1. Introduction
The proliferation of energy concerns globally mandates the implementation of quick and robust energy efficiency measures via the promotion of renewable energy integration and the deployment of Energy Management Systems (EMSs) [
1]; a smart building fault detection system (BFD) is integral to this process. BFD continuously tracks energy consumption and production levels to create energy usage alerts and prevent energy incidents. This task requires the implementation of adequate data acquisition and ingestion mechanisms, as well as appropriate predictive data analytics [
1].
The cloud-based management of smart building fault detection and other analytical processes concerned with building diagnostic data is not itself a novel concept. Nader Mohamed and Sanja Lazarova-Molnar propose a service-based architecture involving a distributed network of devices organized into a hierarchy of tiers, each responsible for a certain type of data load [
2] (building management, perception, ingestion and storage, processing, and analytics). In this article, the authors present an architecture developed for managing smart buildings, perceiving parameters of interest, and finally, storing, processing, and analyzing smart building diagnostic data in the cloud. While their approach is vastly different, their motivations are the same: remove the need for energy-concerned entities to maintain in-house hardware and expensive network infrastructures. Their research is also primarily concerned with the detection and diagnosis of faults. The authors detail the Smart Building Diagnostics as a Service (SBDaaS) model, which consists of three tiers utilized to connect cloud-based services to smart buildings. A smart building itself encompasses the first tier, along with all the infrastructure therein. A distributed network of sensor nodes monitoring energy consumption and environmental conditions make up the topmost layer of the first tier. The second tier is the Cloud-Enabled Building Energy Management System (CE-BEMS). Each smart building houses one CE-BEMS, and all energy-consuming subsystems, sensor nodes, and actuators are connected to it via IoT technologies. Every CE-BEMS is a lower-power device connected to the SBDaaS provider, an endpoint on a cloud platform. This could be an Azure Data Factory or an AWS configuration. Here, more intensive resources are housed. This is the third tier, the internet. Mohamed suggests that the service provider should offer multiple basic maintenance functions for different smart buildings including command and control, software updates, and the addition of sensor nodes [
2]. For smart building diagnostic functionality, the SBDaaS provider should provide data collection and storage for parameters monitored and perceived by the sensor networks (automated, if necessary), diagnostics reports to end-users (possible faults, the current status of sensor nodes), support for virtual aggregate sensors, and energy fault detection and diagnosis [
2]. The most noteworthy feature of their architecture is the implementation of adaptive AI features in the cloud such as knowledge-based systems to provide a feedback loop into the analytics required to generate faults, making the cloud-based smart building infrastructure robust to vertical scaling. This SBDaaS approach aims to create a highly scalable, less specialized infrastructure for companies to manage and report on smart buildings.
Iulia Stamatescu, Valeria Bolbooaca and Grigore Stamatescu propose an architecture more similar to ours, lacking a robust lower tier of distributed sensor nodes or per-building management devices like the CE-BEMS. This architecture connects the network of sensor nodes straight to the cloud through a WSN gateway (wireless sensor network) and forwards parameters to a cloud-based event hub [
3]. The parameters are moved from the event hub straight to Azure services such as Stream Analytics, Data Factory, and finally, the Azure App Service before being reported to users on a dashboard [
3]. The primary difference between this model and the one proposed by Nader Mohamed and Sanja Lazarova-Molnar is the service-based theme. Here, there is a single service provided by the cloud platform, and the buildings are not managed independently. This model is better suited for specialized use cases that do not expect much scaling in the way of provided services. Its strength is in its simplicity.
The approach taken in this paper is similar to the architecture as proposed by Iulia Stamatescu [
3]. Each building is profiled with diagnostics collected by a network of sensors to collect energy consumption aggregates for the smart building, as well as inputs from other energy subsystems within the building. Rather than having a robust lower tier of sensor nodes to collect more than energy data, environmental parameters such as climatic data are collected on a per-building basis from a third-party API. Our smart building fault detection architecture differs in that the supporting infrastructure exists almost entirely in the cloud, rather than having a CE-BEMS or other management devices in each building. Relevant parameters are collected by sensors or other third parties and forwarded directly to the primary cloud storage medium, the Azure Data Lake Storage. This contrasts with the more distributed, as-a-service approach taken by other researchers. Our processing is largely centralized, not lending itself well to vertical scaling or the addition of more data sources, a problem that will be solved in Phase 2. However, the taken approach to a smart building diagnostics architecture allows for easier horizontal scaling. In this case, this looks like the addition of more smart buildings without having to expand the sensor node networks or install management devices in each building. While other architectures are admittedly more robust, the BFD system proposed herein met the needs of the big data workload presented to the University and was more than satisfactory to the employer given its low cost. Additionally, keeping with a tightly centralized design and outsourcing the collection of environmental parameters such as weather data enabled rapid development and deployment.
A smart building fault detection system (SBFD) involving big data analytics requires high-performance computing runtimes and large distributed datasets [
4]. Additionally, the development of a continuous pipeline of workflows that make up such a system requires scheduling strategies, collaboration, version control, and smart dependency management [
5]. Each component in the technology stack is generally responsible for one of these core requirements. With minimal development operations and the use of a robust technology stack, we streamline the process of construction and deployment to focus on preparing analytic approaches that are effective and meet strict deadlines and variable specifications. For the high-performance computing runtime [
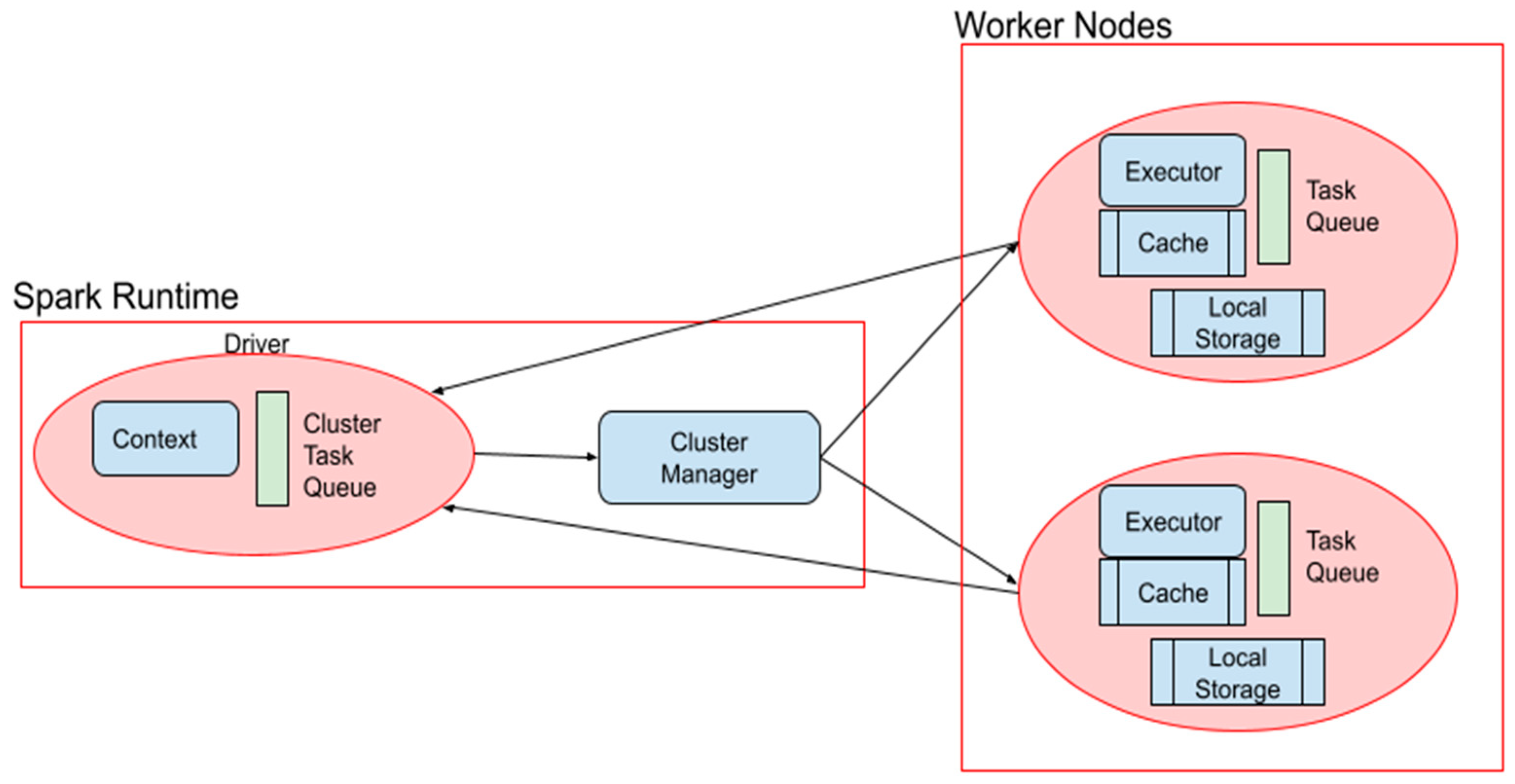
6], Apache Spark takes the lead with around 80% of the Fortune 500 making use of this massive, distributed computing framework. Fortunately, Microsoft’s cloud platform, Azure, provides a workspace, Databricks, giving a uniform interface to Spark’s capabilities (namely multi-node compute clusters) through intuitive GUIs and Jupyter notebooks where developers can house primary pipeline functionality. Our system makes use of two Spark compute clusters, one for the data pipeline workflows and another for the analytics and machine learning workflows [
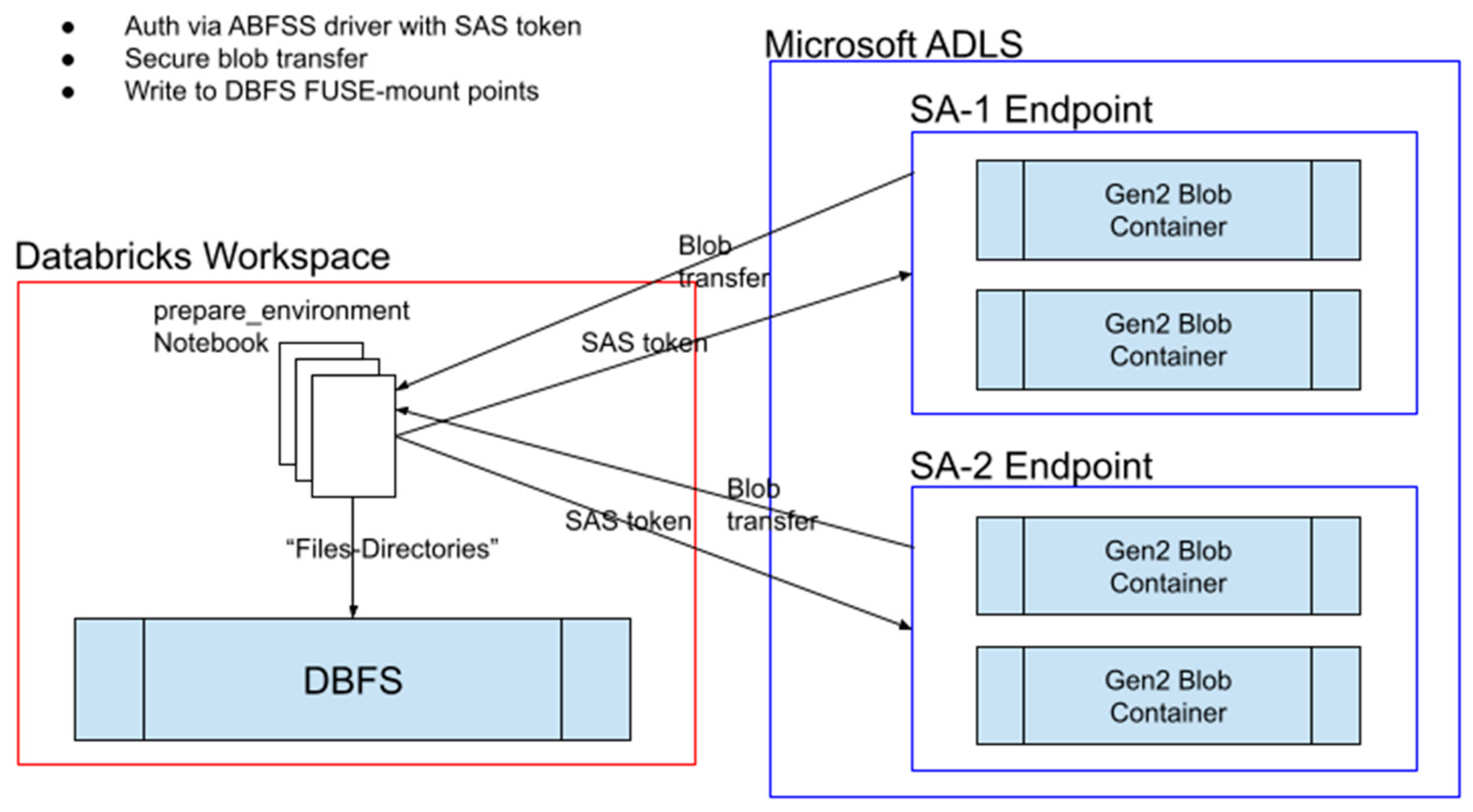
7]. For large distributed datasets, our Databricks workspace came largely pre-configured with an Apache Hive data warehouse. Each component of our pipeline, the workflow notebooks, was able to seamlessly interact with its respective data hierarchy using Structured Query Language (SQL) queries on tables uniquely labeled to reflect their contents and position in the pipeline. Our team devised several scheduling strategies over the lifetime of the project due to variable specifications and changing requirements. All strategies were implemented via the Databricks workflow interface allowing us to focus on analytic approaches rather than the development of some primitive driver to orchestrate and automate various pipeline tasks (real-time ingestion, integration, cleaning, and analytics). A given Jupyter notebook in the Databricks workspace is fully collaborative for all permitted users specified in the permission matrix (Admin console functionality). In our system, dependencies (Python libraries) are version-frozen and pre-installed at the cluster level. For version control, the Databricks workspace was configured to interact with external repositories hosted by GitHub.
3. Infrastructure: Pipeline of Workflows and Datasets
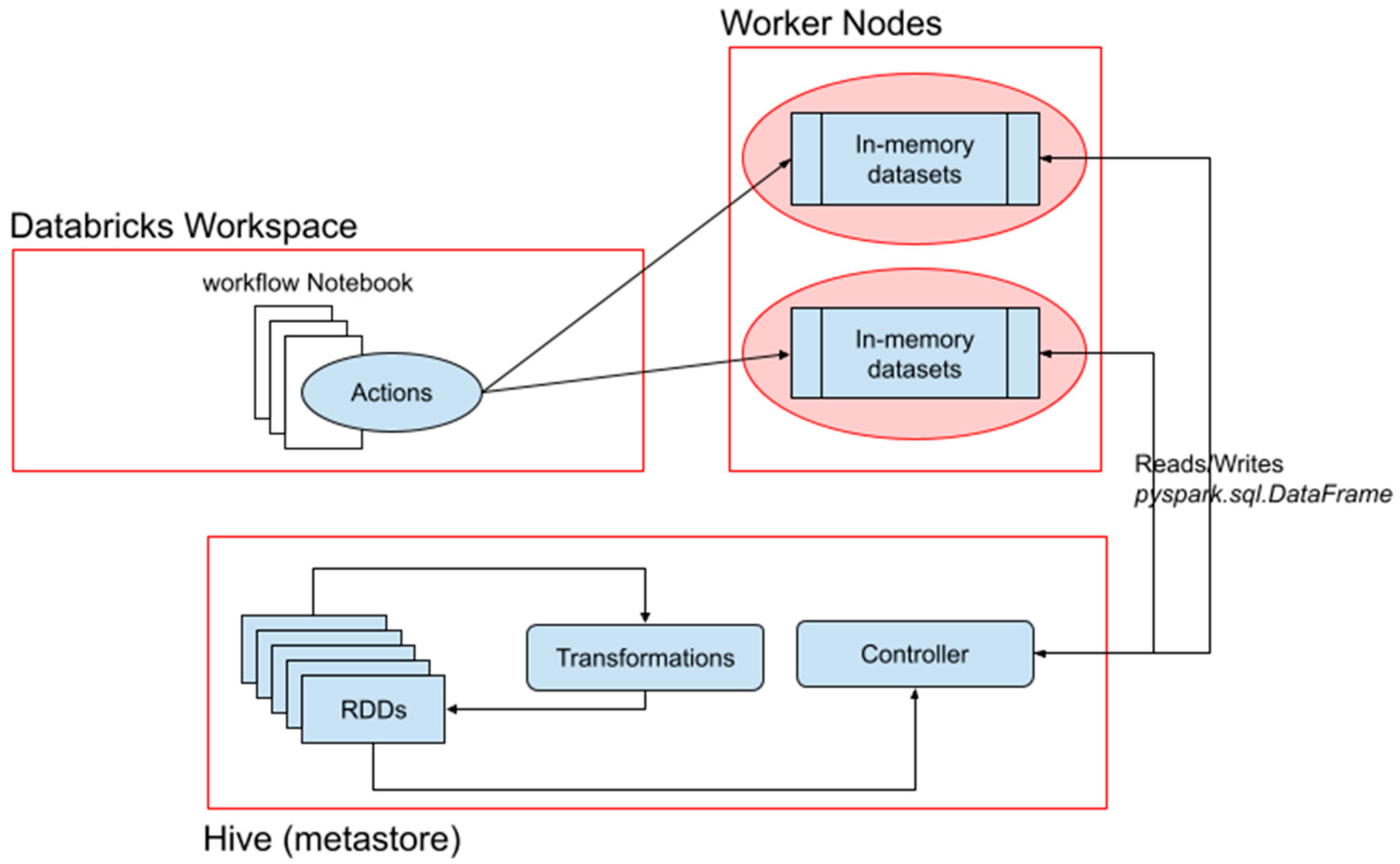
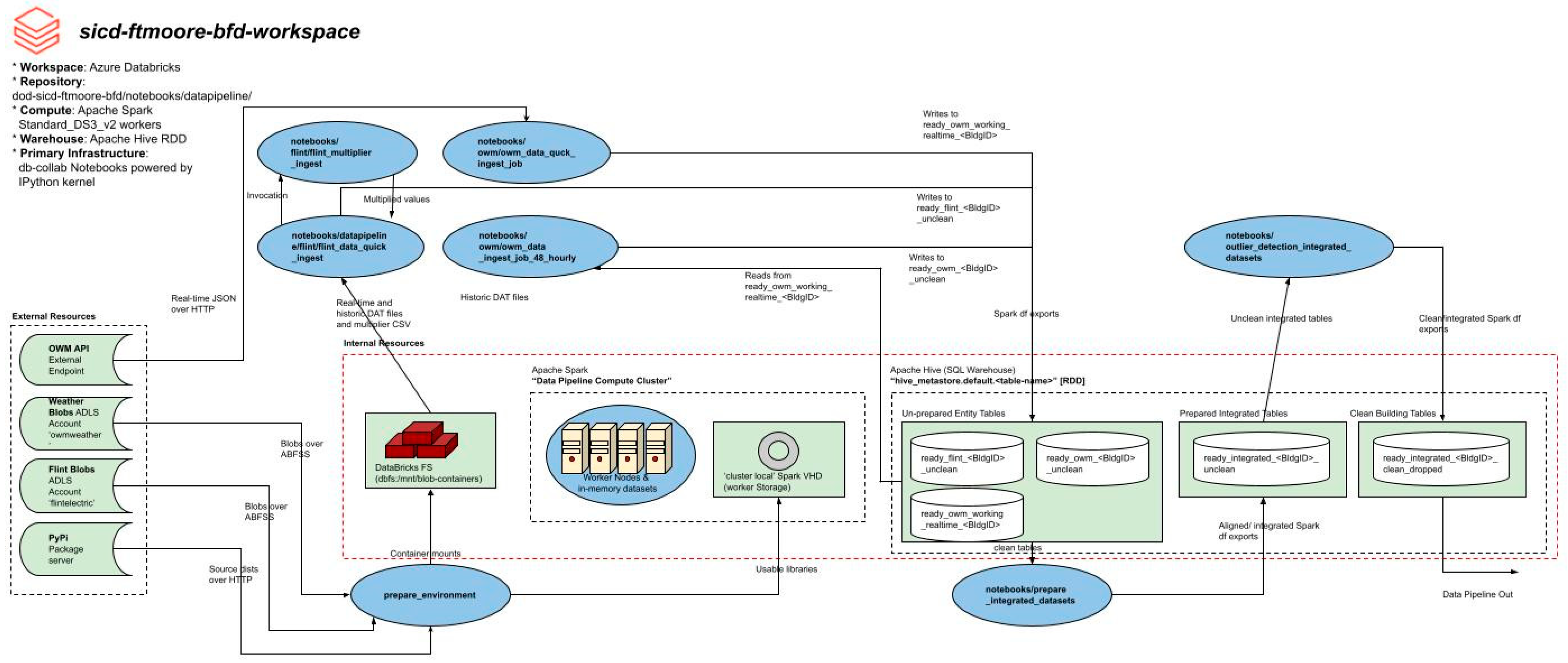
Each workflow in the pipeline (implemented as an interactive notebook specific to the target language) is responsible for the actuation of one of the following tasks: ingestion, integration, cleaning, or analytics. Creating a continuous pipeline between each component of the technology stack was an issue of interaction between the notebooks. For example, ‘prepare_integrated_datasets’ must proc before ‘outlier_detection_integrated_datasets’ in order for the later notebook to ingest the data required to complete that stage. The general architecture is as follows: each notebook read an RDD from Hive into memory as a ‘pyspark.DataFrame’. This enables both programmatic (using ‘PySpark’ API) and structured queries (SQL) to be executed over the dataset. Work is conducted and the resulting dataset is written back to Hive to a new table, tagged with various prefixes and suffixes denoting exactly what work was conducted to the data before being written to that table. This process is repeated N times until the late-stage workflows (analytics and machine learning) converge on results (energy consumption predictions, detected anomalies, etc.). Simply put, each notebook reads and writes to a storage resource that is accessible by the next notebook in the pipeline to take as its input. Therefore, most notebooks must be actuated synchronously.
The synchronous nature of each workflow’s execution enables an element of fault tolerance. The scheduling system prevents the next workflow from being triggered if it has data dependencies with a previous failed run. The idea that each workflow has a responsibility to the next workflow limits opportunities for concurrency, but effectively controls for data hazards. Large analytic processes housed in individual notebooks are managed exclusively by Spark compute resources and do in fact execute in parallel as the cluster manager dispatches tasks to worker queues.
Figure 4 illustrates how every workflow has access to internal resources such as storage and compute, running through the heart of the pipeline.
4. Development Operations
Development Operations (DevOps) is a set of protocols and governing principles that target enhanced collaboration, automation, and efficacy amongst software modules and their developers [
14]. The main objective of DevOps is to optimize and automate both the delivery and development of software infrastructure and maintenance [
14]. Good DevOps practices enabled our team to rapidly deliver a scalable smart building fault detection product to a third party. To meet the needs of a big data analytics use case like our BFD system, a continuous pipeline of workflows was necessary. Here, the DevOps principles of focus were collaborative workflows and version control, dependency management, and scheduling strategies. Our workspace platform, Databricks, enabled us to apply these principles out of the box with minimal configuration.
4.1. Collaborative Workflows and Version Control
Microsoft Azure Databricks, our workspace platform, provides collaborative notebooks. By giving each developer permission to the workspace on the access control matrix through the Databricks Admin Console, multiple developers can program the same workflow in real-time. Cluster-scoped core quotas inhibited collaborative development at times, especially when two developers were programming different workflows attached to the same Spark cluster context. Via inner-team communication and calculated time management, we were able to overcome these issues and pipeline our efforts by allocating time for certain tasks bound to their respective cluster. Version control was outsourced to the Git versioning system, using GitHub as a provider. Databricks provides a way to connect a remote Git repository to a workspace directory. Here, we placed our relevant Version Control System (VCS) configuration files (.gitignore, etc.). Each developer has to identify himself with their Personal Access Token (PAT) in order to commit to the connected repository. This authentication process happens at the user level in Databricks. Once authenticated, Databricks will assume the developer has access to the remote repository. If this is not the case, the developer will be notified upon an unsuccessful commit. Throughout the lifetime of the project, several commits were made to ensure third parties had access to a clean working source tree. Git largely met our VCS needs for the construction of a building fault detection system. This approach to collaborative workflows allowed a team of four developers to concurrently modify notebooks and make version control commits throughout the development cycle of the SBFD system.
4.2. Dependency Management
Early on, we analyzed the architecture of the Apache Spark clusters and the runtime configuration. As mentioned in
Section 2.2 (see output of ‘
!which python’ command), each worker node in a cluster has local storage that houses a virtual environment (‘venv’) with frozen dedicated binaries for necessary utilities [
15]. This is an environment-specific directory that is non-portable and directs all notebooks attached to that cluster to use those specific versions of binaries. In our case, as the selected language implementation on each cluster was Python, this was largely ‘python3′ and ‘pip’, the official PyPi package manager. A full Python 3 unpacked source distribution is present in this virtual environment, along with a site-packages folder where source wheels for Python libraries are installed. Early on, at the beginning of each notebook, there would be command cells dedicated to installing the required dependencies. This is because the persistence policy of the modified virtual environments is weak, i.e., the lifetime of the Spark context. When a cluster is terminated and rebooted, all changes made to the local worker storage are reverted. The work around is admittedly late-stage but simple: Databricks provides a cluster-scoped dependency management console where you can set packages and exact version numbers that you expect to be present on each cluster. The dependency manager applies the set versions to the site-packages folder present on the virtual environments of each of the cluster’s worker nodes. Currently, this meets our needs. The team is exploring the possibility of dedicated initialization scripts for global and cluster scopes using the ‘dbcli’ utility to have robust control over the configuration of Apache Spark including the dependencies made available to each cluster. None of the 3% of workflows that have been observed to generate runtime exceptions have been due to dependencies, displaying the efficacy of this management strategy.
4.3. Automation
Originally, the team had planned to write a primitive driver for the orchestration and automation of pipeline tasks, housed in one notebook that would itself be scheduled by the Databricks workflow scheduling interface. This proved to be unnecessary, as some perceived complexities in the automation simply did not exist. The actual timeline of which ingestion tasks needed to happen at what time and the order that various preparation and cleaning workflows needed to be in turned out to be quite simple. Consequently, the BFD system entirely relies on Databricks for task automation. Each notebook is scheduled to run at a certain time every so often according to the need. Ample time for each stage to complete is given between the scheduled runtime of the next workflow.
The only workflow that is scheduled daily is that which is responsible for the ingestion of open weather data. This happens every hour of every day in real-time to maintain an up-to-date record of observations for various climatic variables that aid in energy consumption predictions.
Three primary workflow jobs consisting of 6–12 notebooks each make up the automated portion of the deployed pipeline. This approach to automation has yielded successful results, with 100% of workflows triggering as scheduled. At the occurrence of Spark runtime exceptions, the fault-tolerant nature of the pipeline has shined. The offending workflows will proc on the next available compute time slice, with most exceptions occurring because of Spark misconfigurations that resolve themselves before the next attempt. These runtime exceptions have been observed to occur in less than 3% of job runs up to this point in deployment.



 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}