This study included two different sessions performed with the MATB task scenario. Session 1 included the collection of data from an EEG, ECG, eye activity tracker and control input device. The data were used to perform offline calibration and validation of the EEG model and multimodal ANFIS models. For Session 2, two separate rounds were performed, which included the online validation of the EEG model and the ANFIS models.
5.1. Discussion of the Pairwise Correlation Analysis
Features used as part of this study included the extraction of four eye activity features, the output from an EEG model, one cardiac feature and one control input feature. The respective features were analyzed, using the pairwise correlation between the respective features and the pre-determined task level. The pairwise correlation served to verify features that were sensitive to changes in MWL in a MATB task scenario. Additionally, this analysis was conducted to assess which features were suitable for creating various generic feature combinations and subject-specific feature combinations.
The results from analyzing the pairwise correlation in Session 1 showed that several features, including BPM, SPE, pupil diameter, proportional dwell time and the EEG model’s output are consistent with previous studies, where they showed to be sensitive to changes in MWL. For the eye activity features, this included a negative correlation with BPM [
20,
21,
65], positive correlation with pupil diameter [
20,
22,
23], correlation with proportional dwell time [
14] and positive correlation with SPE [
24]. As for the sensitivity with the CI, this study demonstrated a strong correlation with the task level. Another study implementing a similar control input measure did not find a correlation with the variation in task load [
66]. The strong correlation was a positive outcome although the result from the CI feature was expected, as the MATB task scenario was highly dependent on more control inputs as the task levels increased. As for the EEG model, the SPoC framework, first proposed by Dähne et al. [
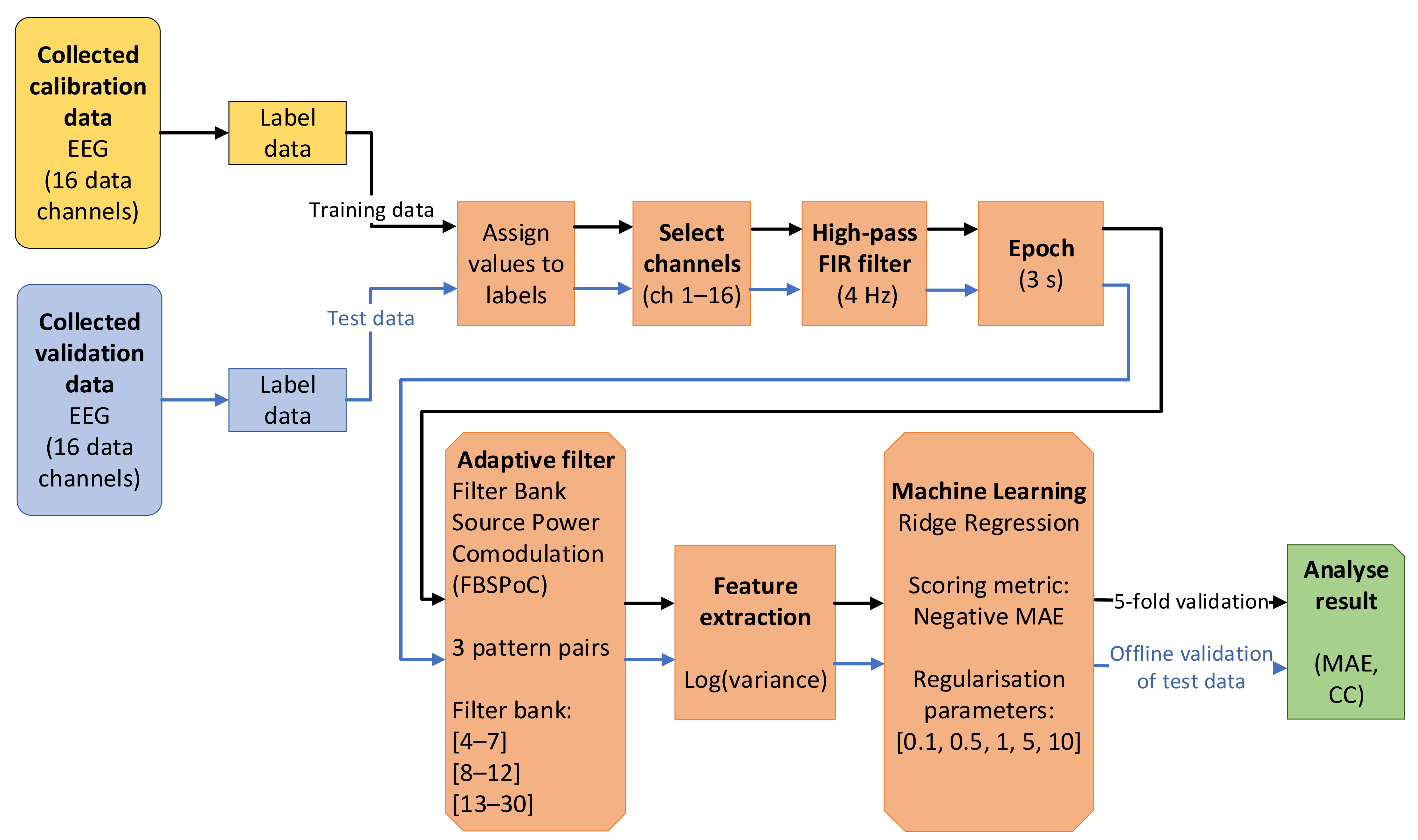
32], previously showed to be effective in classifying MWL between high and low MWL conditions [
67]. Similarly, this study demonstrated that the use of a FBSPoC method in combination with a ridge regression model was effective in inferring MWL, using unseen offline validation data.
Among all the features, HR was the only physiological feature that showed a poor correlation with the task level across all subjects and thus indicated that the HR feature was not sensitive to changes in the task load. Although some studies showed that HR was sensitive to changes in MWL [
15,
25,
68], there was variability in the reported results, where other studies did not find a correlation with MWL [
69]. Since the HR measure showed a poor correlation across all subjects in Session 1, it was not implemented in Session 2.
Similar to Session 1, the pairwise correlation with the task level was conducted for all the respective features in Session 2. The results from this analysis demonstrated that features with a high-level correlation for both rounds included SPE and BPM. However, the EEG model’s output showed a high-level correlation in the first round (offline validation) but a moderate-level correlation in the second round (online validation). Lastly, the CI, proportional dwell time and pupil diameter features showed a moderate-level correlation for both rounds. In comparison with Session 1, most of the features were quite consistent, while the most notable difference was BPM. The BPM feature showed the second lowest correlation in Session 1 but showed a high-level correlation in both rounds in Session 2. The difference in performance between the two sessions could not be conclusively traced to a particular reason. Nevertheless, the standard deviation for BPM was quite high in Session 1 with CC = −0.45 ± 0.30. As made evident by the high standard deviation, BPM did, in fact, demonstrate a high-level correlation for several subjects in Session 1. Moreover, as part of future research, it would be applicable to include additional statistical analysis that can investigate statistical differences between experimental sessions. Hence, most of the respective features, apart from CI, demonstrated in both rounds in Session 2 an average correlation with the task level that was consistent with previous findings in the literature.
5.2. Discussion of Session 1 Results
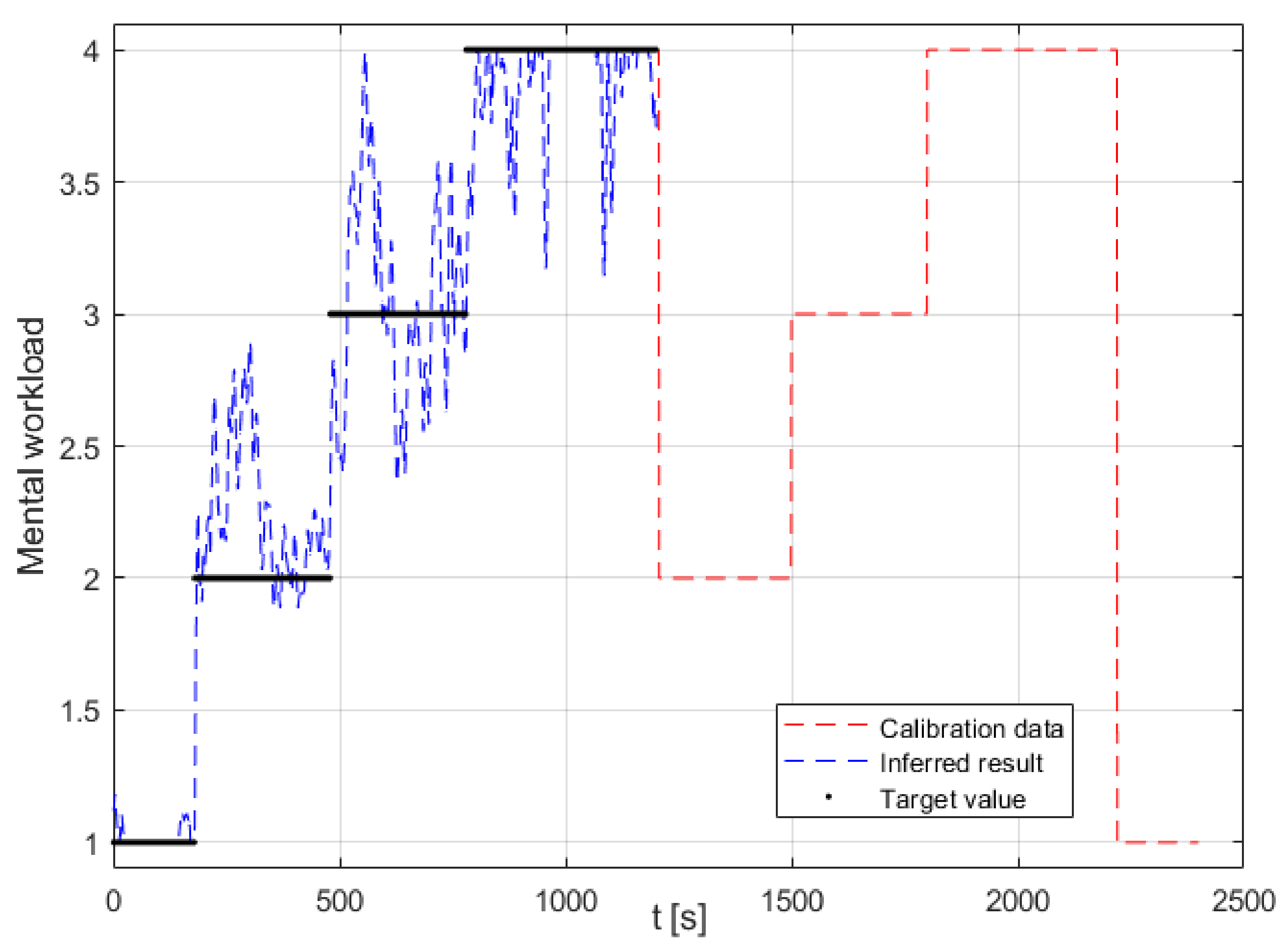
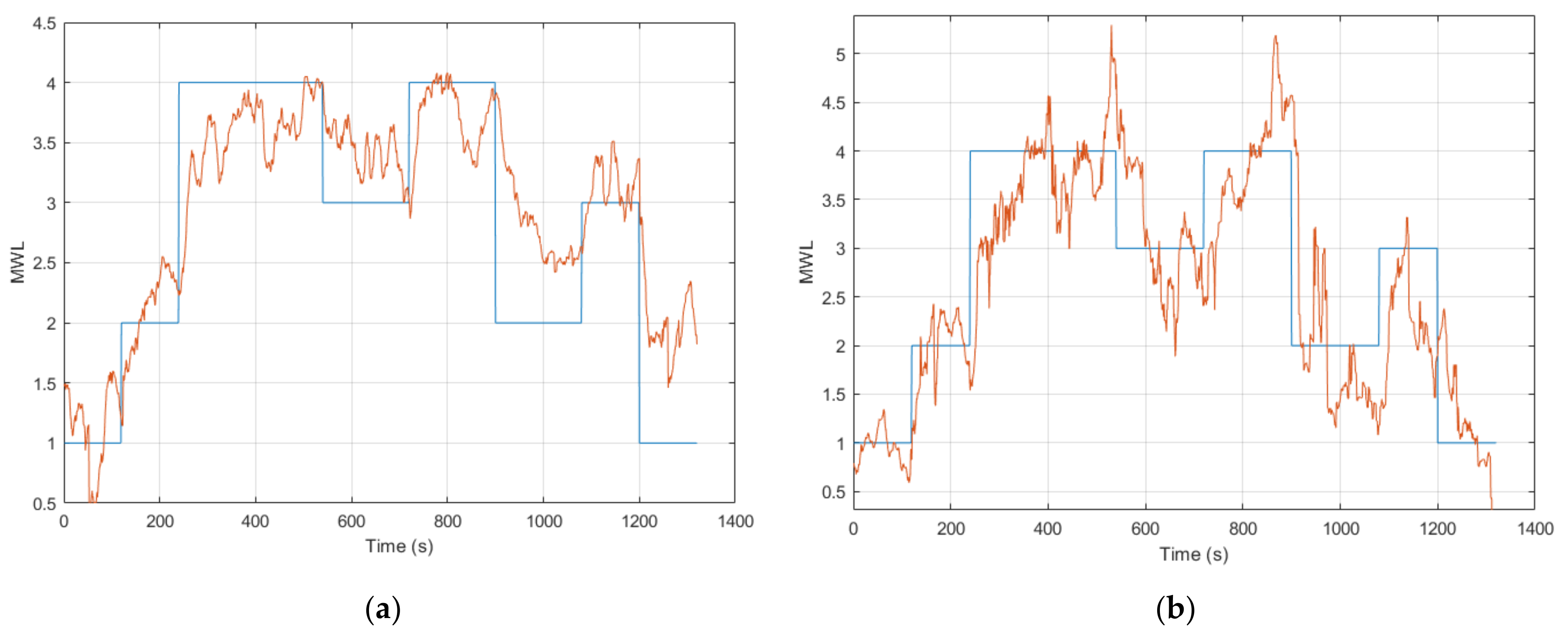
The results from a preliminary analysis in Session 1 (from calibrating and validating the ANFIS model in offline processing) demonstrated that among the generic feature combinations that were tested, the ones that performed the best were ANFIS models that contained two or more features that correlated strongly with the task level. This generally included the use of the EEG, SPE and/or CI in the feature combination and demonstrated results with a MAE ranging between 0.30 to 0.36 (see
Table A1 Appendix A).
A subject-specific feature combination was customized for each subject (
Section 3.3) and was determined by the preceding pairwise correlation analysis (
Section 3.2). Here, the best performing ANFIS models for each subject were selected for further implementation and analysis. The results from this demonstrated that the subject-specific feature combination with CI (ANFIS model 11) gave the lowest error across all the models tested (MAE = 0.28 ± 0.05). Nonetheless, the results from using all seven applicable features in the combination (ANFIS model 8) showed a MAE = 0.36 ± 0.10. While ANFIS model 11 demonstrated a smaller error, ANFIS model 8 showed quite a comparable result, thereby demonstrating that the use of other non-contributing features was not severely detrimental to the ANFIS model when performing multimodal inference of MWL.
The use of NFS for MWL inference was demonstrated in a few previous studies. In studies conducted by Zhang et al. [
58,
59], EEG and cardiac features were implemented during an aCAMS scenario, where the calibration and validation was conducted offline. The optimization of the FIS parameters was achieved by testing both a GA-based Mamdani fuzzy model and an ANFIS model. Of note, Session 1 of this study differed from Zhang et al. [
58,
59], as the feature combination was different. This can be deduced, as the features used included an EEG measure that was solely determined by the ratio of band-power from theta and alpha, while the cardiac features included using HR and HRV. In addition, the sampling intervals used were quite long, as it was performed every 7.5 min as compared to this study in which samples were recorded every second (apart from the EEG model, which had 3 s intervals). Furthermore, the study did not present a performance analysis of the individual features, but only analyzed data obtained by calibrating and validating the models. Lastly, while the GA-based Mamdani fuzzy model showed promising results in the study conducted by Zhang et al. [
58,
59], the ANFIS model implemented did not perform well on the unseen validation data.
Similarly, in a study by Wang et al. [
46], an extension of the preceding studies by Zhang et al. [
58,
59] was expanded on by implementing a DE and a DEACS as methods to optimize the ANFIS parameters. The same features were extracted, although a shorter sampling interval of 2 min was used as compared to that of Zhang et al. [
58,
59] which used a 7.5 min interval. Wang et al. [
46] also presented results from a conventional ANFIS model that performed poorly on the unseen validation data. Nonetheless, the DE-ANFIS and the DEACS-ANFIS showed good performance on the unseen validation data. The lack of the regular ANFIS model’s ability to infer MWL could be a result of the lack in calibration data, as the sampling interval was relatively long.
In a study conducted by Lim et al. [
52], an ANFIS model was also implemented and calibrated on data from cardiac features (HR and HRV), eye activity features (BPM and a SPE feature) and features from an fNIR (oxygenation and blood volume). The initial offline calibration and validation demonstrated a low error. Nevertheless, the features and target values were, in that study, normalized between 0 and 1 before calibrating the model, whereas in Session 1 of this study, the original values from the features were used. Furthermore, in the study by Lim et al. [
52], the initial offline calibration and validation were performed on all the data.
The experiment conducted in Session 1 of this study is thus differentiated from the aforementioned studies by implementing a different set of feature combinations, rigorously testing the individual features and testing multiple feature combinations for the ANFIS model. Additionally, this study implemented more frequent intervals and thus a higher amount of calibration and validation data (especially compared to Zhang et al. and Wang et al. [
46,
58]). In particular, the analysis of the contribution of each feature combination was more recently highlighted as an important factor for examining the performance of the model implemented [
50,
51]. In Session 1 of this study, the offline analysis also demonstrated that the ANFIS models were able to infer MWL accurately based on unseen offline validation data.
5.3. Discussion of Session 2 Results
Session 2 included the online validation of the ANFIS models. This involved presenting results from a few different aspects, including (1) the online cross-session capability of ANFIS models 1 to 5 during Round 1 (tested on six participants), (2) online within-session inference for ANFIS models 1 to 9 in Round 2 (tested on all the participants) and (3) testing ANFIS models 10 and 11, which were calibrated using a subject specific feature combination for five of the subjects that completed Session 1.
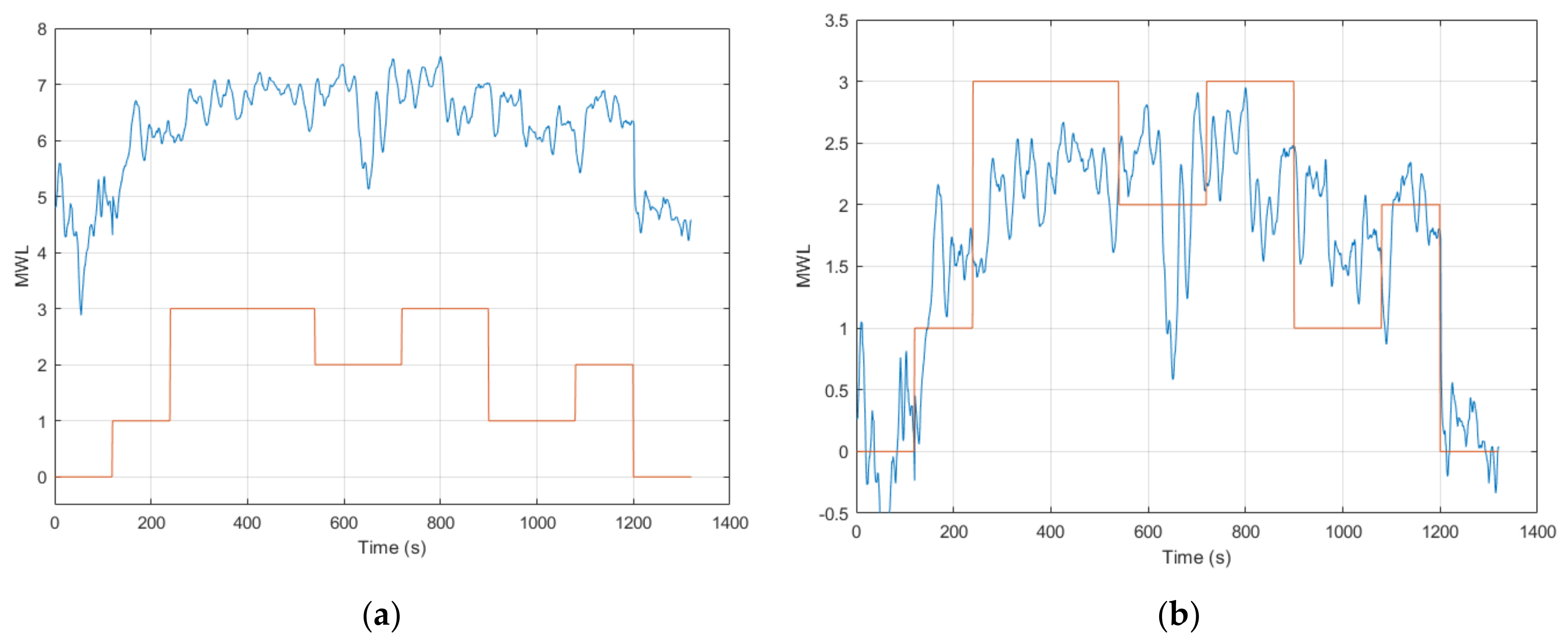
The online cross-session validation of ANFIS models 1 to 5 (containing different feature combinations of eye activity and control input features) showed good results for all the models, with a MAE of around 0.7, the best one being ANFIS model 2 (containing the Scan Pattern Entropy feature and the CI feature), which achieved a MAE = 0.63 ± 0.23. These results were, on average, twice as high compared to the offline validation results presented in Session 1 but still demonstrated a good ability for the online inference of MWL, using a cross-session model that incorporated eye activity and CI features. Ideally, the remaining ANFIS models 6 to 11 (containing the EEG model’s output in the feature combination) would have been tested for an online cross-session validation. Nonetheless, the BrainVision Recorder software (required to record the raw EEG data) and the NeuroPype software (used to process the EEG data) could not be run at the same time, due to networking constraints. Moreover, preliminary testing indicated that the EEG model lacked in the ability to perform cross-session inference of MWL. This was likely due to factors such as changes in electrode impedance and electrode position in between sessions. However, this was not conclusively tested, due to the networking constraints.
The online validation results in Round 2 proved to be somewhat more variable for the ANFIS models. This was mainly a result of a discrepancy with the EEG model’s online output that had an arbitrary offset. This discrepancy resulted in an average MAE = 3.04 ± 2.47 across all subjects; however, adjusting for the offset gave an average MAE = 1.06 ± 0.31. Although improved, this still gave a considerably higher error compared to the offline validation results (see
Section 3.1 and
Section 4.1.2). Looking further at the pairwise correlation showed an average CC = 0.54 ± 0.24. Nevertheless, excluding three of the subjects that showed poor or no correlation with the task level yielded a quite strong average pairwise correlation of CC = 0.65. The offset imbedded in the EEG model’s output likely occurred for the respective subjects due to a loss of validity of calibration. This highlights the benefits of introducing online calibration for the CHMS in future research. Online calibration can be conducted similarly to how the offset was accounted for in post processing. This would include adjusting for any offset during a resting condition or another baseline condition, prior to commencing the task scenario.
As ANFIS models 1 to 5 did not include the EEG model’s output, the results remained quite good and performed equally well, with a slightly improved result compared to the cross-session validated ANFIS models 1 to 5 from Round 1 (see
Section 4.1.1). Hence, this demonstrated the accuracy and repeatability of the ANFIS models that contained eye activity and CI features.
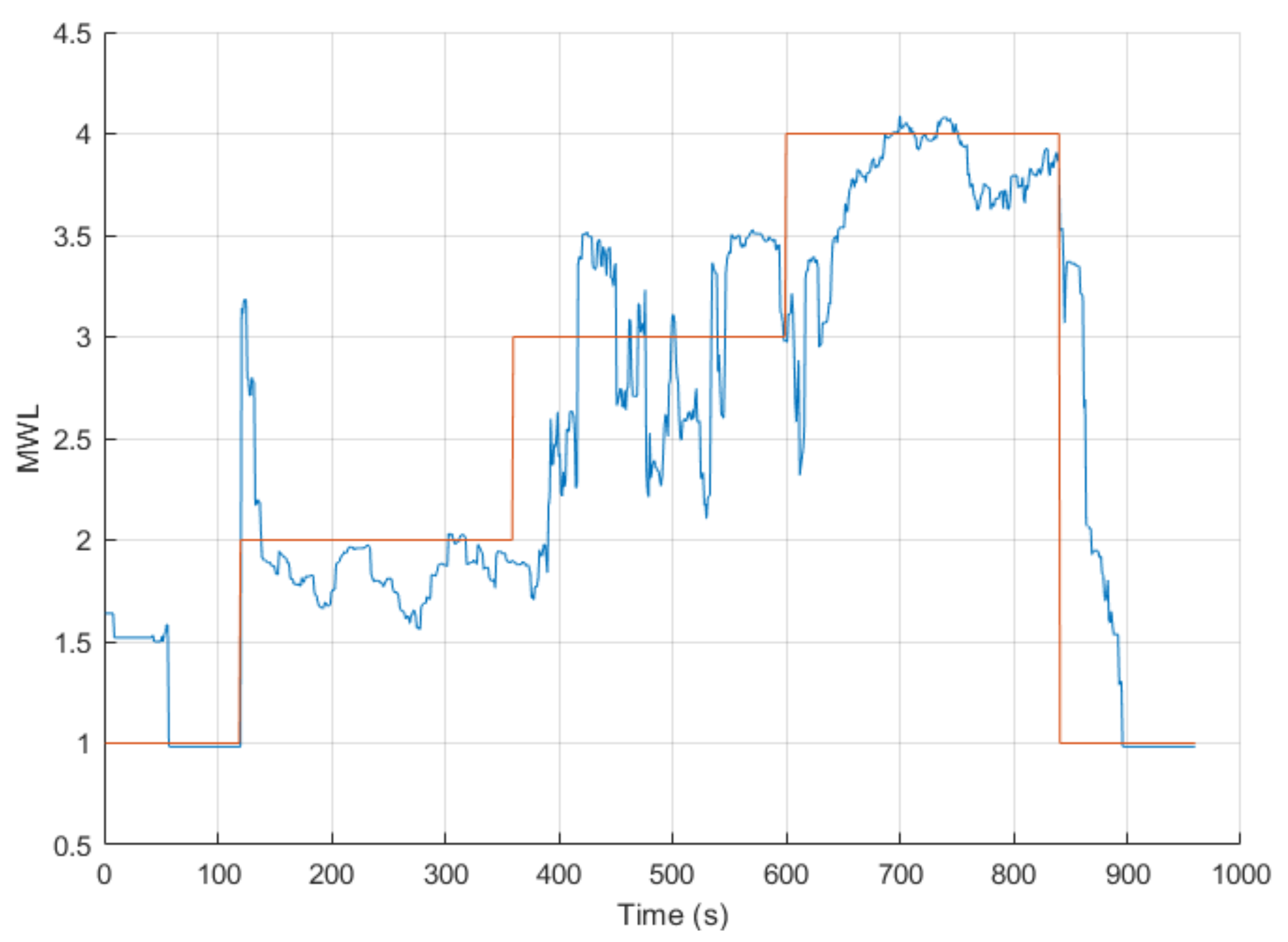
ANFIS models 6 to 9 showed a high error (a MAE between 1.17 to 1.59) with the task level as a result of the discrepancy with the EEG model’s output. However, looking at the normalized pairwise correlation between the respective ANFIS models and the task level showed a quite strong average correlation result that ranged from 0.61 to 0.69. ANFIS models 10 and 11 were calibrated with the subject-specific feature combination for five of the six subjects that completed Session 1. These ANFIS models demonstrated similar results to ANFIS models 6 to 9, as these models also contained the EEG model’s output. Nevertheless, the pairwise correlation showed an equally strong correlation with the task level. Moreover, ANFIS model 11 achieved a CC = 0.77 ± 0.06 across all the respective subjects, which was the highest among all the models tested. However, the results are not directly comparable, as these models were tested on five out of the twelve subjects. When further examining the results for the participants that did produce an output from the EEG model as expected, the results are, in fact, quite strong with a low error. This can be seen for participant 7, where all the ANFIS models for that subject produced comparably good results.
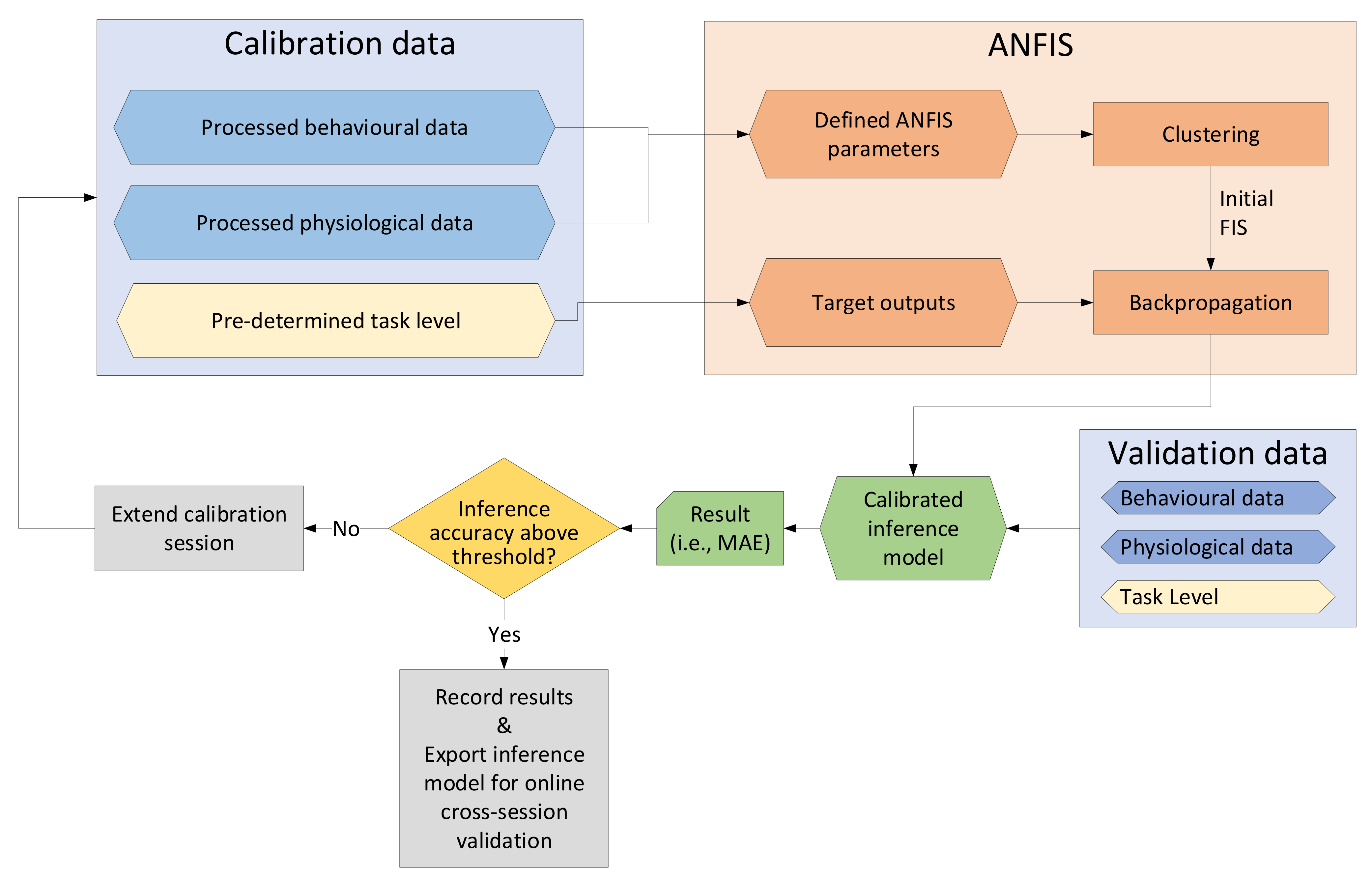
As part of the analysis, a threshold criterion was set as outlined in
Section 2.5.4. Using three-scaled mean absolute deviations from the median gave upper and lower thresholds that were appropriately distanced from the median, thus preventing instances with excessive inference of MWL. For future implementation of a full CHMS, a similar methodology can be implemented in real time by defining upper and lower thresholds (i.e., by setting an upper bound to 5 and a lower bound to 0) in the software, which will prevent excessive inference of MWL.
The analysis of the models’ performance was conducted by calculating the MAE and was chosen over the alternative Root Mean Square Error (RMSE). Whereas the MAE takes the average of the absolute error, RMSE squares the error. This means that large errors are penalized harsher with RMSE than with MAE. Due to the nature of this research, the ground truth is not precisely known. Therefore, it is arguably preferable to use MAE because it penalizes deviations from the target value less.
As discussed above, the use of NFS for multimodal fusion was conducted in a few previous studies. However, an online validation was only conducted for a limited number of studies [
52,
53]. As mentioned above, an ANFIS model was implemented in a study by Lim et al. [
52]. Whereas the offline validation demonstrated a low error, the results from the online validation showed a poor-level correlation with the target value and a relatively high error.
In another study by Ting et al. [
53], an extension of the work based on Zhang et al. [
58] was conducted to perform an online inference of MWL, using HRV, an EEG measure and a task performance measure during an aCAMS scenario. This online inference of MWL was further tested for driving real-time system adaptation. A NFS was implemented, although a GA-based Mamdani fuzzy system was used to optimize the parameters, unlike this study, which used an ANFIS. The intervals for the physiological measures were quite long at 7.5 min intervals, although the task performance measure was taken at 150 s (with a moving average applied). Arguably, this interval can be considered quite high for the requirements of driving system adaptation in a sensing and estimation module of a CHMS. Whereas Ting et al. [
53] focused on real-time system adaptation, this study thus deviates, as that study did not include a detailed analysis of the online performance of the inference model implemented.
Additional studies also used other methods for multimodal fusion when estimating MWL in real-time [
45,
48,
54]. A notable study was conducted by Wilson and Russell [
48], where an ANN was used to fuse data from EEG, EOG and cardiorespiratory measures in a MATB task scenario, using resting, low and high task load conditions. Here, the ANN performed online classification on the respective task load at 5 s intervals and demonstrated a classification accuracy of 84.3%. However, for the multimodal fusion conducted in this study, a regression approach was implemented with a continuous inference of MWL. This is arguably preferable for driving system adaptation in a CHMS system.
Session 2 of this study differentiates from the aforementioned studies by demonstrating the online validation of a multimodal inference model of MWL. This was done by using an ANFIS and thoroughly assessing the performance of various models tested (ANFIS models 1 to 11) as well as assessing the individual features. The feature combinations implemented are, moreover, different, and a regression approach was implemented, contrarily to the study by Wilson and Russell [
48]. Hence, this study demonstrated the inference of MWL in real time with the fusion of multiple modalities with an ANFIS to produce one accurate and repeatable measure of MWL at regular intervals. This mainly included ANFIS models 1 to 5, which additionally demonstrated the capability for cross-session inference of MWL. However, ANFIS models 6 to 9 included the EEG model’s output that had a discrepancy with an offset that equally skewed the ANFIS model’s output. Nevertheless, the efficacy of the EEG model and resulting ANFIS models could be seen with the normalized pairwise correlation with the task level. Lastly, the subject-specific feature combinations used for calibrating ANFIS models 10 to 11 (calibrated on five participants that completed Session 1), equally demonstrated a skewed output due to the EEG model’s output. However, a strong pairwise correlation was seen with the task level, with ANFIS model 11 showing the highest correlation among all the eleven ANFIS models tested in the online validation session (CC = 0.77 ± 0.06).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






