An Efficient Group-Based Control Signalling within Proxy Mobile IPv6 Protocol

 , and
, and
Abstract
:1. Introduction
- A novel efficient clustering mechanism is introduced for grouping MNs moving simultaneously before processing their handoffs.
- A new mechanism is proposed for simultaneously manipulating the mobility-related signalling for a group of MNs that are triggering their handoff at the same time.
- A numerical analysis was performed to test the performance of E-CPMIPv6 in terms of the handoff latency, the analysis was validated by extensive simulations.
2. Mobility-Related Study
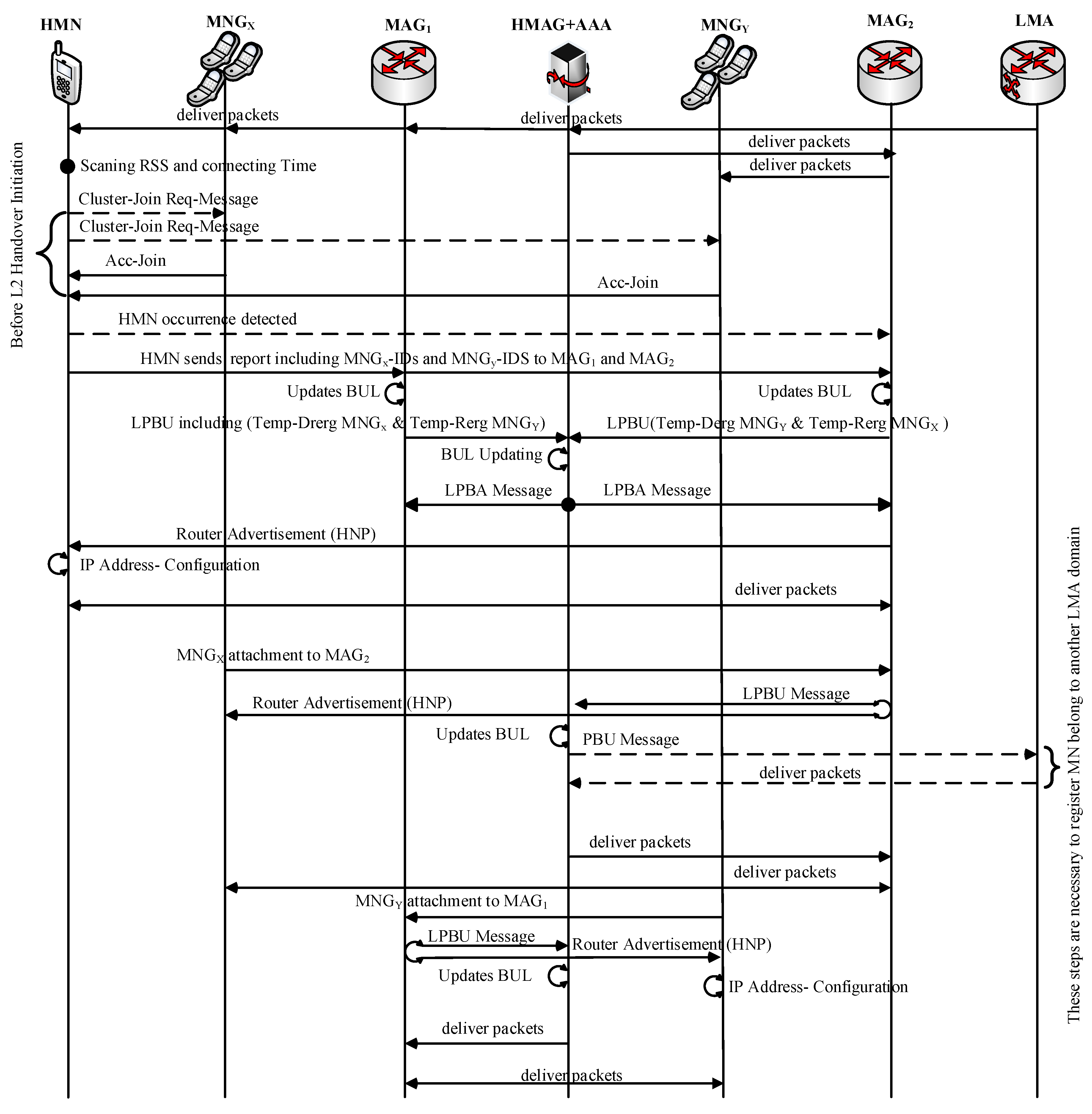
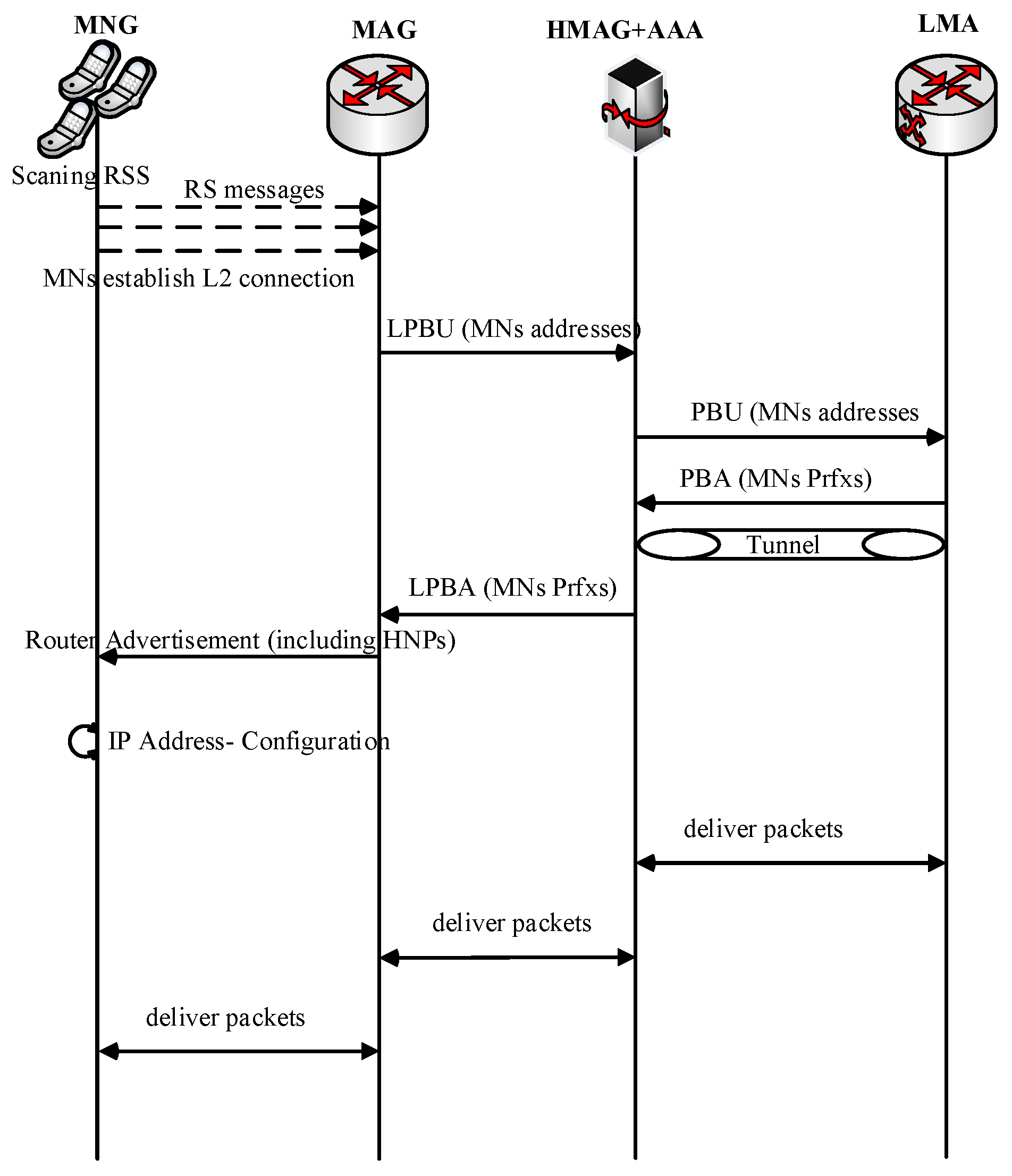
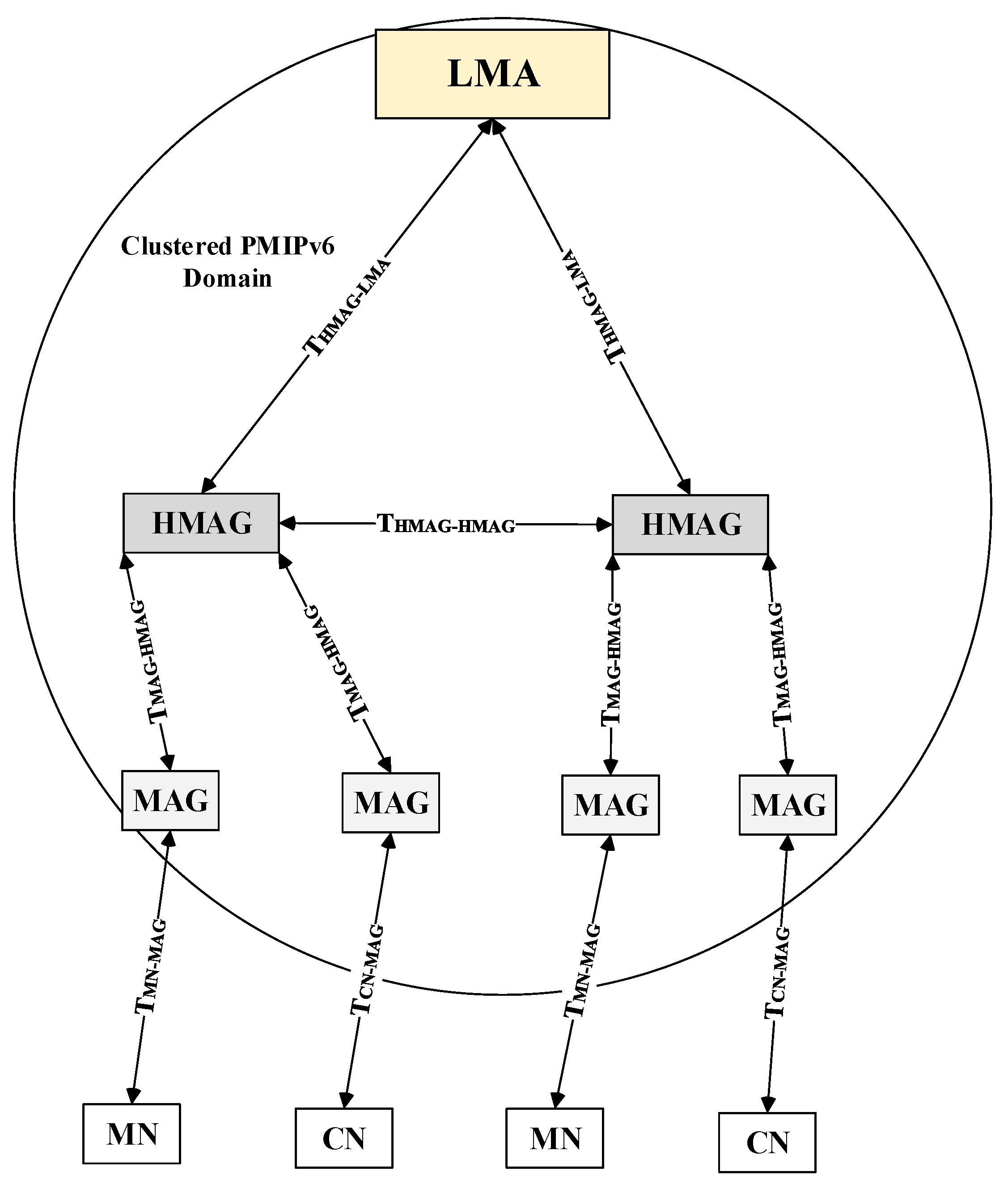
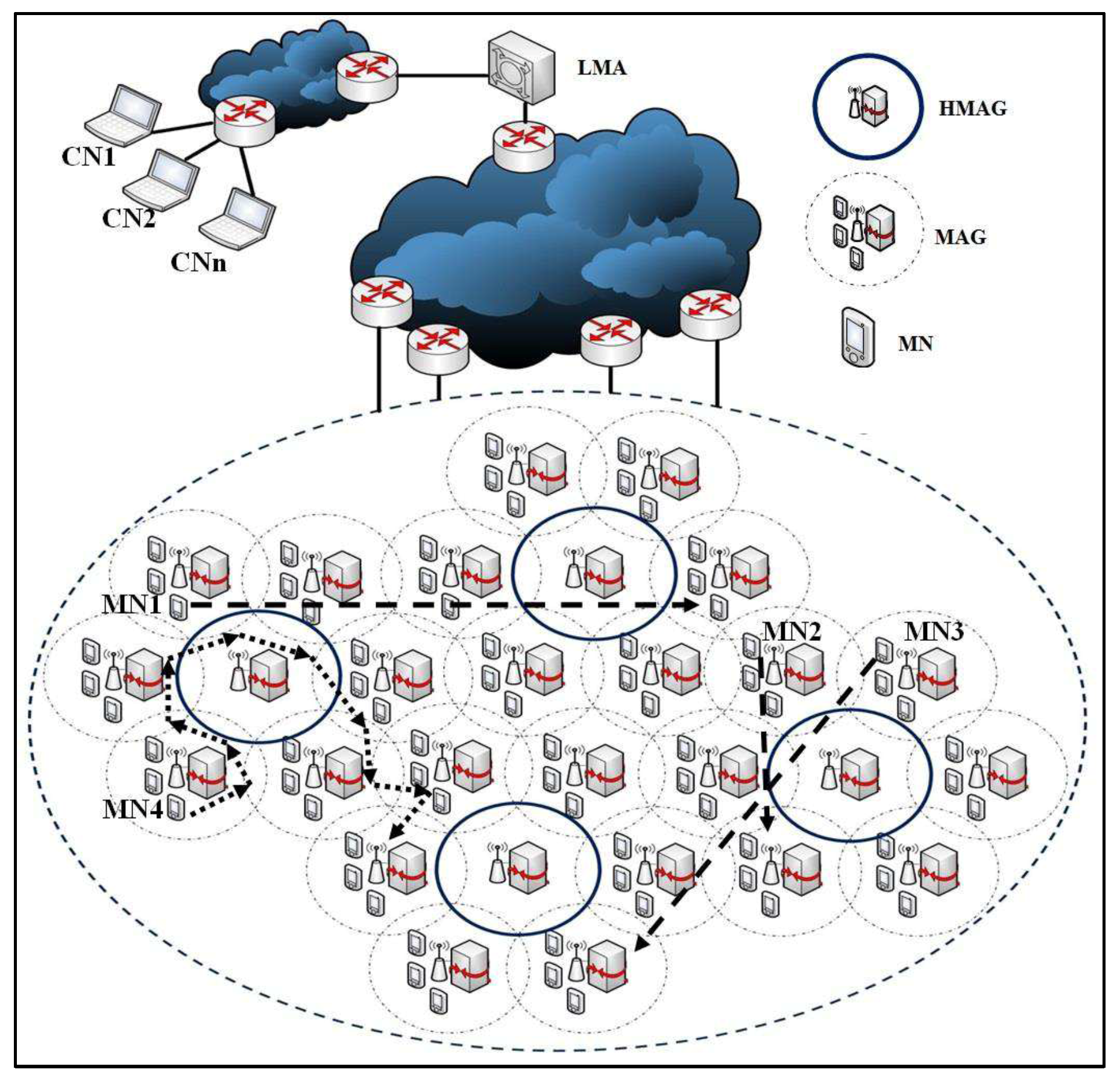
3. The Proposed E-CSPMIPv6 Scheme
| Algorithm 1: HMN functionalities. |
 |
| Algorithm 2: MAG, HMAG and LMA functionalities based on the CN-MN mechanism. |
 |
| Algorithm 3: MAG, HMAG and LMA functionalities based on the CR-MN mechanism. |
 |
The Flow Diagram of the E-CSPMIPv6 Scheme
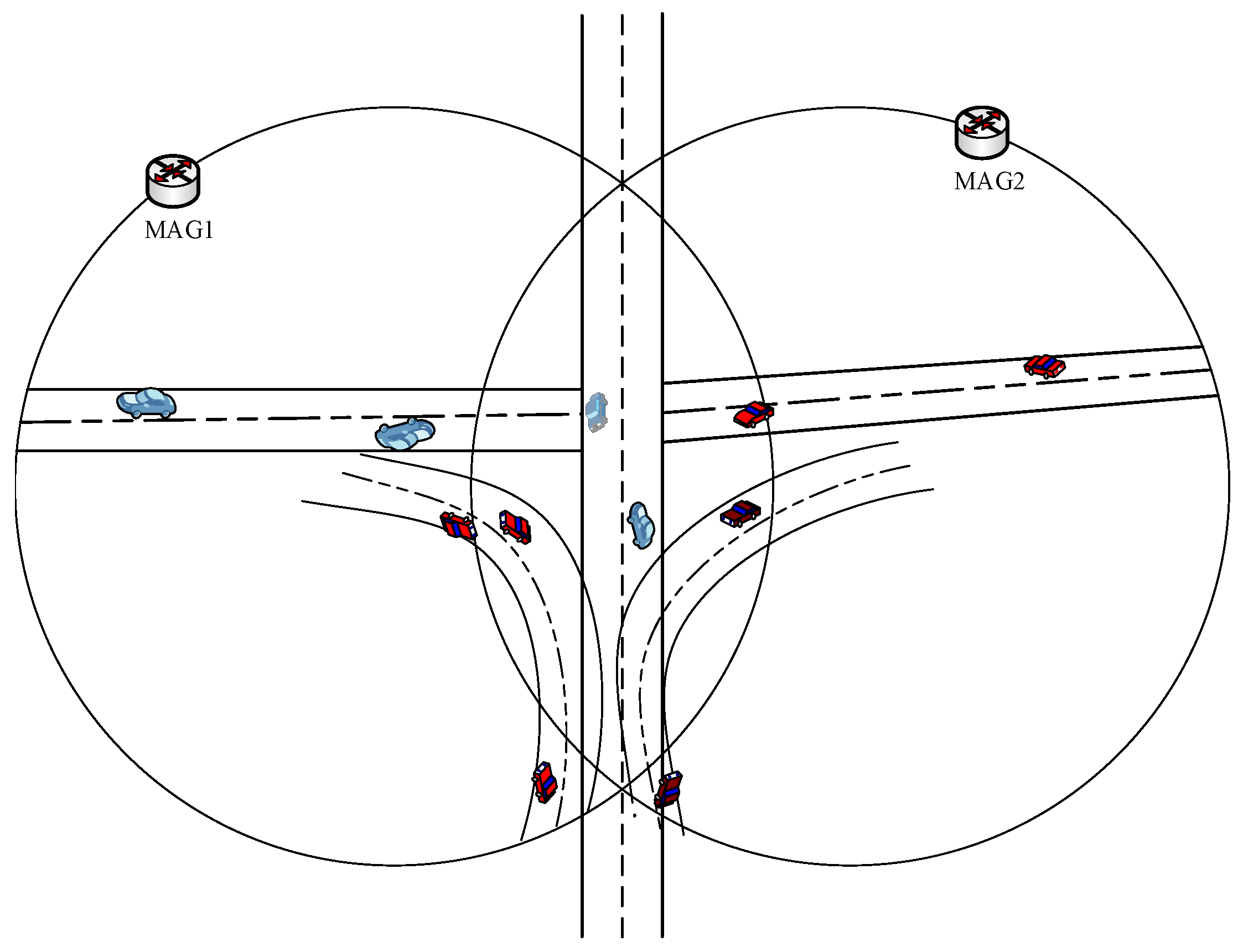
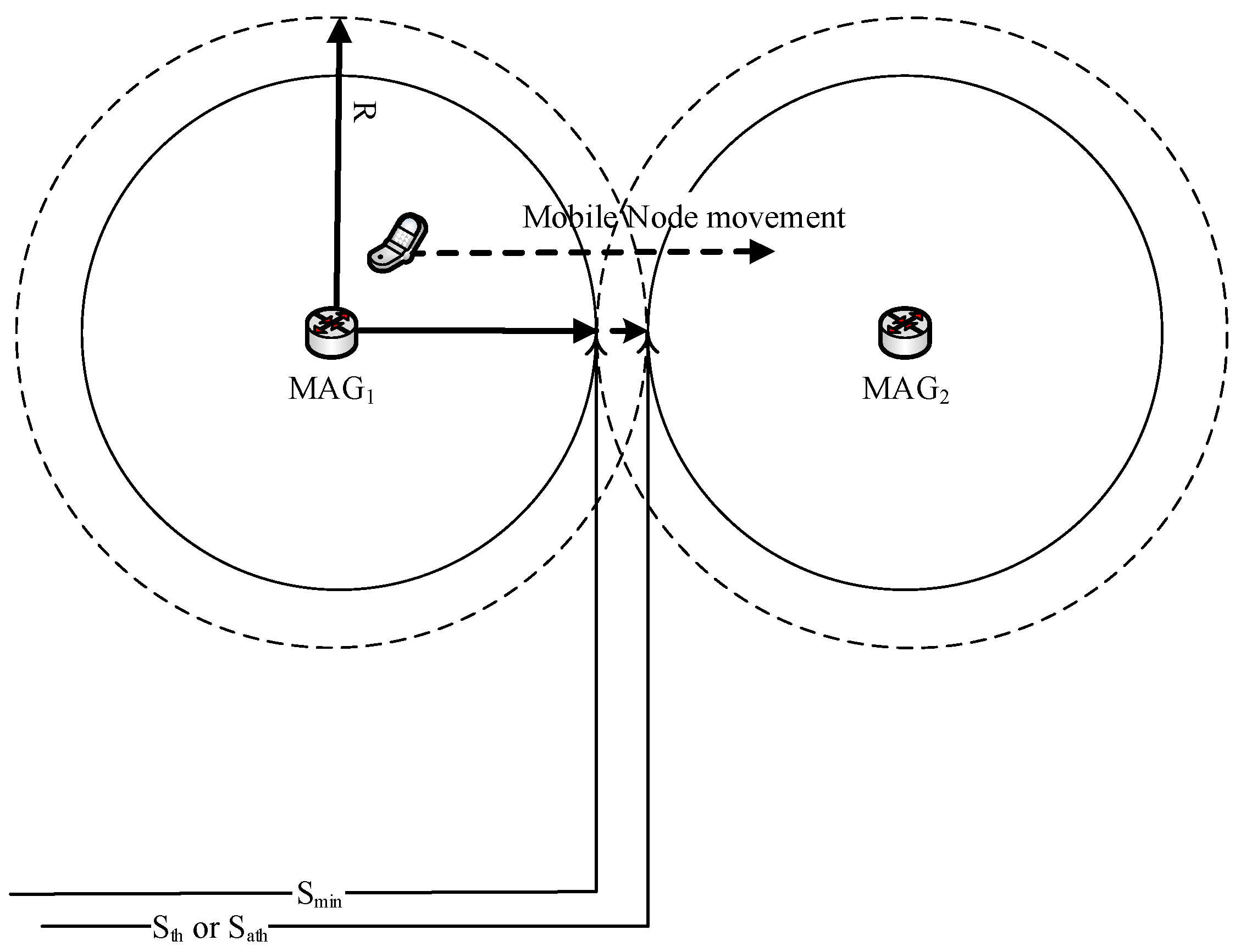
- The CN-MN greatly reduces the false prediction of MNs movement by clearly preventing newer MNs connected to the serving MAG from joining the cluster. This advantage can be justified by carefully observing Figure 4. As shown in Figure 4, the issue of the diamond interchange in the overlapping area that is covered by multiple MAGs is taken into consideration in the proposed E-CSPMIPv6 scheme. This is done by applying a time threshold value that prevents an MN from sending an Acc-join message if this MN has been connected to its serving MAG for a period less than the threshold value.
- The handover latency is reduced by eliminating the de-registration step from the handover process. Instead, the list created earlier by the HMN is sent to both MAGs (i.e., the serving and the new MAG) during the HMN handoff. The prior de-registration increases the system prediction accuracy by increasing the number of handoff MNs in the list prediction, which invariably reduces the handover latency and the signalling cost, and minimises bandwidth waste.
- The HMN keeps receiving the request joining messages after completing its registration processes until a predefined threshold is reached. This is applied to increase the pre-registration of the MNs as much as possible, especially in the sparse networks.
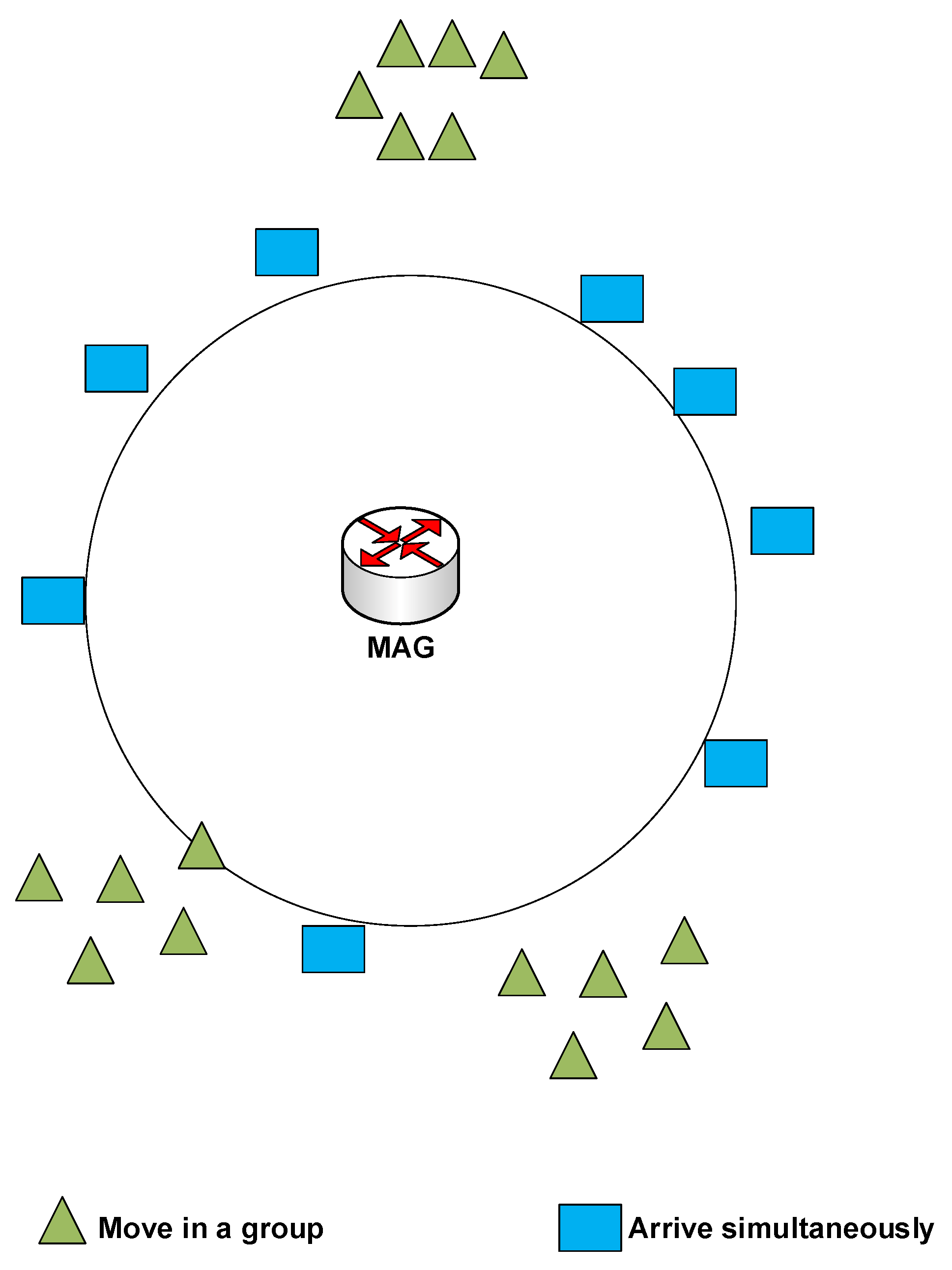
4. System Models
- R represents the circular radius that is covered by the MAG.
- represents the minimum threshold value of RSS at which an MN can consider joining and communicating with another MAG.
- represents the minimum threshold value of RSS, at which the MNs consider grouping the neighbouring MNs to apply pre-registration processes for the joined MNs.
5. Numerical Analysis
5.1. PMIPv6 Cost Analysis
5.2. CSPMIPv6 Cost Analysis
5.2.1. Intra-Cluster Handoff
5.2.2. Inter-Cluster Handoff
5.3. E-CSPMIPv6 Cost Analysis
6. Performance Evaluation
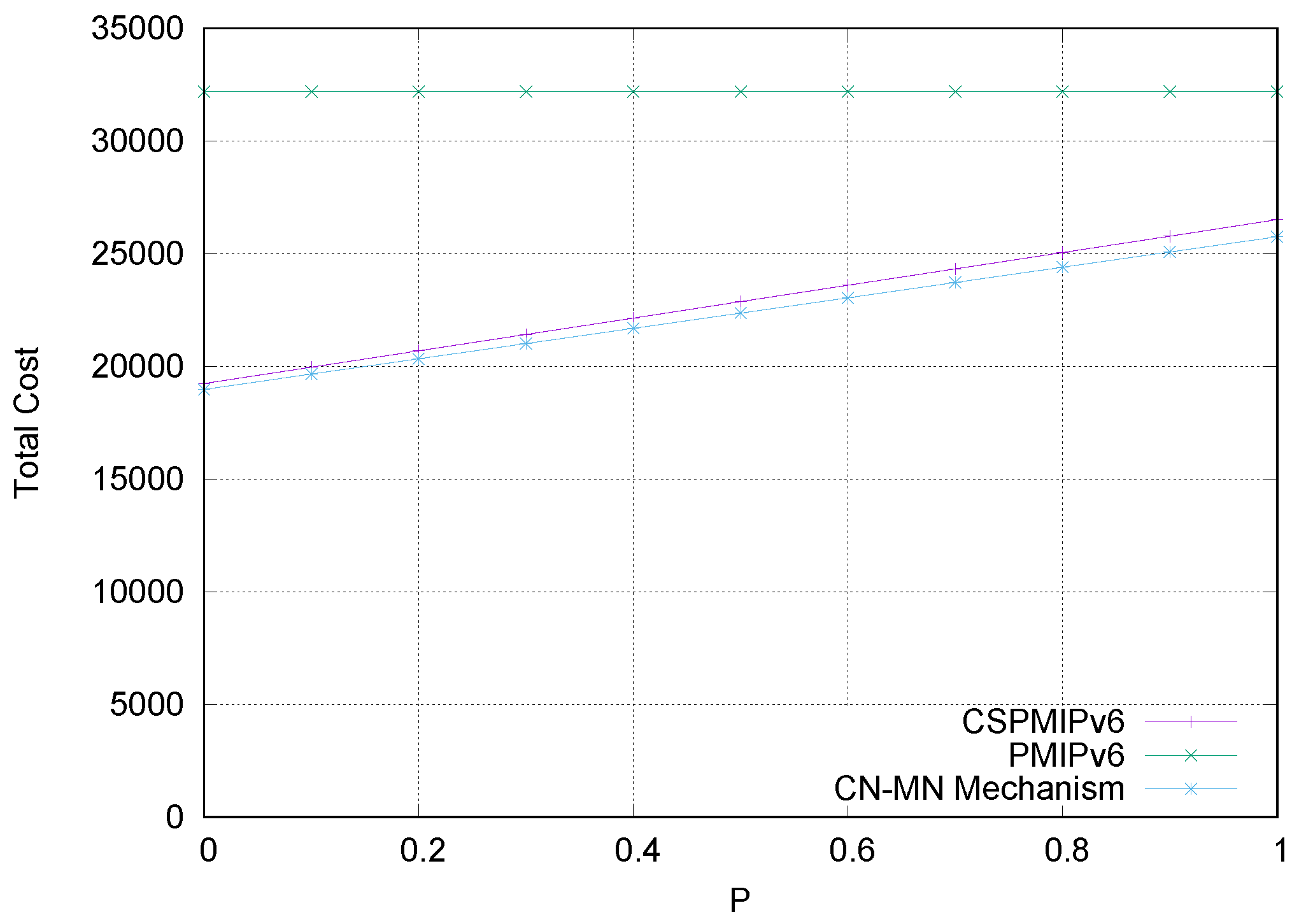
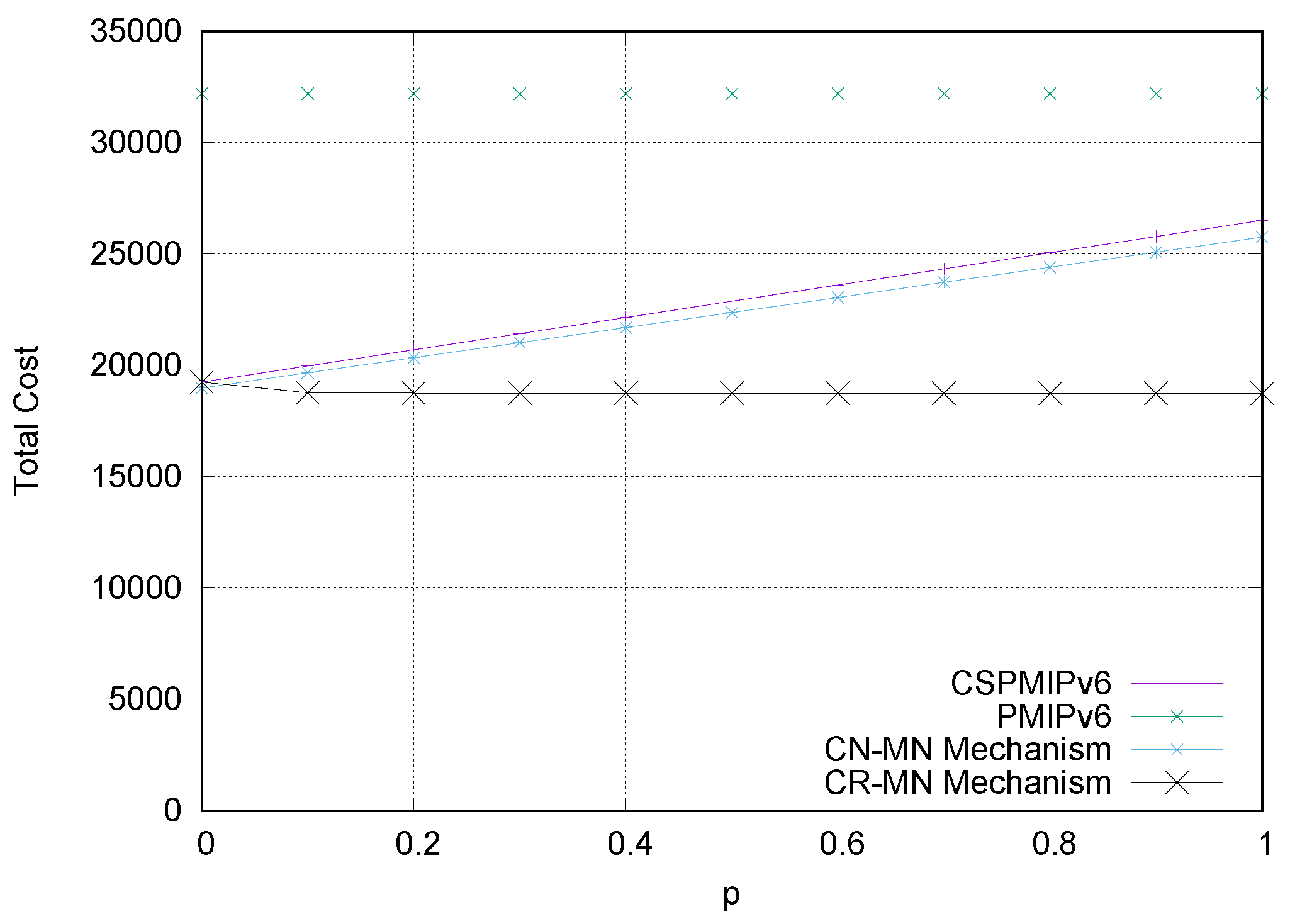
6.1. Numerical results
6.2. Simulation Scenario
6.3. System Setup
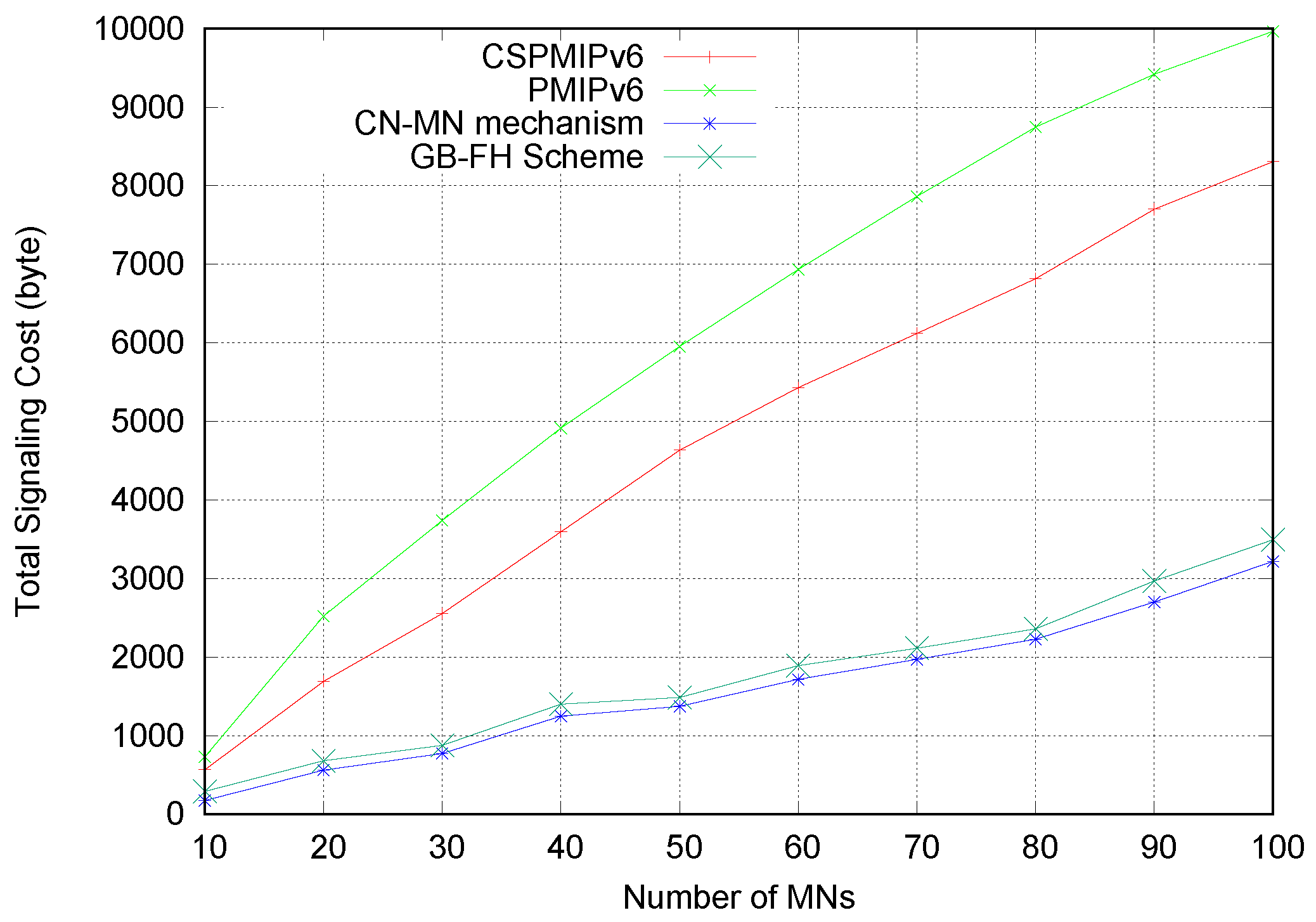
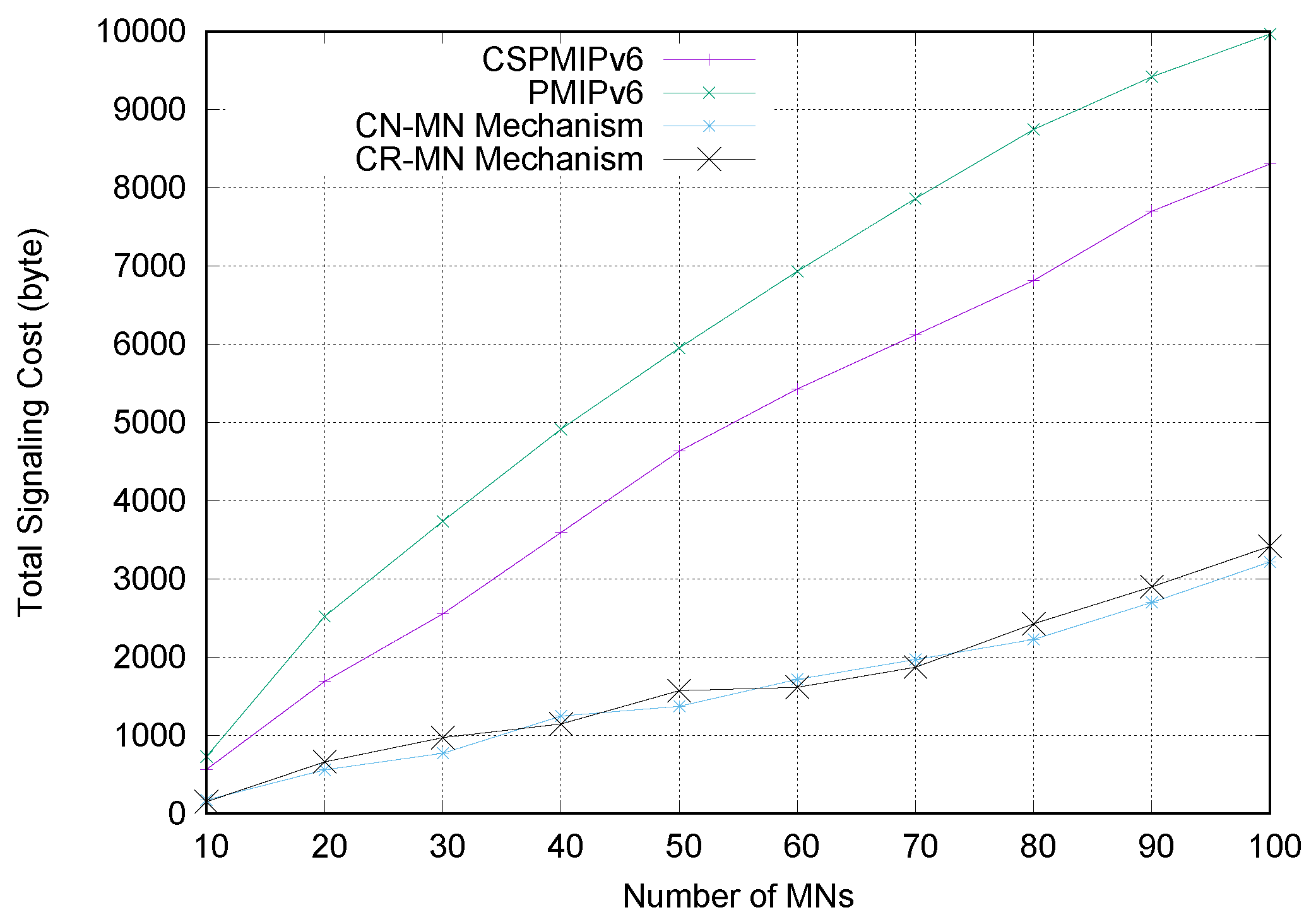
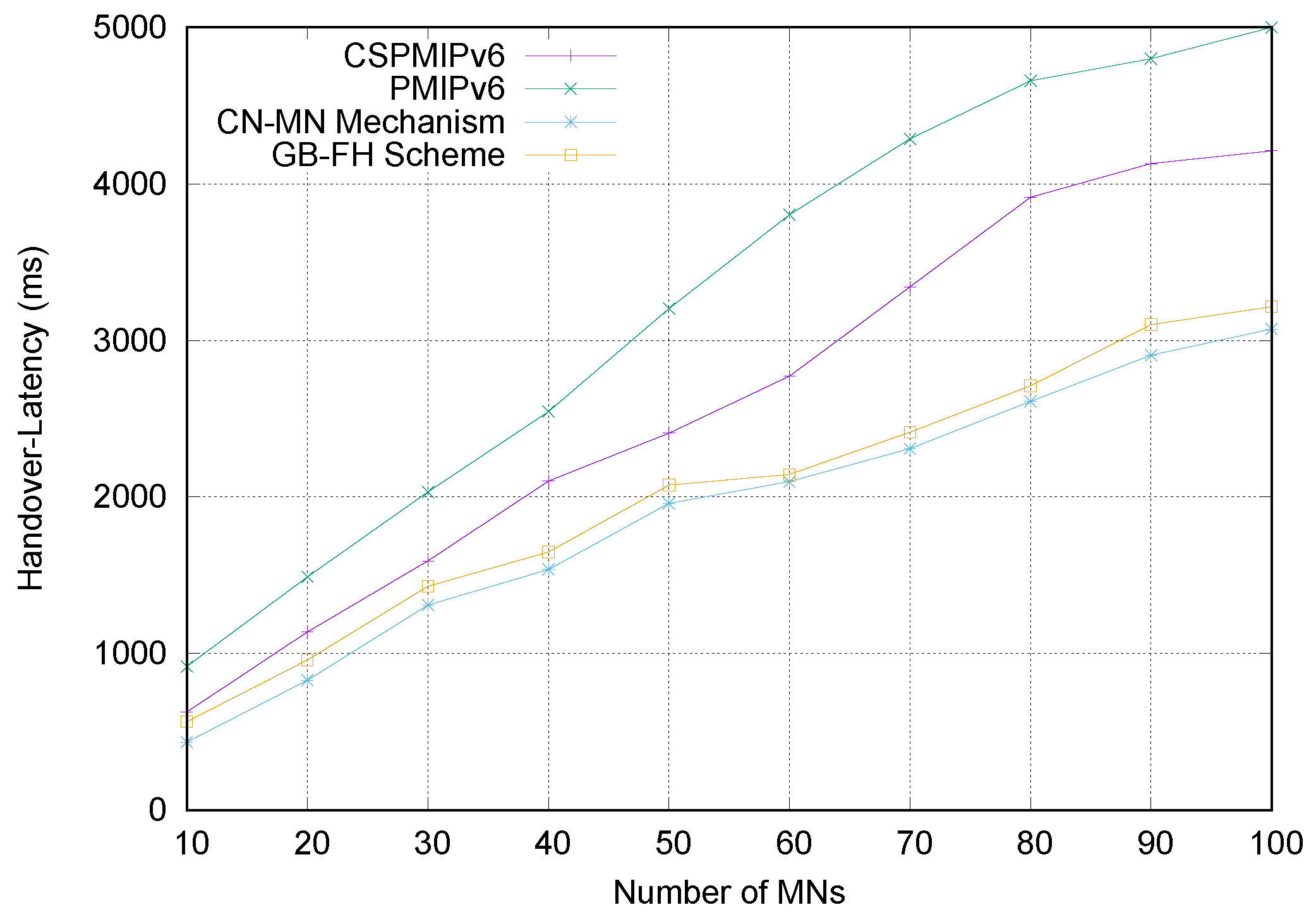
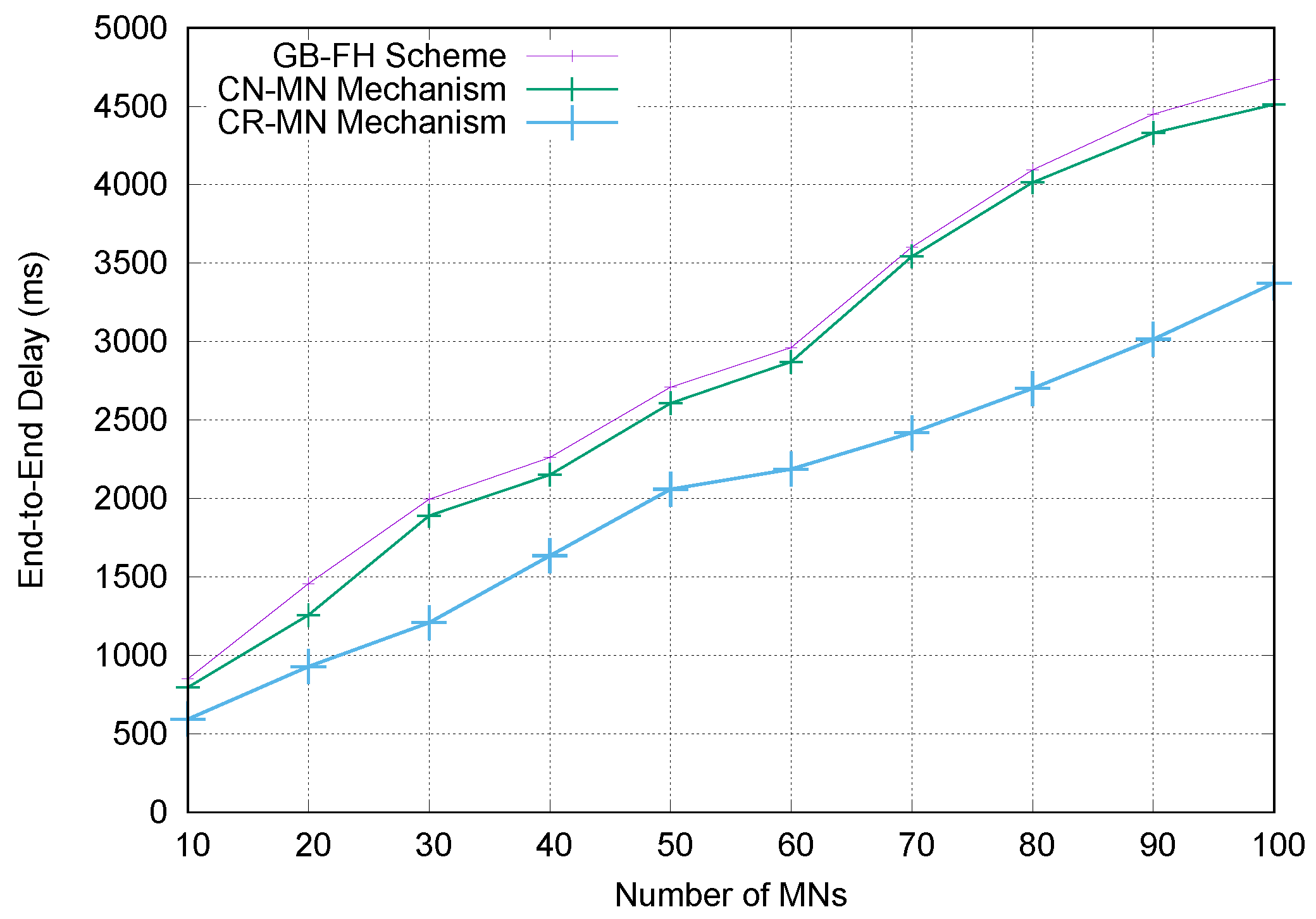
6.4. Simulation Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Johnson, D. IP Mobility Support for IPv6; RFC 3775. 2004. Available online: https://tools.ietf.org/html/rfc3775 (accessed on 30 July 2019).
- Koodli, R. Mobile IPv6 Fast Handovers; IETF, RFC 5568. 2009. Available online: https://tools.ietf.org/html/rfc5268 (accessed on 30 July 2019).
- Soliman, H.; Bellier, L.; Malki, K.E. Hierarchical Mobile IPv6 Mobility Management (HMIPv6); IETF, RFC 4140. 2005. Available online: https://tools.ietf.org/html/rfc5380 (accessed on 30 July 2019).
- Petrescu, A.; Wakikawa, R.; Thubert, P.; Devarapalli, V. Network Mobility (NEMO) Basic Support Protocol; IETF RFC. 4063. 2005. Available online: https://tools.ietf.org/html/draft-ietf-nemo-basic-support-03 (accessed on 30 July 2019).
- Sornlertlamvanich, P.; Kamolphiwong, S.; Elz, R.; Pongpaibool, P. NEMO-Based Distributed Mobility Management. In Proceedings of the 2012 26th International Conference on Advanced Information Networking and Applications Workshops, Fukuoka, Japan, 26–29 March 2012; pp. 645–650. [Google Scholar]
- Jia, W.K. A unified MIPv6 and PMIPv6 route optimization scheme for heterogeneous mobility management domains. Comput. Netw. 2014, 75, 160–176. [Google Scholar] [CrossRef]
- Devarapalli, V.; Chowdhury, K.; Gundavelli, S.; Patil, B.; Leung, K. Proxy Mobile IPv6; IETF, RFC 5213. 2008. Available online: https://tools.ietf.org/html/rfc5213 (accessed on 30 July 2019).
- Yokota, H.; Chowdhury, K.; Koodli, R.; Patil, B.; Xia, F. Fast Handovers for PMIPv6; Internet Engineering Task Force; 2010. Available online: tps://tools.ietf.org/html/rfc5949 (accessed on 30 July 2019).
- Islam, M.M.; Huh, E.N. Sensor proxy mobile IPv6 (SPMIPv6)-A novel scheme for mobility supported IP-WSNs. Sensors 2011, 11, 1865–1887. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.M.; Na, S.H.; Lee, S.J.; Huh, E.N. A Novel Scheme for PMIPv6 Based Wireless Sensor Network. In Future Generation Information Technology; Kim, T.H., Lee, Y.H., Kang, B.H., Ślęzak, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 429–438. [Google Scholar]
- Islam, M.M.; Nguyen, T.D.; Al Saffar, A.A.; Na, S.H.; Huh, E.N. Energy Efficient Framework for Mobility Supported Smart IP-WSN. In Computational Collective Intelligence; Technologies and Applications; Pan, J.S., Chen, S.M., Nguyen, N.T., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 282–291. [Google Scholar]
- Jabir, A.J.; Subramaniam, S.K.; Ahmad, Z.Z.; Hamid, N.A.W.A. A cluster-based proxy mobile IPv6 for IP-WSNs. EURASIP J. Wirel. Commun. Netw. 2012, 2012, 1–17. [Google Scholar] [CrossRef]
- Fu, H.L.; Lin, P.; Yue, H.; Huang, G.M.; Lee, C.P. Group Mobility Management for Large-Scale Machine-to-Machine Mobile Networking. IEEE Trans. Veh. Technol. 2014, 63, 1296–1305. [Google Scholar] [CrossRef]
- Abinader, F.; Gundavelli, S.; Leung, K.; Krishnan, S.; Premec, D. Bulk Binding Update Support for Proxy Mobile IPv6. IETF RFC 6602 2012. Available online: https://www.rfc-editor.org/info/rfc6602 (accessed on 30 July 2019).[Green Version]
- Guan, J.; You, I.; Xu, C.; Zhang, H. The PMIPv6-Based Group Binding Update for IoT Devices. Mob. Inf. Syst. 2016, 2016, 7853219. [Google Scholar]
- Chiang, M.S.; Huang, C.M.; Tuan, D.D. Fast handover control scheme for multi-node using the group-based approach. IET Netw. 2015, 4, 44–53. [Google Scholar] [CrossRef]
- Li, Y.; Jiang, Y.; Su, H.; Jin, D.; Su, L.; Zeng, L. A Group-Based Handoff Scheme for Correlated Mobile Nodes in Proxy Mobile IPv6. In Proceedings of the GLOBECOM 2009–2009 IEEE Global Telecommunications Conference, Honolulu, HI, USA, 30 November–4 December 2009; pp. 1–6. [Google Scholar]
- Chen, Y.S.; Hsu, C.S.; Lee, H.K. An Enhanced Group Mobility Protocol for 6LoWPAN-Based Wireless Body Area Networks. IEEE Sens. J. 2014, 14, 797–807. [Google Scholar] [CrossRef]
- Kim, M.S.; Lee, S. Group-based fast handover for PMIPv6-based network mobility in vehicular networks. In Proceedings of the 2015 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hong Kong, China, 26 April–1 May 2015; pp. 113–114. [Google Scholar]
- Din, S.; Paul, A.; Hong, W.H.; Seo, H. Constrained application for mobility management using embedded devices in the Internet of Things based urban planning in smart cities. Sustain. Cities Soc. 2019, 44, 144–151. [Google Scholar] [CrossRef]
- Gohar, M.; Choi, J.G.; Koh, S.J. CoAP-based group mobility management protocol for the Internet-of-Things in WBAN environment. Future Gener. Comput. Syst. 2018, 88, 309–318. [Google Scholar] [CrossRef]
- Wang, X.; Wang, D.; Qi, S. Mobility support for vehicular networks based on vehicle trees. Comput. Stand. Interfaces 2017, 49, 1–10. [Google Scholar] [CrossRef]
- Magagula, L.A.; Chan, H.A. IEEE802.21 Optimized handover delay for proxy Mobile IPV6. In Proceedings of the MILCOM 2008—2008 IEEE Military Communications Conference, San Diego, CA, USA, 16–19 November 2008; pp. 1–7. [Google Scholar]
- Magagula, L.A.; Chan, H.A. IEEE 802.21-Assisted Cross-Layer Design and PMIPv6 Mobility Management Framework for Next Generation Wireless Networks. In Proceedings of the 2008 IEEE International Conference on Wireless and Mobile Computing, Networking and Communications, Avignon, France, 12–15 October 2008; pp. 159–164. [Google Scholar]
- Jeon, S.; Kang, N.; Kim, Y. Enhanced predictive handover for fast Proxy Mobile IPv6. IEICE Trans. Commun. 2009, 92, 3504–3507. [Google Scholar] [CrossRef]
- Kim, P.S.; Choi, J.H. A Fast Handover Scheme for Proxy Mobile IPv6 Using IEEE 802.21 Media Independent Handover. World Acad. Sci. Eng. Technol. 2010, 43, 654–657. [Google Scholar]
- Hong, K.; Lee, S.; Shin, M. Mobility Management in WLAN-Based Virtualized Networks. Wirel. Pers. Commun. 2013, 72, 581–596. [Google Scholar] [CrossRef]
- Jung, H.; Gohar, M.; Kim, J.I.; Koh, S.J. Distributed Mobility Control in Proxy Mobile IPv6 Networks. IEICE Trans. Commun. 2011, E94.B, 2216–2224. [Google Scholar] [CrossRef]
- Kong, K.S.; Lee, W.; Han, Y.H.; Shin, M.K.; You, H. Mobility management for all-IP mobile networks: Mobile IPv6 vs. proxy mobile IPv6. IEEE Wirel. Commun. 2008, 15, 36–45. [Google Scholar] [CrossRef]
- Issariyakul, T.; Hossain, E. Introduction to Network Simulator NS2; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Fall, J. The ns Manual; The VINT Project: Berkley, CA, USA, 2009. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description |
|---|---|
| Transmission cost of a packet between nodes x and y | |
| Processing cost of node C for binding update or lookup | |
| Setup time for connecting MN with MAG | |
| Number of MAGs in PMIPv6 domain | |
| Number of HMAGs in CSPMIPv6 domain | |
| Number of active hosts per MAG | |
| Number of MAGs per HMAG | |
| n | The probability number of MNs arrived simultaneously |
| Hop count between nodes x and y | |
| Size of a control packet (byte) | |
| Size of data packet (byte) | |
| a | Unit cost of binding update with LMA or HMAG |
| b | Unit cost of lookup for MN at LMA, HMAG, or MAG |
| t | Unit transmission cost of packet per a wired link (hop) |
| k | Unit transmission cost of packet per a wireless link (hop) |
| p | Probability of inter-cluster communications or movements |
| Parameter | Description |
|---|---|
| 500 ms | |
| 20 | |
| 4 | |
| 200 | |
| 5 | |
| n | 0 |
| 50 byte | |
| 1024 byte | |
| a | 3 |
| b | 2 |
| t | 2 |
| k | 4 |
| p | 0.5 |
| 5 | |
| 5 | |
| 1 |
| Parameter | Description |
|---|---|
| Number of MNs | 10–100 |
| Network Area | 3000 × 2500 m |
| Simulation Time | 200 s |
| Node velocity | 1–50 m/s |
| number of MAG | 1–20 |
| number of HMAG | 1–4 |
| Packet Size | 1000 byte |
| Control packet Size | 68 byte |
| Agent | UDP |
| Traffic Type | CBR |
| Wired Link delay | 1–11 |
| Wired Link Bandwidth | 100 Mbps |
| Transmission Range | 500 m |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghaleb, S.M.; Subramaniam, S.; Ghaleb, M.; Mohamed E. Ejmaa, A. An Efficient Group-Based Control Signalling within Proxy Mobile IPv6 Protocol. Computers 2019, 8, 75. https://doi.org/10.3390/computers8040075
Ghaleb SM, Subramaniam S, Ghaleb M, Mohamed E. Ejmaa A. An Efficient Group-Based Control Signalling within Proxy Mobile IPv6 Protocol. Computers. 2019; 8(4):75. https://doi.org/10.3390/computers8040075
Chicago/Turabian StyleGhaleb, Safwan M., Shamala Subramaniam, Mukhtar Ghaleb, and Ali Mohamed E. Ejmaa. 2019. "An Efficient Group-Based Control Signalling within Proxy Mobile IPv6 Protocol" Computers 8, no. 4: 75. https://doi.org/10.3390/computers8040075
APA StyleGhaleb, S. M., Subramaniam, S., Ghaleb, M., & Mohamed E. Ejmaa, A. (2019). An Efficient Group-Based Control Signalling within Proxy Mobile IPv6 Protocol. Computers, 8(4), 75. https://doi.org/10.3390/computers8040075