Conceiving Human Interaction by Visualising Depth Data of Head Pose Changes and Emotion Recognition via Facial Expressions †


{kind=link}
{kind=link}
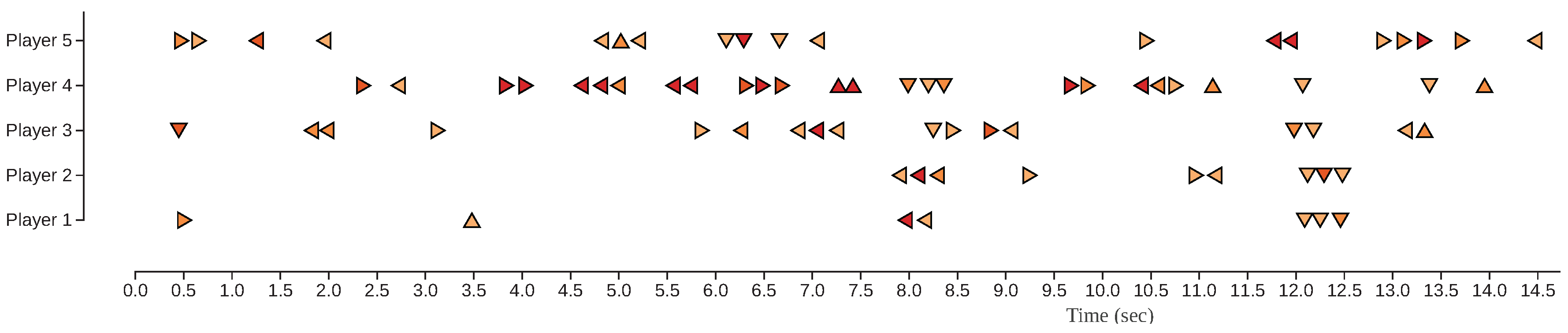{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Overview of Methods for Capturing Head Pose and Emotion Changes
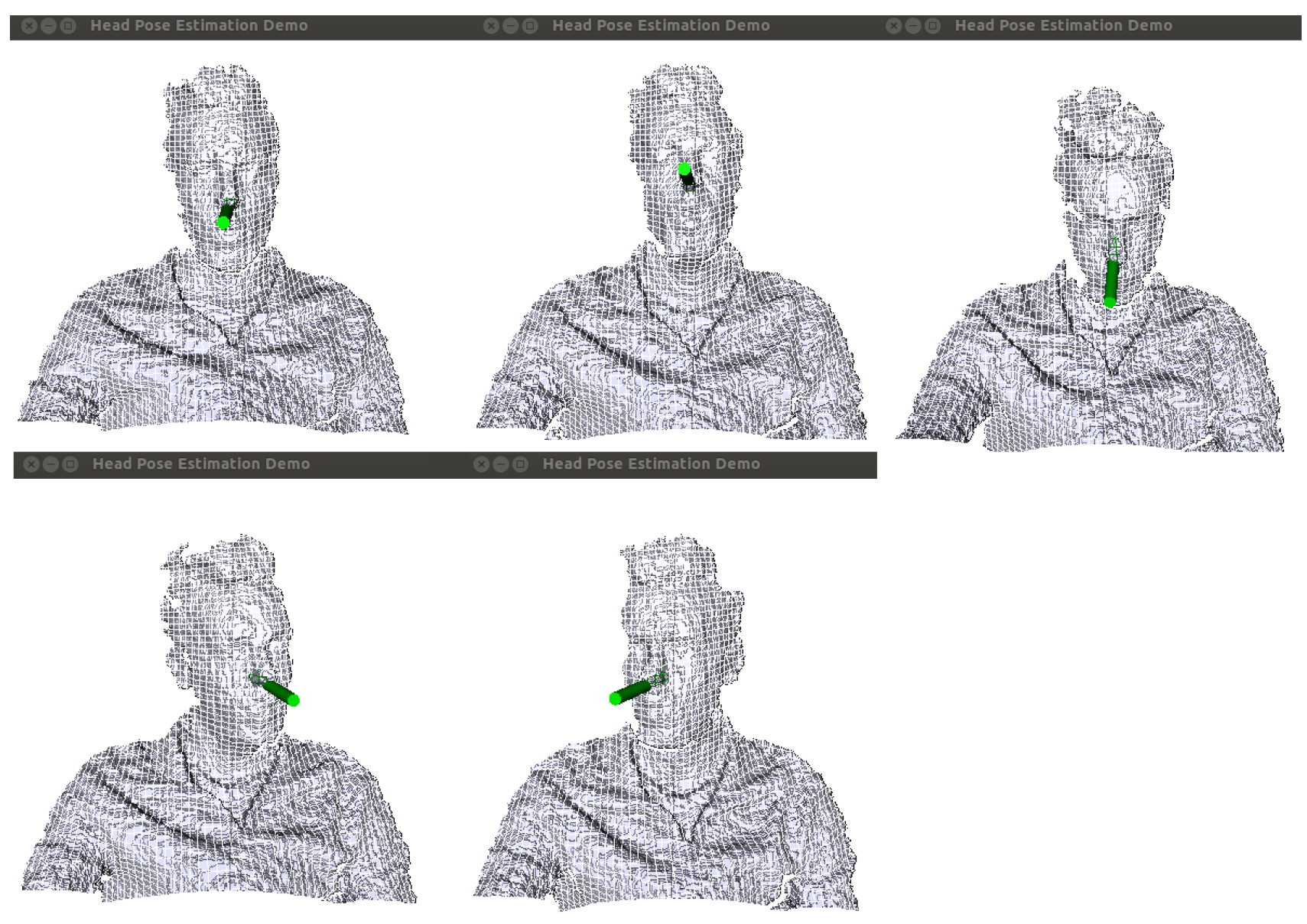
3.1. Estimation of Head Pose Changes
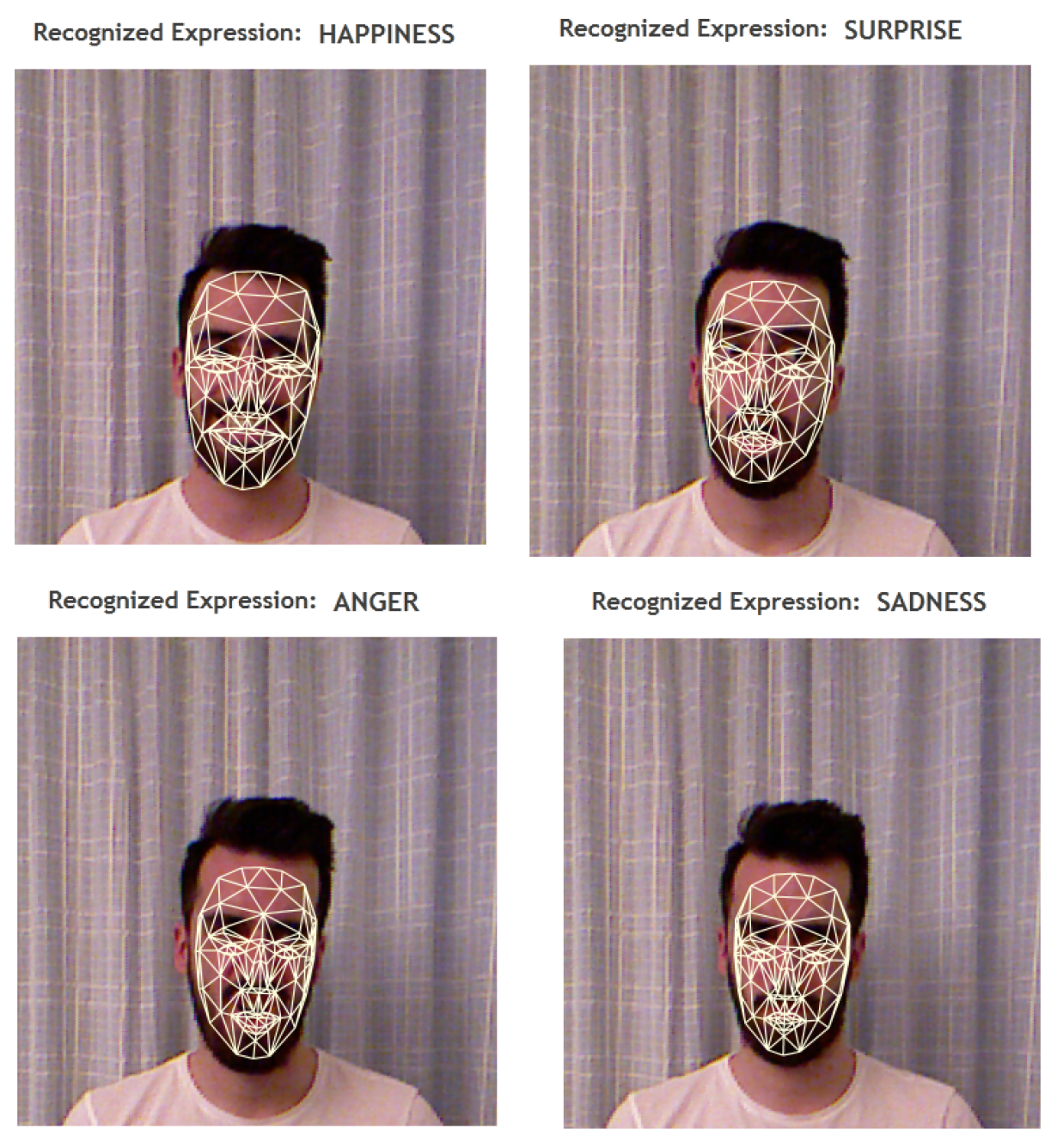
3.2. Emotion Recognition from Facial Expressions
3.3. Data Compilation and Experimental Setup
4. Visualisations on the Web
4.1. Representative Scenario
4.2. Head Pose
4.2.1. Head Pose Changes across Time
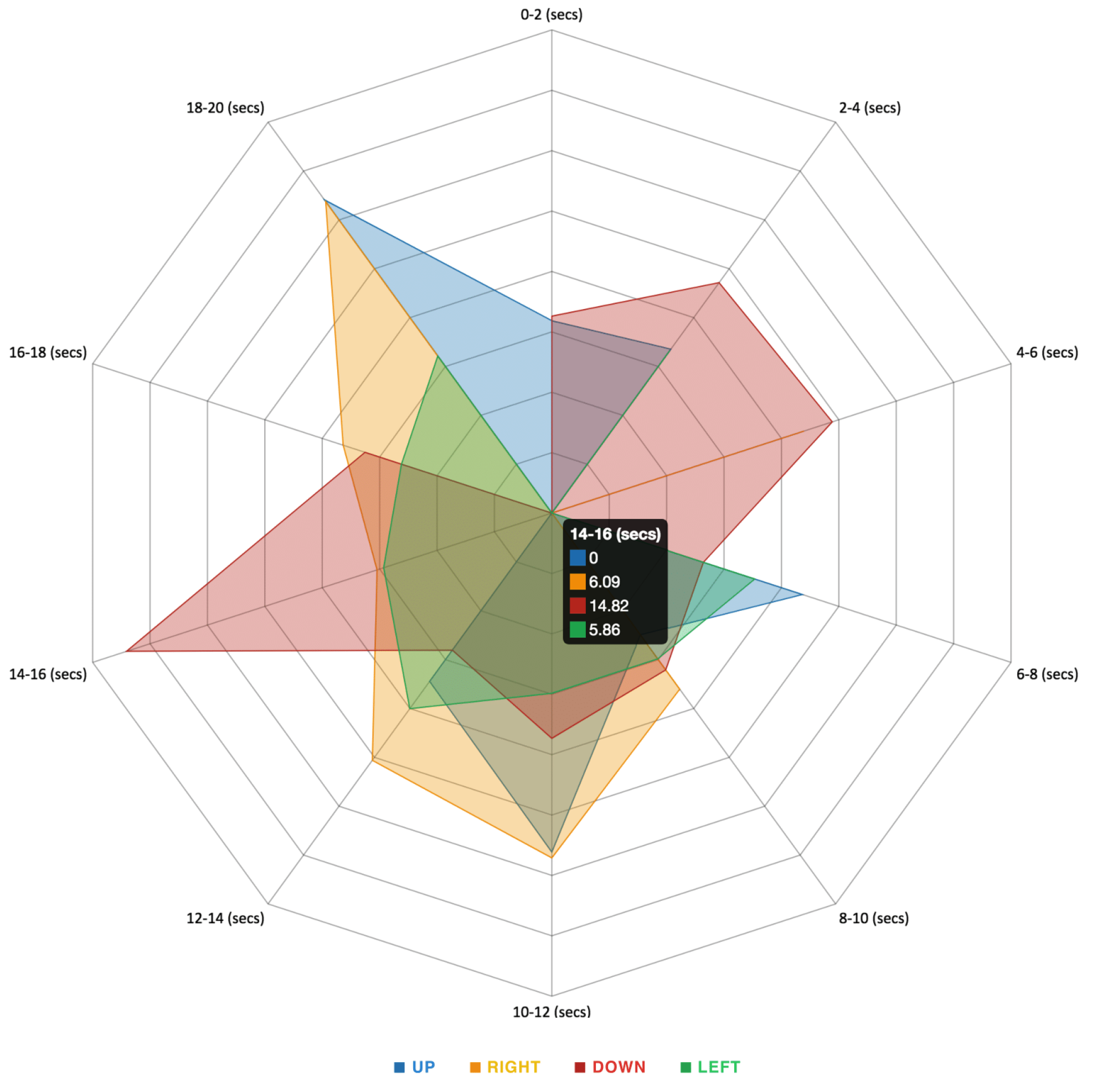
4.2.2. Head Pose Changes Grouped by Direction
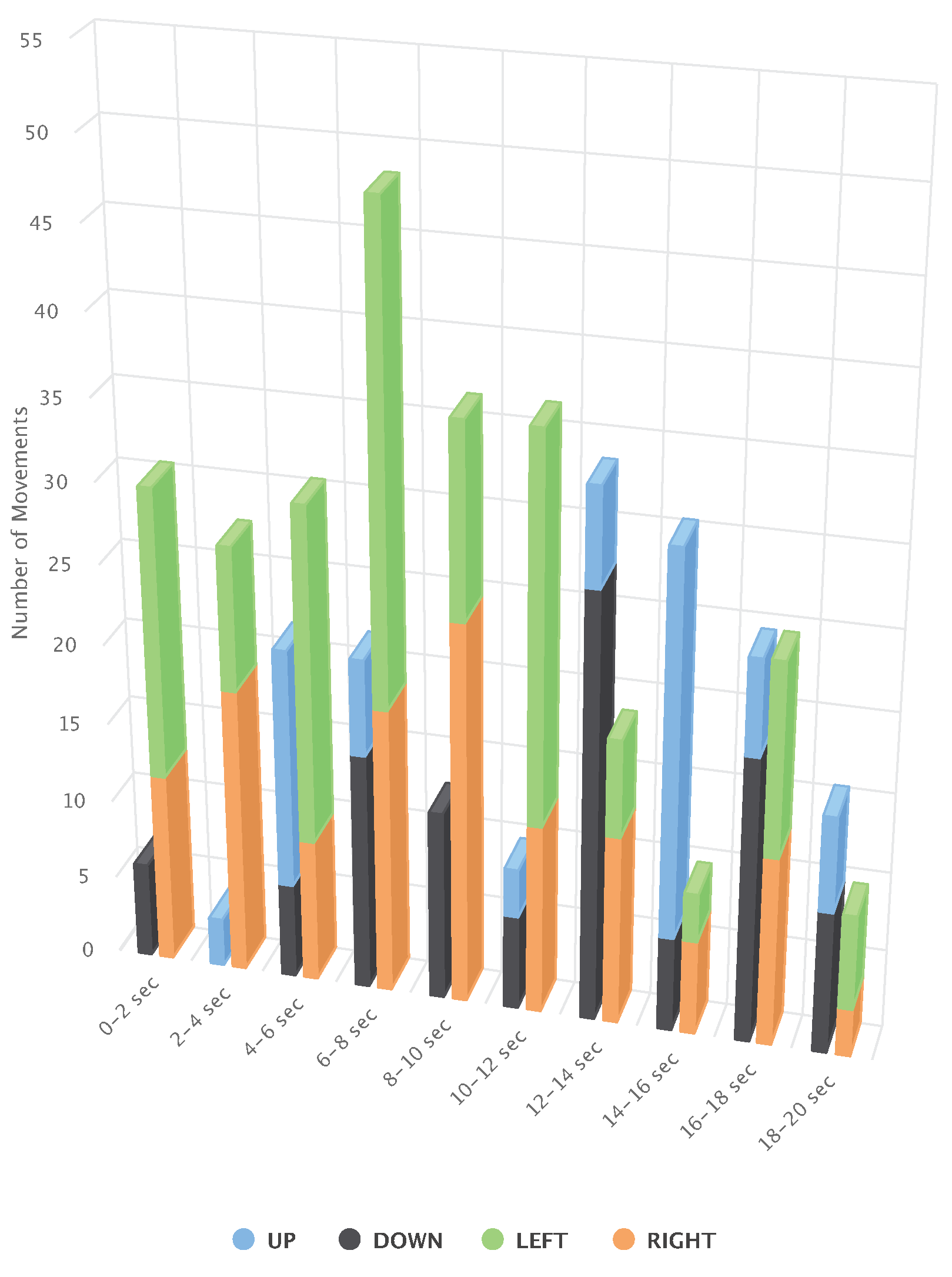
4.2.3. Intensities of Head Pose Changes
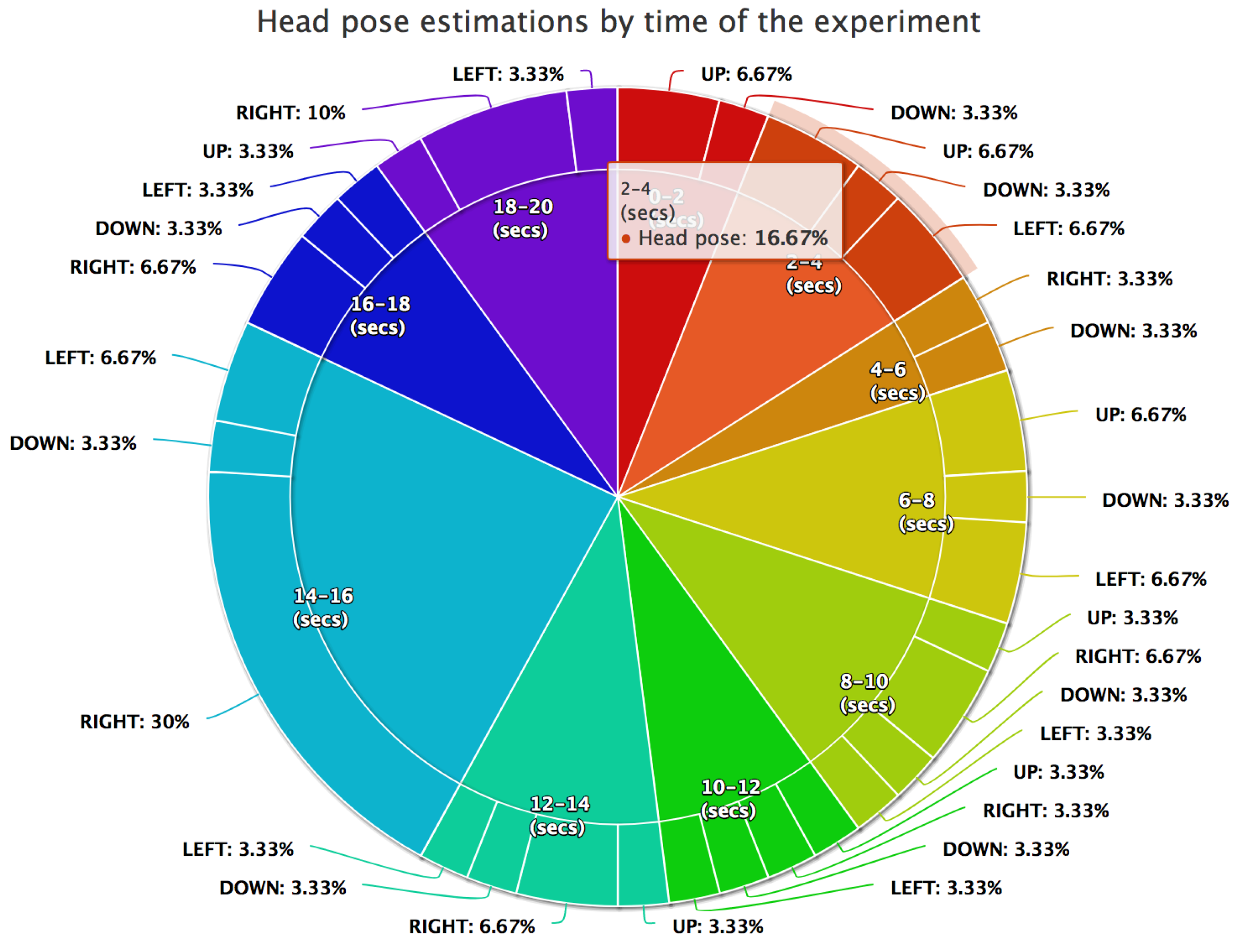
4.2.4. Head Pose Changes Grouped by Proportion of the Direction
4.3. Emotions
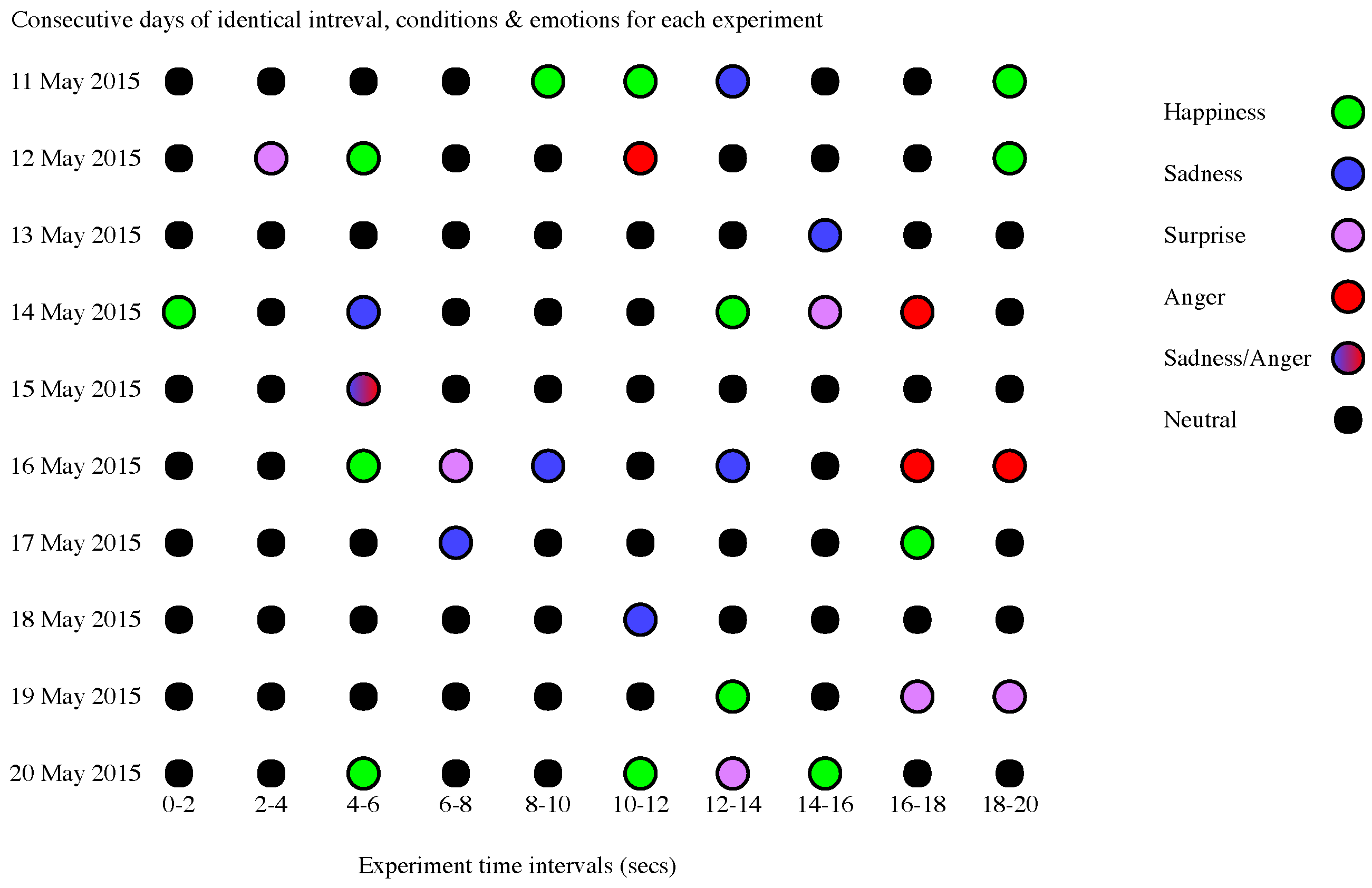
4.3.1. Emotion Changes across Time
4.3.2. Facial Expressions Grouped by Emotion
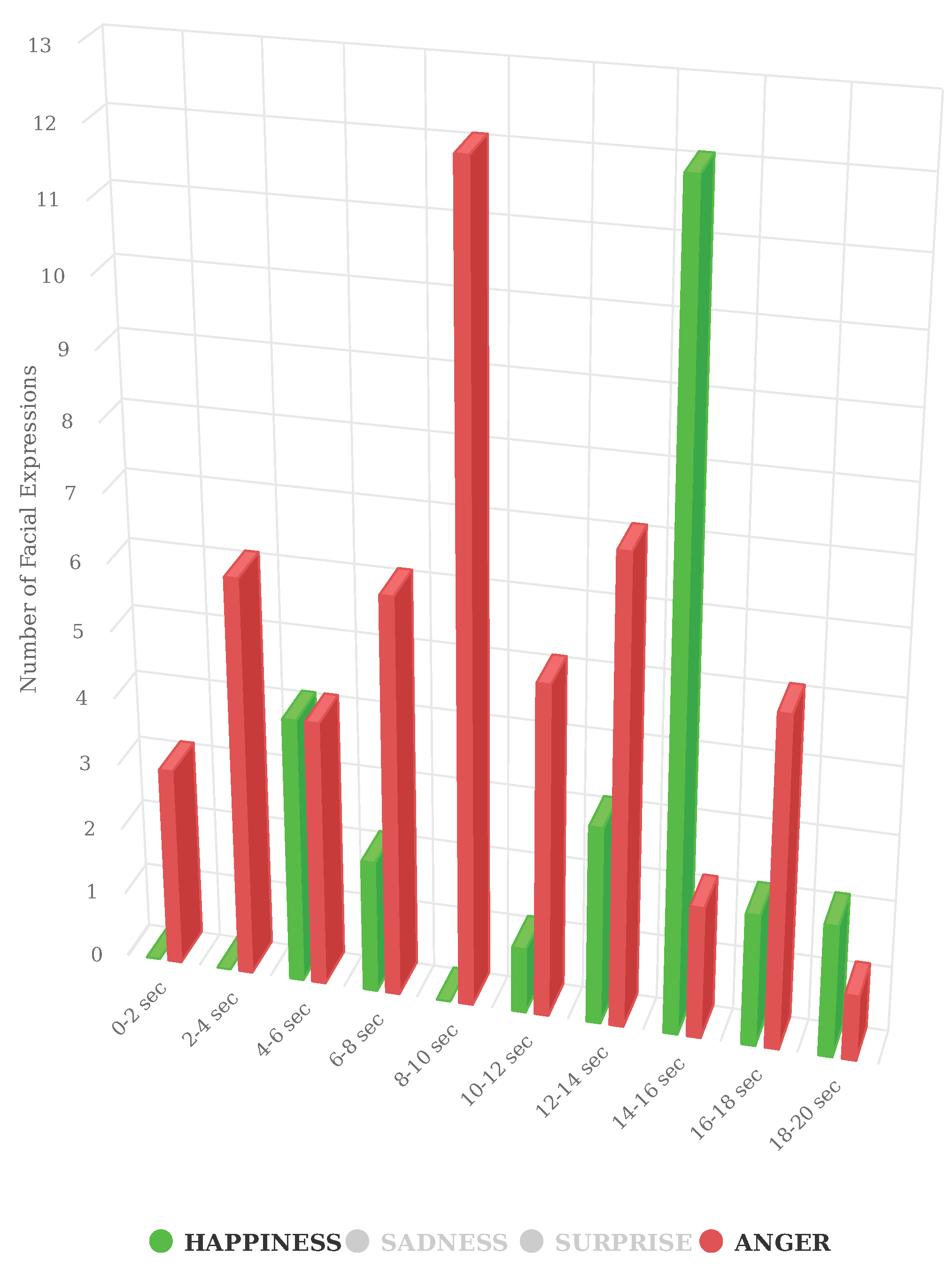
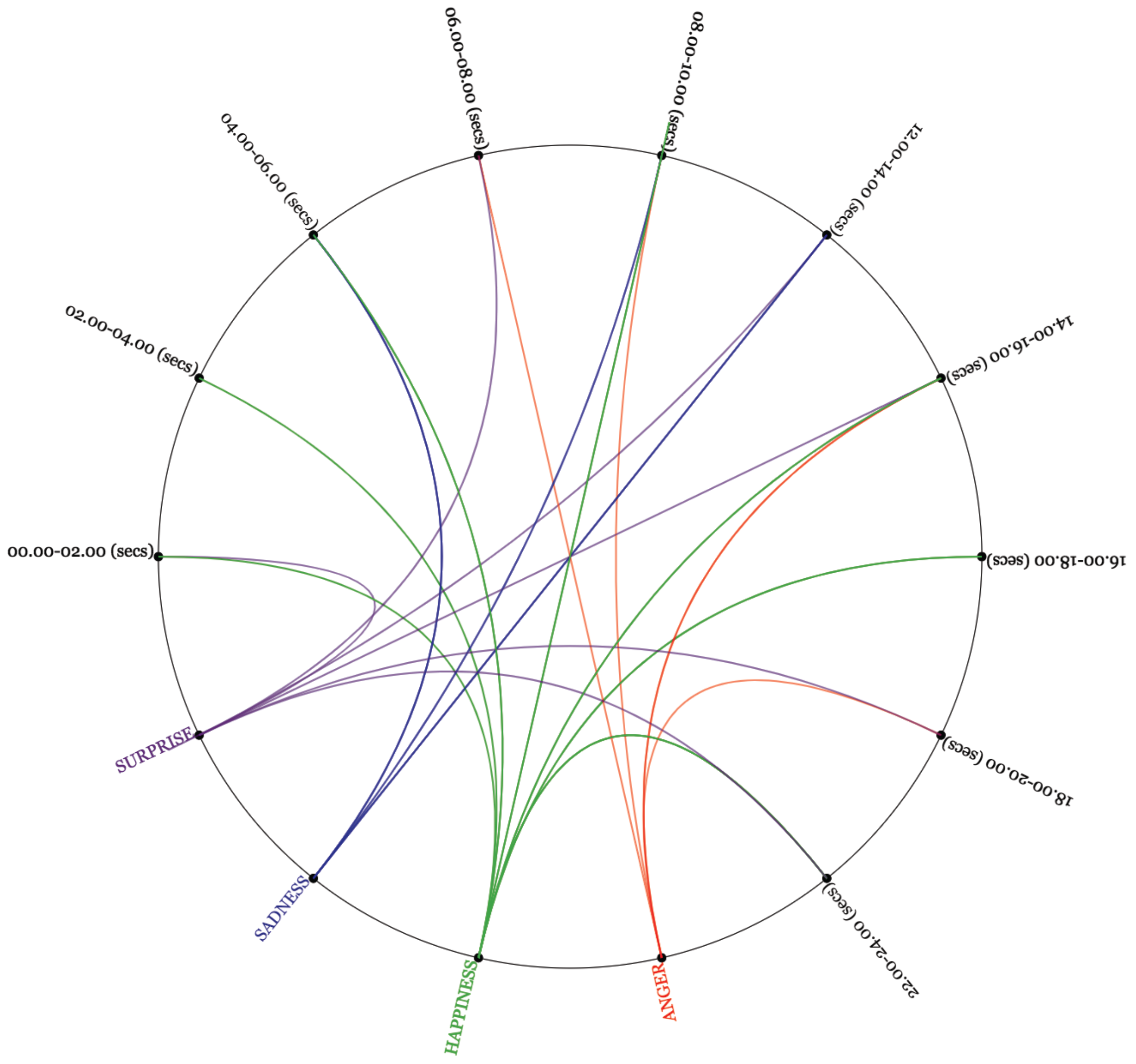
4.3.3. Emotions Grouped by Time Intervals
5. Conclusions and Future Work
Author Contributions
Conflicts of Interest
References
- Kalliatakis, G.; Vidakis, N.; Triantafyllidis, G. Web-based visualisation of head pose and facial expressions changes: Monitoring human activity using depth data. In Proceedings of the 8th Computer Science and Electronic Engineering (CEEC), Colchester, UK, 28–30 September 2016; pp. 48–53. [Google Scholar] [CrossRef]
- Kalliatakis, G.; Triantafyllidis, G.; Vidakis, N. Head pose 3D data web-based visualization. In Proceedings of the 20th International Conference on 3D Web Technology (Web3D ’15), Heraklion, Greece, 18–21 June 2015; ACM: New York, NY, USA, 2015; pp. 167–168. [Google Scholar] [CrossRef]
- Murphy-Chutorian, E.; Trivedi, M.M. Head Pose Estimation in Computer Vision: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 607–626. [Google Scholar] [CrossRef] [PubMed]
- Breitenstein, M.D.; Kuettel, D.; Weise, T.; van Gool, L.; Pfister, H. Real-time face pose estimation from single range images. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Fanelli, G.; Gall, J.; Van Gool, L. Real time head pose estimation with random regression forests. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 617–624. [Google Scholar] [CrossRef]
- Padeleris, P.; Zabulis, X.; Argyros, A.A. Head pose estimation on depth data based on Particle Swarm Optimization. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 42–49. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, H.; Zha, H. Modeling facial expression space for recognition. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 1968–1973. [Google Scholar] [CrossRef]
- Anil, J.K.; Li, S.Z. Handbook of Face Recognition; Springer: New York, NY, USA, 2011. [Google Scholar]
- Fang, T.; Xi, Z.; Ocegueda, O.; Shah, S.K.; Kakadiaris, I.A. 3D facial expression recognition: A perspective on promises and challenges. In Proceedings of the 2011 IEEE International Conference on Automatic Face & Gesture Recognition and Workshops (FG 2011), Santa Barbara, CA, USA, 21–25 March 2011; pp. 603–610. [Google Scholar]
- Xue, M.; Mian, A.; Liu, W.; Li, L. Fully automatic 3D facial expression recognition using local depth features. In Proceedings of the 2014 IEEE Winter Conference Applications of Computer Vision (WACV), Steamboat Springs, CO, USA, 24–26 March 2014; pp. 1096–1103. [Google Scholar]
- Azazi, A.; Lutfi, S.L.; Venkat, I. Analysis and evaluation of SURF descriptors for automatic 3D facial expression recognition using different classifiers. In Proceedings of the 2014 Fourth World Congress on Information and Communication Technologies (WICT), Malacca, Malaysia, 8–10 December 2014; pp. 23–28. [Google Scholar]
- Kim, B.-K.; Roh, J.; Dong, S.-Y.; Lee, S.-Y. Hierarchical committee of deep convolutional neural networks for robust facial expression recognition. J. Multimodal User Interfaces 2016, 2, 173–189. [Google Scholar] [CrossRef]
- Zhen, Q.; Huang, D.; Wang, Y.; Chen, L. Muscular Movement Model-Based Automatic 3D/4D Facial Expression Recognition. IEEE Trans. Multimed. 2016, 18, 1438–1450. [Google Scholar] [CrossRef]
- Siddiqi, M.H.; Ali, R.; Khan, A.M.; Kim, E.S.; Kim, G.J.; Lee, S. Facial expression recognition using active contour-based face detection, facial movement-based feature extraction, and non-linear feature selection. Multimed. Syst. 2015, 21, 541–555. [Google Scholar] [CrossRef]
- Fang, T.; Zhao, X.; Ocegueda, O.; Shah, S.K.; Kakadiaris, I.A. 3D/4D facial expression analysis: An advanced annotated face model approach. Image Vis. Comput. 2012, 30, 738–749. [Google Scholar] [CrossRef]
- Mulrow, E.J. The visual display of quantitative information. Technometrics 2002, 44, 400. [Google Scholar] [CrossRef]
- Jang, Y.M.; Mallipeddi, R.; Lee, S.; Kwak, H.W.; Lee, M. Human intention recognition based on eyeball movement pattern and pupil size variation. Neurocomputing 2014, 128, 421–432. [Google Scholar] [CrossRef]
- Youn, S.-J.; Oh, K.-W. Intention recognition using a graph representation. World Acad. Sci. Eng. Technol. 2007, 25, 13–18. [Google Scholar]
- Vidakis, N.; Vlasopoulos, A.; Kounalakis, T.; Varchalamas, P.; Dimitriou, M.; Kalliatakis, G.; Syntychakis, E.; Christofakis, J.; Triantafyllidis, G. Multimodal desktop interaction: The face-object-gesture-voice example. In Proceedings of the 2013 18th IEEE International Conference on Digital Signal Processing (DSP), Fira, Greece, 1–3 July 2013; pp. 1–8. [Google Scholar]
- Vidakis, N.; Syntychakis, E.; Kalafatis, K.; Christinaki, E.; Triantafyllidis, G. Ludic Educational Game Creation Tool: Teaching Schoolers Road Safety. In Proceedings of the 9th International Conference on Universal Access in Human-Computer Interaction, Los Angeles, CA, USA, 2–7 August 2015; Springer: Cham, Switzerland, 2015; pp. 565–576. [Google Scholar]
- Vidakis, N.; Christinaki, E.; Serafimidis, I.; Triantafyllidis, G. Combining ludology and narratology in an open authorable framework for educational games for children: The scenario of teaching preschoolers with autism diagnosis. In Proceedings of the International Conference on Universal Access in Human-Computer Interaction, Heraklion, Greece, 22–27 June 2014; Springer: Cham, Switzerland, 2014; pp. 626–636. [Google Scholar]
- Schurgin, M.W.; Nelson, J.; Iida, S.; Ohira, H.; Chiao, J.Y.; Franconeri, S.L. Eye movements during emotion recognition in faces. J. Vis. 2014, 14, 14. [Google Scholar] [CrossRef] [PubMed]
- Salgado, A. The facial and vocal expression in singers: A cognitive feedback study for improving emotional expression in solo vocal music performance. Electr. Musicol. Rev. 2005, 9. [Google Scholar]
- Neidle, C.; Liu, J.; Liu, B.; Peng, X.; Vogler, C.; Metaxas, D. Computer-based tracking, analysis, and visualization of linguistically significant nonmanual events in American Sign Language (ASL). In Proceedings of the LREC Workshop on the Representation and Processing of Sign Languages: Beyond the Manual Channel, Reykjavik, Iceland, 31 May 2014; Volume 5, pp. 127–134. [Google Scholar]
- Patwardhan, A. Edge Based Grid Super-Imposition for Crowd Emotion Recognition. Int. Res. J. Eng. Technol. 2016, 3, 459–463. [Google Scholar]
- Alioua, N.; Amine, A.; Bensrhair, A.; Rziza, M. Estimating driver head pose using steerable pyramid and probabilistic learning. Int. J. Comput. Vis. Robot. 2015, 5, 347–364. [Google Scholar] [CrossRef]
- Vatahska, T.; Bennewitz, M.; Behnke, S. Feature-based head pose estimation from images. In Proceedings of the 2007 7th IEEE-RAS International Conference on Humanoid Robots, Pittsburgh, PA, USA, 29 November–1 December 2007; pp. 330–335. [Google Scholar]
- Kalliatakis, G. Towards an Automatic Intelligible Monitoring of Behavioral and Physiological Metrics of User Experience: Head Pose Estimation and Facial Expression Recognition. Master’s Thesis, Department of Applied Informatics and Multimedia, School of Applied Technology, Technological Educational Institute of Creece, Athens, Creece, August 2015. [Google Scholar]
- Fanelli, G.; Weise, T.; Gall, J.; Van Gool, L. Real time head pose estimation from consumer depth cameras. In Joint Pattern Recognition Symposium; Springer: Berlin/Heidelberg, Germany, 2011; pp. 101–110. [Google Scholar]
- Fanelli, G.; Dantone, M.; Gall, J.; Fossati, A.; Van Gool, L. Random forests for real time 3D face analysis. Int. J. Comput. Vis. 2013, 101, 437. [Google Scholar] [CrossRef]
- Tian, Y.-I.; Kanade, T.; Cohn, J.F. Recognizing action units for facial expression analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 97–115. [Google Scholar] [CrossRef] [PubMed]
- Mao, Q.-R.; Pan, X.-Y.; Zhan, Y.-Z.; Shen, X.-J. Using Kinect for real-time emotion recognition via facial expressions. Front. Inf. Technol. Electr. Eng. 2015, 16, 272–282. [Google Scholar] [CrossRef]
- Microsoft, Face Tracking SDK Documentation. Available online: https://msdn.microsoft.com/en-us/library/jj130970.aspx (accessed on 30 May 2017).
- Ahlberg, J. Candide-3-An Updated Parameterised Face. 2001. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.33.5603rep=rep1type=pdf (accessed on 21 July 2017).
- Lin, B.; Chen, Y.; Chen, X.; Yu, Y. Comparison between JSON and XML in Applications Based on AJAX. In Proceedings of the 2012 IEEE International Conference on Computer Science and Service System (CSSS), Nanjing, China, 11–13 August 2012; pp. 1174–1177. [Google Scholar]









© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kalliatakis, G.; Stergiou, A.; Vidakis, N. Conceiving Human Interaction by Visualising Depth Data of Head Pose Changes and Emotion Recognition via Facial Expressions. Computers 2017, 6, 25. https://doi.org/10.3390/computers6030025
Kalliatakis G, Stergiou A, Vidakis N. Conceiving Human Interaction by Visualising Depth Data of Head Pose Changes and Emotion Recognition via Facial Expressions. Computers. 2017; 6(3):25. https://doi.org/10.3390/computers6030025
Chicago/Turabian StyleKalliatakis, Grigorios, Alexandros Stergiou, and Nikolaos Vidakis. 2017. "Conceiving Human Interaction by Visualising Depth Data of Head Pose Changes and Emotion Recognition via Facial Expressions" Computers 6, no. 3: 25. https://doi.org/10.3390/computers6030025
APA StyleKalliatakis, G., Stergiou, A., & Vidakis, N. (2017). Conceiving Human Interaction by Visualising Depth Data of Head Pose Changes and Emotion Recognition via Facial Expressions. Computers, 6(3), 25. https://doi.org/10.3390/computers6030025