This paper aims to create a self-diagnosis test system that will be an integrated application in CONTROLAR’s cyber-physical machines that allow its self-diagnosis in real-time. The proposed architecture for the self-diagnosis test system enables the management, configuration and execution of system tests, presenting a modular and extensible model that allows exploring different levels of tests to be performed on the devices under test.
5.1. Database
For the database, MongoDB was used, which is a document database. That is, it stores the data in the form of JSON documents. According to the system’s data, five collections of data have been identified to be held in the database: configurations, tests, reports, schedules and packages.
The configuration collection contains attributes that may differ from machine to machine and are necessary to ensure the correct operation of the system. Finally, the tests collection stores all the metadata provided by those who create and make available the primitive tests. These are imported into the system database and updated.
The reports collection stores all the reports of the execution of primitive tests or test packages in the system. The schedules collection stores all the performances of primitive tests or sets of tests scheduled for a specific time by the user. The same is not valid for the packages collection, which stores all the metadata for the new test suites created in the system from the primitive tests.
After specifying the data to be saved in each collection of the system’s database, the next section will explain how the system interacts with the database through queries to obtain the data for its operation.
5.2. Backend
The backend is the system tier responsible for managing the database and making the data available to the Ffrontend. Therefore, framed in the Model-View-Controller (MVC) architecture, it is the controller of the system and establishes the connection between the database and the user interfaces, thus guaranteeing the integrity of the data, not allowing other components to access or change them.
The technology used to develop this server was Node.js combined with Framework Express. This server is organized so that there is a division of the code according to its function. Instead of all the code being in one file, it was divided into different files and directories according to its purpose on the server. This will allow the reuse and modularity of the developed code, facilitating its maintenance and understanding in the future.
Thus, the server structure is comprised of the models responsible for the collections stored in the database, the controllers responsible for the execution of all system operations, the grammar, which corresponds to the DSL developed for the system, the routes that forward the requests, from the client and lastly the app.js, activated through the express module.
Each of these elements above plays a crucial role in the server logic and will be detailed below for a better understanding.
5.2.1. Models
Models represent the collections stored in the database. Each model must then represent its collection and validate the data types of its attributes before transactions are performed with the database. In these models, the “mongoose” module is imported, a data modelling object that allows connecting to the database in an asynchronous environment and sending and receiving data in JSON format, which will facilitate the use of the data in the system, as illustrated in Listing 1.
| Listing 1. Report Model. |
const mongoose = require(‘‘mongoose’’);
const testsSchema = new mongoose.Schema(
{
id_test: { type: mongoose.Schema.Types.ObjectID, required: true},
module: { type: String, required: true },
name: { type: String, required: true },
result: { type: String, required: true },
message: { type: String, required: false },
runtime: { type: Number, required: true },
resultValue: { type: String, required: false },
}
{ versionKey: false }
);
const reportSchema = new mongoose.Schema(
{
id_user: { type: String, required: true },
date: { type: String, required: true },
results: [testsSchema],
},
{ versionKey: false }
);
module.exports = mongoose.model("report", reportSchema);
|
In line 1 of listing one, we see the import of the “mongoose” module. Next, between lines 3 and 14, we see the model in the form of an object representing the structure of a test result with its attributes and data types. This object serves as an auxiliary structure, in this case, to be introduced in the report model. Next, between lines 16 and 23, we see the report model in the form of an object with its attributes and data types. Then, in line 20, where the attribute “results” is specified, we see a list of things, which are objects with the structure defined above, for the effects of each test. Finally, in line 25, we see the export of the created model, making it available for use by other files. In this case, it will be used by the controller, who will be responsible for the report collection operations.
5.2.2. Grammar
The DSL developed in this paper aims to create new test suites from the primitive tests available in the system, with rules and logic applied, to be executed in the shortest possible time. The language was created from the terminal symbols to identify by the lexer. The parser was created for the rules of logic and sentence construction of the grammar specified. The terminal symbols have been placed in
Table 1. The structure of the lexer is shown below in Listing 2:
| Listing 2. Grammar Lexer. |
lexer grammar TestLexer;
NEXT : ’->’ ;
AND : ’&’ ;
OR : ’|’ ;
IF : ’?’ ;
ELSE : ’:’ ;
RPAREN : ’)’ ;
LPAREN : ’(’ ;
END : ’;’ ;
KEYWORD : ([A-Za-z]+([/ _-][A-Za-z]+)*) ;
WS
: [ \r\n\t] -> skip ;
|
The structure of the Lexer is quite simple, starting with its identification and then specifying all terminal symbols that must be recognized. These symbols are defined through regular expressions, always ensuring that this definition does not include unexpected elements and, therefore, is not ambiguous.
The symbols we see in this grammar are very intuitive and easy for the end-user to understand, which is one of the objectives. The only symbol that gives any further explanation is the keyword symbol. This symbol must recognize all the names of the primitive tests introduced in the script. Furthermore, its regular expression includes isolated words, thus giving the user some freedom to be more expressive in the choice of keywords. After defining all these factors, it is time to specify the sentence construction rules with these symbols. This is done with the Parser, shown below in Listing 3:
| Listing 3. Grammar Parser. |
parser grammar TestParser;
options {
tokenVocab=TestLexer;
}
test
: statement END ;
statement
: condition #Conditional
| seq #Sequence ;
condition
: expr IF statement ELSE statement #IfElse
| expr IF statement #If ;
seq
: KEYWORD (NEXT statement)* ;
expr
: LPAREN KEYWORD (AND KEYWORD)* RPAREN #And
| LPAREN KEYWORD (OR KEYWORD)* RPAREN #Or ;
|
The parser starts with identification, following the reference for the lexer that provides the symbols to know which are the terminal symbols. After these two steps, the sentences of the grammar are specified. In the element statement, we can see the condition representing a conditional expression and a seq representing a tests sequence. The most important part of the parser to retain is the elements that come at the end of the lines for each possibility determined at the beginning of words by a #. This allows the visitor to know the possible paths in the parsing tree that this parser will generate.
In order for the system can use this grammar, it is necessary to find a way to use it in the system. Since ANTLR offers the transformation of grammar for several programming languages, we will proceed to transform the grammar into JavaScript and include the code directly in the system. For this, it is necessary to execute the following command:
In this command, we specify the lexer and parser to be transformed. After, we define the generation of a visitor. After executing this command, several files will be generated, including the visitor. This is where the code to be developed for the new test suites will be specified, as we can see below, in Listing 4.
| Listing 4. Grammar Visitor. |
TestParserVisitor.prototype.visitAnd = function (ctx) {
this.auxOp = 0;
for (let i = 0; i < ctx.KEYWORD().length; i++) {
this.auxList.push(ctx.KEYWORD(i));
}
return "";
};
|
The visitor is to go through the code script through the elements specified in the parser, and each aspect generates the corresponding code. The generated code within the visitor is nothing more than a string incremented and filled up to the end of the parsing tree. All keywords are also saved in a list so that the list and the line containing the generated script are returned at the end. The list of keywords is necessary because it will be necessary to match after generating this code.
5.2.3. Controllers
Controllers are responsible for executing system operations. The way they are structured is similar to models. There is a file for each model accountable for managing the processes related to that collection or model. In each controller, several operations are available according to the needs of each one, but what is common to all is the create, read, update, and delete (CRUD) operations. Besides these operations, there are still more that are particular to only some models, such as the execution of primitive tests, which is an operation developed only in the test controller, the creation of new test suites that make use of the developed DSL and the execution of those identical test suites that are operations defined only in the package controller.
The operations shown below are those mentioned different from the usual CRUD. However, given the context of the system, they are fundamental to its performance:
A method to execute a primitive test, passing as arguments the directory where the electronic test drivers are kept, the id of the test to be performed, and the test’s parameters.
A query is made to obtain all the information related to the test, and the execution time count is started. Then, the driver responsible for executing the test is run, which executes it and returns the results. The execution time counts stops as soon as the results arrive, and the test execution time is saved. Finally, some information about the test is added to the results to be held in the reports, and the object containing the results of the test execution is returned (Listing 5):
| Listing 5. Execute one primitive test. |
module.exports.runTest = async (driversDirectory, idTest, defaultParam) => {
let test = await Test.findOne({ _id: idTest }).exec();
let startTime = process.hrtime()
exec(‘${driversDirectory}\\${test.module} "${idTest}" "${defaultParam}"‘,
(err, stdout, stderr) => {
if (err) return stderr
else {
let endTime = process.hrtime(startTime)
let result = JSON.parse(stdout)
result.runtime = (endTime[1] / 1000000).toFixed(3);
result.id_test = idTest;
result.module = test.module;
result.name = test.name;
return result;
}
})
};
|
This method starts by using the grammar defined, using the lexer and the parser, to analyze the code script written by the user. Then a parsing tree is created, generated and passed from the visitor of the grammar as an argument. If no error is found in the parsing tree, the visitor will go through that tree and generate the code for the new test suite. After generating the code for the new script, it will be written to a file that will be saved in the directory where the system’s test suites are. Then, the new test suite is also inserted into the database (Listing 6):
| Listing 6. Create new test suite. |
module.exports.insertPackage = async (package) => {
let chars = new antlr4.InputStream(package.script);
let lexer = new Lexer(chars);
let tokens = new antlr4.CommonTokenStream(lexer);
let parser = new Parser(tokens);
parser.buildParseTrees = true;
let tree = parser.test();
if (tree.parser._syntaxErrors === 0) {
let listOfTests = await Test.getTests();
let visitor = new Visitor(listOfTests);
visitor.visitTest(tree);
let textFile = visitor.getRes() + "";
let t = visitor.getTests();
let tests = t.filter(function (elem, pos) {
return t.indexOf(elem) == pos;
});
let fileName = package.name.toLowerCase().replace(/\s/g, ’_’) + ".js";
let filePath = scripts_path + fileName;
fs.writeFile(filePath, textFile, "utf8", function (err) {
if (err) throw err;
let t = new Package({
name: package.name,
description: package.description,
code: package.script,
path: fileName,
tests: tests, });
return t.save(); });
} else {
return { errors: tree.parser._syntaxErrors };
}
};
|
This method starts by querying the package collection for information about the package to be executed. After receiving this information, it only needs to import the test suite code file and call the “run” method that triggers the test suite’s execution. In the end, it waits for the results and returns them (Listing 7).
| Listing 7. Execute a test suite. |
module.exports.runPackage = async (idPackage) => {
let package = await Package.findOne({ _id: idPackage }).exec();
if(package){
const file = require("./../public/Packages/" + package.path);
return await file.execute();
}
return {};
};
|
The operations demonstrated and explained are examples of the different types of procedures that the system performs and supports. However, we can see that all of them have in common that each performs only a specific action that allows us to isolate these actions and reuse them frequently in different parts of the code for other purposes. This will also enable better maintenance of these operations, since whenever it is necessary to make any changes in any of them, it will be done only once and in the indicated location, instead of having to change in different areas, which would easily cause inconsistencies in the code in the long-term.
5.2.4. Routes
The server’s routes, as mentioned previously, are responsible for defining the requests that the client can request, and in this case, they are the ones that receive these requests, forward them to carry out the operations that are necessary to satisfy them, and in the end, send the data to the client. The way the routes are built is based on the URL. For each request, a URL is associated. As the defined API follows the REST architecture, these routes will follow particular and precise formats to notice the type of operation that needs to be executed.
As we saw earlier on controllers, CRUD operations are the most common and on routes. There is also a way to mark requests to determine the category of functions they deal with. In this case, they are HTTP requests. In this system, four types of recommendations have been implemented, namely the get method, responsible for retrieving information from the server using a given uniform resource identifier (URI), a post request used to send data to the server, the put request, which replaces all current representations of the target resource with the uploaded content, and the delete request, responsible for removing all contemporary models of the target resource provided by the URI.
We see all the developed API services available to the client in the previous tables. The implementation of all of them will not be detailed here, but only of some, as a demonstrative example of the implementation format, which is always the same except for some more complex requests. For example, in Listing 8, shown below, we can see the implementation of the route for the get/test request:
| Listing 8. Example of GET request implementation. |
router.get("/tests", function (req, res) {
Tests.getTests()
.then((data) => res.jsonp(data))
.catch((error) => res.status(500).jsonp(error));
});
|
In this example, we see in line 2 the use of “Tests”, which is the reference already imported into the test controller. Then, with this reference, the “getTests” method is called, which is exported in the tests controller. Thus, what is happening is precisely what was described previously. This router forwards the operation to the controller responsible for it. Then, it just waits for the results to arrive to return them to the client.
In Listing 9, shown below, we can see the implementation of the route for the post/packages request:
| Listing 9. Example of POST request implementation. |
router.post("/packages", function (req, res) {
Packages.insertPackage(req.body)
.then((data) => res.jsonp(data))
.catch((error) => res.status(500).jsonp(error));
});
|
In this example, the process is very similar to the previous one. The only difference is that the information saved in the system comes in the request’s body (“req.body”). Therefore, it is necessary to send this information to the method that deals with the operation.
In Listing 10, shown below, we can see the implementation of the route for the put/schedules/:idSchedule request:
| Listing 10. Example of PUT request implementation. |
router.put("/schedules/:idSchedule", function (req, res) {
Schedules.updateSchedule(req.params.idSchedule, req.body)
.then((data) => res.jsonp(data))
.catch((error) => res.status(500).jsonp(error));
});
|
We see the same similarities again in this example, but with a slight difference. Put requests usually bring the identifier of the element that we want to update in the sub-route and, therefore, to have access to it, we must access the request parameters (“req.params”).
In Listing 11, shown below, we can see the implementation of the route for the delete/packages/:idPackage request:
| Listing 11. Example of DELETE request implementation. |
router.delete("/packages/:idPackage", function (req, res, next) {
Packages.deletePackage(req.params.idPackage)
.then((data) => res.jsonp(data))
.catch((error) => res.status(500).jsonp(error));
});
|
In this example, we see the same structure again, but to delete an element from the system, we only need to access the request parameters to obtain the identifier and pass it to the controller.
5.3. Frontend
The frontend is the system level responsible for creating and managing the graphical interfaces. For this system, there are two types of users. The first type of user, more fundamental, will only have access to the execution of primitive tests and test suites. The second type of user, already responsible for managing the system and the test suites, has access to all the other functionalities.
5.3.1. Components
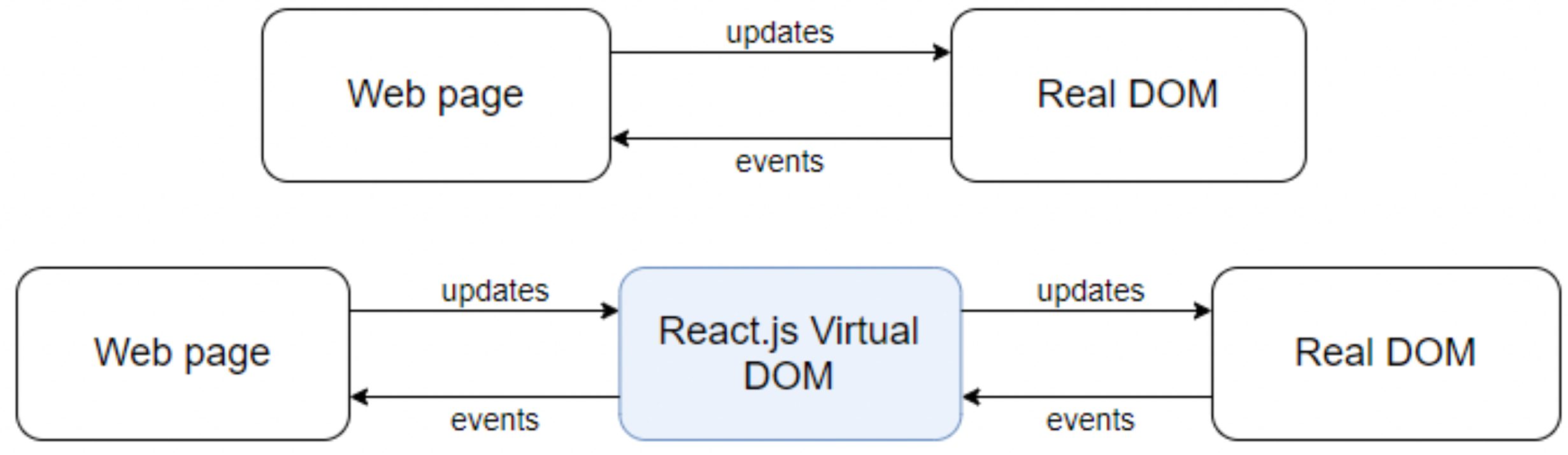
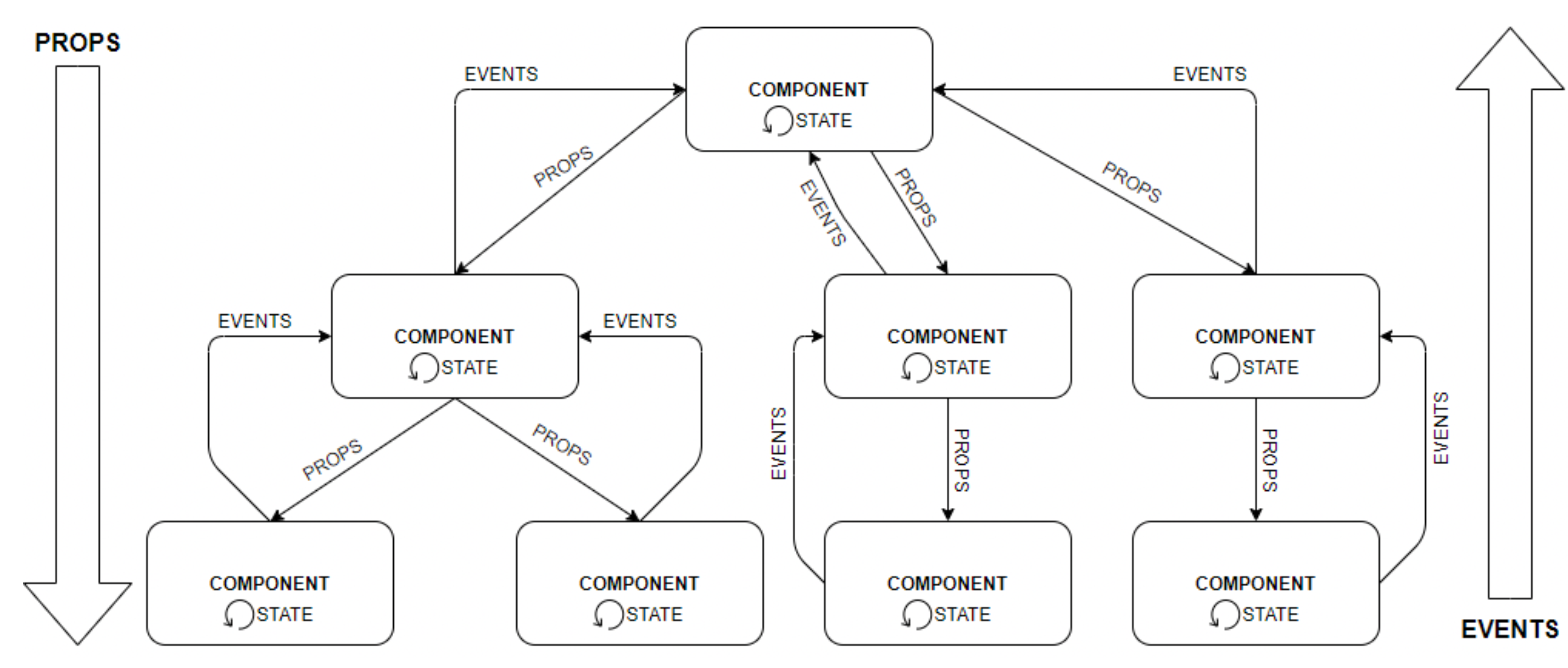
As mentioned, developing components in React becomes an asset. Still, to master the technology, one must understand the fundamentals and how the pieces interact. The three concepts highlighted here are the state of a component is mutable and can be changed by the element itself. These props are the state information of a component and lastly, the events, which are how the child component should inform the parent component of the changes.
Thus, to understand how these concepts apply in practice and make the most of the use of React components, we can see below, in
Figure 8, an illustration of how these concepts are related:
5.3.2. Obtaining API Data
Another critical aspect for this part of the system to work as planned is getting the data managed by the backend tier. The graphical interfaces built should be optimized and fast in obtaining data, facilitating the user in this way, because the user does not have to wait long to load the pages, and the data must be obtained in the best way. Here, the decision made was that the parent components of each page make the data requests to the API at the time of its creation. With this, the system pages are that the data are requested and loaded whenever the user changes the page or enters a new page.
The way to obtain the data is through HTTP. To make the code clearer, a file was created only for requesting data from the API. This file contains the base URL of the data API, and all forms add only the route and sub-route. This can be seen below in Listing 12:
| Listing 12. Example of request to obtain API data. |
exportt const getTests = async() => {
try {
const reponse = await axios.get(’${url}/tests’);
return response.data;
} catch (error) {
const statusCode = error.response ? error.response.status : 500;
throw new Error(statusCode.toString());
}
};
|
This example shows how HTTP requests are made to the API using the imported module “Axios”. Another essential feature that we see in this example is the use of the keyword “await”, which in this particular case makes the method wait for the results of the API.
5.3.3. User Interfaces
The division of access to the pages by each user was carried out through the login on the first page, which will allow assigning a JSON Web Token (JWT) to the user and will only give him access to the appropriate functionalities. After that, the user must enter his ID (provided by CONTROLAR) and enter the proper mode. For example, if it is an operator, it must enter the execution mode, and if it is the system manager, it must enter the configuration mode.
It is only possible to execute primitive tests or test packages on the page available to the operator. The operator has a list of all the primitive tests of the system. To run these tests, they must select the ones they want and execute them all at once. After selecting the tests and passing them to the execution pipe, they need to press a button to run. The system will execute the tests, and, in the end, a table will be presented with the results obtained. The execution interface and the results table shown to the user can be viewed below, in
Figure 9 and
Figure 10, respectively:
The method described above for selecting and executing primitive tests by the user is the same for the test suites.
The results table shows the execution drivers and some metadata added by the system. The critical metric for the test results is whether the test passed, failed or was inconclusive. The goal of these interfaces is to be as functional and straightforward as possible for decision making.
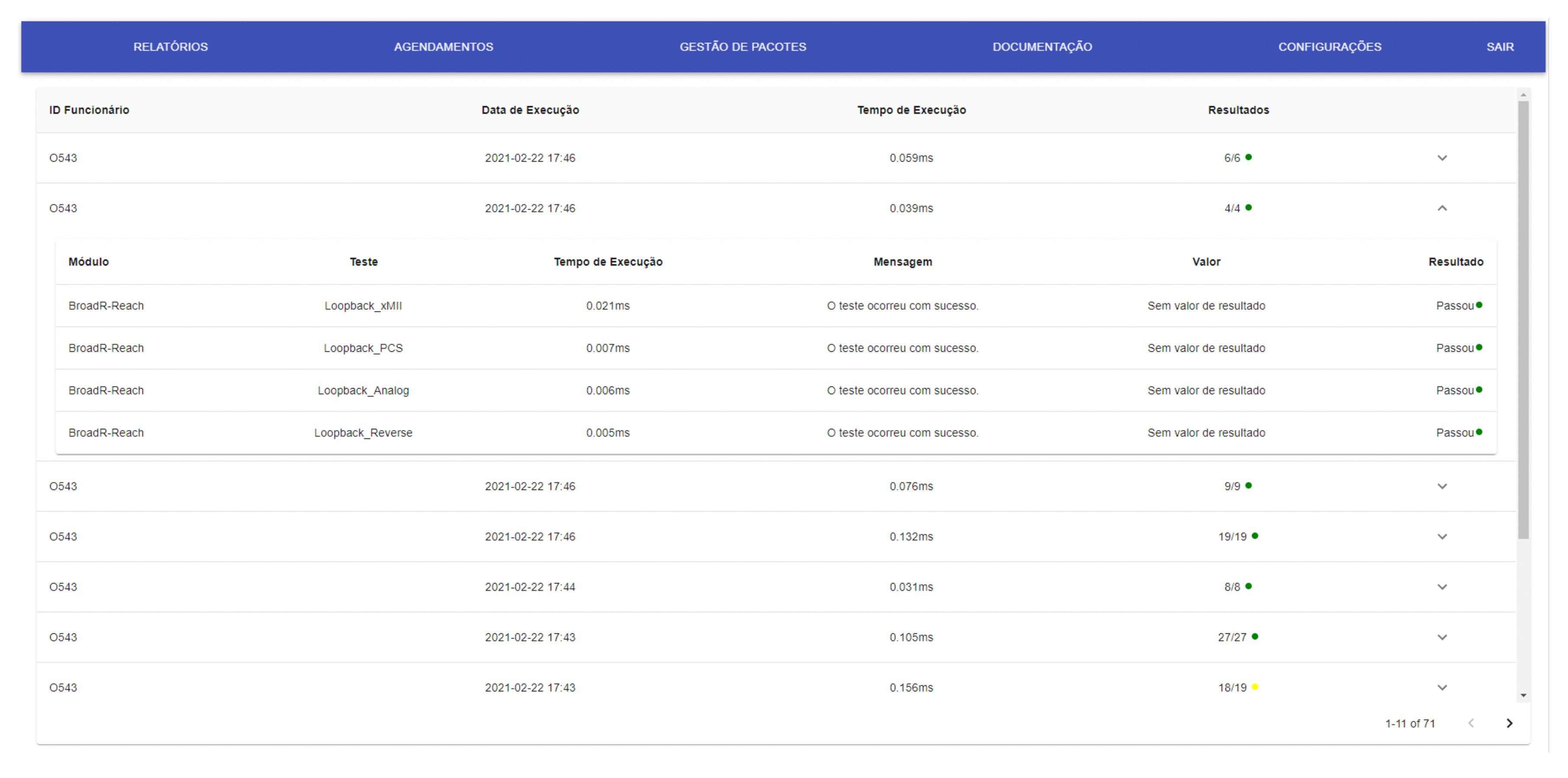
More pages and resources will be accessible to the system manager or administrator. For example,
Figure 11 presents the execution report page with the table with all the execution reports made in the system.
Each row in the table allows for expansion that opens an internal table, detailing the results of all tests performed in this report.
The user also has the page for managing and configuring new test suites for the system, which can be seen in
Figure 12. On this page, the user has at his disposal the list of existing packages in the system, where he can remove or edit them. There is also a form for creating a new test suite, where the user only needs to specify the name, description and code of the new test suite. The code is written with the DSL.
The manager also has a page available where he has access and must update the system settings whenever necessary. These settings are required for the system to work since they are used in fundamental processes. The settings include the the manager ID, which is the only one that has access to this system mode, the MongoDB bin directory, i.e., the directory where the MongoDB executable files are and that allows data extractions and imports, the directory where the system itself is installed, and finally, the directory to where the backups should be exported and also from where they should be imported. For example, this page can be seen in
Figure 13:
This page’s features are the management of the system configurations, exporting the system execution reports in CSV format, which can be filtered, making backup copies, customising the data one wants to copy, and restoring backup copies of the system. The backup copies will allow the system to be constantly aware of failure or data corruption situations. However, these features require that the system configurations are correctly completed and correct.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}