
Assisting Educational Analytics with AutoML Functionalities




Abstract
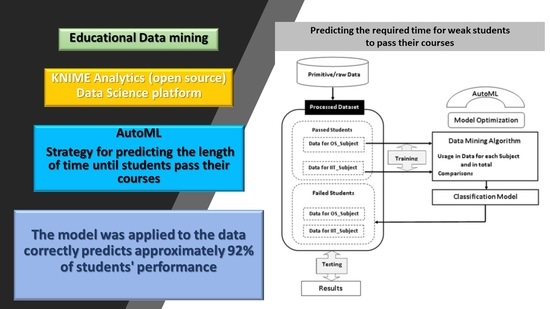
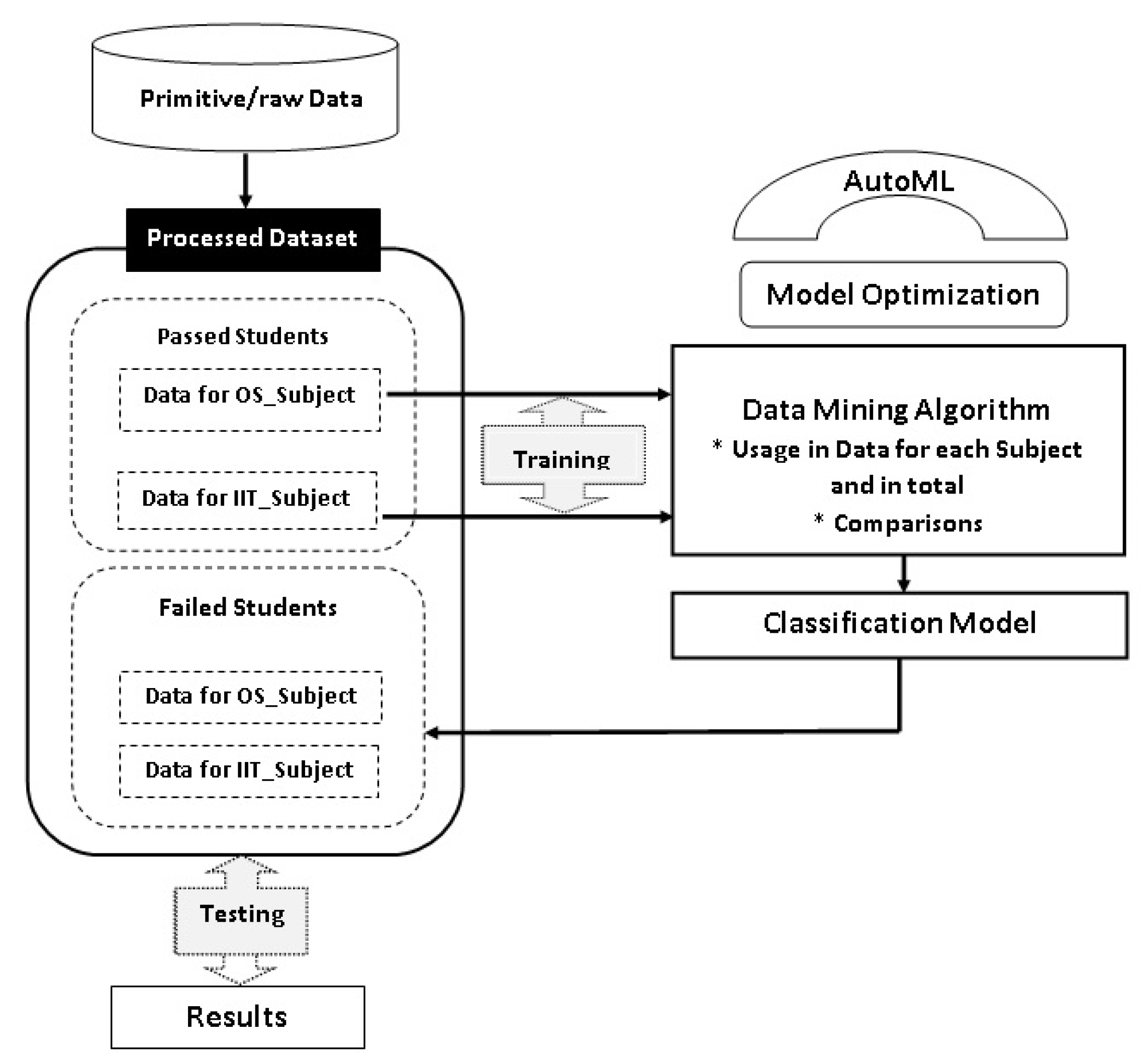
:
1. Introduction
2. Literature Review
3. Methodology: Research Model
3.1. Data Acquisition and Preprocessing
3.2. Exploratory Data Analysis
3.3. Model Design and Setup
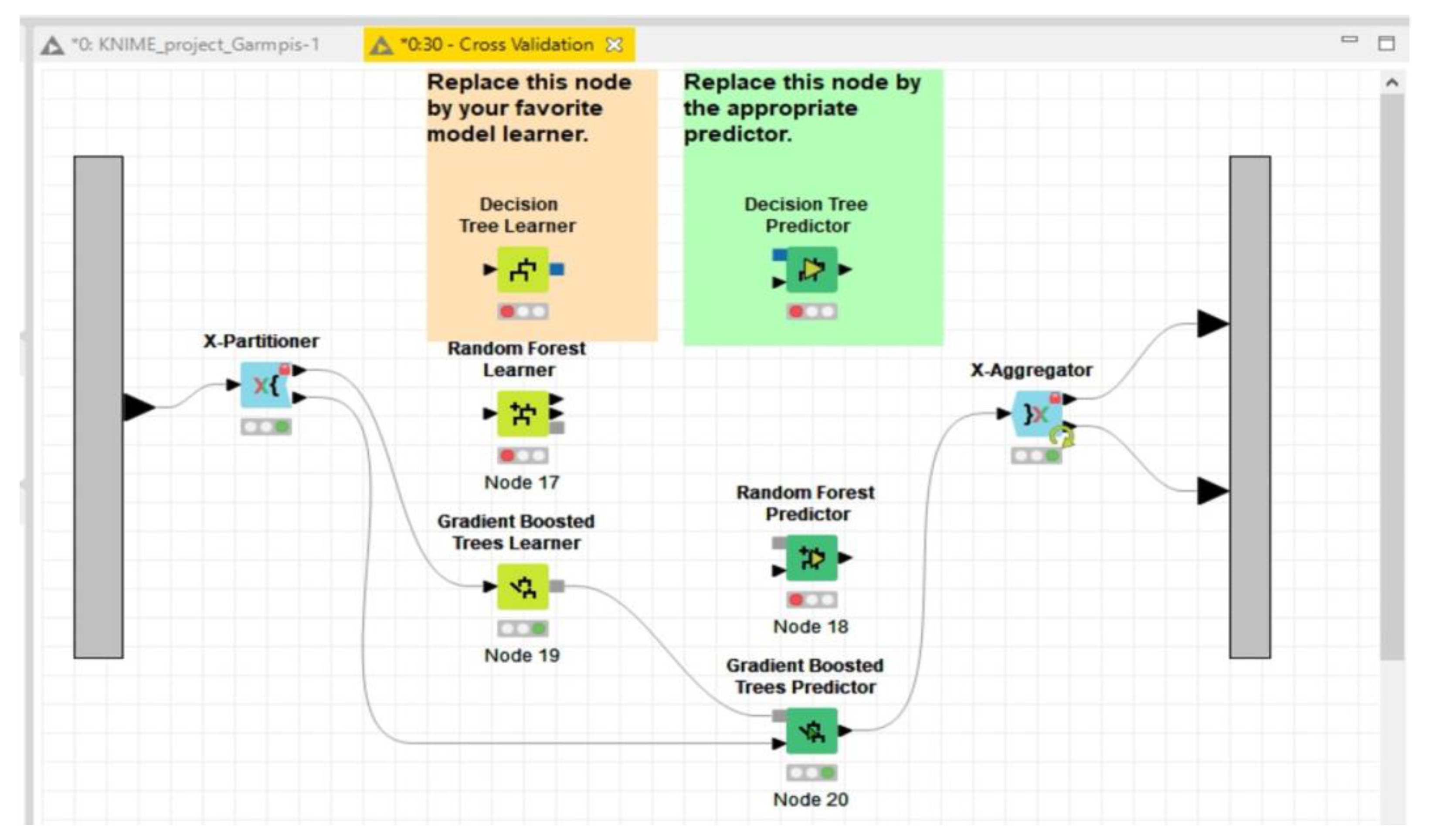
3.4. KNIME Workflow for Analyzing Educational Data
- It has been recognized as a leader by Gartner in the domains of data science and machine learning platforms and has been placed in their magic quadrant for 8 consecutive years.
- It has an integrative nature, while its open-source model ensures all capabilities required of an individual data scientist, which are available for free and with no restrictions; it is a working model that suits the academic environment.
- It has a very active community of more than 200,000 users who exchange ideas and reusable components amongst them.
3.5. Automated Machine Learning Algorithms—AutoML
- A neural network is a computational learning system that uses a network of functions to understand and translate a data input of one form into a desired output, usually in another form. The concept of the artificial neural network was inspired by human biology and the way that neurons of the human brain function together to understand inputs from human senses.
- Logistic regression is an ML algorithm that falls under the supervised learning technique and is used for predicting the categorical dependent variable using a given set of independent variables. It can provide probabilities and classify new data using continuous and discrete datasets.
- Decision tree is a supervised learning technique that can be used for both classification and regression problems. It is a tree-structured classifier, where internal nodes represent the features of a dataset, branches represent the decision rules, and each leaf node represents the outcome. The decisions or the test are performed based on features of the given dataset. It is a graphical representation for realizing all possible solutions to a problem/decision based on given conditions.
- XG Boost is an ensemble learning technique that combines the predictive power of several learners and is implemented over the Gradient Boosted Trees algorithm. The result is a single model that provides the aggregated output from several models. Bagging and Boosting are two widely used ensemble learners with the most predominant usage with decision trees.
- Random forest is an ensemble learning technique that provides predictions by combining multiple classifiers and improves the performance of the model. It contains multiple decision trees for subsets of the given dataset and finds the average to improve the predictive accuracy of the model. Random forest is a fast algorithm and can efficiently deal with missing and incorrect data.
- Gradient-Boosted Trees (GBT) is a tree-based ML algorithm that works for both regression and classification types of data mining problems. This model produces a prediction model in the form of an ensemble of weak prediction models, which are typically decision trees.
- Generalized linear models (GLMs) estimate regression models for outcomes following exponential distributions and include Gaussian, Poisson, binomial, and gamma distributions. Each serves a different purpose and, depending on the distribution and link function choice, can be used for either prediction or classification.
- The naive Bayes algorithm is a supervised learning algorithm that is based on Bayes’ theorem and is used to solve classification problems. It is a probabilistic classifier, which helps in building fast machine learning models that can make quick predictions.
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- Out of 410 active students, 270 (66%) obtained marks within the range [3.5, 5.0), with a grade point average of 4.0, and 139 (34%) were within the range (0.0, 3.0], with a grade point average of 2.0.
- 1892 passed on the 1st try (52%), 959 passed on the 2nd try (27%), 443 passed on the 3rd try (12%), 203 passed on the 4th try (5.70%), 78 passed on the 5th try (2.20%), 27 passed on the 6th try (0.76%), 6 passed on the 7th try (0.17%), 2 passed on the 8th try (0.05%), 0 passed on the 9th try (0%), and 3 passed on the 10th try (0.08%).
- 2204 (61%) students obtained marks within the range [8.0, 10.0], with a grade point average of 8.5, and 1409 (39%) students were within the range [5.0, 8.0), with a grade point average of 5.4.
- Out of 329 active students, 224 (69%) obtained marks within the range [3.5, 5.0), with a grade point average of 4.0, and 100 (31%) were within the range (0.0, 3.0], with a grade point average of 1.8.
- 1714 passed on the 1st try (64%), 550 passed on the 2nd try (20%), 208 passed on the 3rd try (8%), 120 passed on the 4th try (4.45%), 54 passed on the 5th try (2.09%), 29 passed on the 6th try (1.15%), 13 passed on the 7th try (0.55%), 3 passed on the 8th try (0.15%), 3 passed on the 9th (0.15%), and 1 passed on the 10th try (0.04%).
- 2204 (61%) students obtained marks within the range [8.0, 10.0], with a grade point average of 8.6, and 1409 (39%) students were within the range [5.0, 8.0), with a grade point average of 5.6.
- Out of 400 active students, 264 (66%) obtained marks within the range [3.5, 5.0), with a grade point average of 4.0, and 136 (34%) were within the range (0.0, 3.0], with a grade point average of 2.0.
- 422 passed on the 1st try (11.5%), 1233 passed on the 2nd try (33.5%), 830 passed on the 3rd try (22.6%), 507 passed on the 4th try (13.8%), 305 passed on the 5th try (8.35%), 160 passed on the 6th try (4.35%), 105 on the 7th try (2.9%), 56 on the 8th try (1.55%), 28 on the 9th (0.85%), 11 passed on the 10th try (0.4%), and 21 values were missing (0.3%).
- 2207 (60%) students obtained marks within the range [8.0, 10.0], with a grade point average of 8.6, and 1471 (40%) students were within the range [5.0, 8.0), with a grade point average of 5.7.
References
- International Educational Data Mining Society. Available online: http://educationaldatamining.org/ (accessed on 19 January 2021).
- Romero, C.; Ventura, S. Educational Data Mining: A Survey from 1995 to 2005. Expert Syst. Appl. 2007, 33, 135–146. [Google Scholar] [CrossRef]
- Baker, R.; Yacef, K. The State of Educational Data Mining in 2009: A Review and Future Visions. J. Educ. Data Min. 2009, 1, 3–17. [Google Scholar]
- Salisu, S.; Usman, B. Data Mining: Predicting of Student Performance Using Classification Technique. Int. J. Inf. Processing Commun. 2020, 8, 92–101. [Google Scholar]
- Li, Y.; Gou, J.; Fan, Z. Educational data mining for students’ performance based on fuzzy C-means clustering. J. Eng. 2019, 2019, 8245–8250. [Google Scholar] [CrossRef]
- Tsiakmaki, M.; Kostopoulos, G.; Kotsiantis, S.; Ragos, O. Transfer Learning from Deep Neural Networks for Predicting Student Performance. Appl. Sci. 2020, 10, 2145. [Google Scholar] [CrossRef] [Green Version]
- Karimi, H.; Derr, T.; Huang, J.; Tang, J. Online Academic Course Performance Prediction using Relational Graph Convolutional Neural Network. In Proceedings of the 13th International Conference on Educational Data Mining, Fully Virtual Conference, 10–13 July 2020. [Google Scholar]
- Tsiakmaki, M.; Kostopoulos, G.; Kotsiantis, S.; Ragos, O. Fuzzy-based active learning for predicting student academic performance using autoML: A step-wise approach. J. Comput. High. Educ. 2021, 33, 635–667. [Google Scholar] [CrossRef]
- Karlos, S.; Kostopoulos, G.; Kotsiantis, S. Predicting and Interpreting Students’ Grades in Distance Higher Education through a Semi-Regression Method. Appl. Sci. 2020, 10, 8413. [Google Scholar] [CrossRef]
- Kostopoulos, G.; Karlos, S.; Kotsiantis, S. Multiview Learning for Early Prognosis of Academic Performance: A Case Study. IEEE Trans. Learn. Technol. 2019, 12, 212–224. [Google Scholar] [CrossRef]
- Uylaş, N. Semi-Supervised Classification in Educational Data Mining: Students’ Performance Case Study. Int. J. Comput. Appl. 2018, 179, 13–17. [Google Scholar] [CrossRef]
- Umar, M.A. Student Academic Performance Prediction using Artificial Neural Networks: A Case Study. Int. J. Comput. Appl. 2019, 178, 24–29. [Google Scholar]
- Sana Siddiqui, I.F.; Arain, Q.A. Analyzing Students’ Academic Performance through Educational Data Mining. 3c Tecnol. Glosas Innov. Apl. Pyme. 2019, 29, 402–421. [Google Scholar]
- Alom, B.M.; Courtney, M. Educational Data Mining: A Case Study Perspectives from Primary to University Education in Australia. Int. J. Inf. Technol. Comput. Sci. 2018, 10, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Sorenson, P.; Macfadyen, L. Learner Interaction Monitoring System (LiMS): Capturing the Behaviors of Online Learners and Evaluating Online Training Courses. In Proceedings of the 2010 International Conference on Data Mining, DMIN 2010, Las Vegas, NV, USA, 12–15 July 2010. [Google Scholar]
- Naranjo, D.M.; Prieto, J.R.; Moltó, G.; Calatrava, A. A Visual Dashboard to Track Learning Analytics for Educational Cloud Computing. Sensors 2019, 19, 2952. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peña-Ayala, A. Educational data mining: A survey and a data mining-based analysis of recent works. Expert Syst. Appl. 2014, 41, 1432–1462. [Google Scholar] [CrossRef]
- Timbal, M.A. Analysis of Student-at-Risk of Dropping out (SARDO) Using Decision Tree: An Intelligent Predictive Model for Reduction. Int. J. Mach. Learn. Comput. 2019, 9, 3. [Google Scholar] [CrossRef] [Green Version]
- Drăgulescu, B.; Bucos, M.; Vasiu, R. Predicting Assignment Submissions in a Multi- class Classification Problem. TEM J. 2015, 4, 244–254, ISSN 2217-8309, e-ISSN 2217-8333. [Google Scholar]
- Tomasevic, N.; Gvozdenovic, N.; Vranes, S. An overview and comparison of supervised data mining techniques for student exam performance prediction. Comput. Educ. 2019, 143, 103676. [Google Scholar] [CrossRef]
- Iam-On, N.; Boongoen, T. Generating descriptive model for student dropout: A review of clustering approach. Human-Centric Comput. Inf. Sci. 2017, 7, 1. [Google Scholar] [CrossRef] [Green Version]
- Salas, D.J.; Baldiris, S.; Fabregat, R.; Graf, S. Supporting the Acquisition of Scientific Skills by the Use of Learning Analytics. In International Conference on Web-Based Learning; Springer: Berlin/Heidelberg, Germany, 2016; pp. 281–293. [Google Scholar]
- Hussain, S.; Atallah, R.; Kamsin, A.; Hazarika, J. Classification, Clustering and Association Rule Mining in Educational Datasets Using Data Mining Tools: A Case Study. In Computer Science On-line Conference; Springer: Cham, Germany, 2018; pp. 196–211. [Google Scholar] [CrossRef]
- Suganya, D.; Kumar, K.; Ramesh, P.S.; Suganthan, C. Student performance dashboard using mining approach. Int. J. Pure Appl. Math. 2018, 119, 409–421. [Google Scholar]
- Rojanavasu, P. Educational Data Analytics using Association Rule Mining and Classification. In Proceedings of the 2019 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering, Nan, Thailand, 30 January–2 February 2019; pp. 142–145. [Google Scholar] [CrossRef]
- Malekian, D.; Bailey, J.; Kennedy, G. Prediction of Students’ Assessment Readiness in Online Learning Environments: The Sequence Matters. In Proceedings of the Tenth International Conference on Learning Analytics & Knowledge, Frankfurt, Germany, 23–27 March 2020. [Google Scholar]
- Wong, J.; Khalil, M.; Baars, M.; de Koning, B.B.; Paas, F. Exploring sequences of learner activities in relation to self-regulated learning in a massive open online course. Comput. Educ. 2019, 140, 103595. [Google Scholar] [CrossRef]
- Nakamura, S.; Nozaki, K.; Nakayama, H.; Morimoto, Y.; Miyadera, Y. Sequential Pattern Mining System for Analysis of Programming Learning History. In Proceedings of the IEEE International Conference on Data Science and Data Intensive Systems IEEE, Sydney, Australia, 11–13 December 2015; pp. 69–74. [Google Scholar]
- Erkens, M.; Bodemer, D.; Hoppe, H.U. Improving collaborative learning in the classroom: Text mining based grouping and representing. Int. J. Comput. Collab. Learn. 2016, 11, 387–415. [Google Scholar] [CrossRef]
- Ferreira-Mello, R.; André, M.; Pinheiro, A.; Costa, E.; Romero, C. Text mining in education. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1332. [Google Scholar] [CrossRef]
- Hind, H.; Idrissi, M.K.; Bennani, S. Applying Text Mining to Predict Learners’ Cognitive Engagement. In Proceedings of the Mediterranean Symposium on Smart City Application, Tangier, Morocco, 25–27 October 2017; p. 2. [Google Scholar] [CrossRef]
- Aljarrah, A.; Thomas, M.K.; Shehab, M. Investigating temporal access in a flipped classroom: Procrastination persists. Int. J. Educ. Technol. High. Educ. 2018, 15, 1. [Google Scholar] [CrossRef]
- Shah, S.A.A.; Uddin, I.; Aziz, F.; Ahmad, S.; Al-Khasawneh, M.; Sharaf, M. An Enhanced Deep Neural Network for Predicting Workplace Absenteeism. Complexity 2020, 2020, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Alkadhwi, A.H.O.; Adelaja, O.A. Data Mining Application Using Clus-tering Techniques (K-Means Algorithm) In the Analysis of Student’s Result. J. Multi-Discip. Eng. Sci. Stud. 2019, 5, 2587–2593. [Google Scholar]
- Hartatik; Kusrini, K.; Prasetio, A.B. Prediction of Student Graduation with Naive Bayes Algorithm. In Proceedings of the Fifth International Conference on Informatics and Computing (ICIC), Gorontalo, Indonesia, 3–4 November 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Kabakchieva, D. Predicting Student Performance by Using Data Mining Methods for Classification. Cybern. Inf. Technol. 2013, 13, 61–72. [Google Scholar] [CrossRef]
- Damopolii, W.W.; Priyasadie, N.; Zahra, A. Educational Data Mining in Predicting Student Final Grades. Int. J. Adv. Trends Comput. Sci. Eng. 2021, 10, 366–371. [Google Scholar]
- Dataiku Software. Version 10.0—November 2021. Available online: http://www.dataiku.com (accessed on 1 May 2022).
- Adekitan, A.I.; Salau, O. Toward an improved learning process: The relevance of ethnicity to data mining prediction of students’ performance. SN Appl. Sci. 2019, 2, 8. [Google Scholar] [CrossRef] [Green Version]
- Bostock, S.M. D3JS Data Driven Documents. 2014. Available online: http://d3js.org (accessed on 1 May 2022).
- Alcalá-Fdez, J.; Sánchez, L.; García, S.; Del Jesus, M.J.; Ventura, S.; Garrell, J.M.; Otero, J.; Romero, C.; Bacardit, J.; Rivas, V.M.; et al. KEEL: A software tool to assess evolutionary algorithms for data mining problems. Soft Comput. 2008, 13, 307–318. [Google Scholar] [CrossRef]
- Fournier-Viger, P.; Gomariz, A.; Gueniche, Τ.; Soltani, A.; Wu, C.-W.; Tseng, V.S. SPMF: Open-Source Data Mining Library. 2013. Available online: http://www.philippe-fournier-viger.com/spmf/ (accessed on 1 May 2022).
- Rai, S.; Shastry, K.A.; Pratap, S.; Kishore, S.; Mishra, P.; Sanjay, H.A. Machine Learning Approach for Student Academic Performance Prediction. In Evolution in Computational Intelligence. Advances in Intelligent Systems and Computing; Bhateja, V., Peng, S.L., Satapathy, S.C., Zhang, Y.D., Eds.; Springer: Singapore, 2020; pp. 611–618. [Google Scholar] [CrossRef]
- Hussain, S.; Hazarika, G.C. Educational Data Mining Model Using Rattle. Int. J. Adv. Comput. Sci. Appl. 2014, 5, 22–27. [Google Scholar] [CrossRef]
- Harwati, A.P.A.; Wulandari, F.A. Mapping Student’s Performance Based on Data Mining Approach (A Case Study). In Agriculture and Agricultural Science Procedia; Elsevier: Amsterdam, The Netherlands, 2015; Volume 3, pp. 173–177. [Google Scholar]
- Wongkhamdi, T.; Seresangtakul, P. A Comparison of Classical Discriminant Analysis and Artificial Neural Networks in Predicting Student Graduation Outcomes. In Proceedings of the Second International Conference on Knowledge and Smart Technologies 2010, Dortmund, Germany, 24–25 July 2010; pp. 29–34. [Google Scholar]
- KNIME Software. 2021. Available online: https://www.knime.com/knime-software/ (accessed on 1 May 2022).
- Riley, R.D.; Ahmed, I.; Debray, T.P.A.; Willis, B.H.; Noordzij, J.P.; Higgins, J.P.; Deeks, J.J. Summarising and validating test accuracy results across multiple studies for use in clinical practice. Stat. Med. 2015, 34, 2081–2103. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Guyon, I.; Saffari, A.; Dror, G.; Cawley, G. Model selection: Beyond the Bayesian/Frequentist divide. J. Mach. Learn. Res. 2010, 11, 61–87. [Google Scholar]
- Thornton, C.; Hutter, F.; Hoos, H.; Leyton-Brown, K. Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classification Algorithms. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 847–855. [Google Scholar]
- Bardenet, R.; Brendel, M.; Kégl, B.; Sebag, M. Collaborative Hyperparameter Tuning. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 199–207. [Google Scholar]
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2013, 41, 647–665. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Variable Type | Values |
|---|---|---|
| Student_id | Numeric | Any Integer * |
| Subject | Nominal | Operating_Systems (OS), Introduction_Information_Technology (IIT) |
| Curriculum_Year | Numeric | Curriculum_Year_1999, Curriculum_Year_2007, Curriculum_Year_2013 |
| Grade | Numeric | One decimal number |
| Evaluation_Score | Nominal | (0) “Do not attend”, (1.0–3.5), (3.50–5.0), (5.0–8.0), (8.0–10.0) “Excellent mark” |
| Exam_Year | Numeric | 1999 to 2020 |
| Exam_Semester | Nominal | A and A’ (January) or B and B’ (June) or C (September) ** |
| Department | Nominal | Applied_Informatics_Management_Economy, Business_Administration, Management_social_cooperative_business_organizations |
| Student_status | Nominal | Graduate, Active |
| Attempts | Numeric | Natural number—Categorical target variable |
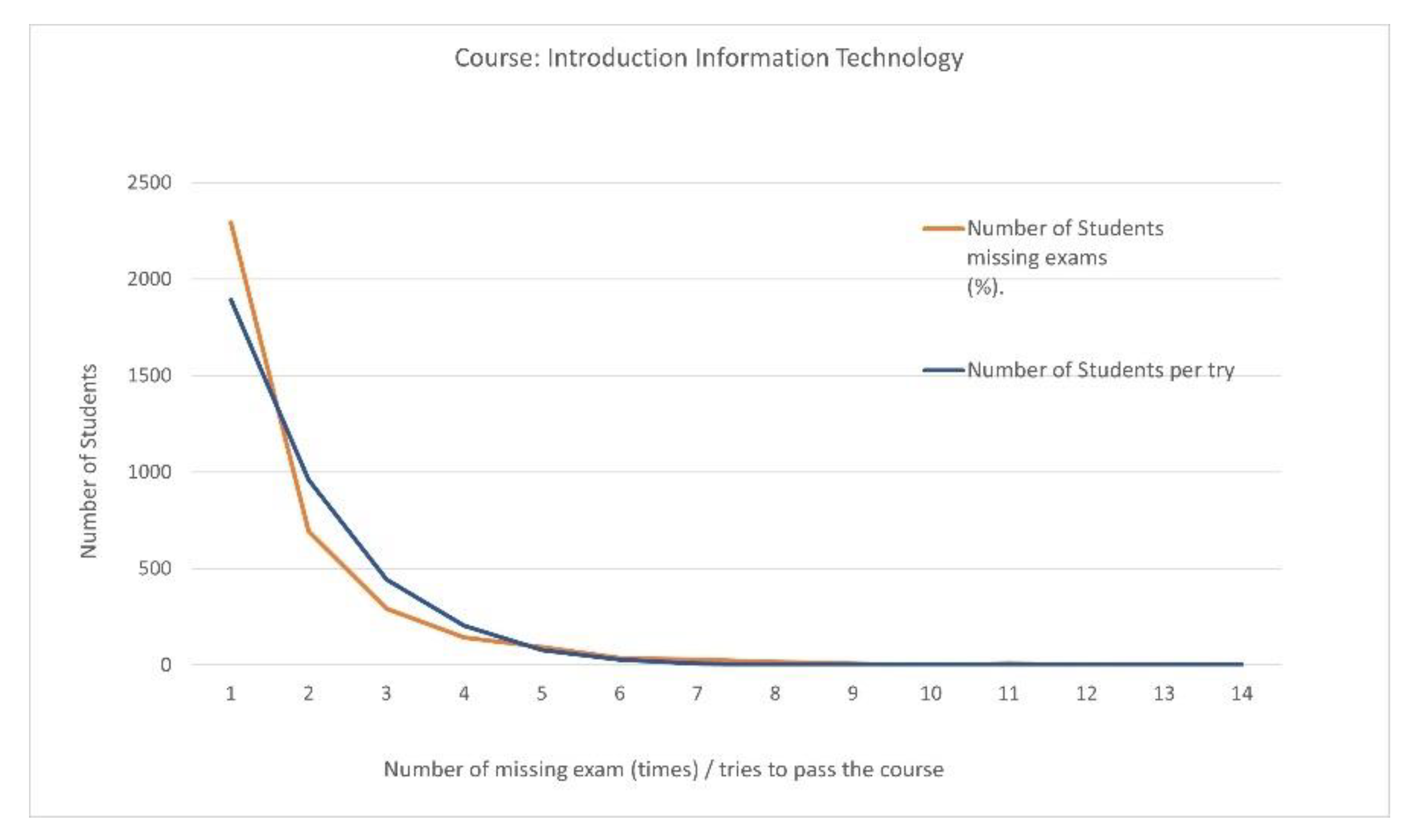
| Passing Students 3613 | Number of Missed Exams (Times) | Number of Students Missing Exams (%) | Number of Students Per Try | Number of Attempts to Pass the Course |
|---|---|---|---|---|
| 0 | 2291 (63.409%) | 1892 | 1 | |
| 1 | 693 (19.181%) | 959 | 2 | |
| 2 | 292 (8.081%) | 443 | 3 | |
| 3 | 143 (3.958%) | 203 | 4 | |
| 4 | 92 (2.546%) | 78 | 5 | |
| 5 | 36 (0.99%) | 27 | 6 | |
| 6 | 27 (0.747%) | 6 | 7 | |
| 7 | 17 (0.47%) | 2 | 8 | |
| 8 | 6 (0.166%) | 0 | 9 | |
| 9 | 1 (0.028%) | 3 | 10 | |
| 10 | 6 (0.17%) | 0 | 11 | |
| 11 | 3 (0.08%) | 0 | 12 | |
| 12 | 4 (0.111%) | 0 | 13 | |
| 15 | 2 (0.055%) | 0 | 14 |
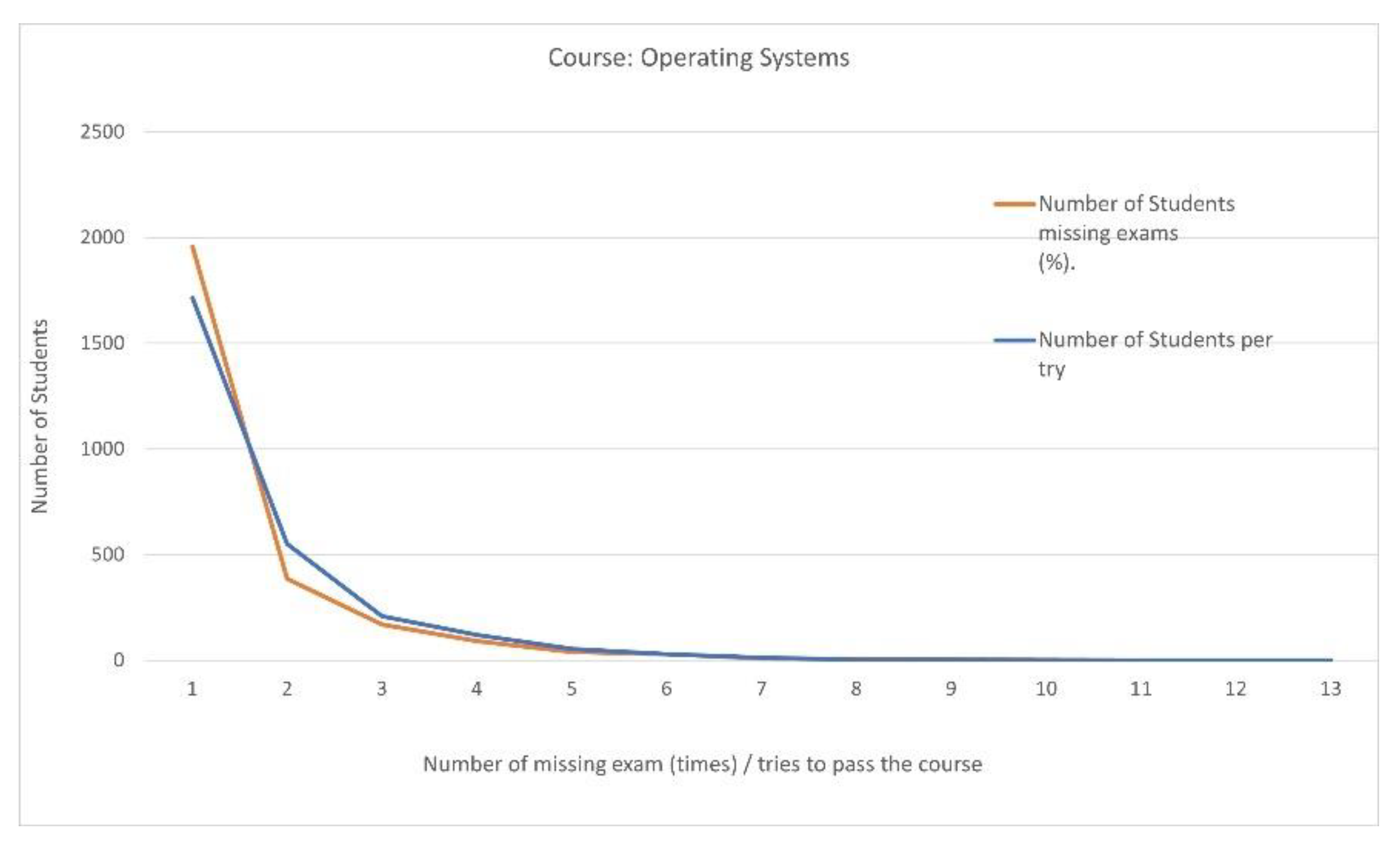
| Passing Students 2695 | Number of Missed Exams (Times) | Number of Students Missing Exams (%). | Number of Students Per Attempt | Number of Attempts to Pass the Course |
|---|---|---|---|---|
| 0 | 1956 (72.579%) | 1714 | 1 | |
| 1 | 385 (14.286%) | 550 | 2 | |
| 2 | 169 (6.271%) | 208 | 3 | |
| 3 | 91 (3.377%) | 120 | 4 | |
| 4 | 40 (1.484%) | 54 | 5 | |
| 5 | 29 (1.076%) | 29 | 6 | |
| 6 | 9 (0.334%) | 13 | 7 | |
| 7 | 6 (0.223%) | 3 | 8 | |
| 8 | 4 (0.148%) | 3 | 9 | |
| 9 | 3 (0.111%) | 1 | 10 | |
| 11 | 1 (0.037%) | 0 | 11 | |
| 12 | 1 (0.037%) | 0 | 12 | |
| 13 | 1 (0%) | 0 | 13 |
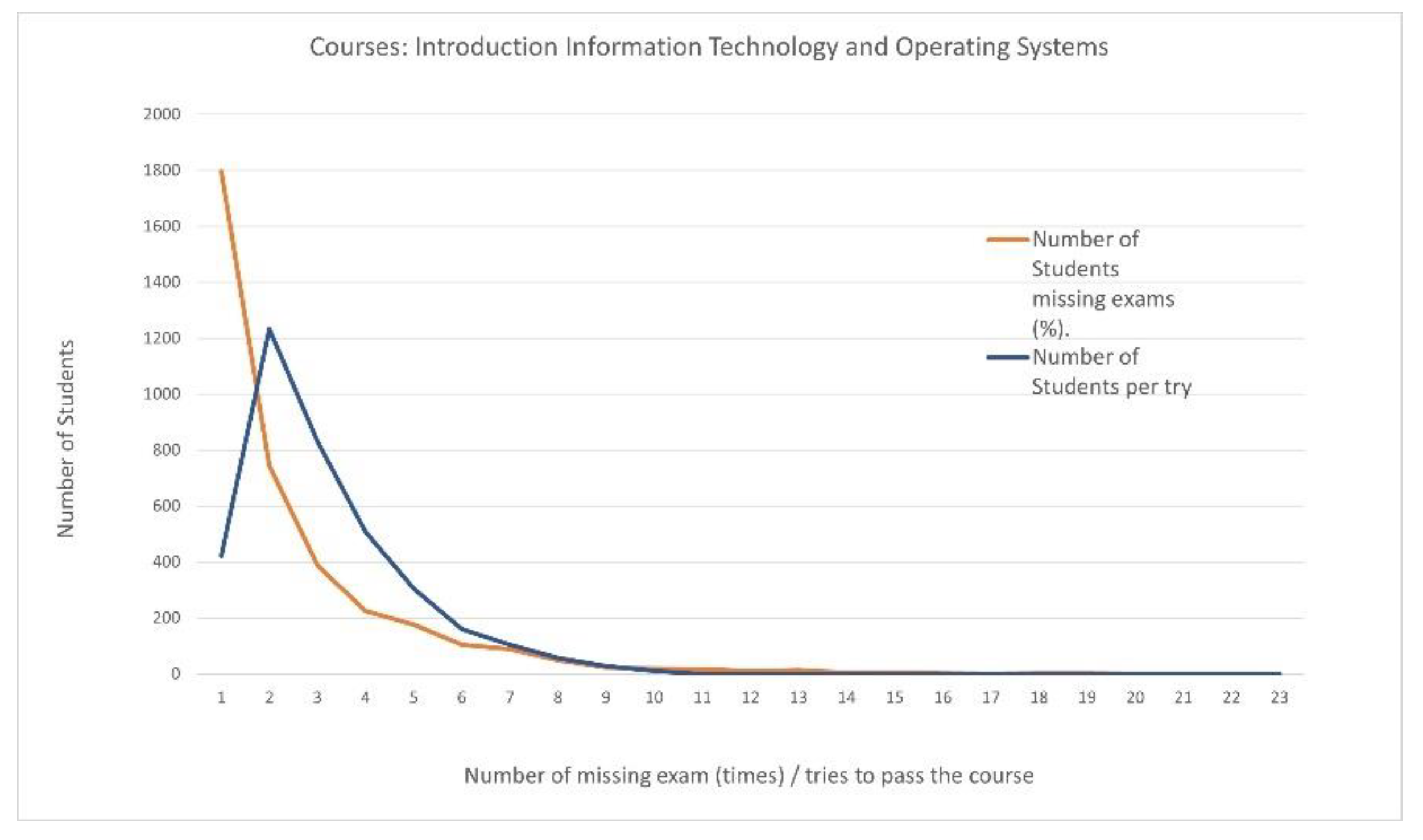
| Passing Students 3678 | Number of Missed Exams (Times) | Number of Students Missing Exams (%) | Number of Students Per Attempt | Number of Attempts to Pass the Course |
|---|---|---|---|---|
| 0 | 1797 (48.858%) | 422 | 1 | |
| 1 | 744 (20.228%) | 1233 | 2 | |
| 2 | 387 (10.522%) | 830 | 3 | |
| 3 | 225 (6.117%) | 507 | 4 | |
| 4 | 175 (4.758%) | 305 | 5 | |
| 5 | 105 (2.855%) | 160 | 6 | |
| 6 | 89 (2.420%) | 105 | 7 | |
| 7 | 49 (1.332%) | 56 | 8 | |
| 8 | 24 (0.653%) | 28 | 9 | |
| 9 | 18 (0.489%) | 11 | 10 | |
| 10 | 17 (0.462%) | 0 | 11 | |
| 11 | 10 (0.272%) | 0 | 12 | |
| 12 | 14 (0.381%) | 0 | 13 | |
| 13 | 4 (0.109%) | 0 | 14 | |
| 14 | 6 (0.163%) | 0 | 15 | |
| 15 | 3 (0.082%) | 0 | 16 | |
| 16 | 1 (0.027%) | 0 | 17 | |
| 17 | 3 (0.082%) | 0 | 18 | |
| 18 | 3 (0.082%) | 0 | 19 | |
| 20 | 1 (0.027%) | 0 | 20 | |
| 22 | 1 (0.027%) | 0 | 21 | |
| 26 | 1 (0.027%) | 0 | 22 | |
| 31 | 1 (0.027%) | 0 | 23 |
| Predicted as: | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual class | Positive | True Positive (TP) | False Negative (FN) |
| Negative | False Positive (FP) | True Negative (TN) | |
| Course: Introduction Information Technology | ||||
|---|---|---|---|---|
| Accuracy | Recall | Precision | F-Measure | |
| Neural Network | 93.3% | 83.6% | 97.7% | 90.1% |
| Logistic Regression | 92.8% | 85.5% | 94.1% | 89.6% |
| Decision Tree | 92.6% | 84.5% | 94.6% | 89.3% |
| XGBoost Trees | 92.6% | 84.3% | 94.8% | 89.3% |
| Random Forest | 92.4% | 84.1% | 94.6% | 89.0% |
| Gradient Boosted Trees | 92.3% | 83.8% | 94.6% | 88.9% |
| Generalized Linear Model (H2O) | 92.2% | 83.6% | 94.3% | 88.6% |
| Naïve Bayes | 92.0% | 85.7% | 91.7% | 88.6% |
| Course: Operating Systems | ||||
|---|---|---|---|---|
| Accuracy | Recall | Precision | F-Measure | |
| Neural Network | 91.1% | 63.0% | 89.5% | 73.9% |
| Logistic Regression | 88.9% | 59.3% | 80.0% | 68.1% |
| Decision Tree | 91.1% | 68.1% | 84.4% | 75.4% |
| XGBoost Trees | 91.1% | 69.6% | 83.2% | 75.8% |
| Random Forest | 90.1% | 52.6% | 100.0% | 68.9% |
| Gradient Boosted Trees | 91.1% | 64.4% | 87.9% | 74.4% |
| Generalized Linear Model (H2O) | 90.2% | 74.1% | 76.3% | 75.2% |
| Naïve Bayes | 81.3% | 31.1% | 56.0% | 40.0% |
| Courses: Introduction Information Technology and Operating Systems | ||||
|---|---|---|---|---|
| Accuracy | Recall | Precision | F-Measure | |
| Neural Network | 94.4% | 88.9% | 95.1% | 91.9% |
| Logistic Regression | 94.0% | 91.1% | 92.2% | 91.6% |
| Decision Tree | 94.6% | 88.9% | 95.8% | 92.2% |
| XGBoost Trees | 94.8% | 89.2% | 96.1% | 92.5% |
| Random Forest | 94.6% | 88.9% | 95.8% | 92.2% |
| Gradient Boosted Trees | 94.8% | 89.2% | 96.1% | 92.5% |
| Generalized Linear Model (H2O) | 94.4% | 88.9% | 95.3% | 92.0% |
| Naïve Bayes | 90.3% | 94.2% | 81.6% | 87.5% |
| Algorithm | Optimal Parameters |
|---|---|
| Decision Tree | Quality measure: Gini index Maximal Depth: 8 Pruning: Yes, MDL |
| XGBoost Trees | Updater: Shotgun Feature Selection: Cyclic Lambda: 0.01 Alpha: 0.004 Top k: 5 |
| Random Forest | Number of Trees: 100 Maximal Depth: 4 |
| Gradient Boosted Trees | Number of Trees: 90 Maximal Depth: 7 Learning Rate: 0.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garmpis, S.; Maragoudakis, M.; Garmpis, A. Assisting Educational Analytics with AutoML Functionalities. Computers 2022, 11, 97. https://doi.org/10.3390/computers11060097
Garmpis S, Maragoudakis M, Garmpis A. Assisting Educational Analytics with AutoML Functionalities. Computers. 2022; 11(6):97. https://doi.org/10.3390/computers11060097
Chicago/Turabian StyleGarmpis, Spyridon, Manolis Maragoudakis, and Aristogiannis Garmpis. 2022. "Assisting Educational Analytics with AutoML Functionalities" Computers 11, no. 6: 97. https://doi.org/10.3390/computers11060097
APA StyleGarmpis, S., Maragoudakis, M., & Garmpis, A. (2022). Assisting Educational Analytics with AutoML Functionalities. Computers, 11(6), 97. https://doi.org/10.3390/computers11060097