1. Introduction
The escalating prevalence of cyberattacks presents a daunting and unrelenting challenge to organizations worldwide. This problem is further compounded by the exponential increase in the volume of malware [
1]. According to AV-Test, cybersecurity researchers identified and catalogued over one billion new malware samples in 2022 alone [
1]. Cyberattacks are often orchestrated by malicious actors with varying degrees of sophistication, and cast a long shadow over businesses and institutions. Not only do they jeopardize sensitive data and critical infrastructure, but they also disrupt regular business operations, potentially leading to reputational damage and substantial financial losses [
2]. This growing threat landscape requires constant vigilance and innovative strategies to defend against malware attacks [
3,
4,
5]. In this context, security researchers are tasked with creating robust detection and prevention mechanisms. These require solutions with the formidable capability of staying one step ahead of cybercriminals [
6,
7]. This imperative has spurred an environment of constant innovation and adaptation, pushing security researchers to think creatively and harness cutting-edge technologies to safeguard digital assets. Among the arsenal of tools and approaches at their disposal, artificial intelligence, particularly machine learning, has emerged as a long-term solution to combat malware threats. With the ability of machine learning to discern intricate patterns and anomalies within vast datasets, security researchers have made significant strides in detecting and deterring a multitude of malware attacks [
8,
9,
10]. The effectiveness of machine learning in identifying new and previously unseen attack vectors presents a promising and forward-looking approach to cyberdefense.
While machine learning holds great promise, its effectiveness is intricately tied to the quality and quantity of the data on which models are trained [
4,
11]. High-quality data are characterized by cleanliness and completeness along with a lack of missing or corrupted information. The integrity of the data is paramount, as even minor discrepancies or inaccuracies can propagate through the learning process, leading to skewed models and erroneous results. Moreover, the distribution and balance of data across different classes or categories are of critical importance. For instance, when training a machine learning model to distinguish between benign and malicious software, having a balanced dataset with a similar number of instances from each class is vital [
12]. Imbalances can lead to biased models that overemphasize the majority class, potentially resulting in misleadingly high accuracy scores. Security researchers often focus on specific attributes or features that characterize malware or malicious behaviour. This attribute-based approach requires the execution of numerous malware samples within a controlled environment, often referred to as a sandbox, in order to capture the relevant data needed for machine learning [
4,
5,
13]. While this process is essential for feature engineering, it is undeniably labour-intensive and susceptible to errors, potentially impacting the reliability and accuracy of the acquired data. A substantial portion of the raw data generated during these experiments often remains underutilized, and in most cases is undisclosed. This underutilization stems from the absence of platforms that can effectively manage, store, and make such data accessible to the broader research community, resulting in a considerable loss of valuable insights and research potential.
To address these challenges and bridge the gap between data availability and research needs, in this paper, we introduce a malware analysis data curation platform. This platform is designed to empower security researchers by offering a highly customizable feature generation process sourced from analysis data reports, particularly those generated in sandboxed environments such as Cuckoo Sandbox [
14]. The platform aims to streamline the labour-intensive data acquisition process while providing a centralized repository for malware analysis data. In this way, it enables researchers to more efficiently build datasets, contribute reports, and collaborate with peers. Through community-driven interactive databanks, the platform facilitates a collective effort to reduce experimentation time and enhance the repeatability and verifiability of research outcomes.
The remainder of this paper is structured as follows. First, the background necessary to better understand the problem at hand is discussed. Thereafter, the proposed platform is presented and further discussed using a high-level process model. This is followed by an evaluation of the platform, which is achieved through the NIST validation cycle [
15] while abiding by software engineering principles. To further highlight the usefulness of the platform, three case studies that involved malware detection with Cuckoo Sandbox reports are assessed to illustrate how the platform can aid researchers. Another method used to show the effectiveness of the platform is the reproduction of the identified case studies using the platform, followed by a comparison of the results. Furthermore, a literature search is conducted to determine the extent to which the platform can aid malware detection research, and a comparative analysis is conducted to determine whether any similar platforms currently exist and how the proposed platform compares to them. Finally, a real-world scenario is then used to illustrate how the platform can foster new novel research approaches using PE entropy for ransomware detection.
2. Background
The process of constructing concrete and reliable datasets for machine learning applications is a formidable undertaking [
5,
16]. Crafting a dataset that stands as a dependable foundation for robust machine learning models requires a comprehensive understanding of the data, mastery of data processing techniques, and the ability to interpret the data and extract meaningful insights. Fundamentally, the quality and relevance of a dataset hinges on its alignment with the intended purpose, making clarity of objectives a crucial starting point. The journey to create such datasets comprises numerous methodologies, each tailored to specific objectives, and often relies on meticulous domain expertise.
In the realm of machine learning, the availability of comprehensive datasets is paramount. These datasets serve as the fuel that powers the algorithms, enabling them to learn, generalize, and make predictions. The vast troves of data encountered in modern applications necessitate sophisticated approaches to processing and analysis. This is where machine learning algorithms come into play, providing the capacity to efficiently handle and derive valuable insights from large and complex datasets [
9]. Machine learning algorithms can be broadly categorized into two main groups: supervised and unsupervised learning. In supervised learning, algorithms are trained on labelled datasets containing both positive and negative examples. This training equips them to recognize the distinguishing characteristics of positive and negative instances, making the resulting models suitable for classification tasks. On the other hand, unsupervised learning empowers algorithms to autonomously uncover patterns and relationships within data, effectively allowing the data to define what constitutes positive and negative instances. While unsupervised learning holds value in various contexts, it is generally discouraged for classification tasks due to the potential introduction of a bias, which can significantly impact outcomes.
Traditional techniques for malware detection have long revolved around static analysis [
17,
18,
19]. Static analysis involves the examination of an executable or information prior to its execution, making it an invaluable tool to quickly identify malicious entities through signature-based pattern matching and key identifiers such as fingerprinting. However, the efficacy of static analysis is limited by the evolving tactics of modern malware, which often employ obfuscation techniques and embedding to evade detection [
20,
21]. Dynamic analysis involves the execution of malware, and has emerged as the most accurate method for detecting malware; yet, this approach comes with inherent risks, as executing malware can potentially inflict irreparable harm on a system [
22]. To mitigate this risk, sandboxed environments have become essential in dynamic analysis. These controlled environments ensure that the host system remains unharmed, and snapshots can be employed to revert to a previous state after analysis. However, dynamic analysis generates copious amounts of data, rendering manual analysis impractical and inefficient [
5,
23,
24].
This is precisely where machine learning emerges as a critical catalyst for progress. Machine learning algorithms possess the ability to sift through vast datasets, discern hidden patterns, and identify correlations that elude human analysts. By leveraging machine learning, the risk of human error is mitigated and the time required to formulate effective defences against malware is significantly reduced. However, a pivotal challenge arises in obtaining data, as malware binary samples must be sourced, executed, and analyzed before the requisite data become available for machine learning algorithms.
In previous work by Singh et al. [
5], machine learning techniques were applied to a dataset comprising ransomware and benign samples in order to detect ransomware attacks using process memory. The dataset comprised 354 benign and 117 ransomware samples, producing a dataset of 937 samples after analysis. Building a balanced dataset was a challenging task, and resulted in laborious execution of these samples to extract process memory. Upon using the various memory access privileges, ransomware was detected with 96.28% accuracy with the XGBoost algorithm. In work by Ashraf et al. [
13], a method was proposed to detect ransomware using transfer learning based on deep convolutional neural networks. Their approach tackled both static and dynamic analysis, using tools to extract the static information and Cuckoo Sandbox to extract the dynamic features. The dataset was sourced from 3646 samples for the static part and 3444 samples for the dynamic part. As there were two datasets, the obtained results were 98% for static features using random forest and 92% for dynamic features using support vector machine. Using the transfer learning technique, an accuracy score of 94% was achieved from 300 features. However, no raw data were available for further validation of the results additional research.
The research by Faruki et al. [
23] detected malware using API call-grams. Using Cuckoo Sandbox, 2510 benign and 2487 malicious samples were analysed to build their dataset. Faruki et al. [
23] identified that the API call-grams generated an imbalanced dataset, with an induced bias towards API calls for certain classes. Using the voted perceptron algorithm from Rosenblatt and Frank [
25], an accuracy score of 98.7% was achieved. Hansen et al. [
26] evaluated behavioural traces of over 270,000 malware and 837 benign samples. Using Cuckoo Sandbox, the samples were analysed, and feature selection based on the information entropy and information gain ratio was used to obtain the feature set. For malware detection, Hansen et al. [
26] decided to perform a dataset reduction of 88%, using only 1650 malware samples. Random forest was used to train the machine learning model on this reduced dataset, resulting in a weighted average score of 0.981. This dataset was heavily imbalanced; thus, dataset reduction can ensure that there is no over-representation of datapoints. Darshan et al. [
27] used Cuckoo Sandbox for malware detection by the impact of exploring n-grams on the behaviour of the sample. With 3000 benign and 3000 malicious samples, and using an n-gram length of 3 and the Pegasos [
28] algorithm, they obtained an accuracy of 90.03%. Poudyal and Dasgupta [
29] created a ransomware detection framework that utilized Cuckoo Sandbox and Ghidra to perform detection using behaviour such as DLL and API calls, then performed NLP on the assembly code extracted from the samples. Using 550 ransomware and 540 benign samples, Poudyal and Dasgupta [
29] achieved 99.54% accuracy using SVM and Adaboost with J48.
A common aspect across all of these research papers is that both static and dynamic analysis are needed for malware detection [
5,
13,
23,
26,
27,
29]. Each paper utilized Cuckoo Sandbox to obtain the raw data from the sample execution. These raw data were then processed using the necessary information (algorithm) based on the different approaches that the researchers developed. The extracted information was then used to build a robust dataset. The process of obtaining raw data is laborious, as it requires the execution of each sample. This makes the efforts of individual research teams unnecessarily complex, as there is no platform available to obtain raw Cuckoo reports. While platforms such as Kaggle [
30], DataRobot [
31], and Alteryx [
32] exist, they depend solely on the processed dataset uploaded by the author and the willingness of authors to upload the code used to build machine learning models from the dataset. Considering that Kaggle is a general-purpose dataset platform, there is no way for raw data to be accessed and reused. This makes it difficult to evaluate the data quality as well as the information presented in the dataset. With DataRobot, both feature extraction and further processing of the data in a dataset are possible; however, it is limited to data uploaded for a project, and cannot be used for general purposes. Similarly, Alteryx [
32] allows for the aggregation of data pipelines from multiple sources. However, these data sources are defined by the end user, and are not available ‘out of the box’ for the user base on the platform. Therefore, it cannot aid in promoting experimental repeatability.
To bridge this crucial gap, in this research we develop a novel solution in the form of a platform designed to facilitate the generation of datasets from Cuckoo Sandbox reports. By simplifying the process of dataset generation and compilation, the proposed platform empowers security researchers and data scientists to construct more accurate and effective machine learning models for malware detection. In the following sections, the intricacies of this platform are discussed, including its architectural composition, functionalities, capabilities, and corresponding pivotal role in fortifying the collective defense against the relentless tide of malware threats.
3. MalFe Platform
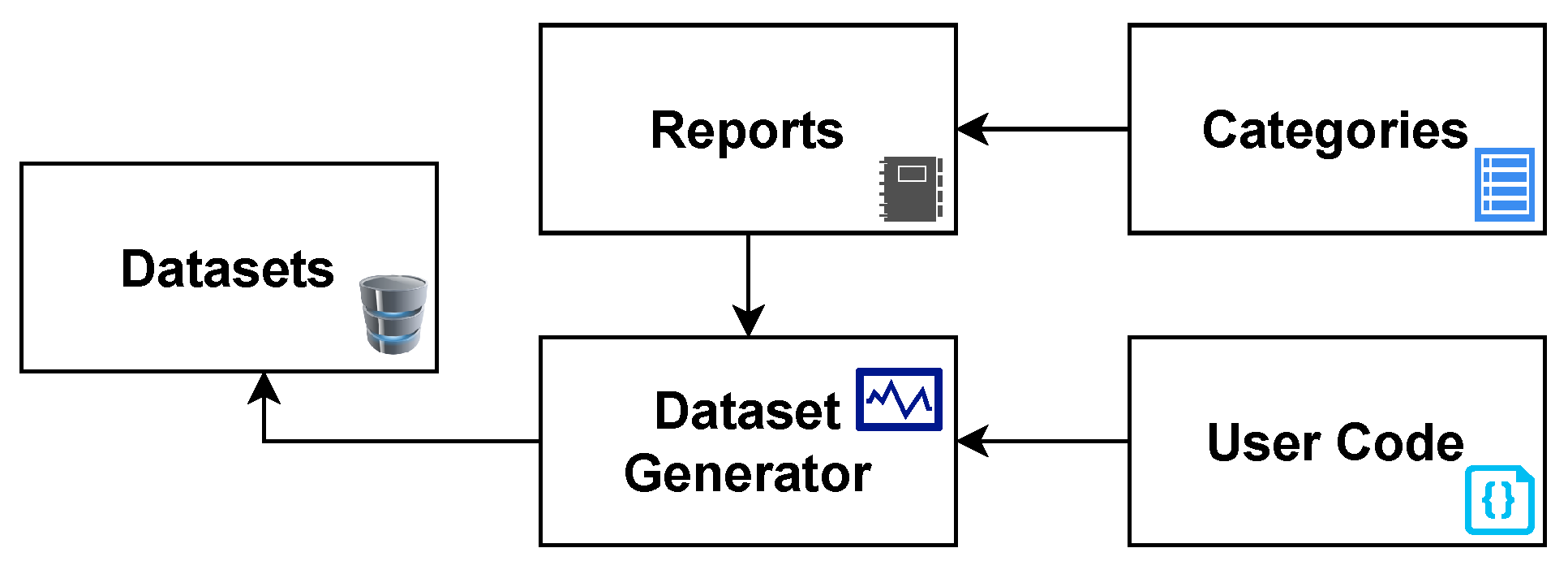
The Malware Feature Engineering (MalFe) platform aims to simplify the difficulty of obtaining and creating custom datasets from a databank through a community-driven platform. To ensure a scientific process, the design approach leverages software engineering principles to develop the processes and features of the platform. On a high level, MalFe contains five key components: Reports, Categories, User Code, Dataset Generator, and Datasets, as depicted in
Figure 1. The reports consist of raw Cuckoo Sandbox reports which, are uploaded by the community from experiments run to analyze malware samples. The categories help with organizing these reports, allowing more targeted datasets to be built. User code is used to parse through this data repository of reports and extract the relevant information required to generate a dataset. The user code is then fed into a dataset generator, which runs on a queue basis and executes the user code, based on the selected categories of reports, resulting in a dataset being generated. After being approved by their creator(s), these datasets are then made available for public viewing.
The MalFe process model is shown in
Figure 2; in order to prevent misuse and to grow trust on the platform, this process starts with account creation and verification. After successful authentication, a user is able to browse the existing datasets that have been generated by the community. Thereafter, a user can search for a dataset that matches their need. In the event that the dataset does not exist on the platform yet, the user has the option to browse the uploaded Cuckoo Sandbox reports to see whether the information needed to build the dataset is available. If the information is not sufficient, the user needs to source more reports, either through experimentation or by obtaining them from an external source. Because such reports can be rather large, it is both difficult and typically not feasible to download all the reports in order to investigate the data.
To solve this problem, a lightweight comparison tool called IntelliView was created and added to the platform. It allows end users to browse sections of reports, making it easier to browse and compare reports. After manual observation conducted through IntelliView, if the user finds any malformed or erroneous reports they can flag these reports, ensuring that high-quality data are always available to the community and further enhancing the trust in the platform. At this stage, the reports are sufficient, and quality control has been conducted. The next step is for the user to add code to allow these reports to be parsed in order to extract the information needed to build the dataset. When this is complete, the metadata needed for the platform to build the dataset are requested from the user. This includes the category of reports for the dataset to be built off, as well as the name and description of the dataset. After the user code is checked for security vulnerabilities and syntax errors, the code is successfully queued on the platform to generate the dataset in a restricted environment. The process of dataset generation involves several status changes, keeping the user aware of what is happening. If the status is set to QUEUED, this means that the dataset has been added to a queue; the next generated dataset is taken from the queue when the previous dataset has been completed. This then sets the dataset generation status to PROCESSING. The processing stage of dataset generation is the core functionality of the platform, providing users with the ability to design the data according to their specific requirements. Error handling is integrated into the platform as well, providing an opportunity to understand any misconfiguration or other sources of errors during the data generation process. After dataset generation is completed, the data are written to a CSV file and saved on the platform, and the status is set to COMPLETE. The owner is then prompted to verify the dataset and perform quality checking. When approved by the owner, the dataset is made publicly available. Finally, the dataset is available to be downloaded, shared, and even commented on for further research and networking with security professionals. The next section discusses the technical details behind the implementation of the platform.
MalFe Implementation
The platform was developed following a modular approach and in line with agile principles to ensure adaptability and flexibility. Python, renowned for its versatility and wealth of built-in frameworks and libraries, was the language of choice for the implementation. To facilitate seamless web-based management, the Django web framework was chosen, which is a robust and widely respected choice in the field [
33]. Security remains a paramount concern, and the platform integrates multiple layers of defense. Django’s default security middleware forms the first line of protection, followed by custom sanitization middleware. This custom middleware diligently scrubs metadata of any special characters and tags, further fortifying the security posture of the platform. The critical middleware components in play are SecurityMiddleware, SessionMiddleware, CsrfViewMiddleware, AuthenticationMiddleware, XFrameOptionsMiddleware, OTPMiddleware, and SessionSecurityMiddleware. In the realm of authentication, Two-Factor Authentication (2FA) was implemented to enhance security. This robust 2FA mechanism is mandatory for logging in and is integrated seamlessly into the user experience. Users have the convenience of utilizing either a token generator or physical keys. Token generators leverage the Time-Based One-Time Pin (TOTP) algorithm [
34], producing 6–8 unique digits based on the current time and a secret key established during account registration. As a security measure, these tokens regenerate every 30 s, thwarting brute force and phishing attacks. Additionally, backup tokens are accessible in case the primary 2FA devices are unavailable, ensuring both recovery and security. The default Django password field was used, which is fortified with PBKDF2 utilizing robust SHA256-bit hashing and a random salt [
33]. Furthermore, email verification is enforced, fostering trust and ensuring the integrity of user accounts.
The process of adding a Cuckoo report to the platform is simplified, as the report undergoes rigorous scrutiny, with essential metadata such as the SHA256 hash, name, and description being extracted and validated. A further layer of scrutiny involves an assessment for any analysis errors before the report is deemed suitable for upload, ensuring the preservation of raw data integrity. For added convenience, the platform seamlessly integrates with Cuckoo Sandbox, enabling users to upload samples directly. These samples are then enqueued for execution within the sandbox environment, and the report is subsequently automatically integrated into the platform. The IntelliView feature represents a unique and innovative approach to manual observation, and was achieved through the implementation of asynchronous calls, with data being clipped to enhance performance and usability.
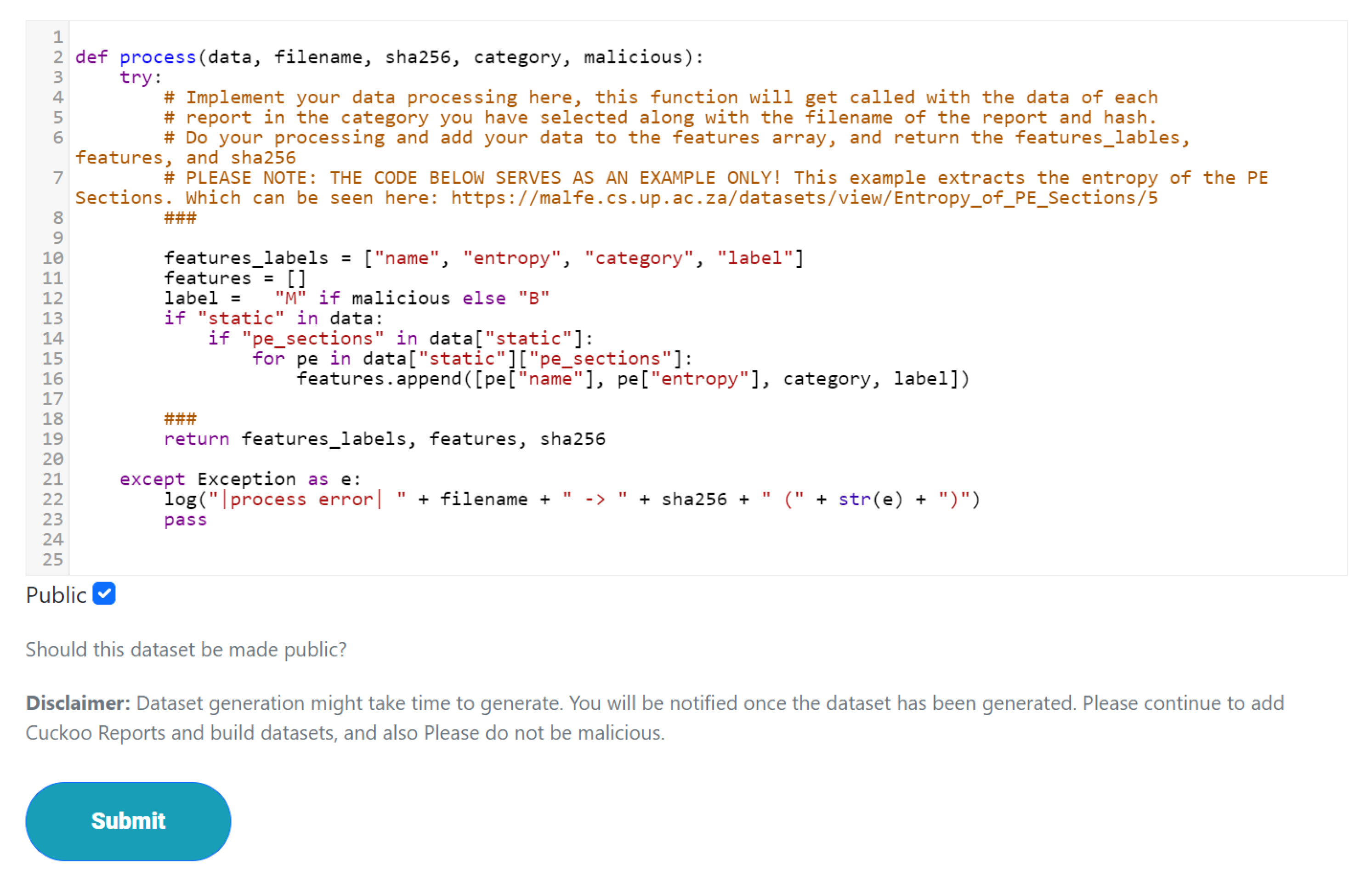
The way datasets are created is a novel feature in which a user provides the code to process an individual report, thereby extracting the data and features needed for building the dataset. A portion of the code responsible for executing user-generated code can be seen in
Figure 3.
This is achieved by users implementing a stub function that is fed the Cuckoo report, filename, SHA256 hash, and category, as well as whether or not it is a malicious sample. Because the platform does not dictate the features, a user can have as many features as they require. Furthermore, because executing user code is a security risk, the code is first checked for syntactical errors using an abstract syntax tree. RestrictedPhyton [
35], which acts as a Python environment with limited imports and functions, is used to execute the user code. Safe built-ins and safe globals are used to ensure additional security and usability. To improve speed, concurrency is utilized with thread pools, allowing faster processing of Cuckoo reports and feature generation. A cron job is used to create the datasets, resulting in a queue system that limits potential resource abuse. Furthermore, each dataset has a maximum execution time.
The next section evaluates the platform with software engineering principles and an adaptation of the NIST Computer Forensics Tool Testing (CFTT) program [
15], then presents a comparative analysis with existing malware analysis research.
5. Using MalFe for Ransomware Detection Using PE Entropy
In this section of the paper, we explore how research is conducted using the MalFe platform. The Portable Execution (PE) header of executable files in the Windows Operating System was explored for ransomware detection. The PE information describes how the OS should execute the file and how to allocate memory. These PE sections, along with their entropies, are available in Cuckoo reports. Because the MalFe platform acts as a repository for Cuckoo reports, this case scenario can be used to demonstrate the platform’s usefulness and ease of use. However, as the platform did not have enough samples, more benign and malicious samples from Cuckoo reports were uploaded from previous experimentation [
5]. The process of uploading a sample to the platform is presented in
Figure 5. Selected metadata are extracted from the selected report, such as the Sample SHA256 hash and Name fields, with the user required to select the category (ransomware) to which the report belongs.
Creating a dataset was effortless, and involved providing a name and description followed by selecting the reports to be used in creating the dataset. In this case, all the benign and ransomware categories were selected, as seen in
Figure 6. Finally, the code was added to parse the raw reports and enqueued in order for the dataset to be generated, as seen in
Figure 7. The dataset generation process took approximately 26 min, spanning 100 + GB worth of data. The dataset consisted of 8599 rows and five columns, with 688 benign and 7911 malicious records sourced from 3084 Cuckoo reports. A snippet of the raw data can be seen in
Table 8. The names map to the type of PE section information extracted from the executable along with the entropy of the data in that section. The category is displayed along with the label, where M stands for malicious and B for benign. The dataset is available on the MalFe platform (created on 12 January 2023) (
https://malfe.cs.up.ac.za/datasets/view/Entropy_of_PE_Sections/5#version1).
The next step is to perform quality control on the dataset and feed it into the machine learning algorithms. For this purpose, the Category and sha256 columns were dropped, leaving only the entropy of the sections for classification. Any null values were dropped as well, and manual checks were conducted. Tree classifiers such as Decision Tree (DT) and Random Forrest (RF) were chosen based on their ability to easily build logic paths that are human-readable and show better accuracy predictions related to computer security [
5,
27,
41]. Boosted classifiers were explored as well, such as XGBoost (XGB), to determine the effects of boosted learning. Probabilistic classifiers such as Naïve Bayes (NB) were explored to check whether patterns in the name of the entropy section could provide good accuracy. Finally, clustering classifiers were explored using the K-nearest Neighbors (KNN) and Support Vector Machine (SVM) approaches. DT follows a rule-based approach, drawing patterns to build a tree structure from the data representing the outcomes. RF works similarly to DT, building multiple trees in a single model to better map hierarchical patterns. SVM is designed for working with small amounts of data and finding associations between the data points using hyperplanes. XGB, on the other hand, is a form of boosted learning combined with a DT that evaluates multiple trees over several iterations until the best solution is found. Finally, NB draws correlations between individual features rather than introducing the relation with each feature as a whole. In order to remove any bias induced by the dataset, ten-fold cross-validation was performed when the models were trained. Furthermore, hyperparameter tuning was employed to determine the best parameters for each model; these parameters are shown in
Table 9. For example, the criterion for DT model refers to the quality measure of how the data are split. The Gini impurity is a measure of how often a randomly chosen element is incorrectly classified. In the context of decision trees, the entropy measures the information gain achieved by a split, quantifying the disorder or randomness in a dataset. Using the log_loss, the classifications are based on probability. The criterion parameter is used to determine which approaches mentioned above better suit the data at hand. For the splitter parameter, the best value uses the criterion to determine the best split, whereas the random value prevents overfitting. These parameters were used in all possible combinations in order to determine the parameters that yielded the best result. With RF, the number of estimators determines how many individual trees to construct and the max depth determines how many nodes the tree will have. Similarly, with KNN the number of neighbours is used to cluster datapoints together, and the distances between the clusters act as the weights. Lastly, with XGB, the type of boosting algorithm and the learning rate can be tuned to determine which configuration reveals the best result.
The results of the machine learning phase are further presented in
Table 10. The precision measures the ratio of true positives and total positives predicted, where the goal is to reach a precision of 1. The recall is the ratio of true positives to all positives. The F-measure is the mean of the precision and recall. This is arguably the most important factor in determining a model’s validity and accuracy. The sensitivity, on the other hand, measures the ability to detect positive instances whereas specificity measures the true negatives. Because there were only two features in this dataset, it would not have been feasible to explore SVM, as this algorithm works better with a larger number of features and fewer records. However, a brief test was conducted to measure the performance; with ten-fold cross-validation, SVM with a linear kernel did not finish training, and was terminated after running for two days. SVM had poor results when no cross-validation was performed, with an accuracy of only 68% even after a significant training and prediction time. In comparison, the other models’ training times were within the range of 9 s to 2 min.
All the models (DT, RF, KNN, XGB, NB) presented in
Table 10 achieved high levels of True Positives (TP) and True Negatives (TN), indicating their effectiveness in correctly classifying both positive and negative instances. The recall values for all models are generally high, suggesting that the models can identify a significant portion of the actual positive cases. The precision values are consistent with the accuracy, indicating that the models make relatively few false positive predictions. Log-loss values vary among the models, with the RF model achieving the lowest log-loss, indicating better probabilistic predictions. The AUC values are generally high for all models, particularly for XGB and RF, indicating strong discriminative capability. The F-measure values are high as well, indicating a balance between precision and recall.
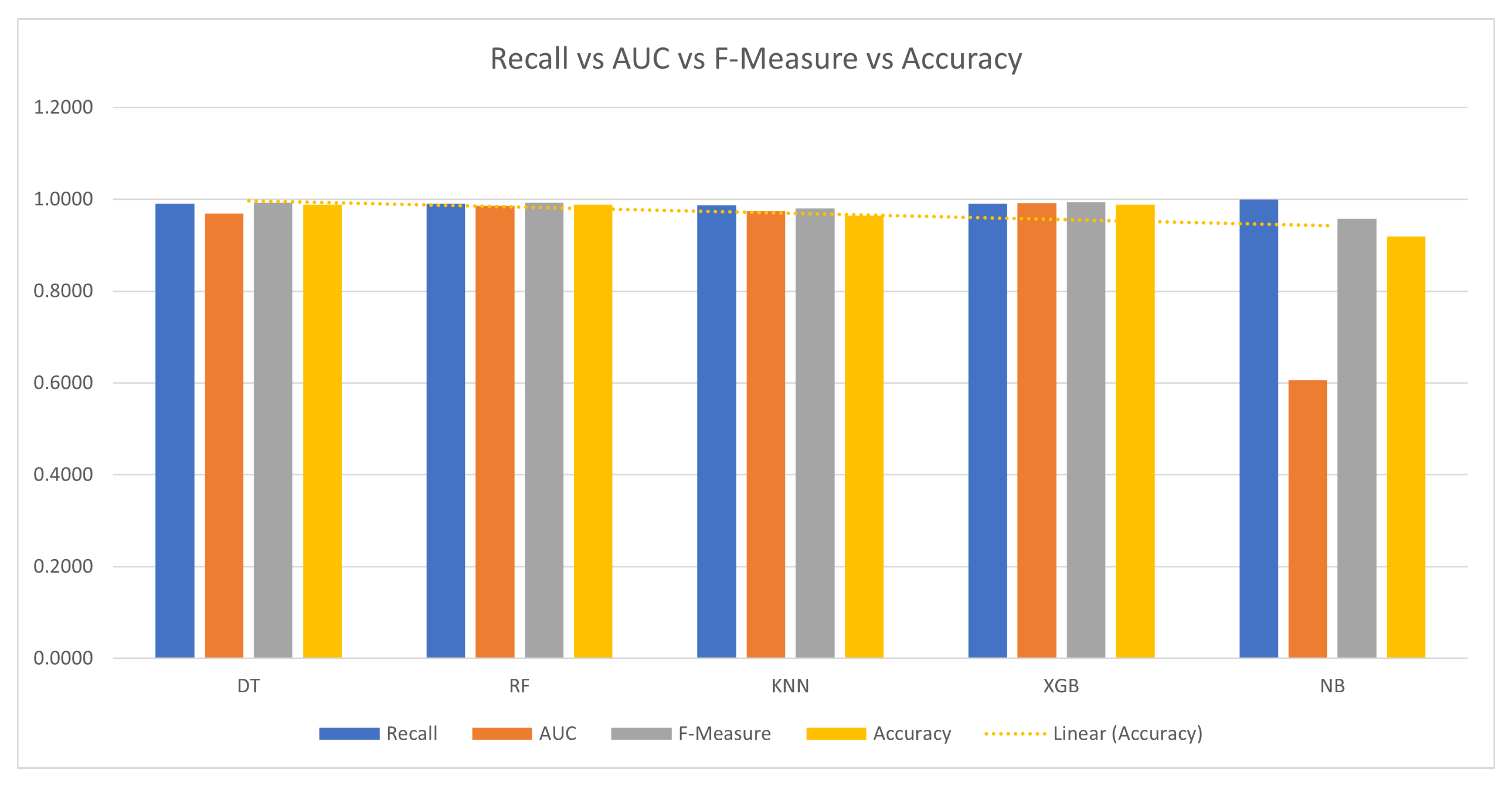
Figure 8 shows the recall vs. the area under the curve vs. the F-measure vs. the accuracy, where NB performs the poorest among all the models. In
Figure 9, the latency varies among the models, with KNN having the highest latency and NB having the lowest. A comparison between the obtained results and those of existing related works is shown in
Table 11. From the comparison, the proposed PE entropy provides a good accuracy score, making it the second best among all the explored results from the literature. However, the work by Poudyal and Dasgupta [
29] only explored 1090 samples, which could have introduced a bias in prediction. Furthermore, the use of multiple classifiers for detection presents a complexity challenge that would void the potential of pre-emptive detection and ransomware prevention. For instance, the NotPetya ransomware would have overtaken a system within the time required to compute and identify the ransomware using multiple classifiers. Preemptive detection relies on timely detection using salient attributes. This logic requires a knowledge base signature which is not achievable using multiple classifiers. In this regard, the results obtained in the current study can be readily deployed both for early detection and as a proactive preventive mechanism.
The Receiver Operating Characteristic (ROC) curve presents a true evaluation of a machine learning algorithm model which graphs the prediction confidence of the model. The confidence is a true reflection of the model’s ability to distinguish the classes in a given feature space. The ROC curve for the machine learning algorithms is shown in
Figure 10. The goal is to obtain a full right-angle curve (area under the curve = 1), which RF, XGB, and KNN are almost able to achieve. NB is able to predict extremely fast, with a 1 ms response time; however, the number of false negatives is fairly high in comparison to the other models. This means that although it is fast, it is not very confident in its predictions, as can be seen in
Figure 10 and
Table 10, with an AUC of 0.6, which is extremely poor. Because DT, RF, and XGB performed fairly similarly, with 98.8% accuracy, a validation test consisting of 1555 malicious and 138 benign unseen records was fed into the trained model to benchmark them against each other. The results of this benchmark resulted in 0.9829, 0.9858, and 0.9829 respectively. This leaves the overall best model with the highest accuracy as Random Forest; however, as speed is more crucial in the domain of ransomware detection, the most suitable and accurate model for ransomware detection in this case is a Decision Tree.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}