
A Temporal Transformer-Based Fusion Framework for Morphological Arrhythmia Classification



Abstract
:1. Introduction
- Developing a temporal transformer-based fusion framework to classify morphological arrhythmia into several multiple classes for lowering the fatality rate associated with CVDs.
- The CNN structure is followed by a transformer encoder network for the interpretation of ECG signals. The Transformer’s integration makes up for CNN’s inadequacies in terms of its inability to function well with temporal features.
- Additionally, recurrence is combined with the network through Bi-LSTM layers that identify the invariant relationship among neighboring time steps.
- A wide range of experiments including ablation, parameter selection, and other evaluation methods have been performed which deduced the proposed model’s superiority to produce cutting-edge results on the dataset.
2. Related Work
3. Materials and Methodology
3.1. Database Description
3.2. Signal Preprocessing
3.2.1. Denoising
3.2.2. Heartbeat Segmentation through QRS Complex Detection
3.2.3. Data Resampling
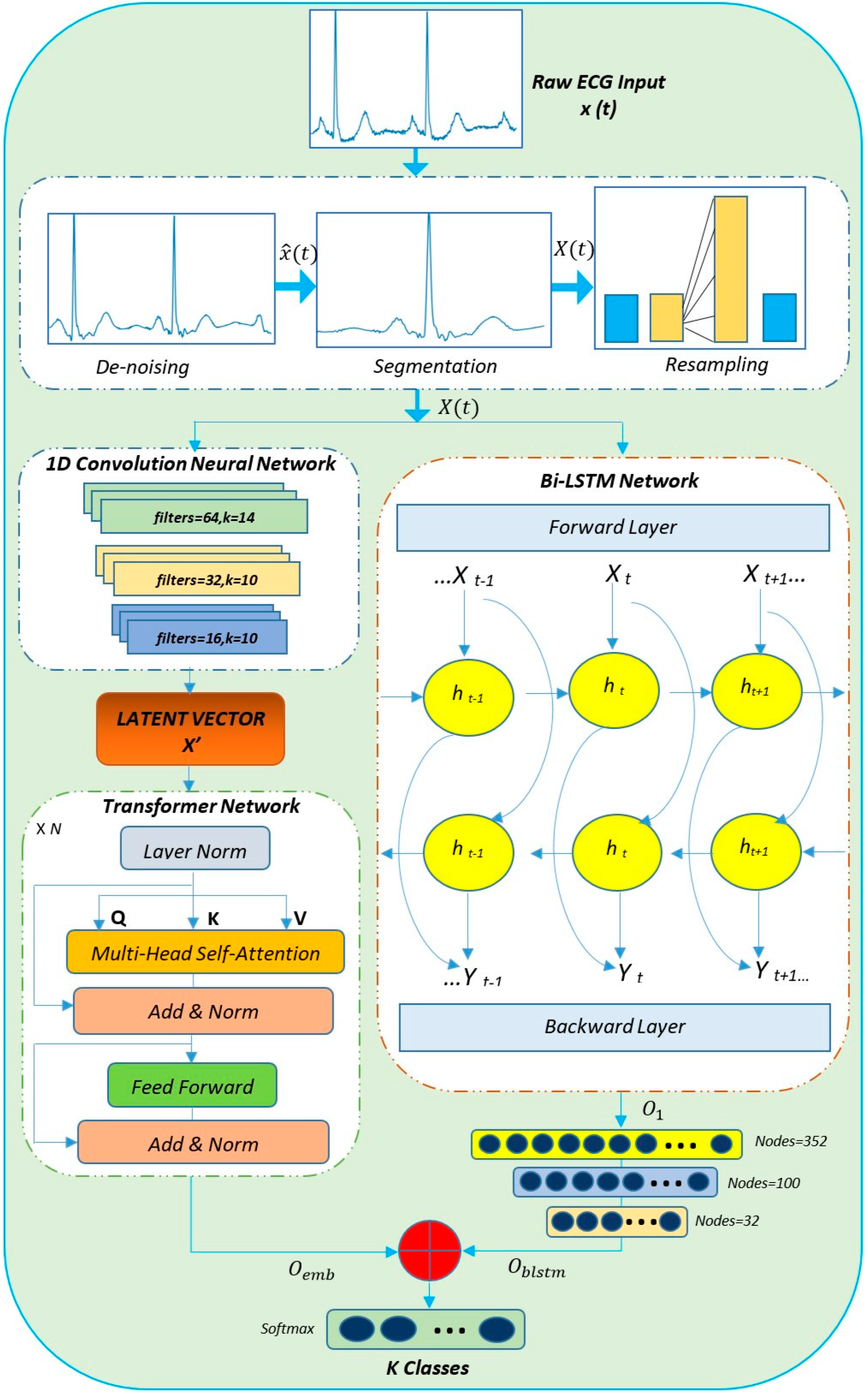
3.3. Transformer-Based Fusion Framework
- (a)
- CNN Network
- (b)
- Transformer Network
- Self-Attention Module: The scaled-dot product attention or self-attention function’s inputs, Q, K, and V, stand for the respective concepts of query, key, and value. The attention weight is determined by how similar the query key is. The attention context is determined based on the attention weight. The scaled dot-product attention used by the model can be calculated as follows:Here Q, K, and V represent the query, key, and value embedding matrices. Queries Q Є , keys K Є , values V Є . Here, N and M represent the length of queries and keys (or values). and represent the dimensions of keys (or queries) and values respectively. The input consists of queries and keys of dimension and values of dimension . The dot products of the query with all the keys are calculated using which is scaled by a factor of . The softmax of this is then multiplied by the values in V.
- Multi-Head Self Attention: The attention technique employed in this work is called scaled dot-product attention, which is a type of self-attention that implies self-learning. The query and key-value pairs are from the same source as evident in the data. Despite the usage of attention mechanisms, it might not be possible to fully explain all the dependencies with only a single attention function. Various self-attention functions are combined. Each function is called a ‘head’ and their combination facilitates simultaneous attention to information from multiple representation subspaces. The formula is expressed as follows:The multi-head attention mechanism integrates the results of the several attentions by projecting Q, K, and V through n linear transformations. Here several self-attention heads such as , run in parallel and each of the smaller dimension vectors is concatenated and projected to a higher dimension. This parallelization computation capability improves the network’s performance in integrating multiple features. The parameters for the transformer encoder stack have been included in Table 3. Here the embedded Q, K, and V vectors have a size of 256 and are processed using four transformer encoder blocks having eight heads each. The ratio of dropout is set at 0.15 for regularization.
- Feed Forward Network: The last stage of the encoder architecture is a straightforward feed-forward network with 1012 multilayer perceptron units, as illustrated in Table 3. Two one-dimensional convolution layers with activation as ReLU and kernel size 1 are used in between as projection layers to reduce dimensionality in this part of the network.Here, FFN(x) is the linear transformations in the network with weight matrices , and biases , which is then followed by layer normalization. Finally, the transformer network output : { ,…,} is obtained which is a learned vector of each feature.
- (c)
- Bi-LSTM Network
- (d)
- Final Classification
4. Experiments and Result Analysis
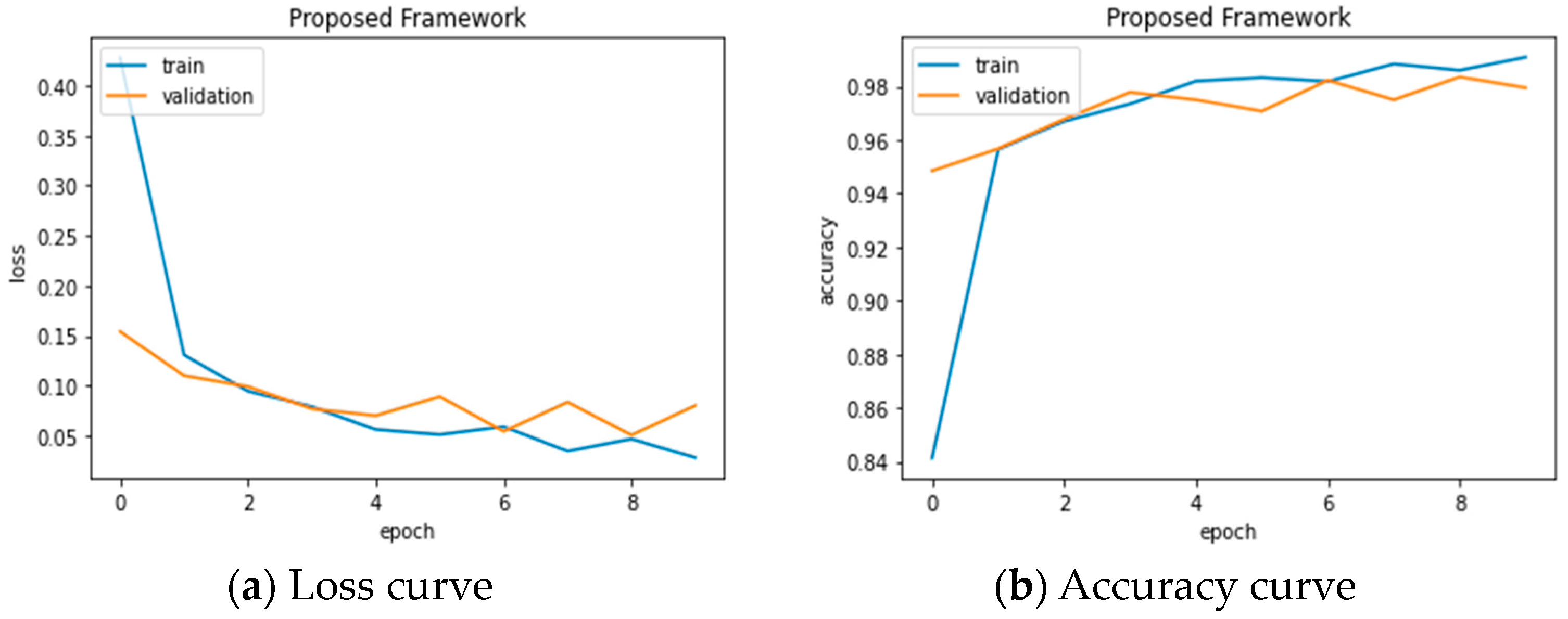
4.1. Quantitative Analysis
4.2. Qualitative Analysis
4.3. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Available online: https://www.who.int/health-topics/cardiovascular-diseases (accessed on 23 October 2022).
- Mayo Clinic. Diseases and Conditions. Available online: https://www.mayoclinic.org/diseases-conditions/heart-arrhythmia/symptoms-causes/syc-20350668 (accessed on 23 October 2022).
- Elgendi, M. Fast Qrs Detection with an Optimized Knowledge-Based Method: Evaluation on 11 Standard Ecg Databases. PLoS ONE 2013, 8, e73557. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Attia, Z.I.; Noseworthy, P.A.; Lopez-Jimenez, F.; Asirvatham, S.J.; Deshmukh, A.J.; Gersh, B.J.; Carter, R.E.; Yao, X.; Rabinstein, A.A.; Erickson, B.J.; et al. An Artificial Intelligence-Enabled Ecg Algorithm for the Identification of Patients with Atrial Fibrillation During Sinus Rhythm: A Retrospective Analysis of Outcome Prediction. Lancet 2019, 394, 861–867. [Google Scholar] [CrossRef] [PubMed]
- Hannun, A.Y.; Rajpurkar, P.; Haghpanahi, M.; Tison, G.H.; Bourn, C.; Turakhia, M.P.; Ng, A.Y. Cardiologist-Level Arrhythmia Detection and Classification in Ambulatory Electrocardiograms Using a Deep Neural Network. Nat. Med. 2019, 25, 65–69. [Google Scholar] [CrossRef] [PubMed]
- Perez, M.V.; Mahaffey, K.W.; Hedlin, H.; Rumsfeld, J.S.; Garcia, A.; Ferris, T.; Balasubramanian, V.; Russo, A.M.; Rajmane, A.; Cheung, L.; et al. Large-Scale Assessment of a Smartwatch to Identify Atrial Fibrillation. N. Engl. J. Med. 2019, 381, 1909–1917. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (Nips 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 1–11. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring Self-Attention for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Virtual, 13–19 June 2020. [Google Scholar]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- Qin, Y.; Song, D.; Chen, H.; Cheng, W.; Jiang, G.; Cottrell, G. A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction. arXiv 2017, arXiv:1704.02971. [Google Scholar]
- Ashley, E.; Niebauer, J. Chapter 3: Conquering the Ecg. In Cardiology Explained; Remedica: London, UK, 2004. [Google Scholar]
- Jiang, J.; Zhang, H.; Pi, D.; Dai, C. A Novel Multi-Module Neural Network System for Imbalanced Heartbeats Classification. Expert Syst. Appl. X 2019, 1, 100003. [Google Scholar] [CrossRef]
- Shoughi, A.; Dowlatshahi, M.B. A Practical System Based on Cnn-Blstm Network for Accurate Classification of Ecg Heartbeats of Mit-Bih Imbalanced Dataset. In Proceedings of the 2021 26th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 3–4 March 2021. [Google Scholar]
- Fang, H.; Lu, C.; Hong, F.; Jiang, W.; Wang, T. Convolutional Neural Network for Heartbeat Classification. In Proceedings of the 2021 IEEE 15th International Conference on Electronic Measurement & Instruments (ICEMI), Nanjing, China, 29–31 October 2021. [Google Scholar]
- Mittal, S.S.; Rothberg, J.; Ghose, K. Deep Learning for Morphological Arrhythmia Classification in Encoded Ecg Signal. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, CA, USA, 13–16 December 2021. [Google Scholar]
- Shaker, A.M.; Tantawi, M.; Shedeed, H.A.; Tolba, M.F. Generalization of Convolutional Neural Networks for Ecg Classification Using Generative Adversarial Networks. IEEE Access 2020, 8, 35592–35605. [Google Scholar] [CrossRef]
- Bertsimas, D.; Mingardi, L.; Stellato, B. Machine Learning for Real-Time Heart Disease Prediction. IEEE J. Biomed. Health Inform. 2021, 25, 3627–3637. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J. ChapmanECG. 2019. Available online: https://figshare.com/collections/ChapmanECG/4560497/1 (accessed on 3 October 2022).
- Tianchi Hefei High-Tech Cup Ecg Human-Machine Intelligence Competition. 2019. Available online: https://tianchi-competition.oss-cnhangzhou.aliyuncs.com/231754/round2/hf_round2_train.zip (accessed on 3 October 2022).
- Clifford, G.D.; Liu, C.; Moody, B.; Li-wei, H.L.; Silva, I.; Li, Q.; Johnson, A.E.; Mark, R.G. AF Classification from a Short Single Lead Ecg Recording: The Physionet/Computing in Cardiology Challenge 2017. In Proceedings of the 2017 Computing in Cardiology (CinC), Rennes, France, 24–27 September 2017. [Google Scholar]
- Ahmad, Z.; Tabassum, A.; Guan, L.; Khan, N.M. Ecg Heartbeat Classification Using Multimodal Fusion. IEEE Access 2021, 9, 100615–100626. [Google Scholar] [CrossRef]
- Prakash, V.J.; Karthikeyan, N.K. Dual-layer deep ensemble techniques for classifying heart disease. Inf. Technol. Control. 2022, 51, 158–179. [Google Scholar] [CrossRef]
- Ullah, H.; Heyat, M.B.; Akhtar, F.; Muaad, A.Y.; Ukwuoma, C.C.; Bilal, M.; Miraz, M.H.; Bhuiyan, M.A.; Wu, K.; Damaševičius, R.; et al. An Automatic Premature Ventricular Contraction Recognition System Based on Imbalanced Dataset and Pre-Trained Residual Network Using Transfer Learning on ECG Signal. Diagnostics 2022, 13, 87. [Google Scholar] [CrossRef] [PubMed]
- Guan, J.; Wang, W.; Feng, P.; Wang, X.; Wang, W. Low-Dimensional Denoising Embedding Transformer for Ecg Classification. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Natarajan, A.; Chang, Y.; Mariani, S.; Rahman, A.; Boverman, G.; Vij, S.; Rubin, J. A Wide and Deep Transformer Neural Network for 12-Lead Ecg Classification. In Proceedings of the 2020 Computing in Cardiology, Rimini, Italy, 13–16 September 2020. [Google Scholar]
- Che, C.; Zhang, P.; Zhu, M.; Qu, Y.; Jin, B. Constrained Transformer Network for Ecg Signal Processing and Arrhythmia Classification. BMC Med. Inform. Decis. Mak. 2021, 21, 184. [Google Scholar] [CrossRef] [PubMed]
- Goldberger, A.; Amaral, L.; Glass, L.; Hausdorff, J.; Ivanov, P.C.; Mark, R.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mallat, S. A Wavelet Tour of Signal Processing; Elsevier: Amsterdam, The Netherlands, 1999. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. Available online: https://www.jmlr.org/papers/volume12/pedregosa11a/pedregosa11a.pdf?ref=https://githubhelp.com (accessed on 13 December 2022).
- Katrompas, A.; Ntakouris, T.; Metsis, V. Recurrence and Self-Attention Vs the Transformer for Time-Series Classification: A Comparative Study. In Proceedings of the International Conference on Artificial Intelligence in Medicine, Halifax, NS, Canada, 14–17 June 2022. [Google Scholar]
- O’Malley, T.; Bursztein, E.; Long, J.; Chollet, F.; Jin, H.; Invernizzi, L.; de Marmiesse, G.; Hahn, A.; Mullenbach, J.; Podivín, J.; et al. KerasTuner. Available online: https://github.com/keras-team/keras-tuner (accessed on 23 November 2022).
- Bousseljot, R.; Kreiseler, D.; Schnabel, A. Nutzung der EKG-Signaldatenbank CARDIODAT der PTB über das Internet. Biomed. Tech. 1995, 40, 317–318. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
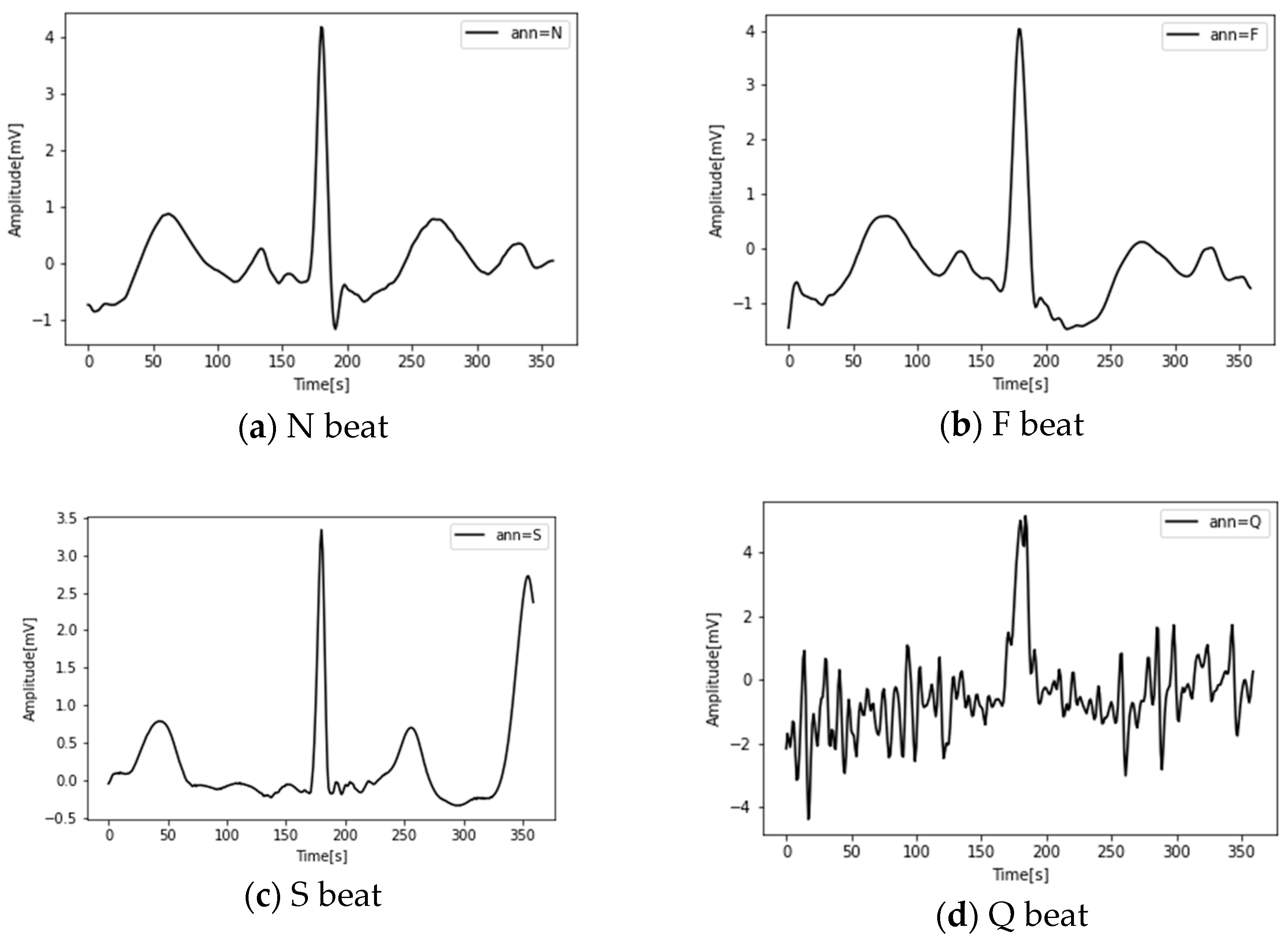
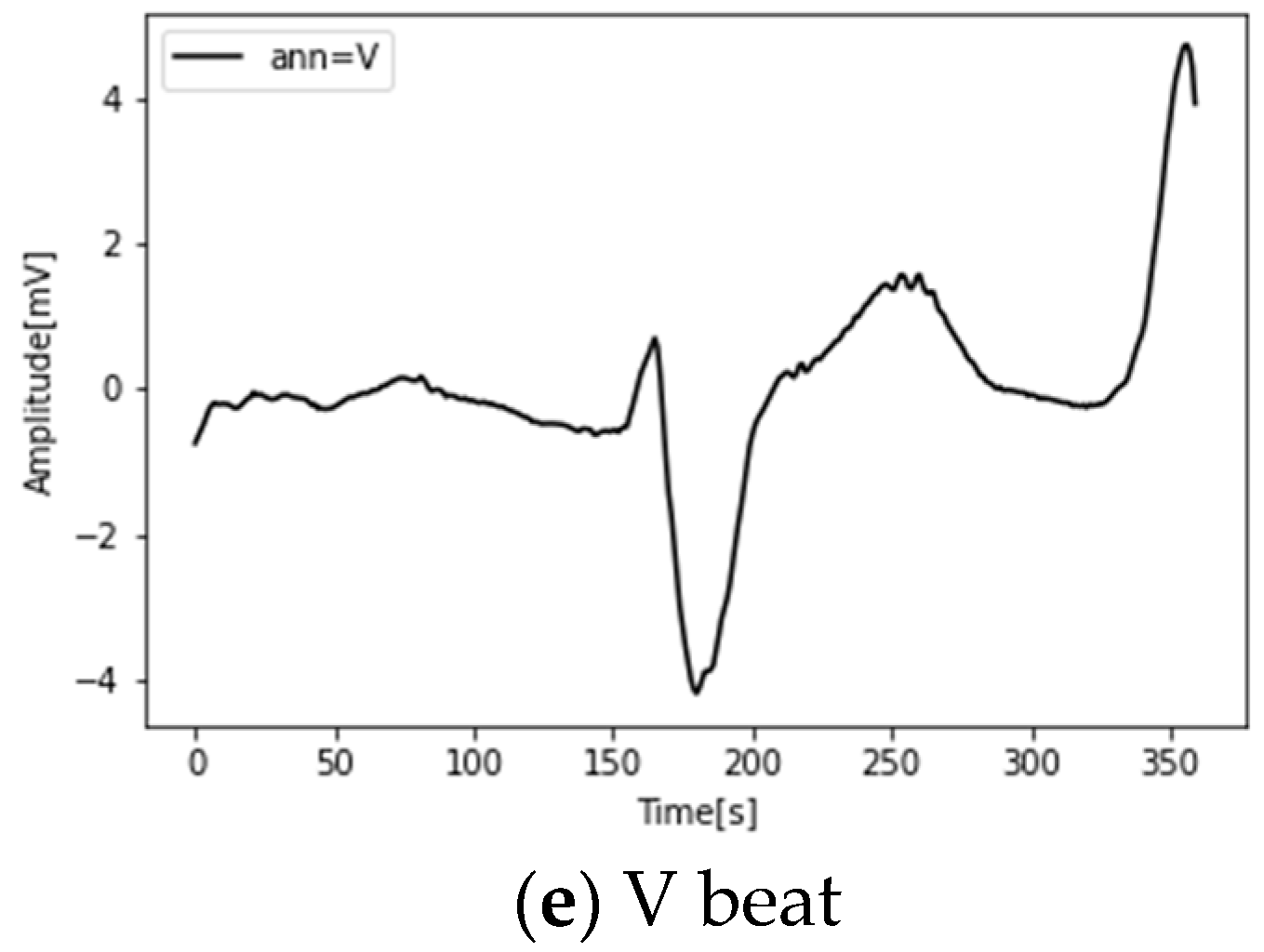
| AAMI Category | ID | Heartbeat Type |
|---|---|---|
| N | 0 | Normal beats (N), Right bundle branch block (R), Left bundle branch block (L), Nodal escape beat (j), Atrial escape beat (e) |
| S | 1 | Supraventricular premature beat (S), Atrial premature contraction (A), Aberrated atrial premature beat (a) |
| F | 2 | Fusion of normal and ventricular beat (F) |
| V | 3 | Ventricular ectopic beats and ventricular premature contraction (V) |
| Q | 4 | Unclassifiable beats(Q), fusion of paced and normal beat (f), paced beat (/) |
| Conv Layer | Number of Filters | Kernel Size |
|---|---|---|
| 1 | 64 | 14 |
| 2 | 32 | 10 |
| 3 | 16 | 10 |
| Parameters | Meaning | Values |
|---|---|---|
| encoder | Number of transformer encoder stacks | 4 |
| Embedding output size and dimension of Q, K, and V vectors | 256 | |
| num_heads | Number of attention heads | 8 |
| ffn_units | Number of units of feed-forward layer | 1012 |
| ff_dim | Filters for convolution layers of feed-forward part | 4 |
| mlp_dropout | Dropout value of feed-forward part | 0 |
| dropout | Dropout value | 0.15 |
| Hyperparameter | Value |
|---|---|
| Loss function | Categorical Cross-Entropy |
| Optimizer | Adam |
| Batch size | 64 |
| Learning rate | 0.001 |
| Epoch | 10 |
| Number of folds | 10 |
| Class | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | Specificity (%) | AUC |
|---|---|---|---|---|---|---|
| Non-ectopic beat (N) | 98.9 | 99 | 97.5 | 98.2 | 98.2 | 0.99 |
| Supraventricular ectopic beat (S) | 99.9 | 99.9 | 99.9 | 99.9 | 99.9 | 1.0 |
| Fusion beat (F) | 97.4 | 97.4 | 99.9 | 98.7 | 99.1 | 0.98 |
| Ventricular ectopic beat (V) | 99.08 | 99.1 | 97.7 | 98.4 | 98.3 | 0.99 |
| Undetermined beat (Q) | 99.9 | 100 | 100 | 99.9 | 99.9 | 1.0 |
| Sample | Models | Actual Class | Predicted Class |
|---|---|---|---|
 | CNN [12] | Non ectopic beat (N) | S(Χ) |
| Bi-LSTM [18] | N(√) | ||
| Transformer [22] | N(√) | ||
| CNN + Transformer | N(√) | ||
| CNN + Bi-LSTM | V(Χ) | ||
| Bi-LSTM + self-attention | N(√) | ||
| CNN + Transformer + Bi-LSTM (Proposed) | N(√) | ||
 | CNN [12] | Supraventricular ectopic beat (S) | F(Χ) |
| Bi-LSTM [18] | F(Χ) | ||
| Transformer [22] | N(Χ) | ||
| CNN + Transformer | S(√) | ||
| CNN + Bi-LSTM | S(√) | ||
| Bi-LSTM + self-attention | S(√) | ||
| CNN + Transformer + Bi-LSTM (Proposed) | S(√) | ||
 | CNN [12] | Fusion beat (F) | F(√) |
| Bi-LSTM [18] | F(√) | ||
| Transformer [22] | F(√) | ||
| CNN + Transformer | F(√) | ||
| CNN + Bi-LSTM | S(Χ) | ||
| Bi-LSTM + self-attention | F(√) | ||
| CNN + Transformer + Bi-LSTM (Proposed) | S(Χ) | ||
 | CNN [12] | Ventricular ectopic beat (V) | N(Χ) |
| Bi-LSTM [18] | N(Χ) | ||
| Transformer [22] | Q(Χ) | ||
| CNN + Transformer | V(√) | ||
| CNN + Bi-LSTM | V(√) | ||
| Bi-LSTM + self-attention | V(√) | ||
| CNN + Transformer + Bi-LSTM (Proposed) | V(√) | ||
 | CNN [12] | Unclassifiable and paced beats (Q) | Q(√) |
| Bi-LSTM [18] | Q(√) | ||
| Transformer [22] | Q(√) | ||
| CNN + Transformer | Q(√) | ||
| CNN + Bi-LSTM | Q(√) | ||
| Bi-LSTM + self-attention | F(Χ) | ||
| CNN + Transformer + Bi-LSTM (Proposed) | Q(√) |
| Model | Conv Layer | Hidden Units | Attention Heads | Accuracy (%) | F1-Score (%) |
|---|---|---|---|---|---|
| Bi-LSTM+ Transformer | None | - | - | 97.1 | 97.1 |
| 1 | 98.4 | 98.4 | |||
| 2 | 97.7 | 97.3 | |||
| 4 | 98.6 | 98.6 | |||
| 5 | 98.3 | 98.1 | |||
| CNN+ Transformer | - | 100 | - | 98 | 98.0 |
| 612 | 98.2 | 98.1 | |||
| 976 | 98.2 | 98.2 | |||
| 2078 | 97.7 | 97.7 | |||
| CNN+Bi-LSTM | - | - | 2 | 97.9 | 97.7 |
| 4 | 98.3 | 98.2 | |||
| 6 | 98.4 | 98.4 | |||
| 10 | 98.3 | 98.3 | |||
| CNN+ Transformer+ Bi-LSTM | 3 | 352 | 8 | 99.2 | 99.2 |
| Dataset | Class | Accuracy (%) | F1-Score (%) | AUC |
|---|---|---|---|---|
| MIT-BIH Arrhythmia | Non-ectopic beat (N) | 98.9 | 98.2 | 0.99 |
| Supraventricular ectopic beat (S) | 99.9 | 99.9 | 1.0 | |
| Fusion beat (F) | 97.4 | 98.7 | 0.98 | |
| Ventricular ectopic beat (V) | 99.08 | 98.4 | 0.99 | |
| Undetermined beat (Q) | 99.9 | 99.9 | 1.0 | |
| PTB Diagnostic ECG | Arrhythmia | 98.6 | 98.8 | 0.98 |
| Healthy | 98.8 | 98.7 | 0.98 |
| Reference | Approach | Performance |
|---|---|---|
| Jiang et al. [12] | CNN | Accuracy: 96.6%, MAUC: 97.8% |
| Shoughi et al. [13] | CNN-BiLSTM | Accuracy: 98.71% |
| Fang et al. [17] | CNN | Accuracy: 92.6%, F1-score: 65.9% |
| Mittal et al. [18] | BiLSTM | AUC: 98.64% |
| Shaker et al. [19] | GANs and CNN | Accuracy: 98%, Recall: 97.7% |
| Bertsimas et al. [20] | XGBoost Algorithm | Accuracy: 94% to 96% |
| Guan et al. [22] | Transformer | Recall: 98.39% and Precision: 98.41% |
| Che et al. [24] | CNN-Transformer | F1-score: 78.6% |
| Proposed | CNN+Transformer+ Bi-LSTM | Accuracy: 99.2%, F1-score: 99.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anjum, N.; Sathi, K.A.; Hossain, M.A.; Dewan, M.A.A. A Temporal Transformer-Based Fusion Framework for Morphological Arrhythmia Classification. Computers 2023, 12, 68. https://doi.org/10.3390/computers12030068
Anjum N, Sathi KA, Hossain MA, Dewan MAA. A Temporal Transformer-Based Fusion Framework for Morphological Arrhythmia Classification. Computers. 2023; 12(3):68. https://doi.org/10.3390/computers12030068
Chicago/Turabian StyleAnjum, Nafisa, Khaleda Akhter Sathi, Md. Azad Hossain, and M. Ali Akber Dewan. 2023. "A Temporal Transformer-Based Fusion Framework for Morphological Arrhythmia Classification" Computers 12, no. 3: 68. https://doi.org/10.3390/computers12030068
APA StyleAnjum, N., Sathi, K. A., Hossain, M. A., & Dewan, M. A. A. (2023). A Temporal Transformer-Based Fusion Framework for Morphological Arrhythmia Classification. Computers, 12(3), 68. https://doi.org/10.3390/computers12030068