

An Information Entropy Masked Vision Transformer (IEM-ViT) Model for Recognition of Tea Diseases


Abstract
:1. Introduction
2. Materials and Methods
2.1. IE of Tea Disease Images
2.2. Tea Leaf’s Disease Recognition
2.2.1. Vision Transformer
2.2.2. Self-Supervised Learning
2.2.3. Masked Visual Autoencoder
2.3. Dataset Description
2.4. Tea Disease Recognition
| Algorithm 1: Image Fragmentation IE Weighting Algorithm |
| Input patches (R G B), mask_ratio |
| Output: input autoEncode model patches |
| 1. Entr = {0,0,…,0} |
| 2. L = len(patch) |
| 3. for patch →patches: |
| 4. I_R(x,y), I_G(x,y),I_B(x,y) = patch(R G B) |
| 5. img(x,y) = 1/3*I_R(x,y) + 1/3*I_G(x,y) + 1/3*I_B(x,y) |
| 6. hist = histogram(img, bins = range(0, 256)) |
| 7. hist = hist[hist > 0] |
| 8. res = −log2(hist/hist.sum()).sum() |
| 9. entr[i] = res |
| 10. len_keep = int(L * (1 − mask_ratio)) |
| 11. ids = argsort(random(L)* entr)[0:len_keep] |
| 12. return patch[ids] |
3. Experimental Results and Analysis
3.1. Model Parameters
3.2. Tea Disease Image Completion
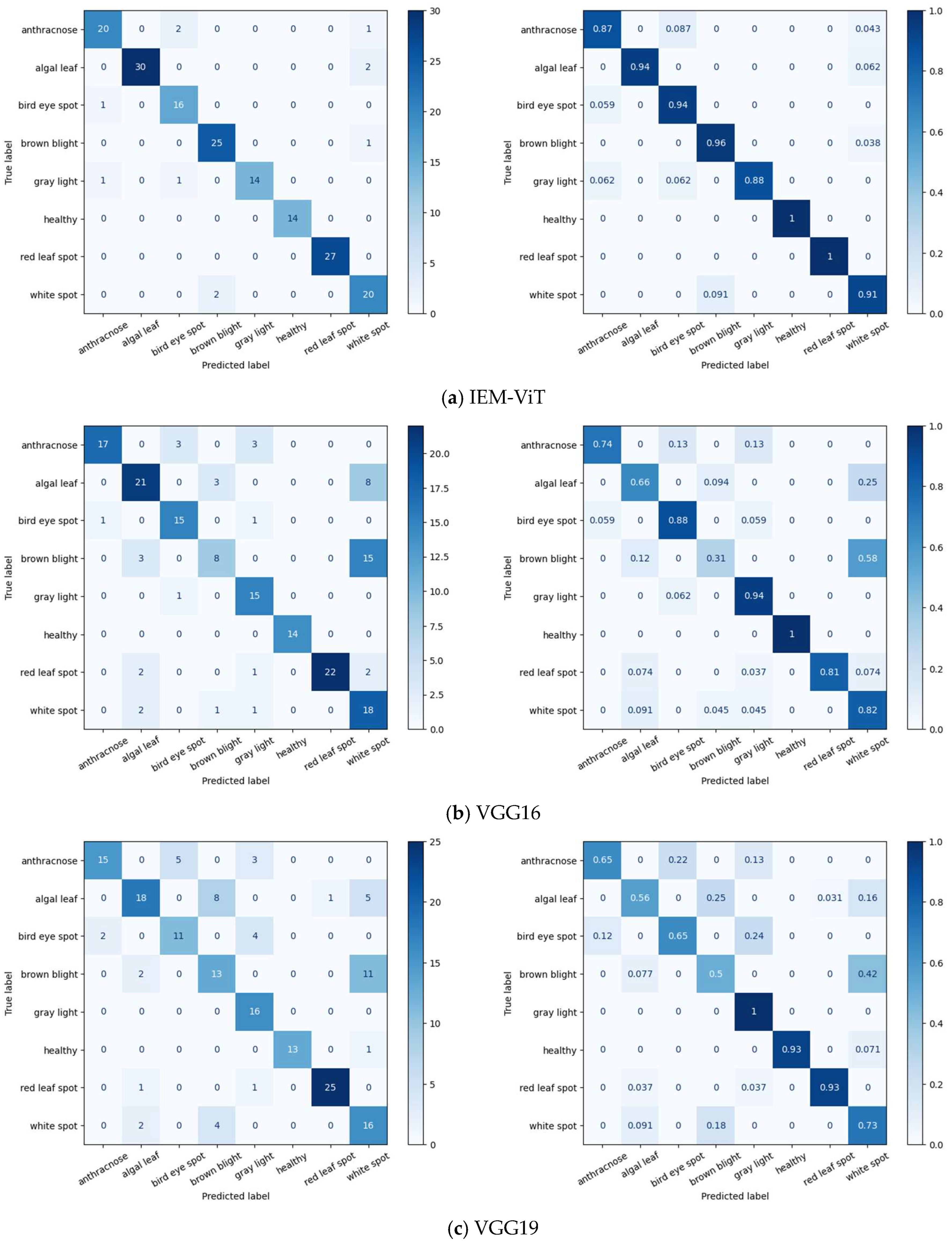
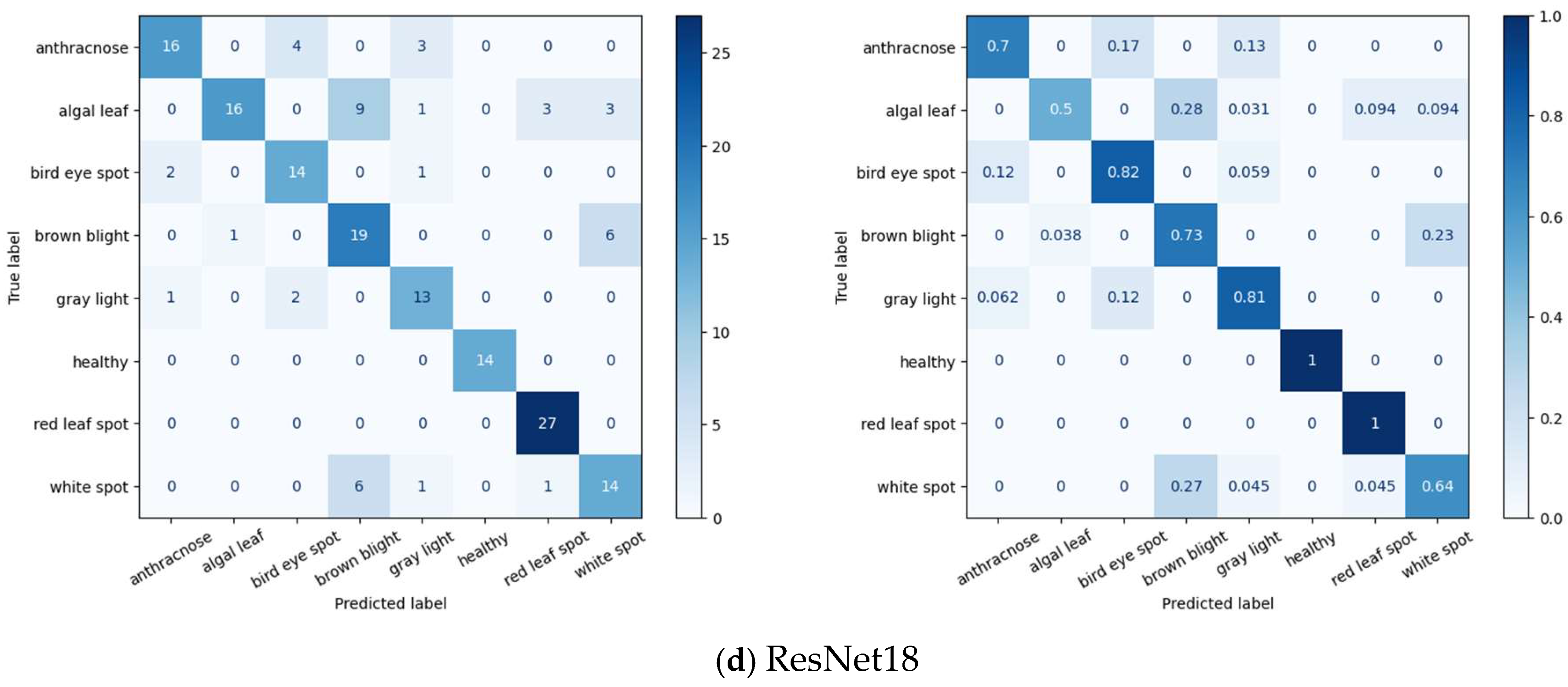
3.3. Experimental Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Waheed, A.; Goyal, M.; Gupta, D.; Khanna, A.; Hassanien, A.E.; Pandey, H.M. An optimized dense convolutional neural network model for disease recognition and classification in corn leaf. Comput. Electron. Agric. 2020, 175, 105456. [Google Scholar] [CrossRef]
- Hong, H.; Jiang, S.; Li, H.; Du, G.; Sun, Y.; Tao, H.; Quan, C.; Zhao, C.; Li, R.; Li, W.; et al. DeepHiC: A generative adversarial network for enhancing Hi-C data resolution. PLoS Comput. Biol. 2020, 16, e1007287. [Google Scholar] [CrossRef] [PubMed]
- Singh, V.; Misra, A.K. Detection of unhealthy region of plant leaves using image processing and genetic algorithm. In Proceedings of the 2015 International Conference on Advances in Computer Engineering and Applications, IEEE, Ghaziabad, India, 19–20 March 2015; pp. 1028–1032. [Google Scholar]
- Hossain, S.; Mou, R.M.; Hasan, M.M.; Chakraborty, S.; Razzak, M.A. Recognition and detection of tea leaf’s diseases using support vector machine. In Proceedings of the 2018 IEEE 14th International Colloquium on Signal Processing & Its Applications (CSPA), IEEE, Penang, Malaysia, 9–10 March 2018; pp. 150–154. [Google Scholar]
- Chen, J.; Liu, Q.; Gao, L. Visual Tea Leaf Disease Recognition Using a Convolutional Neural Network Model. Symmetry 2019, 11, 343. [Google Scholar] [CrossRef]
- Hu, G.; Wang, H.; Zhang, Y.; Wan, M. Detection and severity analysis of tea leaf blight based on deep learning. Comput. Electr. Eng. 2021, 90, 107023. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, A.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, C.; Yang, J.; Zhang, P.; Gao, M.; Xiao, B.; Dai, X.; Yuan, L.; Gao, J. Efficient self-supervised vision transformers for representation learning. arXiv 2021, arXiv:2106.09785. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Technol. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Son, J.; Lee, J.; Larsen, K.R.; Woo, J. Understanding the uncertainty of disaster tweets and its effect on retweeting: The perspectives of uncertainty reduction theory and information entropy. J. Assoc. Inf. Sci. Technol. 2020, 71, 1145–1161. [Google Scholar] [CrossRef]
- Bai, D.; Tian, M.; Chen, X.; Liu, M.; Xie, G. Image entropy based Visual Expression of Random. J. Hunan Univ. (Nat. Sci. Ed.) 2017, 44, 139–146. [Google Scholar]
- Barbedo, J.G.A. Plant disease identification from individual lesions and spots using deep learning. Biosyst. Eng. 2019, 180, 96–107. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.; Salathe, M. Using Deep Learning for Image-Based Plant Disease Detection. arXiv 2016, arXiv:1604.03169. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Xiao, H.; Xu, H.; Rao, Y.; Jiang, X.; Sun, X. Visual discrimination of citrus HLB based on image features. Vib. Spectrosc. 2019, 102, 103–111. [Google Scholar] [CrossRef]
- Ozguven, M.M.; Adem, K. Automatic detection and classification of leaf spot disease in sugar beet using deep learning algorithms. Phys. A Stat. Mech. Its Appl. 2019, 535, 122537. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Zhang, D.; Sun, Y.; Nanehkaran, Y.A. Using deep transfer learning for image-based plant disease identification. Comput. Electron. Agr. 2020, 173, 105393. [Google Scholar] [CrossRef]
- Wang, G.; Sun, Y.; Wang, J. Automatic image-based plant disease severity estimation using deep learning. Comput. Intel. Neurosc. 2017, 2017, 2917536. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, Y.; Wang, J.; Wang, X.; Wang, F. Key problems and Progress of Vision Transformers: The State of the Art and Prospects. J. Autom. 2022, 48, 957–979. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Shamshad, F.; Khan, S.; Zamir, S.W.; Khan, M.H.; Hayat, M.; Khan, F.S.; Fu, H. Transformers in medical imaging: A survey. arXiv 2022, arXiv:2201.09873. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers, European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Zhou, L.; Zhou, Y.; Corso, J.J.; Socher, R.; Xiong, C. End-to-end dense video captioning with masked transformer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8739–8748. [Google Scholar]
- Jiang, Y.; Chang, S.; Wang, Z. Transgan: Two transformers can make one strong gan. arXiv 2021, arXiv:2102.07074. [Google Scholar]
- Zhai, X.; Puigcerver, J.; Kolesnikov, A.; Ruyssen, P.; Riquelme, C.; Lucic, M.; Djolonga, J.; Pinto, A.S.; Neumann, M.; Dosovitskiy, A. A large-scale study of representation learning with the visual task adaptation benchmark. arXiv 2019, arXiv:1910.04867. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Liu, J.; Huang, X.; Liu, Y.; Li, H. MixMIM: Mixed and Masked Image Modeling for Efficient Visual Representation Learning. arXiv 2022, arXiv:2205.13137. [Google Scholar]
- Tong, Z.; Song, Y.; Wang, J.; Wang, L. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. arXiv 2022, arXiv:2203.12602. [Google Scholar]
- Geng, X.; Liu, H.; Lee, L.; Schuurams, D.; Levine, S.; Abbeel, P. Multimodal Masked Autoencoders Learn Transferable Representations. arXiv 2022, arXiv:2205.14204. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Krisnandi, D.; Pardede, H.F.; Yuwana, R.S.; Zilvan, V.; Heryana, A.; Fauziah, F.; Rahadi, V.P. Diseases classification for tea plant using concatenated convolution neural network. CommIT (Commun. Inf. Technol.) J. 2019, 13, 67–77. [Google Scholar] [CrossRef]
- Hu, G.; Wu, H.; Zhang, Y.; Wan, M. A low shot learning method for tea leaf’s disease identification. Comput. Electron. Agr. 2019, 163, 104852. [Google Scholar] [CrossRef]
- Karmokar, B.C.; Ullah, M.S.; Siddiquee, M.K.; Alam, K.M.R. Tea leaf diseases recognition using neural network ensemble. Int. J. Comput. Appl. 2015, 114, 975–8887. [Google Scholar]
- Hu, G.; Yang, X.; Zhang, Y.; Wan, M. Identification of tea leaf diseases by using an improved deep convolutional neural network. Sustain. Comput. Inform. Syst. 2019, 24, 100353. [Google Scholar] [CrossRef]











{kind=link}
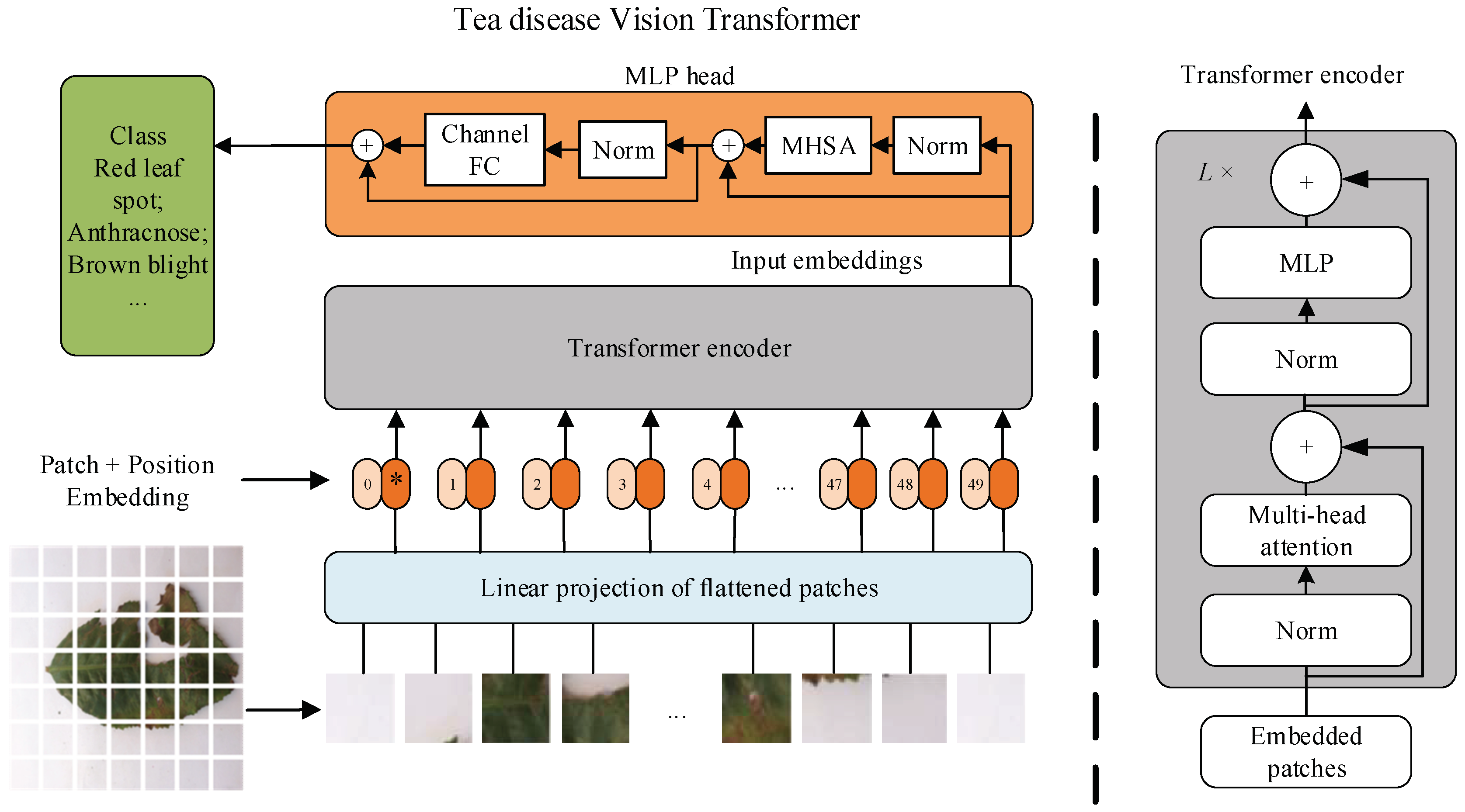{kind=link}
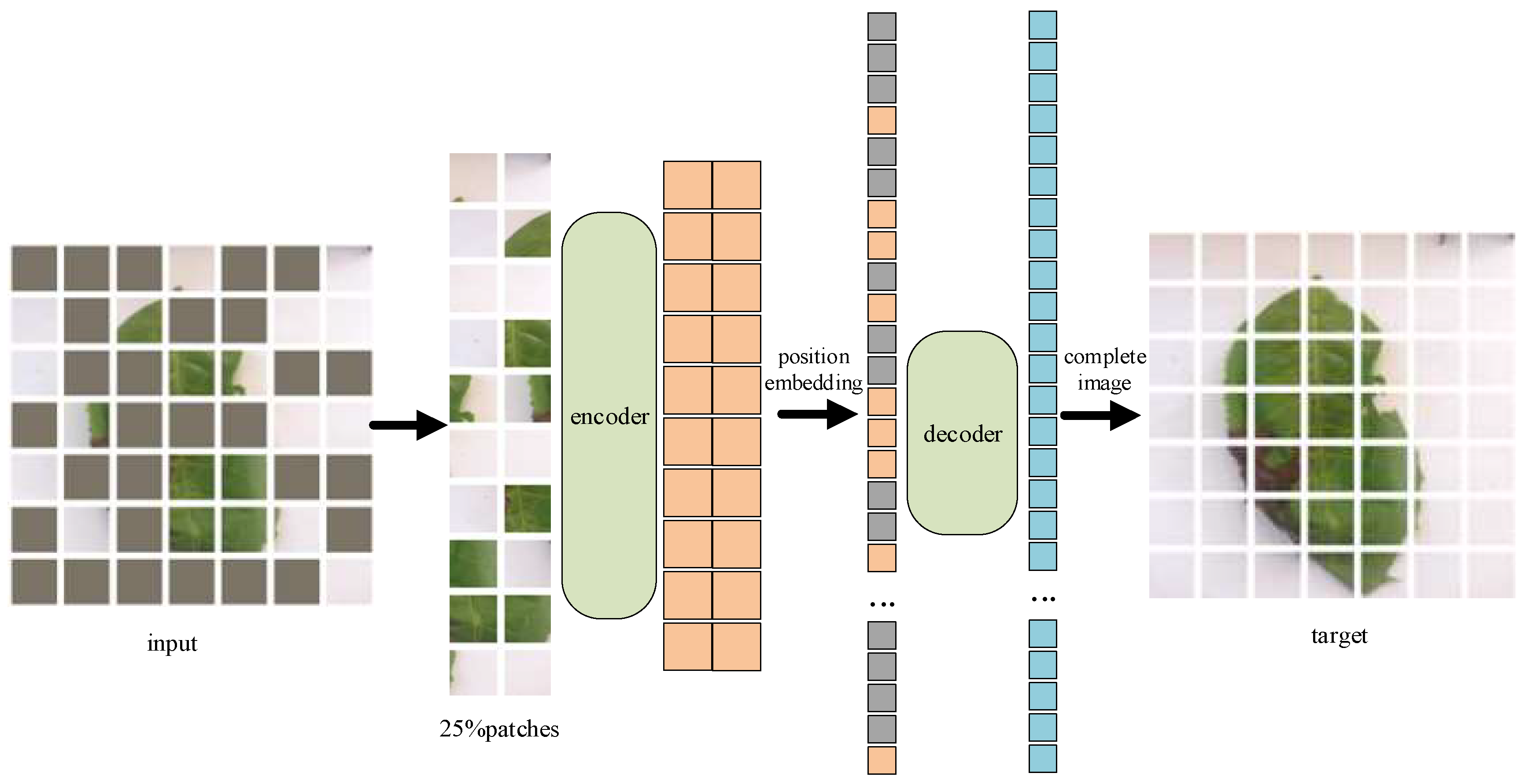{kind=link}
{kind=link}
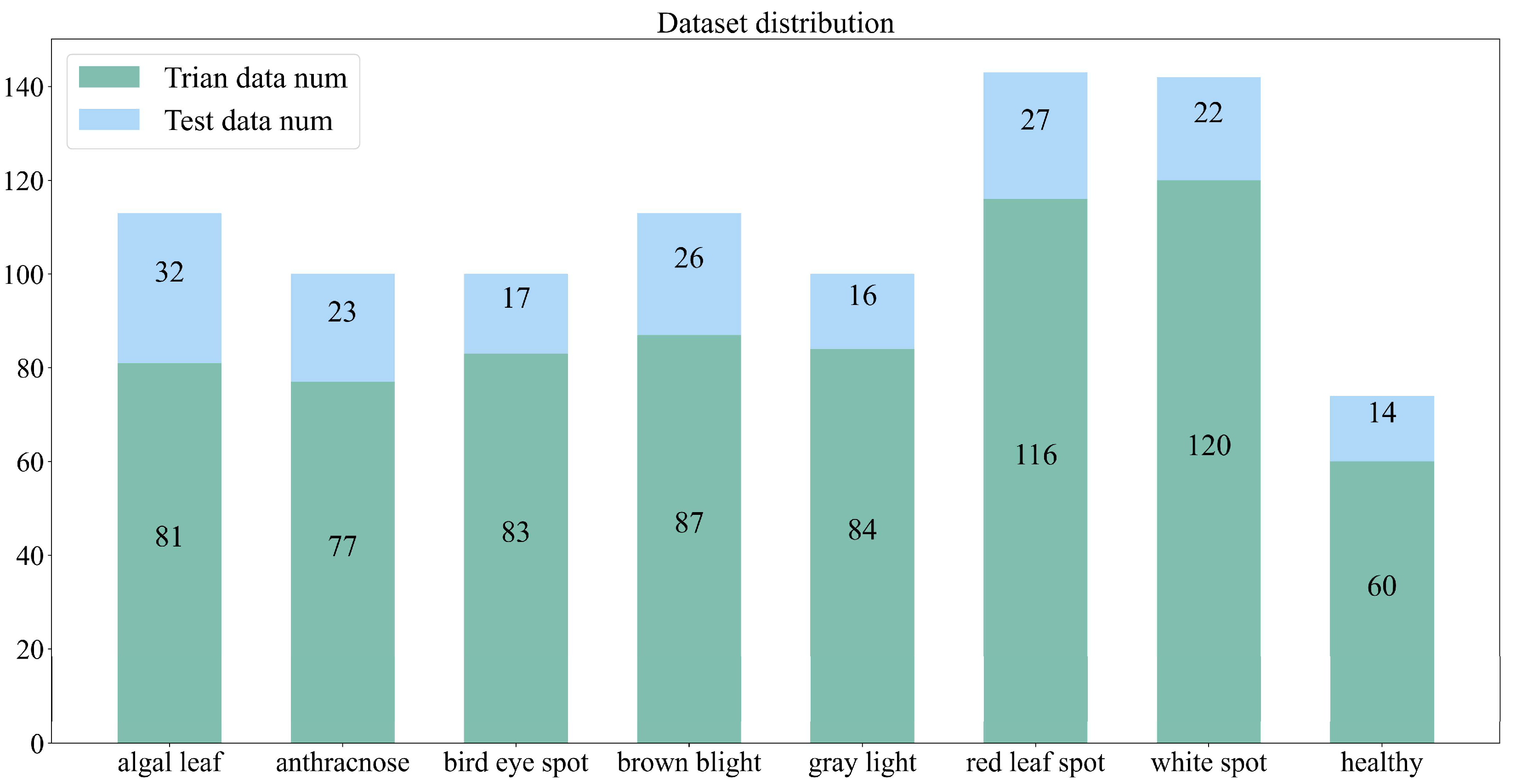{kind=link}
{kind=link}
{kind=link}
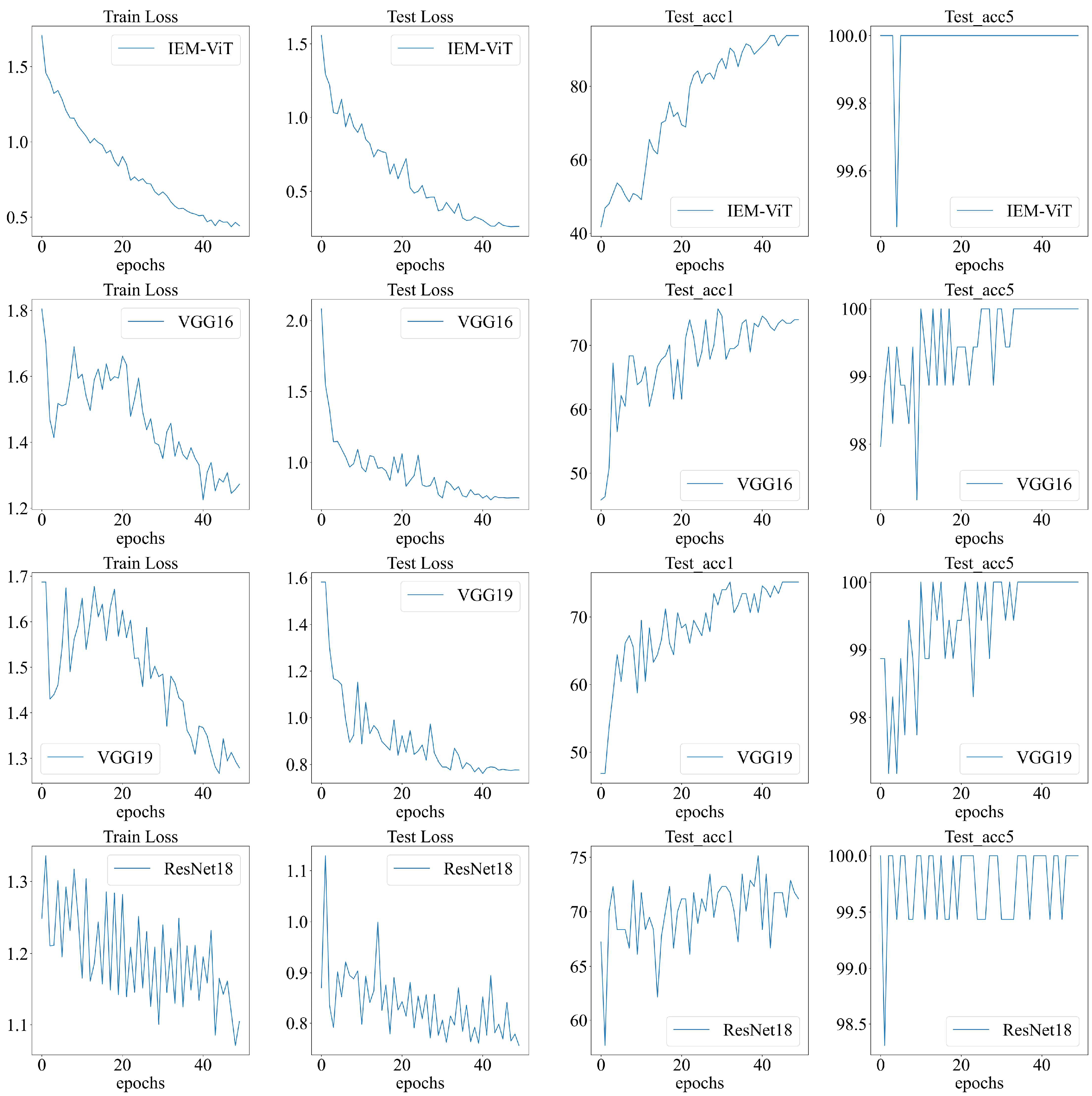{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Description |
|---|---|---|
| Target_size | 224 × 224 × 3 | Size of the image we fed into the model |
| Batch_size | 16 | Number of images in a batch |
| Mask_ratio | 0.75 | Masking ratio |
| Patch_size | 16 × 16 × 3 | Size of the image patch |
| Number_heads | 16 | Number of transformer heads |
| Model | Accuracy (%) | Precision | Recall | Fi-Score |
|---|---|---|---|---|
| IEM-ViT (this work) | 93.78 | 0.9367 | 0.9380 | 0.9364 |
| VGG16 | 73.40 | 0.7850 | 0.7694 | 0.7557 |
| VGG19 | 71.75 | 0.7481 | 0.7429 | 0.7336 |
| ResNet18 | 75.10 | 0.7750 | 0.7748 | 0.7620 |
| Model | Reference | Types Evaluated | Accuracy (%) |
|---|---|---|---|
| Concatenated CNN | Krisnandi et al. [40] | 4 | 89.64 |
| VGG16 | Hu et al. [41] | 3 | 90 |
| LeafNet | Chen et al. [5] | 7 | 90.16 |
| TLDR | Karmokar et al. [42] | 1 | 91 |
| SVM | Hossain et al. [4] | 2 | 91 |
| Improved deep CNN | Hu et al. [43] | 4 | 92.5 |
| IEM-ViT | This paper | 7 | 93.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Guo, H.; Guo, J.; Zhang, J. An Information Entropy Masked Vision Transformer (IEM-ViT) Model for Recognition of Tea Diseases. Agronomy 2023, 13, 1156. https://doi.org/10.3390/agronomy13041156
Zhang J, Guo H, Guo J, Zhang J. An Information Entropy Masked Vision Transformer (IEM-ViT) Model for Recognition of Tea Diseases. Agronomy. 2023; 13(4):1156. https://doi.org/10.3390/agronomy13041156
Chicago/Turabian StyleZhang, Jiahong, Honglie Guo, Jin Guo, and Jing Zhang. 2023. "An Information Entropy Masked Vision Transformer (IEM-ViT) Model for Recognition of Tea Diseases" Agronomy 13, no. 4: 1156. https://doi.org/10.3390/agronomy13041156
APA StyleZhang, J., Guo, H., Guo, J., & Zhang, J. (2023). An Information Entropy Masked Vision Transformer (IEM-ViT) Model for Recognition of Tea Diseases. Agronomy, 13(4), 1156. https://doi.org/10.3390/agronomy13041156