
iHand: Hand Recognition-Based Text Input Method for Wearable Devices



Abstract
:1. Introduction
2. Related Work
3. Methodology
| Algorithm 1: Algorithm of hand gesture recognition module |
| Input: image Output: class label
|
| Algorithm 2: Algorithm of using iHand to input characters |
Output: character
|
3.1. Hand Recognition Algorithm
3.1.1. Palm Detector
3.1.2. Hand Landmark Model
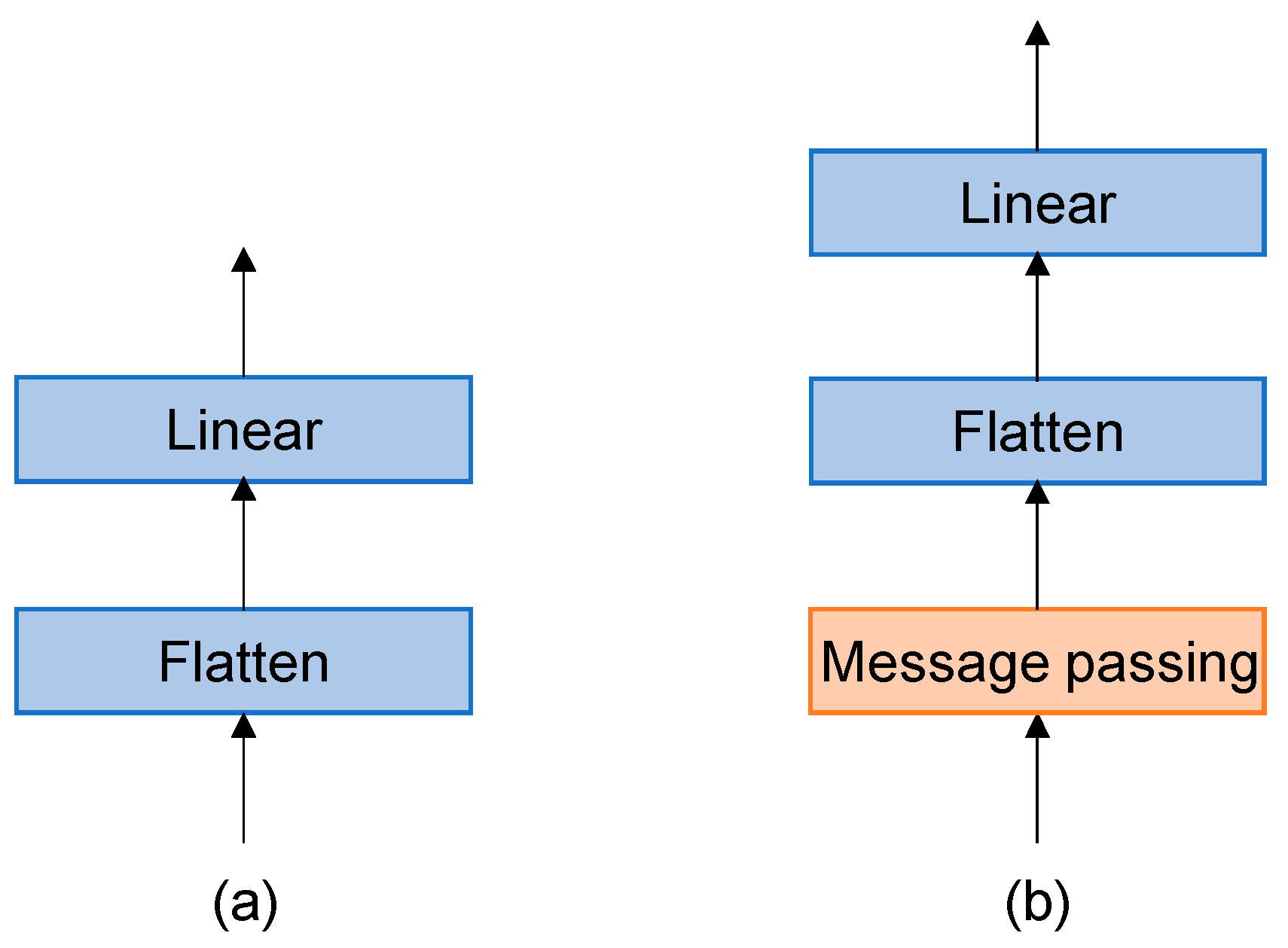
3.1.3. GMLP Head
3.1.4. Lightweight Convolutional Neural Network
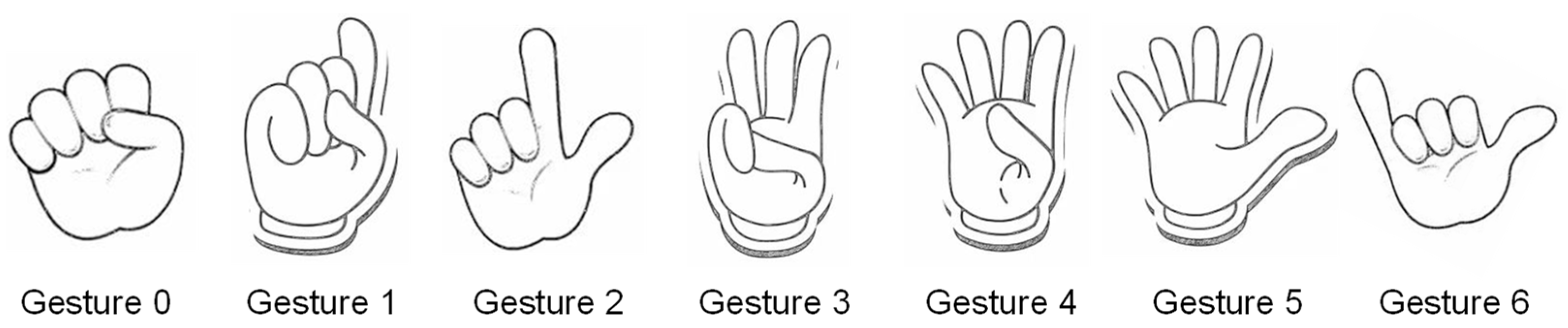
3.2. Alphabet Coding and Input Method
4. Hand Recognition
4.1. Datasets and Experimental Environment
4.2. Evaluation Criteria
4.3. Comparative Experiment
4.4. Ablation Study
5. Hand Gesture Text Input
5.1. Experimental Procedure
5.2. Evaluation Criteria
5.3. Text Input Performance
6. Conclusions
7. Software Copyright
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, C.P.; Zhou, L.; Ge, J.; Wu, Y.; Mi, L.; Wu, Y.; Yu, B.; Li, Y. Design of retinal projection displays enabling vision correction. Opt. Express 2017, 25, 28223–28235. [Google Scholar] [CrossRef]
- Chen, J.; Mi, L.; Chen, C.P.; Liu, H.; Jiang, J.; Zhang, W. Design of foveated contact lens display for augmented reality. Opt. Express 2019, 27, 38204–38219. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.P.; Mi, L.; Zhang, W.; Ye, J.; Li, G. Waveguide-based near-eye display with dual-channel exit pupil expander. Displays 2021, 67, 101998. [Google Scholar] [CrossRef]
- Chen, C.P.; Cui, Y.; Ye, Y.; Yin, F.; Shao, H.; Lu, Y.; Li, G. Wide-field-of-view near-eye display with dual-channel waveguide. Photonics 2021, 8, 557. [Google Scholar] [CrossRef]
- Chen, C.P.; Cui, Y.; Chen, Y.; Meng, S.; Sun, Y.; Mao, C.; Chu, Q. Near-eye display with a triple-channel waveguide for metaverse. Opt. Express 2022, 30, 31256–31266. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.P.; Ma, X.; Zou, S.P.; Liu, T.; Chu, Q.; Hu, H.; Cui, Y. Quad-channel waveguide-based near-eye display for metaverse. Displays 2023, 81, 102582. [Google Scholar] [CrossRef]
- Innocente, C.; Piazzolla, P.; Ulrich, L.; Moos, S.; Tornincasa, S.; Vezzetti, E. Mixed Reality-Based Support for Total Hip Arthroplasty Assessment. In Advances on Mechanics, Design Engineering and Manufacturing IV; Gerbino, S., Lanzotti, A., Martorelli, M., Mirálbes Buil, R., Rizzi, C., Roucoules, L., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 159–169. [Google Scholar] [CrossRef]
- Innocente, C.; Ulrich, L.; Moos, S.; Vezzetti, E. A framework study on the use of immersive XR technologies in the cultural heritage domain. J. Cult. Herit. 2023, 62, 268–283. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, X.; Zhou, X.; Liu, M.; Wang, J.; Liu, T. Application of Virtual Reality Technology in Distance Higher Education. In Proceedings of the 2019 4th International Conference on Distance Education and Learning, Shanghai, China, 24–27 May 2019. [Google Scholar] [CrossRef]
- Venkatakrishnan, R.; Bhargava, A.; Venkatakrishnan, R.; Lucaites, K.M.; Volonte, M.; Solini, H.; Robb, A.C.; Pagano, C. Towards an Immersive Driving Simulator to Study Factors Related to Cybersickness. In Proceedings of the 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Osaka, Japan, 23–27 March 2019. [Google Scholar] [CrossRef]
- Thomas, B.H. A survey of visual, mixed, and augmented reality gaming. CIE 2012, 10, 1–33. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, S.; Zhang, X.; Geng, Q. A two-branch hand gesture recognition approach combining atrous convolution and attention mechanism. Visual Comput. 2022, 39, 4487–4500. [Google Scholar] [CrossRef]
- Dadashzadeh, A.; Targhi, A.T.; Tahmasbi, M.; Mirmehdi, M. HGR-Net: A fusion network for hand gesture segmentation and recognition. IET Comput. Vis. 2019, 13, 700–707. [Google Scholar] [CrossRef]
- Alani, A.A.; Cosma, G.; Taherkhani, A.; McGinnity, T.M. Hand gesture recognition using an adapted convolutional neural network with data augmentation. In Proceedings of the 2018 4th International Conference on Information Management (ICIM), Oxford, UK, 25–27 May 2018. [Google Scholar] [CrossRef]
- Dube, T.J.; Arif, A.S. Text Entry in Virtual Reality: A Comprehensive Review of the Literature. In Human-Computer Interaction. Recognition and Interaction Technologies; Masaaki, K., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 419–437. [Google Scholar] [CrossRef]
- Knierim, P.; Schwind, V.; Feit, A.M.; Nieuwenhuizen, F.; Henze, N. Physical Keyboards in Virtual Reality: Analysis of Typing Performance and Effects of Avatar Hands. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal QC, Canada, 21–26 April 2018. [Google Scholar] [CrossRef]
- Pham, D.; Stuerzlinger, W. HawKEY: Efficient and Versatile Text Entry for Virtual Reality. In Proceedings of the 25th ACM Symposium on Virtual Reality Software and Technology, Parramatta, NSW, Australia, 12–15 November 2019. [Google Scholar] [CrossRef]
- Grubert, J.; Witzani, L.; Ofek, E.; Pahud, M.; Kranz, M.; Kristensson, P.O. Text Entry in Immersive Head-Mounted Display-Based Virtual Reality Using Standard Keyboards. In Proceedings of the 2018 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Reutlingen, Germany, 18–22 March 2018. [Google Scholar] [CrossRef]
- Hutama, W.; Harashima, H.; Ishikawa, H.; Manabe, H. HMK: Head-Mounted-Keyboard for Text Input in Virtual or Augmented Reality. In Adjunct Proceedings of the 34th Annual ACM Symposium on User Interface Software and Technology, Virtual Event, USA, 10–14 October 2021. [Google Scholar] [CrossRef]
- Bakar, M.A.; Tsai, Y.T.; Hsueh, H.H.; Li, E.C. CrowbarLimbs: A fatigue-reducing virtual reality text entry metaphor. IEEE Trans. Vis. Comput. Graph. 2023, 29, 2806–2815. [Google Scholar] [CrossRef]
- Singhal, Y.; Noeske, R.; Bhardwaj, A.; Kim, J.R. Improving Finger Stroke Recognition Rate for Eyes-Free Mid-Air Typing in VR. In Proceedings of the CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022. [Google Scholar] [CrossRef]
- Kern, F.; Niebling, F.; Latoschik, M.E. Text Input for Non-Stationary XR Workspaces: Investigating Tap and Word-Gesture Keyboards in Virtual and Augmented Reality. IEEE Trans. Vis. Comput. Graph. 2023, 29, 2658–2669. [Google Scholar] [CrossRef] [PubMed]
- Speicher, M.; Feit, A.M.; Ziegler, P.; Krüger, A. Selection-based Text Entry in Virtual Reality. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018. [Google Scholar] [CrossRef]
- Venkatakrishnan, R.; Venkatakrishnan, R.; Chung, C.H.; Wang, Y.S.; Babu, S. Investigating a Combination of Input Modalities, Canvas Geometries, and Inking Triggers on On-Air Handwriting in Virtual Reality. ACM Trans. Appl. Percept. 2022, 19, 1–19. [Google Scholar] [CrossRef]
- Bowman, D.A.; Rhoton, C.J.; Pinho, M.S. Text Input Techniques for Immersive Virtual Environments: An Empirical Comparison. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Baltimore, MD, USA, 29 September–4 October 2002. [Google Scholar] [CrossRef]
- Sridhar, S.; Feit, A.M.; Theobalt, C.; Oulasvirta, A. Investigating the Dexterity of Multi-Finger Input for Mid-Air Text Entry. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015. [Google Scholar] [CrossRef]
- Whitmire, E.; Jain, M.; Jain, D.; Nelson, G.; Karkar, R.; Patel, S.; Goel, M. DigiTouch: Reconfigurable Thumb-to-Finger Input and Text Entry on Head-mounted Displays. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–21. [Google Scholar] [CrossRef]
- Fallah, S.; MacKenzie, S. H4VR: One-handed Gesture-based Text Entry in Virtual Reality Using a Four-key Keyboard. In Proceedings of the Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; Association for Computing Machinery: New York, NY, USA, 2023. [Google Scholar] [CrossRef]
- Jiang, H.; Weng, D.; Zhang, Z.; Chen, F. HiFinger: One-Handed Text Entry Technique for Virtual Environments Based on Touches between Fingers. Sensors 2019, 19, 3063. [Google Scholar] [CrossRef] [PubMed]
- Fashimpaur, J.; Kin, K.; Longest, M. PinchType: Text Entry for Virtual and Augmented Reality Using Comfortable Thumb to Fingertip Pinches. In Proceedings of the Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Lee, D.; Kim, J.; Oakley, I. FingerText: Exploring and Optimizing Performance for Wearable, Mobile and One-Handed Typing. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. [Google Scholar] [CrossRef]
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.L.; Grundmann, M. MediaPipe Hands: On-device Real-time Hand Tracking. arXiv 2020, arXiv:2006.10214. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2019, arXiv:1801.04381. [Google Scholar] [CrossRef]
- The NUS Hand Posture Dataset-II. Available online: https://scholarbank.nus.edu.sg/handle/10635/137242 (accessed on 3 March 2024).
- Database for Hand Gesture Recognition. Available online: https://sun.aei.polsl.pl/~mkawulok/gestures/ (accessed on 29 January 2024).
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar] [CrossRef]
- Bhaumik, G.; Verma, M.; Govil, M.C.; Vipparthi, S.K. ExtriDeNet: An intensive feature extrication deep network for hand gesture recognition. Visual Comput. 2022, 38, 3853–3866. [Google Scholar] [CrossRef]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetV2: Enhance Cheap Operation with Long-Range Attention. arXiv 2022, arXiv:2211.12905. [Google Scholar] [CrossRef]
- MacKenzie, I.S.; Soukoreff, R.W. Phrase sets for evaluating text entry techniques. In Proceedings of the CHI 2003 Conference on Human Factors in Computing Systems, Fort Lauderdale, FL, USA, 5–10 April 2003. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | Output Channels | Stride | Repeat |
|---|---|---|---|---|
| 2242 × 3 | Conv 3 × 3 | 24 | 2 | 1 |
| 1122 × 24 | MaxPool 3 × 3 | 24 | 2 | 1 |
| 562 × 24 | BasicUnit | 116 | 2 | 1 |
| 282 × 116 | BasicUnit | 116 | 1 | 3 |
| 282 × 116 | BasicUnit | 232 | 2 | 1 |
| 142 × 232 | BasicUnit | 232 | 1 | 7 |
| 142 × 232 | BasicUnit | 464 | 2 | 1 |
| 72 × 464 | BasicUnit | 464 | 1 | 3 |
| 72 × 464 | GlobalPool 7 × 7 | 464 | / | / |
| 12 × 464 | Conv 1 × 1 | 1024 | 1 | 1 |
| 12 × 1024 | Linear | 7 | / | / |
| Dataset | Class Number | Subject Number | Image Number |
|---|---|---|---|
| NUS-II [35] | 10 | 40 | 2000 |
| HGR1 [36] | 27 | 12 | 899 |
| Dataset | Fold | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|---|---|
| NUS-II | 1 | 96.80 | 96.98 | 96.80 | 96.72 |
| 2 | 98.00 | 98.05 | 98.00 | 97.99 | |
| 3 | 98.20 | 98.23 | 98.20 | 98.20 | |
| 4 | 93.40 | 93.56 | 93.40 | 93.39 | |
| AVG | 96.60 | 96.71 | 96.60 | 96.58 | |
| HGR1 | 1 | 69.95 | 75.37 | 71.03 | 69.24 |
| 2 | 69.68 | 71.89 | 68.56 | 68.01 | |
| 3 | 79.60 | 79.99 | 78.28 | 78.63 | |
| 4 | 79.92 | 86.15 | 79.92 | 78.59 | |
| AVG | 74.79 | 78.35 | 74.45 | 73.62 |
| Method | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|---|
| ShuffleNetV2 [33] | 67.90 | 69.69 | 67.90 | 67.83 |
| MobileNetV2 [34] | 78.90 | 80.65 | 78.90 | 78.86 |
| GhostNetV1 [37] | 70.60 | 72.66 | 70.60 | 70.71 |
| EfficientNetV2 [38] | 67.05 | 69.76 | 67.05 | 66.88 |
| ExtriDeNet [39] | 61.49 | 62.26 | 61.49 | 60.60 |
| GhostNetV2 [40] | 64.45 | 66.39 | 64.45 | 64.31 |
| Ours | 96.60 | 96.71 | 96.60 | 96.58 |
| Method | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|---|
| ShuffleNetV2 [33] | 35.73 | 38.86 | 35.75 | 33.07 |
| MobileNetV2 [34] | 25.76 | 27.09 | 25.84 | 24.10 |
| GhostNetV1 [37] | 34.52 | 39.94 | 34.69 | 33.89 |
| ExtriDeNet [39] | 31.15 | 35.79 | 31.15 | 28.86 |
| GhostNetV2 [40] | 29.87 | 38.97 | 30.13 | 29.16 |
| Ours | 74.79 | 78.35 | 74.45 | 73.62 |
| Method | NUS-II | HGR1 |
|---|---|---|
| ShuffleNetV2 [33] | 4.55 | 12.65 |
| MobileNetV2 [34] | 10.76 | 29.19 |
| GhostNetV1 [37] | 7.08 | 18.55 |
| GhostNetV2 [40] | 10.66 | 25.66 |
| Ours | 10.46 | 10.43 |
| Method | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|---|
| Landmark model + MLP | 93.80 | 94.27 | 93.80 | 93.71 |
| Landmark model + MLP or CNN | 95.70 | 95.93 | 95.70 | 95.66 |
| Landmark model + GMLP or CNN | 96.60 | 96.71 | 96.60 | 96.58 |
| Method | Accuracy (%) | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|---|
| Landmark model + MLP | 72.64 | 74.60 | 72.59 | 71.48 |
| Landmark model + MLP or CNN | 73.71 | 75.67 | 73.66 | 72.31 |
| Landmark model + GMLP or CNN | 74.79 | 78.35 | 74.45 | 73.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, Q.; Chen, C.P.; Hu, H.; Wu, X.; Han, B. iHand: Hand Recognition-Based Text Input Method for Wearable Devices. Computers 2024, 13, 80. https://doi.org/10.3390/computers13030080
Chu Q, Chen CP, Hu H, Wu X, Han B. iHand: Hand Recognition-Based Text Input Method for Wearable Devices. Computers. 2024; 13(3):80. https://doi.org/10.3390/computers13030080
Chicago/Turabian StyleChu, Qiang, Chao Ping Chen, Haiyang Hu, Xiaojun Wu, and Baoen Han. 2024. "iHand: Hand Recognition-Based Text Input Method for Wearable Devices" Computers 13, no. 3: 80. https://doi.org/10.3390/computers13030080
APA StyleChu, Q., Chen, C. P., Hu, H., Wu, X., & Han, B. (2024). iHand: Hand Recognition-Based Text Input Method for Wearable Devices. Computers, 13(3), 80. https://doi.org/10.3390/computers13030080