Crop Yield Prediction through Proximal Sensing and Machine Learning Algorithms



Abstract
:1. Introduction
2. Materials and Methods
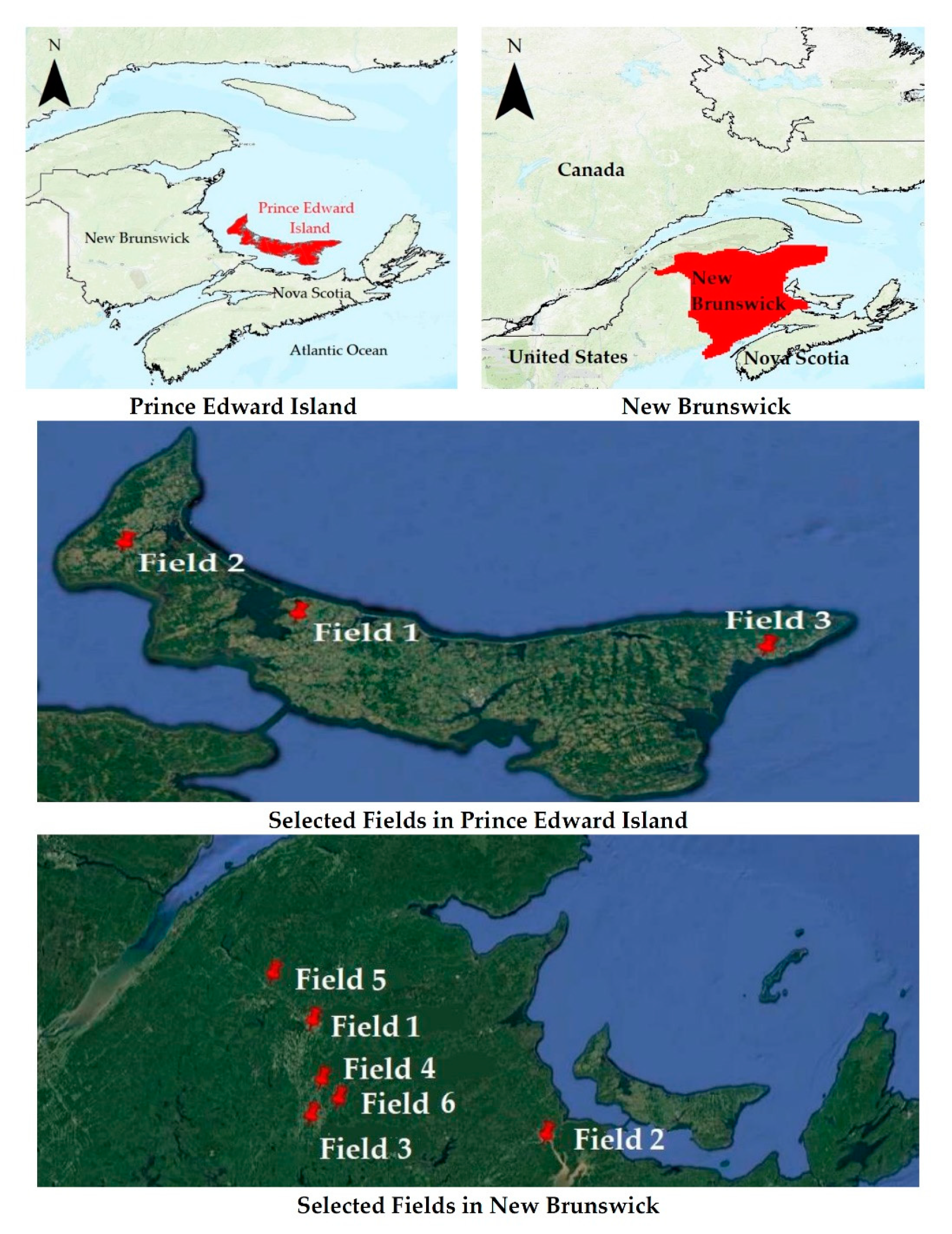
2.1. Collection of Data and the Study Sites
2.2. Proximal Sensing Data
2.3. Soil Sampling Data
2.4. Yield Data
2.5. Machine Learning Algorithms
2.5.1. Linear Regression
2.5.2. Elastic Net
2.5.3. k-Nearest Neighbors (k-NN)
2.5.4. Support Vector Regression
2.6. Tuning of Hyperparameter for Reproducibility
2.7. Model Evaluation Criteria
3. Results and Discussion
3.1. Descriptive Statistics
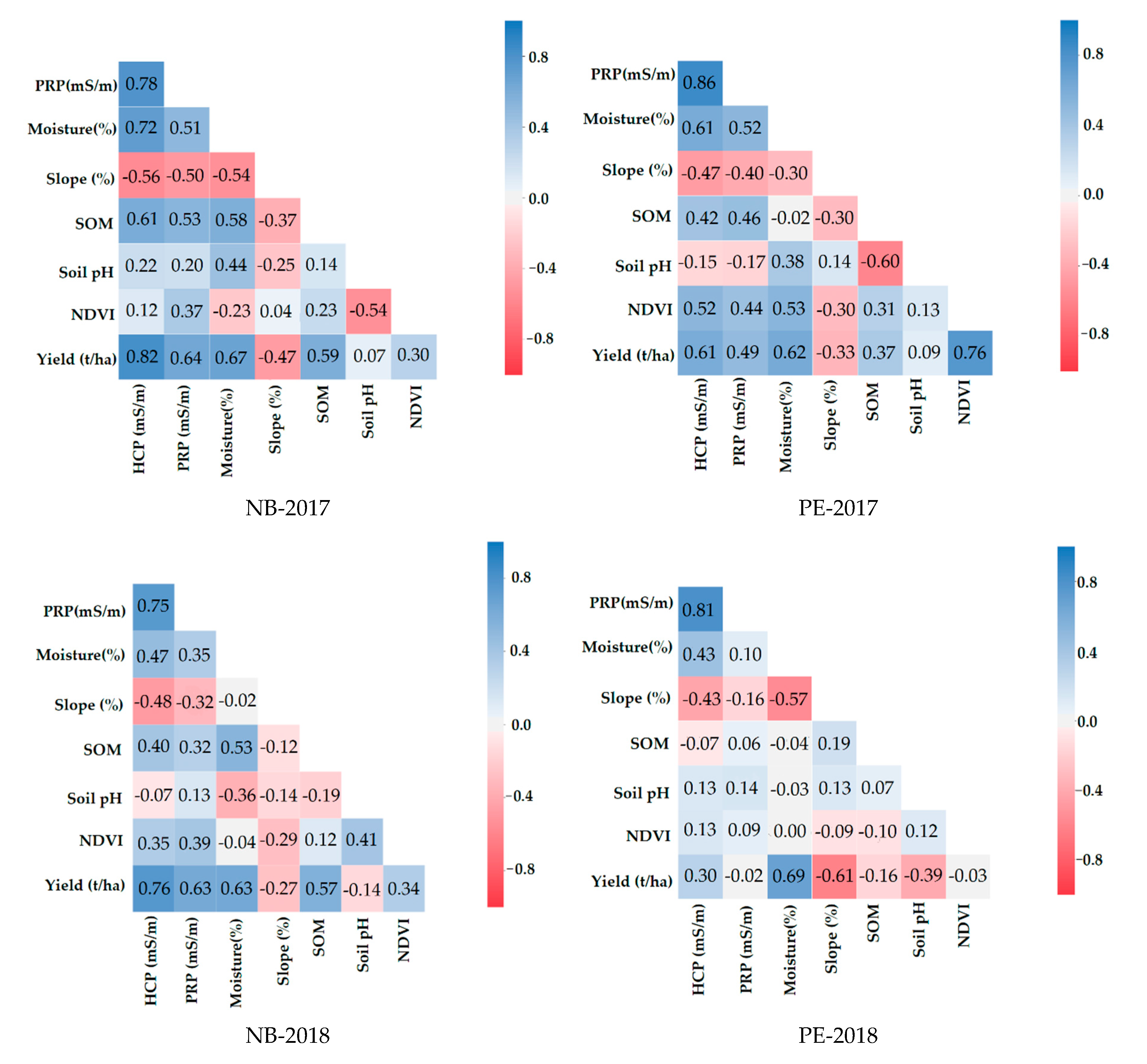
3.2. Correlation Analysis
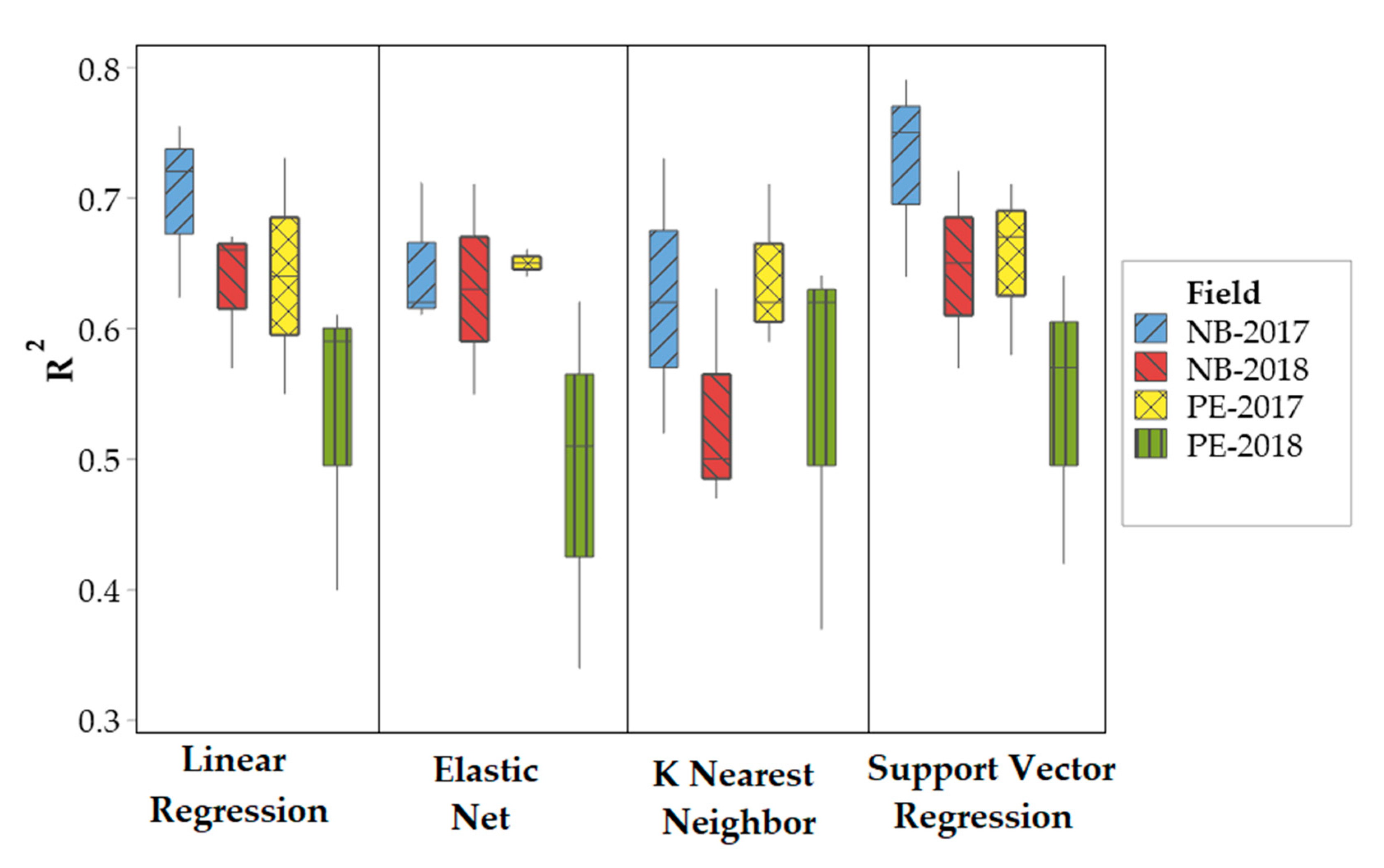
3.3. Evaluation of Machine Learning Algorithms
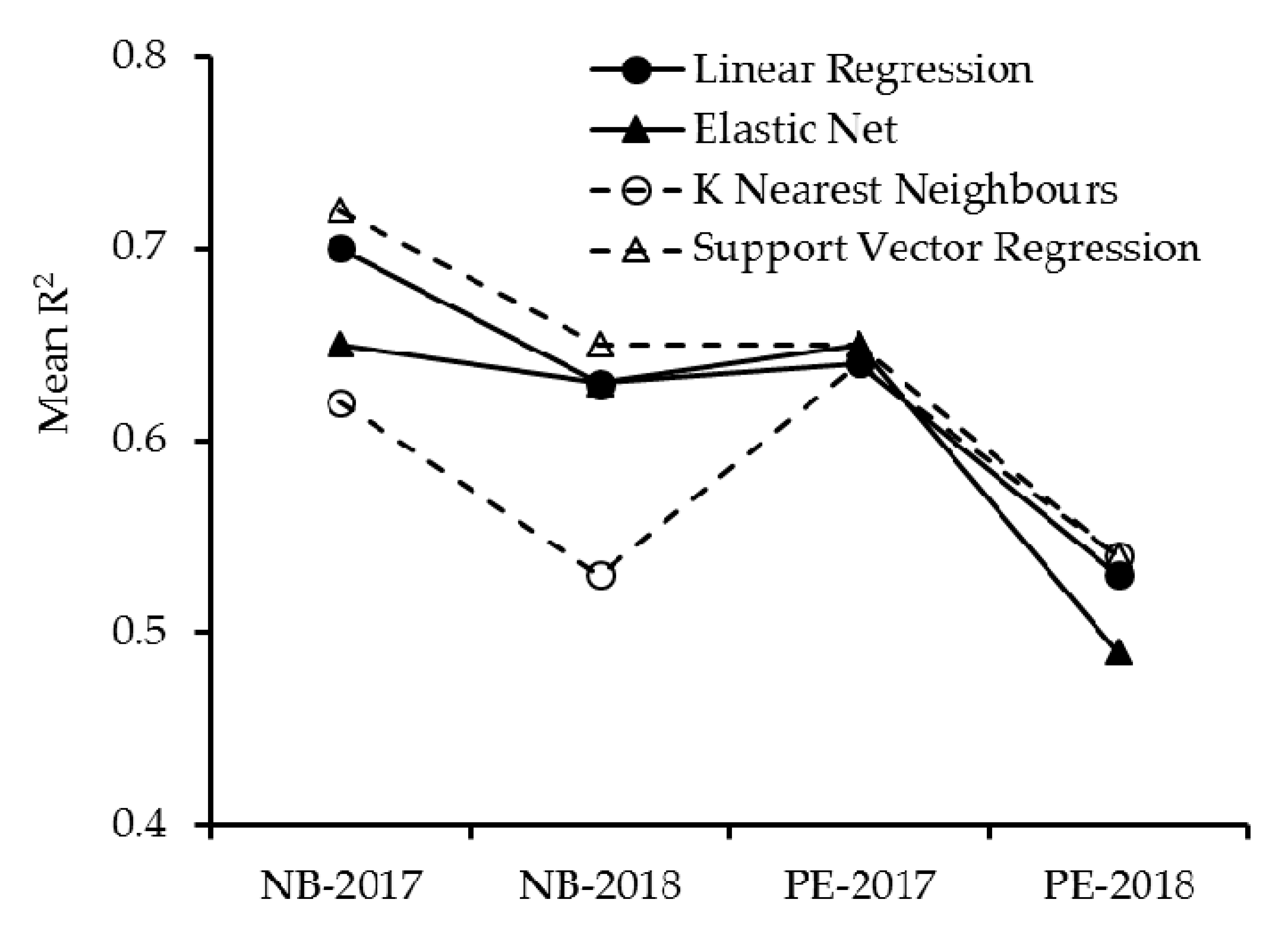
3.4. Comparative Analysis of Machine Learning Algorithms
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Agriculture and Agri-Food Canada (AAFC) Potato Market Information Review 2016–2017. Available online: https://www5.agr.gc.ca/eng/industry-markets-and-trade/canadian-agri-food-sector-intelligence/horticulture/horticulture-sector-reports/potato-market-information-review-2016-2017/?id=1536104016530#a1.2.3 (accessed on 15 January 2020).
- Drummond, S.T.; Sudduth, K.A.; Joshi, A.; Birrell, S.J.; Kitchen, N.R. Statistical and neural methods for site-specific yield prediction. Trans. Am. Soc. Agric. Eng. 2003, 46, 5–14. [Google Scholar] [CrossRef] [Green Version]
- Varcoe, V.J. A note on the computer simulation of crop growth in agricultural land evaluation. Soil Use Manag. 1990, 6, 157–160. [Google Scholar] [CrossRef]
- Farooque, A.A.; Zaman, Q.U.; Schumann, A.W.; Madani, A.; Percival, D.C. Response of wild blueberry yield to spatial variability of soil properties. Soil Sci. 2012, 177, 56–68. [Google Scholar] [CrossRef]
- Kitchen, N.R.; Drummond, S.T.; Lund, E.D.; Sudduth, K.A.; Buchleiter, G.W. Soil electrical conductivity and topography related to yield for three contrasting soil-crop systems. Agron. J. 2003, 95, 483–495. [Google Scholar]
- Drummond, S.T.; Birrell, S.; Sudduth, K.A. Analysis and correlation methods for spatial data. ASAE 1995, 95, 9. [Google Scholar]
- Dai, X.; Huo, Z.; Wang, H. Simulation for response of crop yield to soil moisture and salinity with artificial neural network. Field Crop. Res. 2011, 121, 441–449. [Google Scholar] [CrossRef]
- Cousens, R. An empirical model relating crop yield to weed and crop density and a statistical comparison with other models. J. Agric. Sci. 1985, 105, 513–521. [Google Scholar] [CrossRef]
- Dourado-Neto, D.; Teruel, D.A.; Reichardt, K.; Nielsen, D.R.; Frizzone, J.A.; Bacchi, O.O.S. Principles of crop modeling and simulation: I. uses of mathematical models in agricultural science. Sci. Agric. 1998, 55, 46–50. [Google Scholar] [CrossRef] [Green Version]
- Doraiswamy, P.C.; Moulin, S.; Cook, P.W.; Stern, A. Crop yield assessment from remote sensing. Photogramm. Eng. Remote Sens. 2003, 69, 665–674. [Google Scholar] [CrossRef]
- Prasad, A.K.; Chai, L.; Singh, R.P.; Kafatos, M. Crop yield estimation model for Iowa using remote sensing and surface parameters. Int. J. Appl. Earth Obs. Geoinf. 2006, 8, 26–33. [Google Scholar] [CrossRef]
- Kaul, M.; Hill, R.L.; Walthall, C. Artificial neural networks for corn and soybean yield prediction. Agric. Syst. 2005, 85, 1–18. [Google Scholar] [CrossRef]
- Miao, Y.; Mulla, D.J.; Robert, P.C. Identifying important factors influencing corn yield and grain quality variability using artificial neural networks. Precis. Agric. 2006, 7, 117–135. [Google Scholar] [CrossRef]
- Das, B.; Nair, B.; Reddy, V.K.; Venkatesh, P. Evaluation of multiple linear, neural network and penalised regression models for prediction of rice yield based on weather parameters for west coast of India. Int. J. Biometeorol. 2018, 62, 1809–1822. [Google Scholar] [CrossRef] [PubMed]
- Shahhosseini, M.; Martinez-Feria, R.A.; Hu, G.; Archontoulis, S.V. Maize yield and nitrate loss prediction with machine learning algorithms. Environ. Res. Lett. 2019, 14, 124026. [Google Scholar] [CrossRef] [Green Version]
- Pantazi, X.E.; Moshou, D.; Alexandridis, T.; Whetton, R.L.; Mouazen, A.M. Wheat yield prediction using machine learning and advanced sensing techniques. Comput. Electron. Agric. 2016, 121, 57–65. [Google Scholar] [CrossRef]
- Farooque, A.; Zare, M.; Zaman, Q.; Abbas, F.; Bos, M.; Esau, T.; Acharya, B.; Schumann, A. Evaluation of DualEM-II sensor for soil moisture content estimation in the potato fields of Atlantic Canada. Plant Soil Environ. 2019, 65, 290–297. [Google Scholar] [CrossRef] [Green Version]
- Taylor, R. Introducing Dualem to the IUSS Working Group on Proximal Soil Sensing. Available online: http://www.landbrugsinfo.dk/Planteavl/Praecisionsjordbrug-og-GIS/Filer/pl_11_562_b1_Dualem.pdf (accessed on 4 May 2020).
- Heiri, O.; Lotter, A.F.; Lemcke, G. Loss on ignition as a method for estimating organic and carbonate content in sediments: Reproducibility and comparability of results. J. Paleolimnol. 2001, 25, 101–110. [Google Scholar] [CrossRef]
- Patterson, G.T.; Carter, M.R. Soil Sampling and Methods of Analysis, 2nd ed.; Carter, M.R., Gregorich, E.G., Eds.; CRC Press Taylor & Francis Group: Boca Raton, FL, USA, 2007; Volume 44, ISBN 9780849335860. [Google Scholar]
- Angrist, J.D.; Pischke, J.-S. Mostly Harmless Econometrics: An Empiricist’s Companion; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Fix, E. Discriminatory Analysis: Nonparametric Discrimination, Consistency Properties; USAF School of Aviation Medicine: Dayton, OH, USA, 1951. [Google Scholar]
- Cover, T.M.; Hart, P.E. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Drucker, H.; Surges, C.J.C.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 1997; Volume 9, pp. 155–161. [Google Scholar]
- Kastens, J.H. Small sample behaviors of the delete-d cross validation statistic. Open J. Stat. 2015, 5. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhu, Y.; Zhang, X.; Ye, M.; Yang, J. Developing a Long Short-Term Memory (LSTM) based model for predicting water table depth in agricultural areas. J. Hydrol. 2018, 561, 918–929. [Google Scholar] [CrossRef]
- Afzaal, H.; Farooque, A.A.; Abbas, F.; Acharya, B.; Esau, T. Groundwater estimation from major physical hydrology components using artificial neural networks and deep learning. Water 2019, 12, 5. [Google Scholar] [CrossRef] [Green Version]
- Üstün, B.; Melssen, W.J.; Buydens, L.M.C. Facilitating the application of Support Vector Regression by using a universal Pearson VII function based kernel. Chemom. Intell. Lab. Syst. 2006, 81, 29–40. [Google Scholar] [CrossRef]
- Pan, Y.; Jiang, J.; Wang, R.; Cao, H. Advantages of support vector machine in QSPR studies for predicting auto-ignition temperatures of organic compounds. Chemom. Intell. Lab. Syst. 2008, 92, 169–178. [Google Scholar] [CrossRef]
- Poudel, S.; Shaw, R. The relationships between climate variability and crop yield in a mountainous environment: A case study in Lamjung District, Nepal. Climate 2016, 4, 13. [Google Scholar] [CrossRef] [Green Version]
- Maqsood, J.; Farooque, A.A.; Wang, X.; Abbas, F.; Acharya, B.; Afzaal, H. Contribution of Climate Extremes to Potato Tuber Yield: A Sustainability Prospective for Future Strategies. Sustainability 2020, 12, 4937. [Google Scholar] [CrossRef]
- Farooque, A.A.; Zare, M.; Abbas, F.; Bos, M.; Esau, T.; Zaman, Q. Forecasting potato tuber yield using a soil electromagnetic induction method. Eur. J. Soil Sci. 2019, 1–18. [Google Scholar] [CrossRef]
- Zare, M.; Farooque, A.A.; Abbas, F.; Zaman, Q.; Bos, M. Trends in the variability of potato tuber yield under selected land and soil characteristics. Plant Soil Environ. 2019, 65, 111–117. [Google Scholar] [CrossRef] [Green Version]
- Afzaal, H.; Farooque, A.A.; Abbas, F.; Acharya, B.; Esau, T. Precision Irrigation Strategies for Sustainable Water Budgeting of Potato Crop in Prince Edward Island. Sustainability 2020, 12, 2419. [Google Scholar] [CrossRef] [Green Version]
- Abera Guluma, D. International journal of agriculture & agribusiness factors affecting potato (Solanum tuberosum L.) tuber seed quality in mid and highlands: A review dejene abera guluma. Int. J. Zambrut 2020, 7, 24–40. [Google Scholar]
- Nurmanov, Y.T.; Chernenok, V.G.; Kuzdanova, R.S. Potato in response to nitrogen nutrition regime and nitrogen fertilization. Field Crop. Res. 2019, 231, 115–121. [Google Scholar] [CrossRef]
- Wang, X.; Guo, T.; Wang, Y.; Xing, Y.; Wang, Y.; He, X. Exploring the optimization of water and fertilizer management practices for potato production in the sandy loam soils of Northwest China based on PCA. Agric. Water Manag. 2020, 237, 106180. [Google Scholar] [CrossRef]
- Kumar, N.; Prasad, V.; Pal Yadav, N. Effect of chemical fertilizers and bio fertilizers on flower yield, tuberous root yield and quality parameter on dahlia (Dahlia variabilis L.) cv. Kenya orange. J. Pharmacogn. Phytochem. 2019, 8, 2265–2267. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Province | Year | Dataset Name | Training Points | Testing Points | Fields Location |
|---|---|---|---|---|---|
| Prince Edward Island | 2017 | PE-2017 | 80 | 40 | Field 1 |
| Field 2 | |||||
| Field 3 | |||||
| 2018 | PE-2018 | 79 | 40 | Field 1 | |
| Field 2 | |||||
| Field 3 | |||||
| New Brunswick | 2017 | NB-2017 | 80 | 40 | Field 1 |
| Field 2 | |||||
| Field 3 | |||||
| 2018 | NB-2018 | 80 | 40 | Field 4 | |
| Field 5 | |||||
| Field 6 |
| Algorithm | Hyperparameters Tuning | ||
|---|---|---|---|
| Elastic net | Penalty multiplier | Alpha | 1 |
| Mixing parameters of penalties | L1 Ratio | 0.5 | |
| Number of repetitions | Maximum iterations | 1000 | |
| Random number updates | Selection method | Cyclic | |
| Random number generator | Random state | Seed | |
| k-nearest neighbor | Number of neighbors | n_neighbors | 5 |
| Assignment of weight | weight | uniform | |
| Controlling parameter | leaf size | 30 | |
| Distance calculation parameter | P | 2 | |
| Distance calculation method | Metric | Minkowski | |
| Support vector regression | Defining algorithms | Kernel | Linear |
| Regularization parameter | C | 1 | |
| Kernel coefficient | Gamma | Scale | |
| Penalty association | Epsilon | 0.1 | |
| Reducing factor | shrinking | TRUE | |
| Linear Regression | Intercept calculation | Fit Intercept | TRUE |
| Data normalization | Normalize | FALSE | |
| True X copying | Copy_X | TRUE | |
| Number of iterations | n_jobs | None | |
| Field | Variable | Mean ± SD | Minimum | Maximum | Variable | Mean ± SD | Minimum | Maximum |
|---|---|---|---|---|---|---|---|---|
| NB-2017 | Yield (t/ha) | 53.9 ± 11.2 | 26.2 | 78.9 | Slope (%) | 2.42 ± 1.31 | 0.10 | 4.94 |
| NB-2018 | 43.4 ± 8.17 | 23.3 | 61.0 | 2.79 ± 1.79 | 0.20 | 8.10 | ||
| PE-2017 | 47.7 ± 11.3 | 25.5 | 80.0 | 2.04 ± 1.10 | 0.40 | 5.00 | ||
| PE-2018 | 48.2 ± 10.0 | 26.2 | 83.2 | 2.27 ± 0.68 | 0.76 | 4.69 | ||
| NB-2017 | HCP (mS/m) | 5.85 ± 1.52 | 2.54 | 10.8 | SOM (%) | 3.82 ± 0.86 | 2.20 | 6.63 |
| NB-2018 | 5.42 ± 1.54 | 2.40 | 8.60 | 3.81 ± 0.79 | 2.60 | 5.90 | ||
| PE-2017 | 6.31 ± 1.87 | 2.80 | 10.0 | 2.22 ± 0.50 | 0.80 | 3.20 | ||
| PE-2018 | 6.56 ± 1.32 | 3.38 | 10.5 | 2.66 ± 0.37 | 1.25 | 3.85 | ||
| NB-2017 | PRP (mS/m) | 5.14 ± 1.47 | 1.74 | 9.50 | Soil pH | 5.61 ± 0.40 | 4.85 | 7.10 |
| NB-2018 | 4.04 ± 1.27 | 1.30 | 7.10 | 5.79 ± 0.55 | 4.60 | 7.20 | ||
| PE-2017 | 4.69 ± 1.45 | 1.40 | 7.70 | 5.55 ± 0.21 | 5.10 | 6.10 | ||
| PE-2018 | 4.09 ± 1.14 | 1.87 | 7.45 | 5.71 ± 0.26 | 5.15 | 6.50 | ||
| NB-2017 | Soil Moisture (%) | 17.5 ± 3.89 | 9.96 | 27.7 | NDVI | 0.79 ± 0.06 | 0.66 | 0.92 |
| NB-2018 | 8.37 ± 2.85 | 3.40 | 16.3 | 0.58 ± 0.06 | 0.50 | 0.70 | ||
| PE-2017 | 15.6 ± 3.95 | 6.80 | 25.7 | 0.83 ± 0.06 | 0.70 | 0.90 | ||
| PE-2018 | 11.0 ± 1.77 | 6.33 | 16.7 | 0.50 ± 0.10 | 0.35 | 0.92 |
| Site | Year | Algorithm | MAE (t/ha) | RMSE (t/ha) | Mean R2 | Std. Dev. (R2) |
|---|---|---|---|---|---|---|
| New Brunswick | 2018 | Linear Regression | 3.59 | 4.69 | 0.63 | 0.04 |
| Elastic Net | 3.79 | 4.72 | 0.63 | 0.06 | ||
| k-Nearest Neighbor | 4.21 | 5.23 | 0.53 | 0.07 | ||
| Support vector regression | 3.60 | 4.62 | 0.65 | 0.06 | ||
| 2017 | Linear Regression | 4.77 | 6.19 | 0.70 | 0.05 | |
| Elastic Net | 5.60 | 6.67 | 0.65 | 0.04 | ||
| k-Nearest Neighbor | 5.57 | 6.93 | 0.62 | 0.09 | ||
| Support vector regression | 4.68 | 5.97 | 0.72 | 0.07 | ||
| Prince Edward Island | 2018 | Linear Regression | 5.01 | 6.24 | 0.53 | 0.09 |
| Elastic Net | 5.27 | 6.54 | 0.49 | 0.11 | ||
| k-Nearest Neighbor | 4.85 | 6.49 | 0.54 | 0.12 | ||
| Support vector regression | 4.95 | 6.17 | 0.54 | 0.09 | ||
| 2017 | Linear Regression | 5.23 | 6.70 | 0.64 | 0.07 | |
| Elastic Net | 5.57 | 6.74 | 0.65 | 0.01 | ||
| k-Nearest Neighbor | 5.62 | 6.91 | 0.64 | 0.05 | ||
| Support vector regression | 5.18 | 6.60 | 0.65 | 0.06 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, F.; Afzaal, H.; Farooque, A.A.; Tang, S. Crop Yield Prediction through Proximal Sensing and Machine Learning Algorithms. Agronomy 2020, 10, 1046. https://doi.org/10.3390/agronomy10071046
Abbas F, Afzaal H, Farooque AA, Tang S. Crop Yield Prediction through Proximal Sensing and Machine Learning Algorithms. Agronomy. 2020; 10(7):1046. https://doi.org/10.3390/agronomy10071046
Chicago/Turabian StyleAbbas, Farhat, Hassan Afzaal, Aitazaz A. Farooque, and Skylar Tang. 2020. "Crop Yield Prediction through Proximal Sensing and Machine Learning Algorithms" Agronomy 10, no. 7: 1046. https://doi.org/10.3390/agronomy10071046
APA StyleAbbas, F., Afzaal, H., Farooque, A. A., & Tang, S. (2020). Crop Yield Prediction through Proximal Sensing and Machine Learning Algorithms. Agronomy, 10(7), 1046. https://doi.org/10.3390/agronomy10071046