
Modeling Seasonality of Emotional Tension in Social Media


Abstract
:1. Introduction
- What methods are applicable to detect patterns of variation in multiple assessments of a population’s psychological states when observed over time?
- Do collective emotional tensions in reality have seasonal variations that can be tracked through social media content analysis?
2. Related Works
3. Materials and Methods
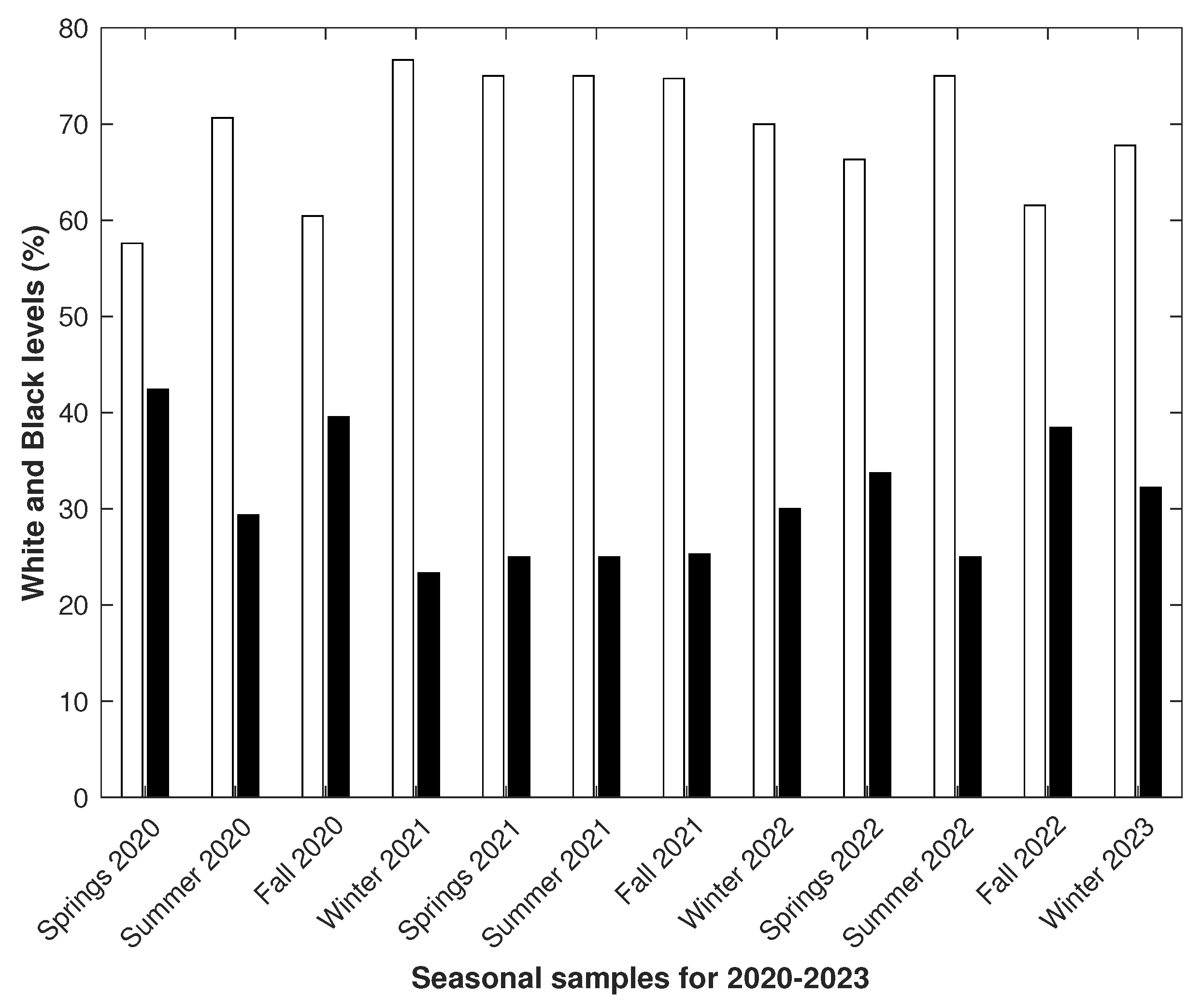
3.1. Data and Text Processing
3.2. Dataset Specification: Main Properties and Features
3.2.1. Descriptive Statistics of the Dataset
3.2.2. Main Properties
3.2.3. Dataset Features
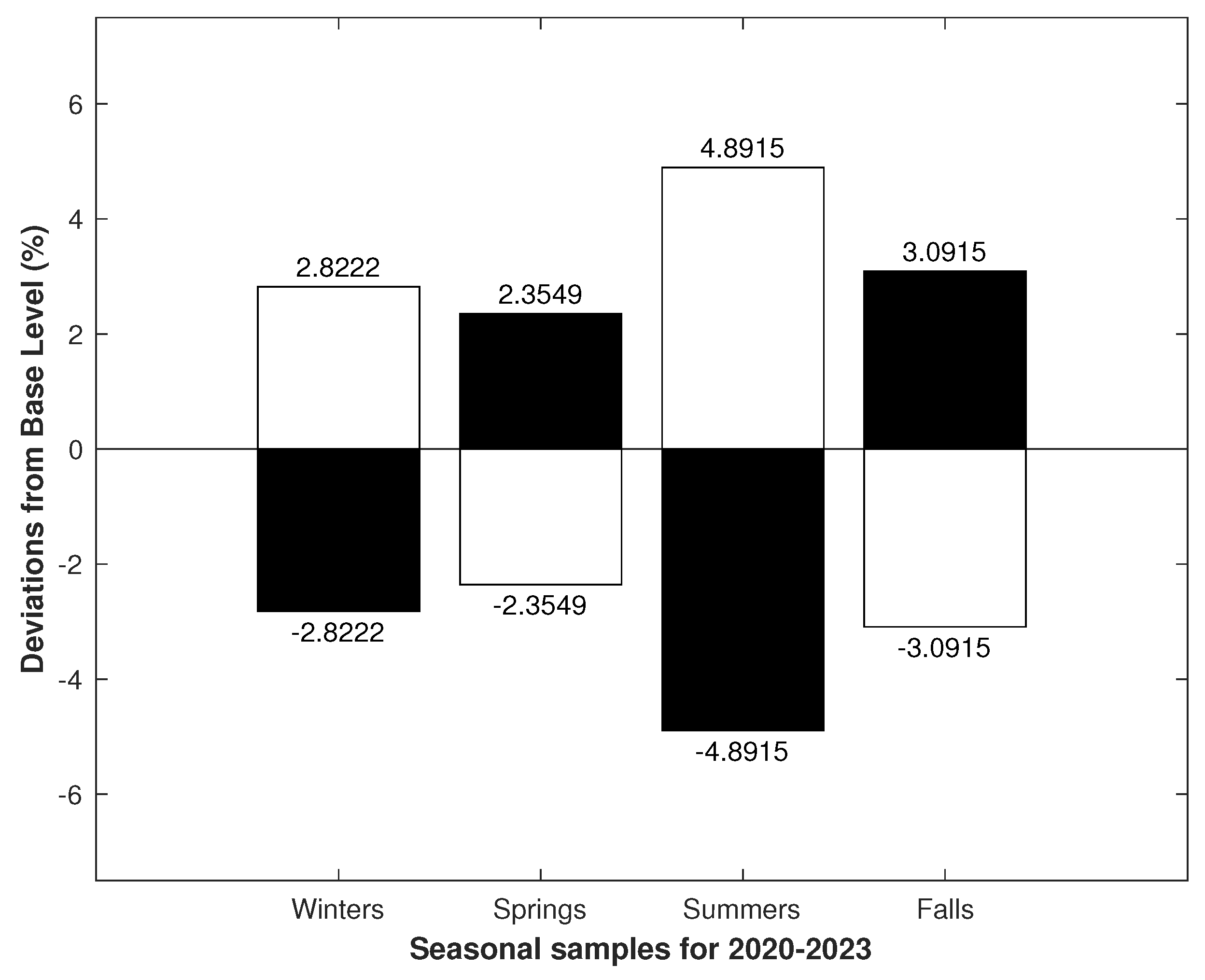
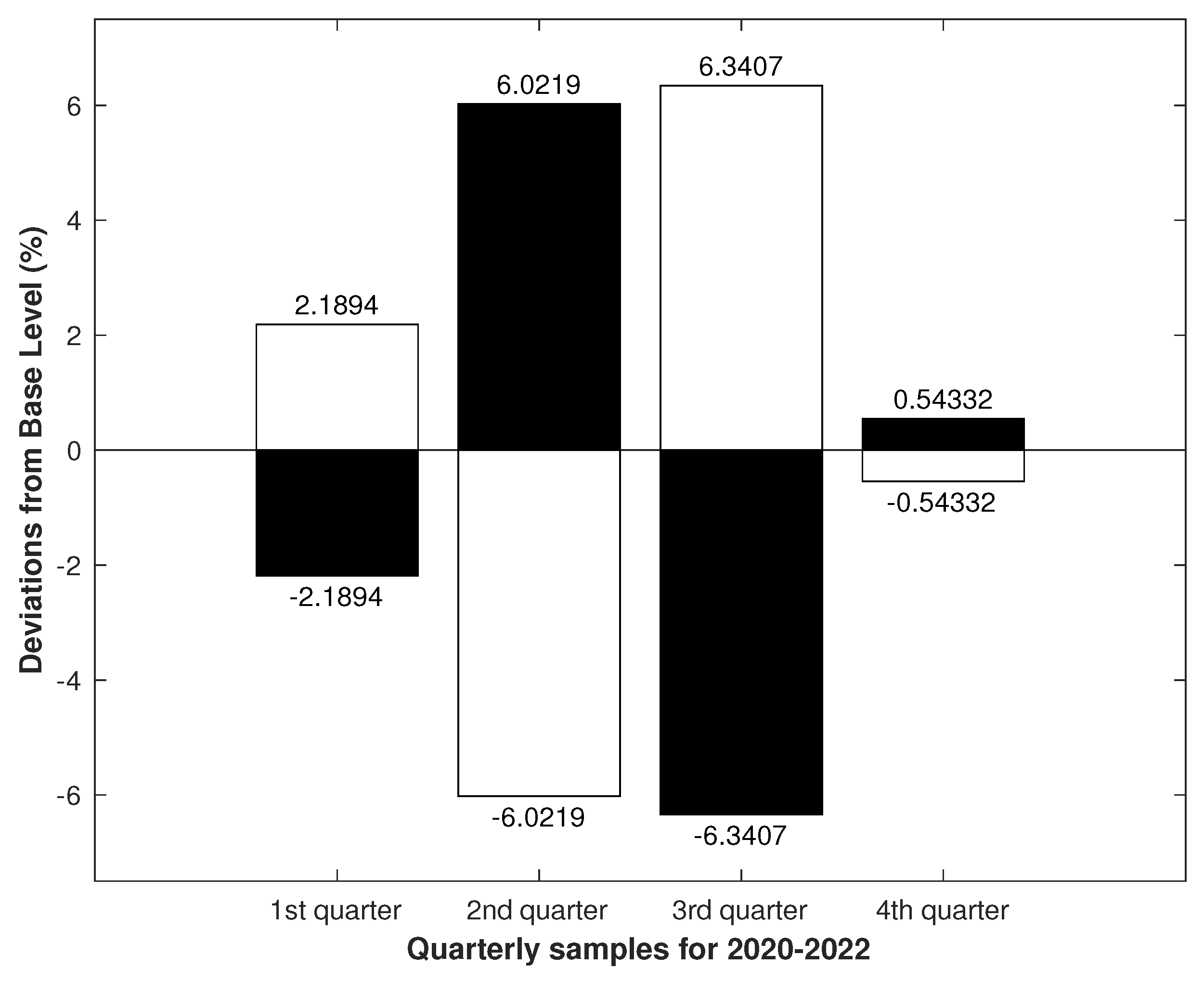
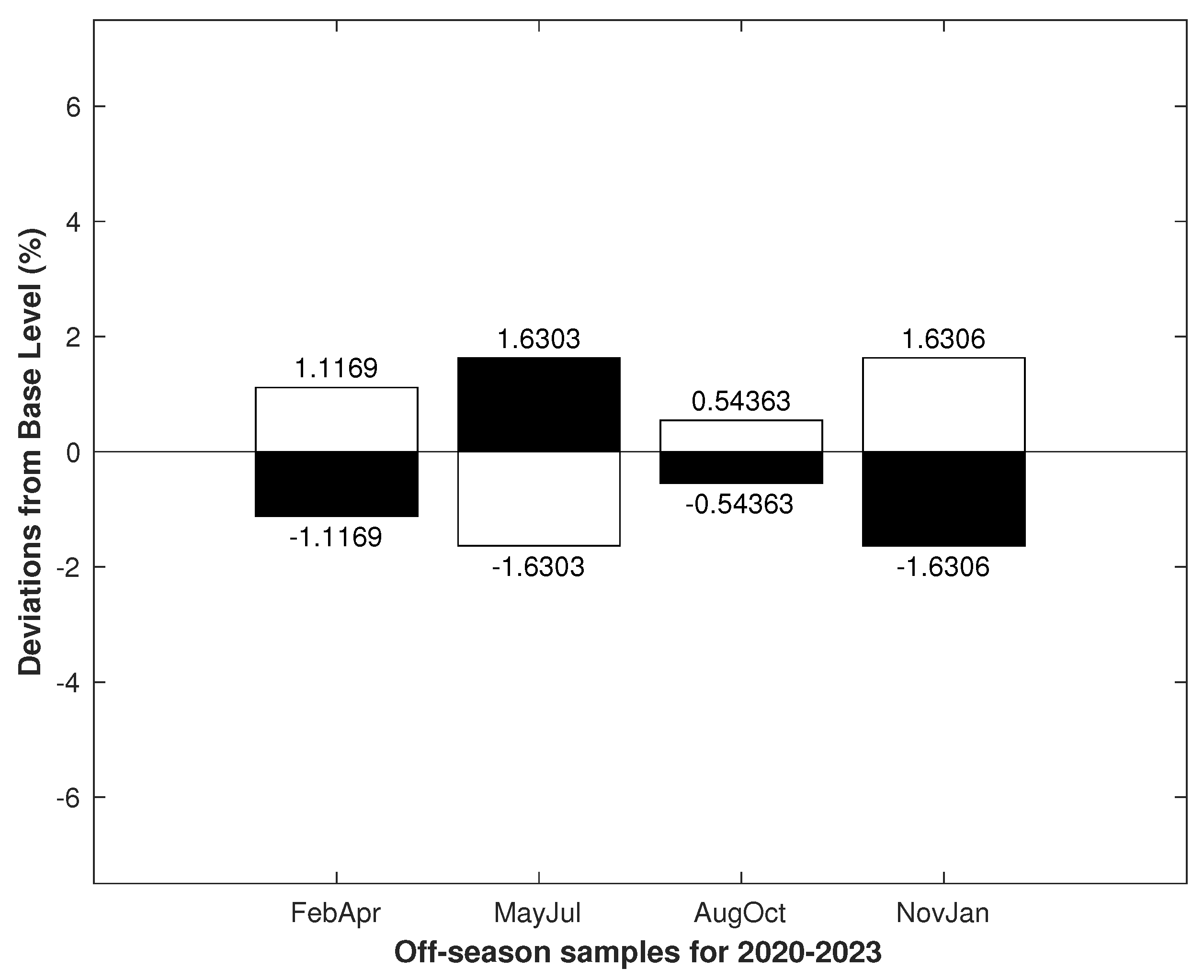
3.3. Seasonality Modeling
Model Aggregated by Time-Duration
3.4. Uniformly Aggregated TAMs
3.5. Extension of Uniformly Aggregated TAMs on a Dataset
3.5.1. Extending the Model by Adding Data
3.5.2. Expanding the Model by Shifting a Uniform Lattice on the Dataset
3.5.3. Evaluating and Comparing Models on the Real Dataset
3.5.4. Cluster Properties
4. Results
- (1)
- What methods are applicable to detect patterns of variation in multiple assessments of a population’s psychological states when observed over time?
- (2)
- Do collective emotional tensions in reality have seasonal variations that can be tracked through social media content analysis?
- As a result of the analysis of the statistical data, features of the data array were identified that make it possible to display mass emotional tension in the ratio of whites and blacks in selected calendar periods;
- The proposal of an approach to model seasonality in a class of time-aggregate models;
- Within the framework of the above proposed approach, it was shown that the data were characterized by the property of “data seasonality”, and the description of this property was obtained in the form of a stable pattern for all models from the found cluster;
- Based on the identified features of data seasonality, a criterion for matching this property for other time aggregated models was formulated.
5. Discussion
Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| EDA | Exploratory Data Analysis |
| NLP | Natural Language Processing |
| SPC | Statistical Process Control |
| TAM | Time-Aggregated Model |
| SAD | Seasonal Affective Disorder |
| API | Application Programming Interface |
| MAPE | Mean Absolute Percentage Error |
References
- Nguyen, L.T.; Wu, P.; Chan, W.; Peng, W.; Zhang, Y. Predicting Collective Sentiment Dynamics from Time-series Social Media. In Proceedings of the First International Workshop on Issues of Sentiment Discovery and Opinion Mining, Beijing, China, 12 August 2012; pp. 1–8. [Google Scholar] [CrossRef]
- Giachanou, A.; Mele, I.; Crestani, F. Explaining Sentiment Spikes in Twitter. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 2263–2268. [Google Scholar] [CrossRef]
- Grebenuyk, A.; Maksimova, A.; Lemer, L. Study of Social Tension Based on Electronic Social Networks Big Data. Digit. Sociol. 2021, 4, 4–12. (In Russian) [Google Scholar] [CrossRef]
- De Choudhury, M.; Counts, S. The Nature of Emotional Expression in Social Media: Measurement, Inference and Utility; Human Computer Interaction Consortium (HCIC): Minneapolis, MN, USA, 2012. [Google Scholar]
- Abdukhamidov, E.; Juraev, F.; Abuhamad, M.; El-Sappagh, S.; AbuHmed, T. Sentiment Analysis of Users’ Reactions on Social Media During the Pandemic. Electronics 2022, 11, 1648. [Google Scholar] [CrossRef]
- Abdul Mueez, A.; Mardiana, O.; Rosliza, A. Role of Social Media in Disaster Management. Int. J. Public Health Clin. Sci. 2019, 6, 77–99. [Google Scholar]
- Holt, C.C. Forecasting Seasonals and Trends by Exponentially Weighted Moving Averages. Int. J. Forecast. 2004, 20, 5–10. [Google Scholar] [CrossRef]
- Winters, P.R. Forecasting Sales by Exponentially Weighted Moving Averages. Manag. Sci. 1960, 6, 324–342. [Google Scholar] [CrossRef]
- Brockwell, P.; Davis, R. Introduction to Time Series and Forecasting; Springer: Cham, Switzerland, 2016; p. 425. [Google Scholar] [CrossRef]
- Hyndman, R.; Athanasopoulos, G. Forecasting: Principles and Practice, 3rd ed.; OTexts: Melbourne, Australia, 2021. [Google Scholar]
- United Nations Economic Commission for Europe. Practical Guide to Seasonal Adjustment with JDEMETRA+: From Source Series to User Communication; UNECE: Geneva, Switzerland, 2020; p. 95. [Google Scholar] [CrossRef]
- Ragheb, W. Affective Behavior Modeling on Social Networks. Ph.D. Thesis, Université Montpellier, Montpellier, France, 2020. [Google Scholar]
- Wang, Y.; Li, H.; Lin, C. Modeling Sentiment Evolution for Social Incidents. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2413–2416. [Google Scholar] [CrossRef]
- Beedie, C.; Terry, P.; Lane, A. Distinctions Between Emotion and Mood. Cogn. Emot. 2005, 19, 847–878. [Google Scholar] [CrossRef]
- Nguyen, T.; Phung, D.; Adams, B.; Venkatesh, S. Mood Sensing from Social Media Texts and its Applications. Knowl. Inf. Syst. 2014, 39, 667–702. [Google Scholar] [CrossRef]
- Mishne, G.; De Rijke, M. Capturing Global Mood Levels using Blog Posts. In Proceedings of the AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs, Stanford, CA, USA, 27–29 March 2006; Volume 6, pp. 145–152. [Google Scholar]
- Greetham, D.V.; Sengupta, A.; Hurling, R.; Wilkinson, J. Interventions in Social Networks: Impact on Mood and Network Dynamics. Adv. Complex Syst. 2015, 18, 1550016. [Google Scholar] [CrossRef]
- Charlton, N.; Singleton, C.; Greetham, D.V. In the Mood: The Dynamics of Collective Sentiments on Twitter. R. Soc. Open Sci. 2016, 3, 160162. [Google Scholar] [CrossRef]
- He, Y.; Lin, C.; Gao, W.; Wong, K.F. Tracking Sentiment and Topic Dynamics from Social Media. In Proceedings of the International AAAI Conference on Web and Social Media, Dublin, Ireland, 4–7 June 2012; Volume 6, pp. 483–486. [Google Scholar] [CrossRef]
- Patel, K.; Hoeber, O.; Hamilton, H.J. Real-time Sentiment-based Anomaly Detection in Twitter Data Streams. In Proceedings of the Advances in Artificial Intelligence: 28th Canadian Conference on Artificial Intelligence, Canadian AI 2015, Halifax, NS, Canada, 2–5 June 2015; Proceedings 28. Springer: Cham, Switzerland, 2015; pp. 196–203. [Google Scholar] [CrossRef]
- Wang, H.; Sun, K.; Wang, Y. Exploring the Chinese Public’s Perception of Omicron Variants on Social Media: Lda-based Topic Modeling and Sentiment Analysis. Int. J. Environ. Res. Public Health 2022, 19, 8377. [Google Scholar] [CrossRef]
- Lane, A.M.; Terry, P.C. The Nature of Mood: Development of a Conceptual Model with a Focus on Depression. J. Appl. Sport Psychol. 2000, 12, 16–33. [Google Scholar] [CrossRef]
- Alam, F.; Celli, F.; Stepanov, E.; Ghosh, A.; Riccardi, G. The Social Mood of News: Self-reported Annotations to Design Automatic Mood Detection Systems. In Proceedings of the Workshop on Computational Modeling of People’s Opinions, Personality, and Emotions in Social Media (PEOPLES), Osaka, Japan, 12 December 2016; pp. 143–152. [Google Scholar]
- Jome Yazdian, P.; Moradi, H. User Mood Detection in a Social Network Messenger Based on Facial Cues. In Proceedings of the Ubiquitous Computing and Ambient Intelligence: 11th International Conference, UCAmI 2017, Philadelphia, PA, USA, 7–10 November 2017; Proceedings. Springer: Cham, Switzerland, 2017; pp. 778–788. [Google Scholar] [CrossRef]
- Meyer, J.D.; Murray, T.A.; Brower, C.S.; Cruz-Maldonado, G.A.; Perez, M.L.; Ellingson, L.D.; Wade, N.G. Magnitude, Timing and Duration of Mood State and Cognitive Effects of Acute Moderate Exercise in Major Depressive Disorder. Psychol. Sport Exerc. 2022, 61, 102172. [Google Scholar] [CrossRef]
- Balog, K.; Mishne, G.; De Rijke, M. Why Are They Excited? Identifying and Explaining Spikes in Blog Mood Levels. In Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 3–7 April 2006; pp. 207–210. [Google Scholar]
- Lee, J.A.; Efstratiou, C.; Bai, L. OSN Mood Tracking: Exploring the Use of Online Social Network Activity as an Indicator of Mood Changes. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct, Heidelberg, Germany, 12–16 September 2016; pp. 1171–1179. [Google Scholar] [CrossRef]
- Smetanin, S.I. The Program for Public Mood Monitoring through Twitter Content in Russia. Proc. ISP RAS 2017, 29, 315–324. [Google Scholar] [CrossRef]
- Maklakov, A. Obshchaya Psikhologiya [General Psychology]; Piter Publisher: Saint Petersburg, Russia, 2001. (In Russian) [Google Scholar]
- Winthorst, W.H.; Bos, E.H.; Roest, A.M.; de Jonge, P. Seasonality of Mood and Affect in a Large General Population Sample. PLoS ONE 2020, 15, e0239033. [Google Scholar] [CrossRef]
- Melrose, S. Seasonal Affective Disorder: An Overview of Assessment and Treatment Approaches. Depress. Res. Treat. 2015, 2015, 178564. [Google Scholar] [CrossRef]
- Khaustova, Y. Seasonal Affective Disorder: Diagnosis and Therapy. Int. Neurol. J. 2012, 48, 188–192. (In Russian) [Google Scholar]
- Buikov, V.; Kolmogorova, V.; Burtova, E. Preventivny’e Lechebny’e Mery’ v Osenne-vesennij Period u Obluchennogo Naseleniya na Yuzhnom Urale [Preventive Therapeutic Measures in the Autumn-spring Period in the Irradiated Population of the Southern Urals]. Human. Sport. Med. 2007, 74, 48–51. (In Russian) [Google Scholar]
- Hohm, I.; Wormley, A.S.; Schaller, M.; Varnum, M.E. Homo Temporus: Seasonal Cycles as a Fundamental Source of Variation in Human Psychology. Perspect. Psychol. Sci. 2023, 1–22. [Google Scholar] [CrossRef]
- Palmu, R.; Koskinen, S.; Partonen, T. Seasonal Changes in Mood and Behavior Contribute to Suicidality and Worthlessness in a Population-based Study. J. Psychiatr. Res. 2022, 150, 184–188. [Google Scholar] [CrossRef]
- Rozanov, V.; Grigoriev, P.; Sumarokov, Y.; Shelygin, K.; Karyakin, A.; Malyavskaya, S.; Sidorenkov, O. Analysis of Seasonal Variations of Suicides in the Archangelsk Region in Relation to Geoclimatic Factors. Suicidology 2019, 10, 82–91. (In Russian) [Google Scholar]
- Spaderova, N. Seasonal Fluctuations of Suicides due to Geoclimatic Factors in People with Addictive Disorders. Ugra Heal. Exp. Innov. 2022, 33, 49–53. (In Russian) [Google Scholar] [CrossRef]
- Golder, S.A.; Macy, M.W. Diurnal and Seasonal Mood Vary with Work, Sleep, and Daylength Across Diverse Cultures. Science 2011, 333, 1878–1881. [Google Scholar] [CrossRef]
- Dzogang, F.; Goulding, J.; Lightman, S.; Cristianini, N. Seasonal Variation in Collective Mood via Twitter Content and Medical Purchases. In Proceedings of the Advances in Intelligent Data Analysis XVI: 16th International Symposium, IDA 2017, London, UK, 26–28 October 2017; Proceedings 16. Springer: Cham, Switzerland, 2017; pp. 63–74. [Google Scholar] [CrossRef]
- Chernenko, A.; Agarkov, V.; Bronfman, S. Analysis of Search Queries as a Tool for Comparative Assessment of the Need for Psychotherapeutic Assistance. Psychol. Psychotech. 2022, 1, 67–79. (In Russian) [Google Scholar] [CrossRef]
- Tan, K.L.; Lee, C.P.; Lim, K.M. A Survey of Sentiment Analysis: Approaches, Datasets, and Future Research. Appl. Sci. 2023, 13, 4550. [Google Scholar] [CrossRef]
- Bos, F.M.; Snippe, E.; de Vos, S.; Hartmann, J.A.; Simons, C.J.; van der Krieke, L.; de Jonge, P.; Wichers, M. Can We Jump from Cross-sectional to Dynamic Interpretations of Networks Implications for the Network Perspective in Psychiatry. Psychother. Psychosom. 2017, 86, 175–177. [Google Scholar] [CrossRef]
- Kuznetsova, Y.; Chudova, N.; Chuganskaya, A. Organization of Emotional Reactions Monitoring of Social Networks Users by Means of Automatic Text Analysis. Artif. Intell. Decis. Mak. 2023, 2, 64–75. (In Russian) [Google Scholar] [CrossRef]
- Rubanov, A. Mass Behavior and its Mechanisms. Philos. Soc. Sci. 2013, 1, 65–72. (In Russian) [Google Scholar]
- Rotenberg, V.S.; Boucsein, W. Adaptive Versus Maladaptive Emotional Tension. Genet. Soc. Gen. Psychol. Monogr. 1993, 119, 207. [Google Scholar]
- Dementieva, I. The Study of Protest Activity of Population in Foreign and Russian Science. Probl. Territ. Dev. 2013, 66, 83–94. (In Russian) [Google Scholar]
- McNair, D.; Lorr, M.; Droppleman, L. Profile of Mood States Manual (rev.); Educational and Industrial Testing Service: San Diego, CA, USA, 1992. [Google Scholar]
- Bollen, J.; Mao, H.; Pepe, A. Modeling Public Mood and Emotion: Twitter Sentiment and Socio-economic Phenomena. In Proceedings of the International AAAI Conference on Web and Social Media, Catalonia, Spain, 17–21 July 2011; Volume 5, pp. 450–453. [Google Scholar] [CrossRef]
- Green, K.H.; van de Groep, S.; Sweijen, S.W.; Becht, A.I.; Buijzen, M.; de Leeuw, R.N.; Remmerswaal, D.; van der Zanden, R.; Engels, R.C.; Crone, E.A. Mood and Emotional Reactivity of Adolescents during the COVID-19 Pandemic: Short-term and Long-term Effects and the Impact of Social and Socioeconomic Stressors. Sci. Rep. 2021, 11, 11563. [Google Scholar] [CrossRef]
- Parsons-Smith, R. In the Mood: Online Mood Profiling, Mood Response Clusters, and Mood-Performance Relationships in High-Risk Vocations. Ph.D. Thesis, University of Southern Queensland, Toowoomba, Australia, 2015. [Google Scholar]
- Vybornova, O.; Smirnov, I.; Sochenkov, I.; Kiselyov, A.; Tikhomirov, I.; Chudova, N.; Kuznetsova, Y.; Osipov, G. Social Tension Detection and Intention Recognition Using Natural Language Semantic Analysis: On the Material of Russian-speaking Social Networks and Web Forums. In Proceedings of the 2011 European Intelligence and Security Informatics Conference, Athens, Greece, 12–14 September 2011; pp. 277–281. [Google Scholar] [CrossRef]
- Sboev, A.; Gudovskikh, D.; Rybka, R.; Moloshnikov, I. A Quantitative Method of Text Emotiveness Evaluation on Base of the Psycholinguistic Markers Founded on Morphological Features. Procedia Comput. Sci. 2015, 66, 307–316. [Google Scholar] [CrossRef]
- Gudovskikh, D.; Moloshnikov, I.; Rybka, R. Sentiment Analysis Based on Morphologically Analysed Psycholinguistic Markers. Proc. Voronezh State University. Ser. Linguist. Intercult. Commun. 2015, 3, 92–97. (In Russian) [Google Scholar]
- Smirnova, D. Klinicheskie i Psiholingvisticheskie Harakteristiki Legkih Depressij [Clinical and Psycholinguistic Characteristics of Mild Depression]. Ph.D. Thesis, Moscow Research Institute of Psychiatry, Moscow, Russia, 2010. (In Russian). [Google Scholar]
- Medvedeva, T.I.; Enikolopov, S.N.; Vorontsova, O.Y. Suicidal Risk and Characteristics of Text Written by Patients with Endogenous Mental Disorders. Neurol. Bull. 2020, 52, 97–100. (In Russian) [Google Scholar] [CrossRef]
- Enikolopov, S.; Medvedeva, T.; Vorontsova, O. Lingustic Characteristics of Texts of People with Different Mental Status. Russ. Soc. Humanit. J. 2019, 3, 119–128. (In Russian) [Google Scholar] [CrossRef]
- Stankevich, M.; Kuznetsova, Y.; Smirnov, I.; Kiselnikova, N.; Enikolopov, S. Predicting Depression from Essays in Russian. In Proceedings of the International Conference “Dialogue” 2019, Moscow, Russia, 29 May–1 June 2019; pp. 647–657. [Google Scholar]
- Voronin, A.; Pavlova, N.; Grebenschikova, T.; Kubrak, T.; Smirnov, I. Evaluation of Network Community Subjectivity: Matching Discourse Markers and RSA Indicators. Inst. Psychol. Russ. Acad. Sci. Soc. Econ. Psychol. 2020, 5, 330–364. (In Russian) [Google Scholar] [CrossRef]
- Ganzin, I. The Clinical Linguistics of Insincere Behavior. Acta Psychiatr. Psychol. Psychother. Ethologica Tavrica 2013, 17, 80–83. (In Russian) [Google Scholar]
- Shewhart, W. Economic Control of Quality of Manufactured Product; D. Van Nostrand Co. Inc.: New York, NY, USA, 1931. [Google Scholar]
- Shewhart, W.; Deming, W. Statistical Method from the Viewpoint of Quality Control; The Graduate School, The Department of Agriculture Washington: Washington, DC, USA, 1939. [Google Scholar]
- Wheeler, D.; Chambers, D. Statistical Process Control: Business Optimization Using Shewhart Control Charts [Statisticheskoe Upravlenie Protcessami: Optimizatciia Biznesa s Ispolzovaniem Kontrolnykh kart Shukharta]; Alpina Business Books: Moscow, Russia, 2009; p. 409. (In Russian) [Google Scholar]
- Goyal, M. Computer-Based Numerical & Statistical Techniques; Infinity Science Press LLC: Hingham, MA, USA, 2007. [Google Scholar]
- Gibbons, J.; Chakraborti, S. Nonparametric Statistical Inference, Fourth Edition: Revised and Expanded; Taylor & Francis: Oxfordshire, UK, 2014. [Google Scholar]
- Witte, R.; Witte, J. Statistics; Wiley: Hoboken, NJ, USA, 2017. [Google Scholar]
- Weiß, C. An Introduction to Discrete-Valued Time Series; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Weiß, C. Discrete-Valued Time Series. Entropy 2023, 25, 1576. [Google Scholar] [CrossRef]
- López-Oriona, Á.; Vilar, J.A. Ordinal Time Series Analysis with the R Package otsfeatures. Mathematics 2023, 11, 2565. [Google Scholar] [CrossRef]
- Mastitskii, S. Time Series Analysis with R. (In Russian). 2020. Available online: https://ranalytics.github.io/tsa-with-r (accessed on 7 November 2023).
- Vasilyev, I.; Ushakov, A.V. Discrete Facility Location in Machine Learning. J. Appl. Ind. Math. 2021, 15, 686–710. [Google Scholar] [CrossRef]
- Smirnov, I.; Stankevich, M.; Kuznetsova, Y.; Suvorova, M.; Larionov, D.; Nikitina, E.; Savelov, M.; Grigoriev, O. TITANIS: A Tool for Intelligent Text Analysis in Social Media. In Proceedings of the Artificial Intelligence: 19th Russian Conference, RCAI 2021, Taganrog, Russia, 11–16 October 2021; Proceedings 19. Springer: Cham, Switzerland, 2021; pp. 232–247. [Google Scholar] [CrossRef]
- Yandex. MyStem. Available online: https://yandex.ru/dev/mystem (accessed on 22 October 2023).
- Stankevich, M. Trager Coefficient by Date. Available online: https://huggingface.co/datasets/Maxstan/trager_coef_by_date (accessed on 7 November 2023).
- Jinka, P.; Schwartz, B. Anomaly Detection for Monitoring; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2016. [Google Scholar]
- NIST/SEMATECH. e-Handbook of Statistical Methods. 2012. Available online: http://www.itl.nist.gov/div898/handbook/pmc/section3/pmc31.htm (accessed on 7 November 2023).
- Moontaha, S.; Arnrich, B.; Galka, A. State Space Modeling of Event Count Time Series. Entropy 2023, 25, 1372. [Google Scholar] [CrossRef]
- Liu, M.; Zhu, F.; Li, J.; Sun, C. A Systematic Review of INGARCH Models for Integer-Valued Time Series. Entropy 2023, 25, 922. [Google Scholar] [CrossRef]
- Enikolopov, S.; Boyko, O.; Medvedeva, T.; Vorontsova, O.; Kazmina, O. Dynamics of Psychological Reactions at the Start of the Pandemic of COVID-19. Psychol.-Educ. Stud. 2020, 12, 108–126. (In Russian) [Google Scholar] [CrossRef]
- Belinskaya, E.; Stolbova, E.; Tsikina, E. Mass Information Requests during the COVID-19 Pandemic: Psychological Determinants and Specific Features. Bull. Kemerovo State University. Ser. Humanit. Soc. Sci. 2021, 23, 427–437. (In Russian) [Google Scholar] [CrossRef]
- Musiychuk, M.; Musiychuk, S. Cognitive Mechanisms of Humor as a Coping Strategy on the Internet during the COVID-19 Pandemic and Self-isolation. Med. Psihol. Ross. 2021, 13, 1–23. (In Russian) [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Number of days | 1171 |
| Number of comments | 606,638 |
| Min and max comments per date | 19 (min)–2976 (max) |
| Avg. comments per date | 518 |
| Avg. character count per comment | 68.95 |
| Avg. word count per comment | 13.63 |
| Avg. sentence count per comment | 1.64 |
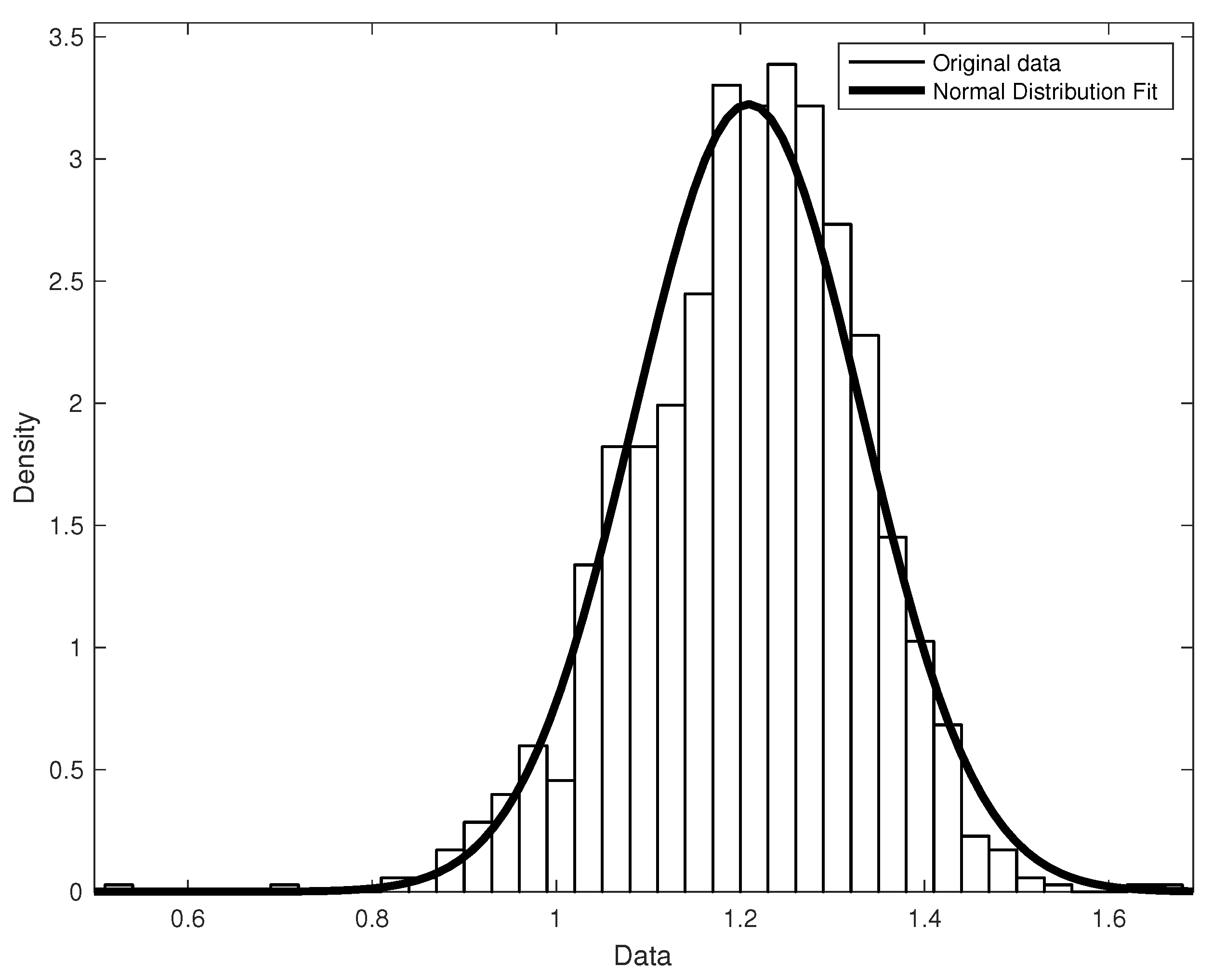
| Statistics | Values |
|---|---|
| Min. | 0.5209 |
| Max. | 1.6797 |
| Mean | 1.2089 |
| Median | 1.2153 |
| Mode | 0.5209 |
| Std. dev. | 0.1237 |
| Range | 1.1588 |
| Skewness | −0.3716 |
| Excess kurtosis | 0.9129 |
| Areas | Number of Records | Percentage by Area | Cumulative Percentage |
|---|---|---|---|
| 1 Std | 804 | 68.6593 | 68.6593 |
| 2 Std | 316 | 26.9854 | 95.6447 |
| 3 Std | 46 | 3.9283 | 99.5730 |
| Out of 3 Std | 5 | 0.4270 | — |
| Total | 1171 | 100.00 |
| Shift Parameter Value | First Cell Size (Days) | Fitting Error |
|---|---|---|
| 80 | 0.0002 | |
| 87 | 0.0015 | |
| 109 | 0.0018 | |
| 85 | 0.0019 | |
| 86 | 0.0022 | |
| 95 | 0.0022 | |
| 94 | 0.0027 | |
| 89 | 0.0028 | |
| 102 | 0.0028 | |
| 88 | 0.0029 | |
| 90 | 0.0033 | |
| 81 | 0.0043 | |
| 93 | 0.0056 | |
| 91 | 0.0060 | |
| 92 | 0.0067 | |
| 84 | 0.0090 | |
| 96 | 0.0090 |
| Shift Parameter | Metric | MAPE * White Level | MAPE Black Level |
|---|---|---|---|
| 0.9818 | 1.1586 | 2.6558 | |
| 0.9939 | 0.6037 | 1.3471 | |
| 0.9864 | 0.9170 | 2.2199 | |
| 0.9866 | 0.8843 | 2.2868 | |
| 0.9877 | 0.9261 | 2.1152 | |
| 0.9924 | 0.6691 | 1.5474 | |
| 0.9887 | 0.7373 | 1.7731 | |
| 0.9860 | 0.9214 | 2.1533 | |
| 0.9876 | 0.9762 | 2.2509 | |
| 0.9931 | 0.6314 | 1.4705 | |
| 0.9941 | 0.6325 | 1.3964 | |
| 0.9934 | 0.6737 | 1.4017 | |
| 0.9896 | 0.7878 | 1.7520 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nosov, A.; Kuznetsova, Y.; Stankevich, M.; Smirnov, I.; Grigoriev, O. Modeling Seasonality of Emotional Tension in Social Media. Computers 2024, 13, 3. https://doi.org/10.3390/computers13010003
Nosov A, Kuznetsova Y, Stankevich M, Smirnov I, Grigoriev O. Modeling Seasonality of Emotional Tension in Social Media. Computers. 2024; 13(1):3. https://doi.org/10.3390/computers13010003
Chicago/Turabian StyleNosov, Alexey, Yulia Kuznetsova, Maksim Stankevich, Ivan Smirnov, and Oleg Grigoriev. 2024. "Modeling Seasonality of Emotional Tension in Social Media" Computers 13, no. 1: 3. https://doi.org/10.3390/computers13010003
APA StyleNosov, A., Kuznetsova, Y., Stankevich, M., Smirnov, I., & Grigoriev, O. (2024). Modeling Seasonality of Emotional Tension in Social Media. Computers, 13(1), 3. https://doi.org/10.3390/computers13010003