in another context. According to Gil and Lalouche [
34] “the code metric values, when inspected out of context, mean nothing”; in fact, they proved that metric values vary among projects.
Until a few years ago, software tools and published proposals did not take the system architecture into account. This means that all classes within an object-oriented application were treated as they were equal to each other and, hence, assessed in the same way, regardless of their specific architectural role. This approach is not satisfactory if applied to an MVC Web application, where Controller classes are quite different from Model classes simply because they play very different roles: the former are responsible for coordinating the flow between the View and the Model layers, while the latter implements business concepts.
Adding context to code metrics is a recent research topic. In Aniche et al. [
15], the authors adapt the threshold of metrics to the “class’s architectural role” with regard to the (Spring) MVC pattern (
Figure 5); where the
architectural role is defined as the particular role that a class plays in a given system architecture. Specifically, Aniche et al. focus on the server-side code, namely on the Controller and Model layers. Ref. [
15] relies on the Chidamber and Kemerer metrics suite [
21], as it covers different aspects of object-oriented programming, such as coupling, cohesion and complexity.
Table 2 shows the class level metrics taken from [
21], while
Table 3 shows the thresholds found by Aniche et al. [
15] for the classes of the five architectural role belonging to the Controller and Model layers. Each metric varies from 0 or 1 to infinite. The triple [
,
,
] denotes, in order, the low, high and very high thresholds corresponding to moderate/high/very high risk. Classes in which metric values range in the 70–80% have “moderate risk”, while from 80–90% the risk is “high” and “very high” between 90–100%. A percentile is a measure used in statistics indicating the value below which a given percentage of observations in a group of observations falls.
In a more recent paper, Aniche et al. [
16] investigated the link between a set of metrics and code-smell detection. Several studies have been carried out adopting the catalog of 22 code smells defined by Martin Fowler and Kent Beck in the Refactoring book [
25], and including smells that fit well in any object-oriented software system. The code smells from [
25] capture general principles of good design, while they ignore the actual architecture of the software or the role played by each class inside the application. Aniche et al. [
16] argued that it is possible to discover bad practices on software systems adopting a specific architecture by taking into account specific types of code smells. In concrete, they proposed a catalog of six smells tailored to MVC Web applications. Their findings show that the adopted smells have more chances of being subject to changes and defects; moreover, the smells survive for long time in the system.
Table 4 reports the six MVC smells of the catalog in [
16], while
Table 5 collects the thresholds used to detect them. To know the motivations behind the adoption of those smells and the detection strategy adopted to spot them, please refer to such a paper.
By exploiting the catalog of smells in [
16], this allows to overcome the critical issue pointed out by Hozano et al. [
35]: “the informal and subjective definition of certain smell types […] may lead two or more developers to reason about each smell occurrence differently.”
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}