
Emotion Transfer for 3D Hand and Full Body Motion Using StarGAN



Abstract
:1. Introduction
- We proposed a new framework for transferring emotions in synthesizing hand and full body skeletal motions, which is built upon the success of our pilot study [5].
- We conducted a user study to validate the perceived emotion on the dataset we captured and open-sourced in our pilot study [5].
- We provide qualitative and quantitative results on the hand and full-body motion emotion transfer using the proposed framework, showing its validity by comparing them to captured motions.
2. Related Work
2.1. Hand Animation
2.2. Style Transfer for Motion
Image Style Transfer
3. Methodology
3.1. Motion Datasets
3.1.1. Hand Motion with Emotion Label
3.1.2. Full Body Motion with Emotion Label
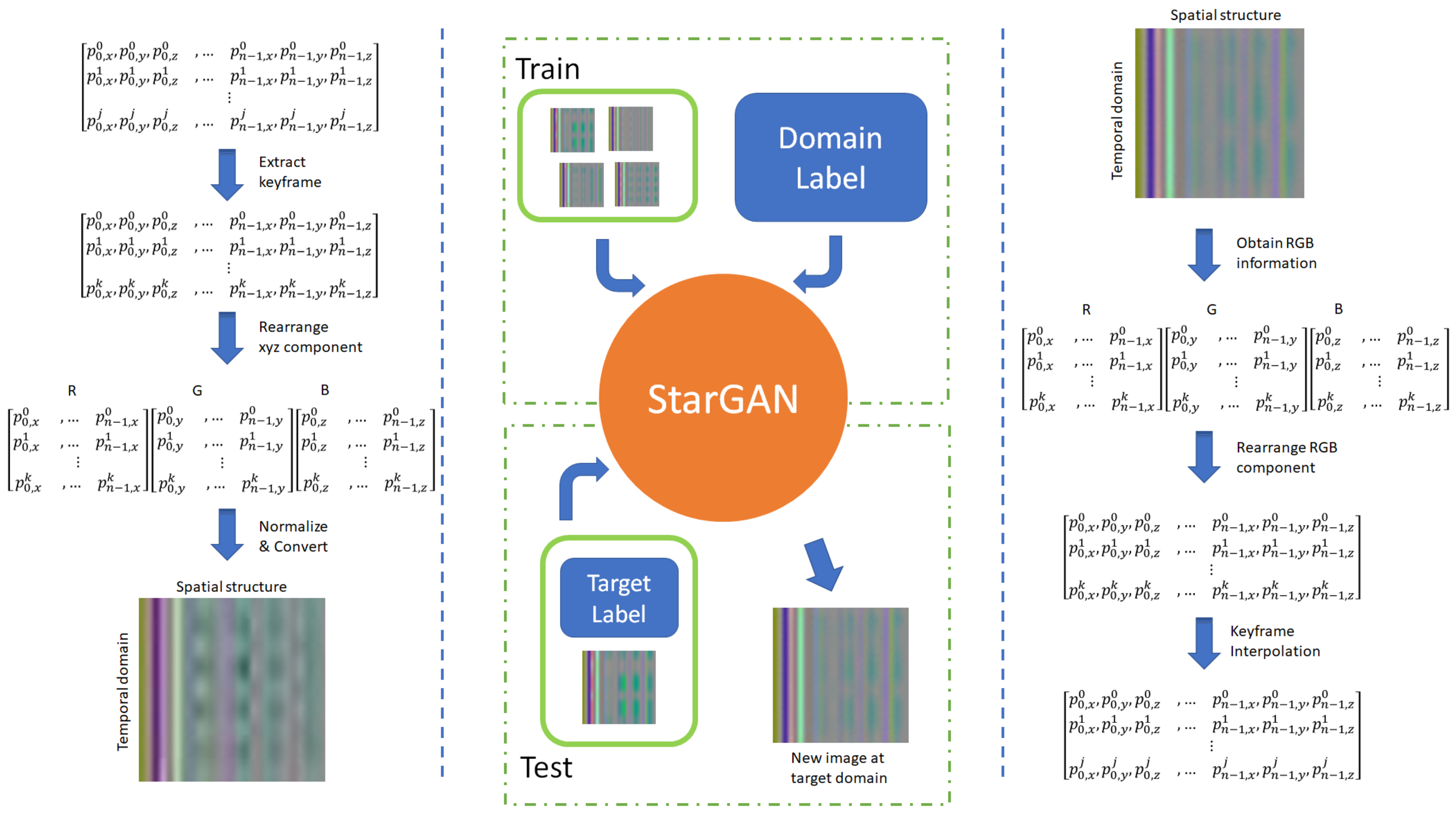
3.2. Standardizing Motion Feature
3.3. Emotion Transfer
3.3.1. Representing Motion as an Image
3.3.2. Emotion Transfer as Image-to-Image Domain Translation
3.3.3. Reconstructing Hand Motion from Generated Images
4. Experimental Results
4.1. User Study on Hand Animations
4.1.1. Evaluating the Emotion Perceived from the Captured Hand Motions
4.1.2. Evaluating the Emotion Perceived from the Hand Motions Synthesized by Our Method
4.1.3. Comparing the Naturalness and Visual Quality of the Synthesized Animations with the Captured Motions and Baseline
4.2. Evaluation on Emotion Transfer
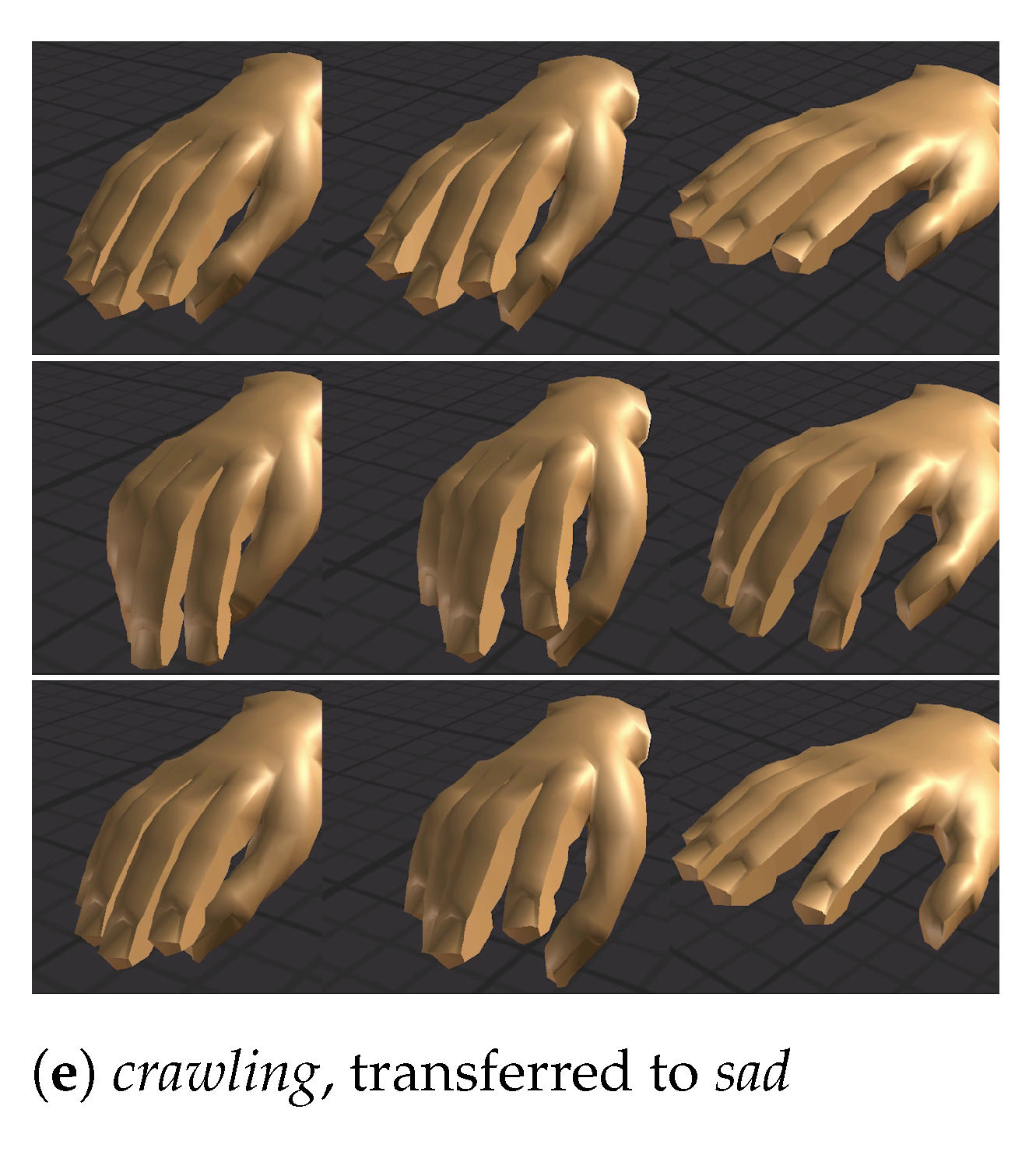
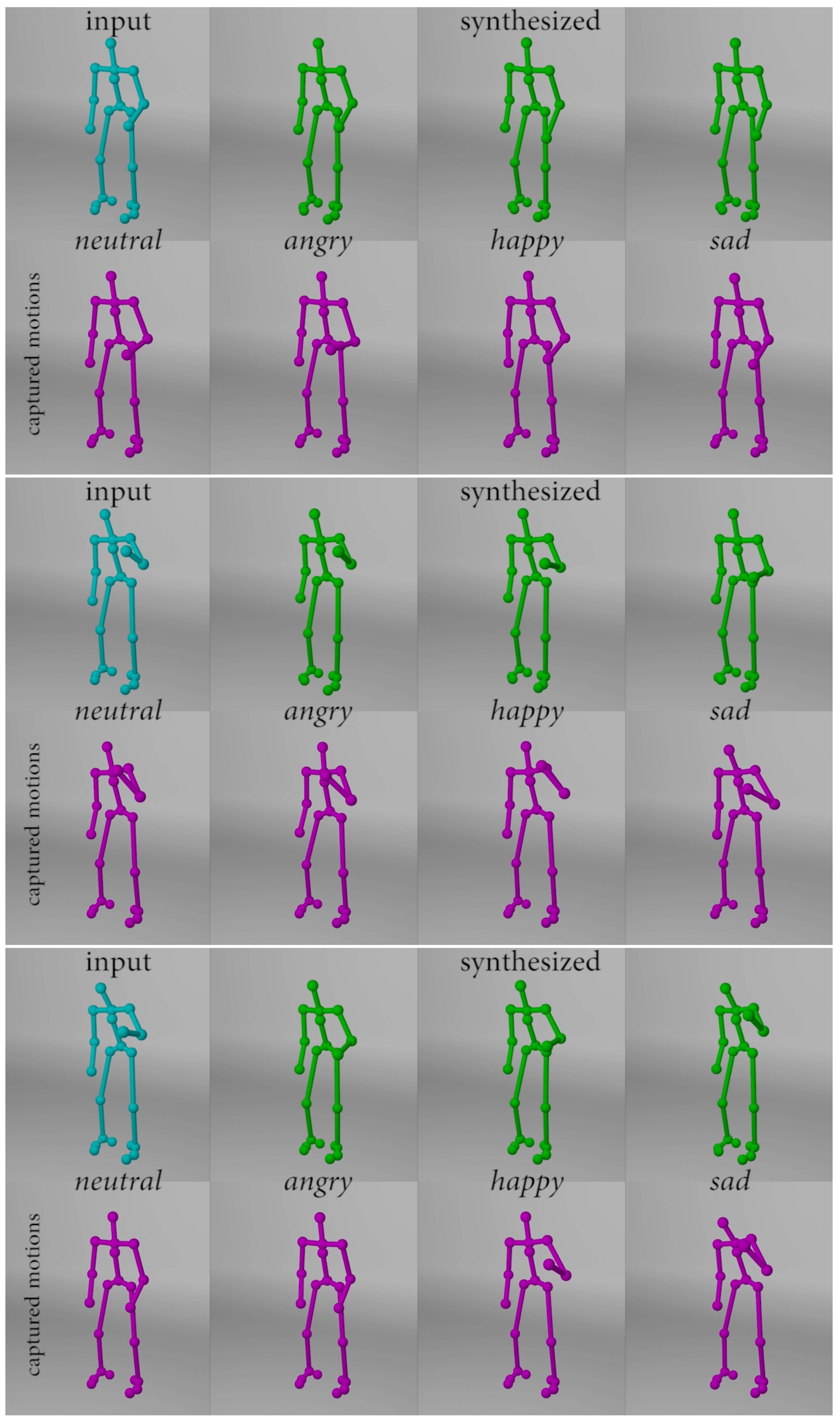
4.2.1. Hand Animation
4.2.2. Comparing Emotion Transferred Motions with Captured Data
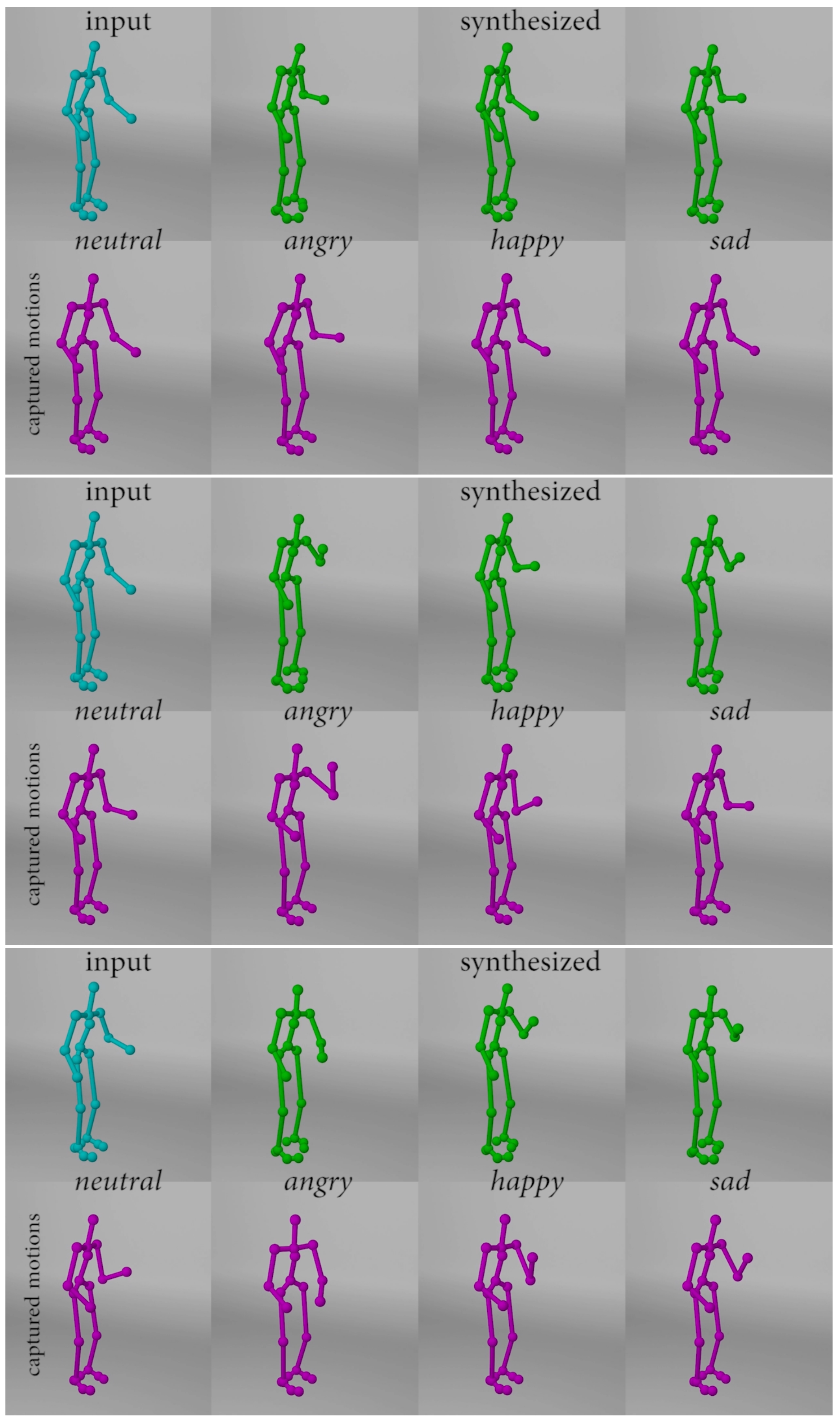
4.2.3. Body Motion Synthesis Results
5. Conclusions and Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Karras, T.; Aila, T.; Laine, S.; Herva, A.; Lehtinen, J. Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion. ACM Trans. Graph. 2017, 36. [Google Scholar] [CrossRef]
- Tinwell, A.; Grimshaw, M.; Nabi, D.A.; Williams, A. Facial expression of emotion and perception of the Uncanny Valley in virtual characters. Comput. Hum. Behav. 2011, 27, 741–749. [Google Scholar] [CrossRef]
- Courgeon, M.; Clavel, C. MARC: A framework that features emotion models for facial animation during human—Computer interaction. J. Multimodal User Interfaces 2013, 7, 311–319. [Google Scholar] [CrossRef]
- Ruttkay, Z.; Noot, H.; Ten Hagen, P. Emotion Disc and Emotion Squares: Tools to Explore the Facial Expression Space. Comput. Graph. Forum 2003, 22, 49–53. [Google Scholar] [CrossRef]
- Chan, J.C.P.; Irimia, A.S.; Ho, E.S.L. Emotion Transfer for 3D Hand Motion using StarGAN. In Computer Graphics and Visual Computing (CGVC); Ritsos, P.D., Xu, K., Eds.; The Eurographics Association: London, UK, 2020. [Google Scholar]
- Wang, Y.; Tree, J.E.F.; Walker, M.; Neff, M. Assessing the Impact of Hand Motion on Virtual Character Personality. ACM Trans. Appl. Percept. 2016, 13. [Google Scholar] [CrossRef] [Green Version]
- Jörg, S.; Hodgins, J.; Safonova, A. Data-Driven Finger Motion Synthesis for Gesturing Characters. ACM Trans. Graph. 2012, 31. [Google Scholar] [CrossRef]
- Ye, Y.; Liu, C.K. Synthesis of Detailed Hand Manipulations Using Contact Sampling. ACM Trans. Graph. 2012, 31, 41:1–41:10. [Google Scholar] [CrossRef]
- Liu, C.K. Synthesis of Interactive Hand Manipulation. In Proceedings of the 2008 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, SCA ’08, Aire-la-Ville, Switzerland, 7–9 July 2008; pp. 163–171. [Google Scholar]
- Andrews, S.; Kry, P.G. Policies for Goal Directed Multi-Finger Manipulation. In Proceedings of the VRIPHYS 2012: 9th Workshop on Virtual Reality Interaction and Physical Simulation, Darmstadt, Germany, 9–23 September 2012. [Google Scholar]
- Liu, C.K. Dextrous Manipulation from a Grasping Pose. In Proceedings of the ACM SIGGRAPH 2009 Papers, SIGGRAPH’09, New York, NY, USA, 1–2 August 2009; pp. 59:1–59:6. [Google Scholar]
- Bai, Y.; Liu, C.K. Dexterous manipulation using both palm and fingers. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1560–1565. [Google Scholar]
- Alexanderson, S.; O’Sullivan, C.; Beskow, J. Robust online motion capture labeling of finger markers. In Proceedings of the 9th International Conference on Motion in Games; ACM: New York, NY, USA, 2016; pp. 7–13. [Google Scholar]
- Han, S.; Liu, B.; Wang, R.; Ye, Y.; Twigg, C.D.; Kin, K. Online Optical Marker-Based Hand Tracking with Deep Labels. ACM Trans. Graph. 2018, 37. [Google Scholar] [CrossRef] [Green Version]
- Irimia, A.S.; Chan, J.C.P.; Mistry, K.; Wei, W.; Ho, E.S.L. Emotion Transfer for Hand Animation. In MIG ’19: Motion, Interaction and Games; ACM: New York, NY, USA, 2019; pp. 41:1–41:2. [Google Scholar]
- Wheatland, N.; Jörg, S.; Zordan, V. Automatic Hand-Over Animation Using Principle Component Analysis. In Proceedings of the Motion on Games; Association for Computing Machinery: New York, NY, USA, 2013; pp. 197–202. [Google Scholar]
- Unuma, M.; Anjyo, K.; Takeuchi, R. Fourier Principles for Emotion-based Human Figure Animation. In Proceedings of the 22Nd Annual Conference on Computer Graphics and Interactive Techniques; ACM: New York, NY, USA, 1995; pp. 91–96. [Google Scholar]
- Amaya, K.; Bruderlin, A.; Calvert, T. Emotion from Motion. In Proceedings of the Conference on Graphics Interface ’96, Toronto, ON, Canada, 22–24 May 1996; pp. 222–229. [Google Scholar]
- Brand, M.; Hertzmann, A. Style machines. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, Orleans, LA, USA, 23–28 July 2000; pp. 183–192. [Google Scholar]
- Urtasun, R.; Glardon, P.; Boulic, R.; Thalmann, D.; Fua, P. Style-based motion synthesis. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2004; Volume 23, pp. 799–812. [Google Scholar]
- Ikemoto, L.; Arikan, O.; Forsyth, D. Generalizing motion edits with gaussian processes. ACM Trans. Graph. Tog 2009, 28, 1–12. [Google Scholar] [CrossRef]
- Xia, S.; Wang, C.; Chai, J.; Hodgins, J. Realtime style transfer for unlabeled heterogeneous human motion. Acm Trans. Graph. Tog 2015, 34, 1–10. [Google Scholar] [CrossRef]
- Hsu, E.; Pulli, K.; Popović, J. Style Translation for Human Motion. In Proceedings of the ACM SIGGRAPH 2005 Papers, Los Angeles, CA, USA, 9–13 August 2015; pp. 1082–1089. [Google Scholar]
- Shapiro, A.; Cao, Y.; Faloutsos, P. Style Components. In Proceedings of the Graphics Interface 2006, Toronto, ON, Canada, 7–9 July 2006; pp. 33–39. [Google Scholar]
- Holden, D.; Habibie, I.; Kusajima, I.; Komura, T. Fast Neural Style Transfer for Motion Data. IEEE Comput. Graph. Appl. 2017, 37, 42–49. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smith, H.J.; Cao, C.; Neff, M.; Wang, Y. Efficient Neural Networks for Real-Time Motion Style Transfer. In Proceedings of the International Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 28 July–1 August 2019; Volume 2. [Google Scholar]
- Lee, S.J.; Popović, Z. Learning Behavior Styles with Inverse Reinforcement Learning. ACM Trans. Graph. 2010, 29. [Google Scholar] [CrossRef]
- Selim, A.; Elgharib, M.; Doyle, L. Painting Style Transfer for Head Portraits Using Convolutional Neural Networks. ACM Trans. Graph. 2016, 35, 129:1–129:18. [Google Scholar] [CrossRef]
- Elad, M.; Milanfar, P. Style Transfer Via Texture Synthesis. IEEE Trans. Image Process. 2017, 26, 2338–2351. [Google Scholar] [CrossRef] [PubMed]
- Matsuo, S.; Shimoda, W.; Yanai, K. Partial style transfer using weakly supervised semantic segmentation. In Proceedings of the 2017 IEEE International Conference on Multimedia Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 267–272. [Google Scholar]
- Ma, Y.; Paterson, H.M.; Pollick, F.E. A motion capture library for the study of identity, gender, and emotion perception from biological motion. Behav. Res. Methods 2006, 38, 134–141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chan, J.C.P.; Shum, H.P.H.; Wang, H.; Yi, L.; Wei, W.; Ho, E.S.L. A generic framework for editing and synthesizing multimodal data with relative emotion strength. Comput. Animat. Virtual Worlds 2019, 30, e1871. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-domain Image-to-Image Translation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 1–23 June 2018; pp. 8789–8797. [Google Scholar]
- Holden, D.; Saito, J.; Komura, T. A Deep Learning Framework for Character Motion Synthesis and Editing. ACM Trans. Graph. 2016, 35. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Men, Q.; Ho, E.S.L.; Shum, H.P.H.; Leung, H. A Quadruple Diffusion Convolutional Recurrent Network for Human Motion Prediction. IEEE Trans. Circuits Syst. Video Technol. 2020. [Google Scholar] [CrossRef]
- Aristidou, A.; Zeng, Q.; Stavrakis, E.; Yin, K.; Cohen-Or, D.; Chrysanthou, Y.; Chen, B. Emotion Control of Unstructured Dance Movements. In Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation, Los Angeles, CA, USA, 28–30 July 2017. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotion | Characteristics |
|---|---|
| Angry | exaggerated, fast, large range of motion |
| Happy | energetic, large range of motion |
| Neutral | normal, styleless motion |
| Sad | sign of tiredness, small range of motion |
| Fearful | asynchronous finger movements, small range of motion |
| Emotion | Captured | Synthesized |
|---|---|---|
| Angry | 70.00% | 73.33% |
| Happy | 60.00% | 60.00% |
| Sad | 70.00% | 60.00% |
| Fearful | 63.33% | 70.00% |
| Average | 65.83% | 65.83% |
| Perceived Emotion | |||||
|---|---|---|---|---|---|
| Angry | Happy | Sad | Fearful | ||
| Angry | 70.00% | 15.00% | 3.33% | 11.67% | |
| Ground Truth Labels | Happy | 23.33% | 60.00% | 6.67% | 10.00% |
| Sad | 6.67% | 10.00% | 70.00% | 13.33% | |
| Fearful | 13.33% | 10.00% | 13.33% | 63.33% | |
| Perceived Emotion | |||||
|---|---|---|---|---|---|
| Angry | Happy | Sad | Fearful | ||
| Angry | 73.33% | 16.67% | 0.00% | 10.00% | |
| Ground Truth Labels | Happy | 23.33% | 60.00% | 6.67% | 10.00% |
| Sad | 0.00% | 21.67% | 60.00% | 18.33% | |
| Fearful | 6.67% | 0.00% | 23.33% | 70.00% | |
| Synthesized is more pleasant | 46.67% |
| Do not know | 13.33% |
| Captured is more pleasant | 40.00% |
| Synthesized is more pleasant | 45.00% |
| Do not know | 18.33% |
| Irimia et al. [15] is more pleasant | 36.67% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chan, J.C.P.; Ho, E.S.L. Emotion Transfer for 3D Hand and Full Body Motion Using StarGAN. Computers 2021, 10, 38. https://doi.org/10.3390/computers10030038
Chan JCP, Ho ESL. Emotion Transfer for 3D Hand and Full Body Motion Using StarGAN. Computers. 2021; 10(3):38. https://doi.org/10.3390/computers10030038
Chicago/Turabian StyleChan, Jacky C. P., and Edmond S. L. Ho. 2021. "Emotion Transfer for 3D Hand and Full Body Motion Using StarGAN" Computers 10, no. 3: 38. https://doi.org/10.3390/computers10030038
APA StyleChan, J. C. P., & Ho, E. S. L. (2021). Emotion Transfer for 3D Hand and Full Body Motion Using StarGAN. Computers, 10(3), 38. https://doi.org/10.3390/computers10030038