


Cognitive Impairment and Dementia Data Model: Quality Evaluation and Improvements



Abstract
:1. Introduction
- Provides semantics of the data in a human-readable format and accelerates the interoperability of clinical datasets;
- Suitable for use as a stand-alone data model for clinical data as well as a middleware for mapping between different data models;
- Provides a foundation for implementing data schemas across different types of databases and further system development;
- Enables the application of Machine Learning (ML) and AI algorithms and models by helping data scientists to understand the data and select appropriate features.
2. Background
3. Materials and Methods
3.1. Procedure
3.2. Completeness
- Type 1 error—items that do not correspond to user requirements;
- Type 2 error—user requirements that are not represented in the data model;
- Type 3 error—items that correspond to user requirements but are inaccurately defined.
3.3. Integrity
3.4. Correctness
3.5. Simplicity
3.6. Flexibility
3.7. Understandability
4. Evaluation of the Original Model
4.1. Completeness
4.2. Simplicity
4.3. Correctness
4.4. Integrity
5. Results and Discussion
5.1. Simplicity and Integrity
5.2. Understandability
5.3. Flexibility
6. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Completeness Evaluation

{kind=link}
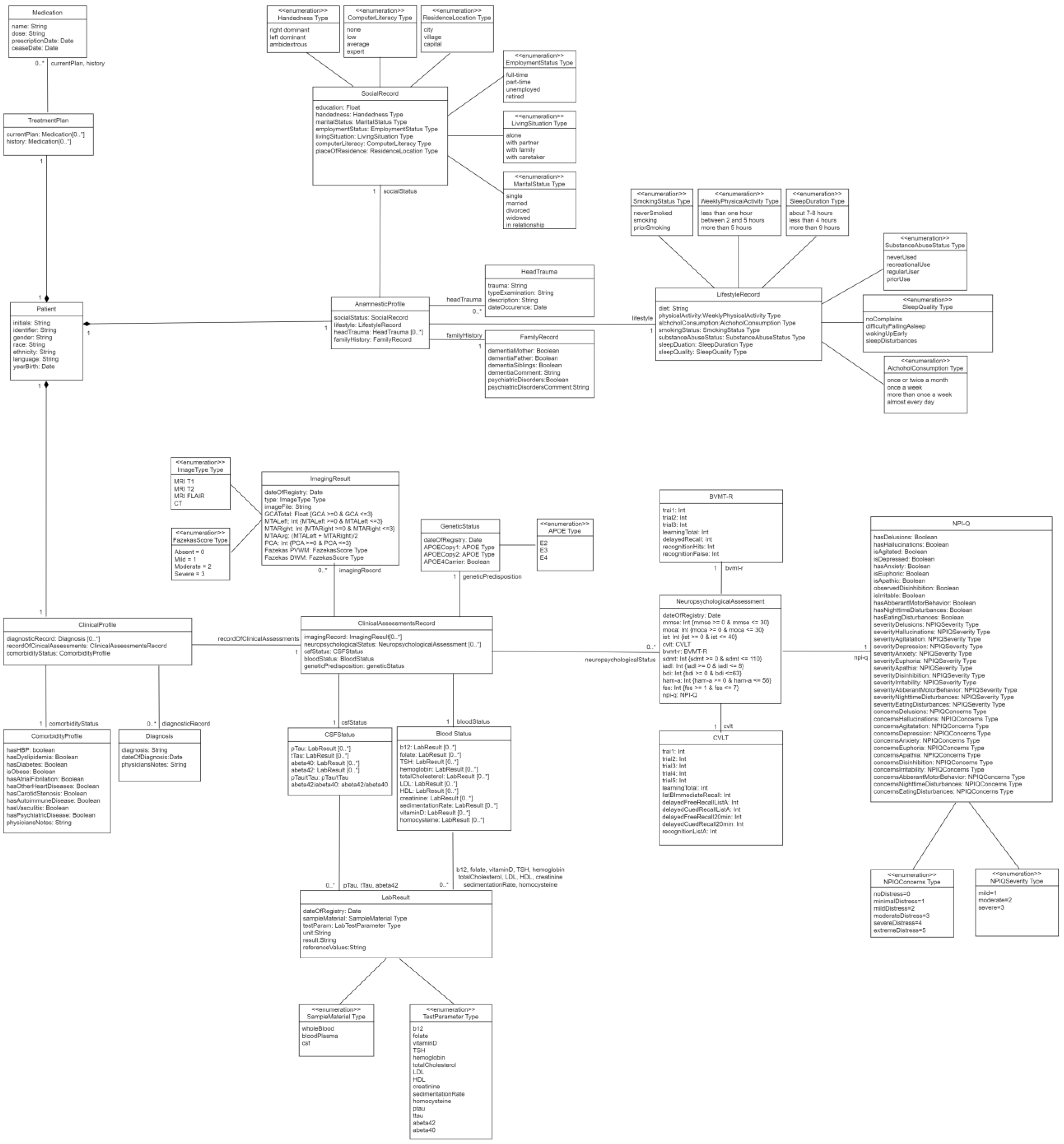{kind=link}
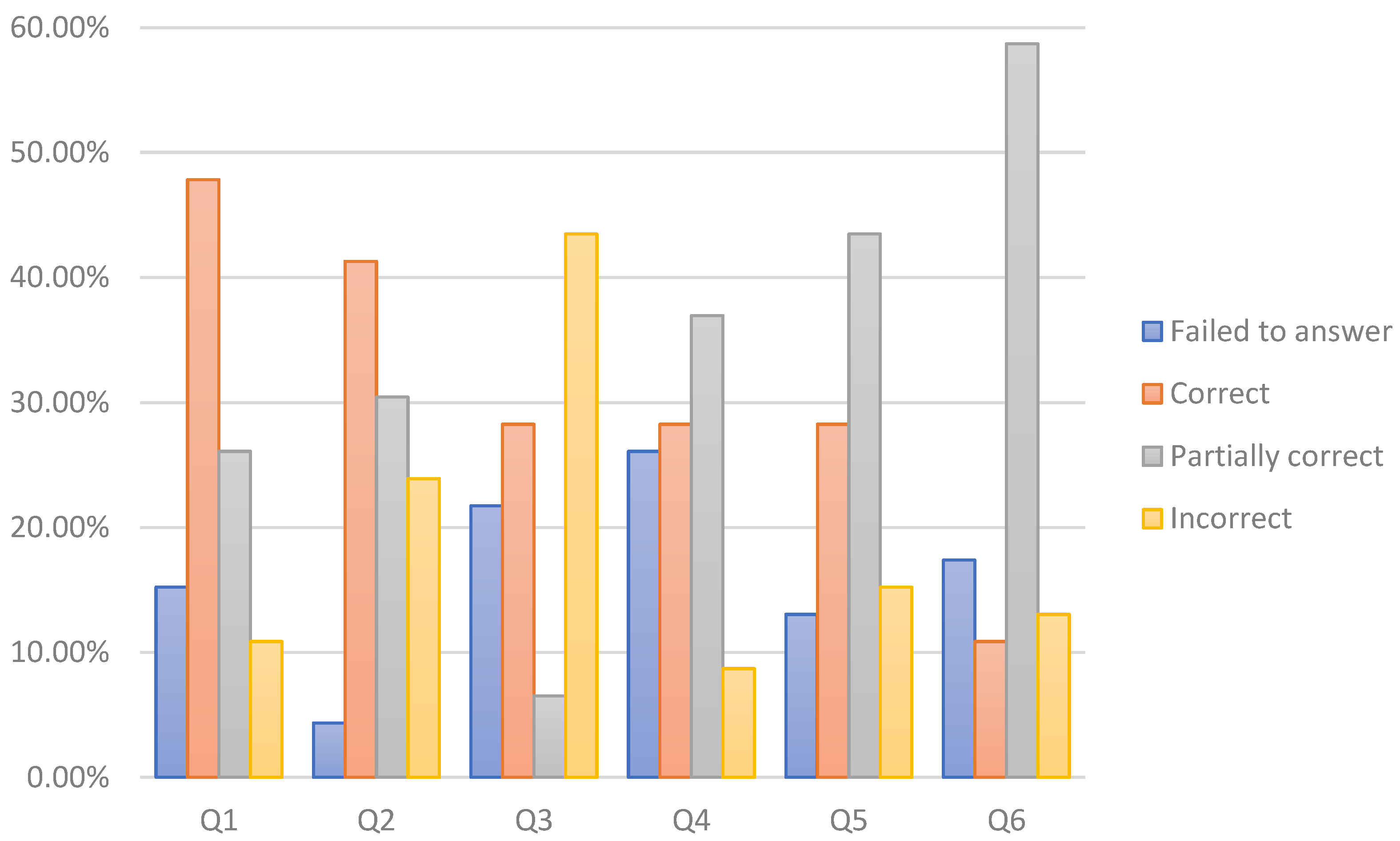{kind=link}
| Requirement | Is Satisfied | Error Type | Type 1 Errors |
|---|---|---|---|
| Yes | - | Financial state listed in anamnestic data |
| Yes | - | Blood test contains clinician name |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| No | Type 2 | |
| Yes | - | |
| Yes | - | |
| Partially | Type 3 | |
| No | Type 2 | |
| No | Type 2 | |
| Yes | - | |
| Yes | - | |
| No | Type 2 | |
| No | Type 2 | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Partially | Type 3 | |
| Partially | Type 3 | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Partially | Type 3 | |
| Partially | Type 3 | |
| Partially | Type 3 | |
| Partially | Type 3 | |
| Partially | Type 3 | |
| No | Type 2 | |
| Partially | Type 3 | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Partially | Type 3 | |
| Partially | Type 3 | |
| Partially | Type 3 | |
| No | Type 2 | |
| Partially | Type 3 | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - | |
| Yes | - |
Appendix A.2. Questionnaires Used for the Evaluation of ‘Understanding’
Appendix A.2.1. Participant Profile and Background
| Question | Answer Options |
|---|---|
| What is the highest degree that you have completed? |
|
| What is the field of your studies? | Free text |
| How familiar are you with UML diagramming? |
|
| How familiar are you with common medical concepts such as anamnesis, brain imaging, comorbidity, medical history, etc.? | 1 (not at all)—5 (very familiar) |
| How familiar are you with cognitive diseas-es? | 1 (not at all)—5 (very familiar) |
Appendix A.2.2. Cloze Test
Appendix A.2.3. Problem-Solving Task
| Question | Base Answer |
|---|---|
| Q1: A healthy elderly patient goes for a regular check but expresses concerns about his/her mental health and memory. Discussing their current condition requires information about their physical and psychological state over the last year. Provided that the physician is using a system that implements the data model, is it possible to retrieve results from neuropsychological assessments that were conducted over the last year? Why? | Yes, it is possible. The data model supports storage of longitudinal data. |
| Q2: John wants to investigate whether depression can predict future onset of dementia. John has access to a system that is implementing the data model and has thousands of records. Is such a system useful to John in terms of finding appropriate data? Motivate your answer. | Yes, it it. The data model contains longitudinal data about the neuropsychological state of a patient as well as a record of diagnoses. |
| Q3: George is a researcher who is investigating the metabolic brain changes in dementia patients compared to cognitively healthy adults. For this purpose, John needs readings from positron emission tomography images (PET imaging) of brain metabolism. Can such information be stored in a system implementing the data model? Motivate your answer. | No. The provided data model allows the storage of four types of images—MRI T1, MRI T2, MRI Flair, CT. |
| Q4: John is interested in the interaction between genetic predisposition and lifestyle factors in determining the risk of developing Alzheimer’s disease. In particular, he wants to investigate whether individuals who have healthy lifestyle habits, family history of Alzheimer’s disease and confirmed genetic predisposition are at same risk as equally genetically burdened individuals with unhealthy lifestyle. Can John find all of the data he needs in a system implementing the CogniTwin data model? | Yes. The data model stores lifestyle data (diet, sport, etc.) as well as data about the predisposition to Alzheimer’s disease in terms of family history and confirmed by laboratory test genetic predisposition. |
| Q5: We want to extend the model to include results from measuring glucose levels in whole blood samples. Which entities do we need to change and how? |
|
| Q6: How would we change the model if we want to be able to store results from measuring glucose levels, protein levels and red blood cell count in urine samples? |
|
References
- Hugo, J.; Ganguli, M. Dementia and Cognitive Impairment. Clin. Geriatr. Med. 2014, 30, 421–442. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- World Health Organization (WHO). Dementia Factsheet. Available online: https://www.who.int/news-room/fact-sheets/detail/dementia (accessed on 4 November 2022).
- Qiu, C.; Fratiglioni, L. Aging without Dementia is Achievable: Current Evidence from Epidemiological Research. J. Alzheimers Dis. 2018, 62, 933–942. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- World Health Organization. Global Action Plan on the Public Health Response to Dementia 2017–2025; World Health Organization: Geneva, Switzerland, 2017; Available online: https://apps.who.int/iris/handle/10665/259615 (accessed on 15 November 2022).
- World Health Organization. Global Status Report on the Public Health Response to Dementia; World Health Organization: Geneva, Switzerland, 2021; Available online: https://apps.who.int/iris/handle/10665/344701 (accessed on 15 November 2022).
- World Health Organization. Towards a Dementia Plan: A WHO Guide; World Health Organization: Geneva, Switzerland, 2018; Available online: https://apps.who.int/iris/handle/10665/272642 (accessed on 15 November 2022).
- Ashish, N.; Bhatt, P.; Toga, A.W. Global Data Sharing in Alzheimer Disease Research. Alzheimer Dis. Assoc. Disord. 2016, 30, 160–168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Petrova-Antonova, D.; Kunchev, T.; Manova, I.; Spasov, I. Cognitive Impairment and Dementia Data Modelling. In Proceedings of the Computational Science and Its Applications—ICCSA 2022, Malaga, Spain, 4–7 July 2022; Gervasi, O., Murgante, B., Hendrix, E., Taniar, D., Apduhan, B.O., Eds.; Springer International Publishing: Cham, Switzerland, 2022; Volume 13376, pp. 58–71. [Google Scholar] [CrossRef]
- Moody, D.L.; Shanks, G.G. What makes a good data model? Evaluating the quality of entity relationship models. In Proceedings of the Entity-Relationship Approach—ER ’94 Business Modelling and Re-Engineering, Manchester, UK, 13–16 December 1994; Loucopoulos, P., Ed.; Springer: Berlin/Heidelberg, Germany, 1994; Volume 881, pp. 94–111. [Google Scholar] [CrossRef]
- Moody, D.L. Theoretical and practical issues in evaluating the quality of conceptual models: Current state and future directions. Data Knowl. Eng. 2005, 55, 243–276. [Google Scholar] [CrossRef]
- Object Management Group, OMG. Unified Modeling Language, Specification. Object Management Group, December 2017. Available online: https://www.omg.org/spec/UML/2.5.1/PDF (accessed on 4 November 2022).
- Oren, B.-K.; Clark, E. Ingy döt Net. YAML Ain’t Markup Language, 3rd ed.; 2009; Available online: https://yaml.org/spec/1.2/spec.html#id2763754 (accessed on 25 January 2022).
- Levitin, A.; Redman, T. Quality dimensions of a conceptual view. Inf. Process. Manag. 1995, 31, 81–88. [Google Scholar] [CrossRef]
- Lindland, O.I.; Sindre, G.; Solvberg, A. Understanding quality in conceptual modeling. IEEE Softw. 1994, 11, 42–49. [Google Scholar] [CrossRef]
- Krogstie, J.; Lindland, O.; Sindre, G. Towards a deeper understanding of quality in requirements engineering. In Active Flow and Combustion Control 2018; King, R., Ed.; Springer International Publishing: Cham, Switzerland, 1995; Volume 141, pp. 82–95. [Google Scholar] [CrossRef]
- Moody, D.L.; Shanks, G.G. Improving the quality of data models: Empirical validation of a quality management framework. Inf. Syst. 1998, 28, 619–650. [Google Scholar] [CrossRef]
- Moody, D.L.; Shanks, G.; Darke, P. Improving the Quality of Entity Relationship Models—Experience in Research and Practice. In Proceedings of the Conceptual Modeling—ER ’98, Singapore, 16–19 November 1998; Ling, T.-W., Ram, S., Lee, M.L., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1507, pp. 255–276. [Google Scholar] [CrossRef]
- Moody, D.L. Metrics for Evaluating the Quality of Entity Relationship Models. In Proceedings of the Conceptual Modeling—ER ’98, Singapore, 16–19 November 1998; Ling, T.-W., Ram, S., Lee, M.L., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1507, pp. 211–225. [Google Scholar] [CrossRef]
- Gosain, A.; Heena. Literature Review of Data Model Quality Metrics of Data Warehouse. Procedia Comput. Sci. 2015, 48, 236–243. [Google Scholar] [CrossRef] [Green Version]
- Savile, D.B.O. Communication problems in interdisciplinary research. Proc. Indian Acad. Sci. 1984, 93, 223–230. [Google Scholar] [CrossRef]
- Motro, A. Integrity = validity + completeness. ACM Trans. Database Syst. 1989, 14, 480–502. [Google Scholar] [CrossRef]
- Chren, S.; Buhnova, B.; Macak, M.; Daubner, L.; Rossi, B. Mistakes in UML Diagrams: Analysis of Student Projects in a Software Engineering Course. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering Education and Training (ICSE-SEET), Montreal, QC, Canada, 25–31 May 2019; pp. 100–109. [Google Scholar] [CrossRef]
- Sien, V.Y. An investigation of difficulties experienced by students developing unified modelling language (UML) class and sequence diagrams. Comput. Sci. Educ. 2011, 21, 317–342. [Google Scholar] [CrossRef]
- Thijssen, E.H.; La Joie, R.; Wolf, A.; Strom, A.; Wang, P.; Iaccarino, L.; Bourakova, V.; Cobigo, Y.; Heuer, H.; Spina, S.; et al. Diagnostic value of plasma phosphorylated tau181 in Alzheimer’s disease and frontotemporal lobar degeneration. Nat. Med. 2020, 26, 387–397. [Google Scholar] [CrossRef] [PubMed]
- Shen, X.-N.; Huang, Y.-Y.; Chen, S.-D.; Guo, Y.; Tan, L.; Dong, Q.; Yu, J.-T. Plasma phosphorylated-tau181 as a predictive biomarker for Alzheimer’s amyloid, tau and FDG PET status. Transl. Psychiatry 2021, 11, 585. [Google Scholar] [CrossRef] [PubMed]
- Tissot, C.; Benedet, A.L.; Therriault, J.; Pascoal, T.A.; Lussier, F.Z.; Saha-Chaudhuri, P.; Chamoun, M.; Savard, M.; Mathotaarachchi, S.S.; Bezgin, G.; et al. Plasma pTau181 predicts cortical brain atrophy in aging and Alzheimer’s disease. Alzheimers Res. Ther. 2021, 13, 69. [Google Scholar] [CrossRef] [PubMed]
- Fossati, S.; Cejudo, J.R.; Debure, L.; Pirraglia, E.; Sone, J.Y.; Li, Y.; Chen, J.; Butler, T.; Zetterberg, H.; Blennow, K.; et al. Plasma tau complements CSF tau and P-tau in the diagnosis of Alzheimer’s disease. Alzheimers Dement. Diagn. Assess. Dis. Monit. 2019, 11, 483–492. [Google Scholar] [CrossRef] [PubMed]
- Park, S.A.; Jang, Y.; Kim, M.; Lee, S.; Moon, S.Y. Promising Blood Biomarkers for Clinical Use in Alzheimer’s Disease: A Focused Update. J. Clin. Neurol. 2022, 18, 401. [Google Scholar] [CrossRef] [PubMed]



| Type I Errors | Type II Errors | Type III Errors | Correctly Implemented | Total Requirements |
|---|---|---|---|---|
| 2 | 7 | 13 | 37 | 57 |
| Major Violations | Minor Violations | Redundancies |
|---|---|---|
| Using association where composition is needed. Example: Treatment is part of Patient and should exist as long as Patient exists. Currently this relationship is not represented in the diagram. | Violation of naming convention I Incorrect naming of classes (upper camel case) and attributes (lower camel case); | Genetic testing is essentially a blood test. It does not have to be a separate entity. |
| Incorrect multiplicities Example: Every Patient should have a single Medical History record. Currently a Patient can have any number of Medical History instances. | Violation of naming convention II Classes cannot be named with adjectives: example—class Clinical. | Entity ‘Clinical’ fails to act as a proper superclass and therefore it is redundant. |
| Enumerations not properly defined Enumerations should be defined as separate entities with their possible values described. Whenever an entity has an attribute of type Enum, there should be also a relation between the corresponding enumeration and entity. | Typos Example: Habbit instead of Habit; Rase instead of Race | NPI items (11 items) defined as entities when they would be better defined as attributes. |
| Missing attribute constraints Attributes should have constraints describing the possible ranges of the attribute values. | Types of comorbidities (10 comorbidities) defined as entities when they would be better defined as attributes. | |
| Incorrect representation of nested entities. Missing definitions for some nested entities. All entities nested in Comorbidities and Habit. Nested entities should also be depicted as fully expanded entities that are related with the entity owner. | Habit entity has six nested classes that would be better defined as attributes. |
| Model Version | Number of Entities | Number of Relationships | E + R |
|---|---|---|---|
| Original model | 45 | 18 (45 actual) | 63 (90 actual) |
| Improved model | 21 | 21 | 42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petrova-Antonova, D.; Lazarova, S. Cognitive Impairment and Dementia Data Model: Quality Evaluation and Improvements. Computers 2023, 12, 29. https://doi.org/10.3390/computers12020029
Petrova-Antonova D, Lazarova S. Cognitive Impairment and Dementia Data Model: Quality Evaluation and Improvements. Computers. 2023; 12(2):29. https://doi.org/10.3390/computers12020029
Chicago/Turabian StylePetrova-Antonova, Dessislava, and Sophia Lazarova. 2023. "Cognitive Impairment and Dementia Data Model: Quality Evaluation and Improvements" Computers 12, no. 2: 29. https://doi.org/10.3390/computers12020029
APA StylePetrova-Antonova, D., & Lazarova, S. (2023). Cognitive Impairment and Dementia Data Model: Quality Evaluation and Improvements. Computers, 12(2), 29. https://doi.org/10.3390/computers12020029