1. Introduction and Related Works
Apple is one of the most popular fruits, and its output is also among the top three in global fruit sales. According to incomplete statistics, there are more than 7500 types of known apples [
1] in the world. However, experienced farmers are still the main force of agricultural production. Manual work consumes time and increases production costs, and workers who lack knowledge and experience will make unnecessary mistakes. With the continuous progress of precision agricultural technology, fruit picking robots have been widely used in agriculture. In the picking systems, there are mainly two subsystems: the vision system and the manipulator system [
2]. The vision system detects and localizes fruits and guides the manipulator to detach fruits from trees. Therefore, a robust and efficient vision system is the key to the success of the picking robot, but due to the complex background in orchards, there are still many challenges in this research.
For the complex background in orchards, the dense occlusion between leaves is one of the biggest interference factors in apple detection, which will cause false detection or missed detection of apples. Therefore, to make the model learn features better, the training data should contain more comprehensive scenes. However, due to the huge number of apples and complex background, apple labeling is a very time-consuming and energy-consuming task, which leads to the number of most datasets ranges from dozens to thousands of images [
3,
4,
5,
6,
7], and covers a single scene. The data for occlusion scenes is even scarcer, which is not conducive to enhancing the detection ability of the model. To overcome this deficiency, we propose a leaf illustration data augmentation method to expand the dataset. To further expand the number of the dataset and enrich the complexity of the scene, common data augmentation methods such as mirror, crop, brightness, blur, dropout, rotation, scale, and translation are also utilized in this paper. The experimental results show that the model trained by traditional augmentation techniques and an illustration augmentation technique proposed in this paper can well detect apples under complex scenes in orchards.
In recent years, the research on apple detection under complex scenes in orchards has also made some progress. Tian Y et al. [
8] proposed an improved YOLOv3 model to detect apples in different growth periods in orchards, with the F1 score of 0.817. Kang H et al. [
9] proposed a new LedNet model and an automatic labeling tool, with the Recall and the accuracy at 0.821 and 0.853, respectively. Mazzia V et al. [
10] used the YOLOv3-tiny model to match the embedded device, which achieved the detection speed of 30 fps without affecting the mean Average Precision (mAP) (83.64%). Kuznetsova A et al. [
11] proposed pre-processing and post-processing operations to adapt to the YOLOv3 model, the detection result shown that the average detection time was 19 ms, 7.8% of the objects were mistaken and 9.2% of apples were not recognized for apples. Gao F et al. [
12] used Faster Regions with Convolutional Neural Networks (Faster R-CNN) to detect apples in dense-foliage fruiting-wall trees, the experimental result was that the mAP was 0.879 and the average detection time was 0.241 s, which effectively detected apples under various occlusion conditions; Liu X et al. [
13] proposed an apple detection based on color and shape features method, the detection results were that the value of Recall, Precision, and F1 score reached 89.80%, 95.12%, and 92.38%, respectively. Jia W et al. [
14] combined ResNet and DenseNet to improve Mask R-CNN, which reduced the input parameters, with the Precision of 97.31% and the Recall of 95.70%.
For picking robots, the model should have fast and accurate detection performance. The YOLO [
15,
16,
17,
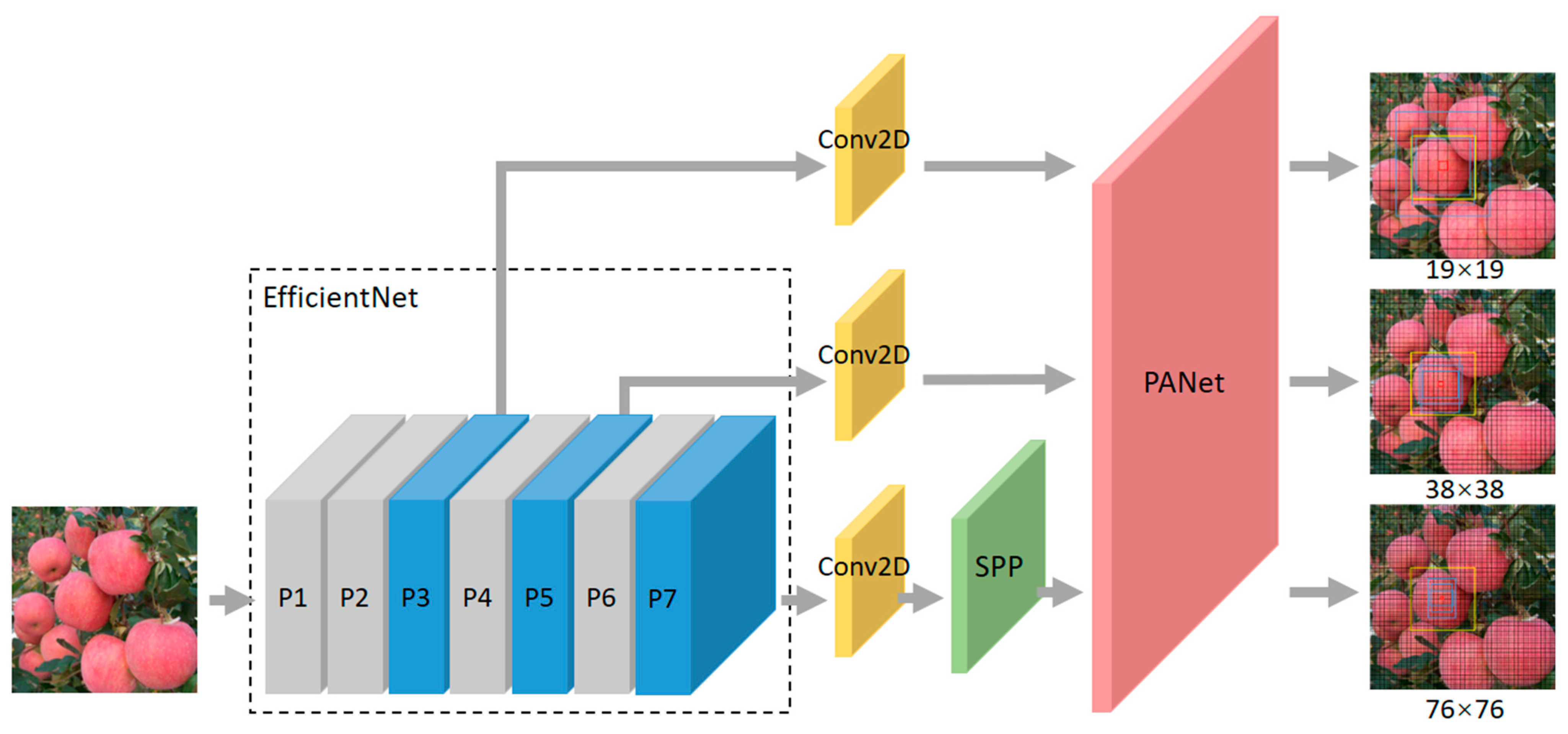
18] models unify object classification and object detection into a regression problem. The YOLO models do not use the area proposal process but directly use regression to detect objects. Therefore, the detection process is effectively accelerated. Compared with the YOLOv3 model, the latest version YOLOv4 model owns better accuracy under maintaining the same speed. However, the YOLOv4 model has not been widely used for fruit detection. Due to the large size and computational complexity of the YOLOv4 model, it is a huge burden for low-performance devices. EfficientNet [
19] uses a compound coefficient to balance the three dimensions (depth, width, and resolution) of the model on limited resources, which can maximize the accuracy of the model. Therefore, we utilize EfficientNet to replace the backbone network CSPDarrknet53 of the YOLOv4 model, and Conv2D is added to the three outputs to further extract and adjust the features, which can make the improved model lighter and better detection performance. The experimental results show that the improved model can be well applied to the vision system of the picking robot.
The rest of this paper is organized as follows.
Section 2 introduces the dataset collection, common data augmentation methods, and the proposed illustration data augmentation method.
Section 3 introduces YOLOv4, EfficientNet, and the improved EfficientNet-B0-YOLOv4 model.
Section 4 is experimental configuration, experimental results, and discussion. Finally, the conclusions and prospects of this paper are described.
5. Conclusions
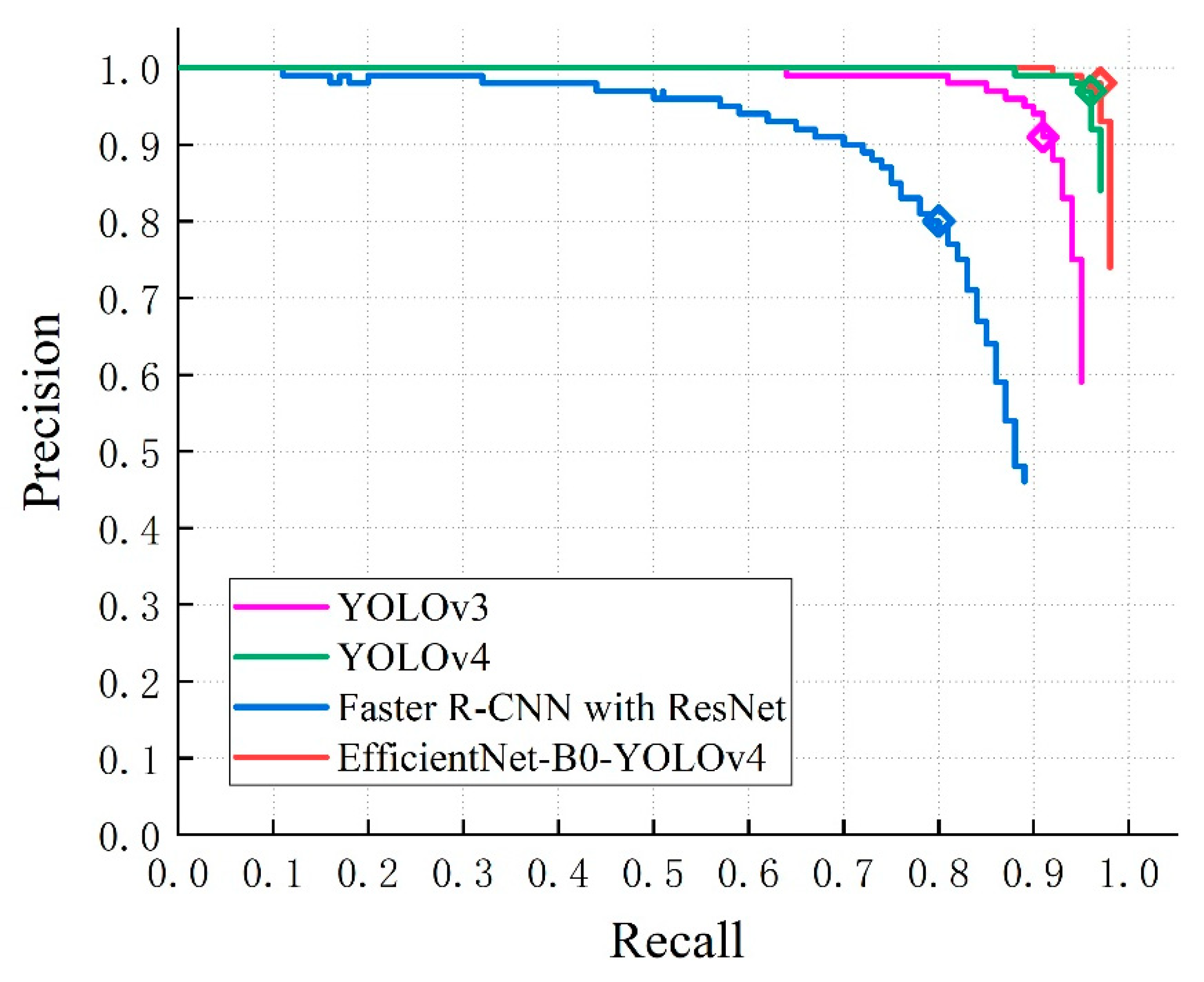
To simulate the possible complex scenes of apple detection in orchards and improve the apple dataset, an illustration data augmentation method is proposed and 8 common data augmentation methods are utilized to expand the dataset. On the expanded 2670 samples, the F1 of using the illustration data augmentation method has increased the most. Given the large size and computational complexity of the YOLOv4 model, EfficientNet is utilized to replace its backbone network CSPDarknet53. The improved EfficientNet-B0-YOLOv4 model has the F1 of 96.54%, the mAP of 98.15%, the Recall of 97.43%, and the average calculation time per frame of 0.338 s, which are better than the current popular YOLOv3 model, YOLOv4 model, and Faster R-CNN with ResNet model. Comparing the proposed EfficientNet-B0-YOLOv4 model with the original YOLOv4 model, the weight size is reduced by 35.25%, the parameter amount is reduced by 40.94%, and the calculation amount is reduced by 57.53%. In future work, we hope to add more apple classes for detection, and conduct level evaluation for each class after picking. For example, each class is divided into three levels: good, medium, and bad, thus forming a complete set of the apple detection system. Furthermore, we will continue to consolidate the illustration data augmentation method to improve the dataset.

















{kind=link}
{kind=link}
{kind=link}
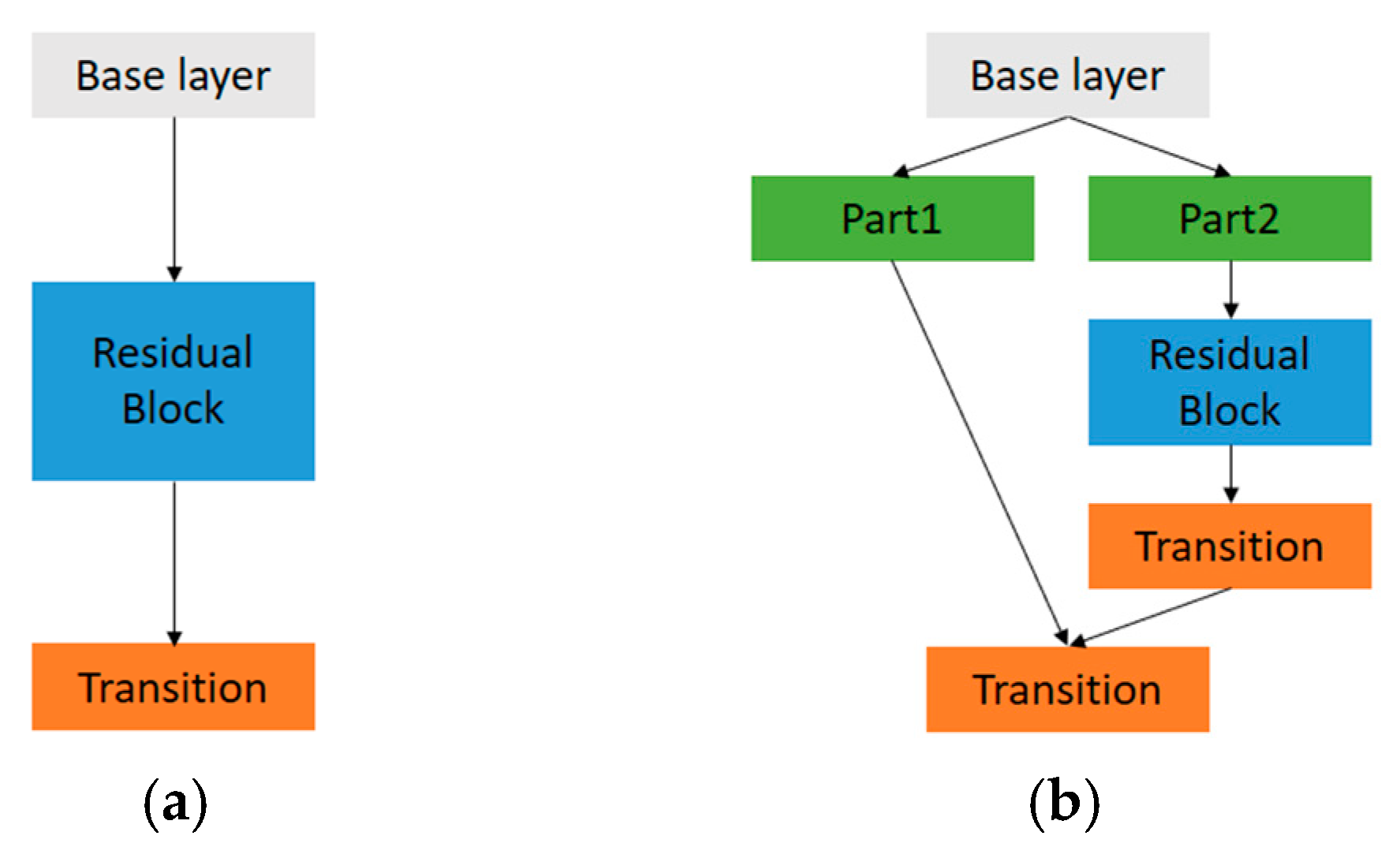{kind=link}
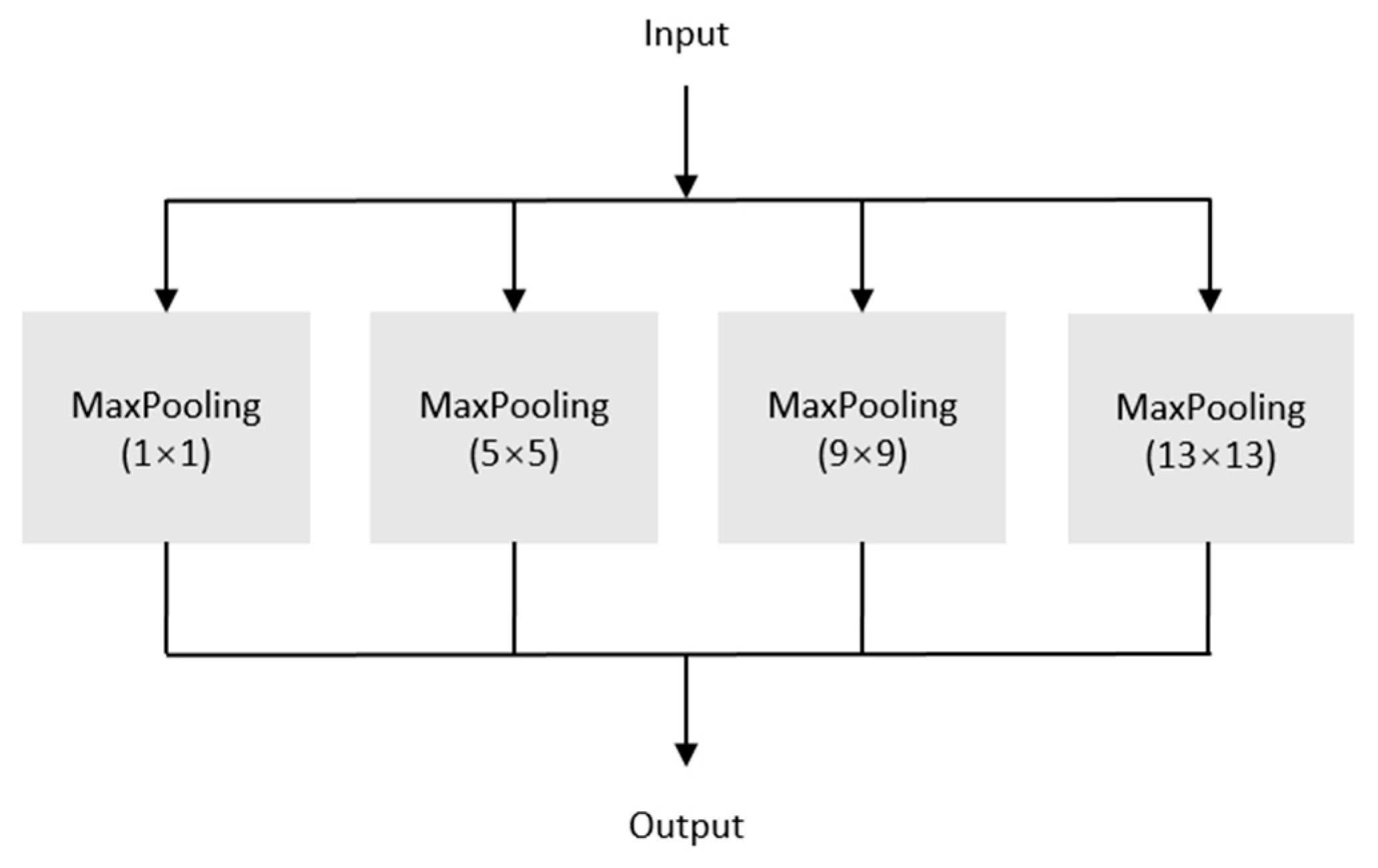{kind=link}
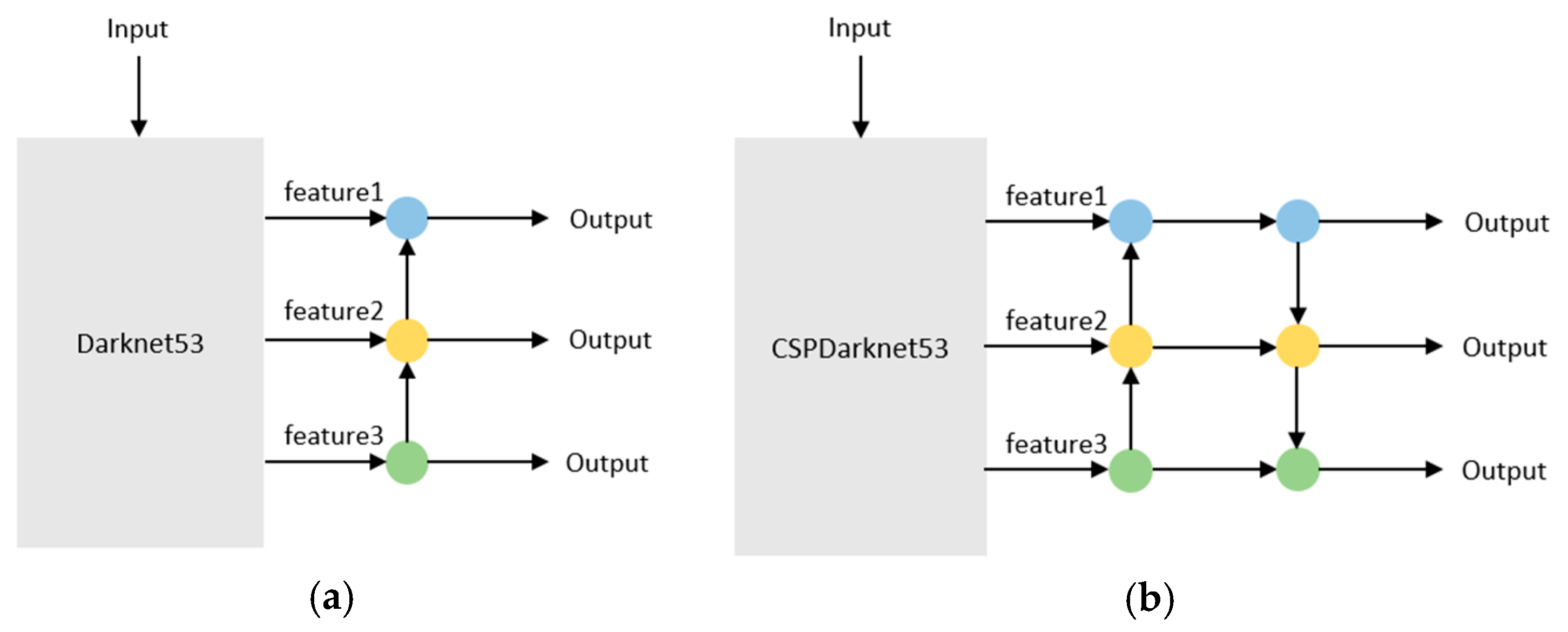{kind=link}
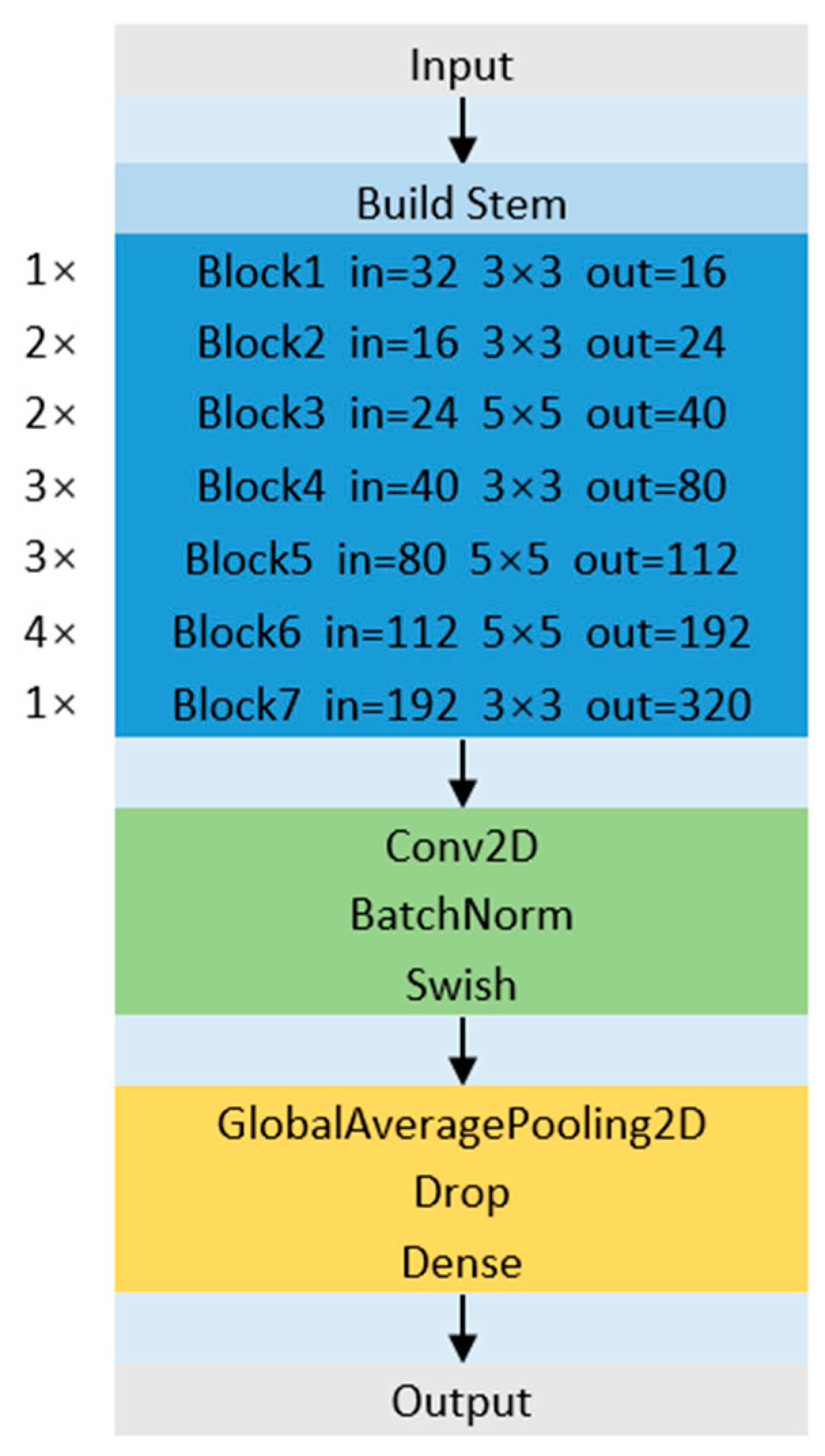{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}