
Identification and Analysis of Strawberries’ Consumer Opinions on Twitter for Marketing Purposes



Abstract
:1. Introduction
2. Literature Review
3. Material and Methods
- Data acquisition: Automatic data acquisition from social media;
- Data processing: Transformation and cleaning with text meaning;
- Data understanding: Factor identification with Word-count (term frequency analysis) technique;
- Theory development: To analyze keywords using GTM to identify association rules among them and major emerging themes;
- Data Insights: Automated content analysis through NA (community detection and modularity analysis) and visualization techniques to generate deep insights from the textual data.
3.1. Automatic Data Acquisition
3.2. Data Processing: Text Cleaning, Tokenization, and Data Loading
3.3. Data Understanding with Word-Count
3.4. Themes with Grounded Theory Method (GTM)
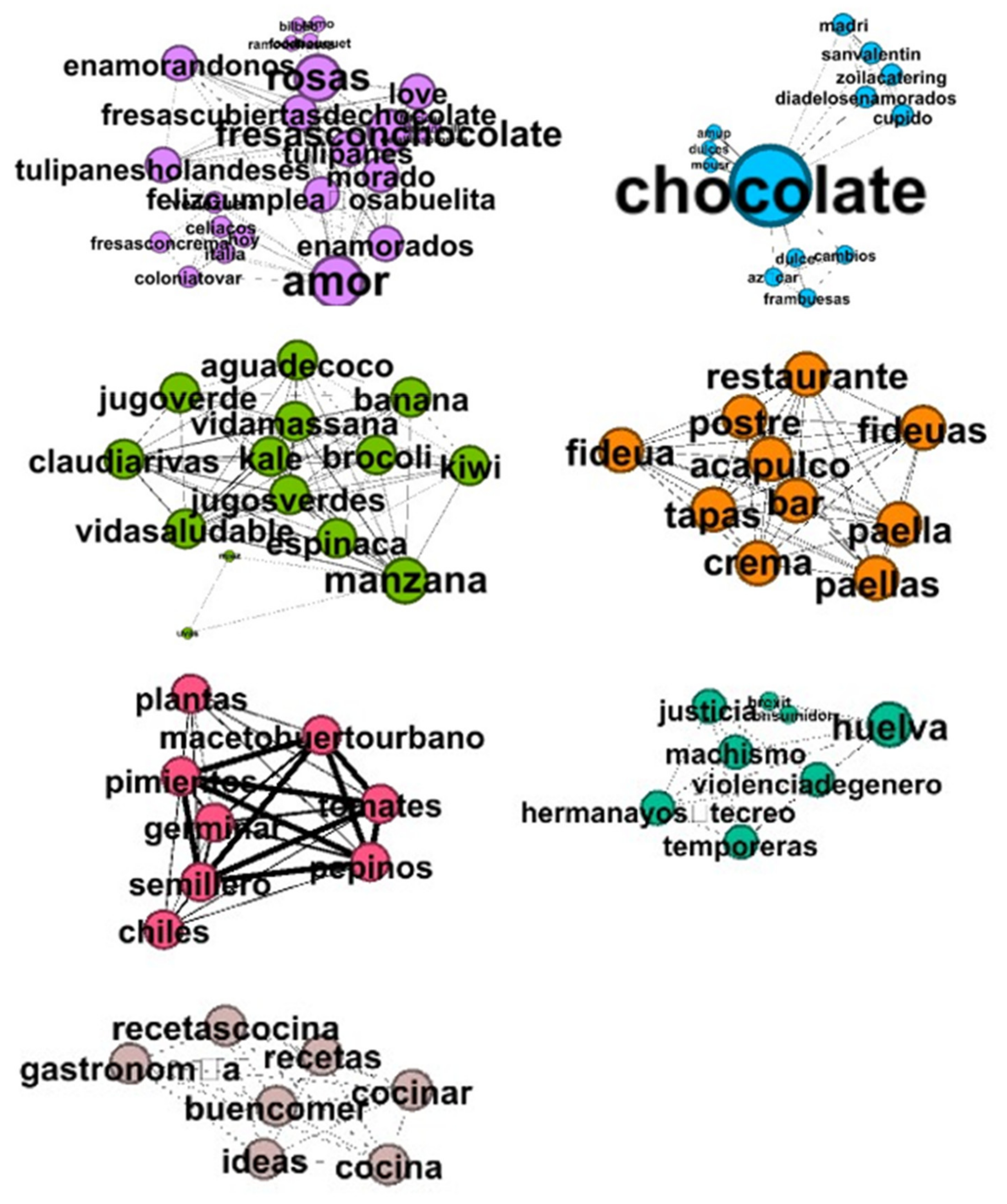
3.5. Insights with Network Analysis (NA)
4. Results
5. Discussion
6. Conclusions
- (i)
- inclusion of non-relevant hashtags; and
- (ii)
- no identification of underlying issues or relationships. Even though content analysis using GTM provided much deeper information, it took much more time. NA, in addition to being faster, proved to be more efficient and allowed the discovery of new underlying themes and relationships.
Author Contributions
Funding
Conflicts of Interest
References
- The Economist. The World’s Most Valuable Resource is No Longer Oil, but Data. Available online: https://www.economist.com/leaders/2017/05/06/the-worlds-most-valuable-resource-is-no-longer-oil-but-data (accessed on 20 February 2021).
- Appel, G.; Grewal, L.; Hadi, R.; Stephen, A.T. The future of social media in marketing. J. Acad. Mark. Sci. 2020, 48, 79–95. [Google Scholar] [CrossRef] [Green Version]
- Galati, A.; Crescimanno, M.; Tinervia, S. Social media as a strategic marketing tool in the Sicilian wine industry: Evidence from Facebook. Wine Econ. Policy 2017, 6, 40–47. [Google Scholar] [CrossRef]
- Li, F.; Larimo, J.; Leonidou, L.C. Social media marketing strategy: Definition, conceptualization, taxonomy, validation, and future agenda. J. Acad. Mark. Sci. 2021, 49, 51–70. [Google Scholar] [CrossRef]
- Stelzner, M. 2016 Social Media Marketing Industry Report: How Marketers Are Using Social Media to Grow Their Business. Available online: http://www.socialmediaexaminer.com (accessed on 20 September 2020).
- Kaplan, A.M.; Haenlein, M. Users of the world, unite! The challenges and opportunities of social media. Bus. Horiz. 2010, 53, 59–68. [Google Scholar] [CrossRef]
- Nobre, H.; Silva, D. Social network marketing strategy and SME strategy benefits. J. Transnatl. Manag. 2014, 19, 138–151. [Google Scholar] [CrossRef]
- Stebner, S.; Baker, L.M.; Peterson, H.H.; Boyer, C.R. Marketing with more: An in-depth look at relationship marketing with new media in the green industry. J. Appl. Commun. 2017, 101. [Google Scholar] [CrossRef] [Green Version]
- Atanassova, I.; Clark, L. Social media practices in SME marketing activities: A theoretical framework and research agenda. J. Cust. Behav. 2015, 14, 163–183. [Google Scholar] [CrossRef] [Green Version]
- Yao, B.; Shanoyan, A.; Peterson, H.H.; Boyer, C.; Baker, L. The use of new-media marketing in the green industry: Analysis of social media use and impact on sales. Agribusiness 2019, 35, 281–297. [Google Scholar] [CrossRef]
- Twitter. About. Available online: https://about.twitter.com/company (accessed on 20 September 2020).
- Zanini, M.; Lima, V.; Migueles, C.; Reis, I.; Carbone, D.; Lourenco, C. Soccer and twitter: Virtual brand community engagement practices. Mark. Intell. Plan. 2019, 37, 791–805. [Google Scholar] [CrossRef]
- Guèvremont, A. Improving consumers’ eating habits: What if a brand could make a difference? J. Consum. Mark. 2019, 36, 885–900. [Google Scholar] [CrossRef]
- Moreno-Sandoval, L.G.; Sánchez-Barriga, C.; Buitrago, K.E.; Pomares-Quimbaya, A.; Garcia, J.C. Spanish Twitter Data Used as a Source of Information About Consumer Food Choice. In Machine Learning and Knowledge Extraction, Lecture Notes in Computer Science, Proceedings of the CD-MAKE 2018, Hamburg, Germany, 27–30 August 2018; Holzinger, A., Kieseberg, P., Tjoa, A., Weippl, E., Eds.; Springer: Cham, Switzerland, 2018; Volume 11015, p. 11015. [Google Scholar]
- Vidal, L.; Ares, G.; Machín, L.; Jaege, S.R. Using Twitter data for food-related consumer research: A case study on “what people say when tweeting about different eating situations”. Food Qual. Prefer. 2015, 45, 58–69. [Google Scholar] [CrossRef]
- Araujo, T.; Kollat, J. Communicating effectively about CSR on Twitter. Internet Res. 2018, 28, 419–431. [Google Scholar] [CrossRef]
- Cucagna, M.E.; Goldsmith, P.D. Value adding in the agri-food value chain. Int. Food Agribus. Manag. Rev. 2018, 21, 293–316. [Google Scholar] [CrossRef]
- Ciampi, K.; Cavicchi, A. Dynamics of Smart Specialisation Agri-food Trans-Regional Cooperation, JRC Technical Reports, S3 Policy Brief Series; Publications Office of the European Union: Luxembrug, 2017. [Google Scholar] [CrossRef]
- European Commission. The European Green Deal. Available online: https://ec.europa.eu/info/sites/info/files/european-green-deal-communication_en.pdf (accessed on 30 March 2021).
- Council of European Union. Draft Council Conclusions on Digitalisation for the Benefit of the Environment. Available online: https://data.consilium.europa.eu/doc/document/ST-13957-2020-INIT/en/pdf (accessed on 30 March 2021).
- De Cicco, A. The Fruit and Vegetable Sector in the EU—A statistical Overview. Eurostat. 2020. Available online: https://ec.europa.eu/eurostat/statistics-explained/index.php/The_fruit_and_vegetable_sector_in_the_EU_-_a_statistical_overview (accessed on 30 March 2021).
- Willer, H.; Schaak, D.; Lernoud, J. Organic farming and market development in Europe and the European union. Org. Int. World Org. Agric. 2018, 217–250. [Google Scholar]
- Mezzetti, B. EUBerry: The Sustainable Improvement of European Berry Production. Quality, and Nutritional Value in a Changing Environment. Int. J. Fruit Sci. 2013, 13, 60–66. [Google Scholar] [CrossRef]
- Baby, B.; Antony, P.; Vijayan, R. Antioxidant and anticancer properties of berries. Crit. Rev. Food Sci. Nutr. 2018, 58, 1–17. [Google Scholar] [CrossRef]
- Bhat, R.; Geppert, J.; Funken, E.; Stamminger, R. Consumers Perceptions and Preference for Strawberries—A Case Study from Germany. Int. J. Fruit Sci. 2015, 15, 405–424. [Google Scholar] [CrossRef]
- Castro, D.; Teodoro, A. Anticancer properties of bioactive compounds of berry fruits—A review. Br. J. Med. Med. Res. 2015, 6, 771–794. [Google Scholar] [CrossRef]
- Skrovankova, S.; Sumczynski, D.; Mlcek, J.; Jurikova, T.; Sochor, J. Bioactive Compounds and Antioxidant Activity in Different Types of Berries. Int. J. Mol. Sci. 2015, 16, 24673. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- COMTRADE. Available online: https://comtrade.un.org/db/mr/rfCommoditiesList.aspx?px=S1&cc=0519 (accessed on 30 March 2021).
- FAO. Available online: http://www.fao.org/faostat/en/#data/QC (accessed on 30 March 2021).
- Sobekova, K.; Thomsen, M.R.; Ahrendsen, B.L. Market trends and consumer demand for fresh berries. Appl. Stud. Agribus. Commer. 2013, 7, 11–14. [Google Scholar] [CrossRef]
- Fortune Business Insights. Organic Berries Market. Markek Research Report. Summary. Available online: https://www.fortunebusinessinsights.com/organic-berries-market-103191 (accessed on 30 March 2021).
- Wang, J.; Yue, C.; Gallardo, K.; McCracken, V.; Luby, J.; McFerson, J. What Consumers Are Looking for in Strawberries: Implications from Market Segmentation Analysis. Agribusiness 2017, 33, 56–69. [Google Scholar] [CrossRef]
- Kahneman, D. Maps of bounded rationality: Psychology for behavioral economics. Am. Econ. Rev. 2003, 93, 1449–1475. [Google Scholar] [CrossRef] [Green Version]
- Decker, R.; Trusov, M. Estimating aggregate consumer preferences from online product reviews. Int. J. Res. Mark. 2010, 27, 293–307. [Google Scholar] [CrossRef]
- Köster, E.P. The psychology of food choice: Some often encountered fallacies. Food Qual. Prefer. 2003, 14, 359–373. [Google Scholar] [CrossRef]
- Podsakoff, P.M.; MacKenzie, S.B.; Lee, J.Y.; Podsakoff, N.P. Common method biases in behavioral research: A critical review of the literature and recommended remedies. J. Appl. Psychol. 2003, 88, 879–903. [Google Scholar] [CrossRef]
- Lawless, H.T.; Heymann, H. Sensory evaluation of food. In Principles and Practices, 2nd ed.; Springer: New York, NY, USA, 2010. [Google Scholar]
- Meiselman, H.L. The future in sensory/consumer research: Evolving to a better science. Food Qual. Prefer. 2013, 27, 208–214. [Google Scholar] [CrossRef]
- Chamlertwat, W.; Bhattarakosol, P.; Rungkasiri, T.; Haruechaiyasak, C. Discovering Consumer Insight from Twitter via Sentiment Analysis. J. UCS 2012, 18, 973–992. [Google Scholar]
- Carr, J.; Decreton, L.; Qin, W.; Rojas, B.; Rossochacki, T.; Wen Yang, Y. Social media in product development. Food Qual. Prefer. 2015, 40, 354–364. [Google Scholar] [CrossRef]
- Gong, S.; Juanjuan, Z.; Ping, Z.; Xuping, J. Tweeting as a Marketing Tool: A Field Experiment in the TV Industry. J. Mark. Res. 2017, 54, 833–850. [Google Scholar] [CrossRef] [Green Version]
- Ruggeri, A.; Samoggia, A. Twitter communication of agri-food chain actors on palm oil environmental, socio-economic, and health sustainability. J. Consum. Behav. 2018, 17, 75–93. [Google Scholar] [CrossRef]
- Boumans, J.W.; Trilling, D. Taking stock of the toolkit: An overview of relevant automated content analysis approaches and techniques for digital journalism scholars. Digit. J. 2016, 4, 8–23. [Google Scholar] [CrossRef] [Green Version]
- Mattila, M.; Salman, H. Analysing Social Media Marketing on Twitter using Sentiment Analysis. Bachelor’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2018. [Google Scholar]
- Mishra, N.; Singh, A. Use of twitter data for waste minimisation in beef supply chain. Ann. Oper. Res. 2018, 270, 337–359. [Google Scholar] [CrossRef] [Green Version]
- Mostafa, M.M. Clustering halal food consumers: A Twitter sentiment analysis. Int. J. Market. Res. 2019, 61, 320–337. [Google Scholar] [CrossRef]
- Singh, A.; Shuklab, N.; Mishra, N. Social media data analytics to improve supply chain management in food industries. Transp. Res. Part E Logist. Transp. Rev. 2018, 114, 398–415. [Google Scholar] [CrossRef]
- Chau, M.; Xu, J. Business Intelligence in Blogs: Understanding Consumer Interactions and Communities. MIS Q. 2012, 36, 1189–1216. [Google Scholar] [CrossRef]
- Yanai, K.; Kawano, Y. Twitter Food Photo Mining and Analysis for One Hundred Kinds of Foods. In Advances in Multimedia Information Processing—Proceedings of the PCM 2014: 15th Pacific-Rim Conference on Multimedia, Kuching, Malaysia, 1–4 December 2014; Ooi, W.T., Snoek, C., Tan, H.K., Ho, C.K., Huet, B., Ngo, C.-W., Eds.; Springer: Cham, Switzerland, 2014; pp. 22–32. [Google Scholar]
- Hannigan, T.R.; Haans, R.F.; Vakili, K.; Tchalian, H.; Glaser, V.L.; Wang, M.S.; Kaplan, S.; Jennings, P.D. Topic modeling in management research: Rendering new theory from textual data. Acad. Manag. Ann. 2019, 13, 586–632. [Google Scholar] [CrossRef] [Green Version]
- Angelopoulos, S.; Merali, Y. Sometimes a cigar is not just a cigar: Unfolding the transcendence of boundaries across the digital and physical. In Proceedings of the ICIS International Conference in Information Systems, Seoul, Korea, 10–13 December 2017. [Google Scholar]
- Barabási, A.L. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Zuo, M.Z.; Angelopoulos, S.A.; Ou, C.X.; Carol, X.C.; Liu, H.L.; Liang, Z.L. Identifying Dynamic Competition in Online Marketplaces Through Consumers. Clickstream Data. 2020. Available online: https://doi.org/10.2139/ssrn.3598889 (accessed on 22 April 2020).
- Anninou, I.; Foxall, G.R. Consumer decision-making for functional foods: Insights from a qualitative study. J. Consum. Mark. 2017, 34, 552–565. [Google Scholar] [CrossRef]
- Eskandari, F.; Lake, A.A.; Weeks, G.; Butler, M. Twitter conversations about food poverty: An analysis supplemented with Google Trends analysis. Lancet 2019, 394. [Google Scholar] [CrossRef] [Green Version]
- Nam, H.; Joshi, Y.V.; Kannan, P.K. Harvesting Brand Information from Social Tags. J. Mark. 2017. [Google Scholar] [CrossRef]
- Tsur, O.; Rappoport, A. What’s in a hashtag? Content based prediction of the spread of ideas in microblogging communities. In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, Seattle, WA, USA, 8–12 February 2012; ACM: New York, NY, USA, 2012; pp. 643–652. [Google Scholar]
- Kar, A.K.; Dwivedi, Y.K. Theory building with big data-driven research—Moving away from the “What” towards the “Why”. Int. J. Inf. Manag. 2020, 54, 1–10. [Google Scholar] [CrossRef]
- Zaki, M.; McColl-Kennedy, J.R. Text mining analysis roadmap (TMAR) for service research. J. Serv. Mark. 2020, 34, 30–47. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Gentry, J. Package ‘twitteR’. 2014. Available online: http://cran.r-project.org/web/packages/twitteR/twitteR.pdf (accessed on 21 October 2020).
- Breen, J. R by Example: Mining Twitter for Consumer Attitudes Towards Airlines. Cambridge Aviation Research. 2011. Available online: http://es.slideshare.net/jeffreybreen/r-by-example-mining-twitter-for (accessed on 20 October 2020).
- Worch, T. What should you know about analysing social media data using twitteR: The experience of a practitioner. In Proceedings of the 6th European Conference on Sensory and Consumer Research, Copenhagen, Denmark, 7–10 September 2014. [Google Scholar]
- Fried, D.; Surdeanu, M.; Kodbourov, S.; Hingle, M.; Bell, D. Analyzing the language of food on social media. In Proceedings of the 2014 IEEE International Conference on Big Data, Washington, DC, USA, 27–30 October 2014. [Google Scholar]
- Linvill, D.L.; McGee, S.E.; Hicks, L.K. Colleges’ and universities’ use of Twitter: A content analysis. Public Relat. Rev. 2012, 38, 636–638. [Google Scholar] [CrossRef] [Green Version]
- George, G.; Osinga, E.C.; Lavie, D.; Scott, B.A. Big data and data science methods for management research. Acad. Manag. J. 2016, 59, 1493–1507. [Google Scholar] [CrossRef] [Green Version]
- Tirunillai, S.; Tellis, G.J. Does chatter really matter? Dynamics of user-generated content and stock performance. Mark. Sci. 2012, 31, 198–215. [Google Scholar] [CrossRef] [Green Version]
- Liu, X. A big data approach to examining social bots on Twitter. J. Serv. Mark. 2019, 33, 369–379. [Google Scholar] [CrossRef]
- Forkmann, S.; Henneberg, S.C.; Witell, L.; Kindström, D. Driver configurations for successful service infusion. J. Serv. Res. 2017, 20, 275–291. [Google Scholar] [CrossRef]
- Charmaz, K. Constructing Grounded Theory: A Practical Guide through Qualitative Analysis; SAGE Publications Ltd.: London, UK, 2006. [Google Scholar]
- Humphreys, A.; Rebecca, J.W. Automated text analysis for consumer research. J. Consum. Res. 2017, 44, 1274–1306. [Google Scholar] [CrossRef]
- Glaser, B.G. Basics of Grounded Theory Analysis; Sociology Press: Mill Valley, CA, USA, 1992. [Google Scholar]
- Gregory, R.W. Design science research and the grounded theory method: Characteristics, differences, and complementary uses. In Proceedings of the 18th European Conference on Information Systems (ECIS 2010), Pretoria, South Africa, 7–9 June 2010. [Google Scholar]
- Schreier, M. Qualitative Content Analysis in Practice; Sage: Thousand Oaks, CA, USA, 2012. [Google Scholar]
- Guba, E.G. Criteria for assessing the trustworthiness of naturalistic inquiries. Educ. Commun. Technol. J. Theory Res. Dev. 1981, 29, 75–91. [Google Scholar]
- Shenton, A.K. Strategies for ensuring trustworthiness in qualitative research projects. Educ. Inf. 2004, 22, 63–75. [Google Scholar] [CrossRef] [Green Version]
- Strauss, A.; Corbin, J. Basics of Qualitative Research; Sage: Thousand Oaks, CA, USA, 1990. [Google Scholar]
- Borgatti, S.P. Centrality and network flow. Soc. Netw. 2005, 27, 55–71. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks: Conceptual clarification. Soc. Netw. 1979, 1, 215–239. [Google Scholar] [CrossRef] [Green Version]
- Girvan, M.; Newman, M.E.J. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clauset, A.; Newman, M.E.J.; Moore, C. Finding community structure in very large networks. Phys. Rev. E 2004, 70, 66111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clauset, A. Finding local community structure in networks. Phys. Rev. E 2005, 72, 26132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 10, P10008. [Google Scholar] [CrossRef] [Green Version]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An Open Source Software for Exploring and Manipulating Networks. Association for the Advancement of Artificial Intelligence (www.aaai.org). 2009. Available online: https://gephi.org/publications/gephi-bastian-feb09.pdf (accessed on 23 February 2021).
- Jaeger, S.R.; Bava, C.M.; Worch, T.; Dawson, J.; Marshall, D.W. The food choice kaleidoscope. A framework for structured description of product, place and person as sources of variation in food choices. Appetite 2011, 56, 412–423. [Google Scholar] [CrossRef]
- Kyutoku, Y.; Minami, Y.; Koizumi, K.; Okamoto, M.; Kusakabe, Y.; Dan, I. Conceptualization of food choice motives and consumption among Japanese in light of meal, gender, and age effects. Food Qual. Prefer. 2012, 24, 213–217. [Google Scholar] [CrossRef]
- Köster, E.P. Diversity in the determinants of food choice: A psychological perspective. Food Qual. Prefer. 2009, 20, 70–82. [Google Scholar] [CrossRef]
- Köster, E.P.; Mojet, J. Theories of food choice development. In Understanding Consumers of Food Products; Frewer, L., van Trijp, H.C.M., Eds.; Woodhead Publishing: Cambridge, UK, 2006; pp. 93–124. [Google Scholar]
- Meiselman, H.L. Experiencing food products within a physical and social context. In Product Experience; Schifferstein, H.N.J., Hekkert, P., Eds.; Elsevier: Oxford, UK, 2008; pp. 559–580. [Google Scholar]
- Desmet, P.M.A.; Schifferstein, H.N.J. Sources of positive and negative emotions in food experience. Appetite 2008, 50, 290–301. [Google Scholar] [CrossRef]
- Piqueras-Fiszman, B.; Jaeger, S.R. What makes meals ‘memorable’? A consumer-centric exploration. Food Res. Int. 2014. [Google Scholar] [CrossRef]
- Piqueras-Fiszman, B.; Jaeger, S.R. Emotions associated to mealtimes: Memorable meals and typical evening meals. Food Res. Int. 2014. [Google Scholar] [CrossRef]
- Rappoport, L.; Downey, R.G.; Huff-Corzine, L. Conceptual differences between meals. Food Qual. Prefer. 2001, 13, 489–495. [Google Scholar] [CrossRef]
- Bisogni, C.A.; Winter Falk, L.; Madore, E.; Blake, C.E.; Jastran, M.; Sobal, J.; Devine, C.M. Dimensions of everyday eating and drinking episodes. Appetite 2007, 218–231. [Google Scholar] [CrossRef]
- Liu, M.; Kasteridis, P.; Yen, S.T. Breakfast, lunch, and dinner expenditures away from home in the United States. Food Policy 2013, 38, 156–164. [Google Scholar] [CrossRef]
- ComScore. The Global Mobile Report. comScore Inc. 2017. Available online: https://www.comscore.com/Insights/Presentations-and-Whitepapers/2017/The-Global-Mobile-Report (accessed on 30 June 2020).
- Yates, L.; Warde, A. The evolving content of meals in Great Britain. Results of a survey in 2012 in comparison with the 1950s. Appetite 2014, 84, 299–308. [Google Scholar] [CrossRef]
- Vehkalahti, K.; Tahvonen, R.; Tuorila, H. Hedonic responses and individual definitions of an ideal apple as predictors of choice. J. Sens. Stud. 2013, 28, 346–357. [Google Scholar]
- Canetti, L.; Bachar, E.; Berry, E.M. Food and emotion. Behav. Process. 2002, 60, 157–164. [Google Scholar] [CrossRef]
- Macht, M. How emotions affect eating: A five-way model. Appetite 2008, 50, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Aprile, M.C.; Caputo, V.; Nayga, R.M., Jr. Consumers’ valuation of food quality labels: The case of the European geographic indication and organic farming labels. Int. J. Consum. Stud. 2012, 36, 158–165. [Google Scholar] [CrossRef]
- Eldesouky, A.; Mesias, F.J.; Escribano, M. Perception of Spanish consumers towards environmentally friendly labelling in food. Int. J. Consum. Stud. 2020, 44, 64–76. [Google Scholar] [CrossRef]
- Samoggia, A.; Bertazzoli, A.; Ruggeri, A. Food retailing marketing management: Social media communication for healthy food. Int. J. Retail Distrib. Manag. 2019, 47, 928–956. [Google Scholar] [CrossRef]
- McEachern, M.G.; Warnaby, G. Exploring the relationship between consumer knowledge and purchase behaviour of value-based labels. Int. J. Consum. Stud. 2008, 32, 414–426. [Google Scholar] [CrossRef]
- Mellon, J.; Prosser, C. Twitter and Facebook are not Representative of the General Population: Political Attitudes and Demographics of British Social Media users. Res. Politics 2017. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, Q.; Rod, M.; Shaobo, J. A thematic exploration of social media analytics in marketing research and an agenda for future inquirí. J. Strateg. Mark. 2020. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| #Strawberries | % | #Fresas | % | |
|---|---|---|---|---|
| Number of tweets with a single token | 259 | 11.88% | 274 | 17.19% |
| Number of tweets with two tokens | 539 | 24.69% | 324 | 20.31% |
| Number of tweets with three tokens | 205 | 9.38% | 324 | 20.31% |
| Number of tweets with four tokens | 198 | 9.06% | 224 | 14.06% |
| Number of tweets with five tokens | 225 | 10.31% | 150 | 9.38% |
| Number of tweets with six tokens | 239 | 10.94% | 150 | 9.38% |
| Number of tweets with seven tokens | 123 | 5.63% | 25 | 1.56% |
| Number of tweets with eight tokens | 198 | 9.06% | 25 | 1.56% |
| Number of tweets with nine tokens | 96 | 4.38% | 50 | 3.13% |
| Number of tweets with ten or more tokens | 102 | 4.69% | 50 | 3.13% |
| Total of tweets | 2184 | 1596 | ||
| Number of tokens | 7690 | 3460 | ||
| Mean | 3.52 | 2.17 | ||
| Standard deviation | 3.09 | 2.54 |
| Themes | Focused Codes | Initial Codes for #Strawberries |
|---|---|---|
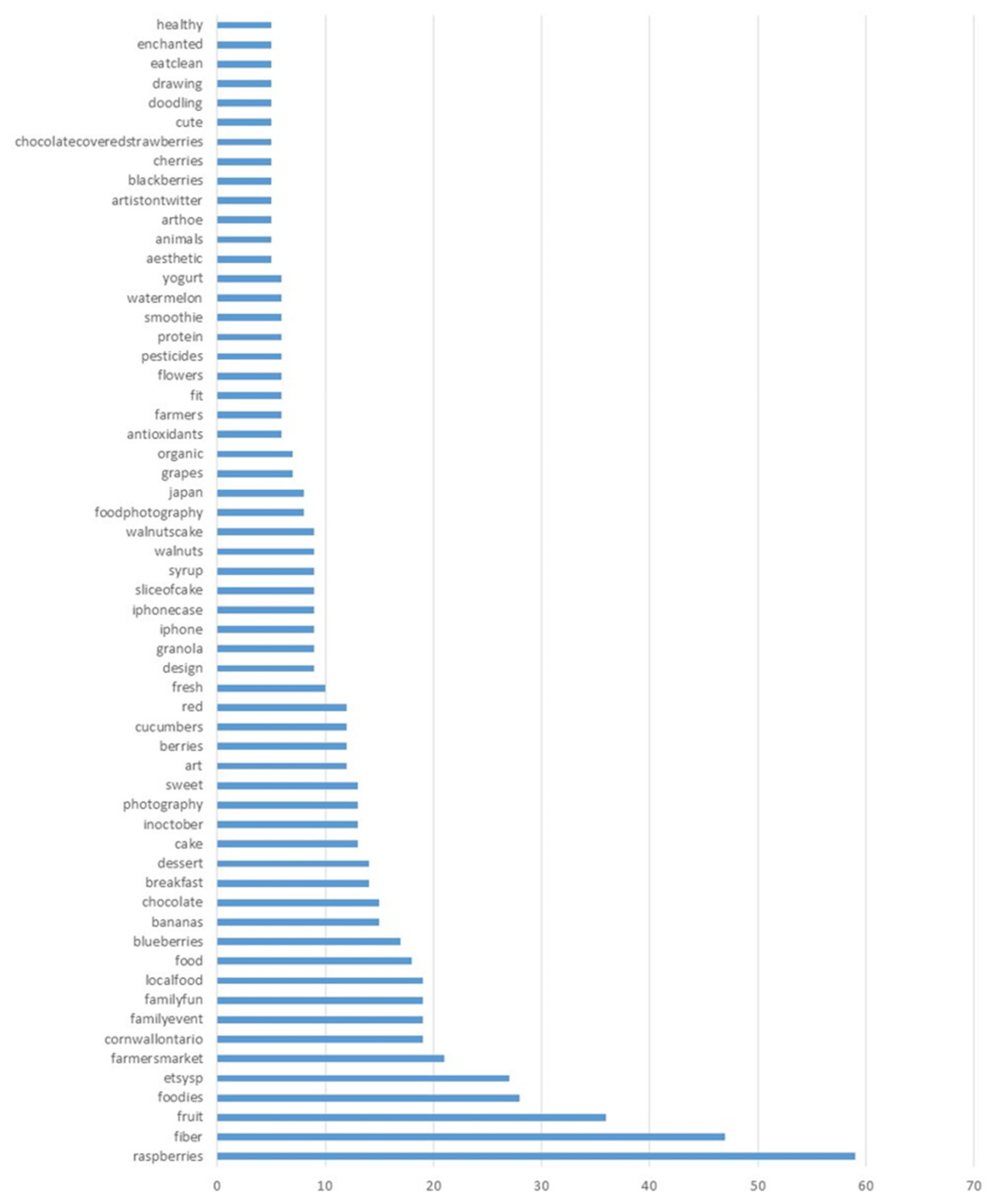
| 1. Fruits | 1 | raspberries, fruits, blueberries, banana, berries, grapes, watermelon, blackberries |
| 2. Context | 2 | breakfast, dessert, food |
| 3 | familyevent, familyfun | |
| 6 | farmersmarket | |
| 8 | flowers | |
| 3. Consumption | 4 | chocolate, cake, syrup, sliceofcake, granola, walnutcake, chocolatecoveredstrawberries |
| sweet | ||
| 4. Healthy lifestyle | 5 | smoothie, yogurt |
| fiber, organic, antioxidants, eatclean, healthy, fresh | ||
| fit | ||
| 5. Production | 9 | localfood |
| 11 | farmers, pesticides | |
| 12 | incotober | |
| 6. Art | 10 | photography, design, foodphotography, red, cute |
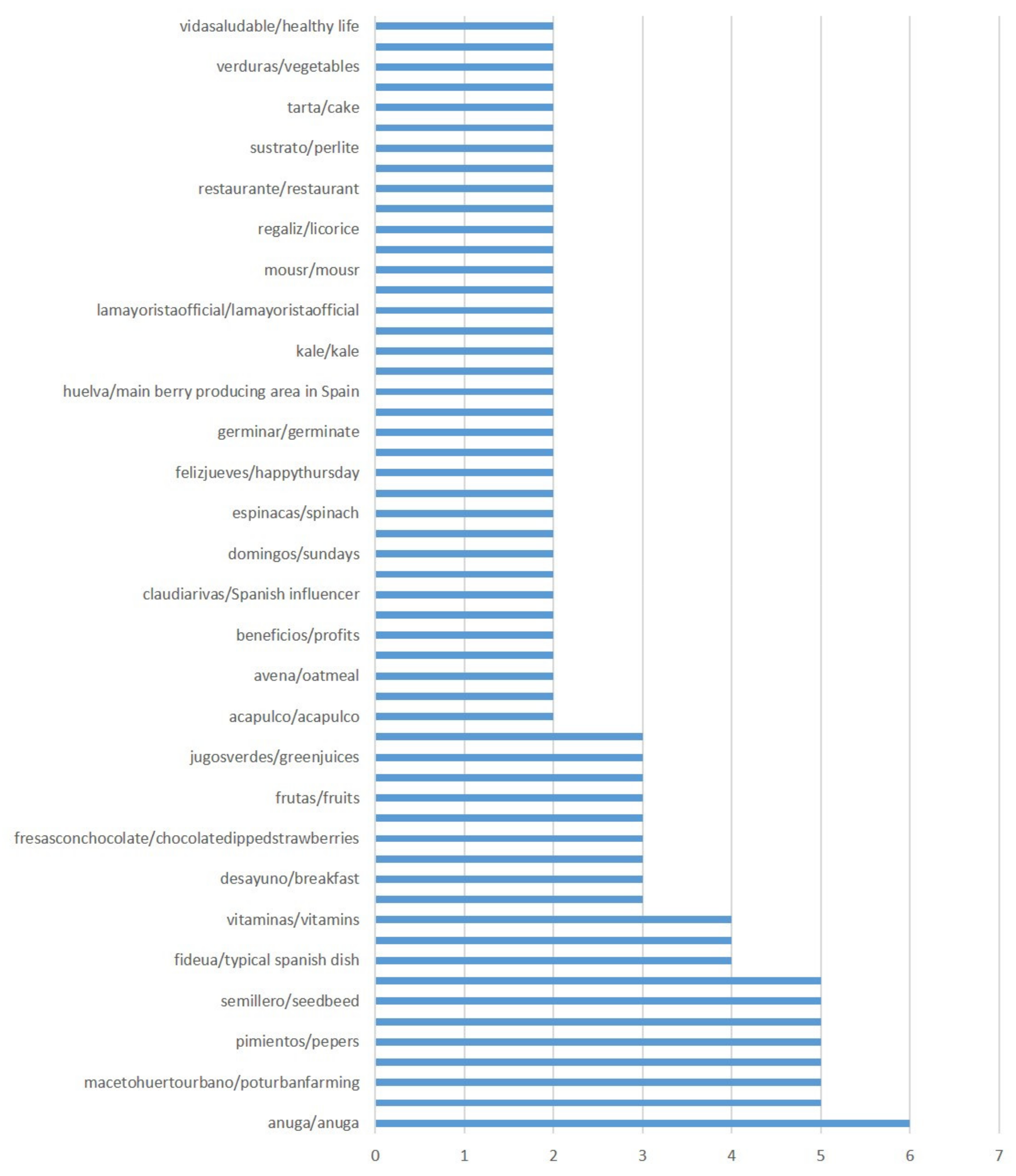
| Themes | Focused Codes | Initial Codes for #fresas (strawberries) |
| 1. Fruits | 1 | frutas (fruits), frutosrojos (berries), manzana (apple), arándanos (blueberries) |
| 2. Context | 2 | desayuno (breakfast), postres (dessert) |
| 3 | domingos (Sundays), felizdomingo (happysunday), felizjueves (happythursday, lafamilia (thefamily), mejoresamigos (bestfriends) | |
| 6 | fideua (typical spanish dish), paella (typical spanish dish), bar(bar), restaurante (restaurant) | |
| 8 | amor (love), rosas(roses) | |
| acapulco (beautiful beach in Mexico) | ||
| 13 | Anuga (the leading food fair in the world) | |
| 3. Consumption | 4 | Chocolate (chocolate), fresasconchocolate (chocolatedippedstrawberries), fresascubiertasdechocolate (chocolatecoveredstrawberries), avena (oatmeal), perversodechocolate (perversechocolate) |
| Dulces (sweets), tarta (cake), tusdulces (yoursweets) | ||
| 4. Healthy lifestyle | 5 | Jugosverdes (greenjuices) |
| Vitaminas (vitamins) | ||
| Vidamassana (healthierlife), vidasaludable (healthylife) | ||
| 5. Production | 7 | Macetahuertourbano (urban farm), semillero (seedbed), pepinos (cucumbers), pimientos (peppers), tomates (tomatoes), germinar (germinate), sustrato (substrate), verduras (vegetables) |
| 9 | Huelva (localcity) | |
| 6. Art |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Borrero, J.D.; Zabalo, A. Identification and Analysis of Strawberries’ Consumer Opinions on Twitter for Marketing Purposes. Agronomy 2021, 11, 809. https://doi.org/10.3390/agronomy11040809
Borrero JD, Zabalo A. Identification and Analysis of Strawberries’ Consumer Opinions on Twitter for Marketing Purposes. Agronomy. 2021; 11(4):809. https://doi.org/10.3390/agronomy11040809
Chicago/Turabian StyleBorrero, Juan D., and Alberto Zabalo. 2021. "Identification and Analysis of Strawberries’ Consumer Opinions on Twitter for Marketing Purposes" Agronomy 11, no. 4: 809. https://doi.org/10.3390/agronomy11040809
APA StyleBorrero, J. D., & Zabalo, A. (2021). Identification and Analysis of Strawberries’ Consumer Opinions on Twitter for Marketing Purposes. Agronomy, 11(4), 809. https://doi.org/10.3390/agronomy11040809