
The Fifteen Puzzle—A New Approach through Hybridizing Three Heuristics Methods

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
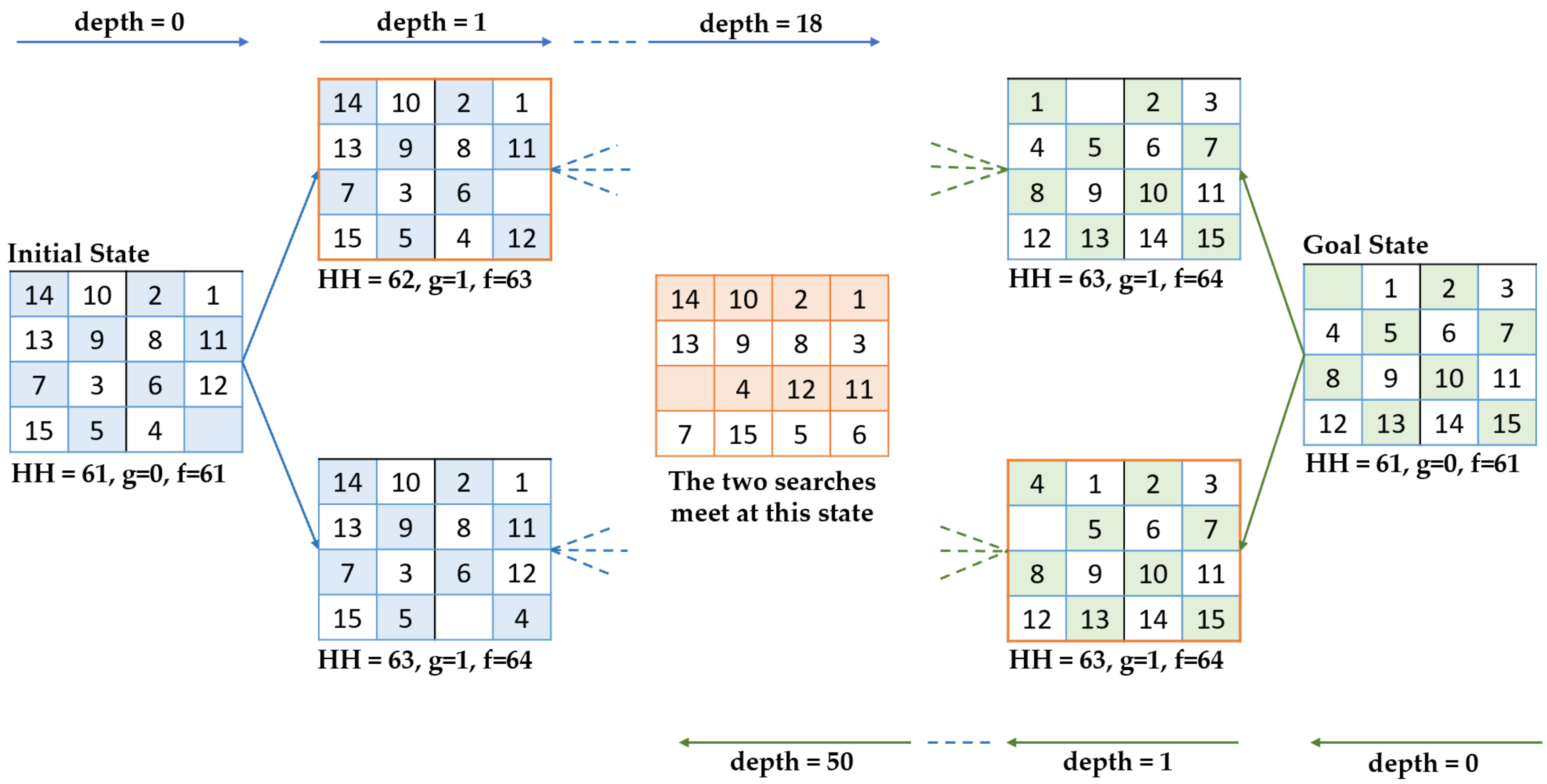
2. Bidirectional A* Algorithm
| Algorithm 1. BA* algorithm pseudocode |
| function BA* (StartState, GoalState) Initialise: Iteratorf to control the loop OpenListf to store the states to be traversed ClosedListf to store already traversed states OpenListb to store the states to be traversed ClosedListb to store already traversed states if Iteratorf = 0 then set depth cost of StartState (g(s) in Equation (2)) to zero calculate HH value from StartState to GoalState. Equation (3) calculate evaluation function for StartState. Equation (2) add StartState into OpenListf and ClosedListf while OpenListf is not empty do CurrentStatef is state with lowest evaluation function value (Equation (2)) in OpenListf remove CurrentStatef from OpenListf if CurrentStatef is GoalState then reconstruct the solution path from StartState to CurrentStatef, and terminates the loop for each NeighboringStatef of CurrentStatef do if NeighboringStatef is not in ClosedListf then depth cost of NeighboringStatef is equal to the depth cost of CurrentStatef plus one calculate HH value from NeighboringStatef to GoalState. Equation (3) calculate evaluation function for NeighboringStatef. Equation (2) add NeighboringStatef into ClosedListf add NeighboringStatef into OpenListf if NeighboringStatef is in ClosedListb then reconstruct the solution path from the two searches: from StartState to NeighboringStatef and from NeighboringStatef to GoalState, and terminates the loop increase Iteratorf by 1 if Iteratorf mod 15000 is equal to 0 after the first step of the cycle or Iteratorf mod 75000 is equal to 0 then ->Expand in the backward direction, analogously |
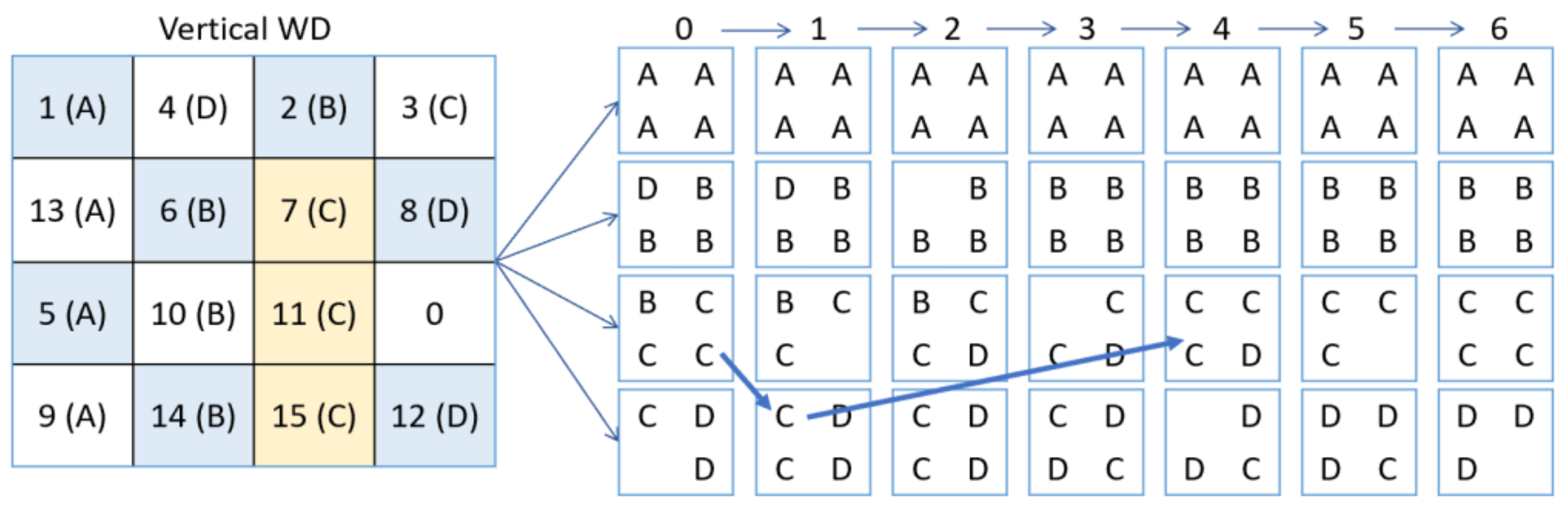
3. Heuristic Functions
4. Hybridized Heuristic Functions
5. Results and Discussions
5.1. Inadmissible Heuristics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NO | INITIAL STATE | Optimal LEN | LEN (ABC) BEST | LEN (BA*) |
|---|---|---|---|---|
| 1 | 1 5 2 7 10 14 11 6 15 12 9 3 13 0 8 4 | 34 | 37 | 34 |
| 2 | 5 6 10 7 1 3 11 8 13 4 15 9 14 0 2 12 | 38 | 43 | 38 |
| 3 | 1 11 6 2 10 13 15 5 3 12 0 4 9 7 14 8 | 40 | 46 | 42 |
| 4 | 6 5 2 7 13 0 10 12 4 1 3 14 9 11 15 8 | 44 | 49 | 46 |
| 5 | 4 3 10 7 6 0 1 2 12 15 5 14 9 13 8 11 | 44 | 52 | 46 |
| 6 | 4 10 3 2 1 0 7 8 9 6 13 15 14 12 11 5 | 44 | 51 | 52 |
| 7 | 3 4 11 2 9 1 14 15 7 6 0 8 5 13 12 10 | 44 | 51 | 44 |
| 8 | 3 10 2 5 15 6 13 4 0 11 1 7 9 12 8 14 | 46 | 52 | 48 |
| 9 | 9 4 0 3 14 7 5 12 15 2 13 6 10 1 8 11 | 46 | 54 | 48 |
| 10 | 7 1 12 10 6 11 15 4 0 2 5 14 3 13 8 9 | 48 | 59 | 50 |
| 11 | 1 13 5 7 14 9 10 12 11 8 2 15 6 0 4 3 | 48 | 62 | 50 |
| 12 | 13 9 5 12 10 2 4 11 3 8 0 7 1 14 6 15 | 48 | 64 | 50 |
| 13 | 2 13 6 1 14 5 11 0 12 4 8 10 9 3 15 7 | 50 | 66 | 50 |
| 14 | 11 3 12 9 2 8 10 14 0 7 15 13 1 6 5 4 | 50 | 68 | 52 |
| 15 | 7 6 15 12 14 1 13 3 0 9 8 4 2 11 5 10 | 50 | 68 | 52 |
| 16 | 5 8 13 15 14 0 1 7 4 6 10 2 11 9 12 3 | 52 | 59 | 56 |
| 17 | 12 2 5 11 10 0 1 6 3 14 8 9 7 4 13 15 | 52 | 62 | 52 |
| 18 | 13 3 2 8 12 0 5 1 11 6 9 15 4 14 7 10 | 52 | 63 | 52 |
| 19 | 7 13 1 4 9 12 8 5 15 14 0 6 11 2 3 10 | 52 | 59 | 52 |
| 20 | 8 11 12 10 2 0 15 1 14 6 4 3 7 9 5 13 | 54 | 61 | 58 |
| 21 | 6 8 12 13 7 2 5 14 9 3 1 15 11 0 10 4 | 54 | 65 | 54 |
| 22 | 9 12 2 5 11 1 10 14 0 4 3 8 6 15 7 13 | 54 | 67 | 60 |
| 23 | 10 12 11 7 8 9 14 5 3 13 4 1 6 0 2 15 | 56 | 69 | 56 |
| 24 | 3 10 14 5 1 12 11 8 15 7 9 6 2 0 13 4 | 56 | 71 | 58 |
| 25 | 9 3 12 5 4 14 6 11 8 7 15 13 10 0 2 1 | 56 | 71 | 60 |
| Average | 48.48 | 58.76 | 50.4 | |
5.2. Bidirectional and Unidirectional Search
| NO | INITIAL STATE | Optimal LEN | LEN (UA*) | Generated States (UA*) | LEN (BA*) | Generated States (BA*) |
|---|---|---|---|---|---|---|
| 1 | 15 14 8 12 10 11 9 13 2 6 5 1 3 7 4 0 | 80 | Memory ran out | 88 | 187,592 | |
| 2 | 15 11 13 12 14 10 8 9 7 2 5 1 3 6 4 0 | 80 | 84 | 138,505 | 84 | 138,505 |
| 3 | 15 11 13 12 14 10 8 9 2 6 5 1 3 7 4 0 | 80 | 82 | 1,605,359 | 86 | 367,391 |
| 4 | 15 11 9 12 14 10 13 8 6 7 5 1 3 2 4 0 | 80 | 82 | 771,924 | 86 | 420,441 |
| 5 | 15 11 9 12 14 10 13 8 2 6 5 1 3 7 4 0 | 80 | 84 | 1,207,604 | 86 | 199,905 |
| 6 | 15 11 8 12 14 10 13 9 2 7 5 1 3 6 4 0 | 80 | 82 | 809,360 | 82 | 185,126 |
| 7 | 15 11 9 12 14 10 8 13 6 2 5 1 3 7 4 0 | 80 | Memory ran out | 86 | 219,470 | |
| 8 | 15 11 8 12 14 10 9 13 2 6 5 1 3 7 4 0 | 80 | 84 | 2,565,243 | 86 | 200,926 |
| 9 | 15 11 8 12 14 10 9 13 2 6 4 5 3 7 1 0 | 80 | 84 | 751,072 | 84 | 190,731 |
| 10 | 15 14 13 12 10 11 8 9 2 6 5 1 3 7 4 0 | 80 | 82 | 1,137,335 | 84 | 205,344 |
| 11 | 15 11 13 12 14 10 9 5 2 6 8 1 3 7 4 0 | 80 | 82 | 1,933,020 | 86 | 530,773 |
| 12 | 0 12 9 13 15 11 10 14 3 7 2 5 4 8 6 1 | 80 | Memory ran out | 88 | 186,644 | |
| 13 | 0 12 10 13 15 11 14 9 3 7 2 5 4 8 6 1 | 80 | 84 | 2,096,287 | 84 | 207,896 |
| 14 | 0 11 9 13 12 15 10 14 3 7 6 2 4 8 5 1 | 80 | 84 | 949,297 | 84 | 198656 |
| 15 | 0 15 9 13 11 12 10 14 3 7 6 2 4 8 5 1 | 80 | 84 | 734,711 | 84 | 167,455 |
| 16 | 0 12 9 13 15 11 10 14 3 7 6 2 4 8 5 1 | 80 | Memory ran out | 86 | 256,899 | |
| 17 | 0 12 14 13 15 11 9 10 3 7 6 2 4 8 5 1 | 80 | 84 | 917,307 | 86 | 205,555 |
| 18 | 0 12 10 13 15 11 14 9 3 7 6 2 4 8 5 1 | 80 | 82 | 1,623,362 | 86 | 341,405 |
| 19 | 0 12 11 13 15 14 10 9 3 7 6 2 4 8 5 1 | 80 | Memory ran out | 86 | 520,393 | |
| 20 | 0 12 10 13 15 11 9 14 7 3 6 2 4 8 5 1 | 80 | 82 | 764,029 | 82 | 199,908 |
| 21 | 0 12 9 13 15 11 14 10 3 8 6 2 4 7 5 1 | 80 | Memory ran out | 86 | 213,147 | |
| 22 | 0 12 9 13 15 11 10 14 8 3 6 2 4 7 5 1 | 80 | 84 | 998,668 | 86 | 205,473 |
| 23 | 0 12 14 13 15 11 9 10 8 3 6 2 4 7 5 1 | 80 | 84 | 1,372,770 | 86 | 416,315 |
| 24 | 0 12 9 13 15 11 10 14 7 8 6 2 4 3 5 1 | 80 | 82 | 1,205,808 | 86 | 213,283 |
| 25 | 0 12 10 13 15 11 14 9 7 8 6 2 4 3 5 1 | 80 | 84 | 105,242 | 84 | 105,242 |
| 26 | 0 12 9 13 15 8 10 14 11 7 6 2 4 3 5 1 | 80 | 82 | 2,259,670 | 86 | 534,581 |
| 27 | 0 12 9 13 15 11 10 14 3 7 5 6 4 8 2 1 | 80 | Memory ran out | 88 | 160,899 | |
| 28 | 0 12 9 13 15 11 10 14 7 8 5 6 4 3 2 1 | 80 | 84 | 2,358,160 | 84 | 209,711 |
| Average | 80 | 83.1 | 1,252,606 | 85.4 | 256,774 | |
5.3. Experiments
| NO | INITIAL STATE | Optimal LEN | IDA* with MD + LC (Generated States) | BA* with HH (Generated States) | LEN (BA*) | BA* with HH (State Expansion) | WD | MD | LC | HH Value | Time (s) (BA*) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 14 13 15 7 11 12 9 5 6 0 2 1 4 8 10 3 | 57 | 12,205,623 | 4348 | 59 | 2146 | 43 | 41 | 2 | 59 | 0.15 |
| 2 | 13 5 4 10 9 12 8 14 2 3 7 1 0 15 11 6 | 55 | 4,556,067 | 104,760 | 59 | 50,143 | 45 | 43 | 0 | 59 | 1.16 |
| 3 | 14 7 8 2 13 11 10 4 9 12 5 0 3 6 1 15 | 59 | 156,590,306 | 39,851 | 59 | 18,672 | 43 | 41 | 0 | 57 | 0.59 |
| 4 | 5 12 10 7 15 11 14 0 8 2 1 13 3 4 9 6 | 56 | 9,052,179 | 128,358 | 58 | 62,894 | 44 | 42 | 0 | 58 | 1.22 |
| 5 | 4 7 14 13 10 3 9 12 11 5 6 15 1 2 8 0 | 56 | 2,677,666 | 20,413 | 58 | 9635 | 44 | 42 | 2 | 60 | 0.41 |
| 6 | 14 7 1 9 12 3 6 15 8 11 2 5 10 0 4 13 | 52 | 4,151,682 | 4682 | 54 | 2234 | 40 | 36 | 4 | 56 | 0.15 |
| 7 | 2 11 15 5 13 4 6 7 12 8 10 1 9 3 14 0 | 52 | 97,264,710 | 150,410 | 54 | 75,251 | 34 | 30 | 0 | 44 | 1.57 |
| 8 | 12 11 15 3 8 0 4 2 6 13 9 5 14 1 10 7 | 50 | 3,769,804 | 22,921 | 54 | 11,354 | 36 | 32 | 4 | 51 | 0.43 |
| 9 | 3 14 9 11 5 4 8 2 13 12 6 7 10 1 15 0 | 46 | 88,588 | 1811 | 48 | 871 | 34 | 32 | 4 | 49 | 0.10 |
| 10 | 13 11 8 9 0 15 7 10 4 3 6 14 5 12 2 1 | 59 | 48,531,591 | 42,218 | 59 | 20,030 | 47 | 43 | 2 | 63 | 0.60 |
| 11 | 5 9 13 14 6 3 7 12 10 8 4 0 15 2 11 1 | 57 | 25,537,948 | 67,872 | 59 | 32,265 | 45 | 43 | 2 | 61 | 0.86 |
| 12 | 14 1 9 6 4 8 12 5 7 2 3 0 10 11 13 15 | 45 | 179,628 | 633 | 45 | 298 | 37 | 35 | 0 | 49 | 0.05 |
| 13 | 3 6 5 2 10 0 15 14 1 4 13 12 9 8 11 7 | 46 | 1,051,213 | 14,327 | 48 | 7164 | 36 | 36 | 2 | 50 | 0.34 |
| 14 | 7 6 8 1 11 5 14 10 3 4 9 13 15 2 0 12 | 59 | 53,050,799 | 153,470 | 63 | 76,125 | 43 | 41 | 2 | 59 | 1.47 |
| 15 | 13 11 4 12 1 8 9 15 6 5 14 2 7 3 10 0 | 62 | 130,071,656 | 43,608 | 64 | 20,685 | 46 | 44 | 2 | 63 | 0.54 |
| 16 | 1 3 2 5 10 9 15 6 8 14 13 11 12 4 7 0 | 44 | 2,421,878 | 67,984 | 44 | 34,375 | 24 | 24 | 2 | 34 | 0.86 |
| 17 | 15 14 0 4 11 1 6 13 7 5 8 9 3 2 10 12 | 66 | 100,843,886 | 206,372 | 76 | 98,417 | 54 | 46 | 0 | 69 | 2.38 |
| 18 | 6 0 14 12 1 15 9 10 11 4 7 2 8 3 5 13 | 55 | 5,224,645 | 19,272 | 57 | 9121 | 43 | 43 | 0 | 57 | 0.38 |
| 19 | 7 11 8 3 14 0 6 15 1 4 13 9 5 12 2 10 | 46 | 385,369 | 5381 | 46 | 2475 | 36 | 36 | 2 | 50 | 0.18 |
| 20 | 6 12 11 3 13 7 9 15 2 14 8 10 4 1 5 0 | 52 | 3,642,638 | 32,036 | 54 | 15,414 | 36 | 36 | 0 | 48 | 0.51 |
| 21 | 12 8 14 6 11 4 7 0 5 1 10 15 3 13 9 2 | 54 | 43,980,448 | 59,920 | 56 | 28,403 | 40 | 34 | 2 | 53 | 0.91 |
| 22 | 14 3 9 1 15 8 4 5 11 7 10 13 0 2 12 6 | 59 | 79,549,136 | 4517 | 63 | 2112 | 45 | 41 | 4 | 63 | 0.14 |
| 23 | 10 9 3 11 0 13 2 14 5 6 4 7 8 15 1 12 | 49 | 770,088 | 43,664 | 51 | 21,113 | 37 | 33 | 4 | 52 | 0.64 |
| 24 | 7 3 14 13 4 1 10 8 5 12 9 11 2 15 6 0 | 54 | 15,062,608 | 31,366 | 54 | 14,750 | 38 | 34 | 4 | 53 | 0.66 |
| 25 | 11 4 2 7 1 0 10 15 6 9 14 8 3 13 5 12 | 52 | 13,453,743 | 5258 | 52 | 2485 | 36 | 32 | 4 | 51 | 0.19 |
| 26 | 5 7 3 12 15 13 14 8 0 10 9 6 1 4 2 11 | 58 | 50,000,803 | 110,470 | 58 | 53,289 | 42 | 40 | 4 | 59 | 1.20 |
| 27 | 14 1 8 15 2 6 0 3 9 12 10 13 4 7 5 11 | 53 | 31,152,542 | 37,847 | 55 | 19,212 | 37 | 33 | 2 | 50 | 0.63 |
| 28 | 13 14 6 12 4 5 1 0 9 3 10 2 15 11 8 7 | 52 | 1,584,197 | 16,633 | 54 | 7814 | 40 | 36 | 0 | 52 | 0.39 |
| 29 | 9 8 0 2 15 1 4 14 3 10 7 5 11 13 6 12 | 54 | 10,085,238 | 21,435 | 54 | 10,644 | 42 | 38 | 2 | 57 | 0.44 |
| 30 | 12 15 2 6 1 14 4 8 5 3 7 0 10 13 9 11 | 47 | 680,254 | 21,016 | 47 | 10,296 | 35 | 35 | 0 | 47 | 0.41 |
| 31 | 12 8 15 13 1 0 5 4 6 3 2 11 9 7 14 10 | 50 | 538,886 | 514 | 52 | 239 | 40 | 38 | 2 | 55 | 0.05 |
| 32 | 14 10 9 4 13 6 5 8 2 12 7 0 1 3 11 15 | 59 | 183,341,087 | 123,812 | 61 | 58,715 | 43 | 43 | 2 | 59 | 1.23 |
| 33 | 14 3 5 15 11 6 13 9 0 10 2 12 4 1 7 8 | 60 | 28,644,837 | 37,806 | 62 | 17,962 | 44 | 42 | 0 | 58 | 0.61 |
| 34 | 6 11 7 8 13 2 5 4 1 10 3 9 14 0 12 15 | 52 | 1,174,414 | 10,257 | 52 | 4916 | 38 | 36 | 6 | 56 | 0.26 |
| 35 | 1 6 12 14 3 2 15 8 4 5 13 9 0 7 11 10 | 55 | 9,214,047 | 58,967 | 55 | 28,765 | 41 | 39 | 0 | 54 | 0.72 |
| 36 | 12 6 0 4 7 3 15 1 13 9 8 11 2 14 5 10 | 52 | 4,657,636 | 13,346 | 52 | 6485 | 38 | 36 | 2 | 52 | 0.31 |
| 37 | 8 1 7 12 11 0 10 5 9 15 6 13 14 2 3 4 | 58 | 21,274,607 | 29,195 | 58 | 14,151 | 44 | 40 | 2 | 59 | 0.52 |
| 38 | 7 15 8 2 13 6 3 12 11 0 4 10 9 5 1 14 | 53 | 4,946,981 | 2105 | 53 | 1003 | 41 | 41 | 2 | 57 | 0.09 |
| 39 | 9 0 4 10 1 14 15 3 12 6 5 7 11 13 8 2 | 49 | 3,911,623 | 18,877 | 49 | 9056 | 35 | 35 | 0 | 47 | 0.35 |
| 40 | 11 5 1 14 4 12 10 0 2 7 13 3 9 15 6 8 | 54 | 13,107,557 | 120,964 | 56 | 58,445 | 38 | 36 | 2 | 52 | 1.17 |
| 41 | 8 13 10 9 11 3 15 6 0 1 2 14 12 5 4 7 | 54 | 12,388,516 | 5793 | 54 | 2776 | 42 | 36 | 4 | 58 | 0.17 |
| 42 | 4 5 7 2 9 14 12 13 0 3 6 11 8 1 15 10 | 42 | 217,288 | 17,756 | 46 | 8504 | 32 | 30 | 2 | 44 | 0.38 |
| 43 | 11 15 14 13 1 9 10 4 3 6 2 12 7 5 8 0 | 64 | 7,034,879 | 9938 | 68 | 4754 | 54 | 48 | 6 | 76 | 0.21 |
| 44 | 12 9 0 6 8 3 5 14 2 4 11 7 10 1 15 13 | 50 | 3,819,541 | 2461 | 50 | 1244 | 34 | 32 | 6 | 51 | 0.10 |
| 45 | 3 14 9 7 12 15 0 4 1 8 5 6 11 10 2 13 | 51 | 764,473 | 654 | 51 | 294 | 39 | 39 | 0 | 52 | 0.05 |
| 46 | 8 4 6 1 14 12 2 15 13 10 9 5 3 7 0 11 | 49 | 1,510,387 | 4417 | 51 | 2175 | 35 | 35 | 6 | 53 | 0.18 |
| 47 | 6 10 1 14 15 8 3 5 13 0 2 7 4 9 11 12 | 47 | 221,531 | 1173 | 47 | 565 | 35 | 35 | 0 | 47 | 0.08 |
| 48 | 8 11 4 6 7 3 10 9 2 12 15 13 0 1 5 14 | 49 | 255,047 | 2302 | 49 | 1080 | 41 | 39 | 0 | 54 | 0.11 |
| 49 | 10 0 2 4 5 1 6 12 11 13 9 7 15 3 14 8 | 59 | 203,873,877 | 156,955 | 65 | 75,800 | 39 | 33 | 4 | 54 | 1.54 |
| 50 | 12 5 13 11 2 10 0 9 7 8 4 3 14 6 15 1 | 53 | 6,225,180 | 37,831 | 57 | 18,100 | 41 | 39 | 2 | 56 | 0.61 |
| 51 | 10 2 8 4 15 0 1 14 11 13 3 6 9 7 5 12 | 56 | 4,683,054 | 25,419 | 56 | 12,338 | 44 | 44 | 0 | 59 | 0.48 |
| 52 | 10 8 0 12 3 7 6 2 1 14 4 11 15 13 9 5 | 56 | 33,691,153 | 120,510 | 60 | 60,031 | 40 | 38 | 4 | 57 | 1.22 |
| 53 | 14 9 12 13 15 4 8 10 0 2 1 7 3 11 5 6 | 64 | 125,641,730 | 103,879 | 68 | 49,722 | 54 | 50 | 0 | 71 | 1.11 |
| 54 | 12 11 0 8 10 2 13 15 5 4 7 3 6 9 14 1 | 56 | 26,080,659 | 47,294 | 58 | 22,908 | 42 | 40 | 2 | 57 | 0.76 |
| 55 | 13 8 14 3 9 1 0 7 15 5 4 10 12 2 6 11 | 41 | 163,077 | 5291 | 43 | 2400 | 33 | 29 | 2 | 45 | 0.18 |
| 56 | 3 15 2 5 11 6 4 7 12 9 1 0 13 14 10 8 | 55 | 166,183,825 | 153,475 | 59 | 75,038 | 35 | 29 | 4 | 49 | 1.50 |
| 57 | 5 11 6 9 4 13 12 0 8 2 15 10 1 7 3 14 | 50 | 3,977,809 | 8430 | 50 | 4021 | 36 | 36 | 0 | 48 | 0.22 |
| 58 | 5 0 15 8 4 6 1 14 10 11 3 9 7 12 2 13 | 51 | 3,563,941 | 8020 | 51 | 3771 | 39 | 37 | 4 | 55 | 0.21 |
| 59 | 15 14 6 7 10 1 0 11 12 8 4 9 2 5 13 3 | 57 | 90,973,287 | 36,373 | 57 | 17,423 | 39 | 35 | 4 | 55 | 0.65 |
| 60 | 11 14 13 1 2 3 12 4 15 7 9 5 10 6 8 0 | 66 | 256,537,528 | 167,180 | 72 | 80,902 | 54 | 48 | 0 | 70 | 1.69 |
| 61 | 6 13 3 2 11 9 5 10 1 7 12 14 8 4 0 15 | 45 | 672,959 | 3024 | 45 | 1471 | 31 | 31 | 4 | 45 | 0.12 |
| 62 | 4 6 12 0 14 2 9 13 11 8 3 15 7 10 1 5 | 57 | 8,463,998 | 23,726 | 61 | 11,426 | 45 | 43 | 2 | 61 | 0.40 |
| 63 | 8 10 9 11 14 1 7 15 13 4 0 12 6 2 5 3 | 56 | 20,999,336 | 14,771 | 56 | 7196 | 42 | 40 | 4 | 59 | 0.34 |
| 64 | 5 2 14 0 7 8 6 3 11 12 13 15 4 10 9 1 | 51 | 43,522,756 | 80,791 | 53 | 38,143 | 37 | 31 | 4 | 51 | 0.96 |
| 65 | 7 8 3 2 10 12 4 6 11 13 5 15 0 1 9 14 | 47 | 2,444,273 | 9450 | 47 | 4669 | 33 | 31 | 4 | 47 | 0.26 |
| 66 | 11 6 14 12 3 5 1 15 8 0 10 13 9 7 4 2 | 61 | 394,246,898 | 57,527 | 61 | 27,714 | 43 | 41 | 2 | 59 | 0.84 |
| 67 | 7 1 2 4 8 3 6 11 10 15 0 5 14 12 13 9 | 50 | 47,499,462 | 154,127 | 56 | 75,339 | 30 | 28 | 2 | 41 | 1.59 |
| 68 | 7 3 1 13 12 10 5 2 8 0 6 11 14 15 4 9 | 51 | 6,959,507 | 28,456 | 51 | 13,873 | 33 | 31 | 4 | 47 | 0.52 |
| 69 | 6 0 5 15 1 14 4 9 2 13 8 10 11 12 7 3 | 53 | 5,186,587 | 48,211 | 57 | 23,657 | 37 | 37 | 2 | 51 | 0.75 |
| 70 | 15 1 3 12 4 0 6 5 2 8 14 9 13 10 7 11 | 52 | 40,161,673 | 85,108 | 52 | 41,672 | 36 | 30 | 2 | 48 | 0.97 |
| 71 | 5 7 0 11 12 1 9 10 15 6 2 3 8 4 13 14 | 44 | 539,387 | 12,680 | 46 | 6422 | 30 | 30 | 4 | 44 | 0.30 |
| 72 | 12 15 11 10 4 5 14 0 13 7 1 2 9 8 3 6 | 56 | 55,514,360 | 147,629 | 64 | 75,073 | 42 | 38 | 2 | 57 | 1.42 |
| 73 | 6 14 10 5 15 8 7 1 3 4 2 0 12 9 11 13 | 49 | 1,130,807 | 1645 | 53 | 809 | 41 | 37 | 2 | 55 | 0.09 |
| 74 | 14 13 4 11 15 8 6 9 0 7 3 1 2 10 12 5 | 56 | 310,312 | 32,986 | 62 | 15,904 | 48 | 46 | 0 | 63 | 0.67 |
| 75 | 14 4 0 10 6 5 1 3 9 2 13 15 12 7 8 11 | 48 | 5,796,660 | 150,985 | 50 | 75,069 | 30 | 30 | 4 | 44 | 1.75 |
| 76 | 15 10 8 3 0 6 9 5 1 14 13 11 7 2 12 4 | 57 | 25,481,596 | 51,179 | 57 | 24,049 | 45 | 41 | 2 | 61 | 0.80 |
| 77 | 0 13 2 4 12 14 6 9 15 1 10 3 11 5 8 7 | 54 | 5,479,397 | 62,726 | 58 | 30,141 | 42 | 34 | 2 | 55 | 0.94 |
| 78 | 3 14 13 6 4 15 8 9 5 12 10 0 2 7 1 11 | 53 | 2,722,095 | 8781 | 55 | 4147 | 43 | 41 | 0 | 57 | 0.22 |
| 79 | 0 1 9 7 11 13 5 3 14 12 4 2 8 6 10 15 | 42 | 107,088 | 4554 | 42 | 2197 | 30 | 28 | 2 | 41 | 0.16 |
| 80 | 11 0 15 8 13 12 3 5 10 1 4 6 14 9 7 2 | 57 | 39,801,475 | 22,413 | 61 | 10,698 | 45 | 43 | 0 | 59 | 0.55 |
| 81 | 13 0 9 12 11 6 3 5 15 8 1 10 4 14 2 7 | 53 | 1,088,123 | 1420 | 53 | 689 | 41 | 39 | 2 | 56 | 0.08 |
| 82 | 14 10 2 1 13 9 8 11 7 3 6 12 15 5 4 0 | 62 | 203,606,265 | 173,460 | 68 | 87,034 | 44 | 40 | 4 | 61 | 1.97 |
| 83 | 12 3 9 1 4 5 10 2 6 11 15 0 14 7 13 8 | 49 | 2,155,880 | 32,271 | 51 | 16,376 | 35 | 31 | 6 | 51 | 0.58 |
| 84 | 15 8 10 7 0 12 14 1 5 9 6 3 13 11 4 2 | 55 | 17,323,672 | 100,981 | 57 | 49,825 | 39 | 37 | 6 | 57 | 1.14 |
| 85 | 4 7 13 10 1 2 9 6 12 8 14 5 3 0 11 15 | 44 | 933,953 | 11,604 | 46 | 5594 | 32 | 32 | 0 | 43 | 0.31 |
| 86 | 6 0 5 10 11 12 9 2 1 7 4 3 14 8 13 15 | 45 | 237,466 | 4906 | 47 | 2342 | 35 | 35 | 2 | 49 | 0.17 |
| 87 | 9 5 11 10 13 0 2 1 8 6 14 12 4 7 3 15 | 52 | 7,928,514 | 38,524 | 52 | 19,390 | 36 | 34 | 2 | 49 | 0.59 |
| 88 | 15 2 12 11 14 13 9 5 1 3 8 7 0 10 6 4 | 65 | 422,768,851 | 85,817 | 67 | 42,265 | 49 | 43 | 2 | 65 | 1.14 |
| 89 | 11 1 7 4 10 13 3 8 9 14 0 15 6 5 2 12 | 54 | 29,171,607 | 50,303 | 54 | 23,800 | 40 | 38 | 2 | 55 | 0.71 |
| 90 | 5 4 7 1 11 12 14 15 10 13 8 6 2 0 9 3 | 50 | 649,591 | 15,343 | 52 | 7592 | 36 | 36 | 4 | 52 | 0.36 |
| 91 | 9 7 5 2 14 15 12 10 11 3 6 1 8 13 0 4 | 57 | 91,220,187 | 36,250 | 57 | 17,644 | 43 | 41 | 0 | 57 | 0.56 |
| 92 | 3 2 7 9 0 15 12 4 6 11 5 14 8 13 10 1 | 57 | 68,307,452 | 35,707 | 57 | 17,553 | 39 | 37 | 2 | 53 | 0.65 |
| 93 | 13 9 14 6 12 8 1 2 3 4 0 7 5 10 11 15 | 46 | 350,208 | 72,971 | 50 | 35,114 | 36 | 34 | 0 | 47 | 0.95 |
| 94 | 5 7 11 8 0 14 9 13 10 12 3 15 6 1 4 2 | 53 | 390,368 | 4655 | 59 | 2158 | 45 | 45 | 0 | 60 | 0.15 |
| 95 | 4 3 6 13 7 15 9 0 10 5 8 11 2 12 1 14 | 50 | 1,517,920 | 14,900 | 54 | 6986 | 42 | 34 | 2 | 55 | 0.39 |
| 96 | 1 7 15 14 2 6 4 9 12 11 13 3 0 8 5 10 | 49 | 1,157,734 | 9322 | 51 | 4642 | 37 | 35 | 2 | 51 | 0.26 |
| 97 | 9 14 5 7 8 15 1 2 10 4 13 6 12 0 11 3 | 44 | 166,566 | 7933 | 44 | 3829 | 32 | 32 | 2 | 45 | 0.24 |
| 98 | 0 11 3 12 5 2 1 9 8 10 14 15 7 4 13 6 | 54 | 41,564,669 | 72,441 | 56 | 35,008 | 38 | 34 | 0 | 49 | 0.95 |
| 99 | 7 15 4 0 10 9 2 5 12 11 13 6 1 3 14 8 | 57 | 18,038,550 | 145,912 | 59 | 69,971 | 43 | 39 | 0 | 56 | 1.52 |
| 100 | 11 4 0 8 6 10 5 13 12 7 14 3 1 2 9 15 | 54 | 17,778,222 | 112,634 | 56 | 53,227 | 40 | 38 | 2 | 55 | 1.35 |
| SUM | 5307 | 3,759,631,814 | 4,841,970 | 5501 | 2,353,978 | 3957 | 3705 | 212 | 5404 | 64 | |
| Average | 53.07 | 37,596,318 | 48,420 | 55.01 | 23,540 | 40 | 37 | 2 | 54.04 | 0.64 | |
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alahmad, R.; Ishii, K. A Puzzle-Based Sequencing System for Logistics Items. Logistics 2021, 5, 76. [Google Scholar] [CrossRef]
- Korf, R.E.; Felner, A. Disjoint pattern database heuristics. Artif. Intell. 2002, 134, 9–22. [Google Scholar] [CrossRef] [Green Version]
- Muralidharan, S. The Fifteen Puzzle—A New Approach. Math. Mag. 2017, 90, 48–57. [Google Scholar] [CrossRef]
- Mulholland, J. Permutation Puzzles: A Mathematical Perspective; Lecture Notes: 2016. Available online: https://www.sfu.ca/~jtmulhol/math302/notes/302notes-Jun30-2016.pdf (accessed on 1 September 2022).
- Bright, C.; Gerhard, J.; Kotsireas, I.; Ganesh, V. Effective problem solving using SAT solvers. In Maple Conference; Springer: Cham, Switzerland, 2019; pp. 205–219. [Google Scholar]
- Edelkamp, S.; Schrödl, S. Chapter 9–Distributed Search. In Heuristic Search; Edelkamp, S., Schrödl, S., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 2012; pp. 369–427. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Korf, R.E. Depth-first iterative-deepening: An optimal admissible tree search. Artif. Intell. 1985, 27, 97–109. [Google Scholar] [CrossRef]
- Russell, S.; Norvig, P. Artificial intelligence: A modern approach, global edition 4th. Foundations 2021, 19, 23. [Google Scholar]
- Grosan, C.; Abraham, A. Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2011; Volume 17. [Google Scholar]
- Edelkamp, S.; Schrodl, S. Heuristic Search: Theory and Applications; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Takahashi, K. How to Make an Automatic 15 Puzzle Answering Program. Available online: http://www.ic-net.or.jp/home/takaken/nt/slide/solve15.html (accessed on 10 September 2022).
- Irani, K.B.; Yoo, S.I. A methodology for solving problems: Problem modeling and heuristic generation. IEEE Trans. Pattern Anal. Mach. Intell. 1988, 10, 676–686. [Google Scholar] [CrossRef]
- Hansson, O.; Mayer, A.; Yung, M. Criticizing solutions to relaxed models yields powerful admissible heuristics. Inf. Sci. (N.Y.) 1992, 63, 207–227. [Google Scholar] [CrossRef]
- Culberson, J.; Schaeffer, J. Efficiently searching the 15-puzzle. Technical Report TR94-08; Department of Computer Science, University of Alberta: Alberta, Canada, 1994. [Google Scholar]
- Holte, R.C.; Newton, J.; Felner, A.; Meshulam, R.; Furcy, D. Multiple Pattern Databases. In ICAPS; AAAI Press: Menlo Park, CA, USA, 2004; pp. 122–131. [Google Scholar]
- Larsen, B.J.; Burns, E.; Ruml, W.; Holte, R. Searching without a heuristic: Efficient use of abstraction. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Felner, A.; Korf, R.E.; Hanan, S. Additive pattern database heuristics. J. Artif. Intell. Res. 2004, 22, 279–318. [Google Scholar] [CrossRef]
- Li, C.; Huang, X.; Ding, J.; Song, K.; Lu, S. Global path planning based on a bidirectional alternating search A* algorithm for mobile robots. Comput. Ind. Eng. 2022, 168, 108123. [Google Scholar] [CrossRef]
- Wang, H.; Qi, X.; Lou, S.; Jing, J.; He, H.; Liu, W. An Efficient and Robust Improved A* Algorithm for Path Planning. Symmetry 2021, 13, 2213. [Google Scholar] [CrossRef]
- Lai, W.K.; Shieh, C.-S.; Yang, C.-P. A D2D Group Communication Scheme Using Bidirectional and InCremental A-Star Search to Configure Paths. Mathematics 2022, 10, 3321. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, J.; Dai, J.; He, C. Optimal path planning with modified A-Star algorithm for stealth unmanned aerial vehicles in 3D network radar environment. Proc. Inst. Mech. Eng. G J. Aerosp. Eng. 2022, 236, 72–81. [Google Scholar] [CrossRef]
- Ernandes, M.; Gori, M. Likely-admissible and sub-symbolic heuristics. In Proceedings of the 16th European Conference on Artificial Intelligence, Valencia, Spain, 24–27 August 2004; pp. 613–618. [Google Scholar]
- Samadi, M.; Felner, A.; Schaeffer, J. Learning from Multiple Heuristics. In Proceedings of the 23rd national conference on Artificial intelligence, Menlo Park, California, 13–17 July 2008; pp. 357–362. [Google Scholar]
- Burke, E.K.; Hyde, M.; Kendall, G.; Ochoa, G.; Özcan, E.; Woodward, J.R. A classification of hyper-heuristic approaches. In Handbook of Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2010; pp. 449–468. [Google Scholar]
- Sheha, M. b, Artificial Intelligence in Diffusion MRI; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Holte, R.C.; Felner, A.; Newton, J.; Meshulam, R.; Furcy, D. Maximizing over multiple pattern databases speeds up heuristic search. Artif. Intell. 2006, 170, 1123–1136. [Google Scholar] [CrossRef] [Green Version]
- Haslum, P.; Bonet, B.; Geffner, H. New admissible heuristics for domain-independent planning. In Proceedings of the 20th national conference on Artificial intelligence, 9–13 July, Menlo Park, California; 2005; Volume 5, pp. 1163–1168. [Google Scholar]
- Katz, M.; Domshlak, C. Optimal Additive Composition of Abstraction-based Admissible Heuristics. In ICAPS; AAAI Press: Menlo Park, CA, USA, 2008; pp. 174–181. [Google Scholar]
- Yang, F.; Culberson, J.; Holte, R.; Zahavi, U.; Felner, A. A general theory of additive state space abstractions. J. Artif. Intell. Res. 2008, 32, 631–662. [Google Scholar] [CrossRef] [Green Version]
- Korf, R.E.; Taylor, L.A. Finding optimal solutions to the twenty-four puzzle. In Proceedings of the National Conference on Artificial Intelligence, Portland, OR, USA, 4–8 August 1996; pp. 1202–1207. [Google Scholar]
- Korf, R.E. Recent progress in the design and analysis of admissible heuristic functions. In Proceedings of the International Symposium on Abstraction, Reformulation, and Approximation, Menlo Park, CA, USA; AAAI Press, 2000; pp. 1165–1170. [Google Scholar]
- Demaine, E.D.; Rudoy, M. A simple proof that the (n2- 1)-puzzle is hard. Theor. Comput. Sci. 2018, 732, 80–84. [Google Scholar] [CrossRef] [Green Version]
- Pizlo, Z.; Li, Z. Solving combinatorial problems: The 15-puzzle. Mem. Cognit. 2005, 33, 1069–1084. [Google Scholar] [CrossRef]
- Araneda, P.; Greco, M.; Baier, J. Exploiting Learned Policies in Focal Search. arXiv 2021, arXiv:2104.10535. [Google Scholar] [CrossRef]
- Thayer, J.; Dionne, A.; Ruml, W. Learning inadmissible heuristics during search. In Proceedings of the International Conference on Automated Planning and Scheduling, Freiburg, Germany, 11–16 June 2011; Volume 21. [Google Scholar]
- Hussain, K.; Salleh, M.N.M.; Cheng, S.; Shi, Y. Metaheuristic research: A comprehensive survey. Artif. Intell. Rev. 2019, 52, 2191–2233. [Google Scholar] [CrossRef] [Green Version]
- el Raoui, H.; Cabrera-Cuevas, M.; Pelta, D.A. The Role of Metaheuristics as Solutions Generators. Symmetry 2021, 13, 2034. [Google Scholar] [CrossRef]
- Bacanin, N.; Stoean, R.; Zivkovic, M.; Petrovic, A.; Rashid, T.A.; Bezdan, T. Performance of a novel chaotic firefly algorithm with enhanced exploration for tackling global optimization problems: Application for dropout regularization. Mathematics 2021, 9, 2705. [Google Scholar] [CrossRef]
- Tuncer, A. 15-Puzzle Problem Solving with the Artificial Bee Colony Algorithm Based on Pattern Database. J. Univers. Comput. Sci. 2021, 27, 635–645. [Google Scholar] [CrossRef]
- Holte, R.C.; Felner, A.; Sharon, G.; Sturtevant, N.R.; Chen, J. MM: A bidirectional search algorithm that is guaranteed to meet in the middle. Artif. Intell. 2017, 252, 232–266. [Google Scholar] [CrossRef]
- Pohl, I. Bi-directional search. Mach. Intell. 1971, 6, 127–140. [Google Scholar]
- de Champeaux, D. Bidirectional heuristic search again. J. ACM (JACM) 1983, 30, 22–32. [Google Scholar] [CrossRef]
- Kaindl, H.; Kainz, G. Bidirectional heuristic search reconsidered. J. Artif. Intell. Res. 1997, 7, 283–317. [Google Scholar] [CrossRef] [Green Version]
- Kwa, J.B.H. BS∗: An admissible bidirectional staged heuristic search algorithm. Artif. Intell. 1989, 38, 95–109. [Google Scholar] [CrossRef]
- Hong, Z.; Sun, P.; Tong, X.; Pan, H.; Zhou, R.; Zhang, Y.; Han, Y.; Wang, J.; Yang, S.; Xu, L. Improved A-Star Algorithm for Long-Distance Off-Road Path Planning Using Terrain Data Map. ISPRS Int. J. Geoinf. 2021, 10, 785. [Google Scholar] [CrossRef]
- Ge, Q.; Li, A.; Li, S.; Du, H.; Huang, X.; Niu, C. Improved Bidirectional RRT Path Planning Method for Smart Vehicle. Math. Probl. Eng. 2021, 2021. [Google Scholar] [CrossRef]
- Pavlik, J.A.; Sewell, E.C.; Jacobson, S.H. Two new bidirectional search algorithms. Comput. Optim. Appl. 2021, 80, 377–409. [Google Scholar] [CrossRef]
- Yamín, D.; Medaglia, A.L.; Prakash, A.A. Exact bidirectional algorithm for the least expected travel-time path problem on stochastic and time-dependent networks. Comput. Oper. Res. 2022, 141, 105671. [Google Scholar] [CrossRef]
- Yijun, Z.; Jiadong, X.; Chen, L. A fast bi-directional A* algorithm based on quad-tree decomposition and hierarchical map. IEEE Access 2021, 9, 102877–102885. [Google Scholar] [CrossRef]
- Korf, R.E.; Schultze, P. Large-scale parallel breadth-first search. In AAAI; AAAI Press: Menlo Park, CA, USA, 2005; Volume 5, pp. 1380–1385. [Google Scholar]
- Bhasin, H.; Singla, N. Genetic based algorithm for N-puzzle problem. Int. J. Comput. Appl. 2012, 51, 22. [Google Scholar] [CrossRef]
- Gasser, R.U. Harnessing computational resources for efficient exhaustive search. Ph.D. Thesis, ETH, Zurich, Switzerland, 1995. [Google Scholar]
- Brüngger, A.; Marzetta, A.; Fukuda, K.; Nievergelt, J. The parallel search bench ZRAM and its applications. Ann. Oper. Res. 1999, 90, 45–63. [Google Scholar] [CrossRef]
- Kociemba, H. 15-Puzzle Optimal Solver. Available online: http://kociemba.org/themen/fifteen/fifteensolver.html (accessed on 8 August 2022).
- Cahlik, V.; Surynek, P. Near Optimal Solving of the (N$$^2$$–1)-puzzle Using Heuristics Based on Artificial Neural Networks. In Proceedings of the Computational Intelligence: 11th International Joint Conference, IJCCI 2019, Vienna, Austria, Switzerland, 17–19 September; Merelo, J.J., Garibaldi, J., Linares-Barranco, A., Warwick, K., Madani, K., Eds., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 291–312. [Google Scholar] [CrossRef]
- Greco, M. Exploiting Learned Policies and Learned Heuristics in Bounded-Suboptimal Search. In Proceedings of the International Symposium on Combinatorial Search, Guangzhou, China; AAAI Press, 2021; Volume 12, pp. 219–221. [Google Scholar]
- Greco, M.; Baier, J.A. Bounded-Suboptimal Search with Learned Heuristics. 2021. Available online: https://prl-theworkshop.github.io/prl2021/papers/PRL2021_paper_33.pdf (accessed on 23 November 2022).
- Clausecker, R. Notes on the Construction of Pattern Databases. 2017. Available online: https://opus4.kobv.de/opus4-zib/files/6558/zibba.pdf (accessed on 23 November 2022).
- Abdullah, J.M.; Ahmed, T. Fitness dependent optimizer: Inspired by the bee swarming reproductive process. IEEE Access 2019, 7, 43473–43486. [Google Scholar] [CrossRef]
- Rahman, C.M.; Rashid, T.A. A new evolutionary algorithm: Learner performance based behavior algorithm. Egypt. Inform. J. 2021, 22, 213–223. [Google Scholar] [CrossRef]
- Rashid, D.N.H.; Rashid, T.A.; Mirjalili, S. ANA: Ant Nesting Algorithm for Optimizing Real-World Problems. Mathematics 2021, 9, 3111. [Google Scholar] [CrossRef]








| No. of Rows | Number of Tiles from 1st Row | Number of Tiles from 2nd Row | Number of Tiles from 3rd Row | Number of Tiles from 4th Row | Blank Tile |
|---|---|---|---|---|---|
| 1st row | 4 | 0 | 0 | 0 | |
| 2nd row | 0 | 3 | 0 | 1 | |
| 3rd row | 0 | 1 | 2 | 0 | ← here |
| 4th row | 0 | 0 | 2 | 2 |
| Problems | Total WD | Total MD | Total LC | Total Optimal |
|---|---|---|---|---|
| Korf’s 100 instances | 3957 | 3705 | 212 | 5307 |
| Criterion | UA* with HH | BA* with HH |
|---|---|---|
| Time complexity | ||
| Space complexity | ||
| Complete | Yes | Yes |
| Optimal | No | No |
| Coverage | Expansions (avg) | Cost (avg) | Average Time (seconds) | |
|---|---|---|---|---|
| BA* with HH | 100% | 23,540 | 55.01 | 0.64 |
| FS (h nn) | 83% | 10,414 | 54.57 | >100 |
| FDS (best) | 100% | 1478 | 55.47 | >10 |
| FDS (rank) | 100% | 6542 | 55.45 | >10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasan, D.O.; Aladdin, A.M.; Talabani, H.S.; Rashid, T.A.; Mirjalili, S. The Fifteen Puzzle—A New Approach through Hybridizing Three Heuristics Methods. Computers 2023, 12, 11. https://doi.org/10.3390/computers12010011
Hasan DO, Aladdin AM, Talabani HS, Rashid TA, Mirjalili S. The Fifteen Puzzle—A New Approach through Hybridizing Three Heuristics Methods. Computers. 2023; 12(1):11. https://doi.org/10.3390/computers12010011
Chicago/Turabian StyleHasan, Dler O., Aso M. Aladdin, Hardi Sabah Talabani, Tarik Ahmed Rashid, and Seyedali Mirjalili. 2023. "The Fifteen Puzzle—A New Approach through Hybridizing Three Heuristics Methods" Computers 12, no. 1: 11. https://doi.org/10.3390/computers12010011
APA StyleHasan, D. O., Aladdin, A. M., Talabani, H. S., Rashid, T. A., & Mirjalili, S. (2023). The Fifteen Puzzle—A New Approach through Hybridizing Three Heuristics Methods. Computers, 12(1), 11. https://doi.org/10.3390/computers12010011