1. Introduction
In cloud computing, security has been a challenge because a third party has access to our data, and the data should be trusted to a third party. Recent trends in cloud security have played an important role in attracting organizations/companies to deploy sensitive data on the cloud. In this paper, the IT Security Specialist, ITSS, is referred to as the person responsible for a company/institution who realizes the “configuration” of security for other users in the organization.
In this context, the proposed model offers different scenarios based on the level of sensitivity of data [
1]. From another point of view, this increases the reliability of clients in cloud computing. This reliability will be increased by offering data security controls to end-user ITSS. Our model, shown in
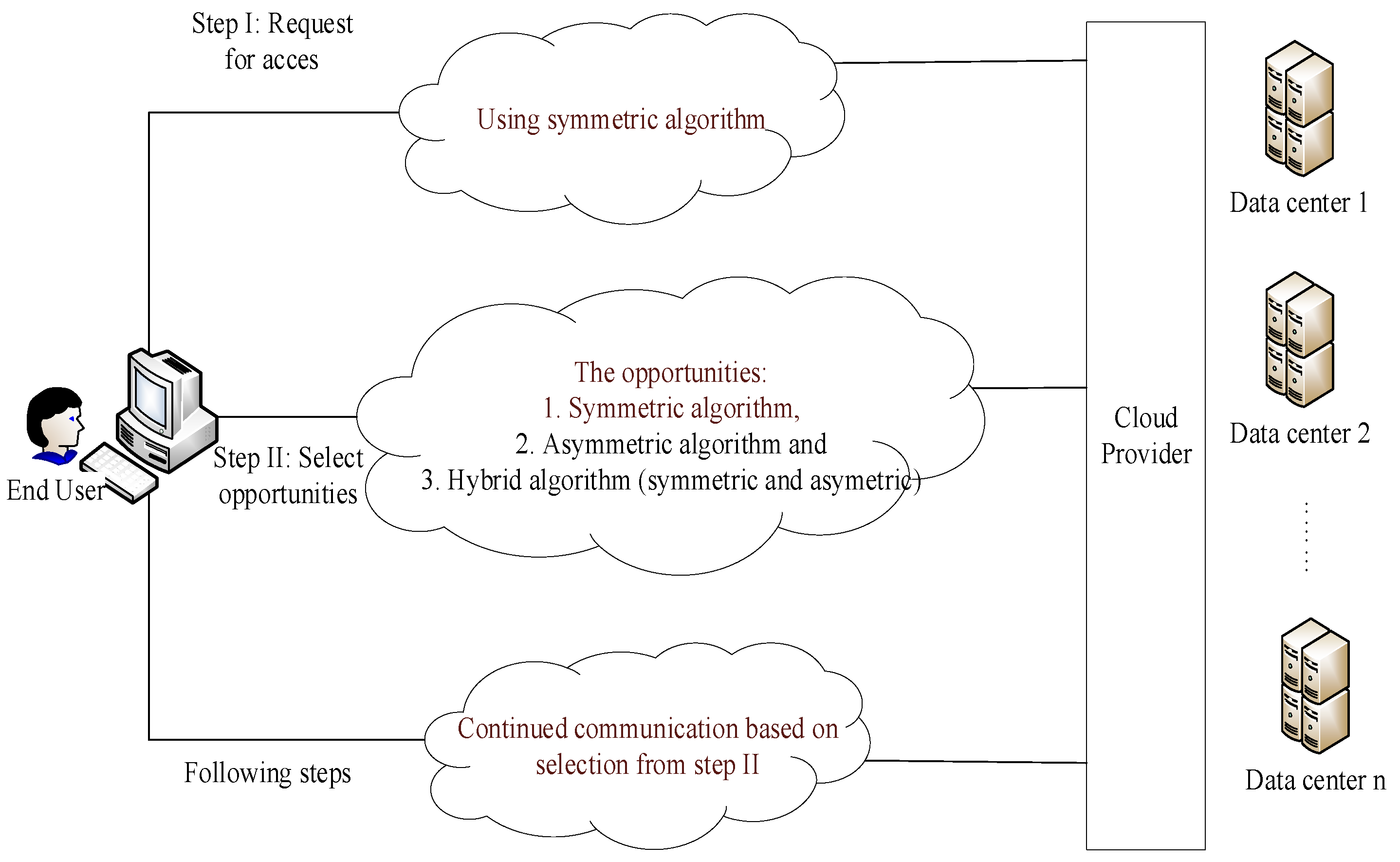
Figure 1, was proposed in [
1] with the same philosophy for controlling security in the cloud, which is based on two objectives: the control of security depending on the ITSS of a certain organization and the possibility of selecting options based on different algorithms. The increase in requirements in programming for performing tasks simultaneously in traditional programming has encountered requirements that cannot be covered by the increase in resources, such as multi-processor processing. After all this, another method of programming is required that will function asynchronously; thus, in order to realize these requirements, we use reactive programming.
The focus of the study will be the evaluation of the effect of reactive programming on the proposed model for cloud security. The effect will be evaluated from the aspect of performance but also from the aspect of the application development process. The language that will be used for this paper is C #, as it is a well-established language with libraries that will facilitate the development, and our aim will be to compare the synchronous programming that developed the solution offered in [
1] and the reactive one that is realized in this study.
There is a great deal of research that has been conducted on reactive programming [
2,
3,
4] that shows the ideas of reactive programming from a theoretical point of view as well as the mathematical models that stand behind the reactive model, which are sometimes difficult concepts to understand, especially for those who have programmed only with traditional techniques. A programming paradigm refers to the programming style, which means building the structure and elements of the program. There are some characteristics that define a programming paradigm, such as modularity, objects, interruptions or events, control flow, etc. [
5]. Everyone has an opinion as to which of the programming paradigms, or coding styles, is best. Sometimes, a single model is not the only solution to the problem and must be combined with different models to solve the same problem, which we propose in our paper.
Using commands such as threads, locks, and events that refer to asynchronous programming, we can achieve the required result, which we completed during this work.
Functional reactive programming enables us to preserve the asynchronous nature of modern applications while preserving the deterministic nature of traditional programming. All these applications are supported by Reactive Add-ons, which allow us to handle asynchronous sources of information, such as events. Data streams are sequences of continuous events sorted by time. They can indicate three different things: a value (of a certain type), an error, or a signal indicating “completion”. It should be noted that the signal indicating “completion” occurs, for example, when the window or the current view containing that button is closed [
6].
In general, reactive programming is constructed on two main concepts, which are:
Data source: The component that emits or transmits data to other components. This component transmits an indefinite amount of data, including transmitting even when we do not have any value. The broadcast can be completed successfully, which means the broadcast is closed or terminated, and it can stop when we have a potential error. There are cases when the data source does not stop transmitting data: even if we do not have any subscribers, some cases where the transmission of data does not stop include information about stocks, Twitter, meteorological information, etc. Data sources may have many subscribers at the same time, but they may equally not have any.
Subscribers: The component that monitors changes or monitors data sources when transmitting data. The moment data are transmitted from the data source, the onNext command is executed on each subscriber, while now, when the data source stops transmitting the data without any error, the onComplete command is executed for each subscriber. However, at the time of transmission completion, if we encounter any error, the onError command is executed on each subscriber.
This study is organized into five main parts. The first and second provide introductory information related to the paper and the purpose of using reactive programming in the proposed model for cloud security as well as providing information to resolve different problems when using reactive programming.
Furthermore, the third and fourth sections give a clear view on the proposed model in the cloud and the form of implementation of the solution while using reactive programing. In the last part, we present the results of the two solutions we have focused on: the first from implementing traditional programing and the second using reactive programming.
2. Literature Review
2.1. Reactive Programming Aspects
Reactive programming has aroused tremendous interest because it offers numerous possibilities for solving problems. These methods have been used and implemented in various systems and programming languages, from low-level to high-level languages. Reactive Programming with Node.js [
7] presents the techniques of reactive programming in Node.Js, while in Programming Reactive Extensions and LINQ [
8], we are dealing with the implementation of Reactive Programming in C # and LINQ. We see that reactive programming methods and techniques find use in different languages and systems.
Bonér, Jonas, and Viktor Klang, in their publication “Reactive Programming vs. Reactive Systems” [
9], pointed out the separation of the concepts of reactive programming and reactive systems where they tried through examples to present these two concepts. They also showed that functional reactive programming is one of the concepts that has been misunderstood and mixed with other concepts. One of the reasons for the separation of reactive programming and reactive systems is the communication method they use. Reactive programming is event-driven, while reactive systems are message-driven.
In “Reactive Programming: A Walkthrough” [
10], by Salvaneschi, Guido, et al., the uses of Reactive Programming are presented, starting from the simplest to its implementation in the Internet of Things and integrated devices. The main idea of using reactive programming is because of the fast response of the system.
Recent research shows that reactive programming is the most appropriate current method for implementing real-time systems. Thus, according to performance analyses in several programming languages and systems, works have been written in different languages and libraries for the use of reactive programming [
2,
3,
4], while research carried out shows how reactive programming is also adequate for constructing and manipulating visual images in GUI [
11,
12].
Reactive programming is a programming paradigm oriented around data streams and the distribution of changes. This means that it should be possible to easily show data streams statically or dynamically in the programming languages used and that the execution model will automatically propagate the changes through the data stream [
13,
14,
15]. It decomposes the problem into different and unique steps where each can be executed asynchronously and in a non-blocking way, and then, the workflow is carried out—there may be limits to its inputs or outputs. The main benefits of reactive programming are the increasing use of informatics resources in multicore and multi-CPU hardware and increased performance by reducing serialization points.
The other benefit is developer productivity, as traditional programming paradigms have stalled to provide a straightforward and maintainable approach to handling asynchronous and non-blocking and I/O computing [
16,
17]. Reactive programming solves most of the challenges here, as it usually eliminates the need for coordination between active components. Reactive programming excels at creating components and composing workflows. To take full advantage of asynchronous execution, the inclusion of back pressure is crucial to avoid excessive utilization or unlimited consumption of resources.
Although reactive programming is a very useful component when building modern software, to justify building a system at a higher level, reactive architecture should be used—the process of designing reactive systems. Furthermore, it is important to know that there are many programming paradigms, and reactive programming is just one of them, just as every paradigm is not intended for all use cases.
2.2. Cloud Security Aspects
The literature has suggested different models to increase security in cloud. For all the customers who are still struggling to migrate to the cloud environment, virtual machine monitoring for addressing security and privacy in the cloud is offered as a choice [
18].
The authors from [
19] proposed the Trusted Cloud Computing Platform (TCCP), which allows the calculation of the integrity and confidentiality of data sent by the provider. This platform informs the CSC (Cloud Service Client) if the data have been accessed by others or the CSC and then decides whether to interrupt the VM or to continue detecting unauthorized access. The TCCP’s main task is to ensure that nothing intervenes between the CSC, CSP (Cloud Service Provider), and VM. Finally, it is the TCCP approach, based on the plain form of the traditional TERRA belief [
20,
21], which provides the integrity and confidentiality of the data with respect to multiple hosts. The authors of [
22] offer a platform for cloud computing: Private Virtual Infrastructure (PVI). This platform manages, monitors, and combines the Trusted Platform Modules (TPMs) and the Locator Bot (LB) that provide security measurements to the properties they own; it also provides the database and offers continuous monitoring in the cloud. From this point of view, it can be said that the data security falls like the CSC and the CSP. Starting from the SLA, there are no proper roles for the security responsibilities for all participants in the cloud environment [
23,
24]. The authors of [
23,
25,
26] argue that cloud service reliability is achieved through the security level of workload to facilitate service quality assurance.
Security level determination is based on the following requirements: Workload State Integrity, Guest OS Integrity, Zombie Protection, Denial of Service attacks, malicious resource exhaustion, platform attacks, and backdoor protection. In this scientific paper, there is no clear method to determine the level of security, as it is claimed, so it is not apparent how this security level information is sent to the CSC and CSP.
The authors of [
27] proposed a private cloud monitoring and management scheme called the PCMONS. Despite many differences from traditional technologies and the cloud environments, it is argued that it is possible that these resources (inherited network and distributed management methods, etc.) have potential for reuse in the private cloud. The PCMONS is focused on centralized architecture described by these features:
A node with accumulated information, which is responsible for collecting local information for the next node;
Cluster Data Integrator—a collection of data for the next layer (collected by monitoring);
Monitoring Data Integrator, which collects information and stores it only for archives in the database and provides these data to the configuration generator;
A Virtual Machine whose task is to transfer data from the VM to the overall monitoring system;
A Configuration Generator whose task is to obtain information from the database; and
A Monitoring Tool Server is used for the sole purpose of gathering information from the monitoring of different resources from a database that is populated with notes from the Configuration Generator and the Monitoring Data Integrator.
The PCMONS projection responds to the private cloud requirements, with only space to provide a security environment for the CSC and the CSP. The whole architecture of this proposal is based on some interesting features that can be used in similar architectures with the sole purpose of providing a safe environment for all parties. One of the features that can be exploited is the monitoring data integrators, which can be exploited by the CSC as a feature to provide information in the cloud environments. From other research, it can be said that researchers have provided some security solutions in the cloud environment, some of which have been implemented. All of the focus has been on the issue of creating a credible environment and monitoring virtual equipment driven only by the CSP, not by all the participating parties, and the ability to monitor all these parties. The goal is for the entire monopoly to be implemented by the CSP. In the paper [
28], the authors discussed the advantages of implementing Blockchain and Using Honeypot Network for detecting new attacks as well as optimizing and exploiting resources, which we believe will increase PCMONS performance.
All the work is based on this slogan [
29]: “if the provider does not need to read the information, why should he be allowed to?” The belief in this article was achieved by dividing the information and then controlling the scattered parts.
In their work, the author identified five cloud computing models designed to increase cloud security:
The separation model separates the storage of data from the processing of data at different providers;
The availability model ensures that there are at least two providers for each of the data storage and processing tasks and defines a replication service to ensure that the data stored at the various stage providers remain consistent at all times;
The migration model defines a cloud data migration service to migrate data from the stage provider to another;
The tunnel model defines a data tunneling servile between a data processing service and a data stage service, introducing a layer of separation where a data processing service is oblivious of the location (or even identity) of a data storage service; and
The cryptography model extends the tunnel model by encrypting the content to be sent to the stage provider.
By using these models, which allow duplication and task sharing, they reduce their integrity, availability, and confidentiality by encrypting the data storage [
16,
30]. According to [
31], the EU confidence increases when exposure and access to sensitive data is banned.
Considering this, a solution is provided where the client requires sensitive data to be processed only in the system where their placement is required to know exactly where they are located to be within the EU. However, this is a dubious point because the cloud service providers have the right to operate all over the world.
The authors from [
32] proposed the pi-cloud (personal secure cloud), which includes the cloud resource management resources that are interrelated to each other for end users. The pi-cloud objective is the last user to format the IT Infrastructure without losing control over its data. The cloud federation refers to a personal combination of the user for private and public cloud sources.
Up to this proposal, in the cloud environments, three facilities of success are jeopardized: availability, integrity, and confidentiality.
The pi-cloud works by sharing trustworthy and untrustworthy sources. The user adapts the cloud based on their needs, providing data flow and execution of services. The pi-cloud is controlled by the pi box, and the task of this gate is to divide sensitive data from the public data. The pi box consists of four main components:
The cockpit;
The service controller;
The data controller; and
The resource manager.
3. Overview of Proposed Model Analysis for Cloud Security Controlled by End User—ITSS
We closely analyzed important elements for the proposed model for security in the cloud and the method of storing data by the organizations after these data are sent to cloud [
21], and then, we compared them with possibilities to enhance or improve our proposed model for security in the cloud, shown in
Table 1.
The elements that will be offered by the proposed model for cloud security are presented in
Table 1. As an initial part, the “configuration” of the security of the organization will be realized by the IT Security Specialist. Based on data sensitivity, we select the options mentioned below (Proposal 1, Proposal 2, and Proposal 3).
The proposed model is based on two main actors: the possibility of categorizing the level of security based on the combination of security algorithms [
33,
34] and all the control of security depending on the end user, the ITSS of a certain organization.
The proposed model enables an increase in security in the cloud (
Figure 1), offering three proposals of choice depending on the sort of sensitive data:
Proposal 1: Security is based on the choice of the end user, the ITSS, depending on the information the proposed model offers. Based on the system proposals, no other specific factors are considered except for the faster way that the system offers.
Proposal 2: Based on the features of the file, possible algorithms are proposed, along with the length of keys, to the user, and then, the user makes a choice. Based on the system proposals that consider the features of the file, the most suitable and fastest solution offered by the model is proposed.
Proposal 3: Security is based on the file cryptography by the client and by keys generated locally to the client. Thereafter, the file is partitioned and encrypted in particular parts (P1, P2,…, Pn); each part can be stored in different clouds. A new po file contains the selected algorithm, along with the indexing and the position of the file. The po file is significantly smaller, encrypted by a more powerful algorithm, and can be stored anywhere in cloud. This solution depends entirely on the selection of ITSS, not taking into account the suggestions that the model can make; the security “configuration” is performed by ITSS in case the data sensitivity is too high, and the safest path is determined using algorithms specific for data encryption and fixed/random partition number.
In this work, it can be seen how the client and the server communicate, and we have defined an executable protocol that verifies the data requested by the client. In previous research [
17], Proof of Retrieval (POR) protocols have been proposed, whose task is for large files to prove that the file was not deleted or modified during the communication process. This encryption technique takes the file and then encrypts blocks to randomly encrypt the file. After this step, the client requires its data to depend on their sensitivity to determine the manner of their archiving.
In addition, communication with cloud providers is realized according to [
23,
24] service level agreement (SLA) mutually agreed upon between all parties to provide the quality of services (QoS), which uses our proposed model for cloud security, as shown in
Figure 1.
To provide a secure communication in the communication channels, we use cryptography. As technology improves, the need to provide new encrypting strategies increases as well [
6,
13,
14], as the only reason that data can be transferred from point A—the end user—to point B—the database—is to be secured. For data encryption, we use two techniques of cryptographies: a symmetric algorithm, where the same key is used for encryption and decryption, and an asymmetric algorithm; however, different keys are used for encryption and decryption. Our proposed model not only uses these two techniques of encryption but also uses the combination of both symmetric and asymmetric algorithms as well, known as hybrid algorithms [
23].
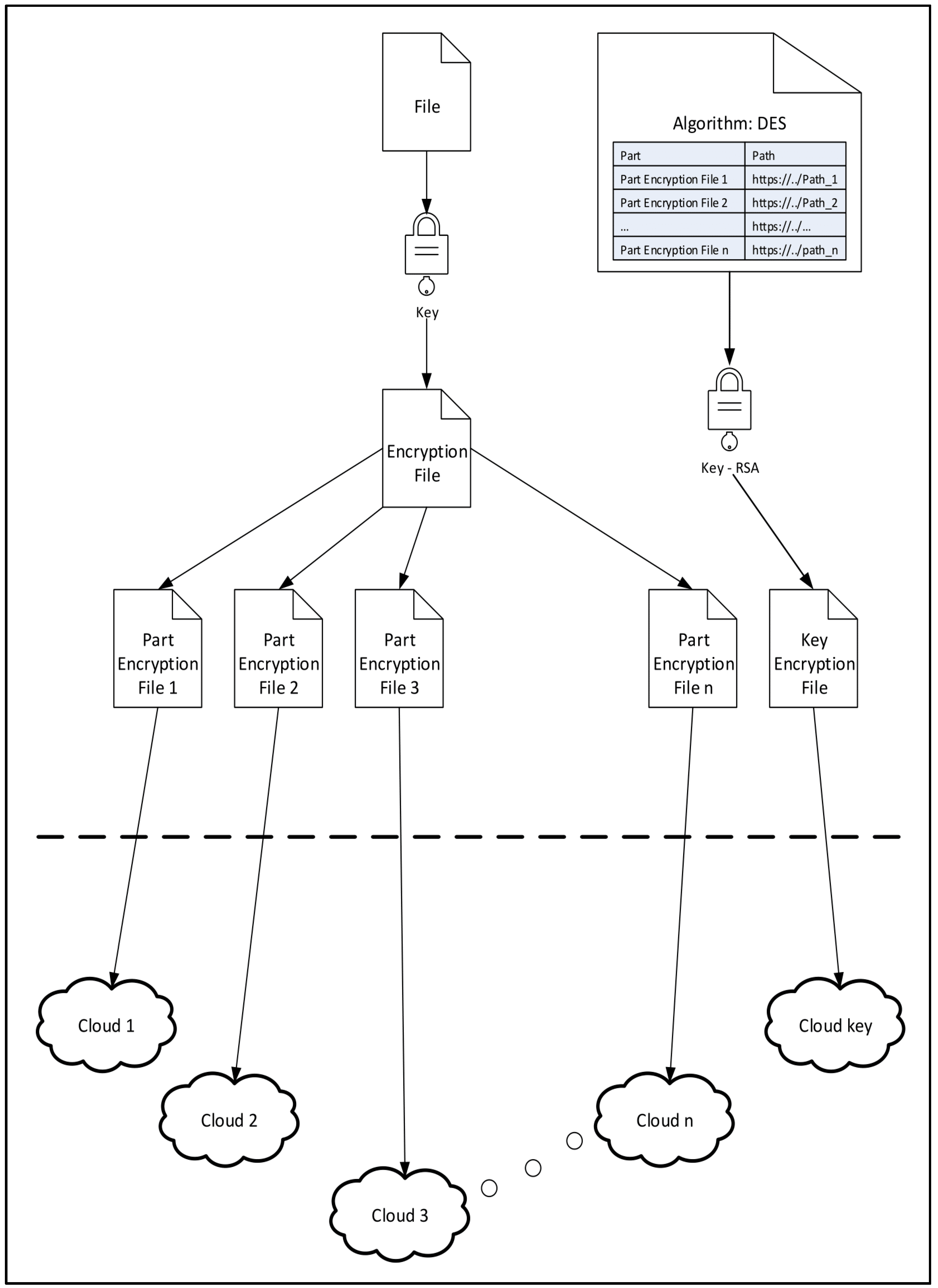
Our proposed model’s distribution of file was completed based on the number of available cloud providers, the space they have, and random distribution in
Figure 2.
Despite segments being divided depending on the partitioning method we used, another file with the suffix “.enc”, as in
Figure 2, was generated, which offers general information on the type of algorithm, the method of partitioning, and the names of the files before and after the encryption (naming of partitioning is random) as well as the keys used for cryptography. In
Figure 2, this file is named as the Key Encryption File.
Figure 3 shows a demonstrated case where a test.docx file is used for testing, and then, we used the first level and selected the RSA algorithm. Partitioning is completed randomly, and then, the partitions are encrypted.
Figure 3 shows the case of return, description, and the merging, and as a result of this option, we obtained the file test_merge.docx, which takes us to the first step. Additionally, in part of
Figure 3, we present the file test.docx..enc, which contains the information we explained above.
4. Utilization of Reactive Programming in the Proposed Model for Cloud Security
In the proposed model for cloud security proposed in [
1,
12], reactive programming was used in the partition distribution by the client to the cloud providers.
Figure 4 presents the earlier method of programming, which is presented in [
1], while in
Figure 5, the proposed method of using reactive programming in the proposed model for cloud security is presented.
We used Reactive Extensions (Rx) to use reactive programming, and the advantage of using Rx is that it offers a new way to build and integrate asynchronous events, such as coordinating multiple data streams as they arrive asynchronously from the cloud. With Rx, these streams can be “flattened” in a single method, making the code very simple.
As an example, the classic async model in .NET is to initiate each call with a BeginXXX method and end it with an EndXXX method, also known as the Begin/End model. If more than several simultaneous asynchronous calls are made, data stream control quickly becomes impossible.
However, with Rx, the Begin/End model is summarized in a single method, making the code much cleaner and easier to be changed. Reactive Add-ons can be seen as a library for building or developing asynchronous and event-based software that uses observable collections.
For the measurements, we followed the path from point A to point B, which is presented in red in
Figure 4 and
Figure 5.
Figure 4 presents the traditional programming applied in the proposed model for cloud security, while
Figure 5 presents the new solution realized in this study for the proposed model for cloud security.
In
Figure 5, for the continuation of our work, we used reactive programming realized in the model for cloud security. The reason why we decided to use reactive programming in this part,
Figure 5, is that, after the analysis of the delay time, it was seen that, when sending and receiving partitions, there are delays, and the use of reactive programming speeds up this process.
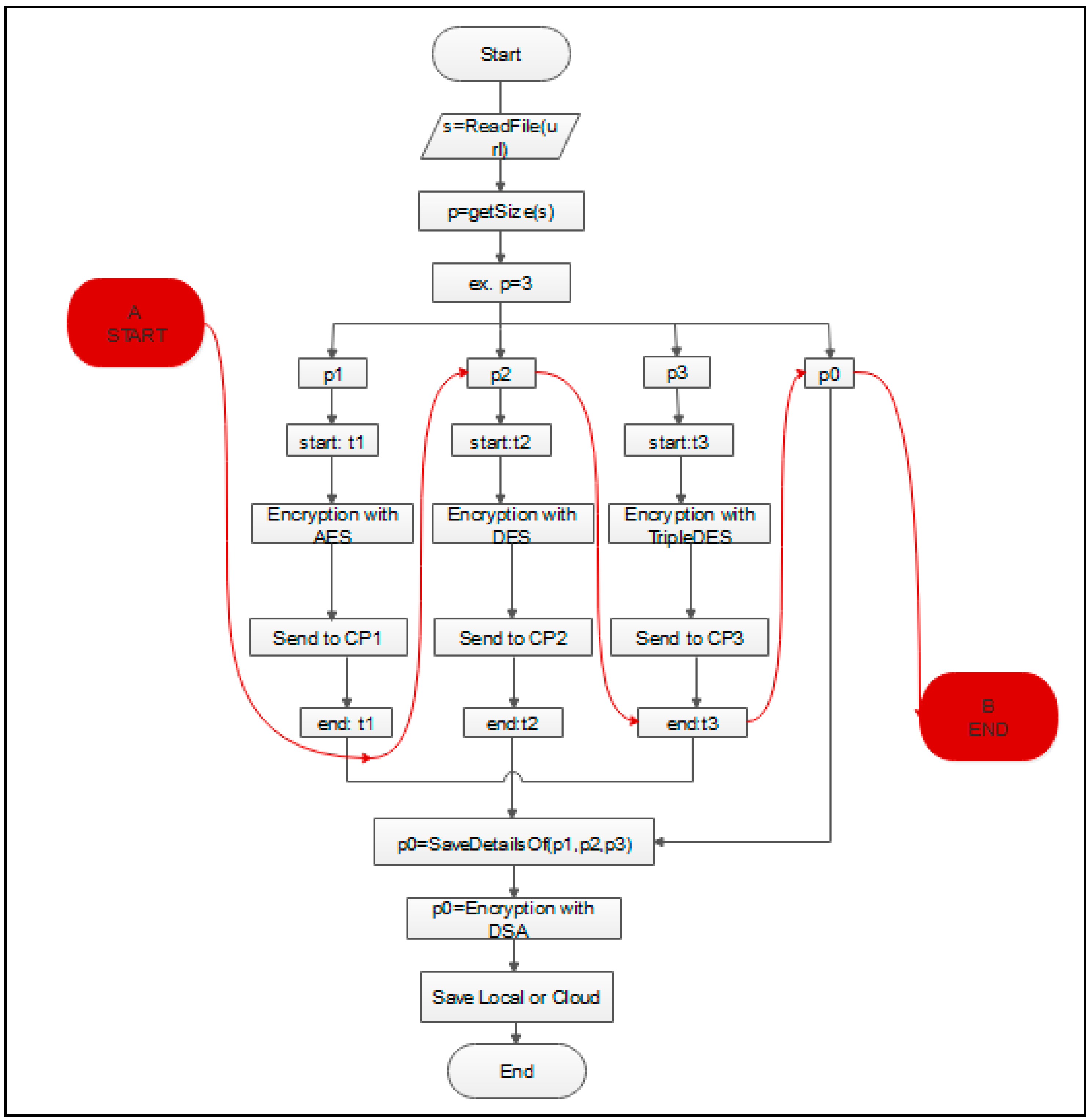
In the algorithm from
Figure 6, the algorithm we used for programming the proposed model in the cloud is presented. During this algorithm, reactive programming was used with the sole purpose of faster and more accurate communication. The algorithm shows that it starts with the question of whether the providers are active as to where the partitions will be sent/received, pn (p1, p2, p3..pn). If yes, then the next step Enc. (Alg.n)/Dec. (Alg.n) is performed at the same time for all partitions. After the completion of this step, the last step is performed, which is the population of the file with the communication rules, which, in the algorithm, we have called p0. The algorithm in
Figure 6 is realized using LINQ communication as part of ASP.NET, as shown in
Figure 7.
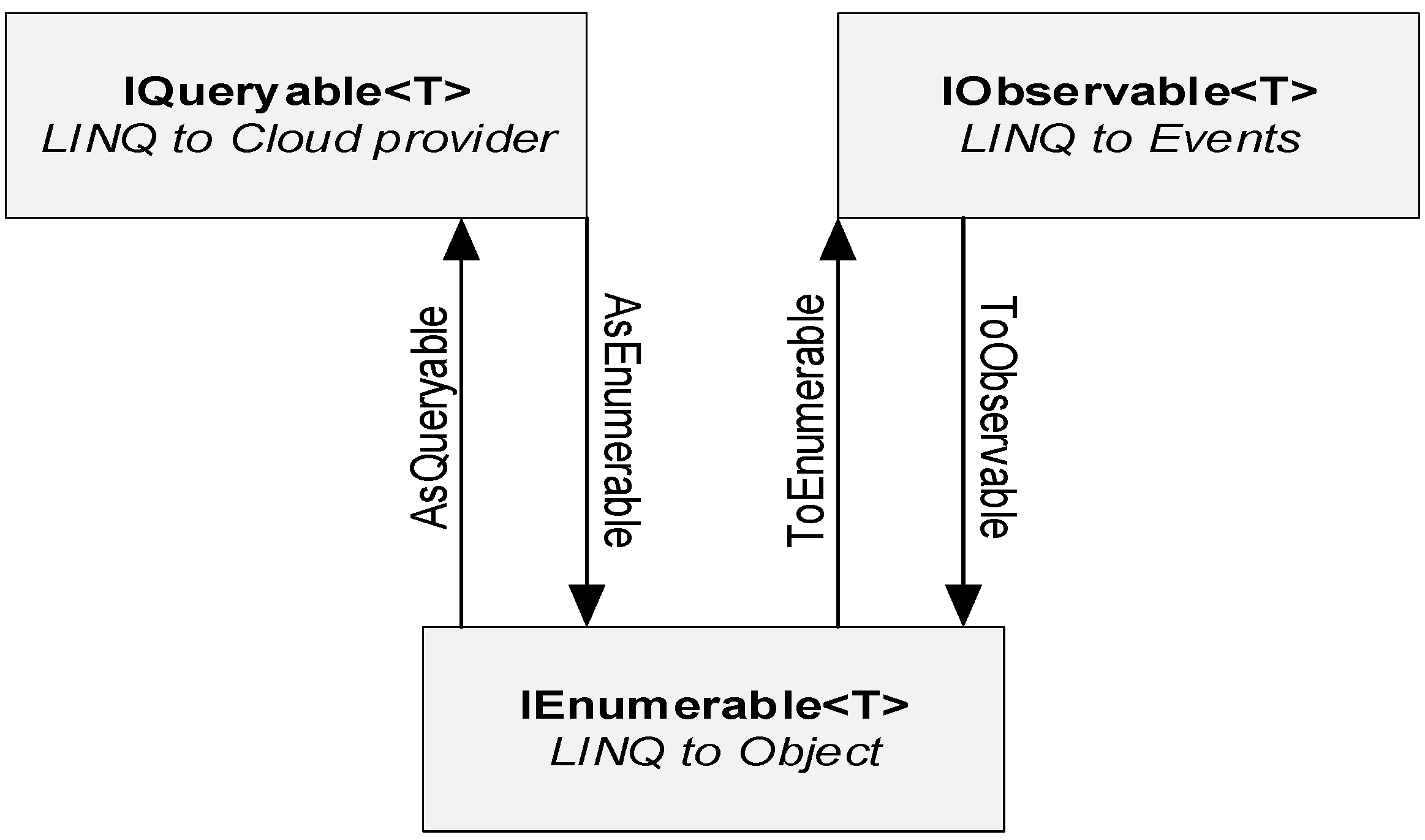
In
Figure 7, the communication that is presented using LINQ as part of ASP.Net is introduced, which is a set of technologies based on the integration of query capabilities directly into the C # language and which is used in our model,
Figure 5. In IQueryable, ready providers are called to place the partitions; for each of them, Objects are created, and through the events, the resources of reactive extensions are called.
5. Results and Analysis
To be able to compare two different methods of programming, we used the same executable environment as well as the same files as in
Table 2. In order to have accurate comparisons of the results, we relied on the same work environment for two methods of programming:
Processor: Initial (R) Celeron (R) CPU 1005 M 1.90 GHz;
Network details: ping: 55 ms, download: 15.46 Mbps, upload: 2.22 Mbps;
We used the same files for the experiments,
Table 2.
The structure of the data analysis is the same as in previous work [
1]; for all measurements, we used the measuring unit of time of execution in milliseconds. Additionally, for every case of measurements, there were two methods of measurements for Upload and Download. These measurements are realized using the same schemas for every type of algorithm (symmetric, asymmetric, and hybrid) for Old Execution Time,
Figure 4, and for New Execution Time,
Figure 5. Moreover, in this part, the execution time of measurement starts after the file is partitioned, and special measurements (i.e., t
1,t
2…t
n) are made for every partition. Additionally, the total time in general is taken for T, while in partitions, t
1,t
2…t
n. For measurements, we used three symmetric algorithms, namely AES, DES, and TripleDES, and three asymmetric algorithms, namely RSA, Diff-Hellman, and El Gamal, as well as hybrid algorithms (combination of both symmetric and asymmetric algorithms).
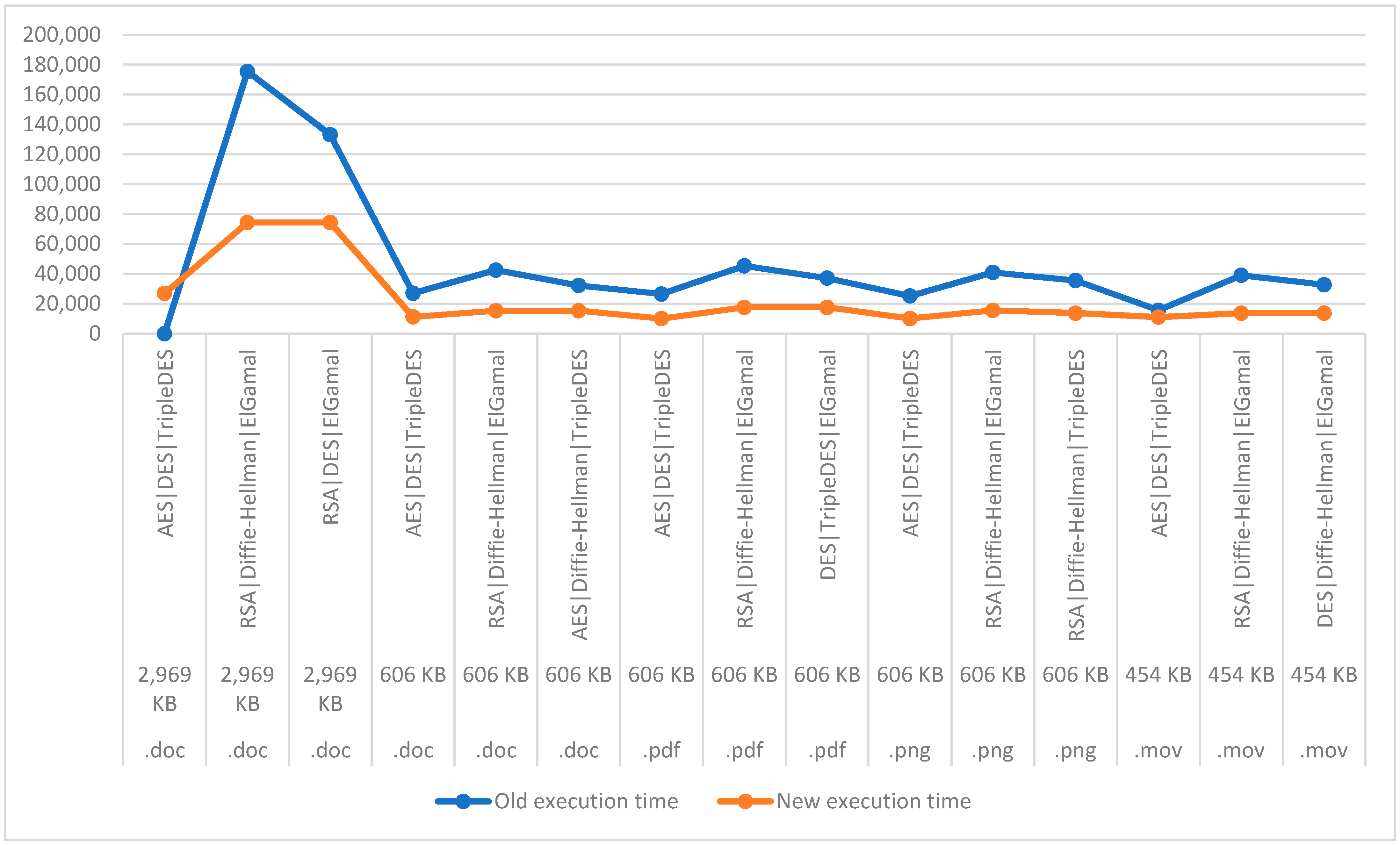
In
Table 3 and
Figure 8, the results of measurements are shown, and the time of calculation is carried out as in Equation (1), while by using reactive programming, it will be found by Equation (2). The MaximumOfTime() function calculates the longest processing time (upload + download) of the partition to a provider, and that is the time it takes to process all the partitions (upload + download) for a file (because it is processed the execution at the same time for all file partitions).
6. Conclusions
In this study, we have presented the model proposal for cloud security and the possibility of categorizing the level of security based on the combination of security algorithms, and then, all the control of the security depends on the end user, the ITSS, of a certain organization, which is a solution that was proposed in our previous work. For the implementation of this solution, we used traditional programming, but we experienced longer delays that came up when files were being partitioned and during the merging of those partitions from the cloud providers.
During this study, we proposed a solution for solving this problem by using reactive programming. As presented in
Figure 6, the use of reactive programming in this case speeds up the processes, e.g., pn(p1,p2, p3..pn), Enc.(alg.1, alg.2, alg.3,,,alg.n), Dec.(alg.1, alg.2, alg.3,,,alg.n). After using this technique of reactive programming, we realized measurements for the same data to come to a more accurate comparison between these two programming techniques for the proposed model for security in the cloud.
The measurements we made are based on the two equations presented in the study: the time calculation is completed as in Equation (1), and using reactive programming, as in Equation 2, is based on the results shown in
Table 3. It can be seen that the difference of execution time exists both during the partitions and during the merging, which is also emphasized in all data types.
From the realized measurements that are presented in
Figure 8, we can conclude that the effect of using reactive programming is presented in each file type and by each algorithm used, reducing the execution time in the proposed model for cloud security.
In conclusion, it can be said that reactive programming use is probably more difficult to apply than the traditional programming that has been used so far, but the execution time is faster, especially in our case.
In the future, it would be good for the proposed model with the changes implemented in this paper to be tested in other environments and with other data in order to have different results and then to improve where it shows delays.
However, in the future, we plan to use FPGA, as a frontage connected with business (IT Security Specialist), to increases the level of security and speed of the encryption and decryption process (as a hardware and software solution). Additionally, in the future, it will be interesting for this model to advance more with testing and provide more cloud storage security managed with data dynamics, including quantum key cryptography.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}