
Architectural and Technological Approaches for Efficient Energy Management in Multicore Processors





Abstract
:1. Introduction
2. Related Work
2.1. Benchmarks
2.2. Multi/Many-Core Simulators
2.3. Value Prediction and Dynamic Instruction Reuse
2.4. Dynamic Voltage and Frequency Scaling
3. Methodology and Technical Modifications
3.1. Simple Core State Predictor Implementation
| Algorithm 1. SCSP Prediction Logic | |
| 1 | for x in [0, num_cores−1]: |
| 2 | actual_state = get_core_state(x) |
| 3 | scsp = get_scsp(x) |
| 4 | predicted_state = scsp.get_prediction() |
| 5 | |
| 6 | # Check and react on last confident prediction |
| 7 | if scsp.CO >= COthreshold: |
| 8 | if predicted_state != actual_state: |
| 9 | adjust_frequency(x, actual_state) |
| 10 | |
| 11 | # Update the confidence counter |
| 12 | if predicted_state != actual_state: |
| 13 | scsp.CO = 0 |
| 14 | else: |
| 15 | if scsp.CO < COthreshold: |
| 16 | scsp.CO += 1 |
| 17 | |
| 18 | scsp.add_state(actual_state) |
| 19 | |
| 20 | # Perform a new prediction |
| 21 | predicted_state = scsp.get_prediction() |
| 22 | |
| 23 | # If confident enough, adjust core frequency accordingly |
| 24 | if scsp.CO >= COthreshold: |
| 25 | adjust_frequency(x, predicted_state) |
- <calling_interval_ns> specifies the periodicity of script execution.
- <idle_frequency_mhz> the frequency that is set in case the predicted state is idle.
- <confidence> represents the threshold of the confidence counter.
- <history> specifies how many previous states are kept in the table.
3.2. Power, Area, and Thermal Estimations
4. Simulation Environment and Metrics
- I = the number of instructions executed.
- N = the number of cycles necessary to execute the instructions.
- C = the number of cores.
- Ek = execution time in cycles for core k.
- MB = Metric of the baseline configuration.
- ME = Metric of the enhanced architecture (with SCSP, DIR, or VP unit).
- P = the dynamic power consumption.
- C = the number of cycles.
- fCPU = frequency of the simulated processor [Hz].
5. Experimental Results
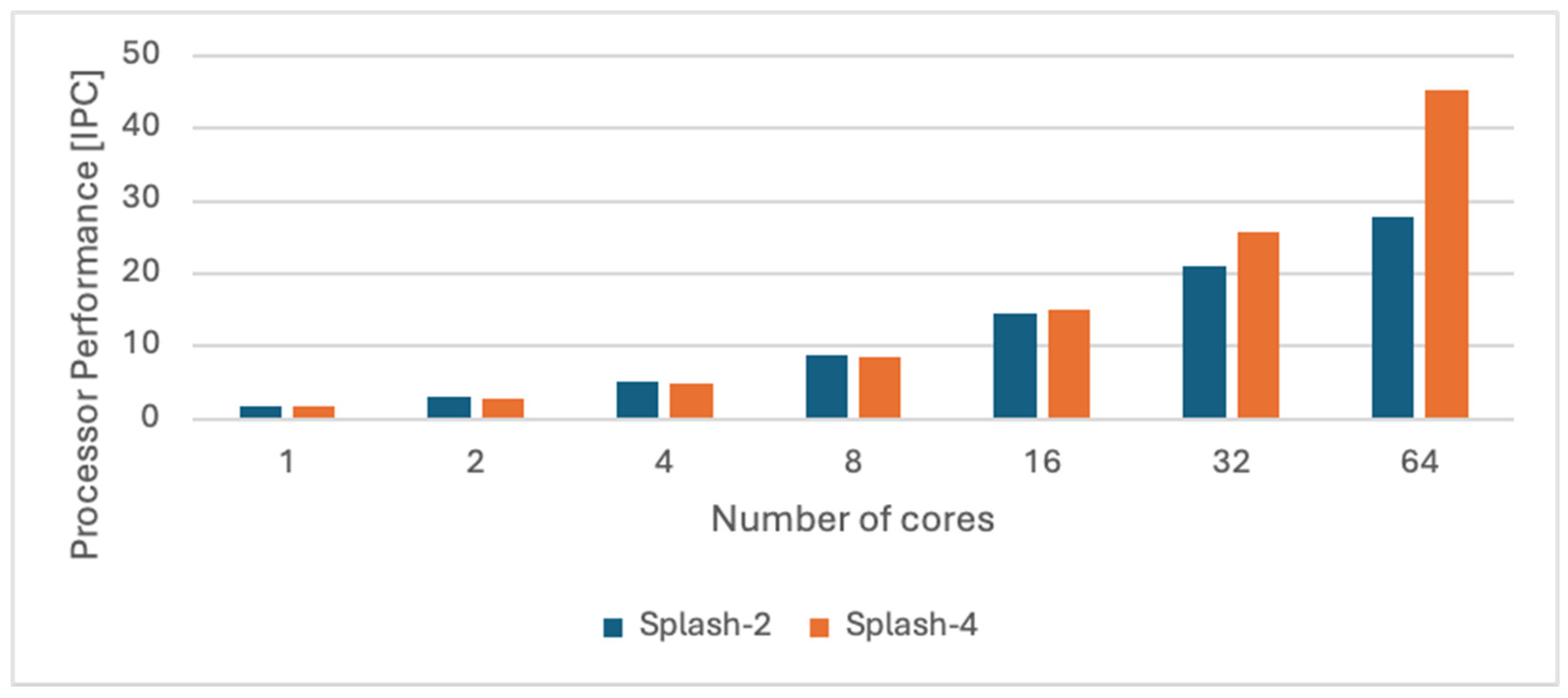
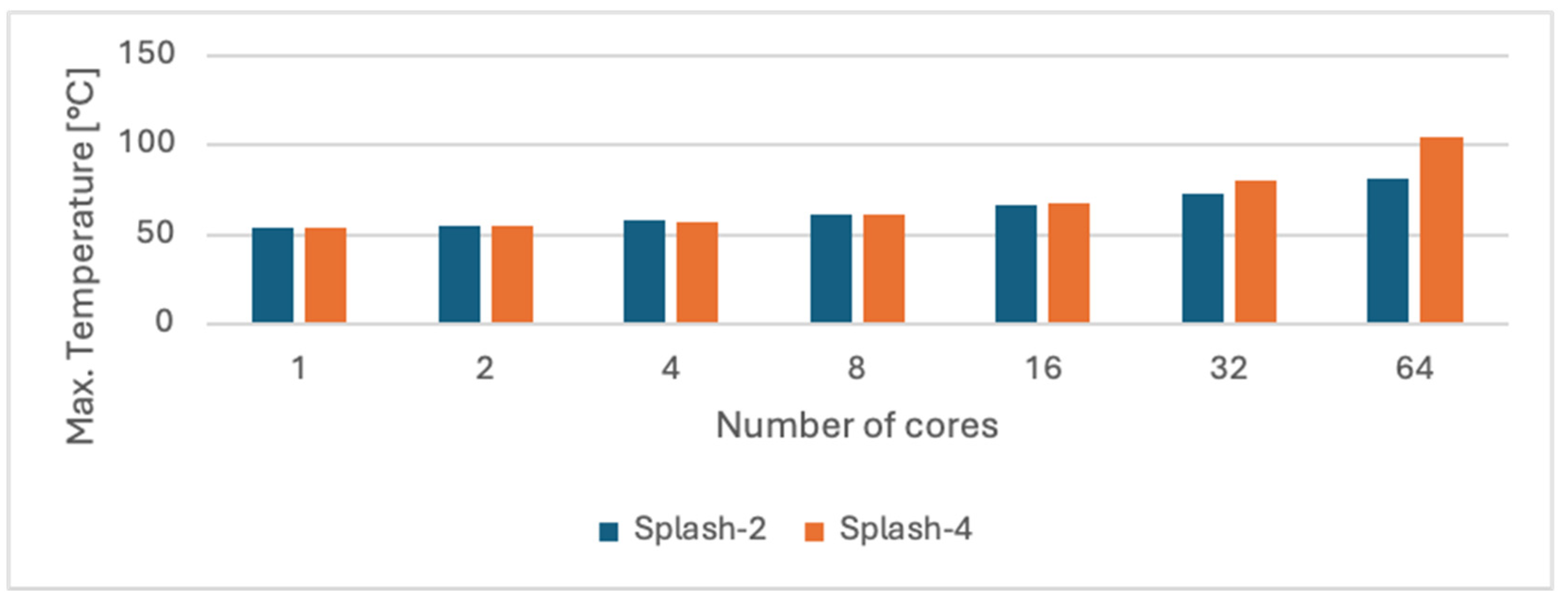
5.1. An Empirical Analysis of Splash-2 and Splash-4
- calling_interval_ns = 2000
- idle_frequency_mhz = 1000
- confidence = 0
- history = 1
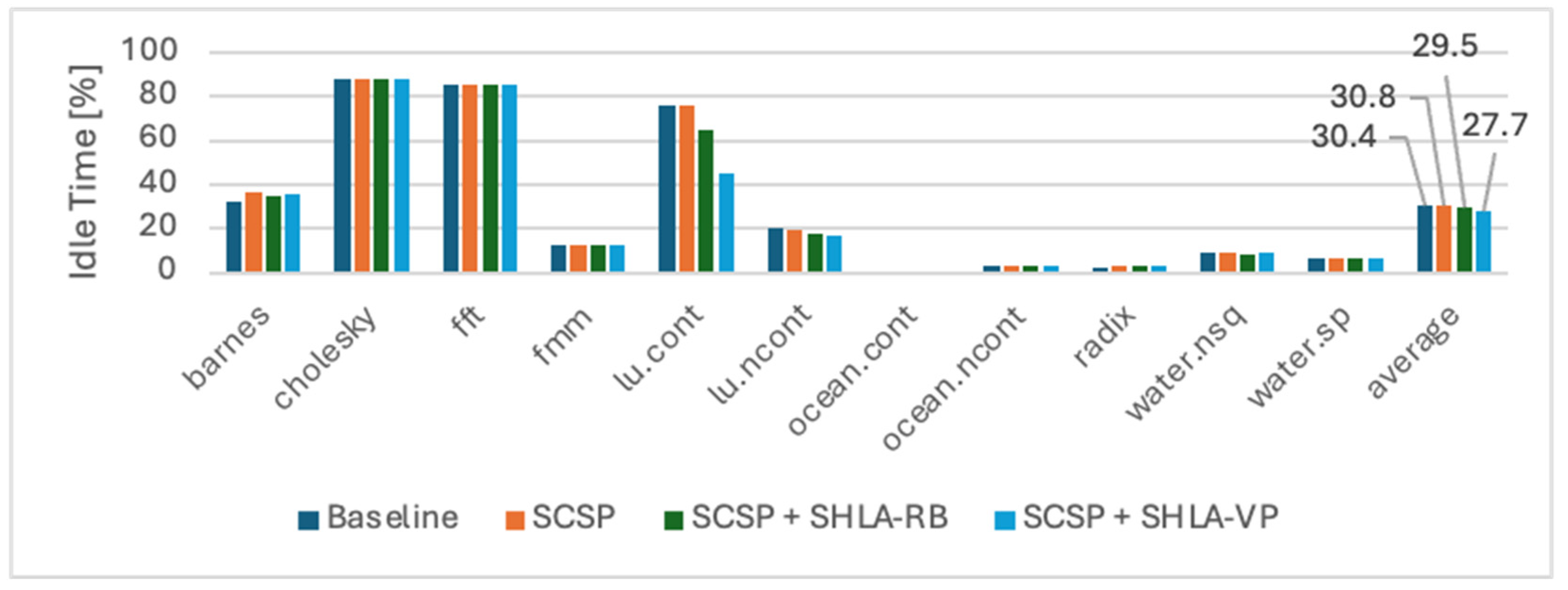
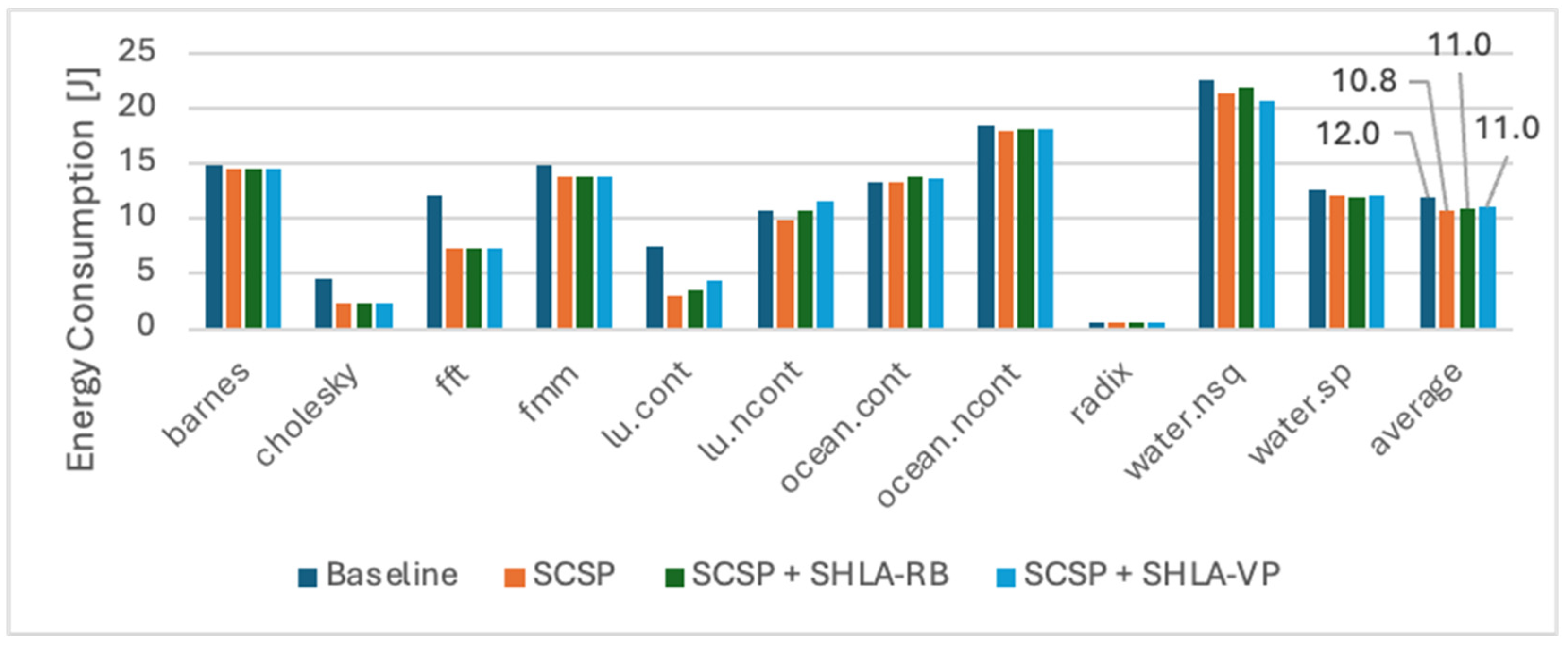
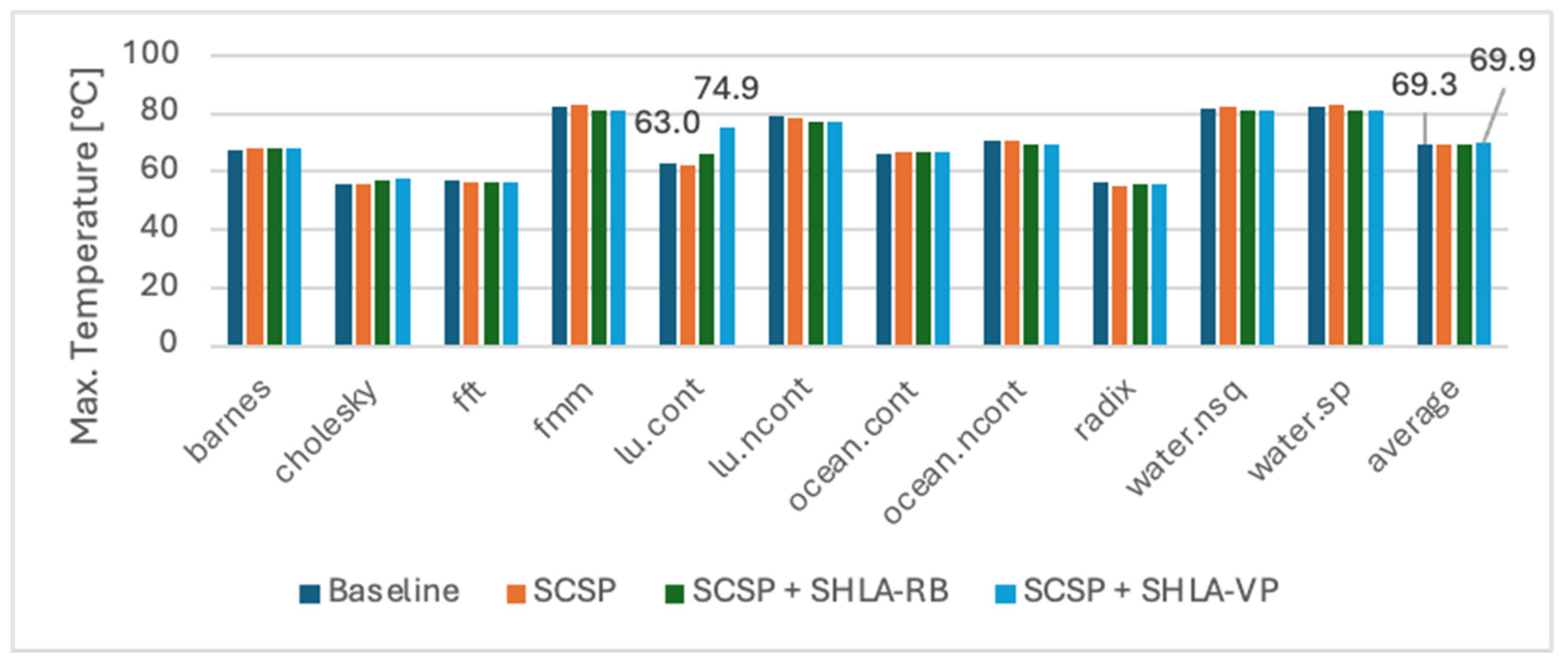
5.2. An Analysis of an Enhanced Architecture with the SCSP
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gomez-Hernandez, E.J.; Cebrian, J.M.; Kaxiras, S.; Ros, A. Splash-4: A Modern Benchmark Suite with Lock-Free Constructs. In Proceedings of the 2022 IEEE International Symposium on Workload Characterization (IISWC), Austin, TX, USA, 6–8 November 2022; pp. 51–64. [Google Scholar] [CrossRef]
- Sankaranarayanan, K.; Velusamy, S.; Stan, M.; Skadron, K. A Case for Thermal-Aware Floorplanning at the Microarchitectural Level. J. Instr.-Level Parallelism 2005, 7, 8–16. [Google Scholar]
- Kim, Y.G.; Kim, M.; Kong, J.; Chung, S.W. An Adaptive Thermal Management Framework for Heterogeneous Multi-Core Processors. IEEE Trans. Comput. 2020, 69, 894–906. [Google Scholar] [CrossRef]
- Kong, J.; Chung, S.W.; Skadron, K. Recent Thermal Management Techniques for Microprocessors. ACM Comput. Surv. 2012, 44, 1–42. [Google Scholar] [CrossRef]
- Woo, S.C.; Ohara, M.; Torrie, E.; Singh, J.P.; Gupta, A. The SPLASH-2 Programs: Characterization and Methodological Considerations. In Proceedings of the 22nd Annual International Symposium on Computer Architecture, Santa Margherita Ligure, Italy, 22–24 June 1995; pp. 24–36. [Google Scholar] [CrossRef]
- Sakalis, C.; Leonardsson, C.; Kaxiras, S.; Ros, A. Splash-3: A Properly Synchronized Benchmark Suite for Contemporary Research. In Proceedings of the 2016 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Uppsala, Sweden, 17–19 April 2016; pp. 101–111. [Google Scholar] [CrossRef]
- Henning, J.L. SPEC CPU2006 Benchmark Descriptions. SIGARCH Comput. Archit. News 2006, 34, 1–17. [Google Scholar] [CrossRef]
- Bucek, J.; Lange, K.-D.; Kistowski, J.V. SPEC CPU2017: Next-Generation Compute Benchmark. In Proceedings of the Companion of the 2018 ACM/SPEC International Conference on Performance Engineering—ICPE ’18, Berlin, Germany, 9–13 April 2018; pp. 41–42. [Google Scholar] [CrossRef]
- Bienia, C. Benchmarking Modern Multiprocessors; Princeton University: Princeton, NJ, USA, 2011. [Google Scholar]
- Miller, J.E.; Kasture, H.; Kurian, G.; Gruenwald, C.; Beckmann, N.; Celio, C.; Eastep, J.; Agarwal, A. Graphite: A Distributed Parallel Simulator for Multicores. In Proceedings of the HPCA-16 2010 The Sixteenth International Symposium on High-Performance Computer Architecture, Bangalore, India, 9–14 January 2010; pp. 1–12. [Google Scholar] [CrossRef]
- Carlson, T.E.; Heirman, W.; Eeckhout, L. Sniper: Exploring the Level of Abstraction for Scalable and Accurate Parallel Multi-Core Simulation. In Proceedings of the 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, Seattle, WA, USA, 12 November 2011; pp. 1–12. [Google Scholar] [CrossRef]
- Genbrugge, D.; Eyerman, S.; Eeckhout, L. Interval Simulation: Raising the Level of Abstraction in Architectural Simulation. In Proceedings of the HPCA-16 2010 The Sixteenth International Symposium on High-Performance Computer Architecture, Bangalore, India, 9–14 January 2010; pp. 1–12. [Google Scholar] [CrossRef]
- Li, S.; Ahn, J.H.; Strong, R.D.; Brockman, J.B.; Tullsen, D.M.; Jouppi, N.P. McPAT: An Integrated Power, Area, and Timing Modeling Framework for Multicore and Manycore Architectures. In Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture-Micro-42, New York, NY, USA, 12–16 December 2009; p. 469. [Google Scholar] [CrossRef]
- Florea, A.; Buduleci, C.; Chis, R.; Gellert, A.; Vintan, L. Enhancing the Sniper Simulator with Thermal Measurement. In Proceedings of the 2014 18th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 17–19 October 2014; pp. 31–36. [Google Scholar] [CrossRef]
- Huang, W.; Ghosh, S.; Velusamy, S.; Sankaranarayanan, K.; Skadron, K.; Stan, M.R. HotSpot: A Compact Thermal Modeling Methodology for Early-Stage VLSI Design. IEEE Trans. VLSI Syst. 2006, 14, 501–513. [Google Scholar] [CrossRef]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The Gem5 Simulator. SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Sodani, A.; Sohi, G.S. Dynamic Instruction Reuse. In Proceedings of the 24th Annual International Symposium on Computer Architecture, Denver, CO, USA, 1–4 June 1997; pp. 194–205. [Google Scholar] [CrossRef]
- Buduleci, C.; Gellert, A.; Florea, A. Selective High-Latency Arithmetic Instruction Reuse in Multicore Processors. In Proceedings of the 2023 27th International Conference on System Theory, Control and Computing (ICSTCC), Timisoara, Romania, 11 October 2023; pp. 410–415. [Google Scholar] [CrossRef]
- Widgen, L.; Sowadsky, E. Operand cache addressed by the instruction address for reducing latency of read instruction. U.S. Patent US5919256A, 06 July 1999. [Google Scholar]
- Gabbay, F.; Mendelson, A. System and method for concurrent processing. U.S. Patent US5996060A, 30 November 1999. [Google Scholar]
- Lipasti, M.H.; Shen, J.P. Exceeding the Dataflow Limit via Value Prediction. In Proceedings of the 29th Annual IEEE/ACM International Symposium on Microarchitecture. MICRO 29, Paris, France, 2–4 December 1996; pp. 226–237. [Google Scholar] [CrossRef]
- Lipasti, M.H.; Wilkerson, C.B.; Shen, J.P. Value Locality and Load Value Prediction. SIGPLAN Not. 1996, 31, 138–147. [Google Scholar] [CrossRef]
- Sazeides, Y.; Smith, J.E. The Predictability of Data Values. In Proceedings of the 30th Annual International Symposium on Microarchitecture, Research Triangle Park, NC, USA, 3–3 December 1997; pp. 248–258. [Google Scholar] [CrossRef]
- Buduleci, C.; Gellert, A.; Florea, A.; Brad, R. Improving Multicore Architectures by Selective Value Prediction of High-Latency Arithmetic Instructions. Adv. Electr. Comput. Eng. 2024; submitted. [Google Scholar]
- Bircher, W.L.; John, L.K. Core-Level Activity Prediction for Multicore Power Management. IEEE J. Emerg. Sel. Top. Circuits Syst. 2011, 1, 218–227. [Google Scholar] [CrossRef]
- Acun, B.; Chandrasekar, K.; Kale, L.V. Fine-Grained Energy Efficiency Using Per-Core DVFS with an Adaptive Runtime System. In Proceedings of the 2019 Tenth International Green and Sustainable Computing Conference (IGSC), Alexandria, VA, USA, 21–24 October 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Halimi, J.-P.; Pradelle, B.; Guermouche, A.; Triquenaux, N.; Laurent, A.; Beyler, J.C.; Jalby, W. Reactive DVFS Control for Multicore Processors. In Proceedings of the 2013 IEEE International Conference on Green Computing and Communications and IEEE Internet of Things and IEEE Cyber, Physical and Social Computing, Beijing, China, 20–23 August 2013; pp. 102–109. [Google Scholar] [CrossRef]
- Lu, T.; Pande, P.P.; Shirazi, B. A Dynamic, Compiler Guided DVFS Mechanism to Achieve Energy-Efficiency in Multi-Core Processors. Sustain. Comput. Inform. Syst. 2016, 12, 1–9. [Google Scholar] [CrossRef]
- Kim, S.; Eom, H.; Yeom, H.Y.; Min, S.L. Energy-Centric DVFS Controlling Method for Multi-Core Platforms. Computing 2014, 96, 1163–1177. [Google Scholar] [CrossRef]
- Curtis-Maury, M.; Shah, A.; Blagojevic, F.; Nikolopoulos, D.S.; De Supinski, B.R.; Schulz, M. Prediction Models for Multi-Dimensional Power-Performance Optimization on Many Cores. In Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques, Toronto, ON, Canada, 25 October 2008; pp. 250–259. [Google Scholar] [CrossRef]
- Cai, Q.; Gonzalez, J.; Magklis, G.; Chaparro, P.; Gonzalez, A. Thread Shuffling: Combining DVFS and Thread Migration to Reduce Energy Consumptions for Multi-Core Systems. In Proceedings of the IEEE/ACM International Symposium on Low Power Electronics and Design, Fukuoka, Japan, 1–3 August 2011; pp. 379–384. [Google Scholar] [CrossRef]
- Gupta, M.; Bhargava, L.; Indu, S. Dynamic Workload-Aware DVFS for Multicore Systems Using Machine Learning. Computing 2021, 103, 1747–1769. [Google Scholar] [CrossRef]
- Basireddy, K.R.; Singh, A.K.; Al-Hashimi, B.M.; Merrett, G.V. AdaMD: Adaptive Mapping and DVFS for Energy-Efficient Heterogeneous Multicores. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 2206–2217. [Google Scholar] [CrossRef]
- Hanumaiah, V.; Vrudhula, S. Temperature-Aware DVFS for Hard Real-Time Applications on Multicore Processors. IEEE Trans. Comput. 2012, 61, 1484–1494. [Google Scholar] [CrossRef]
- Calborean, H. Multi-Objective Optimization of Advanced Computer Architectures Using Domain-Knowledge. Ph.D. Thesis, “Lucian Blaga” University of Sibiu, Sibiu, Romania, 2011. [Google Scholar]
- Mkaouer, W.; Kessentini, M.; Shaout, A.; Koligheu, P.; Bechikh, S.; Deb, K.; Ouni, A. Many-Objective Software Remodularization Using NSGA-III. ACM Trans. Softw. Eng. Methodol. 2015, 24, 1–45. [Google Scholar] [CrossRef]
- Fathollahi-Fard, A.M.; Hajiaghaei-Keshteli, M.; Tavakkoli-Moghaddam, R. Red Deer Algorithm (RDA): A New Nature-Inspired Meta-Heuristic. Soft Comput. 2020, 24, 14637–14665. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Florea, A.; Cofaru, I.; Patrausanu, A.; Cofaru, N.; Fiore, U. Superposition of Populations in Multi-Objective Evolutionary Optimization of Car Suspensions. Eng. Appl. Artif. Intell. 2023, 126, 107026. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
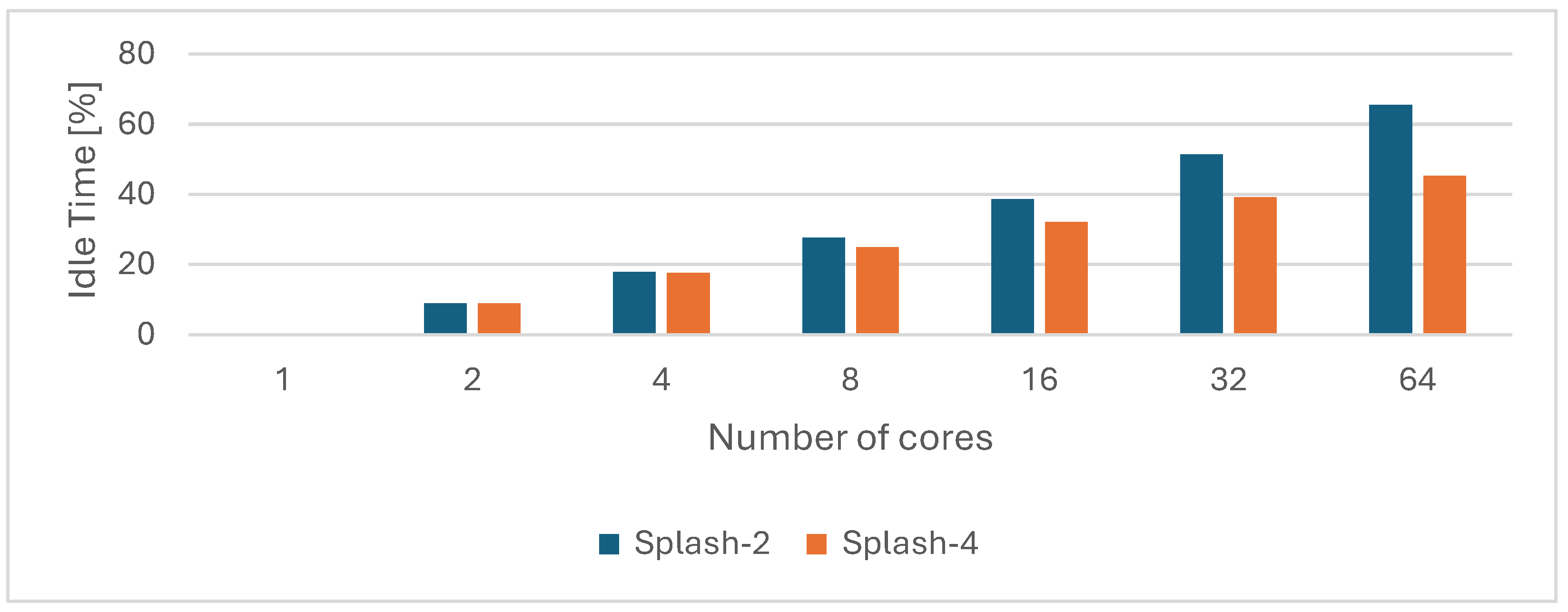{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Intel Nehalem (Gainestown) | ||
|---|---|---|
| Parameter Name | Value | |
| L3 Cache (Shared) | Size | 8192 KB |
| Associativity | 16 | |
| L2 Cache | Size | 256 KB |
| Associativity | 8 | |
| L1 Data Cache | Size | 32 KB |
| Associativity | 8 | |
| L1 Instruction Cache | Size | 32 KB |
| Associativity | 4 | |
| Frequency | 2.66 GHz | |
| Number of cores | 4 | |
| DRAM associativity | 32 | |
| Parameter Name | Value | |
|---|---|---|
| VP | Associativity | 4 |
| Num. entries | 512 | |
| History | 1 | |
| Penalty latency | 17 cycles | |
| Access latency | 1 cycle | |
| Block size | 16 B | |
| Size | 8 KB |
| Parameter Name | Value | |
|---|---|---|
| DIR | Associativity | 4 |
| Num. entries | 512 | |
| Access latency | 1 cycle | |
| Block size | 64 B | |
| Size | 32 KB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buduleci, C.; Gellert, A.; Florea, A.; Brad, R. Architectural and Technological Approaches for Efficient Energy Management in Multicore Processors. Computers 2024, 13, 84. https://doi.org/10.3390/computers13040084
Buduleci C, Gellert A, Florea A, Brad R. Architectural and Technological Approaches for Efficient Energy Management in Multicore Processors. Computers. 2024; 13(4):84. https://doi.org/10.3390/computers13040084
Chicago/Turabian StyleBuduleci, Claudiu, Arpad Gellert, Adrian Florea, and Remus Brad. 2024. "Architectural and Technological Approaches for Efficient Energy Management in Multicore Processors" Computers 13, no. 4: 84. https://doi.org/10.3390/computers13040084
APA StyleBuduleci, C., Gellert, A., Florea, A., & Brad, R. (2024). Architectural and Technological Approaches for Efficient Energy Management in Multicore Processors. Computers, 13(4), 84. https://doi.org/10.3390/computers13040084