We show that wrong assumptions concerning the characteristics of the input trace could steer the design-time and deployment-time decisions towards the incorrect direction and eventually result in sever performance loss. Our empirical assessments of the hypotheses confirm that while the magnitude of the impacts could be considerably large, such effects can only be captured in the presence of
multiple input traces covering a vast spectrum of failure occurrence characteristics.
Hypothesis 1. The choice of the input has an impact on the predicted performance of SHS. Wrong assumptions regarding the characteristics of the input trace can result in large performance prediction errors for the self-healing approaches.
Hypothesis 2. The choice of the self-healing approach has an impact on the performance of SHS. Wrong assumptions regarding the characteristics of the input trace can result in disadvantageous choice of the employed self-healing approach at design-time, and thus can cause sever performance loss.
Hypothesis 3. Tuning the optimization parameter of the parameterized self-healing approaches (e.g., size of the execution horizon) has an impact on the performance of SHS. Wrong assumptions regarding the characteristics of the input trace can result in disadvantageous choice of the employed execution horizon size for the self-healing approach at deployment-time, and thus can cause sever performance loss.
Hypothesis 4. In cases where no accurate information about the real operation environment of the SHS is available, employing multiple input traces to steer the choice of self-healing approaches at design-time reduces the risk of premature wrong decisions.
5.6.1. Validation of Hypotheses
In the following, we conduct a set of experiments to empirically validate the proposed hypotheses. We acknowledge that in this study we investigate the validity of the hypotheses only by employing the available single case study, failure traces, and self-healing approaches. Thus, we can only employ these elements to demonstrate the existence of evidence supporting the proposed hypotheses, but we cannot demonstrate that this applies to all or the majority of cases.
As discussed in
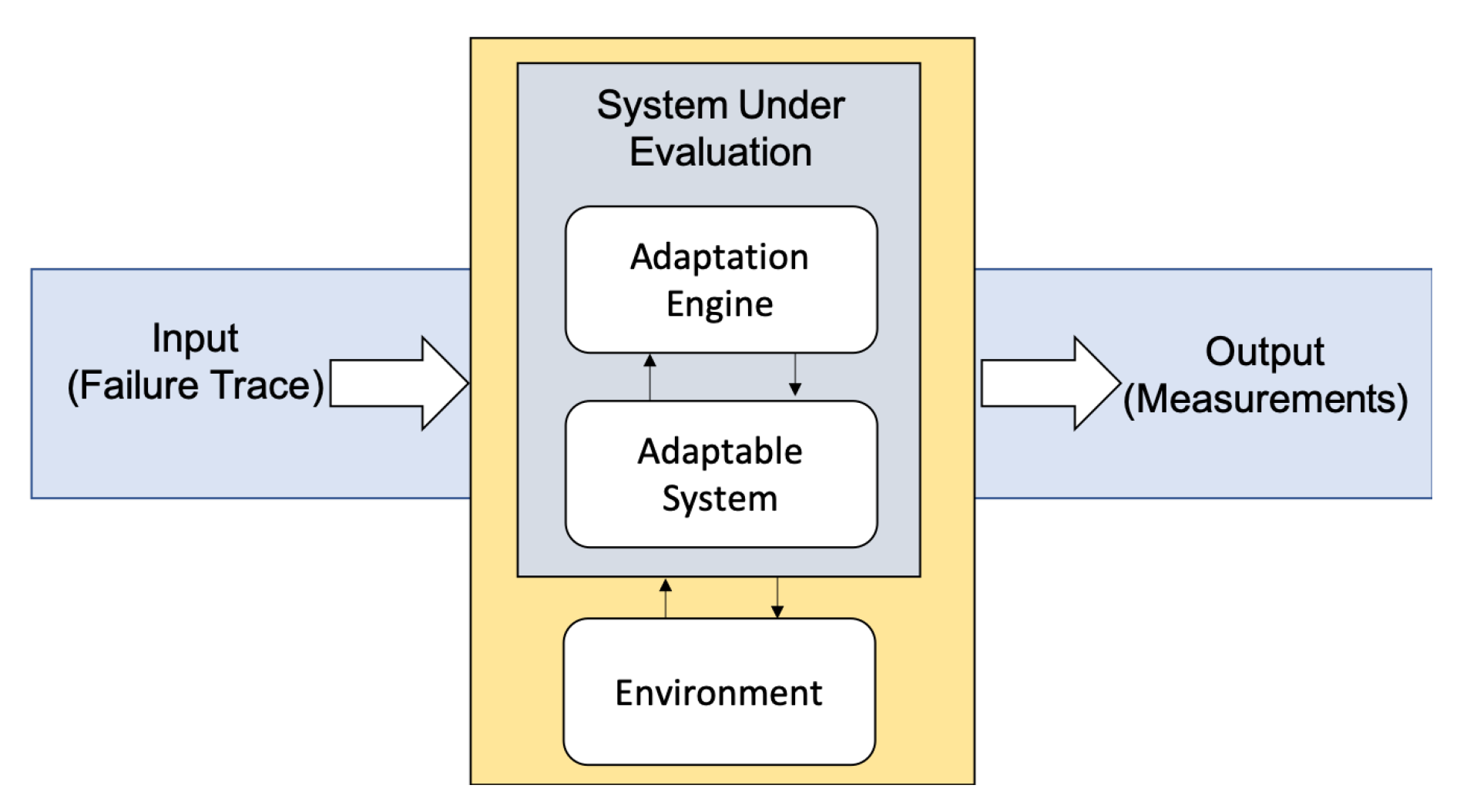
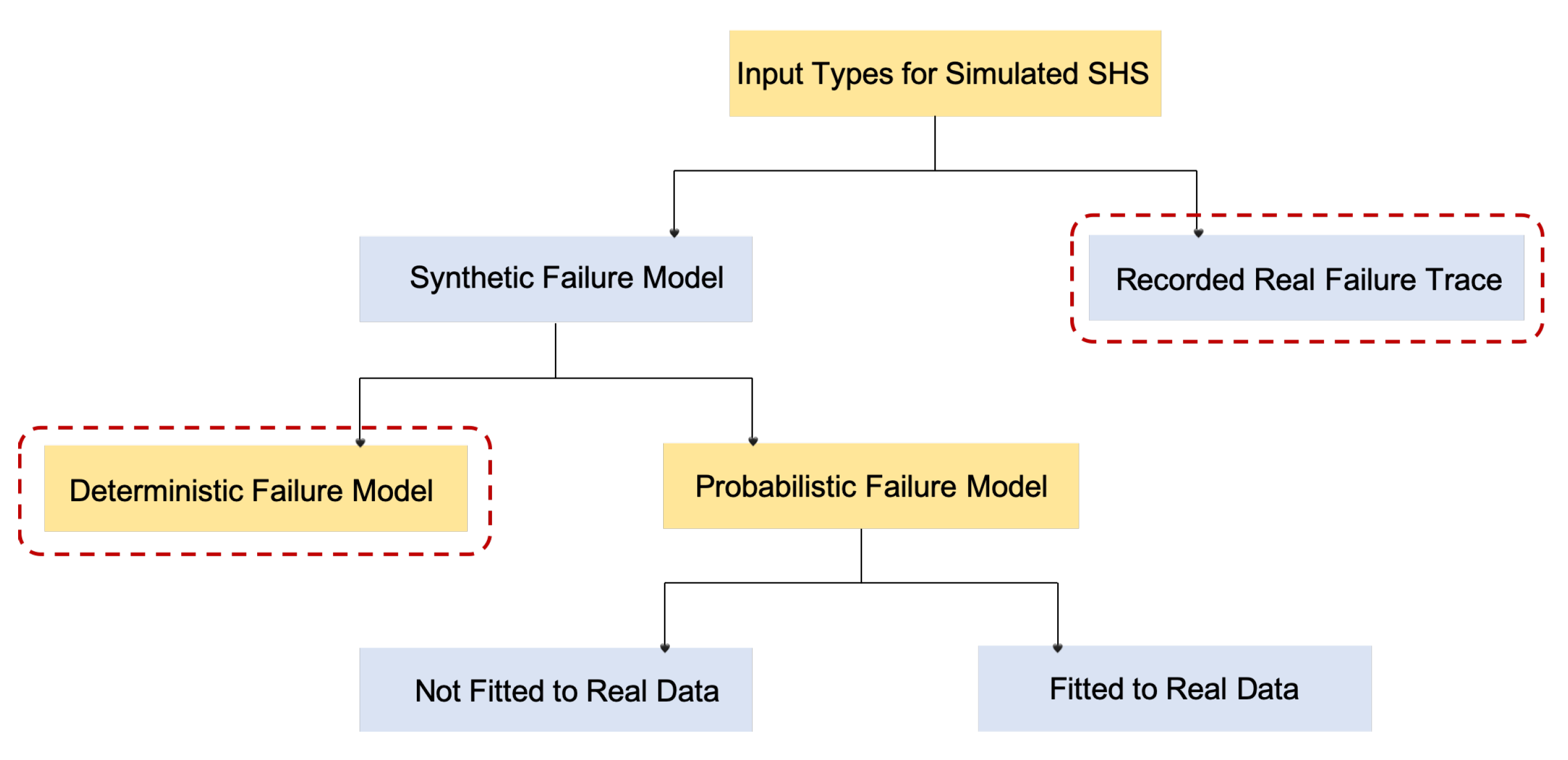
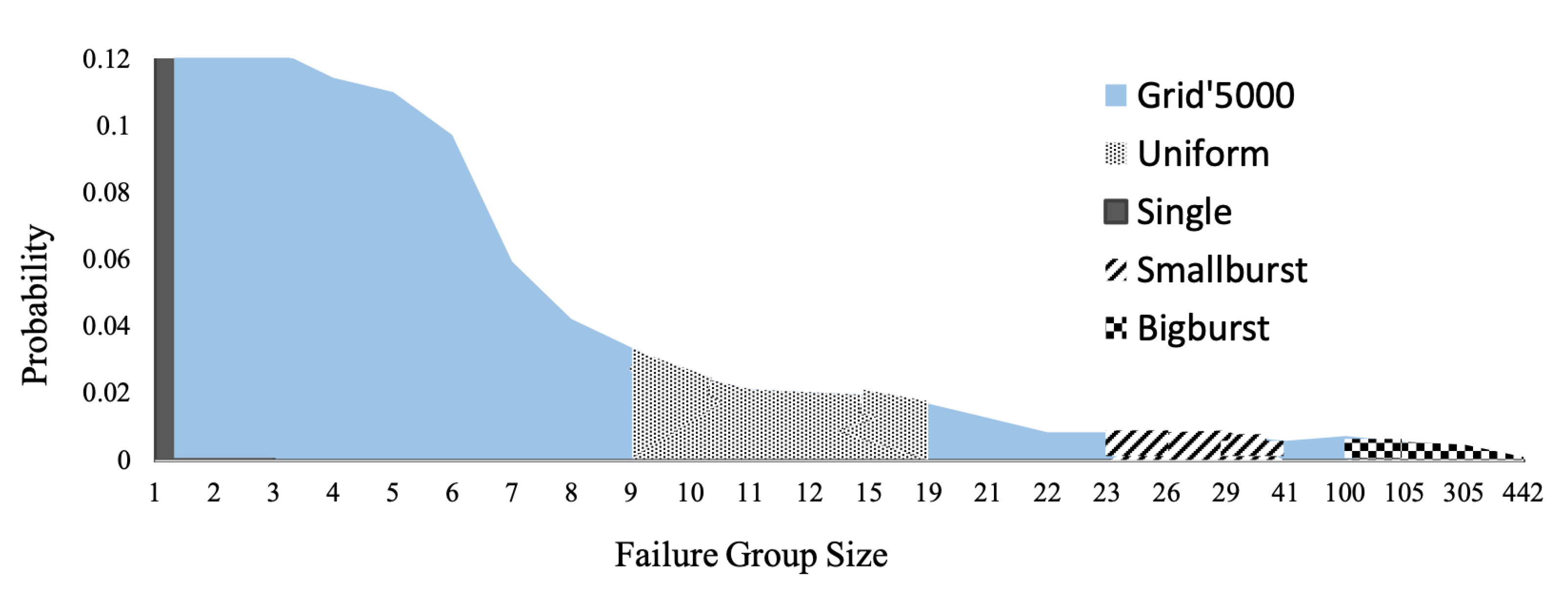
Section 5.2, we consider the accumulated reward (i.e., utility over time) as a measure of performance for the SHS. For each failure trace generated from the failure models presented in
Table 3, we equip mRUBiS (i.e., a simulated SHS introduced in
Section 5.1) with one of the three available self-healing approaches (see
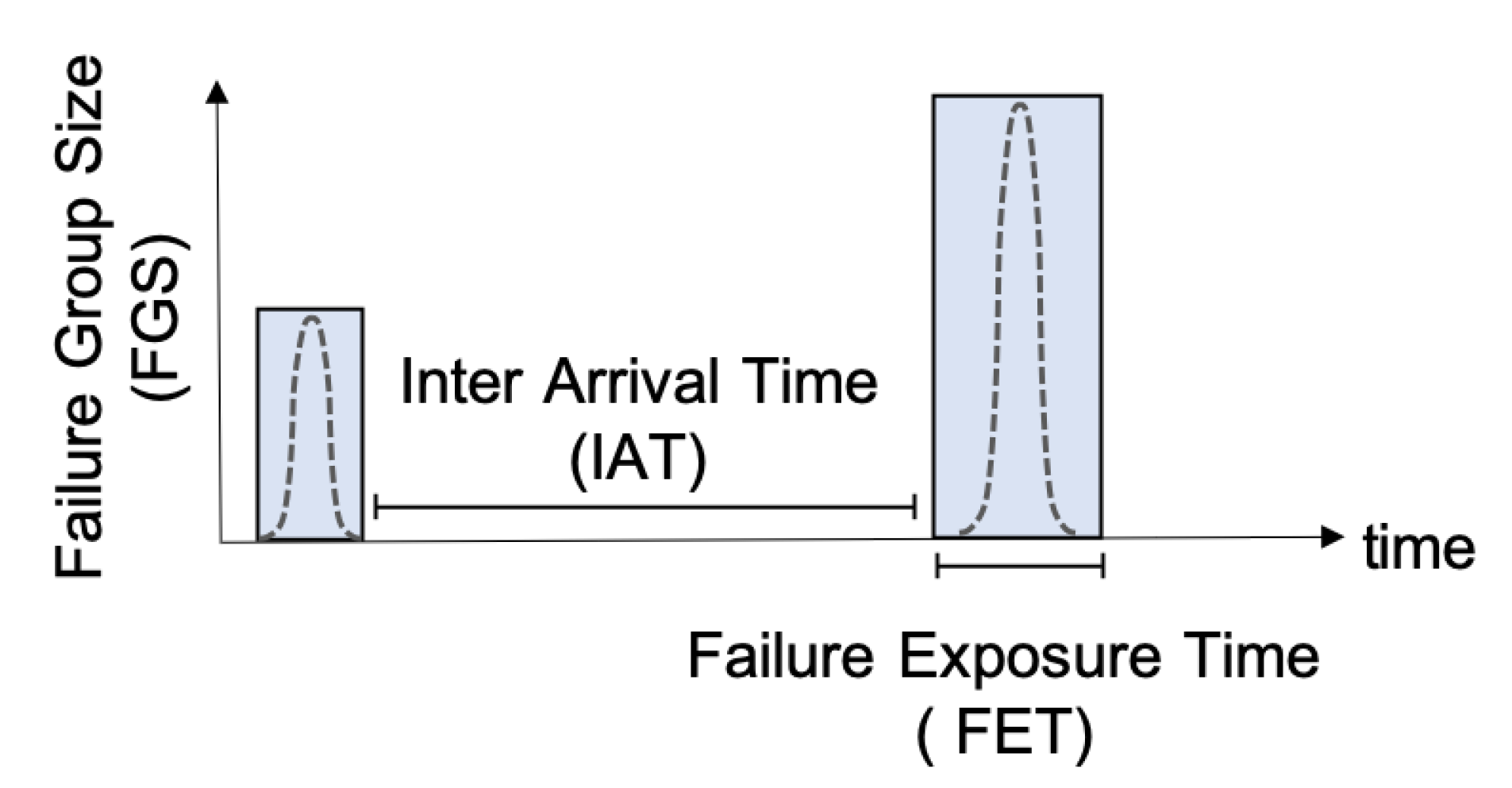
Section 5.3). The employed traces have equal failure density (i.e., 1116 failures overall) to preserve comparability of the results and describe occurrences of the failures for 24 h (see
Section 5.5). However, while the failure traces last for 24 h, the self-healing period in the worst case occupies only
of the considered period. For each combination of the available self-healing approach and failure trace, the self-healing period indicates the time each approach requires to repair all the detected failures. Our measurements reveal that the solver approach presents longer self-healing periods on average, as it often suffers from large runtime overhead due to its costly optimization-based planning (see
Section 5.3). The measurements are the average of 1000 simulation runs for each trace-approach combination (The experiments and simulations have been conducted on a machine with OS X
, Intel processor 2.6 GHz core
, and 8 GB of memory.).
5.6.2. Validating Hypothesis 1
To investigate Hypothesis 1, we study the impact of the employed input on the performance of SHS.
Table 4 presents the accumulated reward values obtained by each of the self-healing approaches in the presence of the employed failure traces during 24 h.
A representative failure trace supports accurate assumptions regarding the characteristics of the SHS input in its operational environment. This results in realistic predictions for the performance of self-healing approaches. These predictions can potentially steer the design-time choice of the self-healing approach.
Hypothesis 1 implies that in cases where the employed trace is not representative of the SHS input space (leading to wrong assumptions regarding the characteristics of the input trace), it can result in performance prediction error. To validate Hypothesis 1, using Equation (
1), we compute the prediction error of the self-healing approaches in case of wrong assumptions regarding the characteristics of the input trace. As we are only interested in the magnitude of the error and not whether the prediction is too optimistic or pessimistic, we present the absolute values of the prediction error in Equation (
1).
Table 5,
Table 6 and
Table 7 depict the performance prediction errors for the u-driven, solver, and static approaches in the presence of different input traces with equal failure densities (see
Section 5.5). As indicated by the results, the solver approach presents the largest sensitivity to wrong assumptions regarding the characteristics of the input trace. The performance prediction errors for the u-driven approach vary from
to
. The larger error values of the u-driven approach are observed for the case when the runtime (i.e., real) trace is the Bigburst trace and the assumptions suggest different input traces for the predictions. Similarly, in the solver approach, the large prediction errors are also observed for the Bigburst trace. The error values for the solver approach are shown to be as high as
. Among the three approaches, the static approach presents less sensitivity to the wrong assumptions regarding the input trace compared to the other two approaches. The performance prediction errors for the static approach vary from
to
, where the larger values relate to the Bigburst trace both as the runtime trace and as the trace used for predictions. Note that in Equation (
1), values above
for the
indicate that the difference between the
and the
is more than twice the
.
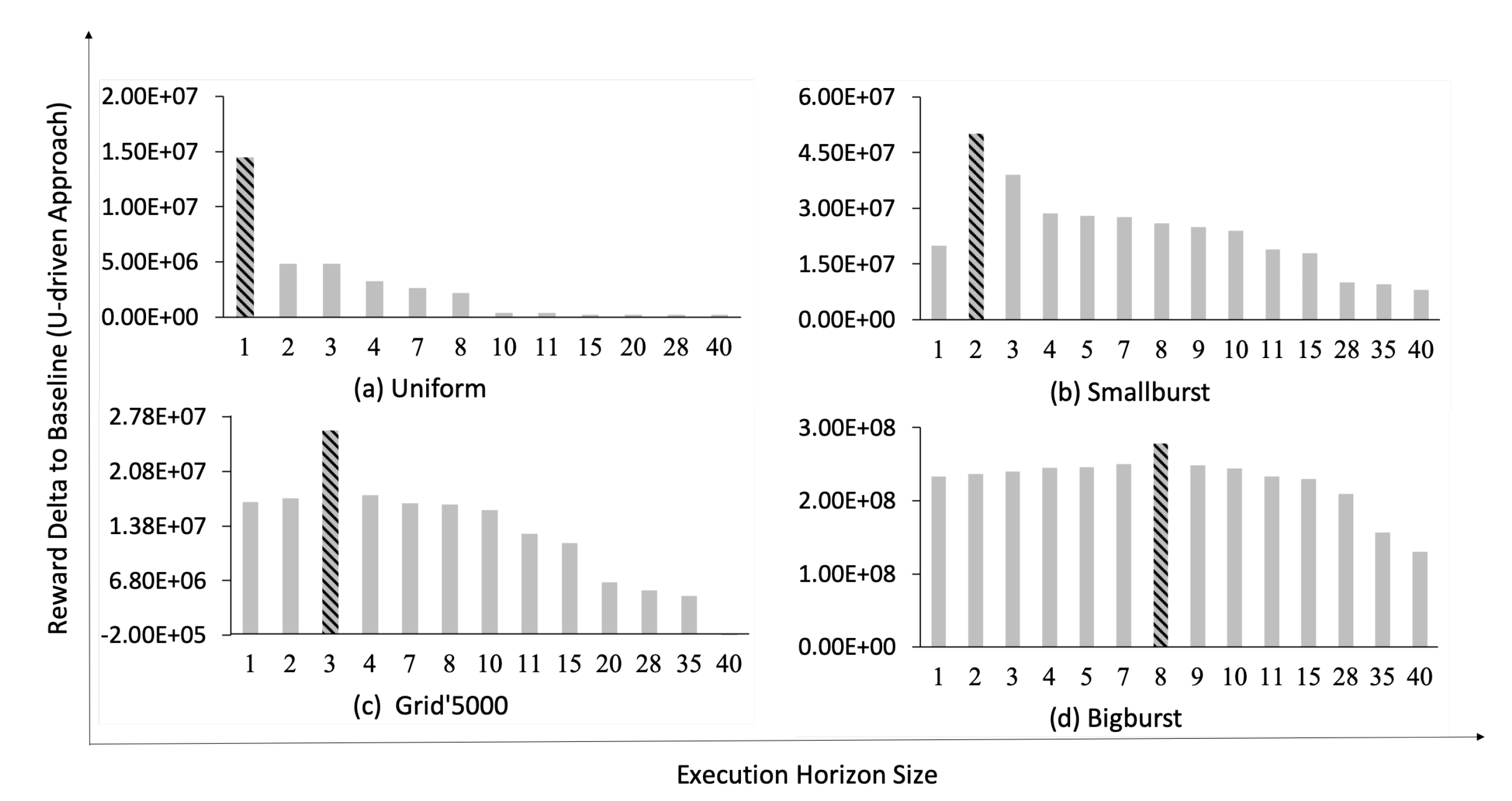
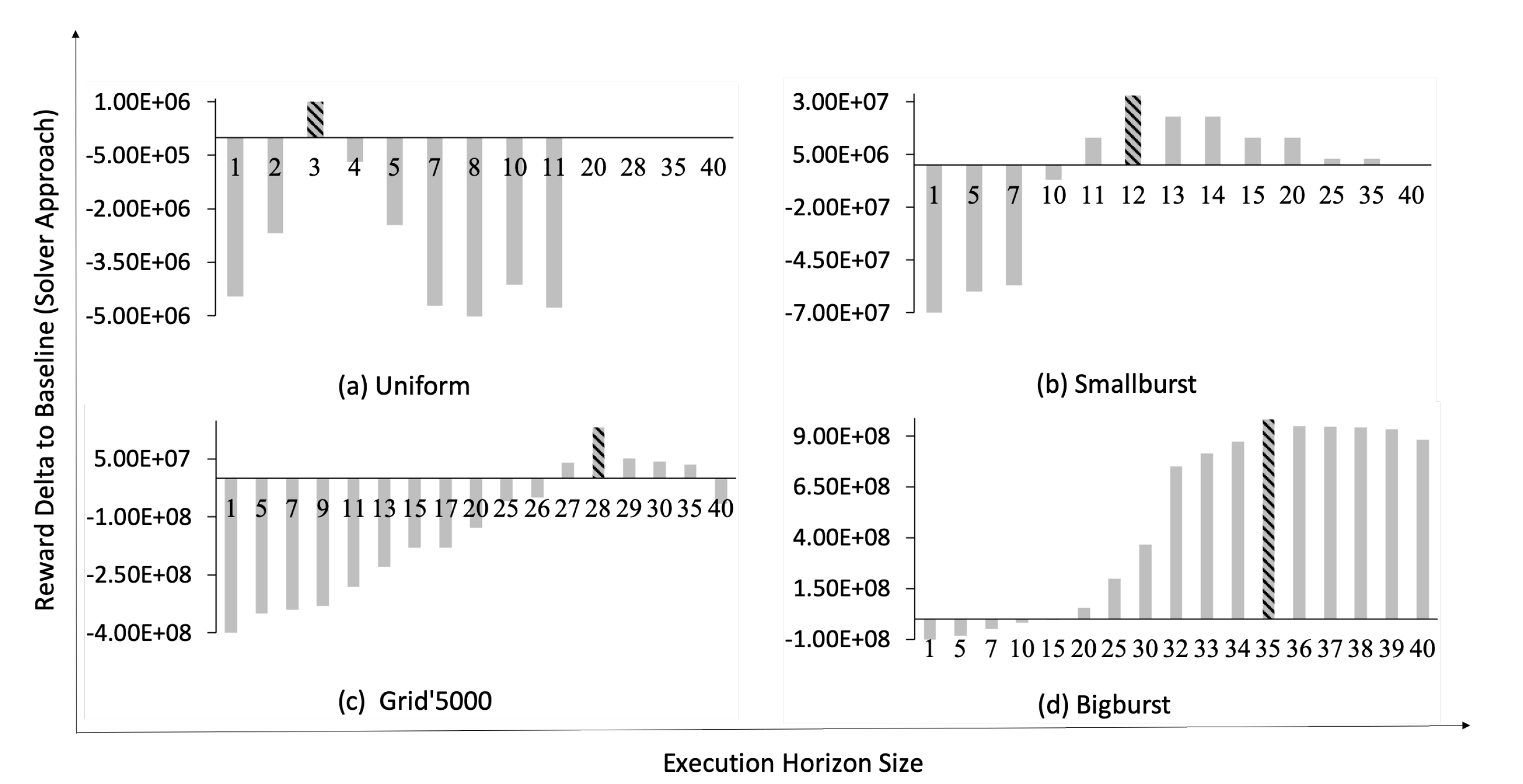
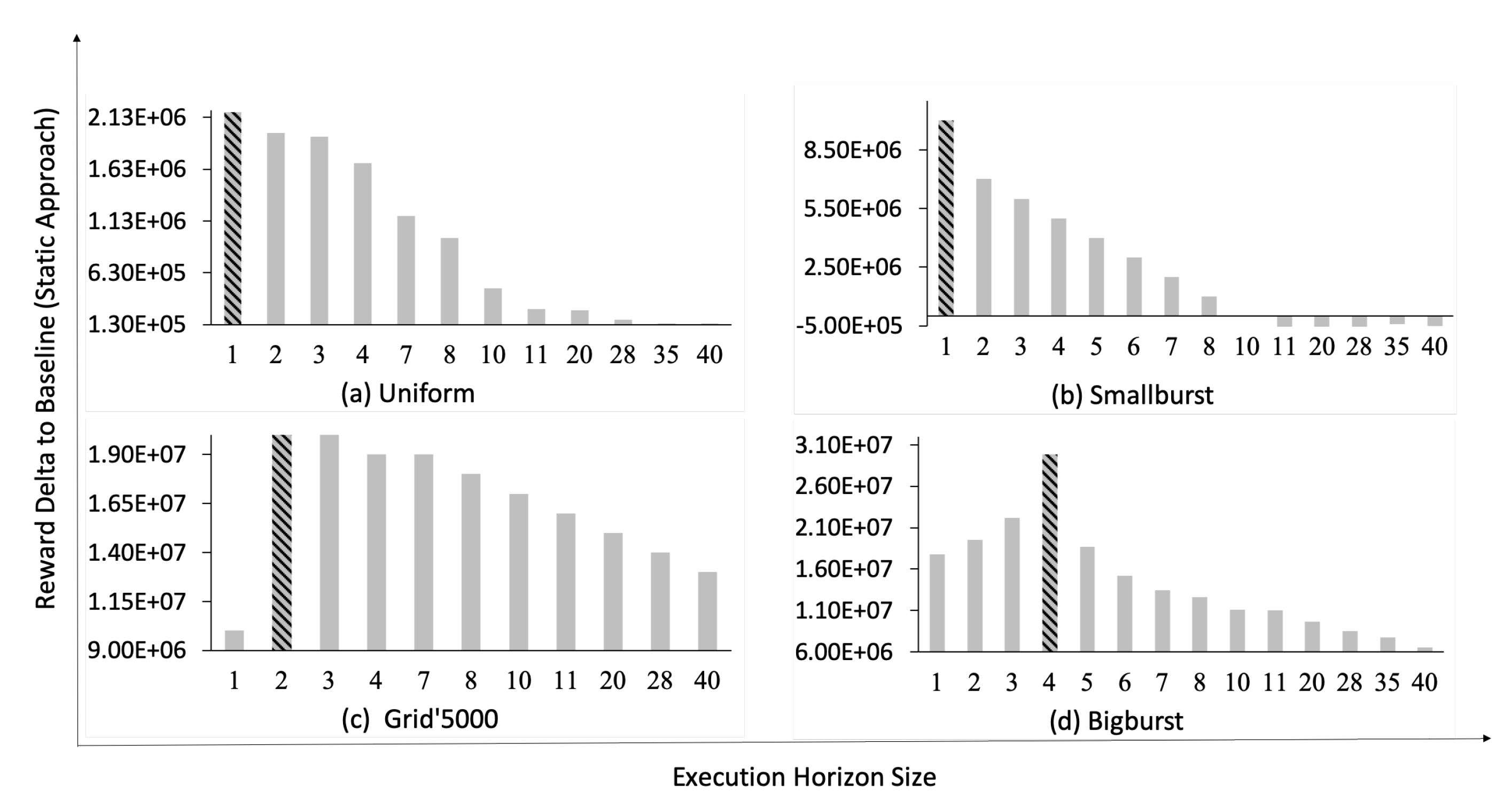
5.6.3. Validating Hypothesis 2
Hypothesis 2 indicates that inaccurate assumptions regarding the input trace characteristics can result in an incorrect choice of the self-healing approach, and thus loss of performance. In the following we investigate the extent of the performance loss as a result of wrong assumptions about the characteristics of the input trace. The u-driven approach is excluded from this set of experiments. As shown in our previous works [
43,
58] and confirmed by the results in
Table 4, the performance of the u-driven approach is robust against the changes of the input trace characteristics due to its incremental planning scheme.
To investigate Hypothesis 2, first we identify the best performing approach (excluding u-driven) for the available input traces. For each input trace, the best performing approach is the one that obtains the largest reward. As depicted in
Table 4, for input traces with smaller FGSs (i.e., Single, Uniform and Smallburst) the solver approach obtains higher reward values compared to the static approach. While for traces with larger FGSs (i.e., Grid’5000 and Bigburst) the static approach performs better than the solver approach, since it does not introduce any runtime overhead (see [
43]).
The next step to validate Hypothesis 2 is to study the reward loss due to a wrong choice of the self-healing approach at design-time. The reward loss of each self-healing approach in the presence of an input trace is computed according to Equation (
2).
For a given input trace,
in Equation (
2) represents the achieved reward by the best performing approach for that trace. The
values for each input trace-approach pair are extracted from
Table 4. For each input trace, if the selected approach is the best performing approach, then
equals zero.
Table 8 presents the
values for different input traces in case of wrong choices for the employed self-healing approaches at design-time. The design-time decisions in
Table 8 are represented as (
,
). This indicates that at design-time,
is chosen to be employed on the SHS, since the input trace is assumed to be
. If these assumptions regarding the characteristics of the input are incorrect, i.e., the runtime trace has different characteristics than
, then the design-time choice of the self-healing approach does not best fit the runtime trace and results in reward loss.
The results presented in
Table 8 reveal that if the choice of the self-healing approach is made based on unrepresentative input traces, it could lead to considerably large performance loss (up to
in our empirical experiments). As stated in
Section 2, reliable input for a SHS under evaluation prevents disadvantageous decisions at design-time or deployment-time. The results confirm that the characteristics of the input trace influence the performance of SHS, and therefore should steer the choice for the employed self-healing approach.
5.6.5. Validating Hypothesis 4
We refer to the set of input traces used at design-time to steer the choice of self-healing approaches as . The size of (i.e., ) indicates the number of the employed input traces. Hypothesis 4 indicates that in cases where no accurate information about the real operational environment of the SHS is available, increasing reduces the risk of making wrong choices of the employed self-healing approach. To validate Hypothesis 4, we investigate how the risk of making wrong choices about the self-healing approach evolves as increases.
In our empirical experiments, the upper bound for
is 5 (i.e., the number of the available input traces introduced in
Section 5.5). The likelihood of correct, inconclusive, and wrong decisions are calculated for
. Similar to the experiments in
Section 5.6.3, the u-driven approach is excluded from the experiments here, since it outperforms the solver and static approaches for all the available input traces (see
Table 4). In order to demonstrate Hypothesis 4, we need to have an alternating set of best performing approaches.
A
correct decision refers to the cases where the self-healing approach suggested by the traces in
is the best performing approach for the runtime trace as well. The best performing approach (excluding u-riven approach) for each of the five available input traces can be extracted from
Table 4. We use the notation
if all the traces in
suggest
to be chosen as the best performing approach.
indicates that
is the best performing approach for the runtime trace. For the set of considered self-healing approaches in this section, likelihoods of the correct decisions are calculated as in Equation (
4).
A
wrong decision refers to a case where the employed self-healing approach, suggested by
, is not the best performing approach for the runtime trace. The likelihood of the wrong decisions can be computed as in Equation (
5) for our set of considered approaches.
An
inconclusive outcome refers to the cases where the traces in
, for
, do not suggest the same self-healing approach to be employed as the best performing approach. Any case which is not correct or wrong is categorized as an inconclusive outcome. Therefore, the likelihood of inconclusive cases can be computed as in Equation (
6). In the conducted experiments we assume that all the traces in
are equally likely to accurately represent the runtime trace and also are equally likely to be included in
.
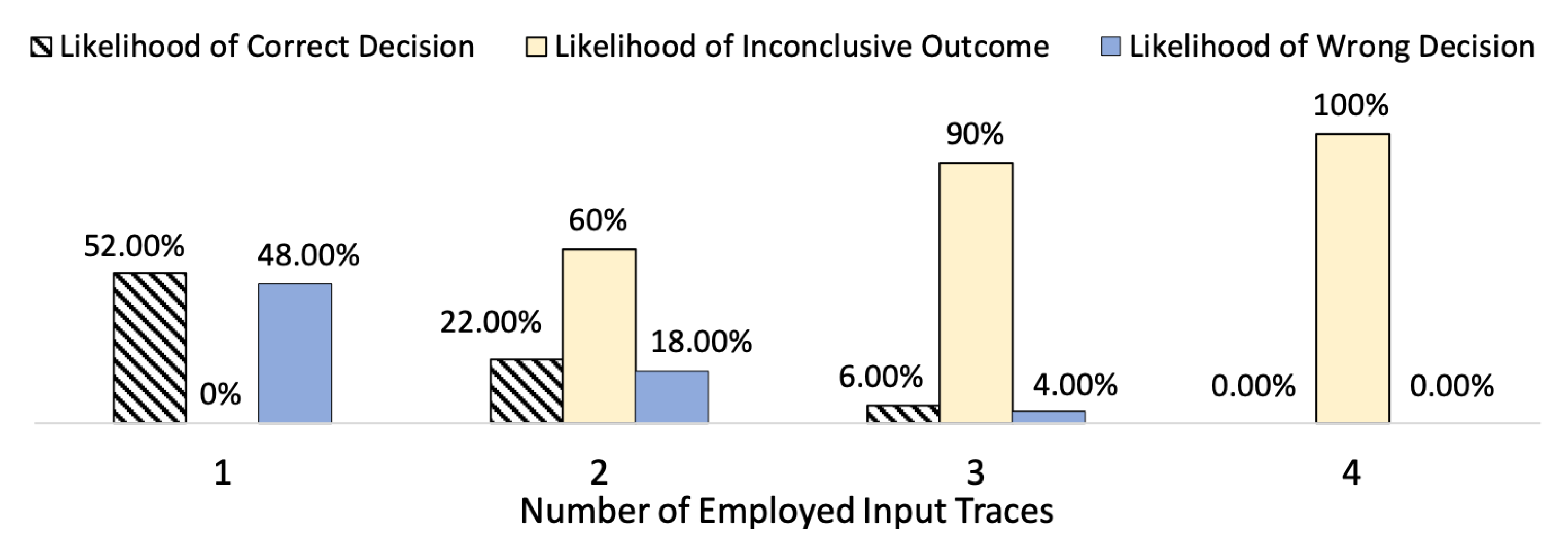
Figure 10 presents the likelihoods of the correct, inconclusive, and wrong design-time decisions for
. We excluded the results for
, as they are similar to the case
. For
, where the decision for the choice of self-healing approach is steered by only one input trace, the solver approach is chosen as the best performing approach for the Single, Uniform, and Smallburst traces (see
Table 4). Therefore,
. For
, since the choice of the self-healing approach is made only base on one input trace,
=
=
. If Grid’5000 or Bigburst trace steer the choice of the self-healing approach at design-time, the static approach is chosen as the best performing approach with
likelihood (i.e.,
). In this case also
equals
=
. Employing Equations (
4)–(
6) for
results in
likelihood of the correct decisions, while there is a risk of
to make wrong decisions. As the case
contains only one trace in the set
, it does not lead to an inconclusive situation, as depicted in
Figure 10.
Employing two input traces (i.e., ) reduces the likelihood of the wrong decisions to ; the likelihood of the correct decisions also drops to ; and of the cases are reported as inconclusive. Adding one more trace to () reduces the likelihood of the wrong decisions to . Correct decisions are observed with likelihood, and in of the cases the outcome of the set is inconclusive.
For , the likelihoods of both wrong and correct decisions drop to zero, and the only possible outcome is inconclusive (i.e., likelihood of ). As elaborated earlier, the inconclusive output for indicates that the traces in do not suggest the same best-performing self-healing approach. Our experiments show that by increasing , the likelihood of wrong decisions drops to zero. However, increasing eventually results in only achieving an inconclusive output. The objective behind increasing is to reduce the risk of making wrong decisions, and our experiments confirm this claim. In addition, we argue that inconclusive output for is also beneficial, as it prevents wrong choices.
We argue that the large likelihood of inconclusive output for large values is due to the limitations of our empirical experiments and the restricted number of the available input traces. If the input space of the SHS is represented more fine grained with considerably more input traces, the likelihood of inconclusive output for can be expected to decrease respectively, since it is more likely that traces with similar characteristics are included in the set . However, in our experiment for , since traces with extreme differences in their characteristics are included in (e.g., Bigburst and Single), it is expected to observe inconclusive outputs.
The results of
Figure 10 confirm that as the number of the considered input traces to steer the choice of the self-healing approach (i.e.,
) increases, the risk of making wrong decisions drops considerably (from
to zero in our experiments). In addition, increasing
supports robustness claims for the performance measurements, as it allows multiple measurements of the system under evaluation in presence of various volatile input conditions (see
Section 2.1).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}