2.1. Construction of the Data Set
The target dataset used for the experiments in this paper is maize leaf diseases. Among the various maize leaf diseases, the most common and representative ones are blotch disease, gray spot, and rust, and images of the three leaf diseases, as well as images of healthy maize leaves, are used as the dataset.
- (a)
Maize blotch disease
The disease produces spots on the leaves, such as long rhombus shape. The color is generally brown or yellow-brown, and the rhombus-shaped spots are generally 5–10 cm long and 1 cm wide, approximately. The disease will gradually expand when the disease is serious, and even lead to leaf death.
- (b)
Maize rust
The disease mainly occurs on maize leaves, on both sides of the leaf, and causes scattered or aggregated growth of round, yellow-brown, powdery spots and scattered rust-colored powder, that is, the summer spore mounds and summer spores of the pathogenic bacteria. Later in the season, round, black winter spore mounds and winter spores grow on the spots.
- (c)
Maize gray spot disease
The disease initially forms oval to rectangular gray to light brown spots on the leaf surface without obvious margins, turning brown later. The spots are mostly confined between parallel leaf veins and are 4 to 20 × 2 to 5 (mm) in size. When the humidity is high, the abaxial surface of the spot produces gray moldy material, that is, the conidiophore and conidia of the disease.
- (d)
Healthy maize leaves
Leaf blade flattened and broad, leaf sheath with transverse veins; ligule membranous, about 2 mm long; linear-lanceolate, base rounded auriculate, glabrous or blemished pilose, midrib stout, margin slightly scabrous.
In the process of target detection model training, dataset production and image annotation are two very important steps. It is the foundation of the dataset and can be directly related to the reliability of the experiment, while the accuracy of the image annotation directly affects the training effect and the accuracy of the test.
The sample dataset of maize leaf disease images selected and used in this paper is mainly collected from the open-source website PlantVillage (
https://tensorflow.google.cn/datasets/catalog/plant_village accessed on 13 June 2022) for three common maize leaf diseases and healthy maize leaf images. The total number of datasets is 4353, in which maize maculatus, maize rust, and maize gray spot are the three common diseases of maize leaves listed in this paper. The three diseases and healthy leaves are shown in
Figure 1.
The number of maize leaf data sets is shown in
Table 1.
Because of the small number of large spots and gray spots, this paper additionally takes the data set of maize leaves taken from the pear test field and expands the number of data sets of gray spot and large spots by cutting out 200 sheets of maize leaves with gray spot and 200 sheets of maize leaves with the large spot from the data set taken from the pear test field and filling them into the original data set.
The image annotation tool used in this paper is Make Sense (
https://www.makesense.ai/ accessed on 13 June 2022), an online annotation tool recommended by the authors of YOLOv5n to annotate the images, which can directly output YOLO format label files and can be directly applied to the YOLOv5n network.
The sorted data set picture files and label files were divided into the training dataset, the validation dataset, and the test dataset according to the ratio of 6:2:2, and then put into the network model for subsequent data enhancement and model training.
2.2. Data Augmentation
When we want to obtain a well-performing neural network model, we must have a large amount of data to support it, but it takes a lot of time and labor to obtain new data. If we use data augmentation [
17], we can use the computer to create new data to increase the number of training samples, for example, by changing color brightness, hue saturation, scaling, rotation, panning, cropping, perspective transformation, etc., and adding some appropriate noise data to improve the model generalization.
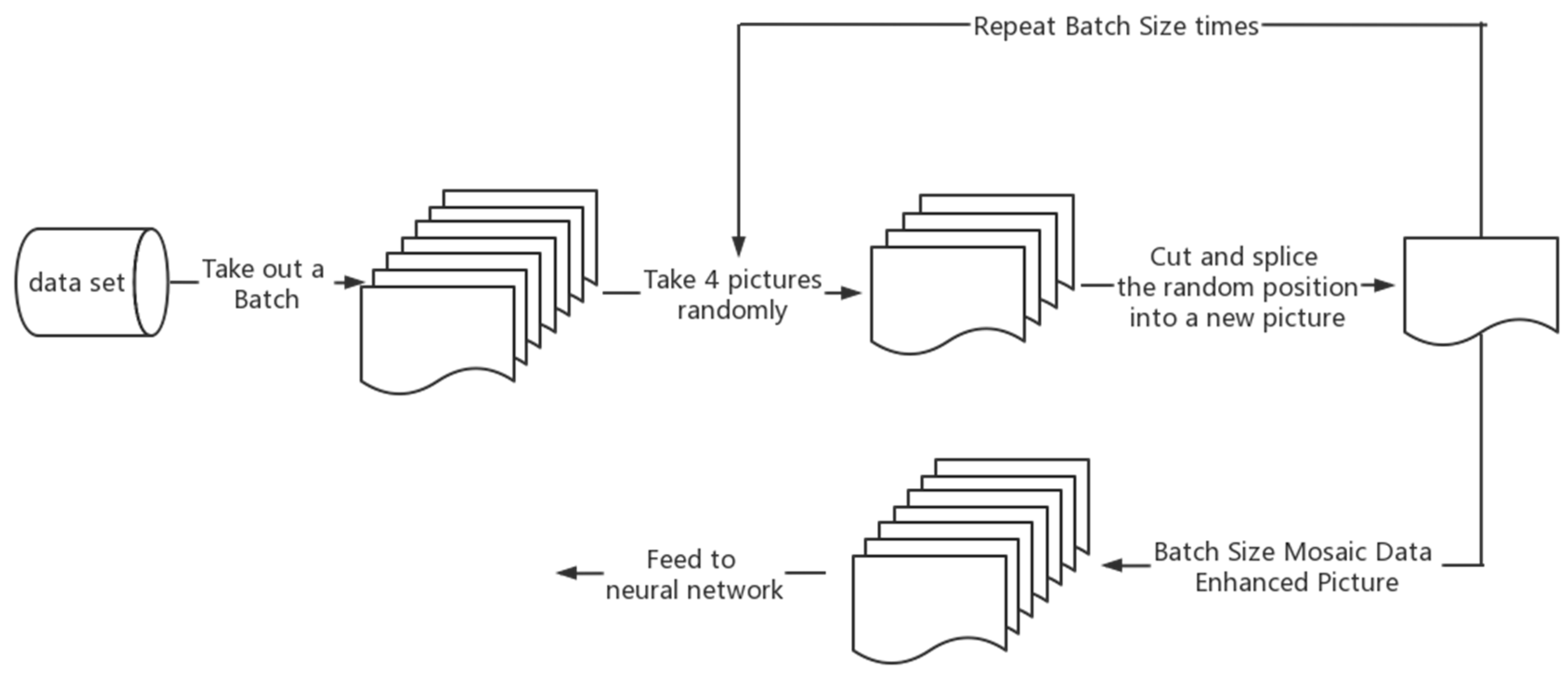
In the YOLOv5n network model described in this paper, not only are some basic data enhancement methods included, but also the Mosaic data enhancement [
18] is used, whose main idea is to select four images from the used dataset, crop and scale them randomly, and then arrange them randomly to form a new image. This has the advantage of increasing the number of datasets while augmenting the number of small sample targets, and it improves the training speed of the model. The flowchart of Mosaic data enhancement is shown in
Figure 2.
Mosaic data enhancement utilizes four images, which enriches the background of the detected objects and calculates the data of four images at once when BN calculates, so that the mini-batch size does not need to be large, and then a GPU can achieve better results.
In practice, Mosaic data enhancement first removes one batch of data from the total data set, takes out four images at random from it each time, crops and splices them at random positions, synthesizes new images, repeats the batch size several times, and finally gets a new batch size of one batch of images after mosaic data enhancement, then feeds to the neural network for training.
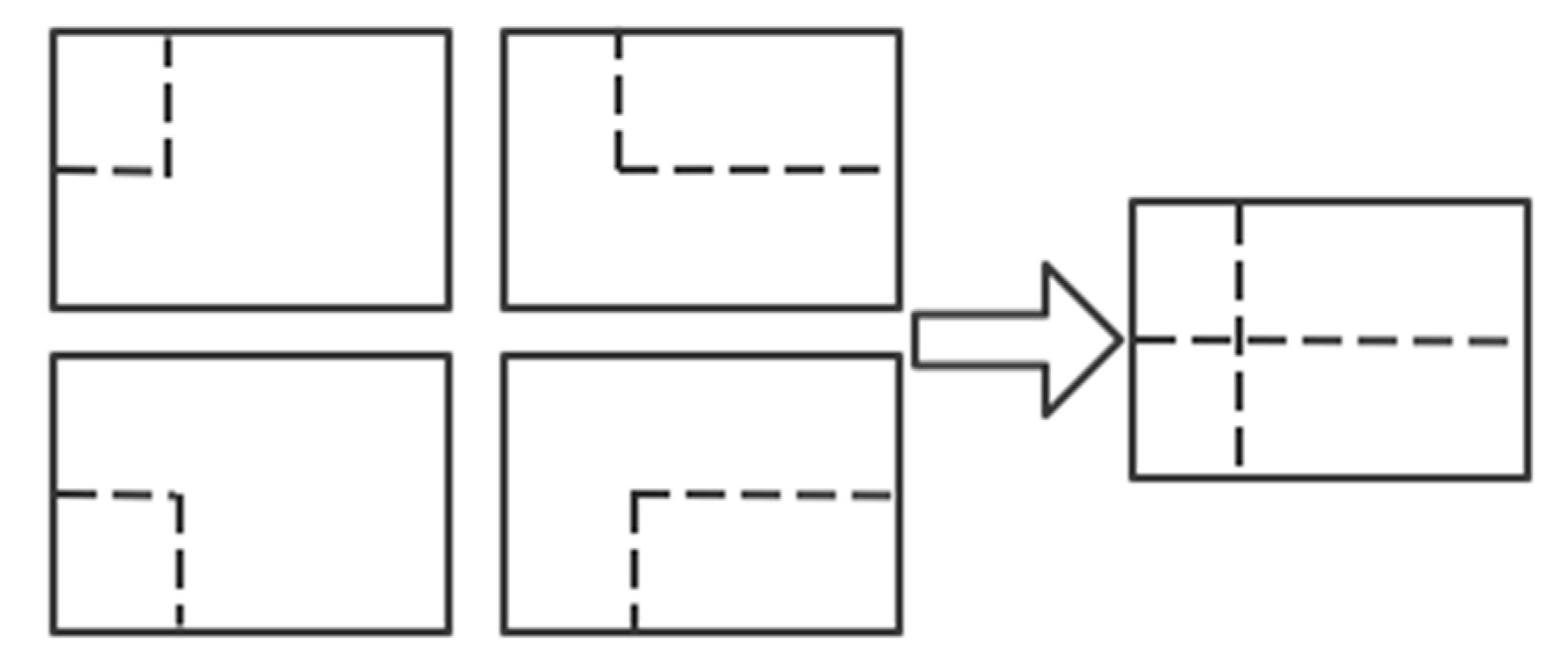
When cropping and splicing the images, the four randomly obtained images are cropped by a randomly positioned crosshair, and the corresponding parts are taken for splicing. At the same time, the target frame of each original image is limited by the crosshair crop, and will not exceed the original crop range. The implementation of Mosaic data enhancement in practice is shown in
Figure 3.
Mosaic has the following advantages: increases data diversity; randomly selects four images for combination; the number of images obtained from the combination is more than the number of original images; enhances model robustness; mixes four images with different semantic information; allows the model to detect targets beyond the conventional context; and enhances the effect of batch normalization. When the model is set to BN operation, the training will increase the total number of samples (BatchSize) as much as possible, because the BN principle is to calculate the mean and variance of each feature layer; if the total number of samples is larger, then the mean and variance calculated by BN will be closer to the mean and variance of the whole dataset, and the better the effect. The Mosaic data enhancement algorithm is helpful to improve the performance of small target detection. The enhanced images are stitched together from four original images, so that each image has a higher probability of containing small targets.
The operation principle of Mosaic data enhancement is equivalent to passing in four images for learning at one time during the training process, increasing the number of single training samples and target diversity, improving network training convergence speed and detection accuracy, and reducing large samples to small samples randomly, increasing the number of small-scale targets. Since the target of this paper is maize leaf disease and the disease spot is a small-scale target, Mosaic data enhancement provides important help for this study.
Figure 4 shows 16 examples of data enhanced by Mosaic data. The file name in the picture is the file name of the image data involved in data enhancement. In the example, the file name is only for demonstration and will not be integrated into the picture to affect the subsequent model training. The colored boxes in the figure are identification boxes, where 0 indicates gray spot, 1 indicates rust, 2 indicates healthy maize leaves, and 3 indicates large spot disease. As shown in
Figure 4.
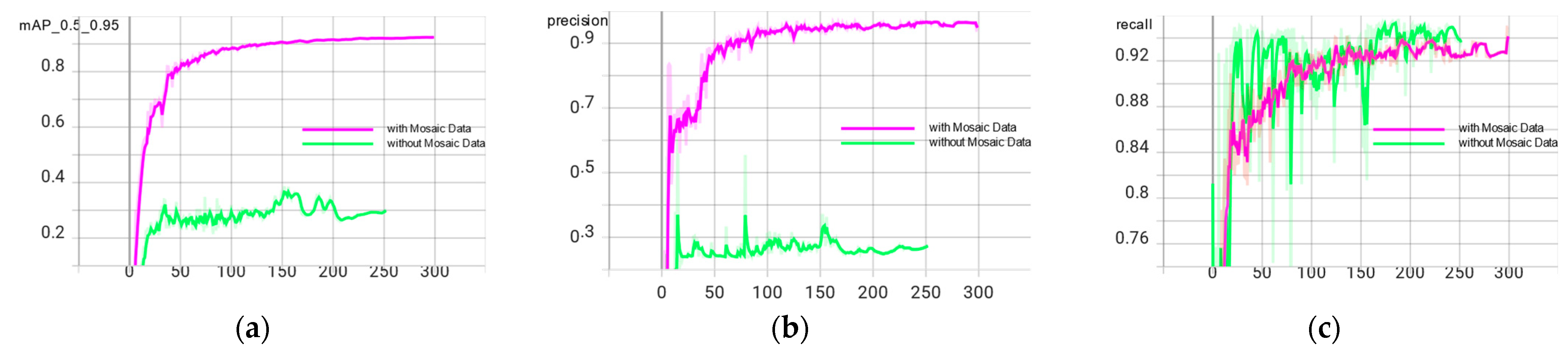
To verify that the Mosaic data enhancement is real and effective for the experimental effect, this paper compares the parameters of the YOLOv5n network model with and without Mosaic data enhancement. The effect is shown in
Figure 5.
From the
Figure 5, it can be seen that the accuracy of the model is significantly and substantially improved after adding Mosaic data augmentation, and the convergence of the model is significantly improved compared to that without Mosaic data augmentation. At the same time, it can be seen that due to the Early Stopping method in the YOLOv5n model, which can resist overfitting, the model terminates early after 252 iterations in the training curve without the Mosaic data augmentation, because the accuracy no longer improves.
2.3. YOLOv5 Network Model
The YOLOv5 target detection algorithm is the 5th version of YOLO, whose core idea is to use the whole map as the input of the network and regress the location coordinates and category of the target directly in the output layer, which is characterized by high detection accuracy and fast detection speed to meet the demand of real-time monitoring.
The YOLOv5 network has been updated with five versions, YOLOv5n, YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x in order, with similar network structures and changes in network depth and width of feature maps based on YOLOv5s. Its accuracy and inference speed follow, of which YOLOv5n is in 2021 October after YOLOv5 update version 6.0, which has the advantage of being the fastest and the smallest model size compared to other versions. The ultimate goal is to deploy the model to mobile for real-time detection. To meet the lightweight requirement, the final study of this paper decided to use the YOLOv5n detection model with the lowest complexity to reduce the model storage footprint and increase the recognition speed.
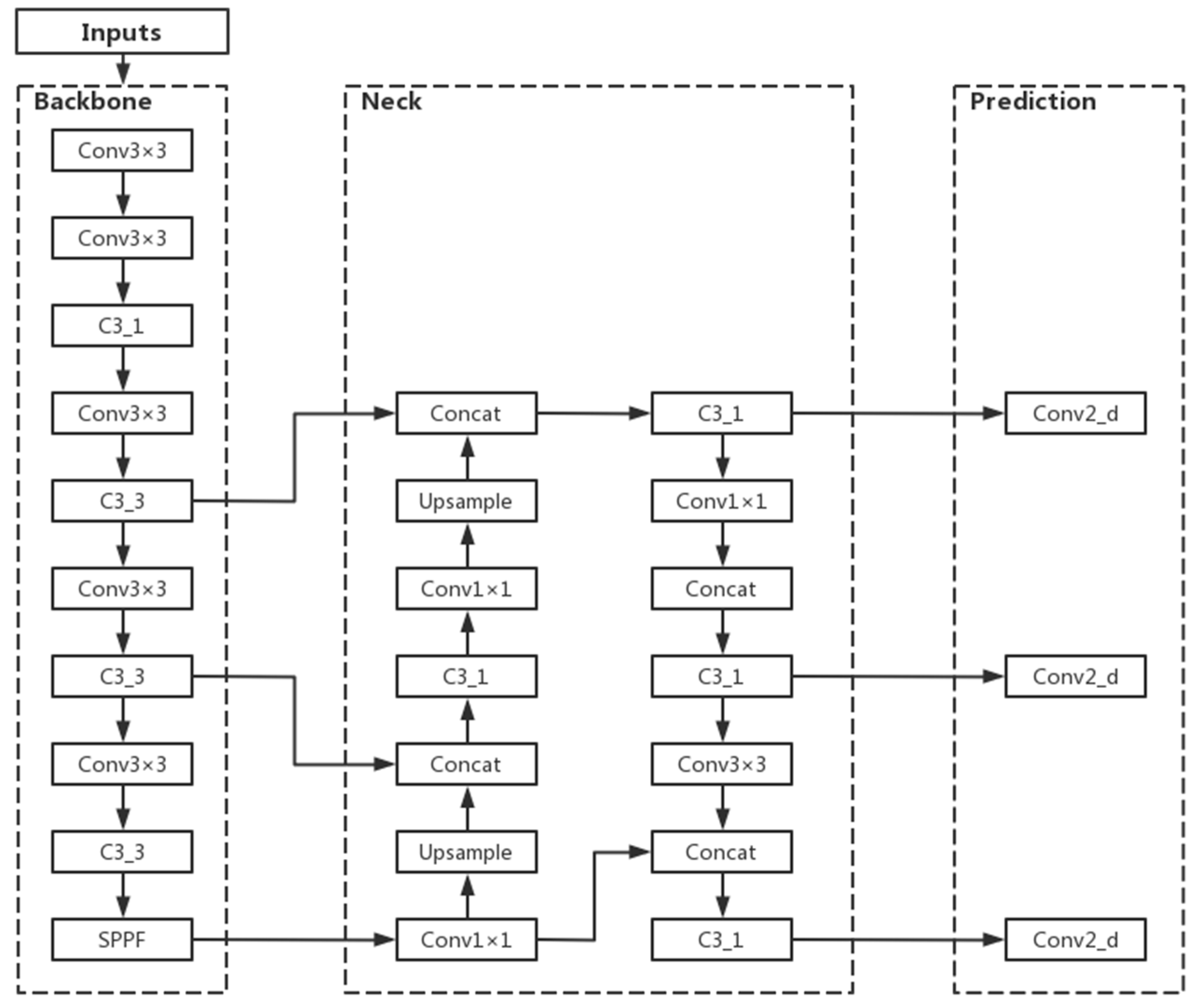
The YOLOv5n algorithm consists of four parts: input, backbone, neck, and prediction [
19]. Among them, Mosaic data enhancement is beneficial for detecting small targets and is suitable for leaf disease identification in this paper. The adaptive image scaling operation fixes images of different sizes to 640 pixels × 640 pixels as input. In the backbone network, YOLOv5n mainly uses the Conv module CSP structure and SPPF module. The feature fusion stage mainly borrows the idea from PANet [
20]. The FPN (Feature Pyramid Network) and PAN (Path Aggregation Network) are borrowed to form the FPN + PAN structure. The prediction output continues the previous idea of YOLO by outputting three sizes of prediction maps at the same time, which are suitable for detecting small, medium and large targets. The network structure of YOLOv5n is shown in
Figure 6.
2.4. Improvements to the YOLOv5n Model
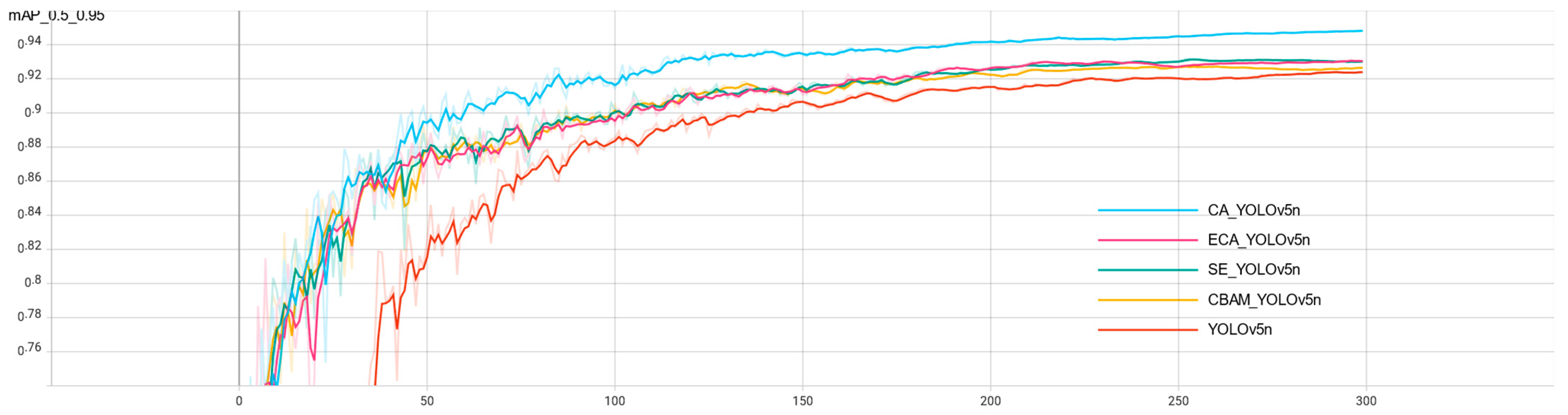
2.4.1. Adding CA to Improve Model Accuracy
In the task of maize leaf disease detection, since the disease spots occupy relatively few pixels of the image, their feature information is easily lost in the deep network, resulting in errors such as the wrong detection and missed detection. At this point, it would be more beneficial for the network model to recognize the images if the unsupervised network can automatically acquire the ability to focus on smaller pixel blocks. Therefore, this paper introduces the CA (Coordinate Attention) mechanism [
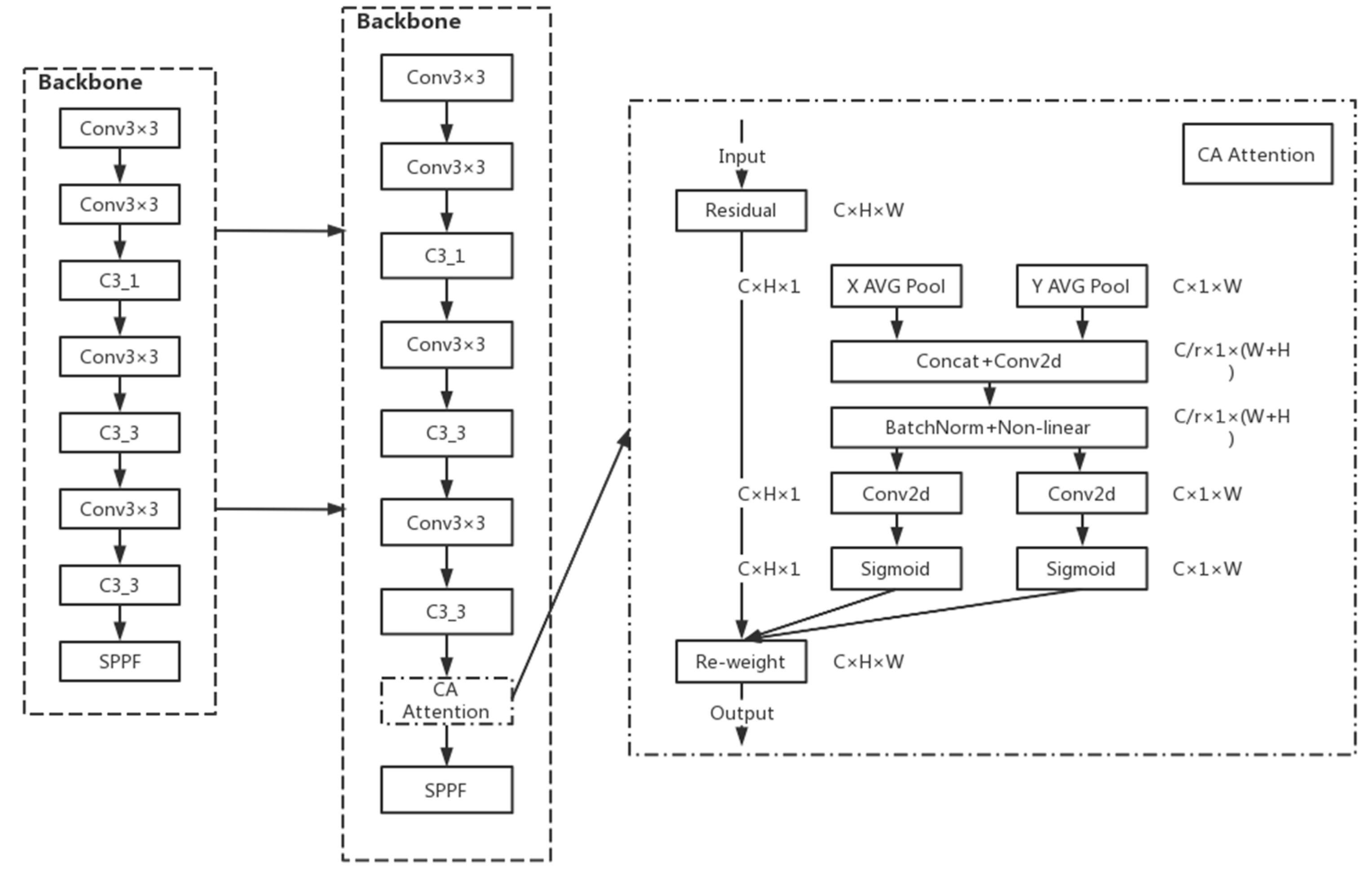
21] in the YOLOv5n backbone network, which is used to tell the model “what” and “where,” and which has been widely studied and deployed to improve the performance of neural networks. The use of lightweight attention modules can improve the network’s ability to extract features from maize leaf spots while saving parameters.
For other channel attentions, they are taken to transform the input into individual feature vectors by 2D global pooling. The general idea of Coordinate Attention used in this paper is to decompose channel attention into two 1D feature encodings of aggregated features along different directions in the H-direction as well as the W-direction, that is, into and . CA This idea has the advantage of capturing long-range dependencies along one spatial direction while retaining accurate location information along the other spatial direction. After that, the generated feature maps are encoded separately, resulting in two direction-aware, as well as position-sensitive, feature maps, which can be complementarily applied to the input feature maps to enhance the representation of the target of interest. The two directional feature maps are then Concept spliced and then fed into a shared convolution to reduce the dimensionality to C/r, after which they are separated and allowed to Sigmoid in different directions to obtain the coefficients and then multiplied together. Finally, the feature map is obtained.
After adding CA attention to the YOLOv5n backbone network [
22], keeping the parameters unchanged, the model is trained again, and the trained model has significantly improved the effect compared with the original model; the average accuracy mean value is increased from 0.924 to 0.948, and the model size is not significantly increased, which meets the requirement of being lightweight.
In this paper, after adding CA attention to the YOLOv5n backbone network, the specific structure of the backbone network is shown in
Figure 7.
2.4.2. Incorporating Swin Transformer Structure to Improve Model Generalization Performance
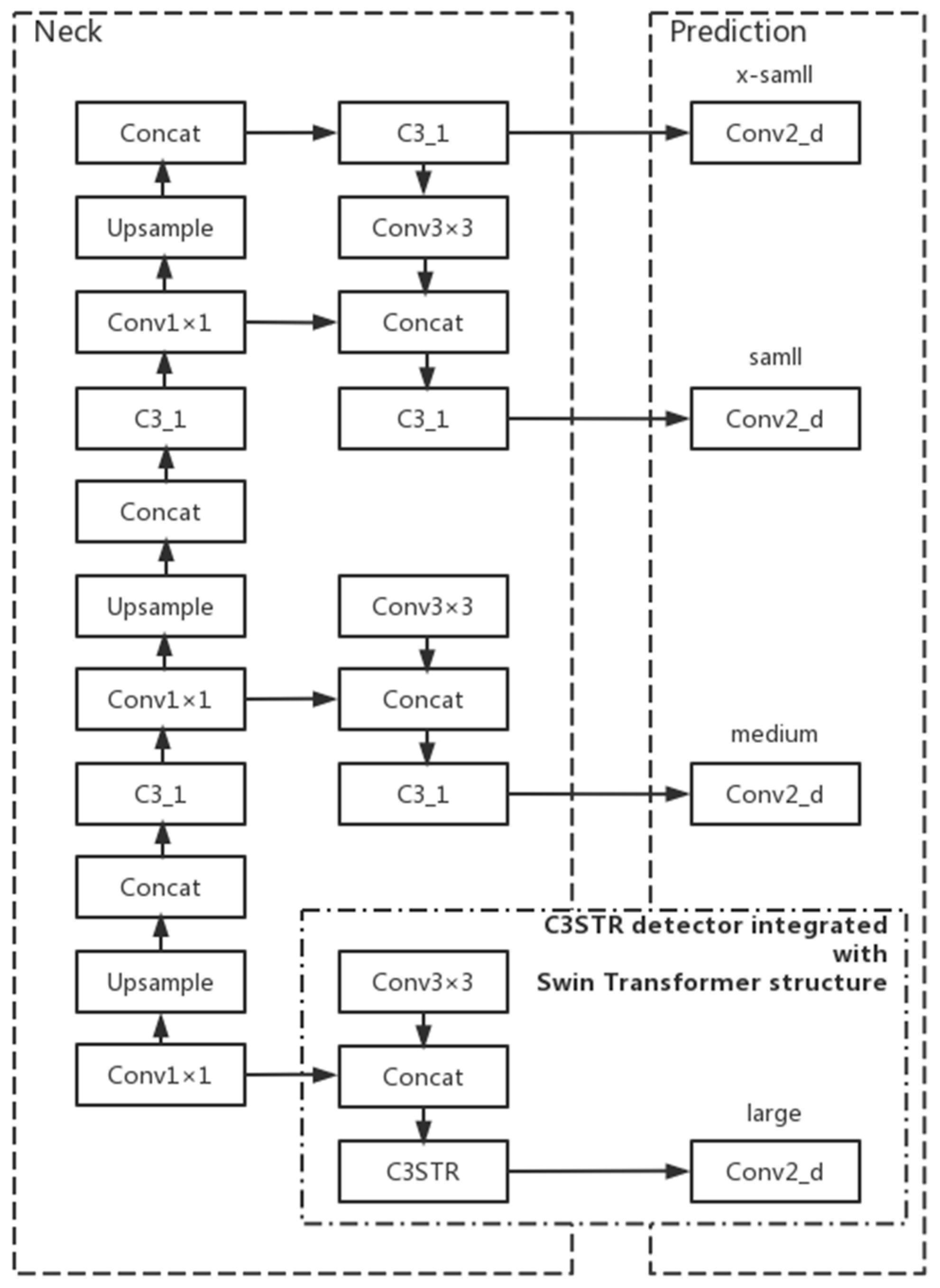
In the detection of maize leaf spots, the distribution of different types of spots in the leaf images differs: large spots occupy a small area of the leaf and rely more on local information of high-level features; rusts have a large distribution area and rely on global information more obviously; gray spots are moderate in size and rely on both local and global information. The performance of Convolutional Neural Networks (CNN) is more capable of capturing local information and has a certain disadvantage in global information acquisition. To alleviate the adverse effects of the non-uniform spot size, the model is improved by extracting global information using Swin Transformer [
23]. In this paper, a smaller size target detection head was added to the original small, medium and large size detection heads of the YOLOv5n model to enhance its ability to identify small targets of the spots. The x-small size detection head in
Figure 8, and the Swin Transformer structure, was incorporated into the large size detection head to replace the original C3 structure with the C3STR structure incorporated into the large size detection head to change the original C3 structure to C3STR structure, thus improving the model’s capture of feature information.The improved network structure is shown in
Figure 8.
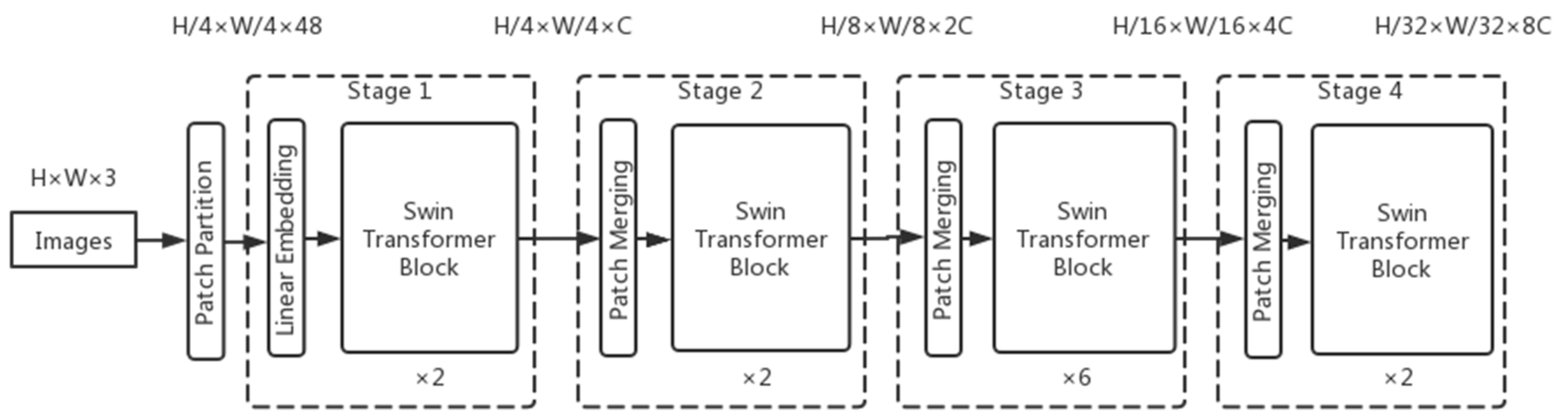
The Swin Transformer model was proposed by Microsoft Research in 2021. Swin Transformer uses hierarchical feature maps similar to those used in convolutional neural networks, such as feature map sizes with 4×, 8×, and 16× down-sampling of images, such that the backbone helps to build on top of this for tasks such as target detection, instance segmentation, etc. The Swin Transformer network is another collision of the Transformer model in the field of vision. The Swin Transformer network is another collision of Transformer model in vision field.
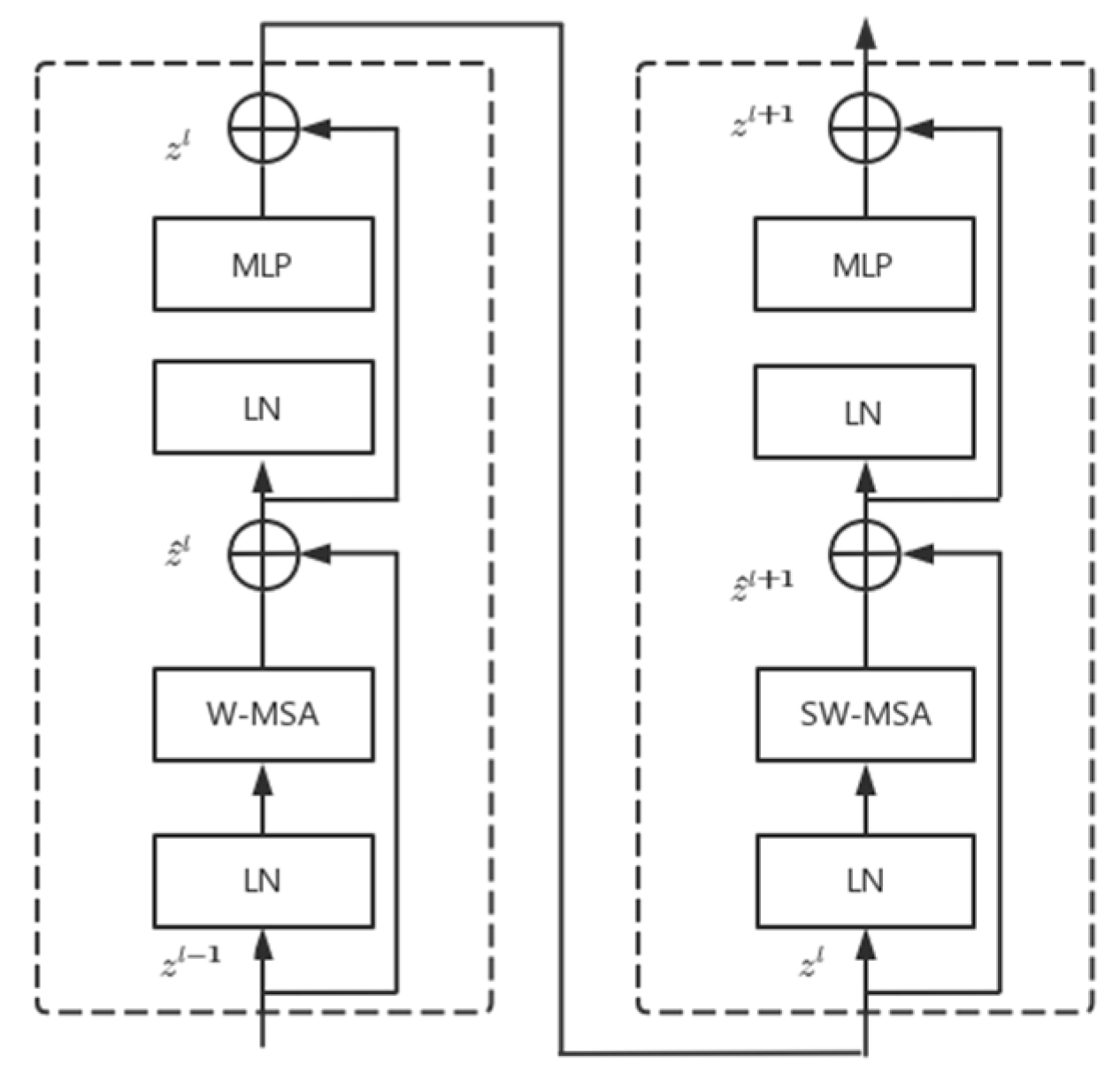
The concept of Windows Multi-Head Self-Attention (W-MSA) is used in Swin Transformer, for example, in the 4-fold downsampling and 8-fold downsampling in the figure below. The feature map is divided into multiple disjointed regions (Window), and Multi-Head Self-Attention is performed only within each window (Window).
The basic flow of the whole framework is as follows.
First, the image is input to the patch partition module for chunking, i.e., every 4 × 4 adjacent pixels is a patch, and then it is flattened in the channel direction. Assuming that the input is a three-channel RGB image, each patch has 4 × 4 = 16 pixels, and each pixel has three values, R, G, and B. The flattened image shape is 16 × 3 = 48, so the image shape changes from [H, W, 3] to [H/4, W/4, 48] after patch partition. Then the channel data of each pixel is linearly transformed by the linear embedding layer from 48 to C, i.e., the image shape is changed from [H/4, W/4, 48] to [H/4, W/4, C].
The Swin Transformer divides patches by first determining the size of each patch and then calculating the number of patches. The number of Swin Transformers decreases, and the perceptual range of each patch expands as the network depth deepens, which is designed to facilitate the construction of layers of Swin Transformer and to adapt to the multi-scale of visual tasks.The architecture of a Swin transformer (Swin-T) is shown in
Figure 9.
Then the feature maps of different sizes are constructed by four stages; except for Stage 1, where a linear embedding layer is first passed, the remaining three stages are first downsampled by a patch merging layer. Note that there are two types of blocks, as shown in
Figure 10, which differ only in that one uses the W-MSA structure and the other uses the SW-MSA structure. Moreover, these two structures are used in pairs, with one W-MSA structure used first and then one SW-MSA structure used.
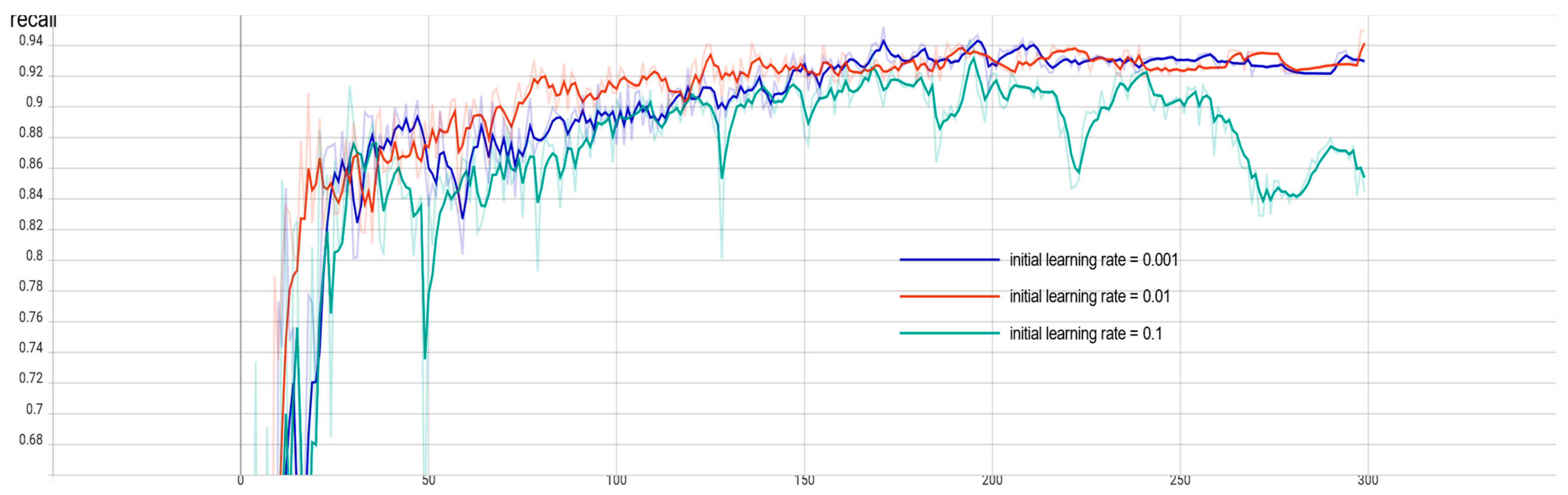
2.6. Evaluation Metrics
In this paper, the performance of the YOLOv5n network model is evaluated using several metrics from the target detection algorithm, specifically Precision (P), Recall (R), and mean Average Precision (mAP) [
24]. Average Precision (AP) is the integral of the PR curve formed by taking Precision (P) as the vertical axis and Recall (R) as the horizontal axis. A recall is a metric that reflects the ability of the model to find positive sample targets, precision is used to reflect the ability of the model to classify samples, and average precision is a metric that reflects the overall performance of the model to detect and classify targets. The mean Average Precision (mAP) represents the average of the mean accuracy of all categories. Among all the metrics, mAP is the most important evaluation metric in the target detection algorithm, which can measure the accuracy of the detection algorithm. mAP
0.5 is the AP of the target detection model evaluated at an IoU threshold of 0.5. mAP
0.5 is its mean value for all categories; AP
0.5–0.95 is the mean value of the AP of the model evaluated at different IoU thresholds (0.5–0.95, step size 0.05); and AP
0.5–0.95 is the average value of AP evaluated under different IoU thresholds (0.5–0.95, step size 0.05), which is a more stringent model accuracy index. mAP
0.5–0.95 is the average value of all categories. In this paper, we choose mAP
0.5–0.95 as the evaluation index. The additional evaluation index considered in this paper is the number of parameters, and the number of parameters indicates the size of the storage space occupied by the model file in MB.
The expressions for the calculation of Precision (P), Recall (R), Average Precision (AP), and mean Average Precision (mAP) are shown in Equations (1)–(4).
where:
- -
The number of true samples.
- -
The number of false positive samples.
- -
Number of pseudo-negative samples.
- -
The number of species in the sample.
The positive and negative samples are judged by setting the average Intersection over Union (IoU) threshold between the predicted target area and the actual target area, and if the IoU of both exceeds the threshold, the sample is positive, and if vice versa, the sample is negative.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}