
Construction and Validation of Peanut Leaf Spot Disease Prediction Model Based on Long Time Series Data and Deep Learning




Abstract
:1. Introduction
2. Materials and Methods
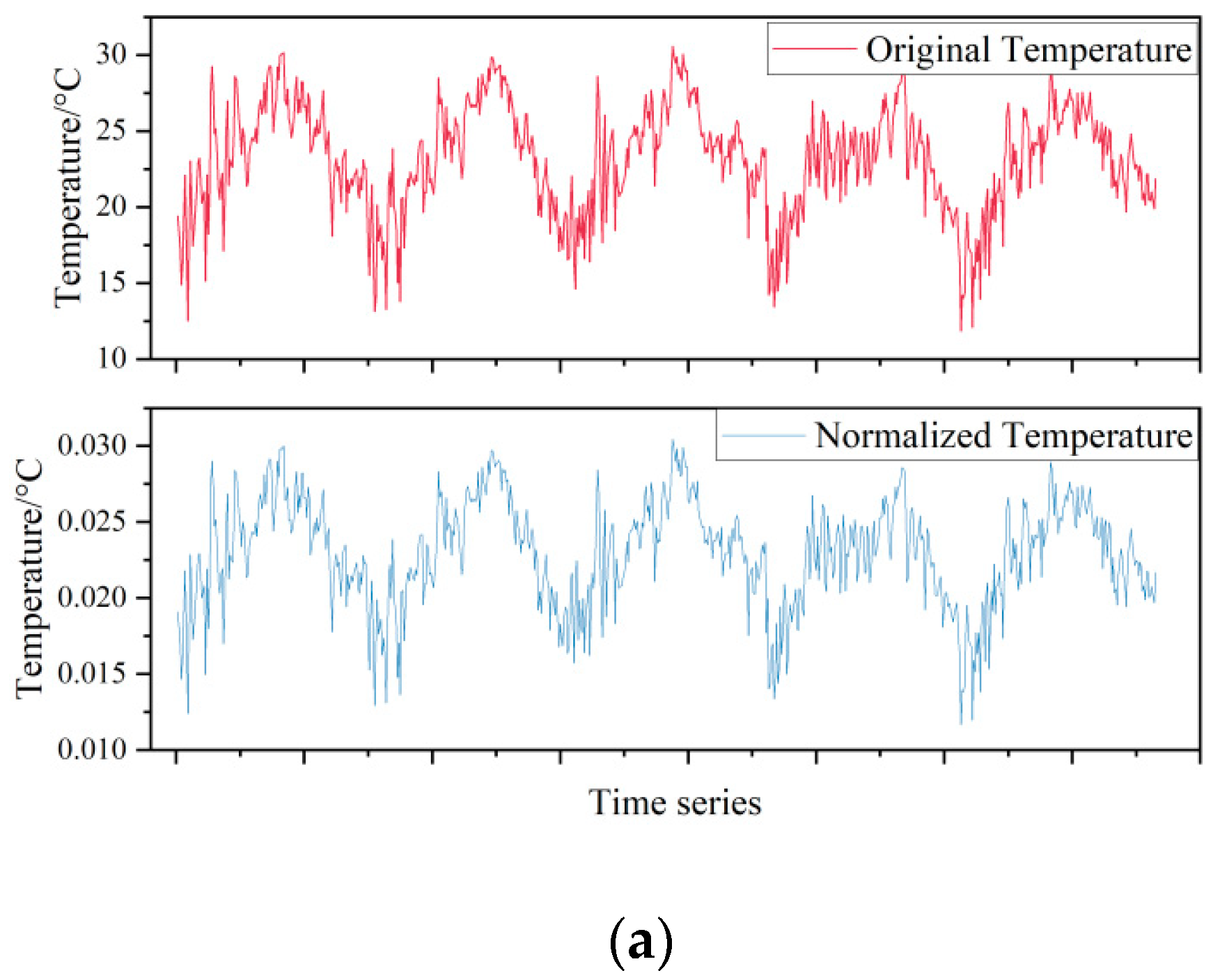
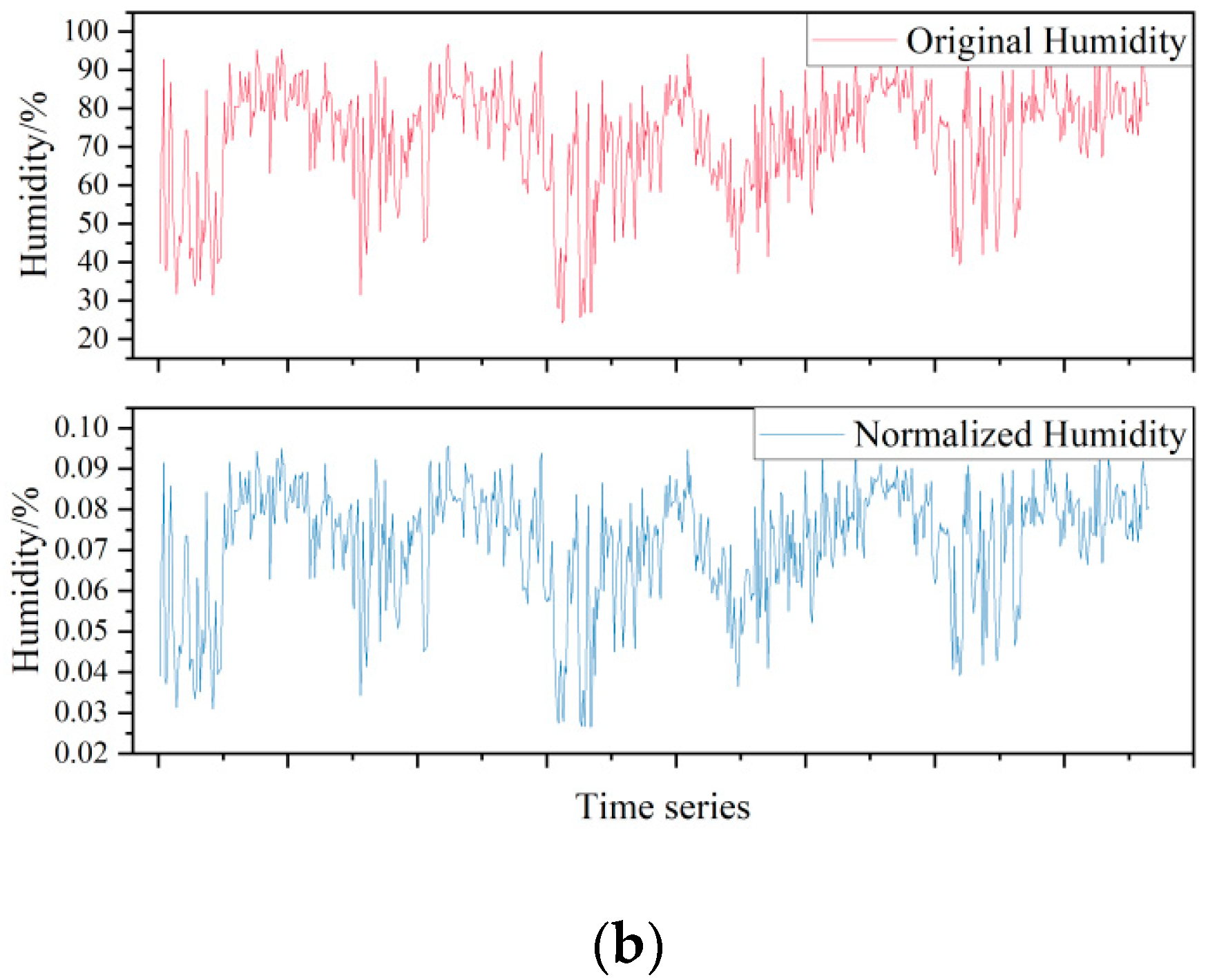
2.1. Data Acquisition and Normalization
2.2. Disease Survey
2.3. Model Building
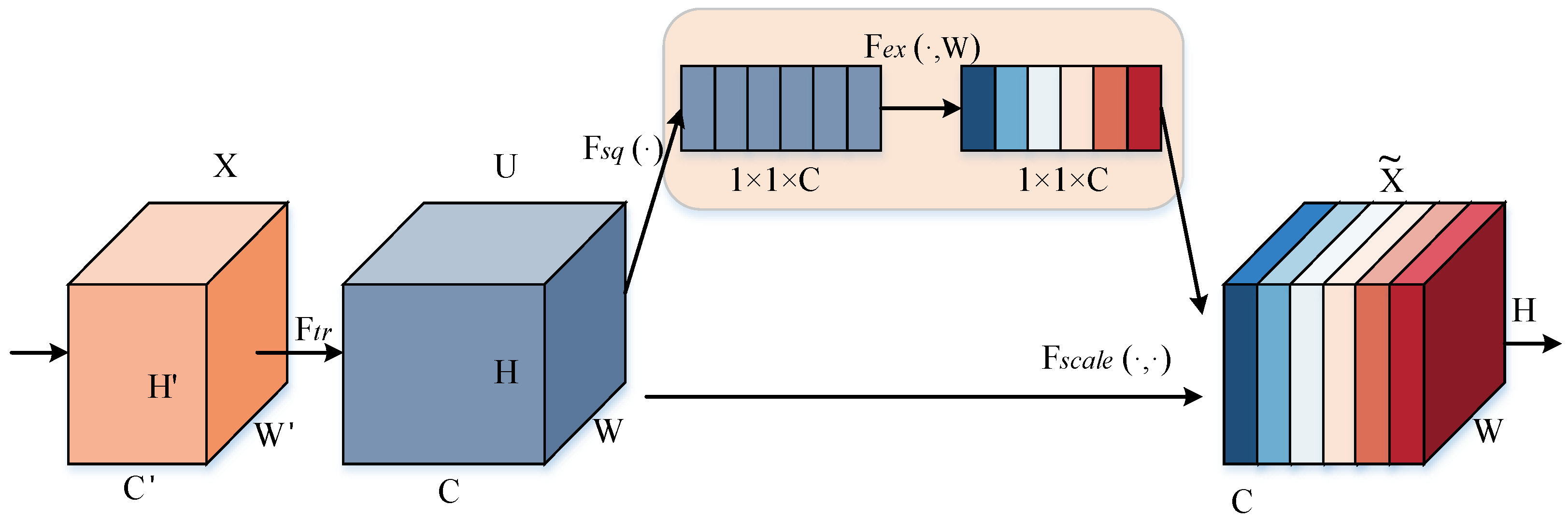
2.3.1. Feature Processing Module
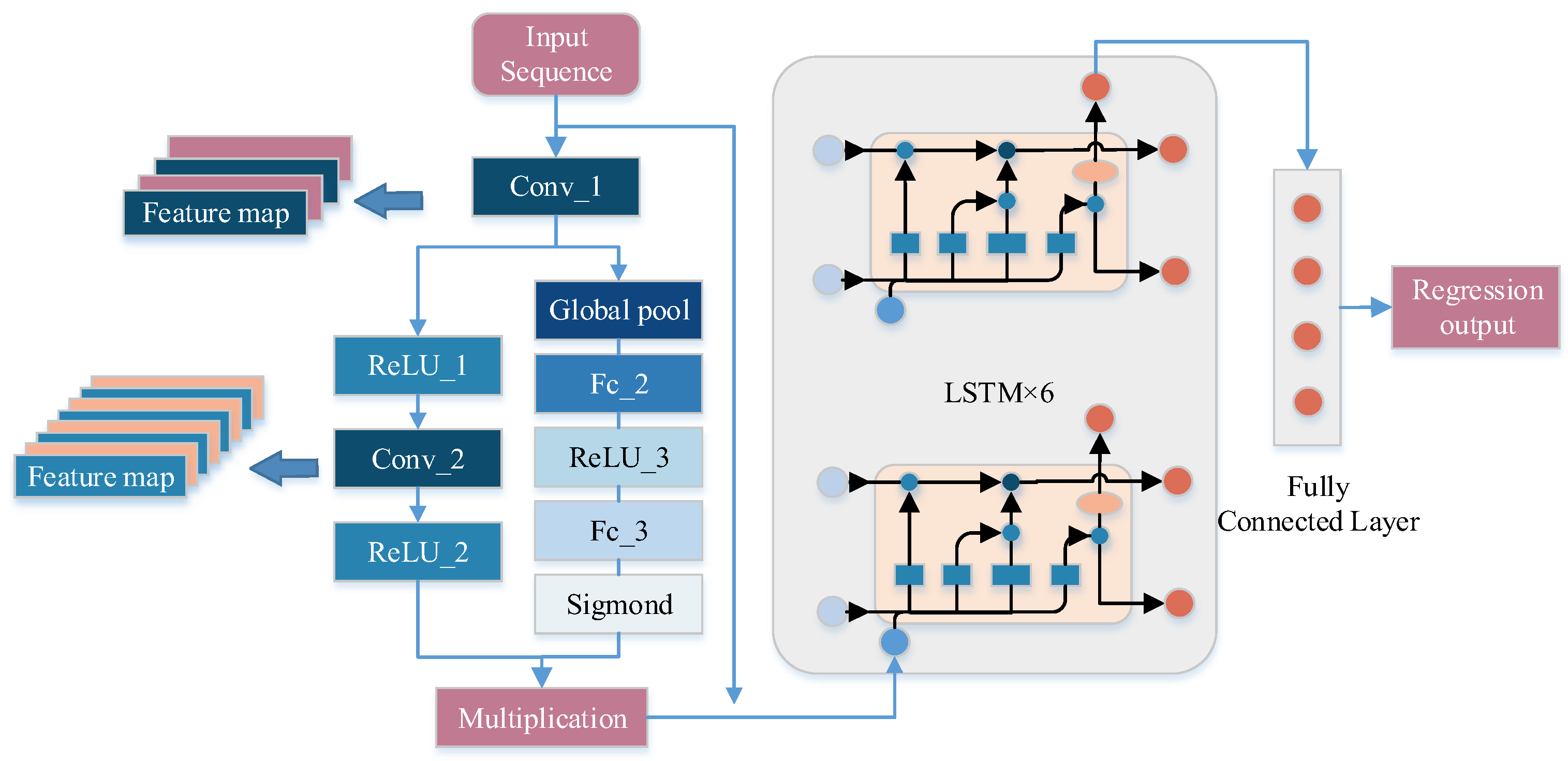
2.3.2. The Proposed Model
2.4. Evaluation Metrics
3. Results
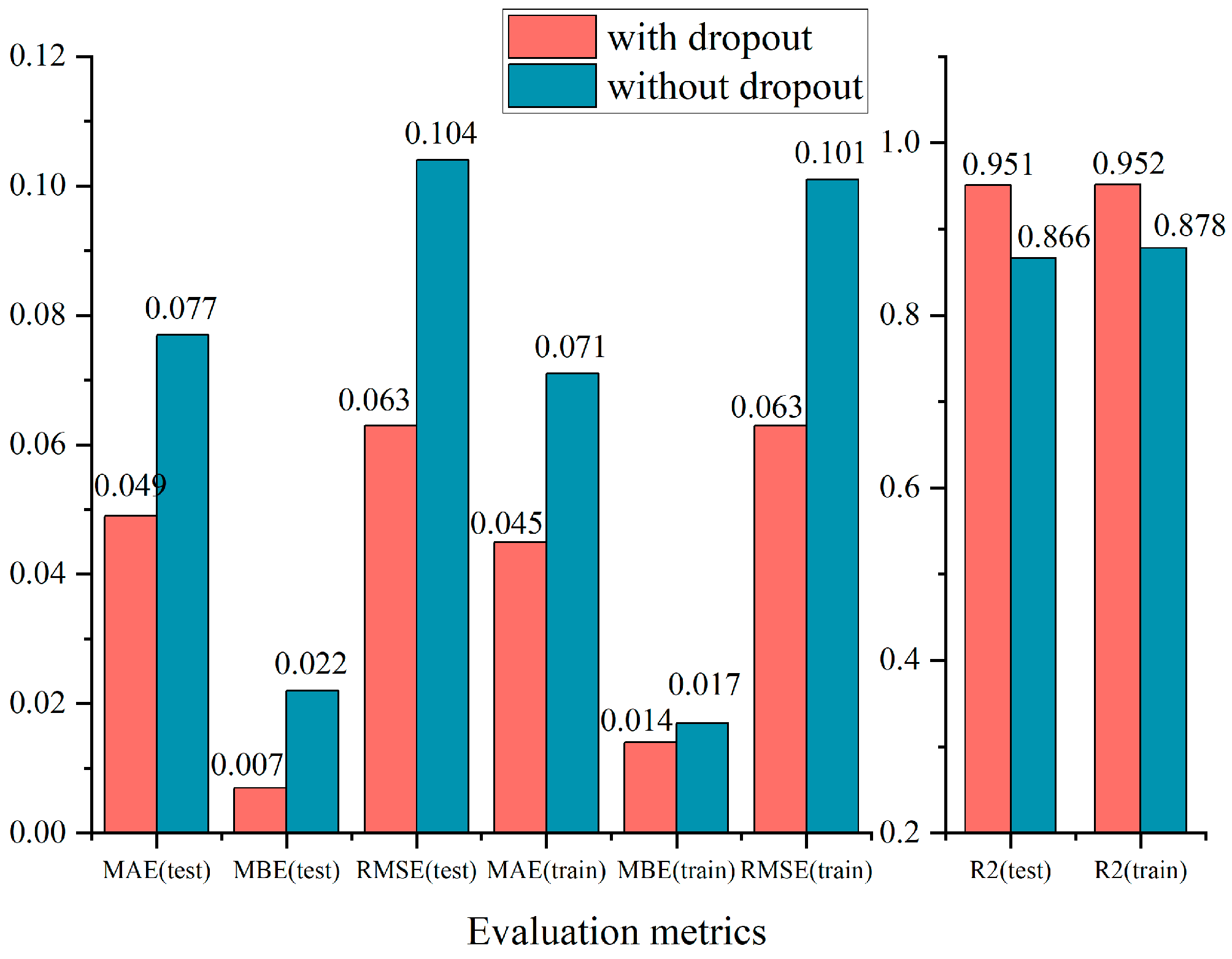
3.1. Model Optimization
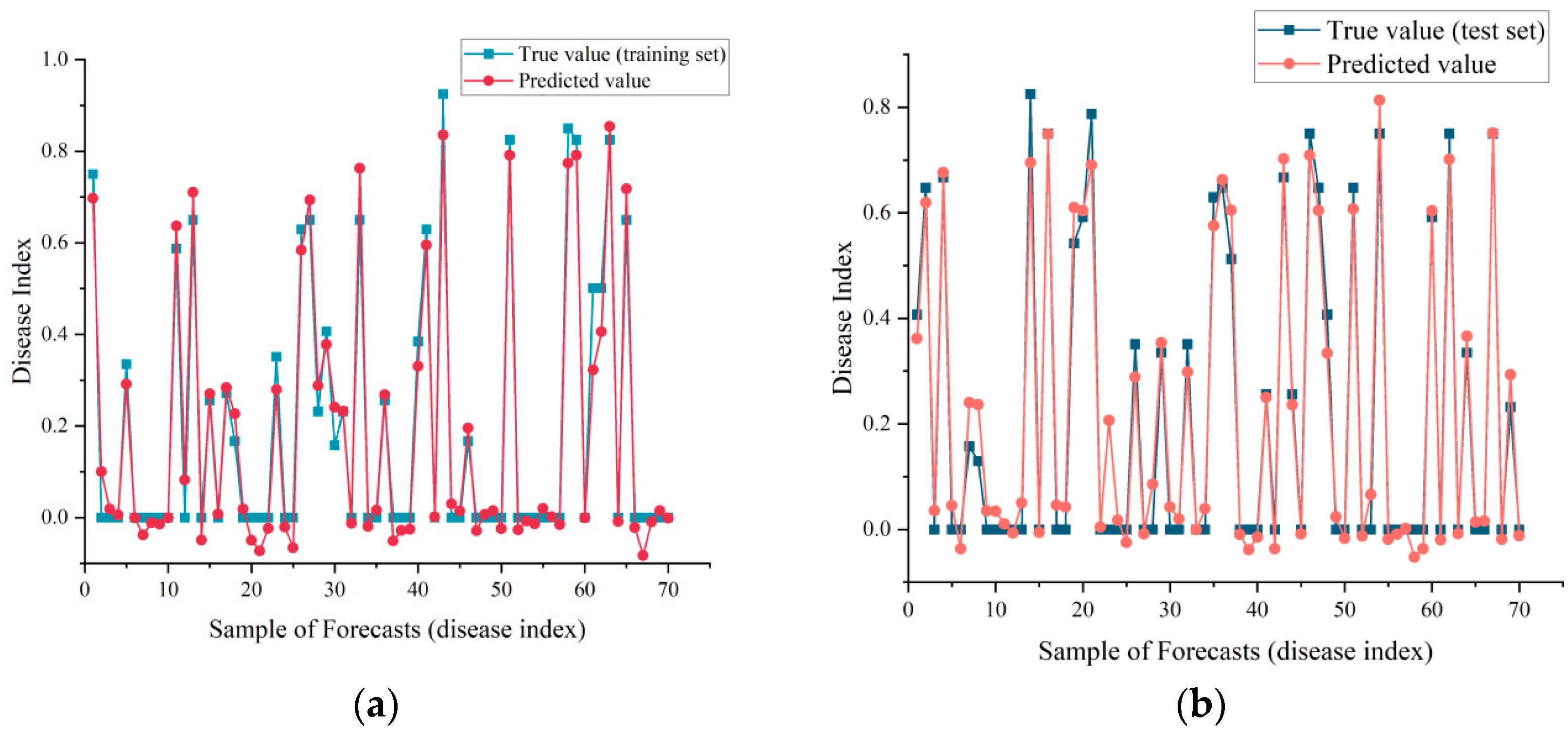
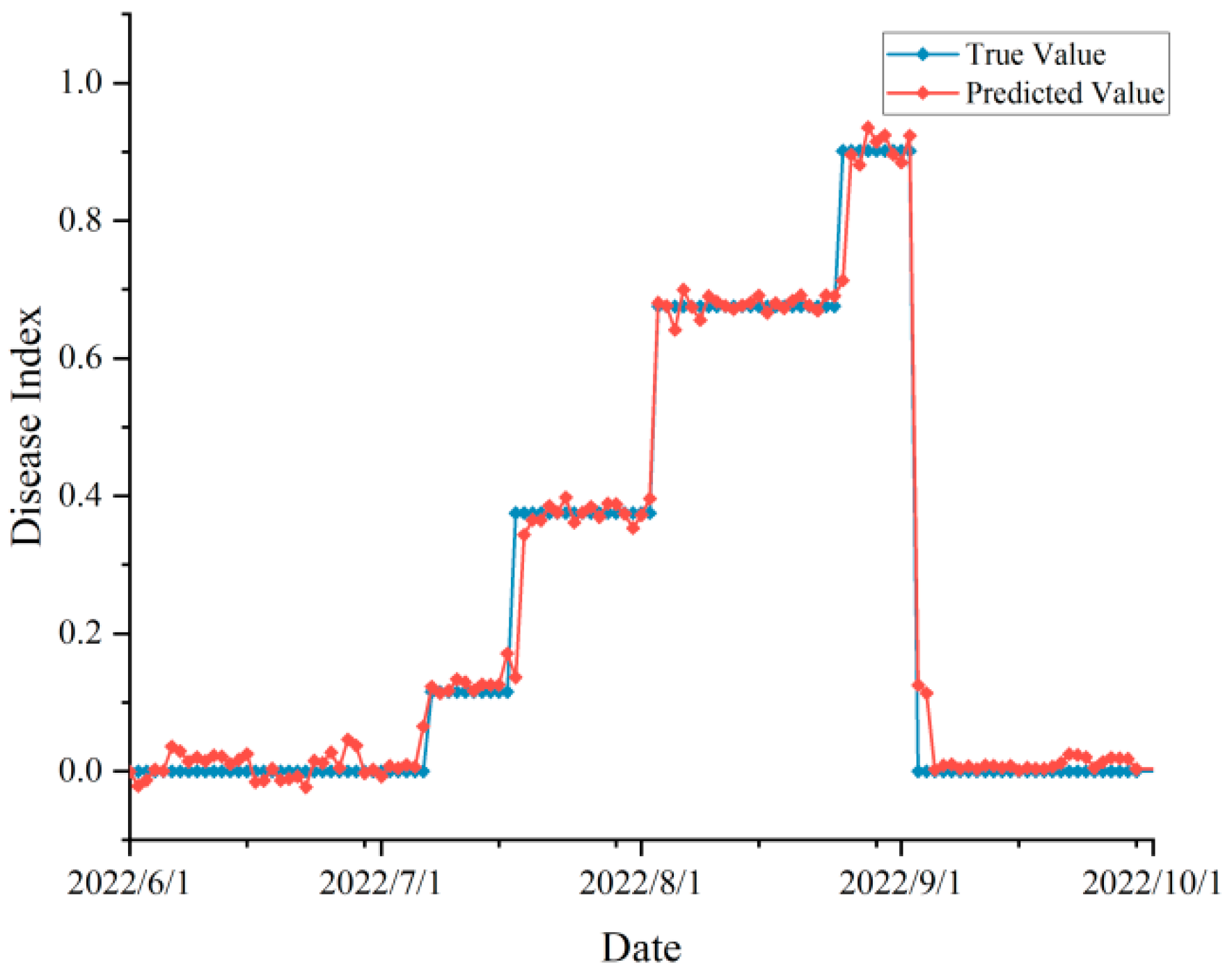
3.2. Disease Index Prediction
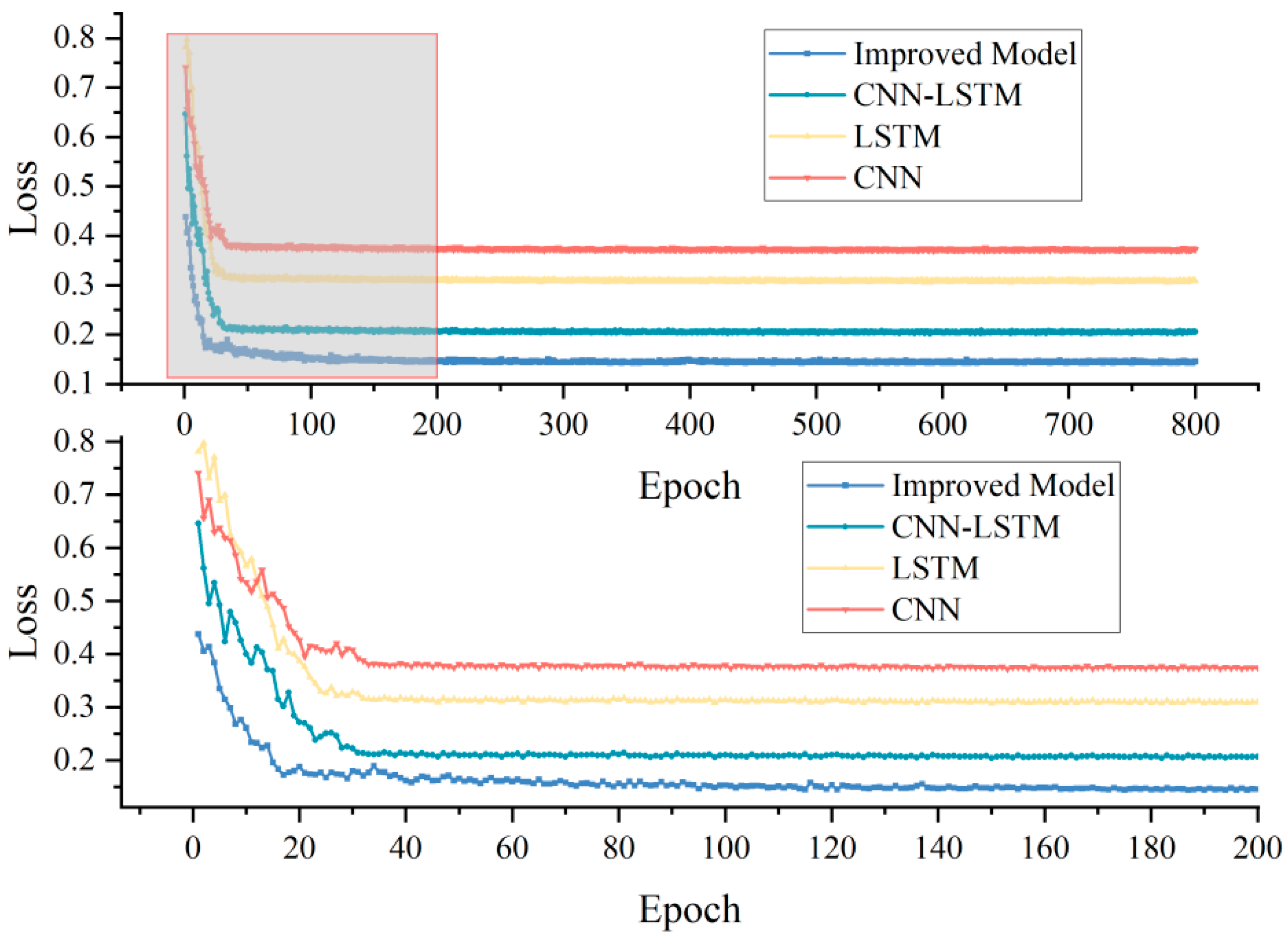
3.3. Comparison of Prediction Models
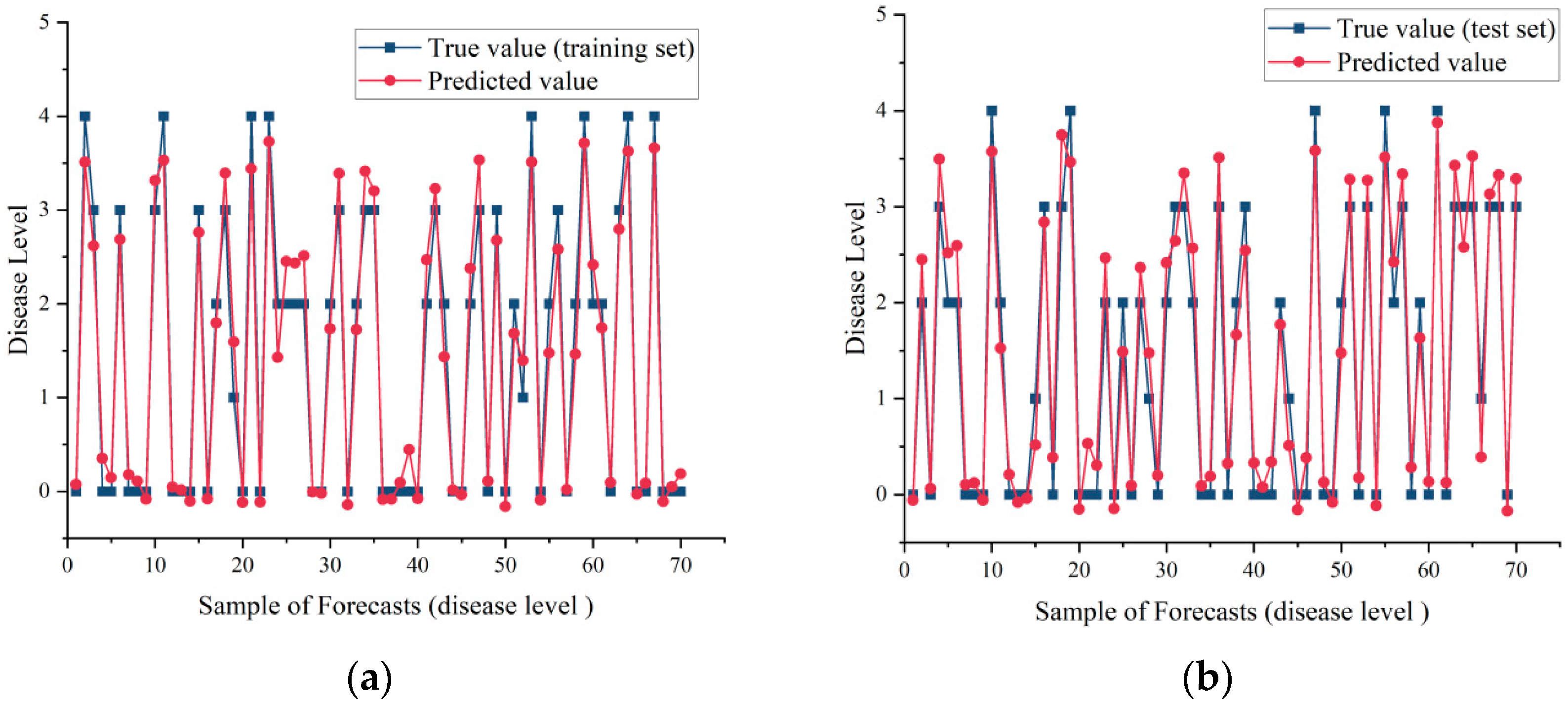
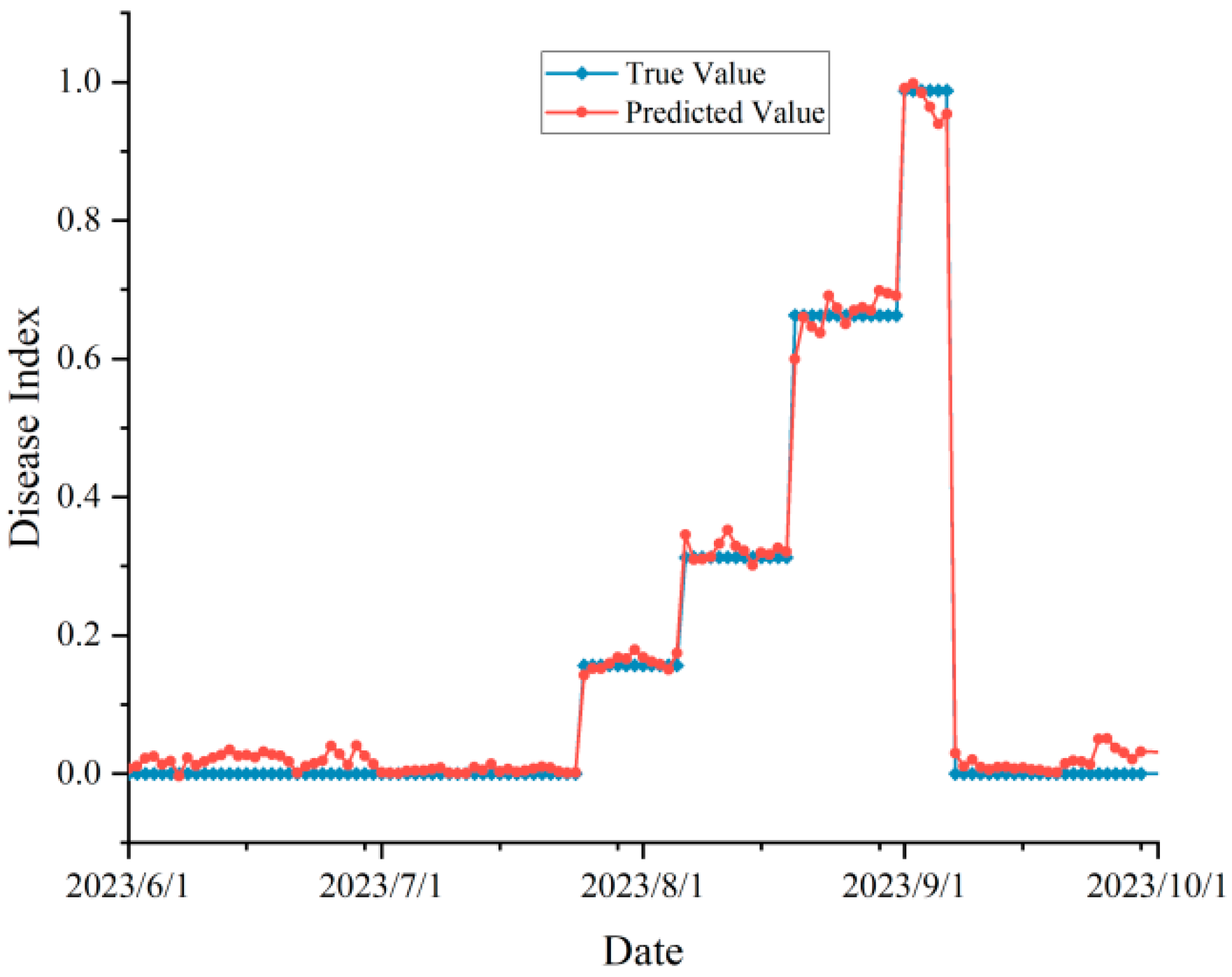
3.4. Model Validation
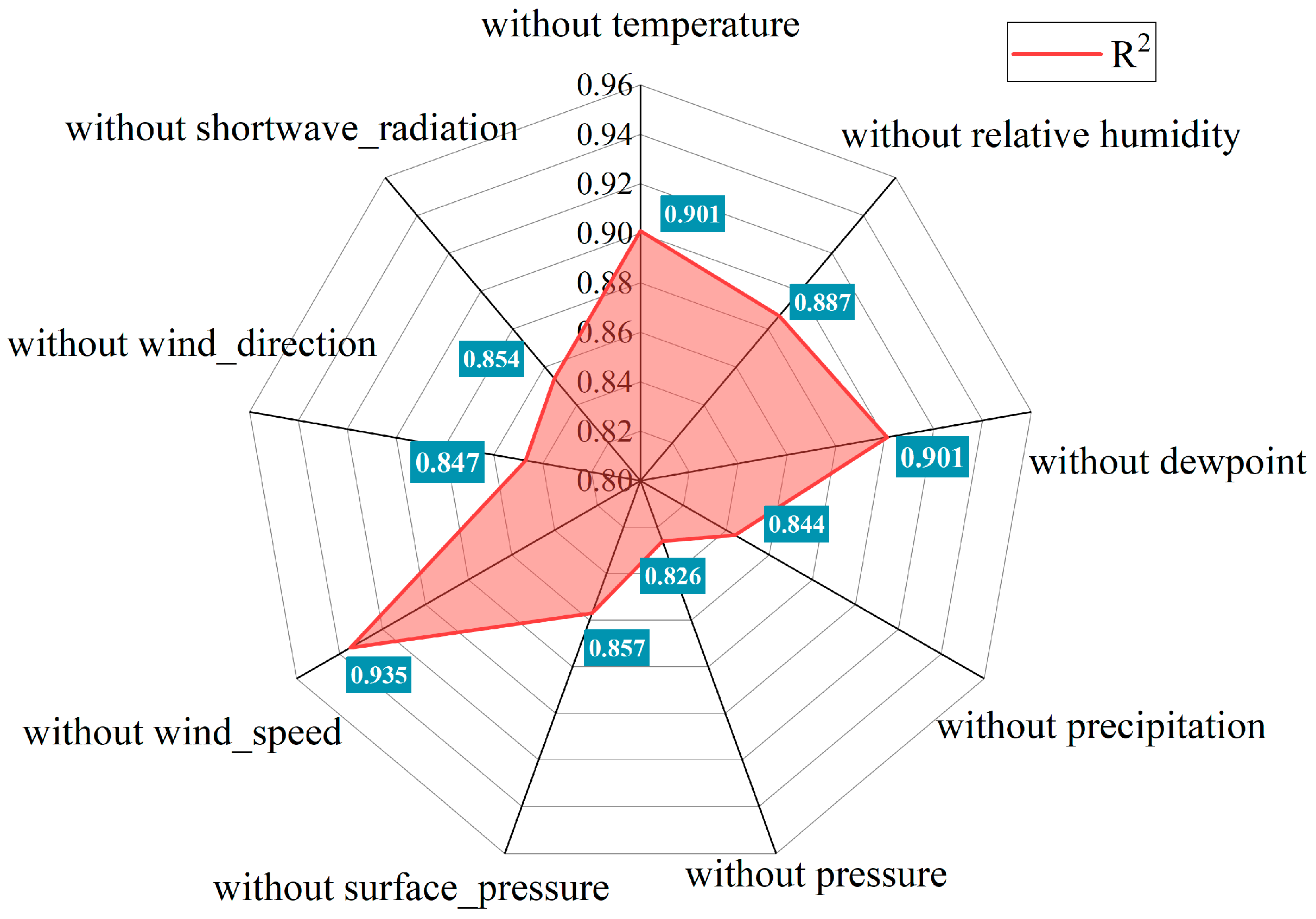
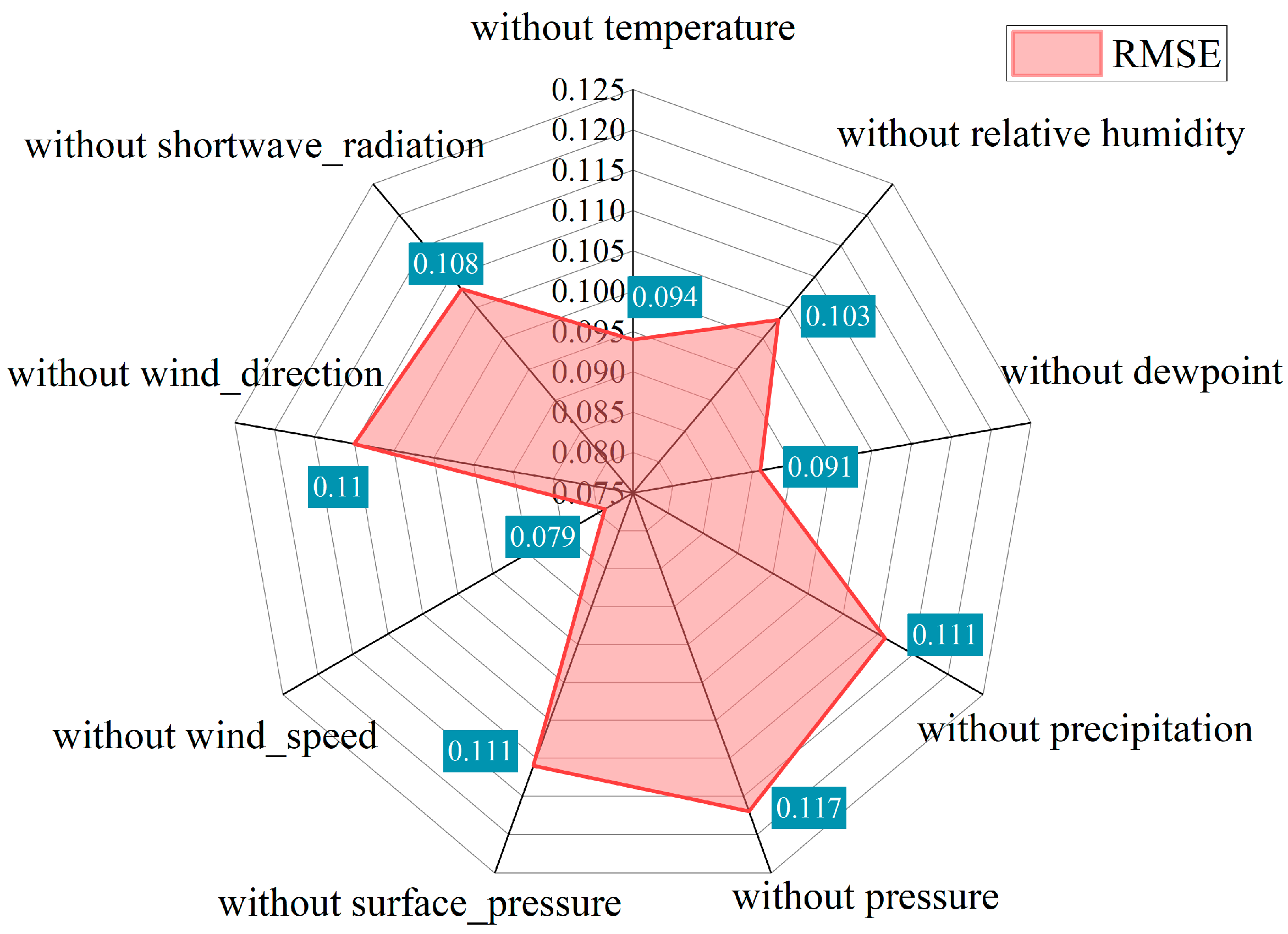
3.5. Sensitivity Analysis of the Proposed Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Giordano, D.F.; Pastor, N.; Palacios, S.; Oddino, C.M.; Torres, A.M. Peanut leaf spot caused by Nothopassalora personata. Trop. Plant Pathol. 2021, 46, 139–151. [Google Scholar] [CrossRef]
- Kundu, N.; Rani, G.; Dhaka, V.S.; Gupta, K.; Nayak, S.C.; Verma, S.; Ijaz, M.F.; Woźniak, M. IoT and interpretable machine learning based framework for disease prediction in pearl millet. Sensors 2021, 21, 5386. [Google Scholar] [CrossRef] [PubMed]
- Fulmer, A.M.; Mehra, L.K.; Kemerait, R.C., Jr.; Brenneman, T.B.; Culbreath, A.K.; Stevenson, K.L.; Cantonwine, E.G. Relating Peanut Rx risk factors to epidemics of early and late leaf spot of peanut. Plant Dis. 2019, 103, 3226–3233. [Google Scholar] [CrossRef] [PubMed]
- Kankam, F.; Akpatsu, I.B.; Tengey, T.K. Leaf spot disease of groundnut: A review of existing research on management strategies. Cogent Food Agric. 2022, 8, 2118650. [Google Scholar] [CrossRef]
- Paredes, J.A.; Edwards Molina, J.P.; Cazón, L.I.; Asinari, F.; Monguillot, J.H.; Morichetti, S.A.; Rago, A.M.; Torres, A.M. Relationship between incidence and severity of peanut smut and its regional distribution in the main growing region of Argentina. Trop. Plant Pathol. 2021, 47, 233–244. [Google Scholar] [CrossRef]
- Buja, I.; Sabella, E.; Monteduro, A.G.; Chiriacò, M.S.; De Bellis, L.; Luvisi, A.; Maruccio, G. Advances in plant disease detection and monitoring: From traditional assays to in-field diagnostics. Sensors 2021, 21, 2129. [Google Scholar] [CrossRef] [PubMed]
- Martinelli, F.; Scalenghe, R.; Davino, S.; Panno, S.; Scuderi, G.; Ruisi, P.; Villa, P.; Stroppiana, D.; Boschetti, M.; Goulart, R.L.; et al. Advanced methods of plant disease detection: A review. Agron. Sustain. Dev. 2015, 35, 1–25. [Google Scholar] [CrossRef]
- Patil, R.R.; Kumar, S. Predicting rice diseases across diverse agro-meteorological conditions using an artificial intelligence approach. PeerJ Comput. Sci. 2021, 7, e687. [Google Scholar] [CrossRef]
- Islam, M.M.; Adil, M.A.A.; Talukder, M.A.; Ahamed, M.K.U.; Uddin, M.A.; Hasan, M.K.; Sharmin, S.; Rahman, M.; Debnath, S.K. DeepCrop: Deep learning-based crop disease prediction with web application. J. Agric. Food Res. 2023, 14, 100764. [Google Scholar] [CrossRef]
- Fenu, G.; Malloci, F.M. Forecasting plant and crop disease: An explorative study on current algorithms. Big Data Cogn. Comput. 2021, 5, 2. [Google Scholar] [CrossRef]
- Azadbakht, M.; Ashourloo, D.; Aghighi, H.; Radiom, S.; Alimohammadi, A. Wheat leaf rust detection at canopy scale under different LAI levels using machine learning techniques. Comput. Electron. Agric. 2019, 156, 119–128. [Google Scholar] [CrossRef]
- Guan, Q.; Zhao, D.; Feng, S.; Xu, T.; Wang, H.; Song, K. Hyperspectral Technique For Detection Of Peanut Leaf Spot Disease Based On Improved PCA Loading. Agronomy 2023, 13, 1153. [Google Scholar] [CrossRef]
- Bhatia, A.; Chug, A.; Singh, A.P. Application of extreme learning machine in plant disease prediction for highly imbalanced dataset. J. Stat. Manag. Syst. 2020, 23, 1059–1068. [Google Scholar] [CrossRef]
- Xiao, Q.; Li, W.; Chen, P.; Wang, B. Prediction of crop pests and diseases in cotton by long short term memory network. In Intelligent Computing Theories and Application: Proceedings of the 14th International Conference, ICIC 2018, Wuhan, China, 15–18 August 2018; Proceedings, Part II 14; Springer International Publishing: New York, NY, USA, 2018; pp. 11–16. [Google Scholar]
- Ji, T.; Languasco, L.; Li, M.; Rossi, V. Effects of temperature and wetness duration on infection by Coniella diplodiella, the fungus causing white rot of grape berries. Plants 2021, 10, 1696. [Google Scholar] [CrossRef]
- Ji, T.; Salotti, I.; Dong, C.; Li, M.; Rossi, V. Modeling the effects of the environment and the host plant on the ripe rot of grapes, caused by the Colletotrichum species. Plants 2021, 10, 2288. [Google Scholar] [CrossRef] [PubMed]
- Juroszek, P.; Racca, P.; Link, S.; Farhumand, J.; Kleinhenz, B. Overview on the review articles published during the past 30 years relating to the potential climate change effects on plant pathogens and crop disease risks. Plant Pathol. 2020, 69, 179–193. [Google Scholar] [CrossRef]
- Benos, L.; Tagarakis, A.C.; Dolias, G.; Berruto, R.; Kateris, D.; Bochtis, D. Machine learning in agriculture: A comprehensive updated review. Sensors 2021, 21, 3758. [Google Scholar] [CrossRef]
- Bhagawati, R.; Bhagawati, K.; Singh, A.K.K.; Nongthombam, R.; Sarmah, R.; Bhagawati, G. Artificial neural network assisted weather based plant disease forecasting system. Int. J. Recent Innov. Trends Comput. Commun. 2015, 3, 4168–4173. [Google Scholar]
- Prank, M.; Kenaley, S.C.; Bergstrom, G.C.; Acevedo, M.; Mahowald, N.M. Climate change impacts the spread potential of wheat stem rust, a significant crop disease. Environ. Res. Lett. 2019, 14, 124053. [Google Scholar] [CrossRef]
- Fenu, G.; Malloci, F.M. An application of machine learning technique in forecasting crop disease. In Proceedings of the 3rd International Conference on Big Data Research, Cergy-Pontoise, France, 20–22 November 2019; pp. 76–82. [Google Scholar]
- Fenu, G.; Malloci, F.M. Artificial intelligence technique in crop disease forecasting: A case study on potato late blight prediction. In Intelligent Decision Technologies: Proceedings of the 12th KES International Conference on Intelligent Decision Technologies (KES-IDT 2020), Virtual, 17–19 June 2020; Springer: Singapore, 2020; pp. 79–89. [Google Scholar]
- Kim, Y.; Roh, J.-H.; Kim, H.Y. Early forecasting of rice blast disease using long short-term memory recurrent neural networks. Sustainability 2017, 10, 34. [Google Scholar] [CrossRef]
- Liu, K.; Zhang, C.; Yang, X.; Diao, M.; Liu, H.; Li, M. Development of an Occurrence Prediction Model for Cucumber Downy Mildew in Solar Greenhouses Based on Long Short-Term Memory Neural Network. Agronomy 2022, 12, 442. [Google Scholar] [CrossRef]
- Liu, K.; Mu, Y.; Chen, X.; Ding, Z.; Song, M.; Xing, D.; Li, M. Towards developing an epidemic monitoring and warning system for diseases and pests of hot peppers in Guizhou, China. Agronomy 2022, 12, 1034. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, J.; Zhang, J.; Yuan, L.; Zhou, X.; Xu, X.; Yang, G. Forecasting Alternaria Leaf Spot in Apple with Spatial-Temporal Meteorological and Mobile Internet-Based Disease Survey Data. Agronomy 2022, 12, 679. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A survey of deep learning and its applications: A new paradigm to machine learning. Arch. Comput. Methods Eng. 2020, 27, 1071–1092. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Neural Networks for Perception; Academic Press: Cambridge, MA, USA, 1992; pp. 65–93. [Google Scholar]
- Specht, D.F. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [PubMed]
- Chiteka, Z.A.; Gorbet, D.W.; Shokes, F.M.; Kucharek, T.A.; Knauft, D.A. Components of resistance to late leafspot in peanut. I. Levels and variability-implications for selection. Peanut Sci. 1988, 15, 25–30. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Jin, X.; Xie, Y.; Wei, X.S.; Zhao, B.R.; Chen, Z.M.; Tan, X. Delving deep into spatial pooling for squeeze-and-excitation networks. Pattern Recognit. 2022, 121, 108159. [Google Scholar] [CrossRef]
- Ying, X. An overview of overfitting and its solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Poernomo, A.; Kang, D.-K. biased dropout and crossmap dropout: Learning towards effective dropout regularization in convolutional neural network. Neural Netw. 2018, 104, 60–67. [Google Scholar] [CrossRef]
- Postalcıoğlu, S. Performance analysis of different optimizers for deep learning-based image recognition. Int. J. Pattern Recognit. Artif. Intell. 2020, 34, 2051003. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dogo, E.M.; Afolabi, O.J.; Nwulu, N.I.; Twala, B.; Aigbavboa, C.O. A comparative analysis of gradient descent-based optimization algorithms on convolutional neural networks. In Proceedings of the 2018 International Conference on Computational Techniques, Electronics and Mechanical Systems (CTEMS), Belagavi, India, 21–23 December 2018; pp. 92–99. [Google Scholar]
- Larcher, C.H.; Barbosa, H.J. Evaluating Models with Dynamic Sampling Holdout. In Applications of Evolutionary Computation: Proceedings of the 24th International Conference, EvoApplications 2021, Held as Part of EvoStar 2021, Virtual Event, 7–9 April 2021; Proceedings 24; Springer International Publishing: New York, NY, USA, 2021; pp. 729–744. [Google Scholar]
- Bhamra, G.K.; Borah, M.; Borah, P.K. Rhizoctonia Aerial Blight of Soybean, its Prevalence and Epidemiology: A Review. Agricultural 2022, 43, 463–468. [Google Scholar] [CrossRef]
- Barocco, R.L.; Sanjel, S.; Dufault, N.S.; Barrett, C.; Broughton, B.; Wright, D.L.; Small, I.M. Peanut Disease Epidemiology under Dynamic Microclimate Conditions and Management Practices in North Florida. Plant Dis. 2021, 105, 2333–2342. [Google Scholar] [CrossRef]
- Jain, S.; Ramesh, D. AI based hybrid CNN-LSTM model for crop disease prediction: An ML advent for rice crop. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–7. [Google Scholar]
- Patle, K.S.; Saini, R.; Kumar, A.; Palaparthy, V.S. Field evaluation of smart sensor system for plant disease prediction using lstm network. IEEE Sens. J. 2021, 22, 3715–3725. [Google Scholar] [CrossRef]
- Chen, P.; Xiao, Q.; Zhang, J.; Xie, C.; Wang, B. Occurrence prediction of cotton pests and diseases by bidirectional long short-term memory networks with climate and atmosphere circulation. Comput. Electron. Agric. 2020, 176, 105612. [Google Scholar] [CrossRef]
- Kim, T.-Y.; Cho, S.-B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Chung, W.H.; Gu, Y.H.; Yoo, S.J. District heater load forecasting based on machine learning and parallel CNN-LSTM attention. Energy 2022, 246, 123350. [Google Scholar] [CrossRef]
- Tang, J.; Li, Y.; Ding, M.; Liu, H.; Yang, D.; Wu, X. An ionospheric tec forecasting model based on a CNN-LSTM-attention mechanism neural network. Remote Sens. 2022, 14, 2433. [Google Scholar] [CrossRef]
- Wan, A.; Chang, Q.; Al-Bukhaiti, K.; He, J. Short-term power load forecasting for combined heat and power using CNN-LSTM enhanced by attention mechanism. Energy 2023, 282, 128274. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Pintelas, P. A CNN–LSTM model for gold price time-series forecasting. Neural Comput. Appl. 2020, 32, 17351–17360. [Google Scholar] [CrossRef]
- Elmaz, F.; Eyckerman, R.; Casteels, W.; Latré, S.; Hellinckx, P. CNN-LSTM architecture for predictive indoor temperature modeling. Build. Environ. 2021, 206, 108327. [Google Scholar] [CrossRef]
- Yan, R.; Liao, J.; Yang, J.; Sun, W.; Nong, M.; Li, F. Multi-hour and multi-site air quality index forecasting in Beijing using CNN, LSTM, CNN-LSTM, and spatiotemporal clustering. Expert Syst. Appl. 2021, 169, 114513. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease Level | Description |
|---|---|
| 0 | No disease |
| 1 | The lower leaves of the peanut plants having small necrotic spots or a small number of necrotic spots (none on upper canopy) |
| 2 | More lesions on the lower leaves and obvious lesions on the middle leaves |
| 3 | The middle and lower leaves of the peanut plant having more necrotic-spots and slight defoliation, and the upper leaves having necrotic spots |
| 4 | The upper, middle, and lower leaves of the peanut plant covered with necrotic spots and noticeable defoliation |
| Learning Rate | Test Set | Training Set | ||||||
|---|---|---|---|---|---|---|---|---|
| MAE | MBE | RMSE | MAE | MBE | RMSE | |||
| 0.01 | 0.907 | 0.059 | 0.005 | 0.071 | 0.914 | 0.050 | 0.003 | 0.052 |
| 0.001 | 0.951 | 0.049 | 0.006 | 0.063 | 0.952 | 0.045 | 0.014 | 0.063 |
| 0.0001 | 0.532 | 0.138 | 0.012 | 0.196 | 0.552 | 0.141 | 0.002 | 0.193 |
| Model | Test Set | Training Set | ||||||
|---|---|---|---|---|---|---|---|---|
| MAE | MBE | RMSE | MAE | MBE | RMSE | |||
| CNN-LSTM | 0.938 | 0.052 | 0.016 | 0.082 | 0.983 | 0.031 | 0.002 | 0.047 |
| LSTM | 0.830 | 0.184 | 0.146 | 0.267 | 0.845 | 0.139 | 0.113 | 0.221 |
| CNN | 0.796 | 0.235 | −0.205 | 0.316 | 0.802 | 0.218 | −0.197 | 0.302 |
| GRNN | 0.811 | 0.048 | −0.004 | 0.120 | 0.994 | 0.010 | −0.001 | 0.023 |
| BP Network | 0.455 | 0.134 | 0.014 | 0.218 | 0.509 | 0.120 | 0.007 | 0.199 |
| Ours | 0.951 | 0.049 | 0.007 | 0.063 | 0.952 | 0.045 | 0.014 | 0.063 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Z.; Chen, X.; Li, M.; Chi, Y.; Shi, D. Construction and Validation of Peanut Leaf Spot Disease Prediction Model Based on Long Time Series Data and Deep Learning. Agronomy 2024, 14, 294. https://doi.org/10.3390/agronomy14020294
Guo Z, Chen X, Li M, Chi Y, Shi D. Construction and Validation of Peanut Leaf Spot Disease Prediction Model Based on Long Time Series Data and Deep Learning. Agronomy. 2024; 14(2):294. https://doi.org/10.3390/agronomy14020294
Chicago/Turabian StyleGuo, Zhiqing, Xiaohui Chen, Ming Li, Yucheng Chi, and Dongyuan Shi. 2024. "Construction and Validation of Peanut Leaf Spot Disease Prediction Model Based on Long Time Series Data and Deep Learning" Agronomy 14, no. 2: 294. https://doi.org/10.3390/agronomy14020294
APA StyleGuo, Z., Chen, X., Li, M., Chi, Y., & Shi, D. (2024). Construction and Validation of Peanut Leaf Spot Disease Prediction Model Based on Long Time Series Data and Deep Learning. Agronomy, 14(2), 294. https://doi.org/10.3390/agronomy14020294