
A Sampling Strategy to Develop a Primary Core Collection of Miscanthus spp. in China Based on Phenotypic Traits


Abstract
:1. Introduction
2. Materials and Methods
2.1. Plant Materials
2.2. Evaluation of Phenotypic Traits
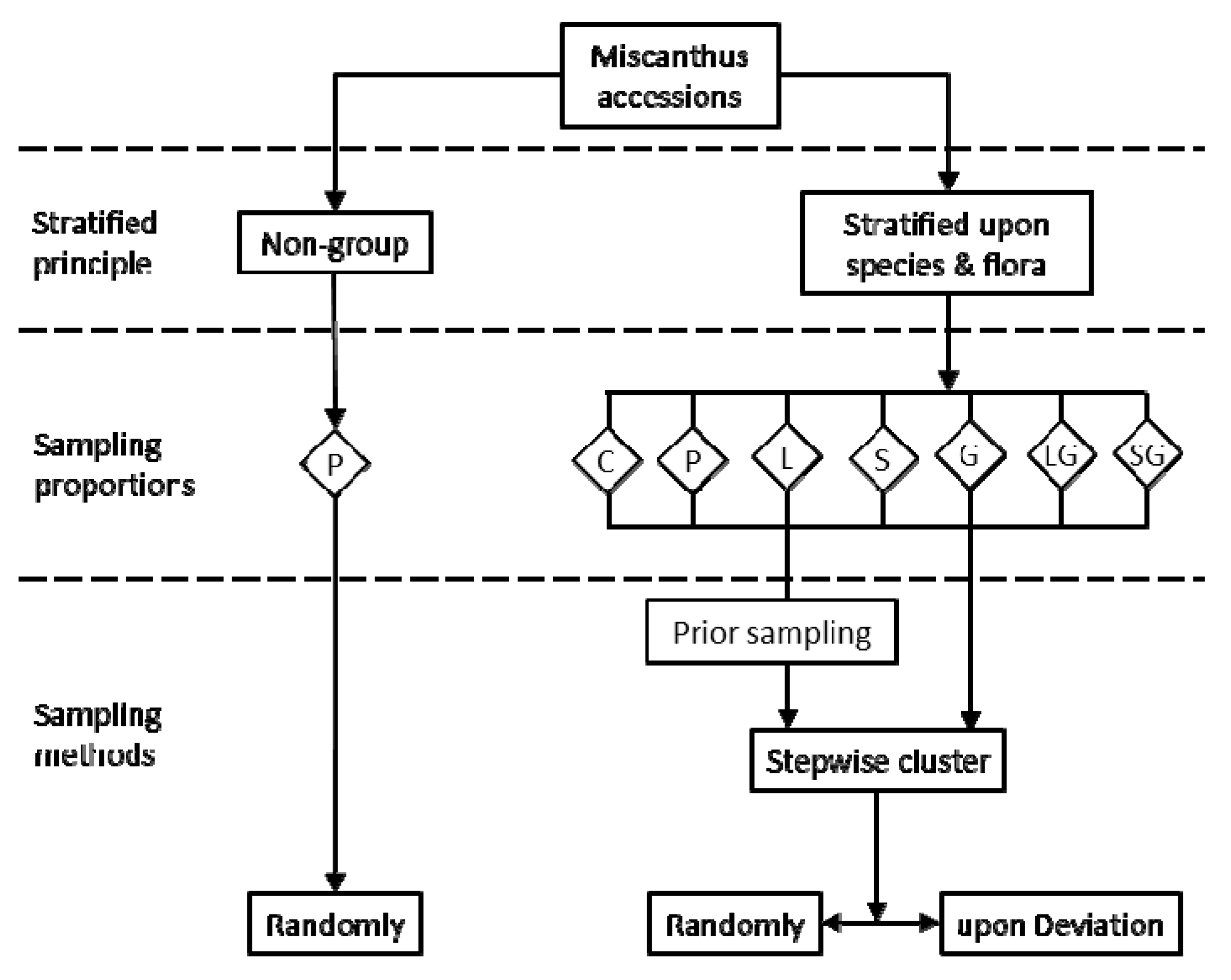
2.3. Sampling Strategy
- (1)
- A non-group random sampling method (NGR): In this method, the primary core collection was randomly selected from every subgroup with two germplasms at the lowest standard of categorizing. When one germplasm was in the subgroup, it was immediately selected for the cluster analysis. The procedures for the clustered and selected germplasms were repeated until the group scale was reduced to a given number.
- (2)
- Deviation sampling (D): In this method, the degree of deviation degree of two germplasms were contrasted in each subgroup at the lowest standard of categorizing. The germplasm with the higher degree of deviation was selected for the following cluster analysis. When one germplasm was present in the subgroup, it was immediately selected for cluster analysis. The subsequent germplasms were processed similarly to the preceding step. The other procedures were similar to the stepwise clustering method.
- (3)
- Prior sampling (PR): Germplasms with the traits expressing the maximum or minimum values were chosen as core collections before clustering. The residual germplasms were processed using a method similar to the random clustering method.
- (4)
- Prior and Deviation sampling (PD): This strategy was based on the prior sampling method. Germplasms were processed in a similar way to the deviation sampling method after the germplasms with the traits expressing the maximum or minimum values were selected as the core collections.
2.4. Evaluating the Parameters for the Core Collection
3. Results
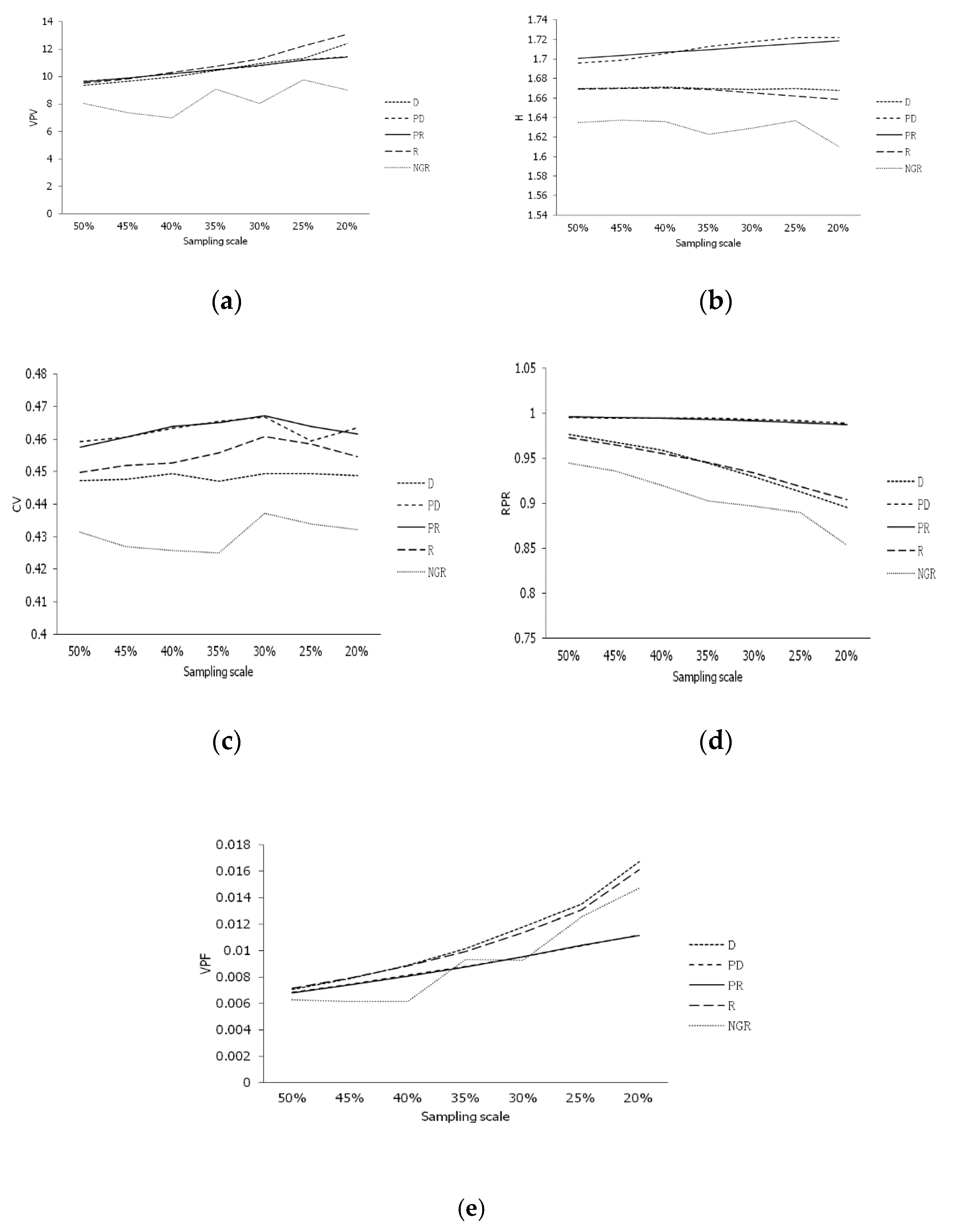
3.1. The Tendency of Parameters for Sampling Methods in Different Sampling Scales
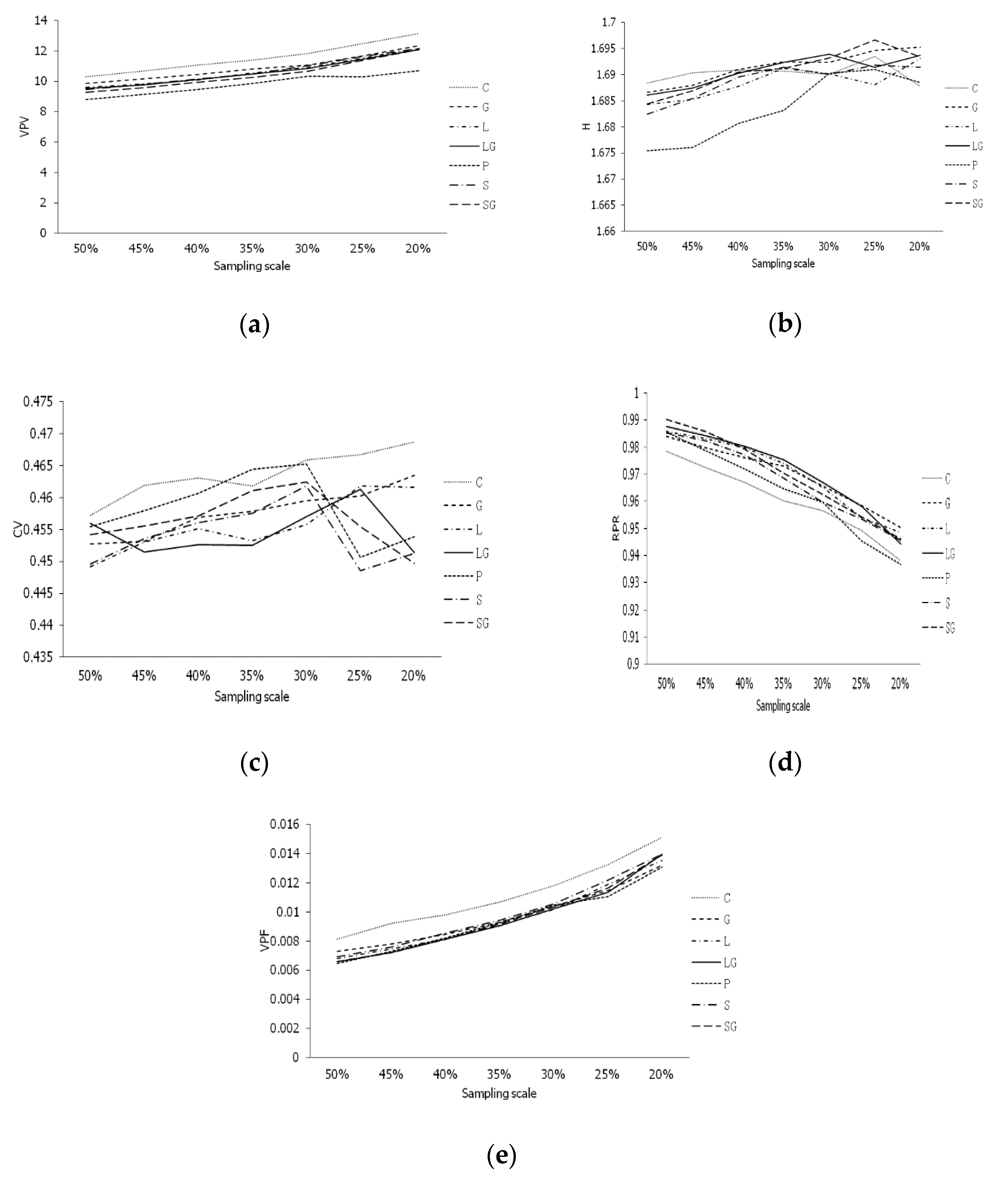
3.2. The Tendency of the Parameters for Sampling Strategies in Different Sampling Scales

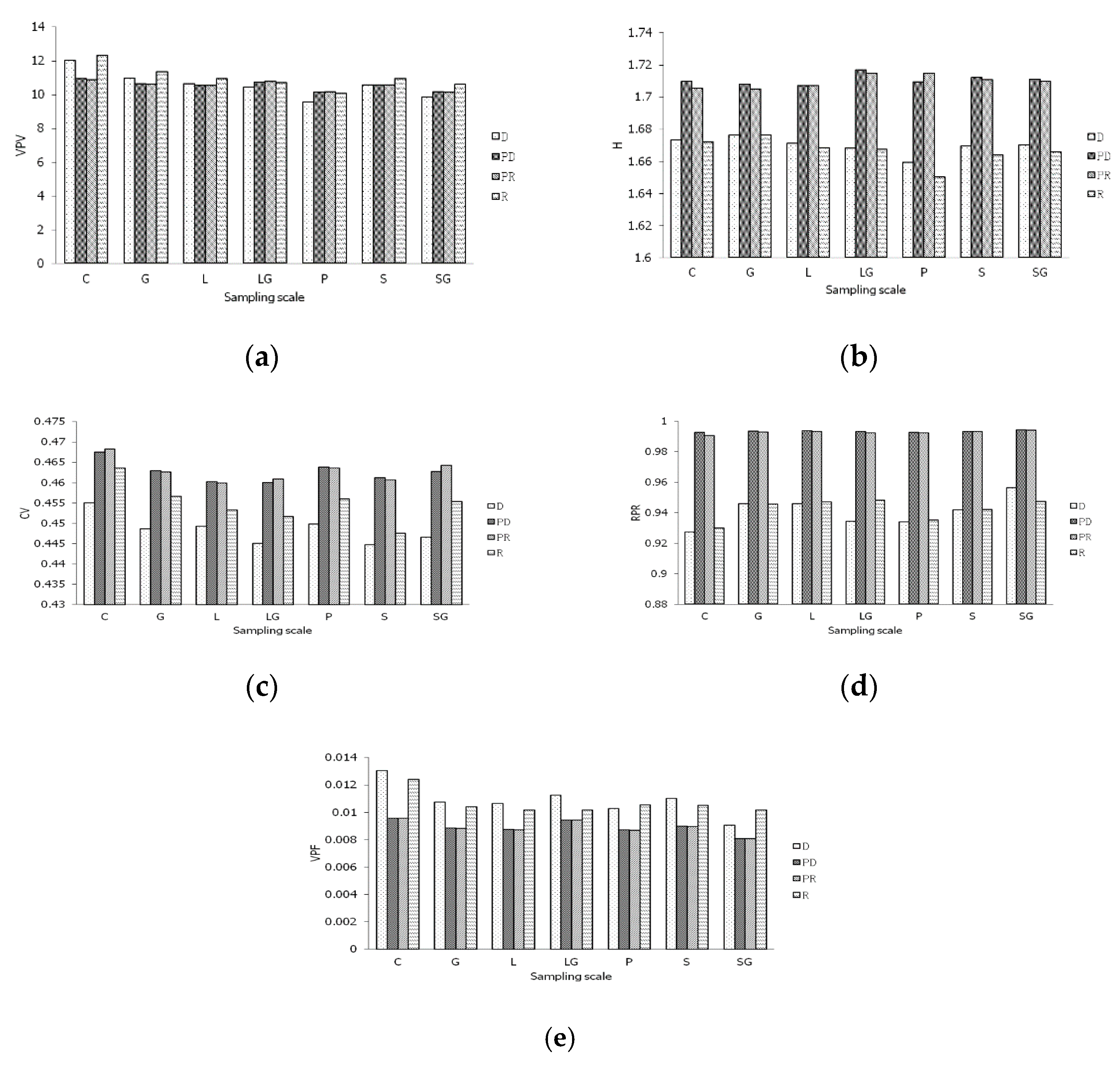
3.3. The Relationship of the Parameters between Different Sampling Strategies and Methods
3.4. Comparison of the Sampling Strategies and Methods
3.5. Comparison of the Sampling Scale of the Core Collection
3.6. Assessment of the Core Collections with 21 Quantitative Traits
3.7. Determination of the Sampling Scheme of the Core Collection
4. Discussion
4.1. Phenotype Data Construction of a Primary Core Collection
4.2. The Method to Establish the Primary Core Collection
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Londoño-Pulgarin, D.; Cardona-Montoya, G.; Restrepo, J.C.; Muñoz-Leiva, F. Fossil or bioenergy? Global fuel market trends. Renew. Sustain. Energ. Rev. 2021, 143, 110905. [Google Scholar] [CrossRef]
- Demirbas, A. Political, economic and environmental impacts of biofuels: A review. Appl. Energy 2019, 86, 108–117. [Google Scholar] [CrossRef]
- Agostini, A.; Serra, P.; Giuntoli, J.; Martani, E.; Ferrarini, A.; Amaducci, S. Biofuels from perennial energy crops on buffer strips: A win-win strategy. J. Clean. Prod. 2021, 297, 126703. [Google Scholar] [CrossRef]
- Dubis, B.; Jankowski, K.J.; Załuski, D.; Bórawski, P.; Szempliński, W. Biomass production and energy balance of Miscanthus over a period of 11 years: A case study in a large-scale farm in Poland. GCB Bioenergy 2019, 11, 1187–1201. [Google Scholar] [CrossRef] [Green Version]
- Shumny, V.K.; Veprev, S.G.; Nechiporenko, N.N.; Goryachkovskaya, T.N.; Slynko, N.M.; Kolchanov, N.A.; Peltek, S.E. A new form of Miscanthus (Chinese silver grass, Miscanthus sinensis—Andersson) as a promising source of cellulosic biomass. Adv. Biosci. Biotechnol. 2015, 1, 167–170. [Google Scholar] [CrossRef] [Green Version]
- Clifton-Brown, J.C.; Lewandowski, I.; Andersson, B.; Basch, G.; Teixeira, F. Performance of 15 miscanthus genotypes at five sites in Europe. Agron. J. 2008, 93, 1013–1019. [Google Scholar] [CrossRef] [Green Version]
- Qian, S.; Lin, Q.I.; Zi-Li, Y.I.; Yang, Z.R.; Zhou, F.S. A taxonomic revision of miscanthus s.l. (Poaceae) from China. Bot. J. Linn. Soc. 2010, 164, 178–220. [Google Scholar]
- Chen, S.L.; Renvoize, S.A. Miscanthus Andersson. In Flora of China; Beijing Science Press: Beijing, China, 2006. [Google Scholar]
- Hastings, A.; Clifton-Brown, J.; Wattenbach, M.; Stampfl, P.; Mitchell, C.P.; Smith, P. Potential of Miscanthus grasses to provide energy and hence reduce greenhouse gas emissions. Agron. Sustain. Dev. 2008, 28, 465–472. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Zhu, M.; Zhu, T.P. Exploitation and utilization of Miscanthus & Triarrhena. J. Nat. Resour. 2001, 16, 562–563. (In Chinese) [Google Scholar]
- Yi, Z.L. Exploitation and utilization of Miscanthus as energy plant. J. Hunan Agric. Univ. 2012, 38, 455–463. (In Chinese) [Google Scholar] [CrossRef]
- Hao, C.Y.; Zhang, X.Y.; Wang, L.F.; Dong, Y.S.; Shang, X.W.; Jia, J.Z. Genetic diversity and core collection evaluations in common wheat germplasm from the nothwestern spring wheat region in China. Mol. Breeding. 2006, 17, 69–77. [Google Scholar] [CrossRef]
- Hao, C.Y.; Dong, Y.C.; Wang, L.F.; You, G.X.; Zhang, H.N.; Ge, H.M.; Jia, J.Z.; Zhang, X.Y. Genetic diversity and construction of core collection in Chinese wheat genetic resources. Chin. Sci. Bull. 2008, 53, 1518–1526. (In Chinese) [Google Scholar]
- Zhang, H.L.; Zhang, D.L.; Wang, M.X.; Sun, J.L.; Qi, Y.W.; Li, J.J.; Wei, X.H.; Han, L.Z.; Qiu, Z.E.; Tang, S.X.; et al. A core collection and mini core collection of Oryza sativa L. in China. Theor. Appl. Genet. 2011, 122, 49–61. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.M.; Dong, Y.S.; Liu, B.; Hao, S.; Wang, K.J.; Li, X.H. Establishment of a core collection for the Chinese annual wild soybean (Glycine Soja). Chin. Sci. Bull. 2015, 50, 989–996. (In Chinese) [Google Scholar] [CrossRef]
- Li, Z.C.; Zhang, H.L.; Zeng, Y.W.; Yang, Z.Y.; Shen, S.Q.; Sun, C.Q.; Wang, X.K. Studies on sampling schemes for the establishment of core collection of rice landraces in Yunnan, China. Genet. Resour. Crop. Evol. 2002, 49, 67–74. [Google Scholar] [CrossRef]
- Zhang, Y.X.; Zhang, X.R.; Hua, W.; Wang, L.H.; Che, Z. Analysis of genetic diversity among indigenous landraces from sesame (Sesamum indicum L.) core collection in China as revealed by SRAP and SSR markers. Genes. Genom. 2010, 32, 207–215. [Google Scholar] [CrossRef]
- Hintum, T.L.; Morales, E.A.V. (Eds.) Core Collections of Plant Genetic Resources; John Wiley and Sons: Chichester, UK, 1995; pp. 127–146. [Google Scholar]
- Malosetti, M.; Avadie, T. Sampling strategy to develop a core collection of Uruguayan maize landraces based on morphological traits. Genet. Resour. Crop. Evol. 2001, 48, 381–390. [Google Scholar] [CrossRef]
- Wu, Z.Y. Floristics of Seed Plants from China; Science Publisher: Beijing, China, 2010; pp. 52–56. [Google Scholar]
- Hu, J.; Zhu, J.; Xu, H.M. Methods of constructing core collections by stepwise clustering with three sampling strategies based on the genotypic values of crops. Theor. Appl. Genet. 2000, 101, 264–268. [Google Scholar] [CrossRef]
- Li, C.T.; Shi, C.H.; Wu, J.G.; Xu, H.M.; Zhang, H.Z.; Ren, Y.L. Methods of developing core collections based on the predicted genotypic value of rice (Oryza sativa L.). Theor. Appl. Genet. 2004, 108, 1172–1176. [Google Scholar] [CrossRef]
- Balfourier, F.; Roussel, V.; Strelchenko, P.; Exbrayat-Vinson, F.; Sourdille, P.; Boutet, G.; Koenig, J.; Ravel, C.; Mitrofanova, O.; Beckert, M.; et al. A worldwide bread wheat core collection arrayed in a 384-well plate. Theor. Appl. Genet. 2007, 114, 1265–1275. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, M.F.; Nelson, R.L.; Geraldi, I.O.; Cruz, C.D.; Toledo, J.F.F.D. Establishing a soybean germplasm core collection. Field Crops Res. 2010, 119, 277–289. [Google Scholar] [CrossRef]
- Chandra, S.; Huaman, Z.; Krishna, S.H.; Ortiz, R. Optimal sampling strategy and core collection size of Andean tetraploid potato based on isozyme data—A simulation study. Theor. Appl. Genet. 2002, 104, 1325–1334. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.X.; Li, T.H.; Zhang, H.L.; Qi, Y.W. Sampling Strategy for a Primary Core Collection of Peach (Prunus persica (L.) Batsch.) Germplasm. Eur. J. Hortic. Sci. 2007, 72, 268–274. [Google Scholar]
- Zhang, J.; Wang, Y.; Zhang, X.Z.; Li, T.Z.; Wang, K.; Xu, X.F.; Han, Z.H. Sampling strategy to develop a primary core collection of apple cultivars based on fruit traits. Afr. J. Biotechnol. 2010, 9, 123–127. [Google Scholar]
- Wang, Y.Z.; Zhang, J.H.; Sun, H.Y.; Ning, N.; Yang, L. Construction and evaluation of a primary core collection of apricot germplasm in China. Sci. Hortic. 2011, 128, 311–319. (In Chinese) [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Q.; Yang, Y.; Luo, Z. Revision of a Primary Core Collection of Persimmon (Diospyros kaki Thunb.) Originated in China. Acta Hortic. 2013, 996, 213–217. (In Chinese) [Google Scholar] [CrossRef]
- Martínez, I.B.; Cruz, M.V.; Nelson, M.R.; Bertin, P. Establishment of a Core Collection of Traditional Cuban Theobroma cacao Plants for Conservation and Utilization Purposes. Plant Mol. Biol. Report. 2016, 35, 47–60. [Google Scholar] [CrossRef]
- Liu, X.L.; Cai, Q.; Ma, L.; Wu, C.W.; Lu, X.; Ying, X.M.; Fan, Y.H. Strategy of sampling for pre-core collection of sugarcane hybrid. Acta Agron. Sin. 2009, 35, 1209–1216. (In Chinese) [Google Scholar] [CrossRef]
- Lerceteau, E.; Robert, T.; Petiard, V.; Crouzillat, D. Evaluation of the extent of genetic variability among Theobroma cacao accessions using RAPD and RFLP markers. Theor. Appl. Genet. 1997, 95, 10–19. [Google Scholar] [CrossRef]
- Xiao, L.; Yi, Z.L.; Jiang, J.X.; Liu, S.L.; Qin, J.P.; Yi, J.Q.; Yang, S. Establishment of China’s Miscanthus sinensis Primary Core Collection. J. Plant Genet. Resour. 2014, 15, 1196–1201. (In Chinese) [Google Scholar]
- Xiang, W.; Xue, S.; Liu, F.; Qin, S.; Xiao, L.; Yi, Z. MGDB: A database for evaluating Miscanthus spp. to screen elite germplasm. Biomass Bioenergy 2020, 138, 105599. [Google Scholar] [CrossRef]
- Kumar, S.; Ambreen, H.; Variath, M.T.; Rao, A.R.; Agarwal, M.; Kumar, A.; Goel, S.; Jagannath, A. Utilization of Molecular, Phenotypic, and Geographical Diversity to Develop Compact Composite Core Collection in the Oilseed Crop, Safflower (Carthamus tinctorius L.) through Maximization Strategy. Front. Plant Sci. 2016, 7, 1554. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, Y.; Dong, S.; Liu, Q.; Chen, J.; Pan, J.; Zhang, J. Selection of a core collection of Prunus sibirica L. germplasm by a stepwise clustering method using simple sequence repeat markers. PLoS ONE 2021, 16, e0260097. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Wang, L.; Wang, H.; Mao, C.; Kong, D.; Chen, S.; Zhang, H.; Shen, Y. Development of a Core Collection of Six-Rowed Hulless Barley from the Qinghai-Tibetan Plateau. Plant Mol. Biol. Rep. 2020, 38, 305–313. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traits | Abbreviation | Description and Classes | |
|---|---|---|---|
| 1 | Date of bud emergence | DBE | Emergence date of second leaf |
| 2 | Date of beginning flowers | DBF | Flowering date of first flower |
| 3 | Days to beginning flowering | DsBF | Days from bud emergence to any plant produces flower |
| 4 | Plant height | PH | Height of largest over-ground complete plant |
| 5 | Stem length | SL | Length of over-ground complete stem |
| 6 | First internode length | FIL | First complete internode length of above-ground stem |
| 7 | stem axis long diameter of FIL | SALD | stem axis long diameter of FIL’s middle |
| 8 | Node number of per stem | NS | Node number of per over-ground complete stem |
| 9 | Largest leaf length | LL | Length of visual largest leaf |
| 10 | Largest leaf width | LW | Width of visual largest leaves |
| 11 | Fresh weight of per stem | FWS | Fresh weight of stem after reproductive stage |
| 12 | Dry weight of per stem | DWS | Weighted after fresh stem was dried three days at 45 ℃ |
| 13 | Node hairiness | NH | Does node have hairiness? (No = “0”, Yes = “1”) |
| 14 | Leaf back hairiness | LBH | Does leaf back have hairiness? (No = “0”, Yes = “1”) |
| 15 | Sheath hairiness | ShH | Does sheath have hairiness? (No = “0”, Yes = “1”) |
| 16 | Sheath mouth hairiness | ShMH | Does sheath mouth have hairiness? (No = “0”, Yes = “1”) |
| 17 | Internode waxiness | IWa | Does internode have waxiness? (No = “0”, Yes = “1”) |
| 18 | Node waxiness | NWa | Does node have waxiness? (No = “0”, Yes = “1”) |
| 19 | Leaf waxiness | LWa | Does leaf have waxiness? (No = “0”, Yes = “1”) |
| 20 | Sheath waxiness | ShWa | Does sheath have waxiness? (No = “0”, Yes = “1”) |
| 21 | Stem color | StC | 0 = Yellow, 1 = Light green, 3 = Green, 5 = Dark green, 7 = lilac or pale-purple speckles interspersed; 9 = purple-red speckles interspersed |
| 22 | Leaf color | LC | 1 = Light green, 3 = Green, 5 = Dark green |
| 23 | Sheath color | ShC | 0 = Yellow, 1 = Light green, 3 = Green, 5 = Dark green, 7 = lilac or pale-purple speckles interspersed; 9 = purple-red speckles interspersed |
| 24 | Axillary bud on culm | ABC | 0 = No, 1 = Yes Does node have waxiness? |
| 25 | Angle of Stem | AS | 1 = Erect or θ ≥ 80°, 3 = 80° > θ ≥ 60°, 5 = 60° > θ ≥ 40°, 7 = 40° > θ ≥ 20°, 9 = θ < 20°or Prostrate (Angle between plant outside stem and ground) |
| 26 | Tillers number per plot | TNP | Total number of tillers to plant on one plot |
| 27 | Dry matter content | DM | Dry matter content after fresh stem was dried to constant weight at 45 ℃ and at 105 ℃ |
| 28 | Neutral detergent fiber content | NDF | Determined with detergent fiber analysis |
| 29 | Acid detergent fiber content | ADF | Determined with detergent fiber analysis |
| 30 | Hemi-fibre content | HF | Determined with detergent fiber analysis |
| 31 | Fibre content | FC | Determined with detergent fiber analysis |
| 32 | Acid dissoluble lignin content | ADL | Determined with detergent fiber analysis |
| 33 | Acid insoluble ash content | AIA | Determined with detergent fiber analysis |
| 34 | Total ash content | TA | Ash content of matter incinerated in muffle furnace at 550 ℃ three hours |
| 35 | Total moisture content | TM | Total water content after fresh matter was dried to constant weight at 45 ℃ and at 105 ℃ |
| 36 | Total biomass per plot | TMP | Total biomass production of plants in one plot |
| 37 | Withered state | WiS | 0 = No, 1 = Yes (Have the plants begun to wither?) |
| Quantitative Trait | Number of Category | Qualitative Trait | Number of Category |
|---|---|---|---|
| DBE | 7 | NH | 2 |
| DBF | 26 | LBH | 2 |
| DsBF | 29 | ShH | 2 |
| PH | 10 | ShMH | 2 |
| SL | 15 | IWa | 2 |
| FIL | 13 | NWa | 2 |
| SALD | 12 | LWa | 2 |
| NS | 14 | ShWa | 2 |
| LL | 10 | StC | 6 |
| LW | 13 | LC | 3 |
| FWS | 12 | ShC | 6 |
| DWS | 12 | ABC | 2 |
| TNP | 13 | AS | 5 |
| DM | 14 | WiS | 2 |
| NDF | 11 | - | - |
| ADF | 12 | - | - |
| HF | 14 | - | - |
| FC | 10 | - | - |
| ADL | 12 | - | - |
| AIA | 11 | - | - |
| TA | 14 | - | - |
| TM | 13 | - | - |
| TMP | 12 | - | - |
| Sampling Strategy | Ideal | Actual | ||||
|---|---|---|---|---|---|---|
| Number | Ratio (%) | Non-prior | Ratio (%) | Prior | Ratio (%) | |
| C | 92 | 20 | 81 | 17.2 | 134 | 28.5 |
| 115 | 25 | 98 | 20.8 | 141 | 29.9 | |
| 138 | 30 | 115 | 24.4 | 150 | 31.8 | |
| 161 | 35 | 131 | 27.8 | 159 | 33.8 | |
| 184 | 40 | 146 | 31.0 | 167 | 35.5 | |
| 207 | 45 | 161 | 34.2 | 177 | 37.6 | |
| 253 | 50 | 187 | 39.7 | 197 | 41.8 | |
| G | 96 | 20 | 99 | 21.0 | 138 | 29.3 |
| 119 | 25 | 120 | 25.5 | 150 | 31.8 | |
| 142 | 30 | 140 | 29.7 | 161 | 34.2 | |
| 165 | 35 | 160 | 34.0 | 174 | 36.9 | |
| 186 | 40 | 178 | 37.8 | 189 | 40.1 | |
| 212 | 45 | 198 | 42.0 | 203 | 43.1 | |
| 234 | 50 | 213 | 45.2 | 216 | 45.9 | |
| L | 95 | 20 | 98 | 20.8 | 134 | 28.5 |
| 116 | 25 | 119 | 25.3 | 145 | 30.8 | |
| 144 | 30 | 147 | 31.2 | 163 | 34.6 | |
| 163 | 35 | 166 | 35.2 | 177 | 37.6 | |
| 189 | 40 | 189 | 40.1 | 194 | 41.2 | |
| 211 | 45 | 210 | 44.6 | 210 | 44.6 | |
| 237 | 50 | 231 | 49.0 | 231 | 49.0 | |
| LG | 93 | 20 | 96 | 20.4 | 130 | 27.6 |
| 118 | 25 | 121 | 25.7 | 144 | 30.6 | |
| 142 | 30 | 145 | 30.8 | 159 | 33.8 | |
| 166 | 35 | 169 | 35.9 | 176 | 37.4 | |
| 188 | 40 | 191 | 40.6 | 194 | 41.2 | |
| 214 | 45 | 217 | 46.1 | 217 | 46.1 | |
| 235 | 50 | 237 | 50.3 | 237 | 50.3 | |
| P | 95 | 20 | 98 | 20.8 | 127 | 27.0 |
| 118 | 25 | 121 | 25.7 | 138 | 29.3 | |
| 142 | 30 | 146 | 31.0 | 157 | 33.3 | |
| 164 | 35 | 167 | 35.5 | 177 | 37.6 | |
| 187 | 40 | 190 | 40.3 | 198 | 42.0 | |
| 211 | 45 | 214 | 45.4 | 220 | 46.7 | |
| 244 | 50 | 244 | 51.8 | 248 | 52.7 | |
| S | 97 | 20 | 97 | 20.6 | 131 | 27.8 |
| 116 | 25 | 116 | 24.6 | 140 | 29.7 | |
| 143 | 30 | 140 | 29.7 | 155 | 32.9 | |
| 165 | 35 | 162 | 34.4 | 170 | 36.1 | |
| 186 | 40 | 181 | 38.4 | 185 | 39.3 | |
| 212 | 45 | 206 | 43.7 | 208 | 44.2 | |
| 236 | 50 | 227 | 48.2 | 228 | 48.4 | |
| SG | 95 | 20 | 98 | 20.8 | 129 | 27.4 |
| 120 | 25 | 123 | 26.1 | 142 | 30.1 | |
| 143 | 30 | 146 | 31.0 | 157 | 33.3 | |
| 164 | 35 | 167 | 35.5 | 174 | 36.9 | |
| 188 | 40 | 191 | 40.6 | 194 | 41.2 | |
| 213 | 45 | 216 | 45.9 | 218 | 46.3 | |
| 234 | 50 | 237 | 50.3 | 238 | 50.5 | |
| Parameter | Sampling Strategy | Sampling Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | G | L | LG | P | S | SG | PR | PD | R | D | NGR | |
| VPV | 1 | 2 | 4 | 5 | 7 | 3 | 6 | 4 | 3 | 2 | 1 | 5 |
| H | 4 | 1 | 6 | 3 | 7 | 5 | 2 | 2 | 1 | 3 | 4 | 5 |
| VPF | 1 | 3 | 5 | 6 | 2 | 7 | 4 | 1 | 2 | 4 | 3 | 5 |
| RPR | 7 | 5 | 4 | 2 | 1 | 6 | 3 | 1 | 2 | 5 | 4 | 3 |
| CV | 7 | 4 | 2 | 1 | 6 | 5 | 3 | 2 | 1 | 4 | 3 | 5 |
| Sum of rank | 20 | 15 | 21 | 17 | 23 | 26 | 18 | 10 | 9 | 18 | 15 | 23 |
| Sampling Strategies | Sampling Methods | Average | ||||
|---|---|---|---|---|---|---|
| D | R | PD | PR | NGR | ||
| C | 19.0 | 16.2 | 8.8 | 10.2 | - | 13.55 |
| G | 17.6 | 15.6 | 8.4 | 11.2 | - | 13.20 |
| L | 19.6 | 16.2 | 8.2 | 8.2 | - | 13.05 |
| LG | 17.6 | 17.4 | 7.8 | 9.4 | - | 13.05 |
| P | 25.0 | 25.6 | 11.8 | 10.0 | 25.8 | 19.64 |
| S | 22.8 | 19.0 | 9.2 | 10.8 | - | 15.45 |
| SG | 23.6 | 18.6 | 10.2 | 10.6 | - | 15.75 |
| Average | 20.74 | 18.37 | 9.20 | 10.06 | 25.80 | 14.81 |
| Parameter | Sampling Scale | ||||||
|---|---|---|---|---|---|---|---|
| 20% | 25% | 30% | 35% | 40% | 45% | 50% | |
| VPV | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| H | 2 | 1 | 3 | 4 | 5 | 6 | 7 |
| VPF | 5 | 3 | 1 | 2 | 4 | 6 | 7 |
| RPR | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| CV | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Sum of rank | 22 | 18 | 17 | 18 | 20 | 22 | 23 |
| Sampling Scale | ||||||||
|---|---|---|---|---|---|---|---|---|
| 20% | 25% | 30% | 35% | 40% | 45% | 50% | ||
| Sampling Method | D | 90.24 | 96.40 | 91.18 | 96.28 | 100.00 | 100.00 | 100.00 |
| R | 92.35 | 97.53 | 92.46 | 97.32 | 100.00 | 100.00 | 100.00 | |
| PD | 94.38 | 98.01 | 93.85 | 100.00 | 100.00 | 100.00 | 100.00 | |
| PR | 95.67 | 89.76 | 95.30 | 100.00 | 100.00 | 100.00 | 100.00 | |
| Sampling Strategy | C | 94.09 | 95.14 | 96.18 | 96.37 | 97.22 | 98.13 | 98.40 |
| G | 95.45 | 96.28 | 96.69 | 98.13 | 98.28 | 98.40 | 98.95 | |
| LG | 94.91 | 95.98 | 96.35 | 97.81 | 97.96 | 98.76 | 98.95 | |
| SG | 95.54 | 96.29 | 96.87 | 97.10 | 98.04 | 98.91 | 99.03 | |
| L | 95.18 | 95.97 | 97.32 | 98.15 | 98.39 | 98.82 | 99.01 | |
| P | 94.91 | 95.56 | 96.34 | 96.74 | 97.25 | 97.48 | 98.60 | |
| S | 94.91 | 95.98 | 97.21 | 97.36 | 98.32 | 98.68 | 98.89 | |
| Parameter | Sampling Scheme | Sampling Scale | ||||||
|---|---|---|---|---|---|---|---|---|
| 20% | 25% | 30% | 35% | 40% | 45% | 50% | ||
| H | PD-G | 1.719 | 1.716 | 1.710 | 1.708 | 1.705 | 1.700 | 1.698 |
| PD-LG | 1.724 | 1.725 | 1.721 | 1.716 | 1.706 | 1.698 | 1.699 | |
| PR-G | 1.713 | 1.709 | 1.702 | 1.704 | 1.702 | 1.704 | 1.701 | |
| PR-LG | 1.722 | 1.717 | 1.714 | 1.713 | 1.709 | 1.705 | 1.702 | |
| CV | PD-G | 46.764 | 46.513 | 46.566 | 46.267 | 46.186 | 45.938 | 45.802 |
| PD-LG | 46.717 | 46.409 | 46.087 | 46.066 | 45.961 | 45.745 | 45.193 | |
| PR-G | 46.726 | 46.637 | 46.793 | 46.122 | 46.179 | 45.869 | 45.511 | |
| PR-LG | 46.932 | 46.359 | 46.369 | 45.858 | 45.775 | 45.489 | 45.147 | |
| RPR | PD-G | 98.900 | 99.300 | 99.400 | 99.400 | 99.400 | 99.500 | 99.500 |
| PD-LG | 98.900 | 99.300 | 99.400 | 99.500 | 99.500 | 99.500 | 99.500 | |
| PR-G | 98.800 | 98.800 | 99.300 | 99.400 | 99.400 | 99.500 | 99.600 | |
| PR-LG | 98.700 | 99.100 | 99.300 | 99.500 | 99.500 | 99.500 | 99.600 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Zheng, C.; Xiang, W.; Yi, Z.; Xiao, L. A Sampling Strategy to Develop a Primary Core Collection of Miscanthus spp. in China Based on Phenotypic Traits. Agronomy 2022, 12, 678. https://doi.org/10.3390/agronomy12030678
Liu S, Zheng C, Xiang W, Yi Z, Xiao L. A Sampling Strategy to Develop a Primary Core Collection of Miscanthus spp. in China Based on Phenotypic Traits. Agronomy. 2022; 12(3):678. https://doi.org/10.3390/agronomy12030678
Chicago/Turabian StyleLiu, Shuling, Cheng Zheng, Wei Xiang, Zili Yi, and Liang Xiao. 2022. "A Sampling Strategy to Develop a Primary Core Collection of Miscanthus spp. in China Based on Phenotypic Traits" Agronomy 12, no. 3: 678. https://doi.org/10.3390/agronomy12030678
APA StyleLiu, S., Zheng, C., Xiang, W., Yi, Z., & Xiao, L. (2022). A Sampling Strategy to Develop a Primary Core Collection of Miscanthus spp. in China Based on Phenotypic Traits. Agronomy, 12(3), 678. https://doi.org/10.3390/agronomy12030678