1. Introduction
As a geographical indication protection product of Yunnan,
Gastrodia elata is a type of rare Chinese medicinal material, and it is widely used in the treatment of spasms, vertigo, paralysis, epilepsy, tetanus, asthma, and immune dysfunction [
1]. At present, the market classification of
Gastrodia elata is only performed according to its size, which is a sign of the quality of traditional Chinese medicine and the basis for commodity pricing. In the market, different grades of
Gastrodia elata have large price differentiation and component content differences [
2,
3]. The weight and appearance of
Gastrodia elata are the main factors in market classification, and the classification methods mainly include manual sorting and mechanical sorting. The former relies on experience and manual operation, with strong subjective factors, low sorting efficiency, and high labor intensity, and it often causes misclassification; the latter mainly adopts the way of weighing with a single classification standard. Therefore, it is of great significance to classify different grades of
Gastrodia elata quickly and accurately.
Currently, with the development of computer vision, deep learning has been widely applied in agriculture [
4,
5,
6], medicine [
7,
8,
9], and other fields. Though the classification of
Gastrodia elata takes both weights and shape into consideration, it is only sorted by manual experience or only considering weight, leading to low sorting accuracy and a heavy workload. The application of computer vision technology based on deep learning to the detection and classification of agricultural products, such as fruits [
10,
11], vegetables [
12,
13], and Chinese medicinal materials [
14,
15], provides a reference for the visual classification of
Gastrodia elata.
For instance, Wang et al. [
16] proposed an improved object detection network I-YOLOv4-Tiny based on YOLOv4-Tiny to realize precise and rapid identification of blueberry fruit maturity in the complex natural environment. The convolutional attention module CBAM was added to the neck network FPN. Experimental results indicated that the trained I-YOLOv4-Tiny target detection network achieved an average accuracy of 97.30% on a blueberry data set. By comparing YOLOv4-Tiny, YOLOv4, SSD-MobileNet, and Faster R-CNN object detection networks, the average accuracy can reach 96.24% in complex scenes with unequal occlusion and illumination. The average detection time was 5.723 ms, and the memory occupation was only 24.20 M, which can meet the requirements of blueberry fruit recognition accuracy and velocity. Deng et al. [
17] constructed a lightweight object detection model (CDDNet) to identify carrots for classification, and a carrot classification approach was proposed based on the smallest enclosing rectangle (MBR) fitting and convex polygon approximation. The experimental results showed that the precision of the proposed CDDNet was 99.82% for the two-category classification (normal, flawed) and 93.01% for the four-category classification (normal, bad, abnormal, and fibrous root). The classification precision of MBR fitting and convex polygon approximation were 92.8% and 95.1%, respectively, indicating that the method can detect carrot defects quickly and precisely. Xu et al. [
18] designed an improved YOLOv5 detection network to identify jujube maturity by integrating Stem, RCC, Maxpool, CBS, SPPF, C3, PANet, and CIoU loss networks, which improved the detection accuracy of jujube in complex environments to 88.8% and frames per second (FPS) to 245. The improved network model YOLO-Jujube was proven to be suitable for the identification of jujube maturity. Wang et al. [
19] proposed a maturity detection approach for millet spicy green pepper in a complex orchard environment. Based on the improved YOLOv5s model, the convolutional layer of the cross-phase part (CSP) in the backbone network was replaced by GhostConv, the attention mechanism (CA) module was added, and the path aggregate network (PANet) in the neck network was replaced by the bidirectional feature pyramid network (BiFPN) to improve detection accuracy. The experimental results indicated that the maximum mAP of the modified model was 85.1%, and the minimum model size was 13.8 MB. Li et al. [
20] proposed a modified YOLOX object detection model called YOLOX-EIoU-CBAM, which was applied to identify the maturity category of sweet cherries quickly and accurately in natural environments. The convolutional attention module (CBAM) was added to the model to consider the different maturity characteristics of sweet cherries. Meanwhile, the replacement of the loss function with an Efficient IoU loss makes the regression of the prediction box more precise. The experimental results indicated that compared with the YOLOX model, the mAP, recall rate, and F-score of this method were increased by 4.12%, 4.6%, and 2.34%, respectively, and the model size and single picture extrapolation time were basically the same.
Studies have shown that deep learning can effectively solve difficult object recognition problems in complex environments, attributed to its high robustness and generalization ability [
21,
22]. Particularly, the YOLO model can be improved according to the target characteristics and application scenarios to improve the model performance. Therefore, it is necessary to realize efficient and accurate sorting of different grades of
Gastrodia elata by the deep learning model, which is of great practical significance for promoting the development of the whole
Gastrodia elata industry.
At present, major target detection algorithms conduct target detection of large sample sizes and multiple categories, and their network structure may not be suitable for all projects. Two-stage detection algorithms [
23,
24] require a large amount of computation, which is difficult to meet the requirement of real-time detection in an ordinary hardware environment. The one-stage detection algorithm [
25] has a fast detection speed and can realize real-time detection, but its detection accuracy is slightly lower than that of two-stage detection algorithms. The most classic algorithm in this category is YOLO (You only look once) series [
26], among which the YOLOX target detection algorithm is a relatively new and widely used target detection algorithm at present [
27]. However, due to its complex network structure, it requires high computing power when applied to devices. To achieve real-time detection and classification of
Gastrodia elata in complex environments, it is crucial to improve the model to reduce the number of parameters, improve the model accuracy, and keep the model size small.
To date, no research has conducted research on
Gastrodia elata grade detection model based on deep learning and computer vision. To meet the requirements of rapid and accurate detection of different grades of
Gastrodia elata, a YOLOX-based target detection algorithm I-YOLOX for different grades of
Gastrodia elata was proposed in this study. To enhance the feature expression and improve the detection performance of
Gastrodia elata grade, the ECA attention mechanism module [
28] was introduced into the transmission process of the feature layer between the backbone network and the neck enhancement feature extraction network in the YOLOX model, and the improvement effect of different attention mechanisms on the network was compared. In the neck enhancement feature extraction network FPN [
29] and the head network, depthwise separable convolution was replaced to reduce the calculation of model parameters, and the improvement effects of different replacement positions were analyzed. The EIoU loss function [
30] was used to improve the model convergence effect and make the prediction box regression more precise. Finally, the feasibility and reliability of the proposed method were validated on the
Gastrodia elata data set.
By establishing the improved YOLOX target detection model of different grades of Gastrodia elata, the problem of grade discrimination relying on manual experience and low recognition efficiency was solved, which provided the foundation for the construction of the sorting system of Gastrodia elata later.
The subsequent sections are structured as follows:
Section 2 introduces the establishment of the
Gastrodia elata image data set and the detailed content of the I-YOLOX classification detection algorithm proposed in this study.
Section 3 evaluates the performance of the I-YOLOX network through experiments.
Section 4 summarizes the work of this study and points out the shortcomings and prospects of this study.
2. Materials and Methods
In order to identify different grades of Gastrodia elata quickly and effectively, the image data set of Gastrodia elata was established, and the network model was improved by different methods. An improved YOLOX target detection algorithm for different grades of Gastrodia elata was proposed, which improved the detection effect of Gastrodia elata.
2.1. Image Data Acquisition of Gastrodia elata
The images of different grades of Gastrodia elata were taken and collected, and the image data set of Gastrodia elata was established by image screening and enhancement.
2.1.1. Test Materials
Yunnan is one of the origins of
Gastrodia elata, and Yiliang County, Zhaotong City, is the representative and main producing area of Yunnan Xiaocaoba
Gastrodia elata. Different grades of Gastrodia have a large price difference. In this study, Xiaocaoba
Gastrodia elata was taken as the research object, and data collection was conducted in Xiaocaoba Changtong
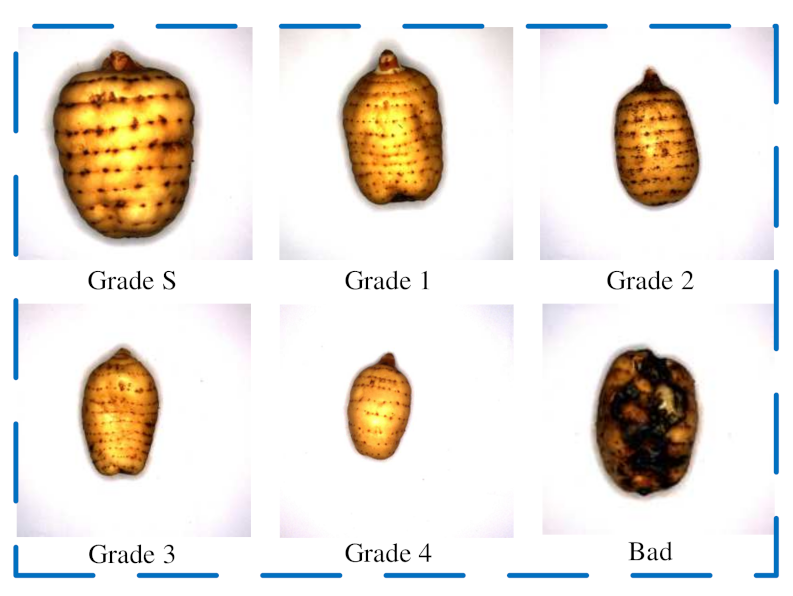
Gastrodia elata Cooperative. After measuring and weighing each Gastrodia, more than 200
Gastrodia elata of each grade were selected to collect image information, including Grade S, Grade 1, Grade 2, Grade 3, Grade 4, and Bad Grade. The six grades of
Gastrodia elata are shown in
Figure 1.
2.1.2. Grading Standards of Gastrodia elata
According to the local standard of
Gastrodia elata of Yunnan Province (DB53T1077-2021), fresh
Gastrodia elata was divided into five grades: Grade S, Grade 1, Grade 2, Grade 3, and Grade 4. In the process of growth, digging, and storage of fresh
Gastrodia elata, there are Bad
Gastrodia elata, such as mildew, moths, skin damage, etc. In this paper, to better study the classification of fresh
Gastrodia elata, Bad
Gastrodia elata is added to the above five grades as one grade, and there are six grades in total. The grading specifications of fresh
Gastrodia elata are listed in
Table 1.
2.1.3. Data Collection
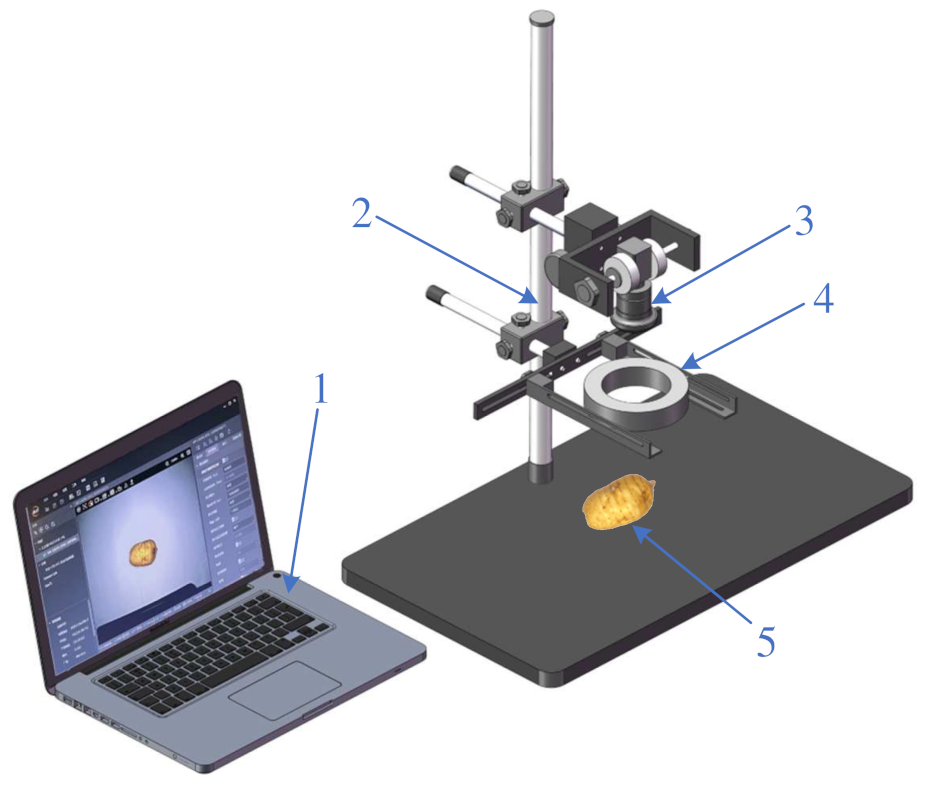
In this study, the Hikvision industrial camera (MV-CA050-20GC, 5 million pixels, CMOS Gigabit Ethernet industrial array camera, resolution of 2592 × 2048, Hikvision, Hikvision) was used for image acquisition. The camera was set up with an adjustable bracket, and the camera was fixed 25 cm away from the horizontal plane to take pictures. The model of the light source is JL-HAR-110W, the power is 5.9 W, and the installation height is 25 cm away from the horizontal plane. Material surface brightness is about 2.3 × 104 Lux. All images were captured under the same camera height, the same white background plate, and the same light source brightness.
As shown in
Figure 2, industrial cameras were used in this study to take images of
Gastrodia elata of six grades, namely, Grade S, Grade 1, Grade 2, Grade 3, Grade 4, and Bad
Gastrodia elata, with more than 200
Gastrodia elata in each grade. A total of 800 images of each grade were collected, and a total of 4800 images were saved in the .jpg format.
2.2. Image Data Screening, Enhancement, and Dataset Establishment
The main purpose of this study is to improve the classification recognition accuracy of
Gastrodia elata. First, the collected image data were screened, and the images that were not suitable for the detection algorithm caused by damaged image data files and image blurring caused by external factors in the collection process were screened. As shown in
Table 2, more than 800 original images of each grade of
Gastrodia elata were collected. After screening, 800 images of each grade of
Gastrodia elata were retained, and a total of 4800 images of six grades were collected. Then, the images of each grade in the data set saved after screening were enhanced.
There was only a single
Gastrodia elata in each image collected, and there were no other types of targets. Therefore, Mosaic and MixUp data enhancement strategies for YOLOX were not adopted in this study because they have good effects for detecting multi-target and multi-type images. For the
Gastrodia elata dataset in this study, it is more suitable for random processing of the original image data through flipping, translation, rotation, changing brightness, and adding noise, thus expanding the number of images, enhancing the diversity of image information and samples, and avoiding overfitting in the training process. The image after the sample image enhancement is shown in
Figure 3.
In this paper, by image enhancement, the images of each grade of
Gastrodia elata were expanded at an equal ratio, the dataset was expanded to 9600, and the training set, verification set, and test set were divided at a ratio of 8:1:1. The sample quantity of the
Gastrodia elata dataset is presented in
Table 2. Additionally, LableImg software version 1.8.1 was used to annotate the image dataset, and XML files containing the dataset name, center point (
,
) coordinate information, label name, and other information were obtained. Then, the XML files were converted into annotation files in the txt format required by the YOLO training model through Python programming. In this way, the image dataset of
Gastrodia elata was established.
2.3. Improved YOLOX Gastrodia Classification Recognition Model
By introducing the ECA attention mechanism, replacing the depthwise separable convolution, and using the EIoU position regression function calculation to improve the original YOLOX network structure, an improved YOLOX Gastrodia elata classification recognition model was established.
2.3.1. I-YOLOX Network
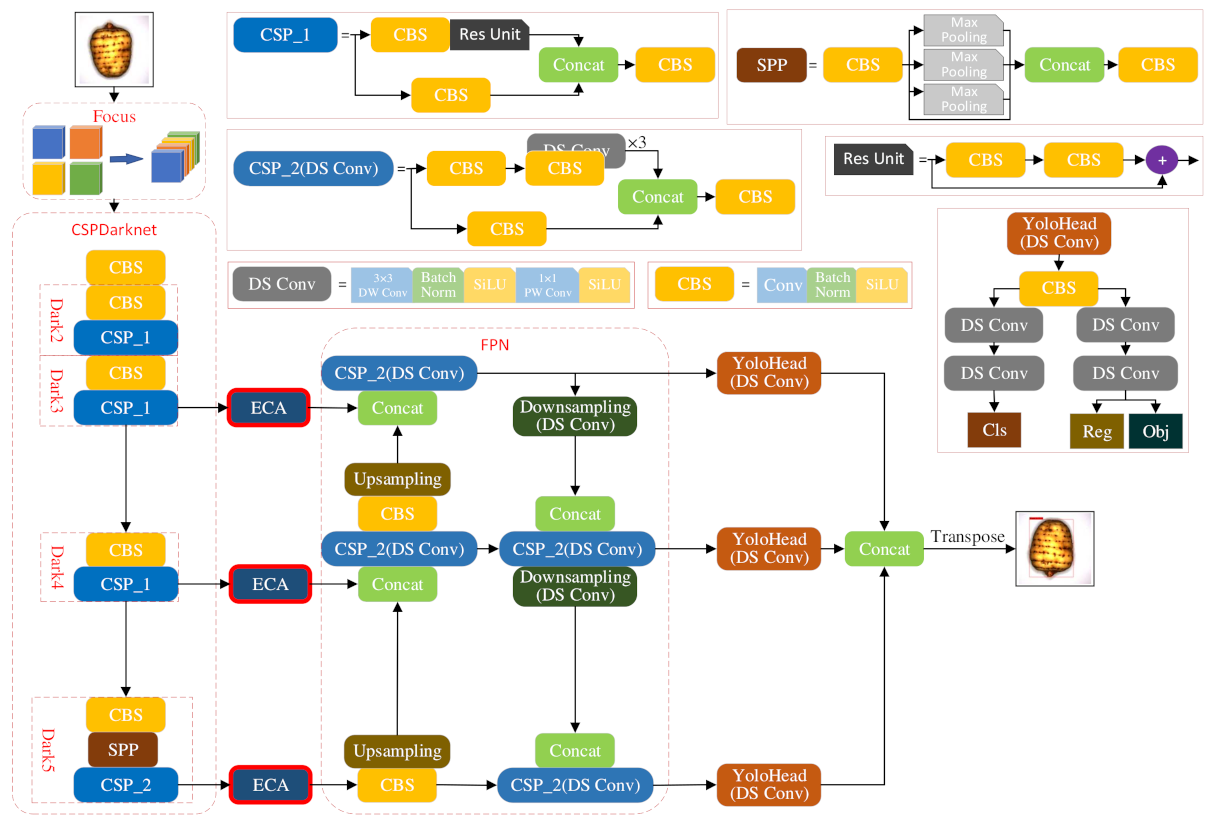
At present, the main target detection algorithm network structure is diverse and complex, with different applicability. YOLOX, as one of the most advanced real-time object detection algorithms, has the advantages of high detection precision and flexible deployment. Considering the problems of model deployment and cost control, the YOLOXs target detection network is selected as the basic network model in this paper to reduce model storage occupation and improve the identification speed.
The network structure of YOLOX consists of four parts: the input terminal, the backbone feature extraction network, the enhanced feature extraction network, and the head prediction network. Specifically, the input terminal performs data enhancement and adaptive image scaling for the input image. The backbone feature extraction network adopts residual convolution operation to extract feature maps at different levels [
31] and adopts the CSPDarknet53 structure for the main part. Then, the extracted features are fused by jumping connections, which alleviates the problem of gradient disappearance caused by adding depth in the deep learning network, reduces parameter redundancy, and improves model accuracy. In the network structure, the feature pyramid network structure is used to enhance the semantic features from top to bottom, and the path aggregation network structure is used to enhance the positioning features from bottom to top. Then, feature fusion is performed by combining the information of different scales to achieve a better feature extraction effect. The head prediction network forgoes the coupled head method of the YOLO series and uses the decoupled head as the detection head to support two branches, classification and regression, where the former obtains category information, and the latter obtains detection frame information and confidence information. Finally, the information is integrated into the prediction stage. After decoupling, different branches of the detection head have independent parameters, so directional reverse optimization can be performed according to the loss function to accelerate the convergence speed and improve the precision of the model.
YOLOX re-adopted the idea of Anchor free. Instead of using clustering algorithm to obtain prior boxes, it used simOTA to flexibly match positive samples for objects of different sizes. This method solves the problems that anchor-based detection method requires artificial design of Anchor frames and a large number of anchor frames in the training process cause huge computation. Since the shapes and sizes of different grades of Gastrodia elata vary, the model detection box needs to adapt to the target detection of various scales of Gastrodia elata. Therefore, simOTA positive and negative samples in YOLOX target detection algorithm are more suitable for hierarchical detection of different grades of Gastrodia elata. The data enhancement strategy enhanced the image information and sample diversity and improved the generalization ability of target detection model of Gastrodia elata.
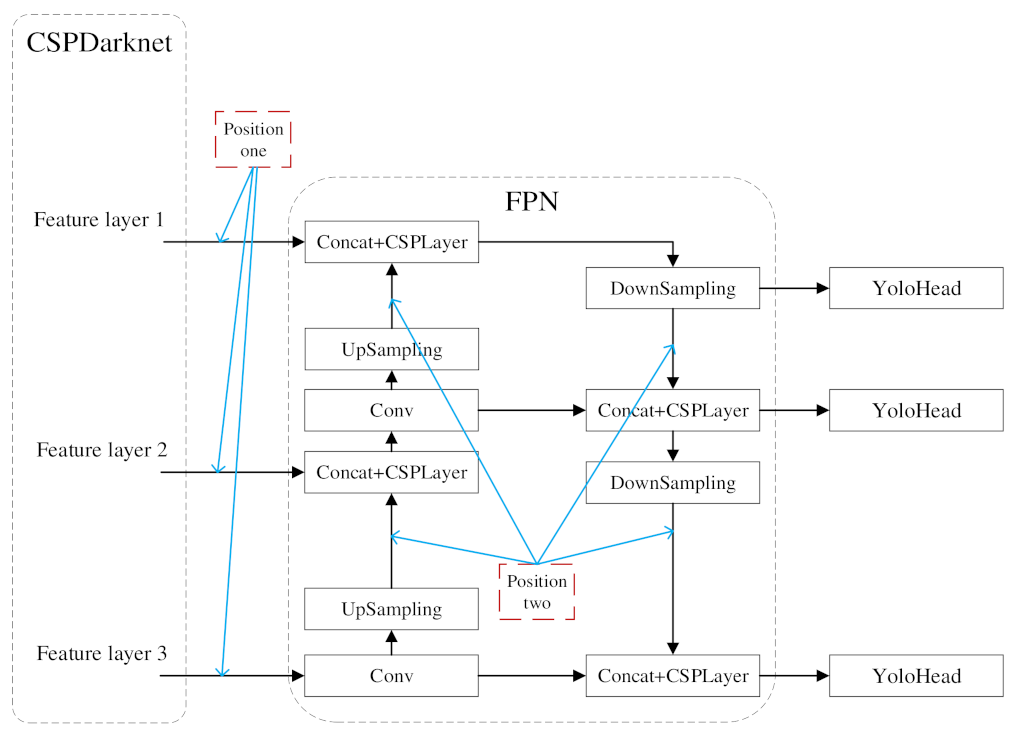
In this study, only the classification of
Gastrodia elata was involved. To enhance the feature expression and improve the detection performance of
Gastrodia elata grade, as shown in
Figure 4, the following improvements were made to YOLOX: the ECA attention mechanism module is added to the basic YOLOX network to enhance image feature extraction; in the YOLOX FPN network and head network, depthwise separable convolution is used instead of normal convolution to further reduce the number model parameters. EIoU loss is used to replace the boundary box loss function in the original YOLOX model to make the regression of the prediction frame more precise.
2.3.2. The Network Structure Improvement of the ECA Attention Mechanism
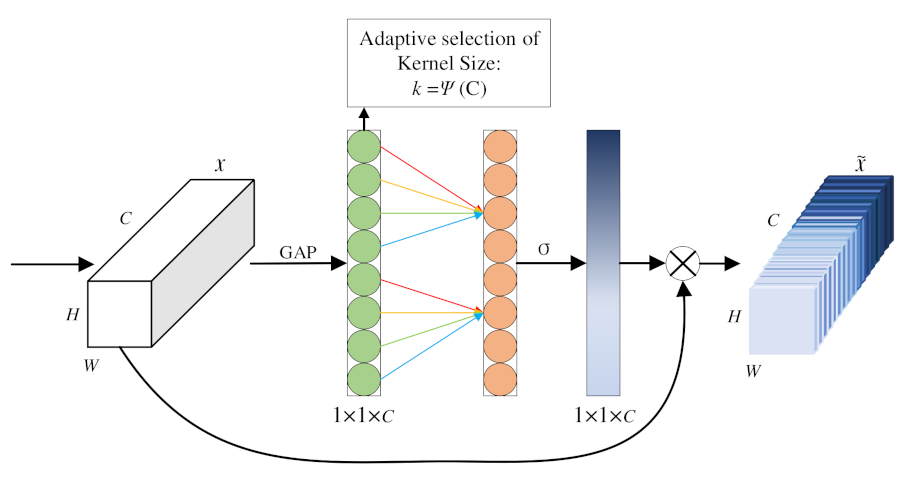
The attention mechanism imitates the biological vision mechanism. By rapidly scanning the global image, the regions of interest can be selected, more attention resources can be invested, and other useless information can be suppressed, thus improving the efficiency and accuracy of visual information processing.
The ECA attention mechanism module is a channel attention module, which is commonly used in visual detection models. It can enhance the channel feature of the input feature graph, eliminate the full connection layer, avoid dimension reduction, and capture cross-channel interactions effectively. The final output of the ECA module does not change the size of the input characteristic pattern. It can be regarded as an improved version of the SE attention module: it solves the problem that dimension reduction in the SE attention module brings side effects to the channel attention mechanism, and captures the dependency between all channels has low efficiency.
As shown in
Figure 5, the ECA module performs global averaging pooling on input feature graphs, making the feature graphs change from a matrix of size [H,W,C] to a vector of size [1,1,C]. After the global averaging pooling layer, one-dimensional 1 × 1 convolution is used to obtain a cross-channel mutual information. The size of the convolution kernel is adjusted by an adaptive function, which allows layers with a larger number of channels to interact more across channels. The adaptive function is represented below:
where,
= 2 and
= 1.
The adaptive function is applied to one-dimensional 1 × 1 convolution to obtain the weight of each channel of the characteristic pattern. Finally, the normalized weight is multiplied by the initial input characteristic pattern channel by channel to generate the weighted characteristic pattern with channel attention.
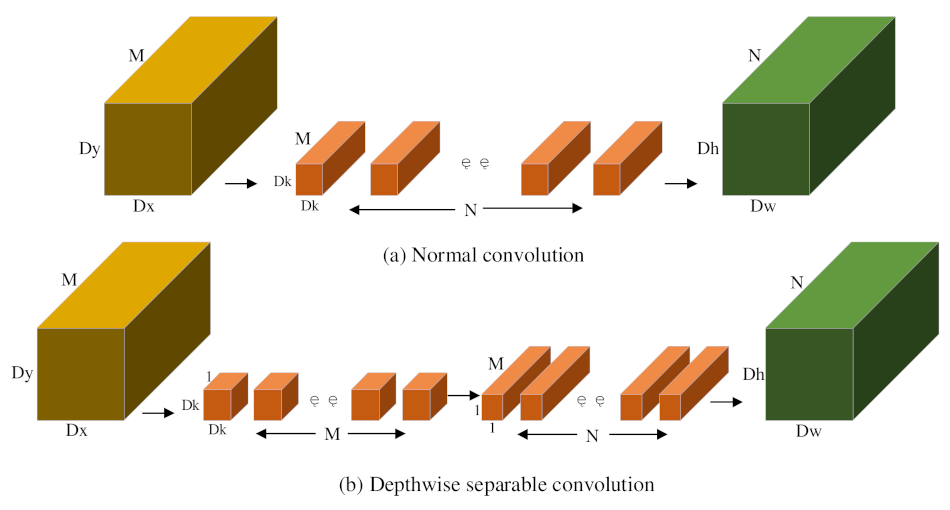
2.3.3. Structure Improvement of the Feature Fusion Network Based on Depthwise Separable Convolution
The depthwise separable convolution is composed of depthwise (DW) convolution and pointwise (PW) convolution. Similar to normal convolution, this configuration can be used to extract characteristics, but it has a smaller parameter number and lower work cost than normal convolution. The common convolution in YOLOX's enhanced feature extraction network FPN and the head network was replaced by depthwise separable convolution to further compress the model and improve its computational efficiency.
As shown in
Figure 6, normal convolution is to perform convolution operation on the input characteristic pattern and the corresponding convolution kernel of each channel, then add them to output features. The calculation amount
is:
where
represents the size of the convolution kernel; M and N represent the number of channels of input and output data, respectively; and
and
represent the width and length of output data, respectively.
Depthwise separable convolution changes the one-step operation of ordinary convolution into 3 × 3 depthwise convolution and 1 × 1 pointwise convolution, and its calculation amount
is:
Therefore, the arithmetical ratio of depth-wise separable convolution to normal convolution is:
Generally, is set to 3, and the network computation amount and parameter number are reduced by about 1/3 after replacing normal convolution with depthwise separable convolution.
The lightweight improvement of the network structure can greatly reduce the parameter number and calculation amount of the model; however, it will cause a loss of detection accuracy. Therefore, it is necessary to further optimize the model to improve the detection precision of the model.
2.3.4. Adopting the EIoU Position Regression Loss Function
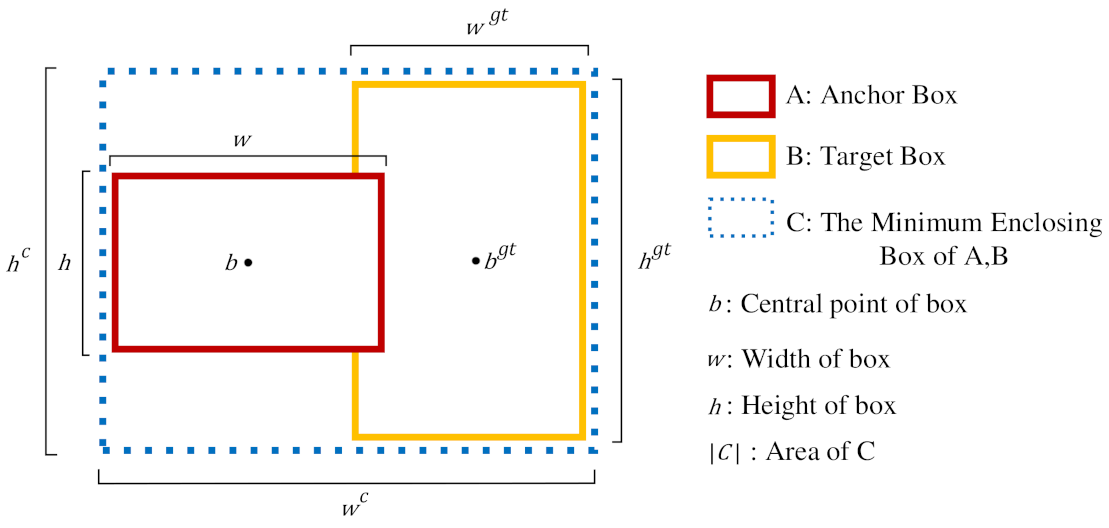
The EIoU loss consists of three parts: IoU loss, distance loss, and height-width loss (overlapping area, center distance, and height-width ratio). The height-width loss directly minimizes the difference between the height and width of the predicted object boundary box and the real boundary box to achieve a faster convergence rate and better positioning results.
As shown in
Figure 7, the calculation formula for the EIoU loss is as follows:
where
and
are the width and height of the minimum enclosing rectangle of the predicted boundary box and the real boundary box, respectively.
is the Euclidean distance between two points.
EIoU loss is an improvement of the CIoU loss. Based on CIoU, the aspect ratio is disassembled, and the loss item of the aspect ratio is divided into the difference between the width and height of the predicted frame and the width and height of the real minimum external frame, which improves the convergence effect and the regression precision. Meanwhile, by adding focal focusing high-quality anchor frames, the sample imbalance problem in the boundary box regression task is resolved, i.e., the contribution of many anchor frames with little registration with the object frame to the optimization of B Box regression is reduced, making the course of regression centered on superior anchor frames.
2.4. Transfer Learning
Since there is no public Gastrodia elata data set, there are few research on visual classification of Gastrodia elata at home and abroad. In order to expedite model training and improve model generalization, this study loaded the pre-training parameters of the model in VOC2012 data sets based on the think of transfer learning. During the training, the front-end pre-training weight network layer should be frozen first, and only the back-end network should be retrained, and the parameters updated. After thawing this part of the training layer, the weight can be effectively retained.
2.5. Test Environment and Parameter Setting
All tests in this paper were completed in the laboratory workstation; the workstation model is DELL-P2419H. Hardware configuration: The CPU processor is Inter Core i7-9700F CPU @ 3.70 GHz, the CPU processor core is 16, the multi-threading is 32, the running memory is 64 GB, the GPU processor is Quadro P5000, 16 G video memory, 2560 CUDA cores, and the operating system is Windows 10. Pytorch1.3.2 deep learning environment of GPU version, compiled by Python3.8 version and CUDA11.0 version. All model training and testing are worked in the same hardware environment.
The image input size is 640 × 640. The model optimizer selected SGD, and the learning rate was set to 0.01. The total number of iterations is set to 300. In the first 50 rounds of training, the network trunk was frozen, the batch size was set to 32 times, and only the later network layers were trained. In the last 250 rounds, the batch size was set to 16 times, and the thread was set to 8.
2.6. Model Evaluation Index
In this paper, precision rate (
), recall rate (
), harmonic mean (
), Average Precision (
), and Mean Average Precision (
) were used to evaluate the detection precision of the proposed
Gastrodia elata grade detection model and the lightweight degree of the model and the number of frames per second (FPS) were used to judge the real-time capability of the model. The calculation formulas of
,
,
,
, and
are shown in Equations (6)–(10).
where TP, FP, and FN represent the number of true cases, false positive cases, and false negative cases, respectively; true cases represent the actual positive cases that are divided into positive cases by model classification; false positive cases represent the actual negative cases that are divided into positive cases by model classification; false negative cases represent the actual positive cases that are divided into negative cases by model classification; and
C is the number of detection categories. This study needs to identify the Grade S, Grade 1, Grade 2, Grade 3, Grade 4, and Bad
Gastrodia elata, i.e.,
C = 6.
4. Conclusions
At present, there are few studies on the visual classification of Gastrodia elata. To fill this research gap and provide technical support for the classification of Gastrodia elata, this paper collected and established the Gastrodia elata image dataset and improved the detection accuracy and efficiency of different grades of Gastrodia elata by improving the deep learning network model.
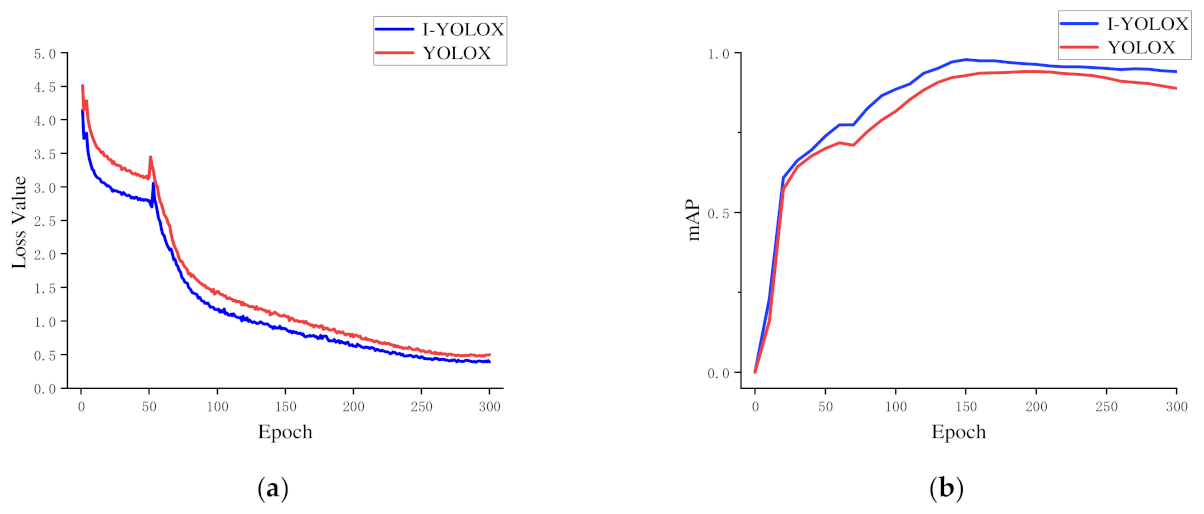
In this study, an improved YOLOX network target detection model called I-YOLOX was proposed for the recognition and detection of different grades of Gastrodia elata. By analyzing the influence of model improvement and transfer learning on the model performance, the conclusions are as follows.
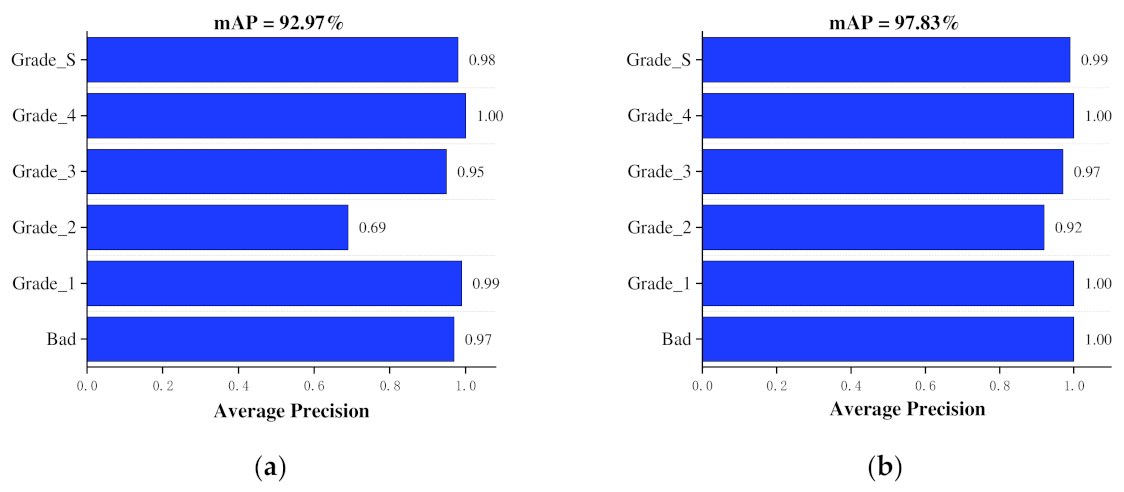
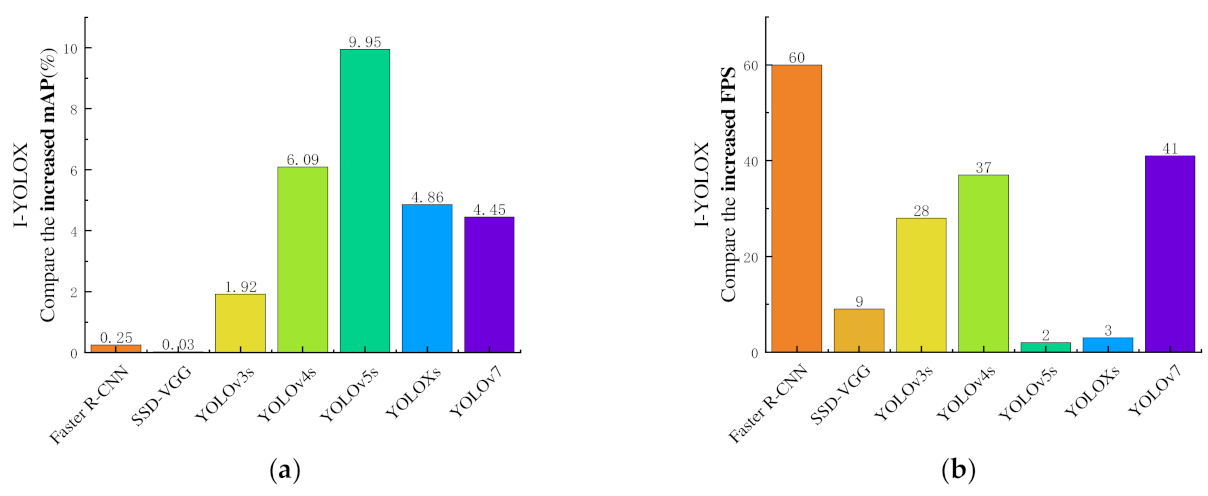
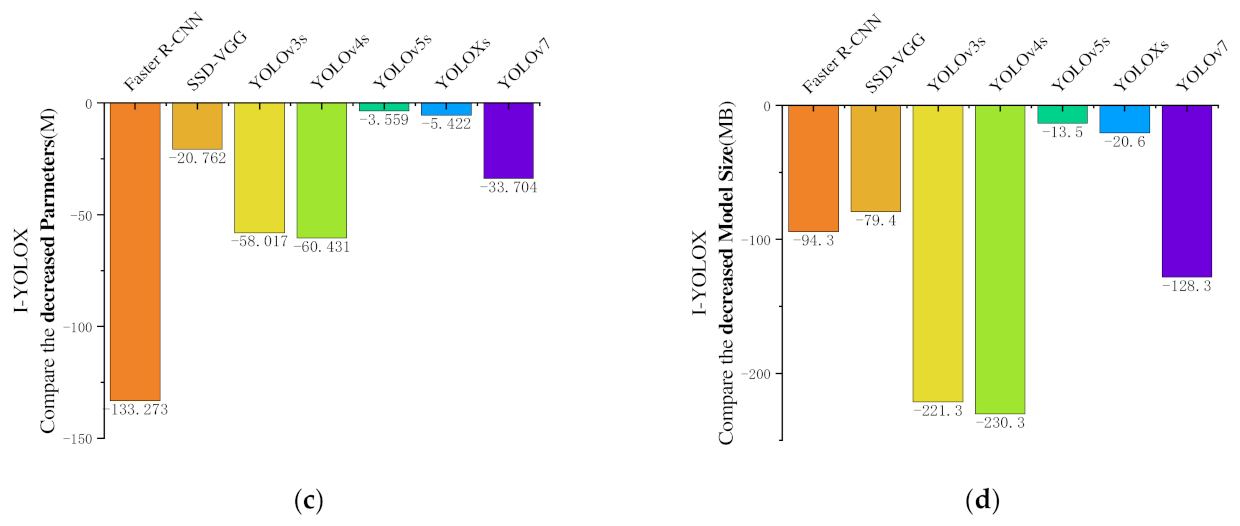
By adding the ECA attention mechanism module between the backbone network and the neck network to enhance feature extraction of image information and improve model characterization ability, depthwise separable convolution was used to replace normal convolution in the FPN network and the head network to reduce the number of parameters and model size, and a better EIoU loss function was adopted. The model can obtain faster convergence speed and better prediction frame regression accuracy. Meanwhile, the modeling effects of different attention mechanisms, improved positions, improved modules, and different typical target detection networks were explored on the Gastrodia elata dataset. The results indicate that compared with the original YOLOX model, the mAP of the improved I-YOLOX model increased by 4.86%, the number of parameters was reduced by 5.422 M, the FPS per increased by 3, and the model size was reduced by 20.6 MB. It shows that the improvement enhanced the detection precision and speed while reducing the calculation amount.
In this study, an improved Gastrodia elata grade detection model called I-YOLOX was proposed to identify and detect the six grades of Gastrodia elata, which was improved from the aspects of detection accuracy, model complexity, detection speed, etc. This study provides a reference for the deployment and application of the model in the complex environment of Gastrodia elata sorting devices in the later stage and extends the use of deep learning models in other fields of Chinese medicinal materials. It promotes the development of the Gastrodia elata sorting standards and processing industry and lays a theoretical foundation for the subsequent establishment of automatic Gastrodia elata sorting systems.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}