
GPU-Based Cellular Automata Model for Multi-Orient Dendrite Growth and the Application on Binary Alloy


Abstract
:1. Introduction
2. Materials and Methods
2.1. Description of Numerical Model
2.1.1. Heat Transfer Model
2.1.2. Solute Distribution Model
2.1.3. CA Model
2.2. Parallel Solver Based on GPUq
2.2.1. GPU-CA Framework
2.2.2. Implementation by CUDA C
- Task scheduling scheme
- 2
- Parallel algorithms
| Algorithm 1 parallel solute redistribution algorithm |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
| 11 |
3. Results and Discussion
3.1. Validated by the LGK Model
3.2. Model Capability
3.2.1. Single Dendrite of Fe–0.6C Alloy
3.2.2. Multi-Dendrites of Fe–5.3Si Alloy
3.2.3. Acceleration Performance
4. Conclusions
- (1)
- The steady dendrite tip velocity calculated by this CA model agrees well with the analytical LGK model.
- (2)
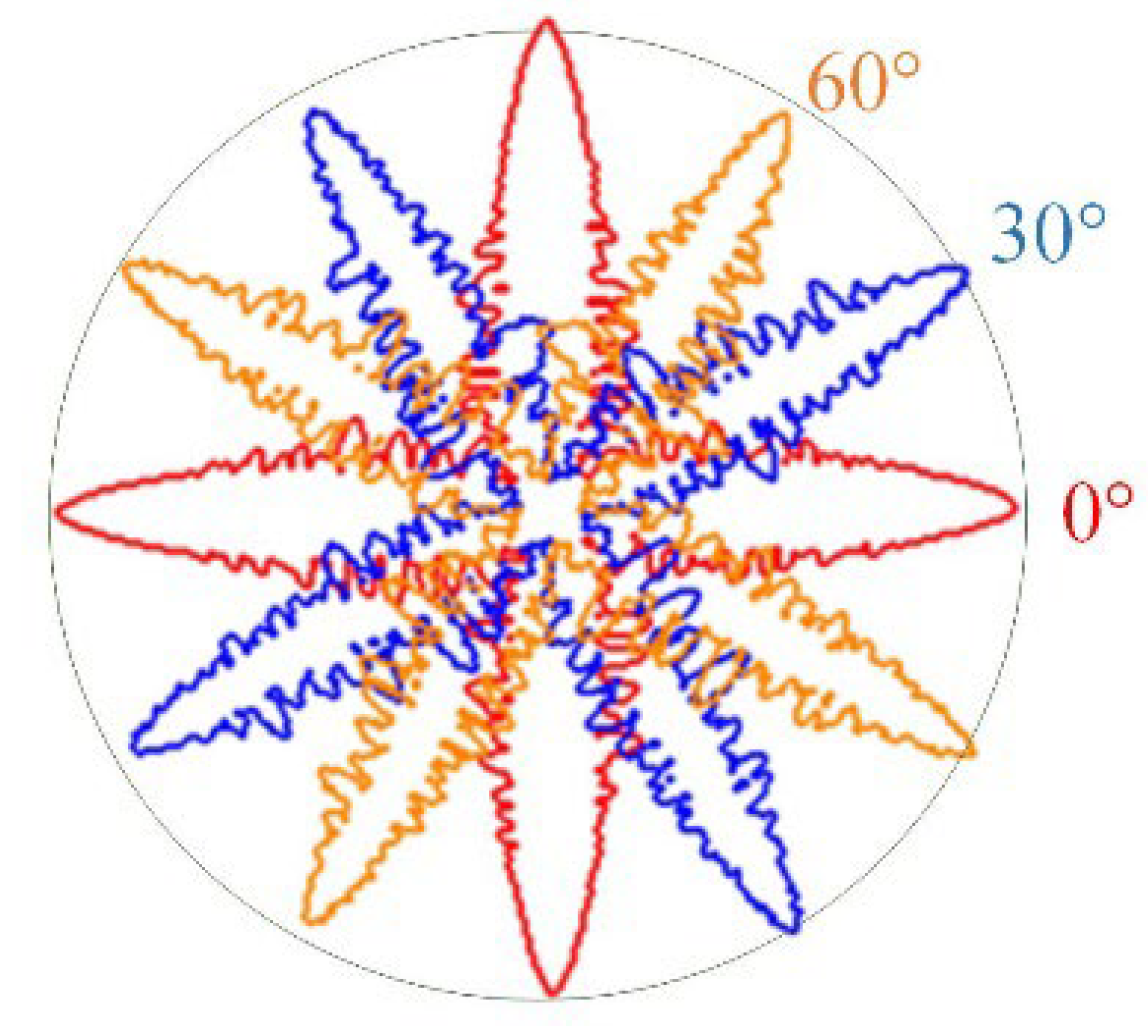
- The present model can simulate dendrite morphologies with a random orientation of the Fe–0.6C alloy and can maintain velocity symmetry under different orientations.
- (3)
- The simulation result of Fe–5.3Si not only matches well with the in situ experiment but can also reveal the segregation existing between and within dendrite. This model can be used to simulate multi-dendrite growth in actual casting.
- (4)
- Compared to traditional CPU calculation, this work can achieve noticeable acceleration, and the speedup increases with the number of grids, which is up to 158×.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Domitner, J.; Kharicha, A.; Grasser, M.; Ludwig, A. Reconstruction of Three-Dimensional Dendritic Structures based on the Investigation of Microsegregation Patterns. Steel Res. Int. 2010, 81, 644–651. [Google Scholar] [CrossRef]
- Guo, E.Y.; Shuai, S.; Kazantsev, D.; Karagadde, S.; Phillion, A.B.; Jing, T.; Li, W.Z.; Lee, P.D. The influence of nanoparticles on dendritic grain growth in Mg alloys. Acta. Mater. 2018, 152, 127–137. [Google Scholar] [CrossRef]
- Liss, K.D.; Garbe, U.; Li, H.J.; Schambron, T.; Almer, J.D.; Yan, K. In Situ Observation of Dynamic Recrystallization in the Bulk of Zirconium Alloy. Adv. Eng. Mater 2009, 11, 637–640. [Google Scholar] [CrossRef]
- Osher, S.; Fedkiw, R.P. Level set methods: An overview and some recent results. J. Comput. Phys. 2001, 169, 463–502. [Google Scholar] [CrossRef] [Green Version]
- Rodgers, T.M.; Madison, J.D.; Tikare, V. Simulation of metal additive manufacturing microstructures using kinetic Monte Carlo. Comput. Mater. Sci. 2017, 135, 78–89. [Google Scholar] [CrossRef]
- Wei, L.; Lin, X.; Wang, M.; Huang, W.D. Cellular automaton simulation of the molten pool of laser solid forming process. Acta. Phys. Sin.-Chi. Ed. 2015, 64, 018103. [Google Scholar] [CrossRef]
- Bai, Y.; Wang, Y.; Zhang, S.; Wang, Q.; Li, R. Numerical Model Study of Multiple Dendrite Motion Behavior in Melt Based on LBM-CA Method. Crystals 2020, 10, 70. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Wang, Y.; Zhang, S.; Guo, B.; Li, C.; Li, R. Numerical Simulation of Three-Dimensional Dendrite Movement Based on the CA–LBM Method. Crystals 2021, 11, 1056. [Google Scholar] [CrossRef]
- Zhang, X.F.; Zhao, J.Z. Effect of forced flow on three dimensional dendritic growth of al-cu alloys. Acta. Met. Sin. 2012, 48, 615–620. [Google Scholar] [CrossRef]
- Wang, W.; Wang, Z.; Yin, S.; Luo, S.; Zhu, M. Numerical simulation of solute undercooling influenced columnar to equiaxed transition of Fe-C alloy with cellular automaton. Comput. Mater. Sci. 2019, 167, 52–64. [Google Scholar] [CrossRef]
- Ma, W.; Li, R.; Chen, H. Three-Dimensional CA-LBM Model of Silicon Facet Formation during Directional Solidification. Crystals 2020, 10, 669. [Google Scholar] [CrossRef]
- SenGupta, A.; Santillana, B.; Sridhar, S.; Auinger, M. Dendrite growth direction measurements: Understanding the solute advancement in continuous casting of steel. IOP Conf. Ser. Mater. Sci. Eng. 2019, 529, 012065. [Google Scholar] [CrossRef]
- Beltran-Sanchez, L.; Stefanescu, D.M. Growth of solutal dendrites: A cellular automaton model and its quantitative capabilities. Met. Mater. Trans. A 2003, 34, 367–382. [Google Scholar] [CrossRef]
- Wei, L.; Lin, X.; Wang, M.; Huang, W. A cellular automaton model for the solidification of a pure substance. Appl. Phys. A Mater. 2010, 103, 123–133. [Google Scholar] [CrossRef]
- Rappaz, M.; Gandin, C.A. Probabilistic modelling of microstructure formation in solidification proc. Acta Mater. 1993, 41, 345–360. [Google Scholar] [CrossRef]
- Wang, W.; Lee, P.D.; McLean, M. A model of solidification microstructures in nickel-based superalloys: Predicting primary dendrite spacing selection. Acta Mater. 2003, 51, 2971–2987. [Google Scholar] [CrossRef]
- Yuan, L.; Lee, P.D. Dendritic solidification under natural and forced convection in binary alloys: 2D versus 3D simulation. Model. Simul. Mater. Sci. 2010, 18, 055008. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, D.F.; Long, M.J.; Arif, T.T.; Qin, R.S. A Three-Dimensional Cellular Automata Model for Dendrite Growth with Various Crystallographic Orientations During Solidification. Met. Mater. Trans. B 2014, 45, 719–725. [Google Scholar] [CrossRef]
- Chen, R.; Xu, Q.; Liu, B. A Modified Cellular Automaton Model for the Quantitative Prediction of Equiaxed and Columnar Dendritic Growth. J. Mater. Sci. Technol. 2014, 30, 1311–1320. [Google Scholar] [CrossRef]
- Luo, S.; Zhu, M.Y. A two-dimensional model for the quantitative simulation of the dendritic growth with cellular automaton method. Comput. Mater. Sci. 2013, 71, 10–18. [Google Scholar] [CrossRef]
- Wang, W.L.; Luo, S.; Zhu, M.Y. Development of a CA-FVM Model with Weakened Mesh Anisotropy and Application to Fe–C Alloy. Crystals 2016, 6, 147. [Google Scholar] [CrossRef] [Green Version]
- Wei, L.; Lin, X.; Wang, M.; Huang, W.D. Orientation selection of equiaxed dendritic growth by three-dimensional cellular automaton model. Phys. B 2012, 407, 2471–2475. [Google Scholar] [CrossRef] [Green Version]
- Provatas, N.; Greenwood, M.; Athreya, B.; Goldenfeld, N.; Dantzig, J. Multiscale modeling of solidification: Phase-field methods to adaptive mesh refinement. Int. J. Mod. Phys. B 2005, 19, 4525–4565. [Google Scholar] [CrossRef] [Green Version]
- Jelinek, B.; Eshraghi, M.; Felicelli, S.; Peters, J.F. Large-scale parallel lattice Boltzmann-cellular automaton model of two-dimensional dendritic growth. Comput. Phys. Commun. 2014, 185, 939–947. [Google Scholar] [CrossRef]
- Feng, W.M.; Xu, Q.Y.; Liu, B.C. Microstructure simulation of aluminum alloy using parallel computing technique. ISIJ Int. 2002, 42, 702–707. [Google Scholar] [CrossRef]
- Campos, R.S.; Lobosco, M.; dos Santos, R.W. A GPU-based heart simulator with mass-spring systems and cellular automaton. J. Supercomput. 2014, 69, 1–8. [Google Scholar] [CrossRef]
- Yam-Uicab, R.; Lopez-Martinez, J.; Trejo-Sanchez, J.; Hidalgo-Silva, H.; Gonzalez-Segura, S. A fast Hough Transform algorithm for straight lines detection in an image using GPU parallel computing with CUDA-C. J. Supercomput. 2017, 73, 4823–4842. [Google Scholar] [CrossRef]
- Aoki, T.; Ogawa, S.; Yamanaka, A. Multiple-GPU Scalability of Phase-Field Simulation for Dendritic Solidification Progress in nuclear science and technology. Prog. Nucl. Sci. Technol. 2011, 2, 639–642. [Google Scholar]
- Takaki, T.; Rojas, R.; Ohno, M.; Shimokawabe, T.; Aoki, T. GPU phase-field lattice Boltzmann simulations of growth and motion of a binary alloy dendrite. IOP Conf. Ser. Mater. Sci. Eng. 2015, 84, 012066. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Xu, Q.; Liu, B. GPU-accelerated three-dimensional phase-field simulation of dendrite growth in a nickel-based superalloy. Comput. Mater. Sci. 2017, 136, 133–143. [Google Scholar] [CrossRef]
- Sakane, S.; Takaki, T.; Rojas, R.; Ohno, M.; Shibuta, Y.; Shimokawabe, T.; Aoki, T. Multi-GPUs parallel computation of dendrite growth in forced convection using the phase-field-lattice Boltzmann model. J. Cryst. Growth 2017, 474, 154–159. [Google Scholar] [CrossRef]
- Yang, C.; Xu, Q.Y.; Liu, B.C. Primary dendrite spacing selection during directional solidification of multicomponent nickel-based superalloy: Multiphase-field study. J. Mater. Sci. 2018, 53, 9755–9770. [Google Scholar] [CrossRef]
- Sakane, S.; Takaki, T.; Ohno, M.; Shimokawabe, T.; Aoki, T. GPU-accelerated 3D phase-field simulations of dendrite competitive growth during directional solidification of binary alloy. IOP Conf. Ser. Mater. Sci. Eng. 2015, 84, 012063. [Google Scholar] [CrossRef] [Green Version]
- Kao, A.; Krastins, I.; Alexandrakis, M.; Shevchenko, N.; Eckert, S.; Pericleous, K. A Parallel Cellular Automata Lattice Boltzmann Method for Convection-Driven Solidification. JOM 2019, 71, 48–58. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.M.; Wei, J.J.; Wang, X.D.; Yao, M. Progress and Application of Microstructure Simulation of Alloy Solidification. Acta Met. Sin. 2018, 54, 193–203. [Google Scholar]
- Shin, Y.H.; Hong, C.P. Modeling of dendritic growth with convection using a modified cellular automaton model with a diffuse interface. ISIJ Int. 2002, 42, 359–367. [Google Scholar] [CrossRef]
- Wang, J.J.; Meng, H.J.; Yang, J.; Xie, Z. A fast method based on GPU for solidification structure simulation of continuous casting billets. J. Comput. Sci. 2021, 48, 101265. [Google Scholar] [CrossRef]
- Beltran, S.L.; Stefanescu, D.M. A quantitative dendrite growth model and analysis of stability concepts. Met. Mater. Trans. A 2004, 35a, 2471–2485. [Google Scholar] [CrossRef]
- Wang, W.L.; Ji, C.; Luo, S.; Zhu, M.Y. Modeling of Dendritic Evolution of Continuously Cast Steel Billet with Cellular Automaton. Met. Mater. Trans. B 2018, 49, 200–212. [Google Scholar] [CrossRef]
- Nastac, L. Numerical modeling of solidification morphologies and segregation patterns in cast dendritic alloys. Acta Mater. 1999, 47, 4253–4262. [Google Scholar] [CrossRef]
- Yasuda, H.; Yamamoto, Y.; Nakatsuka, N.; Yoshiya, M.; Nagira, T.; Sugiyama, A.; Ohnaka, I.; Uesugi, K.; Umetani, K. In situ observation of solidification phenomena in Al-Cu and Fe-Si-Al alloys. Int. J. Cast Met. Res. 2009, 22, 15–21. [Google Scholar] [CrossRef]
- Kurz, W.; Fisher, D.J. Fundamentals of Solidification, 3rd ed.; Trans Tech Publication: Aedermannsdorf, Switzerland, 1992; pp. 71–92. [Google Scholar]
- Cheng, J.; Crossman, M.; Mckercher, T. Professional CUDA C Programming; John Wiley & Sons, Inc.: Indianapolis, Indiana, 2014; p. 96. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kernel Functions | Computation Task |
|---|---|
| capturing neighbors | |
| solute diffusion coefficient | |
| solute diffusion | |
| solute redistribution in interface | |
| temperature distribution | |
| equilibrium solute | |
| velocity and the arm length | |
| storing data for the next slice |
| Property and Symbol | Fe–0.6C | Fe–5.3Si |
|---|---|---|
| Initial composition, | 0.6 | 5.3 |
| Liquidus temperature | 1763.37 | 1732.87 |
| Liquidus slope, | −80 | −7.6 |
| Solute partition coefficient, | 0.34 | 0.77 |
| Solute diffusion coefficient in liquid | 2 × 10−9 | 8.0 × 10−4exp (−29,943.23/T) |
| Solute diffusion coefficient in solid | 5 × 10−10 | 8.0 × 10−8exp (−29,943.23/T) |
| Gibbs-Thomson coefficient, | 1.9 × 10−7 | 1.9 × 10−7 |
| Kernel Configuration | Time Elapsed (s) |
|---|---|
| (128,1) | 37.94 |
| (128,2) | 37.64 |
| (128,4) | 38.85 |
| (64,4) | 37.59 |
| (64,2) | 37.53 |
| (62,1) | 38.13 |
| (32,8) | 37.70 |
| (32,4) | 37.23 |
| (32,2) | 37.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Meng, H.; Yang, J.; Xie, Z. GPU-Based Cellular Automata Model for Multi-Orient Dendrite Growth and the Application on Binary Alloy. Crystals 2023, 13, 105. https://doi.org/10.3390/cryst13010105
Wang J, Meng H, Yang J, Xie Z. GPU-Based Cellular Automata Model for Multi-Orient Dendrite Growth and the Application on Binary Alloy. Crystals. 2023; 13(1):105. https://doi.org/10.3390/cryst13010105
Chicago/Turabian StyleWang, Jingjing, Hongji Meng, Jian Yang, and Zhi Xie. 2023. "GPU-Based Cellular Automata Model for Multi-Orient Dendrite Growth and the Application on Binary Alloy" Crystals 13, no. 1: 105. https://doi.org/10.3390/cryst13010105
APA StyleWang, J., Meng, H., Yang, J., & Xie, Z. (2023). GPU-Based Cellular Automata Model for Multi-Orient Dendrite Growth and the Application on Binary Alloy. Crystals, 13(1), 105. https://doi.org/10.3390/cryst13010105